
paddle常规操作
0,有时间看看源码还是看看源码吧,虽然看了也还是菜鸡。。。
https://github.com/PaddlePaddle
1,常用方法总结
'''========================================1,资源配置========================================'''
paddle.fluid.is_compiled_with_cuda()
paddle.set_device('gpu:0'/'cpu')
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
'''========================================2,tensor========================================'''
#************************************转为tensor************************************
paddle.to_tensor(**, stop_gradient=False)
#************************************转变tensor的dtype************************************
paddle.cast(tensor, 'float32')
tensor.astype('float32')
#************************************维度扩展************************************
tensor.unsqueeze([0, 1])
#************************************取随机************************************
paddle.randn([2,10])
'''========================================3,数据加载========================================'''
paddle.io.Dataset/DataLoader
class myDataset(Dataset):
def __init__(self, files):
...
def __len__(self):
return len(...)/...shape[0]
def __getitem__(self,index):
...
return data, label
traingData = myDataset(files)
trainingDataloader = Dataloader(traingData, batch_size=, shuffle=True)
#************************************获取数据和标签************************************
data, label = next(iter(trainingDataloader))
for (data, label) in trainingDataloader:
for batch, (data, label) in enumerate(trainingDataloader):
'''========================================4,基本模型库========================================'''
#************************************模型构造方法1 nn基础模型************************************
myNet = paddle.nn.Linear(10, 10)
myNet.weight
myNet.weight.grad
myNet.bias
myNet.bias.grad
myNet.parameters()
#************************************模型构造方法2.1 nn.Sequential************************************
