
kaggle比赛1-NFL Health & Safety - Helmet Assignment(NFL 健康与安全 - 头盔分配)
比赛链接
NFL Health & Safety - Helmet Assignment | Kaggle
21.9.10:数据集及目标
-
数据集介绍:
/train/and/test/folders contain the video mp4 files to be labeled.(需要标记的视频文件)train_labels.csv- This file is only available for the training dataset and provides the ground truth for the 120 training videos.(train/下的逐帧人员以及头盔的标记框)train_player_tracking.csvandtest_player_tracking.csvcontain the tracking data for all players on the field during the play.(人员的传感器信息,记录有人员的位置以及是否受冲撞)- NGS data is sampled at a rate of 10Hz, while videos are sampled at roughly 59.94Hz.(传感器信息和视频帧率不同)
- NGS data and videos can be approximately synced by linking the NGS data where
event == "ball_snap"to the 10th frame of the video (approximately syncronized to the ball snap in the video).(介绍如何将传感器信息与视频文件匹配) - The NGS data and the orientation of the video cameras are not consistent. Your solution must account for matching the orientation of the video angle relative to the NGS data.(NGS 数据和摄像机的方向不一致。 您的解决方案必须考虑匹配视频角度相对于 NGS 数据的方向。)
- NGS also includes the speed (
s), acceleration (a),distance traveled from prior time point, in yards(dis), orientation of player (deg) (o) and angle of player motion (dir) for each player. More details can be found in the data description page.(NGS 还包括每个玩家的速度 (s)、加速度 (a)、方向 (o) 和方向 (dir)。 更多详细信息可以在数据描述页面中找到。)
train_baseline_helmets.csvandtest_baseline_helmets.csvcontain imperfect baseline predictions for helmet boxes. The model used to create these files was trained only on the additional images found in the images folder. If you so choose, you may train your own helmet detection model and ignore these files.(一个官方提供的预测基准信息,可以忽略)- Extra Images:
