常见综合评价算法
9.1 综合评价的基本理论和数据预处
9.1.1 综合评价的基本概念

1 评价对象

2 评价指标

3 权重系数


4 综合评价模型

5 评价者

9.1.2 综合评价体系的构建

1 评价指标和评价体系


2 评价指标的筛选方法

1)专家调研法(Delphi法)

2)最小均方差法


3)极大极小离差法

9.1.3 评价指标的预处理方法

1 指标的一致化标准




2 指标的无量纲化处理

1)标准样本变化法

2)比例变换法

3)向量归一化方法
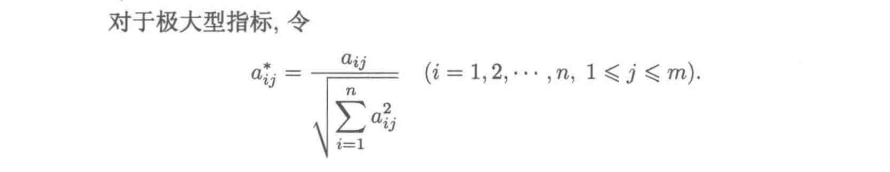
4)极差变换法

5)功效系数法

ps: 这种方法和土力学中的液限指数有点像
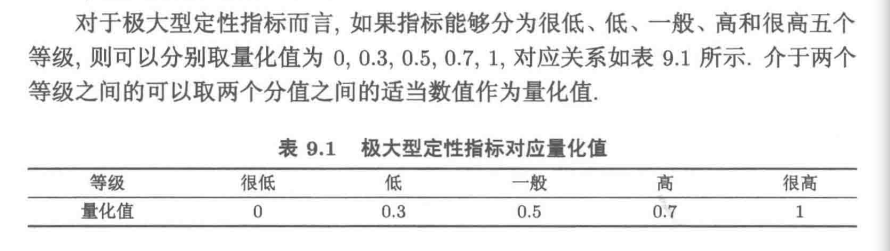
3 定性指标定量化

1)极大型定型指标量化的标准
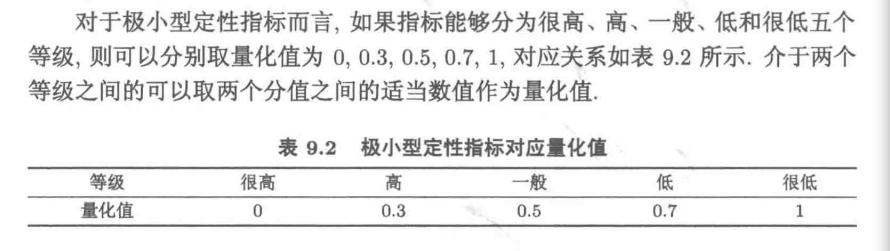
2)极小型指标量化标准
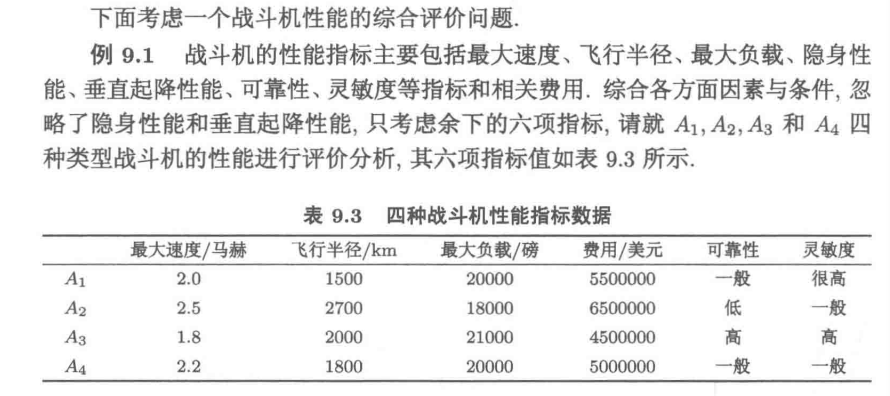
9.1.4 综合评价指标预处理的示例——战斗机的评价

