
cuda0-cuda编程模型
1,基础知识
- CUDA模型是一个异构模型,需要CPU和GPU协同工作
- 在CUDA中,host指代cpu及其内存,device指代gpu及其内存
- cuda程序既包含host程序,又包含device程序,分别在cpu和gpu上运行
- host与device之间可以进行通信,可以进行数据拷贝
2,程序执行流程
- 分配host内存,并进行数据初始化
- 分配device内存,并从host拷贝数据到device
- 调用cuda核函数在device上完成指定的运算
- 将device上的运算结果拷贝到host上
- 释放device和host上分配的内存
3,核函数
- 程序执行流程中最重要的过程是调用cuda核函数在device上完成指定的运算
- kernel是cuda的一个重要概念,是在device线程中并行执行的函数
- 核函数用__global__符号声明,在调用的时候用<<<grid,block>>>指定kernel要执行的线程数量
- cuda中,每一个线程都要执行核函数,并且每一个线程都会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx获得。
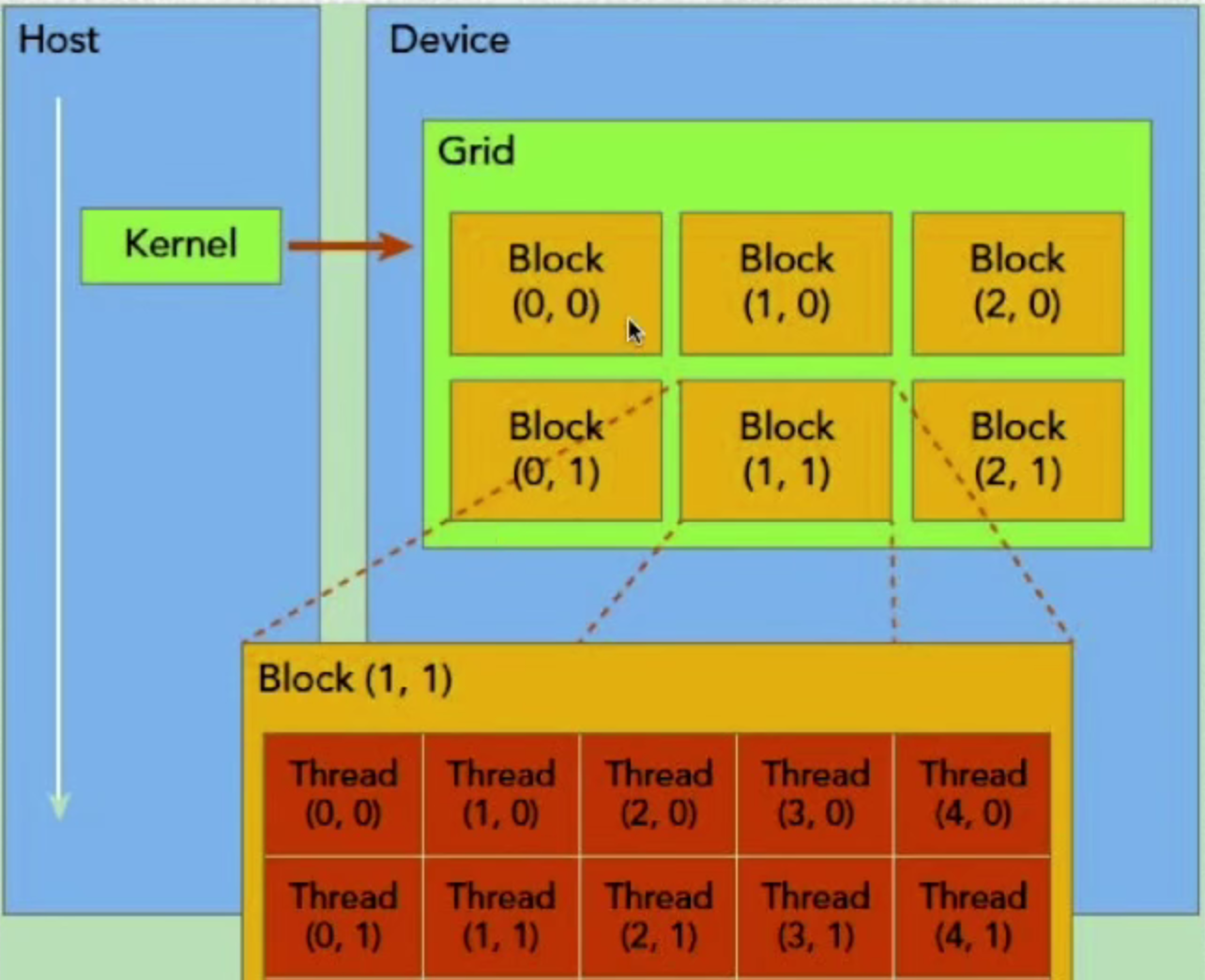
4,cuda程序层次结构-kernel,grid,block,warp,thread
- GPU上很多并行化的轻量级线程
- kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid)
- 同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次
- 网格又可以分为很多线程块(block),一个线程块里包含很多线程,这是第二个层次
- warp:32个线程一组,这是第三个层次
- grid和block一般是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时缺省值初始化为1
- grid和block可以灵活地定义成1-dim,2-dim以及3-dim结构
- kenrnel在调用时必须通过执行配置<<<grid_size,block_size>>>指定kernel所使用的线程数及结构。(grid_size对应一个kernel/一个grid/一次调用中block的数量,block_size对应一个block中Thread数量。)
- 不同GPU架构,grid和kernel的维度有限制
- 从开普勒架构开始,最大允许的block_size为1024,最大允许的grid_size为2^32-1(最多可以指派大约两万亿个线程,一般来说只要线程数比CPU中的计算核心数多几倍时,就有可能充分利用GPU中的全部计算资源。)
dim3 grid_size(3,2); //总的grid/kernel有6个block
dim3 block_size(5,3); //每个block有15个线程,也就是该核函数会调用90个线程。(最好定义为32的倍数)
