
pytorch中网络特征图(feture map)、卷积核权重、卷积核最匹配样本、类别激活图(Class Activation Map/CAM)、网络结构的可视化方法
0,可视化的重要性:
深度学习很多方向所谓改进模型、改进网络都是在按照人的主观思想在改进,常常在说模型的本质是提取特征,但并不知道它提取了什么特征、哪些区域对于识别真正起作用、也不知道网络是根据什么得出了分类结果。为了增强结果的可解释性,需要给出模型的一些可视化图来证明模型或新methods对于任务的作用,这一点不仅能增加新模型或新methods可信度;还可以根据可视化某个网络的结果分析其不足之处,从而提出新的改进方法。(写论文还可以用来凑字数、凑工作量:)
无特殊说明,本文中所用的网络是:
torchvision.models.resnet50(pretrained=True)
所用的图片为

1,特征图(feture map)
- 概念
特征图是一个在深度学习的研究过程中经常会遇到的概念,简单来说就是对输入进行一次计算处理后的输出,通过对特征图的可视化可以看出输入样本在网络中的变化情况。 - 可视化方法:
- 直接可视化:直接让输入数据经过各层网络,获取各层网络处理后的输出,然后绘制想要展示的特征图即可。
- 反卷积网络(deconvnet)From 'Visualizing and Understanding Convolutional Networks':对一个训练好的神经网络中任意一层feature map经过反卷积网络后重构出像素空间,主要操作是
- Unpooling/反池化:将最大值放到原位置,而其他位置直接置零。
- Rectification:同样使用Relu作为激活函数。
- Filtering/反卷积:使用原网络的卷积核的转置作为卷积核,对Rectification后的输出进行卷积。
- 导向反向传播(Guided-backpropagation)From 'Striving for simplicity: The all convolutional net':其与反卷积网络的区别在于对ReLU的处理方式,在反卷积网络中使用ReLU处理梯度,只回传梯度大于0的位置;而在普通反向传播中只回传feature map中大于0的位置;在导向反向传播中结合这两者,只回传输入和梯度都大于0的位置。
- 例子
'''方法1,直接可视化'''
import torch
import torchvision
import cv2
from PIL import Image
import torchvision.models as models
import torch.nn as nn
from matplotlib import pyplot as plt
import math
'''1,加载训练模型'''
resnet50 = models.resnet50(pretrained=True)
print(resnet50)
'''2,提取CNN层,非必须'''
conv_layers = []
model_weights = []
model_children = list(models.resnet50().children())
counter = 0
for i in range(len(model_children)):
if type(model_children[i]) == nn.Conv2d:
counter += 1
model_weights.append(model_children[i].weight)
conv_layers.append(model_children[i])
elif type(model_children[i]) == nn.Sequential:
for j in range(len(model_children[i])):
for child in model_children[i][j].children():
if type(child) == nn.Conv2d:
counter += 1
model_weights.append(child.weight)
conv_layers.append(child)
'''3,读取数据'''
img = cv2.cvtColor(cv2.imread('data.jpg'), cv2.COLOR_BGR2RGB)
img = torchvision.transforms.Compose([
torchvision.transforms.ToPILImage(),
torchvision.transforms.Resize((1050, 1680)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])(img).unsqueeze(0)
'''4,特征映射,这里绘制第一层卷积的feature map'''
featuremaps = [conv_layers[0](img)]
plt.figure(1)
for i in range(64):
plt.subplot(8, 8, i + 1)
plt.axis('off')
plt.imshow(featuremaps[0][0, i, :, :].detach(), cmap='gray')
plt.show()