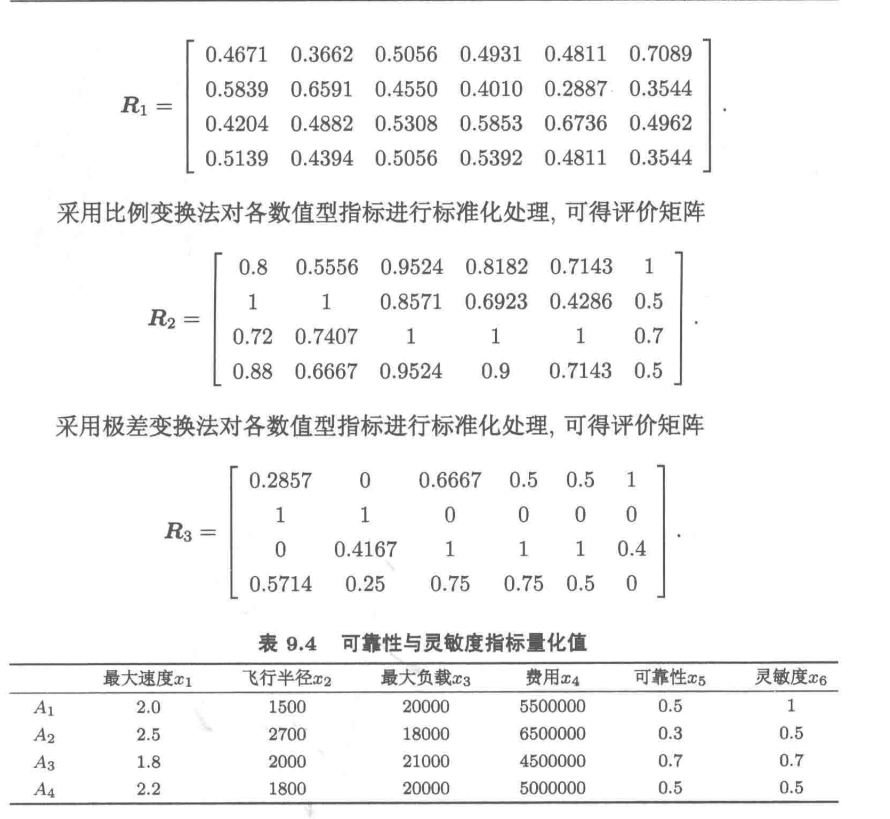
#程序文件Pex9_1.py
# python的复制是按照地址传递的,这一点要格外注意
import numpy as np
import pandas as pd
a=np.loadtxt("data/Pdata9_1_1.txt",)
R1=a.copy(); R2=a.copy(); R3=a.copy() #初始化
#注意R1=a,它们的内存地址一样,R1改变时,a也改变
# ------------------------算法部分:begin-------------------
for j in [0,1,2,4,5]:
R1[:,j]=R1[:,j]/np.linalg.norm(R1[:,j]) #向量归一化
R2[:,j]=R1[:,j]/max(R1[:,j]) #比例变换
R3[:,j]=(R3[:,j]-min(R3[:,j]))/(max(R3[:,j])-min(R3[:,j]));
R1[:,3]=1-R1[:,3]/np.linalg.norm(R1[:,3])
R2[:,3]=min(R2[:,3])/R2[:,3]
R3[:,3]=(max(R3[:,3])-R3[:,3])/(max(R3[:,3])-min(R3[:,3]))
# ------------------------算法部分:end---------------------
# ------------------------文件保存:begin-------------------
np.savetxt("Pdata9_1_2.txt", R1); #把数据写入文本文件,供下面使用
np.savetxt("Pdata9_1_3.txt", R2); np.savetxt("Pdata9_1_4.txt", R3)
DR1=pd.DataFrame(R1) #生成DataFrame类型数据
DR2=pd.DataFrame(R2); DR3=pd.DataFrame(R3)
f=pd.ExcelWriter('Pdata9_1_5.xlsx') #创建文件对象
DR1.to_excel(f,"sheet1") #把DR1写入Excel文件1号表单中,方便做表
DR2.to_excel(f,"sheet2"); DR3.to_excel(f, "Sheet3"); f.save()
# ------------------------文件保存:end-------------------
9.2 常用的综合评价数学模型