- The
/images/folder andimage_labels.csvcontains helmet boxes for random frames in videos. These images were used to train the model that produced the*_baseline_helmets.csvfiles. You may choose to use these to train your own helmet detection model.(随机抽取的各帧图像,以及对应的头盔位置框)
- The
-
目标:
- 队员头盔的定位:
- 这一部分需要用到train(图像),train_labels(图像逐帧对应的队员的编号,以及头盔的边界框位置)。
- 所用算法可以是数据分割的算法(YOLO-V5),通过该算法可以得到test中逐帧的头盔位置。
- 通过该部分不能得到队员对应的编号
- 给队员匹配对用的主客场编号:
- 这一部分需要用到train_player_tracking(有各队员在场中对应的x,y坐标)
- 通过队员的坐标X,Y以及预测的帽子的边框,将边框与运动员主客场的编号进行匹配
- 队员头盔的定位:
21.9.11:尝试SORT
- 尝试使用深度学习方法强化的SORT(simple online and realtime tracking)进行处理(SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC 2017)(https://github.com/nwojke/deep_sort)
- 所要解决的任务:框出人(要尽可能地框全),并且给人正确的编号。和本赛题很相似(框出头盔,并且给头盔的队员以相应的编号)
- 重点:
- sort:simple online and realtime tracking(简单在线实时跟踪):一种简单的跟踪框架,它使用匈牙利方法在图像空间中执行卡尔曼滤波和逐帧数据关联,并使用基于边界框重叠的关联度量。
- 匈牙利算法(Hungarian Algorithm)是一种组合优化算法(combinatorial optimization algorithm),用于求解指派问题(assignment problem),算法时间复杂度为O(n3)。
- 该方法的创新之处在于应用了一个预训练的卷积神经网络 (CNN)获取具有良好辨别力的特征嵌入,以执行最近邻查询;并基于运动和外观信息进行更明智的度量(一方面,马哈拉诺比斯距离提供了关于基于运动的可能对象位置的信息,这对于短期预测特别有用。 另一方面,余弦距离考虑的外观信息在运动的辨别力较低时,对于在长期遮挡后恢复身份特别有用。)。(在原文中预训练的CNN可以用于识别行人)
- 跟踪场景定义在包含边界框中心位置(u,v),纵横比γ,高度h以及它们各自在图像坐标中的速度(u', v', γ', h')的八维状态空间中,将边界坐标(u,v,γ,h)作为对物体状态的直接观察
问题:
对科研的启发:
-
YOLO网络主要由三个主要组件组成。
1)Backbone -在不同图像细粒度上聚合并形成图像特征的卷积神经网络。(主干)
2)Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。(特征混合/特征提取器)
3)Head: 对图像特征进行预测,生成边界框和并预测类别。(预测器)
-
yolo-v4
-
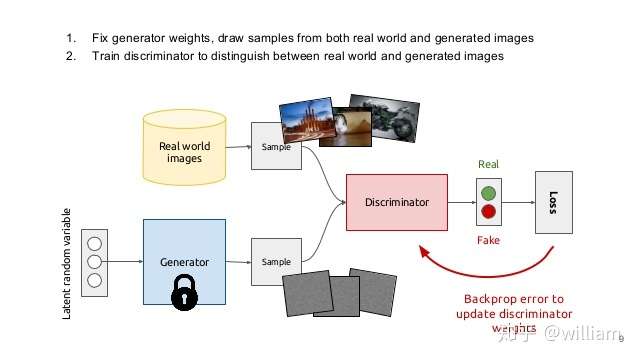
自对抗训练:Self-Adversarial Training(SAT)