2,卷积核权重
- 概念
卷积核的计算可以看作是在计算相似度,二维卷积核本身可以看作是一副缩略图,一维卷积核本身也可以看作是一段一维信号,卷积核权重的可视化就是将这些信息可视化。(虽然这些信息几乎都是杂乱无章的,没什么用:) - 可视化方法
取出某个想要可视化的卷积核权重,然后绘图即可。 - 例子
for i in range(64): plt.subplot(8, 8, i+1) plt.axis('off') plt.imshow(model_weights[0][i][0, :, :].detach(), cmap='gray') plt.show()
3,卷积核最匹配样本
- 概念
正如2中提到的,卷积核的计算可以看作是在计算相似度,那么在一批样本中经过卷积核计算以后的相似度值肯定有高有底,那么相似度越高也就越满足这个卷积核的“口味”,这也意味着该样本与该卷积核越匹配。那么,有没有方法能够超越有限的训练样本,生成与特定卷积核最匹配的样本呢?答案是肯定的。一个可行的思路是:随机初始化生成一个样本(指的是对样本的各个数据点随机取值,而不是在数据集中随机选一个样本),然后经过前向传播到该卷积核;我们希望这个随机生成的样本在经过这一层卷积核时响应值能尽可能的大(响应值比较大的样本是这个卷积核比较认可的,是与识别任务更相关的);我们要做的就是不断调整样本各个数据点的值,直到响应值足够大,我们就可以认为此时的样本就是这个卷积核所认可的,从而达到生成卷积核最匹配样本的目的。 - 可视化方法
设计一个损失函数(例如:经过变换后的响应值),使用梯度上升,更新数据点的值,使响应值最大。 - 例子
下图展示的是pytorch中的resnet50中的layer1的最后一次卷积操作中的256个卷积核中的0,10,...,150这16个卷积核的最匹配样本。优化过程中用了两种方法,结果如图:
方法1

方法2,可以明显看出方法2的结果区别性更大

4,类别激活图(Class Activation Map/CAM)
- 概念
特征图可视化、卷积核权重可视化、卷积核最匹配样本这些方法更多是用于分析模型在某一层学习到的东西;但是对于不同的类,我们又如何知道模型是根据哪些信息进行识别的?是否能将这些信息在原始数据上表示出来(比如说热力图)?答案依旧是肯定的。这个方法主要是CAM系列,目前有CAM, Grad-CAM, Grad-CAM++。其中CAM需要特定的结构-GAP,但大部分现有的模型没有这个结构,想要使用该方法便需要修改原模型结构,并重新训练,因此适用范围有限。针对CAM的缺陷,有了之后Grad-CAM的提出。 - 可视化方法
Grad-CAM的最大特点就是不再需要修改现有的模型结构,也不需要重新训练,可以直接在原模型上可视化。Grad-CAM对于想要可视化的类别C,使最后输出的类别C的概率值通过反向传播到最后一层feature maps,得到类别C对该feature maps的每个像素的梯度值;对每个像素的梯度值取全局平均池化,即可得到对feature maps的加权系数alpha;接下来对特征图加权求和,使用ReLU进行修正,再进行上采样。使用ReLU的原因是对于那些负值,可认为与识别类别C无关,这些负值可能是与其他类别有关,而正值才是对识别C有正面影响的。

计算梯度及全局平均池化:
\[\alpha_k^c=\overbrace{\frac{1}{Z}\displaystyle{\sum_i\sum_j}}^{global~average~pooling}\underbrace{\frac{\partial{y^c}}{\partial{A^k_{ij}}}}_{grdients~via~backprop}
\]
加权:
\[L^c_{Grad-CAM}=ReLU\underbrace{\left(\displaystyle\sum_k\alpha^c_kA^k\right)}_{linear~combination}
\]
- 例子
1,由蓝到红,越红代表关注度越高,对于类别分配的结果影响越大,这个例子将图片识别为n02909870 水桶,从关注的区域也可以看出预测是失败的,没有关注到有效的信息