9.2.1 线性加权综合评价模型

9.2.2 TOPSIS法

9.2.3 灰色关联度分析

9.2.4 熵值法

9.2.5 秩和比法


9.2.6 综合评价示例
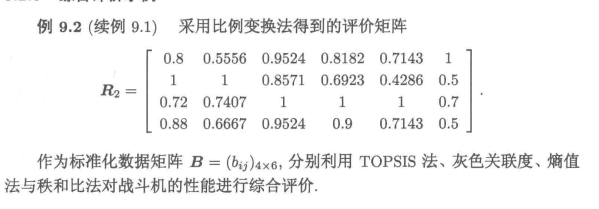
1 利用TOPSIS进行综合评价分析

2 灰色关联度法评价

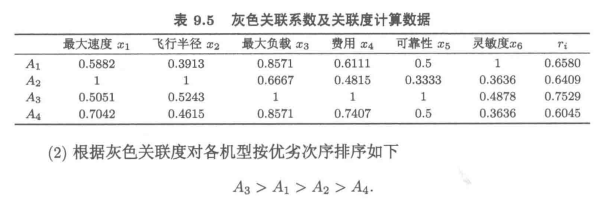
3 熵值法


4 利用秩和比发尽心那个综合评价
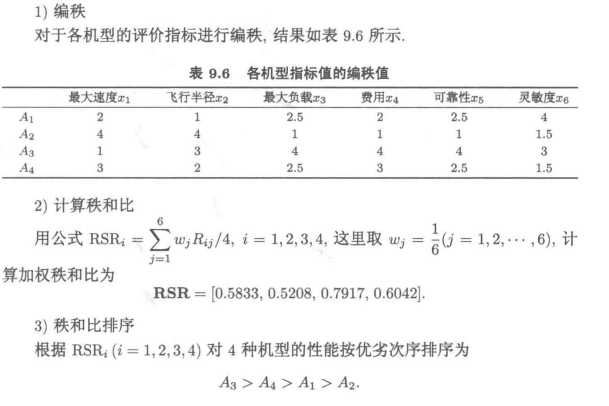
#程序文件Pex9_2.py
import numpy as np
from scipy.stats import rankdata
a=np.loadtxt("data/Pdata9_1_3.txt")
cplus=a.max(axis=0) #逐列求最大值
cminus=a.min(axis=0) #逐列求最小值
print("正理想解=",cplus,"负理想解=",cminus)
d1=np.linalg.norm(a-cplus, axis=1) #求到正理想解的距离
d2=np.linalg.norm(a-cminus, axis=1) #求到负理想解的距离
print(d1, d2) #显示到正理想解和负理想解的距离
f1=d2/(d1+d2); print("TOPSIS的评价值为:", f1)
t=cplus-a #计算参考序列与每个序列的差
mmin=t.min(); mmax=t.max() #计算最小差和最大差
rho=0.5 #分辨系数
xs=(mmin+rho*mmax)/(t+rho*mmax) #计算灰色关联系数
f2=xs.mean(axis=1) #求每一行的均值
print("\n关联系数=", xs,'\n关联度=',f2) #显示灰色关联系数和灰色关联度
[n, m]=a.shape
cs=a.sum(axis=0) #逐列求和
P=1/cs*a #求特征比重矩阵
e=-(P*np.log(P)).sum(axis=0)/np.log(n) #计算熵值
g=1-e #计算差异系数
w = g / sum(g) #计算权重
F = P @ w #计算各对象的评价值,矩阵乘法
print("\nP={}\n,e={}\n,g={}\n,w={}\nF={}".format(P,e,g,w,F))
R=[rankdata(a[:,i]) for i in np.arange(6)] #求每一列的秩
R=np.array(R).T #构造秩矩阵
print("\n秩矩阵为:\n",R)
RSR=R.mean(axis=1)/n; print("RSR=", RSR)
9.3 层次分析法案例
9.3.1 问题提出