- Self-Adversarial Training是在一定程度上抵抗对抗攻击的数据增强技术。CNN计算出Loss, 然后通过反向传播改变图片信息,形成图片上没有目标的假象,然后对修改后的图像进行正常的目标检测。需要注意的是在SAT的反向传播的过程中,是不需要改变网络权值的。
- 使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。
-
类标签平滑
-
Class label smoothing是一种正则化方法。如果神经网络过度拟合和/或过度自信,我们都可以尝试平滑标签。也就是说在训练时标签可能存在错误,而我们可能“过分”相信训练样本的标签,并且在某种程度上没有审视了其他预测的复杂性。因此为了避免过度相信,更合理的做法是对类标签表示进行编码,以便在一定程度上对不确定性进行评估。YOLO V4使用了类平滑,选择模型的正确预测概率为0.9,例如[0,0,0,0.9,0...,0 ]。
-
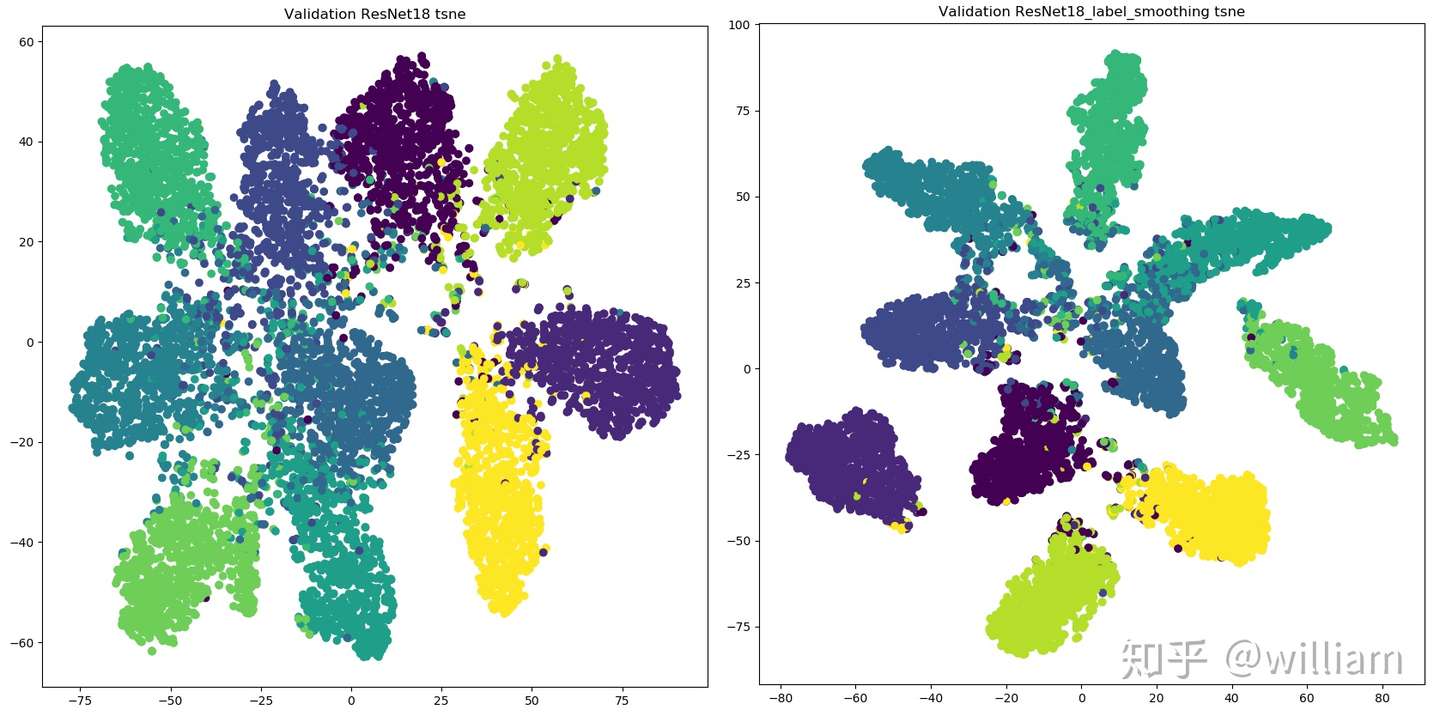
从上图看出,标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离,实现更好的泛化。
-
YOLO V5 似乎没有使用类标签平滑。
-
-
-
YOLOV5
-
都会通过数据加载器传递每一批训练数据,并同时增强训练数据。数据加载器进行三种数据增强:缩放,色彩空间调整和马赛克增强。
- 马赛克数据增强确实能有效解决模型训练中最头疼的“小对象问题”,即小对象不如大对象那样准确地被检测到。
-
在YOLO V5 中锚定框是基于训练数据自动学习的。
-
对于COCO数据集来说,YOLO V5 的配置文件*.yaml 中已经预设了640×640图像大小下锚定框的尺寸:
# anchors anchors: - [116,90, 156,198, 373,326] # P5/32 - [30,61, 62,45, 59,119] # P4/16 - [10,13, 16,30, 33,23] # P3/8 -
但是对于你的自定义数据集来说,由于目标识别框架往往需要缩放原始图片尺寸,并且数据集中目标对象的大小可能也与COCO数据集不同,因此YOLO V5会重新自动学习锚定框的尺寸。
-
YOLO V4并没有自适应锚定框。
-
-
Backbone-跨阶段局部网络(CSP)
- YOLO V5和V4都使用CSPDarknet作为Backbone,从输入图像中提取丰富的信息特征。CSPNet全称是Cross Stage Partial Networks,也就是跨阶段局部网络。CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。
- CSPNet实际上是基于Densnet的思想,复制基础层的特征映射图,通过dense block 发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。
-
Neck-路径聚合网络(PANET)
- Neck主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。在PANET出来之前,FPN一直是对象检测框架特征聚合层的State of the art,直到PANET的出现。在YOLO V4的研究中,PANET被认为是最适合YOLO的特征融合网络,因此YOLO V5和V4都使用PANET作为Neck来聚合特征。