kernel_func<<<grid_size,block_size>>>(params...);
dim3 grid_size(128);
dim3 block_size(256);
kernel_func<<<grid_size,block_size>>>(params...);
dim3 grid_size(100,120);
dim3 block_size(16,16,1);
kernel_func<<<grid_size,block_size>>>(params...);
5,函数类型限定词:__global__ __device__ __host__
- GPU程序是异构模型,所以需要区分host和device上的代码,在cuda中是通过函数类型限定词区别host和device上的函数,主要的三个函数类型限定词如下
- __global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变类型参数,不能成为类成员函数
- 注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步
- __device__:在device上执行,但尽可以从decive中调用,不可以和__global__同时用
- __host__:在host上执行,尽可以从host上调用,一般省略不写,不可以和__global__同时用,但可以和__device__同时用,此时函数会在device和host都编译。
6,cuda内置变量
-
一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程在grid中的位置,而threadIdx指明线程所在block中的位置
- blockIdx包含三个值:blockIdx.x,blockIdx.y,blockIdx.z
- threadIdx同样包含三个值:threadIdx.x,threadIdx.y,threadIdx.z
-
一个线程块上的线程是放在同一个流处理器(SM)上的
-
单个SM的资源有限,这导致线程块中线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个(由GPU的架构决定)
-
有时候需要知道一个线程在block中的全局ID,此时就必须还要知道block的组织结构,这是通过线程的内置变量blockDim获得,它获取线程块各个维度的大小;另外线程还有内置变量gridDim,用于获得网格块中各个维度的大小。
附录
官方文档
最重要的两个
CUDA C++ Programming Guide
CUDA C++ Best Practices Guide
针对特定GPU架构进行优化的指南
kepler~turing tuning guide
CUDA API手册
行动是治愈恐惧的良药,而犹豫拖延将不断滋养恐惧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号