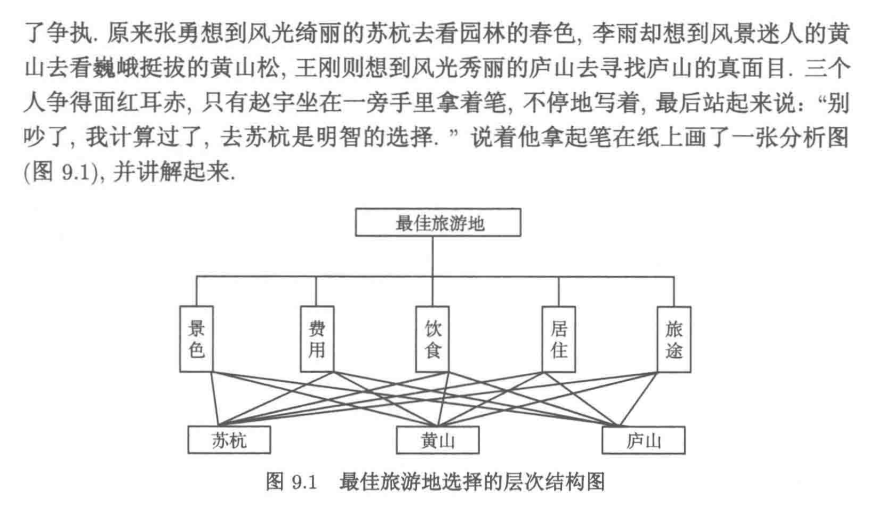
9.3.2 问题分析

9.3.3 模型的建立与求解
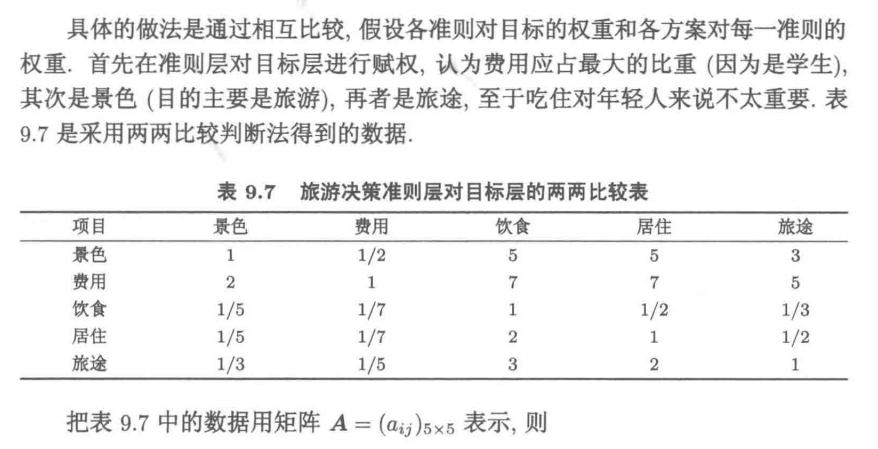


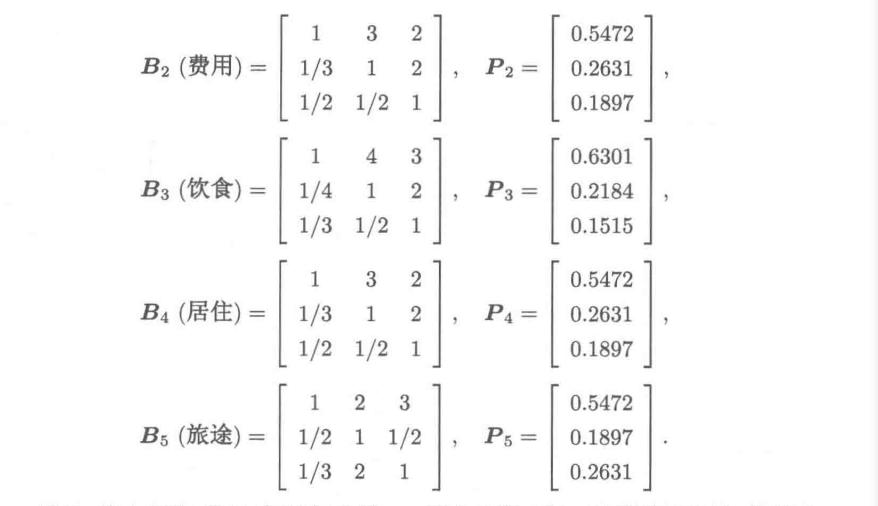
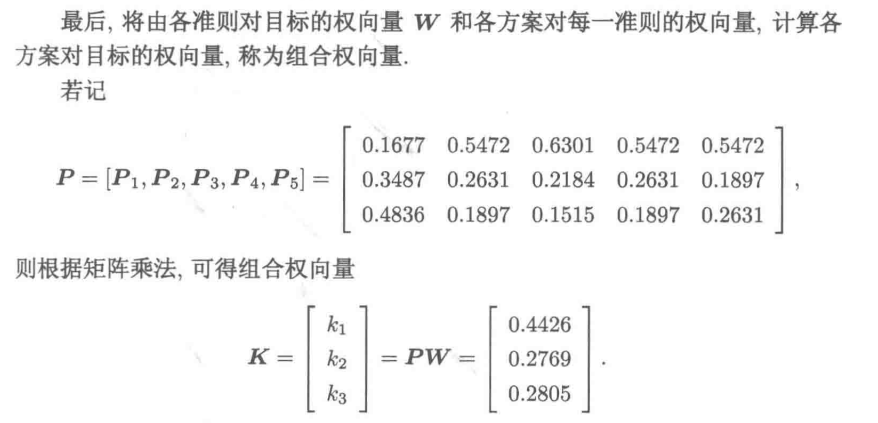
9.3.4 模型的一致性检验