myNet = paddle.nn.Sequential(
nn.Linear(10, 10),
nn.Tanh(),
nn.Linear(10, 10)
)
[param.shape for param in myNet.parameters()]
[(name, param.shape) for (name, param) in myNet.named_parameters()]
#************************************模型构造方法2.2 collections.OrderedDict 与 nn.Sequential 结合,为子模块命名************************************
myNet = nn.Sequential(('hidden_linear',nn.Linear(10,10)),
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(10,10)))
[param.shape for param in myNet.parameters()]
[(name, param.shape) for (name, param) in myNet.named_parameters()]
myNet.hidden_linear.weight
myNet.hidden_linear.weight.grad
myNet.hidden_linear.bias
myNet.hidden_linear.bias.grad
#************************************动态添加子模块************************************
nn.Sequential().add_sublayer()
#************************************模型构造方法3 nn.Module************************************
paddle.nn.Layer
class myModule(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, inputs):
...
myNet = myModule()
[(name, param.shape) for (name, param) in myNet.named_parameters()]
'''========================================5,优化器========================================'''
#************************************四大类优化器************************************
opt = paddle.optimizer.SGD(learning_rate=lr, parameters=myNet.parameters())
paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())
paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())
paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())
#************************************5.1:针对模型不同层设置不同的学习率************************************
#************************************5.2:自定义根据 epoch 改变学习率************************************
#************************************5.3:手动设置学习率衰减区间************************************
#************************************5.4:变学习率API,与pytorch相比不用step************************************
