
pytorch2-gym
1,官网
2,gym简介
Gym是一个用于开发和比较强化学习算法的工具包,是测试问题——环境(environment)的集合。这些环境具有共享接口,允许编写通用算法。
3,gym安装
-
pip安装
pip install gym -
从源码构建(直接克隆gym Git存储库, 如果想要修改 Gym 本身或添加环境时特别有用;这需要安装更多必须的依赖项,包括 cmake 和最新的 pip 版本。)
git clone https://github.com/openai/gym cd gym pip install -e . #当前目录下需包含setup.py文件
4,运行案例及各类环境安装
-
推车杆问题(cart-pole问题)最低限度的例子:运行CartPole-v0 环境的实例 1000 个时间步,在每一步渲染环境。
import gym env = gym.make('CartPole-v0') env.reset() for _ in range(1000): env.render() #环境渲染 env.step(env.action_space.sample()) # take a random action env.close() -
显示所有可用的环境
>>> from gym import envs >>> envs.registry.all() dict_values([EnvSpec(Copy-v0), EnvSpec(RepeatCopy-v0), EnvSpec(ReversedAddition-v0), EnvSpec(ReversedAddition3-v0), EnvSpec(DuplicatedInput-v0), EnvSpec(Reverse-v0), EnvSpec(CartPole-v0), EnvSpec(CartPole-v1), EnvSpec(MountainCar-v0), EnvSpec(MountainCarContinuous-v0), EnvSpec(Pendulum-v0), EnvSpec(Acrobot-v1), EnvSpec(LunarLander-v2), EnvSpec(LunarLanderContinuous-v2), EnvSpec(BipedalWalker-v3), EnvSpec(BipedalWalkerHardcore-v3), EnvSpec(CarRacing-v0), EnvSpec(Blackjack-v0), -
win10环境下安装各类environment
-
Algorithms
- 如果注释掉环境渲染是可以运行的,但是如果渲染总是报错IndexError: list index out of range
-
Atari
-
linux系统
-
windows系统
pip install gym pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
-
-
Box2D
-
在https://www.lfd.uci.edu/~gohlke/pythonlibs/#pybox2d下载相应的whl文件
我这里根据自己的python和操作系统,下载的是Box2D‑2.3.10‑cp36‑cp36m‑win_amd64.whl
-
通过pip安装即可
pip install Box2D-2.3.10-cp36-cp36m-win_amd64.whl
-
-
Classic control
- 此类environment在win10下都可以运行,没有额外必须的依赖
-
MuJoCo
-
Robotics
-
Toy text
- 此类environment在win10下都可以运行,没有额外必须的依赖
-
-
环境分类
- Classic control 以及 toy text:小规模入门级任务,主要来自 RL 文献。
- Algorithms:执行计算,例如添加多位数字和反转序列。挑战在于纯粹从示例中学习这些算法。这些任务有一个很好的特性,即通过改变序列长度很容易改变难度。
- Atari:经典的 Atari 游戏。
- 2D 和 3D 机器人:在模拟中控制机器人。这些任务使用 MuJoCo 物理引擎,该引擎专为快速准确的机器人模拟而设计。 MuJoCo 是专有软件,但提供免费试用许可证。
-
自定义gym环境
将自己的环境添加到注册表中非常容易,只需在加载时 register() 即可,从而使该环境可用于gym.make()。
5,细节
-
env.step():将动作作用于环境。返回四个值,分别是:
- observation/观测(object):一个特定于环境的对象,代表对环境的观察。例如,来自相机的像素数据、机器人的关节角度和关节速度,或棋盘游戏中的棋盘状态。
- reward/奖励(float):前一个动作获得的奖励量。 量纲因环境而异,但目标始终是增加总奖励。
- done(boolean):是否是时候再次重置环境了。 大多数(但不是全部)任务已被划分为明确定义的episodes,done为True意味着所有的episodes已经终止。 (例如,也许杆子倾斜得太远,或者在游戏中已经丢了一条命。)
- info/信息(dict):对调试有用的诊断信息。有时对学习很有用(例如,它可能包含环境最后状态变化背后的原始概率);但是,在官方评估算法性能时不允许将此用于学习(相当于作弊)。
-
agent-environment loop/智能体-环境循环:每个时间步,agent选择一个action,environment返回一个observation以及reward;这一过程通过调用reset()方法开始,这会返回一个初始的观测值。