- PANET基于 Mask R-CNN 和 FPN 框架,同时加强了信息传播。该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3x3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息。同时使用自适应特征池化(Adaptive feature pooling)恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配。
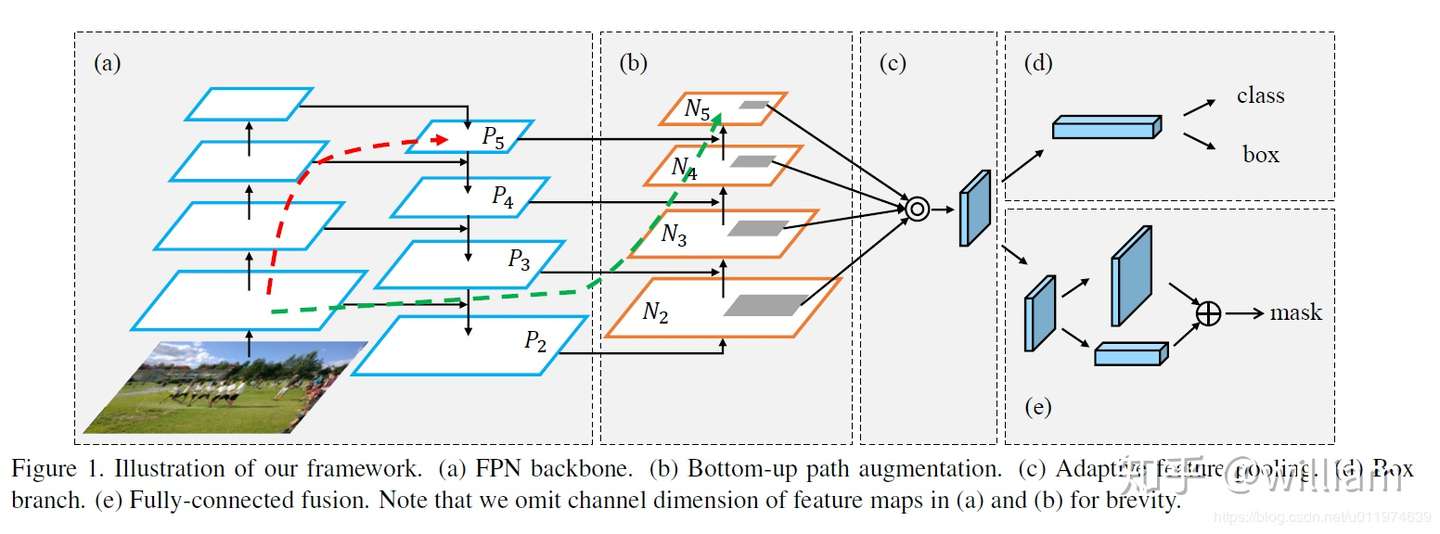 pi 代表 CSP 主干网络中的一个特征层
pi 代表 CSP 主干网络中的一个特征层
-
Head-YOLO 通用检测层
- 模型Head主要用于最终检测部分。它在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。在 YOLO V5模型中,模型Head与之前的 YOLO V3和 V4版本相同。
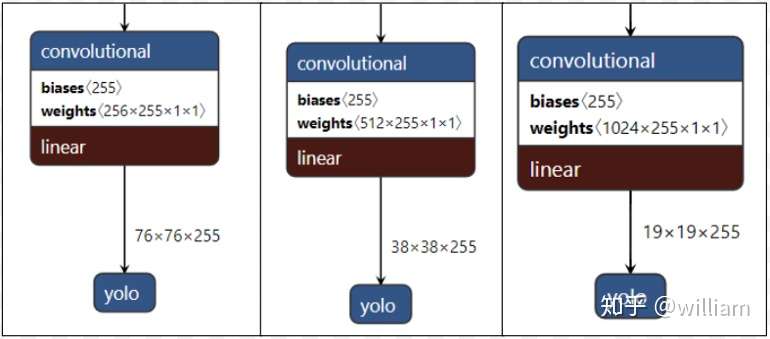 这些不同缩放尺度的Head被用来检测不同大小的物体,每个Head一共(80个类 + 1个概率 + 4坐标) * 3锚定框,一共255个channels。
这些不同缩放尺度的Head被用来检测不同大小的物体,每个Head一共(80个类 + 1个概率 + 4坐标) * 3锚定框,一共255个channels。
-
YOLO 系列的损失计算是基于 objectness score, class probability score,和 bounding box regression score。YOLO V5使用 GIOU Loss作为bounding box的损失,使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时我们也可以使用fl _ gamma参数来激活Focal loss计算损失函数。
-
One more thing
-
There are infinite ways of approaching this problem. Some ideas that can be explored are:
- Using optimization methods to match helmet boxes to NGS data based on relative distances.
- Tracking of helmets throughout the duration of a play and assigning labels to these tracks.
- Imputing boxes for partially occluded helmets based on the surrounding frames.
- Using computer vision techniques to identify player jersey numbers and pair with helmets.
- Identifying key points on the field (line numbers, hash marks) as reference points.
We are excited to see what solutions the kaggle community comes up with!
-
总的来说,YOLO V4 在性能上优于YOLO V5,但是在灵活性与速度上弱于YOLO V5。由于YOLO V5仍然在快速更新,因此YOLO V5的最终研究成果如何,还有待分析。我个人觉得对于这些对象检测框架,特征融合层的性能非常重要,目前两者都是使用PANET,但是根据谷歌大脑的研究,BiFPN才是特征融合层的最佳选择。谁能整合这项技术,很有可能取得性能大幅超越。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号