lr = paddle.optimizer.lr.PolynomialDecay(learning_rate=0.01, decay_steps=total_steps, end_lr=0.001)
opt = paddle.optimizer.Momentum(learning_rate=lr, parameters=model.parameters())
'''========================================6,损失函数========================================'''
paddle.nn.CrossEntropyLoss()
paddle.nn.functional.cross_entropy()
'''========================================7,训练========================================'''
myNet.train()
loss.backward()
opt.step()
opt.clear_grad()
'''========================================8,保存========================================'''
#************************************方法一************************************
paddle.save(opt.state_dict(), '')
paddle.save(model.state_dict(), '')
#************************************方法二************************************
paddle.save(optimizer, '') #报错,不支持
paddle.save(myNet, '') #报错,不支持
'''========================================9.加载========================================'''
#保存方法一的对应加载
myNet = myModule()
model_dict = paddle.load()
myNet.set_state_dict(model_dict)
optimizer同理
#保存方法二的对应加载,不支持
myNet = paddle.load()
optimizer = paddle.load()
'''========================================10,测试========================================'''
myNet.eval()
'''========================================11,计算准确率========================================'''
paddle.metric.Accuracy()
'''========================================12,视觉库========================================'''
paddle.vision
paddle.vision.models
paddle.vision.transforms
'''========================================其他========================================'''
model.parameters()
model.named_parameters()
model.state_dict()
optimizer.state_dict()
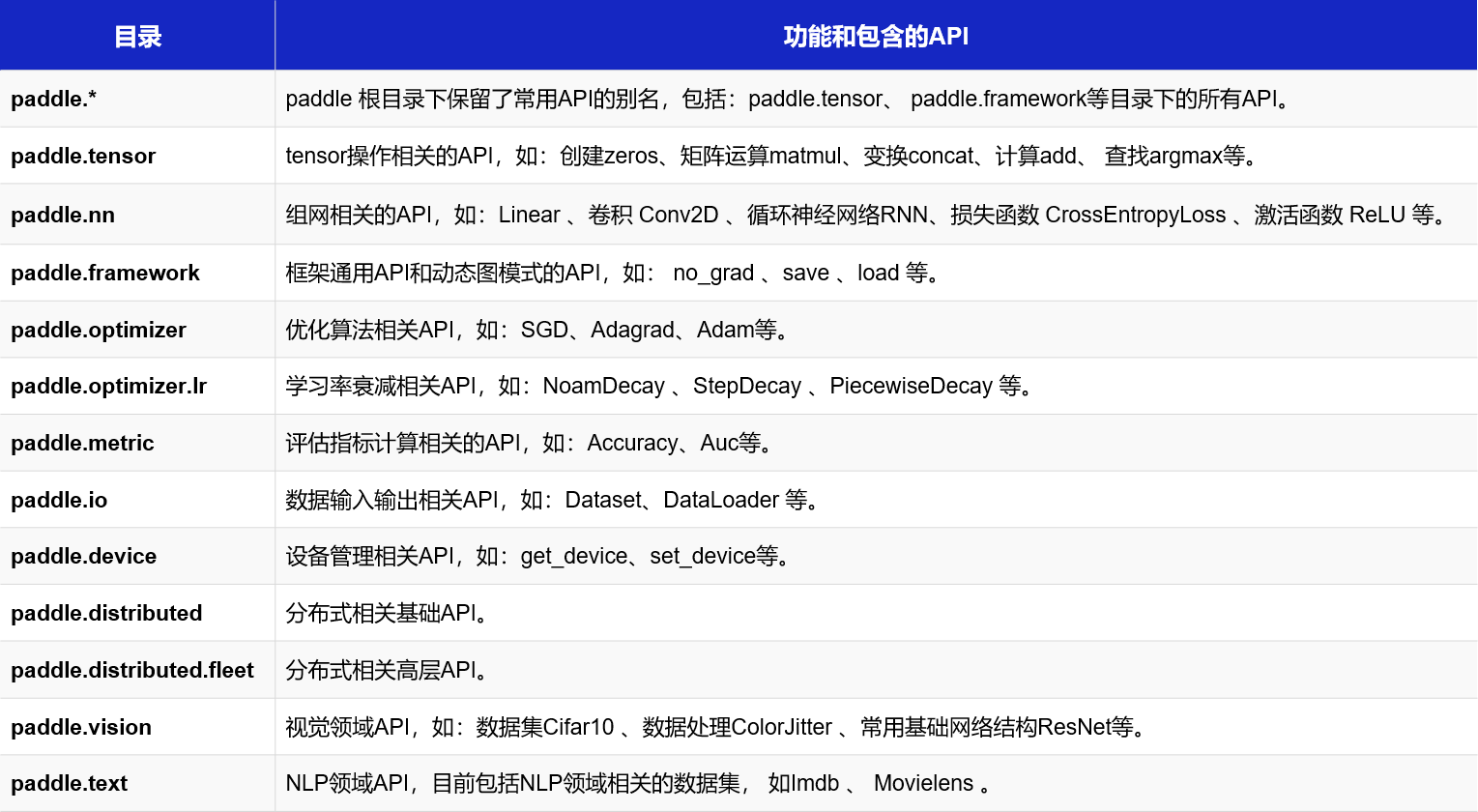
2,paddle API文档
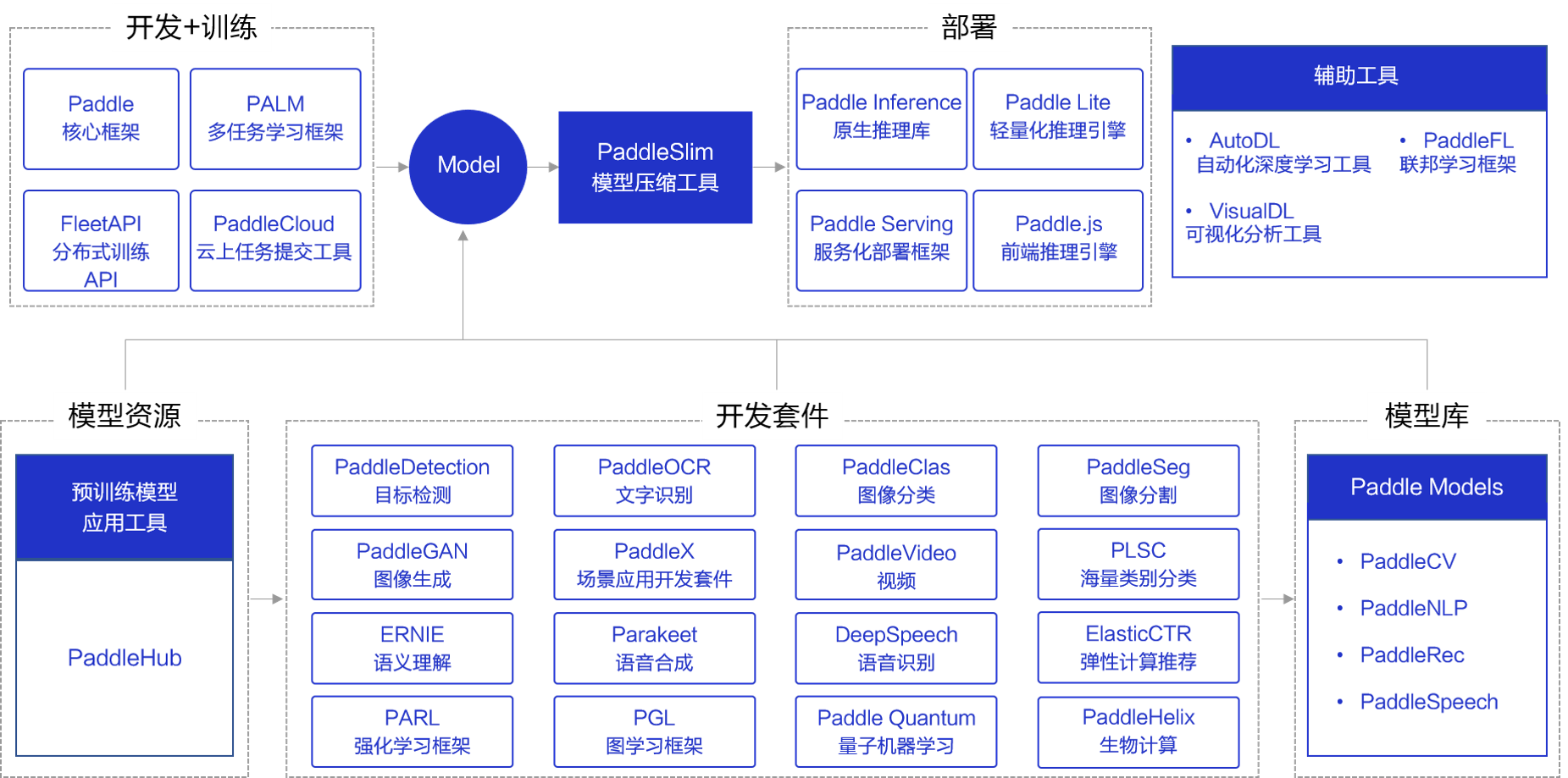
3,paddle 组件
行动是治愈恐惧的良药,而犹豫拖延将不断滋养恐惧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号