这个预训练模型眼里好像不是水桶就是钩子。。。
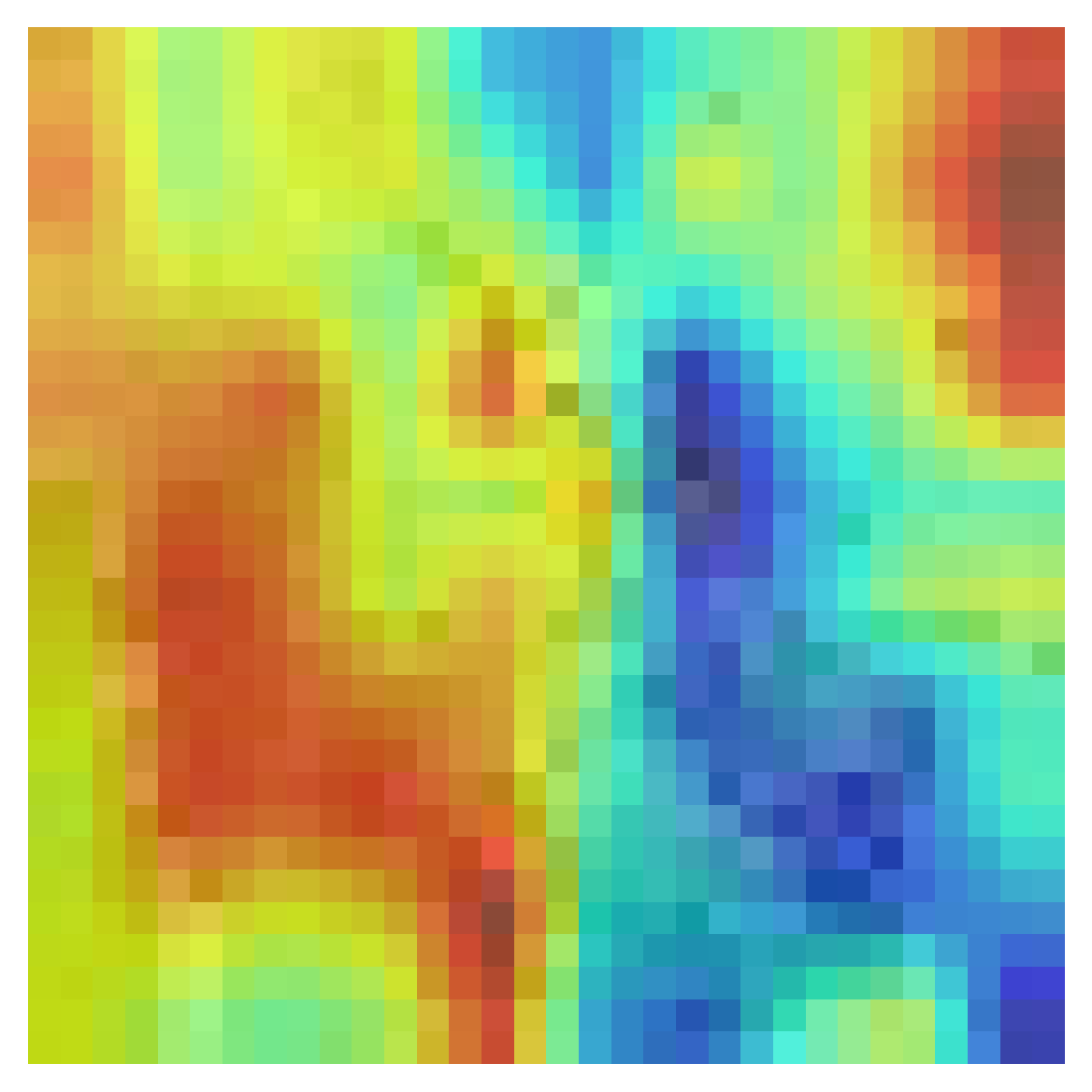
2,从网上找了一个模型,效果就挺好的
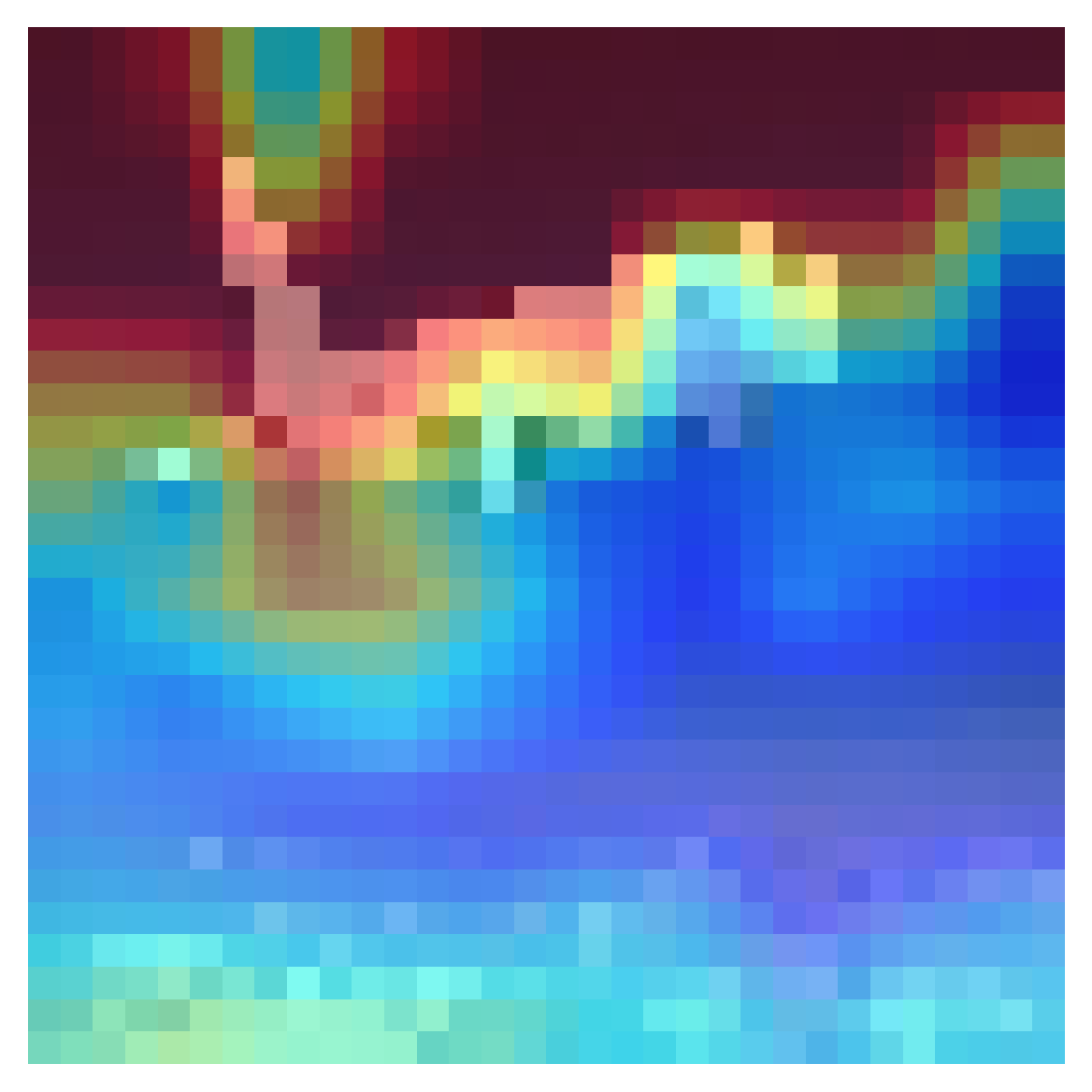











识别青蛙的结果很有意思,这意味着网络关注的重点不在于青蛙,反而在于青蛙周围的环境,而且网络的预测结果还是正确的!



5,网络结构的可视化
- 可视化方法
用tensorboard直接绘制就行,注意两点- 路径不要有中文
- pytorch版本在1.3.0及以上(低版本不显示)
- 例子
from torch.utils.tensorboard import SummaryWriter
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
1,初始化writer
'''
writer = SummaryWriter('runs/resnet50') # 指定写入文件的位置
'''
2,加载模型
'''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(6 * 12 * 12, 120)
self.fc2 = nn.Linear(120, 84)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 6 * 12 * 12)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return x
net = Net()
'''
3,添加网络结构
'''
writer.add_graph(net, torch.randn(1, 1, 28, 28))
writer.close()

行动是治愈恐惧的良药,而犹豫拖延将不断滋养恐惧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号