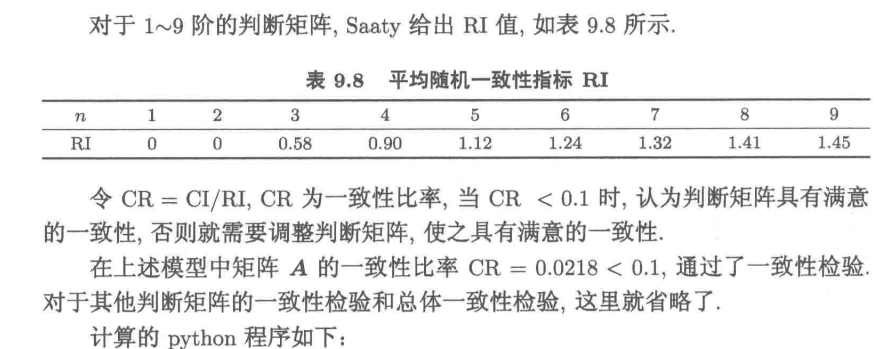
#程序文件Pan9_1.py
from scipy.sparse.linalg import eigs
from numpy import array, hstack
a=array([[1,1/2,5,5,3],[2,1,7,7,5],[1/5,1/7,1,1/2,1/3],
[1/5,1/7,2,1,1/2],[1/3,1/5,3,2,1]])
L,V=eigs(a,1);
CR=(L-5)/4/1.12 #计算矩阵A的一致性比率
W=V/sum(V); print("最大特征值为:",L)
print("最大特征值对应的特征向量W=\n",W)
print("CR=",CR)
B1=array([[1,1/3,1/2],[3,1,1/2],[2,2,1]])
L1,P1=eigs(B1,1); P1=P1/sum(P1)
print("P1=",P1)
B2=array([[1,3,2],[1/3,1,2],[1/2,1/2,1]])
t2,P2=eigs(B2,1); P2=P2/sum(P2)
print("P2=",P2)
B3=array([[1,4,3],[1/4,1,2],[1/3,1/2,1]])
t3, P3=eigs(B3,1); P3=P3/sum(P3)
print("P3=",P3)
B4=array([[1,3,2],[1/3,1,2],[1/2,1/2,1]])
t4, P4=eigs(B4,1); P4=P4/sum(P4)
print("P4=", P4)
B5=array([[1,2,3],[1/2,1,1/2],[1/3,2,1]])
t5, P5=eigs(B5,1); P5=P5/sum(P5)
print("P5=",P5)
K=hstack([P1,P2,P3,P4,P5])@W #矩阵乘法
print("K=",K)
9.3.5 结果分析