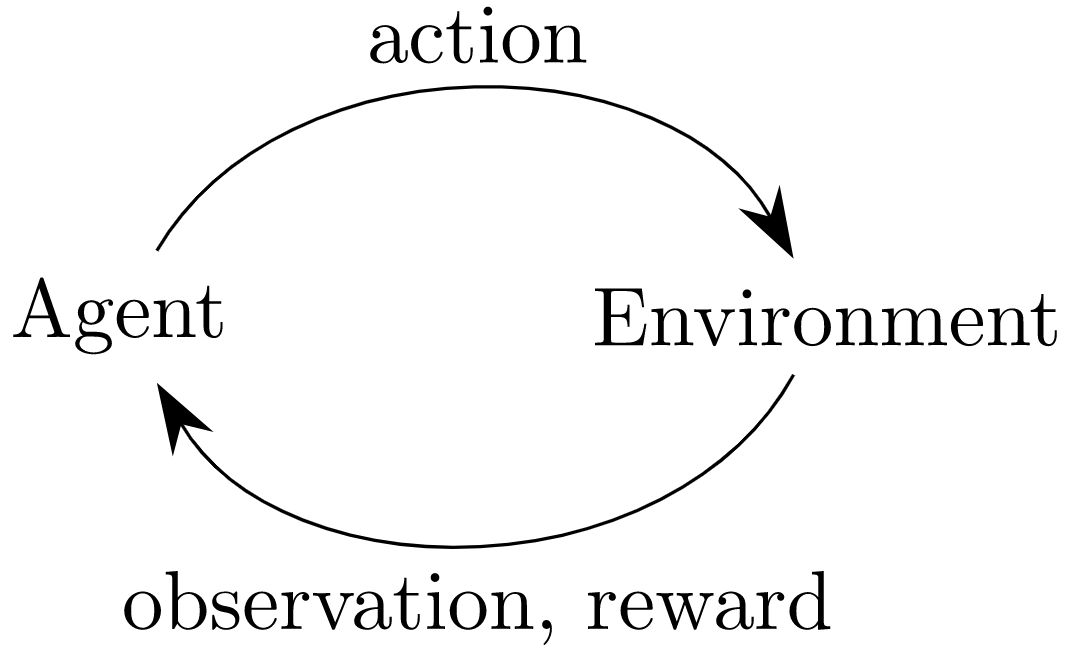
'''例2''' import gym with gym.make('CartPole-v0') as env: #环境实例化make for i_episodes in range(20): observation = env.reset() #环境初始化并获取初始化观测值reset for t in range(100): env.render() #环境渲染render print(observation) action = env.action_space.sample() #在动作集合中随机选取动作action_space.sample observation, reward, done, info = env.step(action) #将动作作用于环境step if done: print(f"\033[3{i_episodes%10}mEpisode finished after {t+1} timesteps.\033[0m") break #每个episode并不一定跑满时间步,因为往往在这之前就已经达到终止条件了(在杆车系统中,随机选取动作跑不满100个时间步,往往20个左右就已经可以判定为结束了,此时直接break,环境初始化进入下一个episode) -
action_space/动作空间 以及 observation_space/观测空间:每个环境都带有一个 action_space 和一个observation_space, 这些值都属于 Space 类型,它们描述了有效操作和观察的格式:
>>> import gym >>> env = gym.make('CartPole-v0') >>> env.action_space Discrete(2) >>> env.observation_space Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32) >>> env.observation_space.high array([4.8000002e+00, 3.4028235e+38, 4.1887903e-01, 3.4028235e+38], dtype=float32) >>> env.observation_space.low array([-4.8000002e+00, -3.4028235e+38, -4.1887903e-01, -3.4028235e+38], dtype=float32)- Discrete表示允许固定范围的非负数。在上面的例子中,有效动作是 0 或 1,其中一个动作向左侧施加力,其中一个动作向右侧施加力。
- Box表示由 n 维数组组成。在上面的例子中,有效观察值将是一个包含 4 个数字的数组,分别是:小车位置、小车速度、棍的倾斜角度、棍的角速度;游戏中如果角度大于12度,或者小车位置超过2.4就意味着失败,直接结束。
Box和Discrete是最常见的空间类型,可以从 Space 中采样或检查某些值是否属于特定的空间:
>>> from gym import spaces >>> space = spaces.Discrete(8) >>> x = space.sample() >>> assert space.contains(x) >>> assert space.n == 8
附录
1,OpenAI Gym 白皮书
- 严格的版本控制:如果环境发生了变化,变化前后的结果将是不可比拟的。 为避免此问题,gym保证对环境的任何更改都将伴随版本号的增加 。例如 CartPole 任务的初始版本命名为 Cartpole-v0,如果其功能发生变化,名称将更新为 Cartpole-v1。
- 默认监控: 默认情况下,环境使用监视器进行检测,该监视器跟踪调用的每个时间步(模拟的一步)和重置(对新的初始状态进行采样)。 监视器的行为是可配置的,它可以定期录制视频, 也可以产生学习曲线。
2,Gym Documents
3,Gym website / 排行榜
4,杆车的位置策略控制和角策略控制
'''位置策略'''
import gym
def action(status):
pos, v, ang, va = status
print(status)
if pos <= 0:
return 1
else:
return 0
env = gym.make('CartPole-v0')
status = env.reset()
for step in range(1000):
i = 0
env.render()
status, reward, done, info = env.step(action(status))
if done:
print('dead in %d steps' % step)
break
env.close()
'''角策略'''
import gym
def action_a(status):
pos, v, ang, va = status
print(status)
if ang > 0:
return 1
else:
return 0
env = gym.make('CartPole-v0')
status = env.reset()
for step in range(1000):
i = 0
env.render()
status, reward, done, info = env.step(action_a(status))
if done:
print('dead in %d steps' % step)
break
env.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号