from scipy.sparse.linalg import eigs
from numpy import array,hstack
a = array([[1,1/2,5,5,3],[2,1,7,7,5],[1/5,1/7,1,1/2,1/3],[1/5,1/7,2,1,1/2],[1/3,1/5# L应该是最大特征值,V应该是特征向量
L,V=eigs(a,1)
L,3,2,1]])
CR = (L-5)/4/1.2
CR
W = V/sum(V)
习题9
data/xt9_1.txt
8.1 255 12.6 13.2 76 5.4
6.7 210 13.2 10.7 102 7.2
6.0 233 15.3 9.5 63 3.1
4.5 202 15.2 13 120 2.6
"""
TOPSIS
"""
import numpy as np
a = np.loadtxt("data/xt9_1.txt")
c_plus = [];c_minus = []
si_plus = [];si_minus = []
F = []
# 比例变换法
for i in range(np.size(a,axis = 1)):
a[:,i] = a[:,i]/max(a[:,i])
c_plus.append(max(a[:,i]))
c_minus.append(min(a[:,i]))
# 计算正理想解与负理想解的距离
for i in range(np.size(a,axis = 0)):
si_plus_tmp = 0
si_minus_tmp = 0
for j in range(np.size(a,axis = 1)):
si_plus_tmp += (a[i][j] - c_plus[j])**2
si_minus_tmp += (a[i][j] - c_minus[j])**2
si_plus.append(np.sqrt(si_plus_tmp))
si_minus.append(np.sqrt(si_minus_tmp))
# 计算距离
for i in range(np.size(a,axis = 0)):
f = si_minus[i]/(si_minus[i] + si_plus[i])
F.append(f)
F = np.array(F)
print(F.argsort())
"""
灰色关联度分析
一个不错的网站:https://blog.csdn.net/edogawachia/article/details/85330067#t8
"""
import numpy as np
import copy as cp
a = np.loadtxt("data/xt9_1.txt")
# 数据归一化,进行标准化
for i in range(np.size(a,axis = 1)):
a_mean = np.average(a[:,i])
a[:,i] = (a[:,i] - a_mean)/np.var(a[:,i])
# 进行拷贝与转置
b = cp.copy(np.transpose(a))
# 灰色关联度法
zeta = []
zeta_mean = []
rho = 0.5
# 计算两个关键参数,进行矩阵化操作
# 矩阵拼接,矩阵阵列也可以
tmp1 = np.r_[[b[0,:]],[b[0,:]],[b[0,:]]]
tmp2 = np.r_[[b[1,:]],[b[2,:]],[b[3,:]]]
global_min = np.min(np.abs(tmp1 - tmp2))
global_max = np.max(np.abs(tmp1 - tmp2))
for i in range(np.size(tmp1,axis=1)):
zeta.append((global_min + rho * global_max)/(abs(b[0,:] - b[i,:]) + rho * global_max)) # 利用numpy的广播机制
zeta_mean.append(np.mean(zeta[i]))
b = np.argsort(zeta_mean)
print(b)
# 灰色关联度法的matlab程序
% Grey relation analysis
clear all
close all
clc
zongshouru = [3439, 4002, 4519, 4995, 5566];
daxuesheng = [341, 409, 556, 719, 903];
congyerenyuan = [183, 196, 564, 598, 613];
xingjifandian = [3248, 3856, 6029, 7358, 8880];
% define comparative and reference
x0 = zongshouru;
x1 = daxuesheng;
x2 = congyerenyuan;
x3 = xingjifandian;
% normalization
x0 = x0 ./ x0(1);
x1 = x1 ./ x1(1);
x2 = x2 ./ x2(1);
x3 = x3 ./ x3(1);
% global min and max
global_min = min(min(abs([x1; x2; x3] - repmat(x0, [3, 1]))));
global_max = max(max(abs([x1; x2; x3] - repmat(x0, [3, 1]))));
% set rho
rho = 0.5;
% calculate zeta relation coefficients
zeta_1 = (global_min + rho * global_max) ./ (abs(x0 - x1) + rho * global_max);
zeta_2 = (global_min + rho * global_max) ./ (abs(x0 - x2) + rho * global_max);
zeta_3 = (global_min + rho * global_max) ./ (abs(x0 - x3) + rho * global_max);
% show
figure;
plot(x0, 'ko-' )
hold on
plot(x1, 'b*-')
hold on
plot(x2, 'g*-')
hold on
plot(x3, 'r*-')
legend('zongshouru', 'daxuesheng', 'congyerenyuan', 'xingjifandian')
figure;
plot(zeta_1, 'b*-')
hold on
plot(zeta_2, 'g*-')
hold on
plot(zeta_3, 'r*-')
title('Relation zeta')
legend('daxuesheng', 'congyerenyuan', 'xingjifandian')
import numpy as np
import copy as cp
a = np.loadtxt("data/xt9_1.txt")
# 数据标准化:向量归一化
col = np.size(a,axis=1)
row = np.size(a,axis=0)
for i in range(col):
a[:,i] = a[:,i]/np.linalg.norm(a[:,i])
# 利用熵值法进行判别
# 计算在第j项指标下第i个评价对象的特征比重
p = np.zeros([row, col])
# 计算第j项评价指标下第i个评价对象的特征比重
for j in range(col):
p[:,j] = a[:,j]/np.sum(a[:,j])
# 计算第j项指标的差异系数
e = np.zeros([1,col])
for j in range(col):
sum = 0
for i in range(row):
sum += p[i][j] * np.log(p[i][j])
e[0][j] = -np.log(row) * sum
# 计算差异系数
g = np.zeros([1,col])
g = 1 - e
# 计算权重系数
w = np.zeros([1,col])
w = g/np.sum(g)
# 计算综合评价指标
f = np.zeros([1,row])
for i in range(row):
for j in range(col):
f[0][i] += w[0][j] * p[i][j]
print(f.argsort())
posted on 2022-08-08 13:27 TensorBoyRuanPh 阅读(849) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号