HBase集成MapReduce
集成分析
- HBase表中的数据最终都是存储在HDFS上,HBase天生的支持MR的操作,我们可以通过MR直接处理HBase表中的数据,
并且MR可以将处理后的结果直接存储到HBase表中。 - 参考地址:http://hbase.apache.org/book.html#mapreduce
1 实现方式一
- 读取HBase当中某张表的数据,将数据写入到另外一张表的列族里面去
2 实现方式二
- 读取HDFS上面的数据,写入到HBase表里面去
3 实现方式三
-
通过bulkload的方式批量加载数据到HBase表中
-
加载数据到HBase当中去的方式多种多样,我们可以使用HBase的javaAPI或者使用sqoop将我们的数据写入或者导入到HBase当中去,
但是这些方式不是最佳的,因为在导入的过程中占用Region资源导致效率低下- HBase数据正常写流程回顾
![]()
- HBase数据正常写流程回顾
-
通过MR的程序,将我们的数据直接转换成HBase的最终存储格式HFile,然后直接load数据到HBase当中去即可
- bulkload方式的处理示意图
![]()
- bulkload方式的处理示意图
-
使用bulkload的方式批量加载数据的好处
- 导入过程不占用Region资源
- 能快速导入海量的数据
- 节省内存

实现方式一
- 读取HBase当中person这张表的info1:name、info2:age数据,将数据写入到另外一张person1表的info1列族里面去
- 第一步:创建person1这张hbase表
注意:列族的名字要与person表的列族名字相同
create 'person1','info1'
- 第二步:创建maven工程并导入jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>tenic</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>HbaseMrDdemo</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*/RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 第三步:开发MR程序实现功能
- 自定义map类
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class HBaseReadMapper extends TableMapper<Text, Put> {
/**
* @param key rowKey
* @param value rowKey此行的数据 Result类型
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
// 获得rowKey的字节数组
byte[] rowKeyBytes = key.get();
String rowKeyStr = Bytes.toString(rowKeyBytes);
Text text = new Text(rowKeyStr);
Put put = new Put(rowKeyBytes);
// 获取一行中所有的Cell对象
Cell[] cells = value.rawCells();
for (Cell cell : cells) {
//列族
byte[] familyBytes = CellUtil.cloneFamily(cell);
String familyStr = Bytes.toString(familyBytes);
//当前cell是否是info1
if ("info1".equals(familyStr)) {
//在判断是否是name | age
byte[] qualifier_bytes = CellUtil.cloneQualifier(cell);
String qualifierStr = Bytes.toString(qualifier_bytes);
if ("name".equals(qualifierStr) || "age".equals(qualifierStr)) {
put.add(cell);
}
}
}
// 判断是否为空;不为空,才输出
if (!put.isEmpty()) {
context.write(text, put);
}
}
}
- 自定义reduce类
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* TableReducer第三个泛型包含rowkey信息
*/
public class HBaseWriteReducer extends TableReducer<Text, Put, ImmutableBytesWritable> {
//将map传输过来的数据,写入到hbase表
@Override
protected void reduce(Text key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//key 就是上边mapper阶段输出的rowkey
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable();
immutableBytesWritable.set(key.toString().getBytes());
//遍历put对象,并输出
for(Put put: values) {
context.write(immutableBytesWritable, put);
}
}
}
- main入口类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Main extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
// 设定绑定的zk集群
configuration.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
int run = ToolRunner.run(configuration, new Main(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf());
job.setJarByClass(Main.class);
// mapper
TableMapReduceUtil.initTableMapperJob(TableName.valueOf("person"), new Scan(), HBaseReadMapper.class, Text.class, Put.class, job);
// reducer
TableMapReduceUtil.initTable ReducerJob("person1", HBaseWriteReducer.class, job);
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
}

实现方式二
- 读取hdfs上面的数据,写入到hbase表里面去
hadoop03执行以下命令准备数据文件,并将数据文件上传到HDFS上面去
在/bigdata/install/documents/目录,创建user.txt文件
cd /bigdata/install/documents/
vi user.txt
内容如下:
rk0003 honghong 18
rk0004 lilei 25
rk0005 kangkang 22
将文件上传到hdfs的路径下面去
hdfs dfs -mkdir -p /hbase/input
hdfs dfs -put /bigdata/install/documents/user.txt /hbase/input/
- 代码开发
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import java.io.IOException;
/**
* 将HDFS上文件/hbase/input/user.txt数据,导入到HBase的person1表
*/
public class HDFS2HBase {
public static class HDFSMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// 数据原样输出
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
public static class HBaseReducer extends TableReducer<Text, NullWritable, ImmutableBytesWritable> {
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
/**
* key -> 一行数据
* 样例数据:
*rk0003 honghong 18
*rk0004 lilei 25
*rk0005 kangkang 22
*/
String[] split = key.toString().split("\t");
// split[0] 对应的是rowkey
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn("info1".getBytes(), "name".getBytes(), split[1].getBytes());
put.addColumn("info1".getBytes(), "age".getBytes(), split[2].getBytes());
context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])), put);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
// 设定zk集群
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
Job job = Job.getInstance(conf);
job.setJarByClass(HDFS2HBase.class);
job.setMapperClass(HDFSMapper.class);
job.setInputFormatClass(TextInputFormat.class);
// map端的输出的key value 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 设置reduce个数
job.setNumReduceTasks(1);
// 输入文件路径
TextInputFormat.addInputPath(job, new Path("hdfs://hadoop01:8020/hbase/input/user.txt"));
// 指定输出到hbase的表名
TableMapReduceUtil.initTableReducerJob("person1", HBaseReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

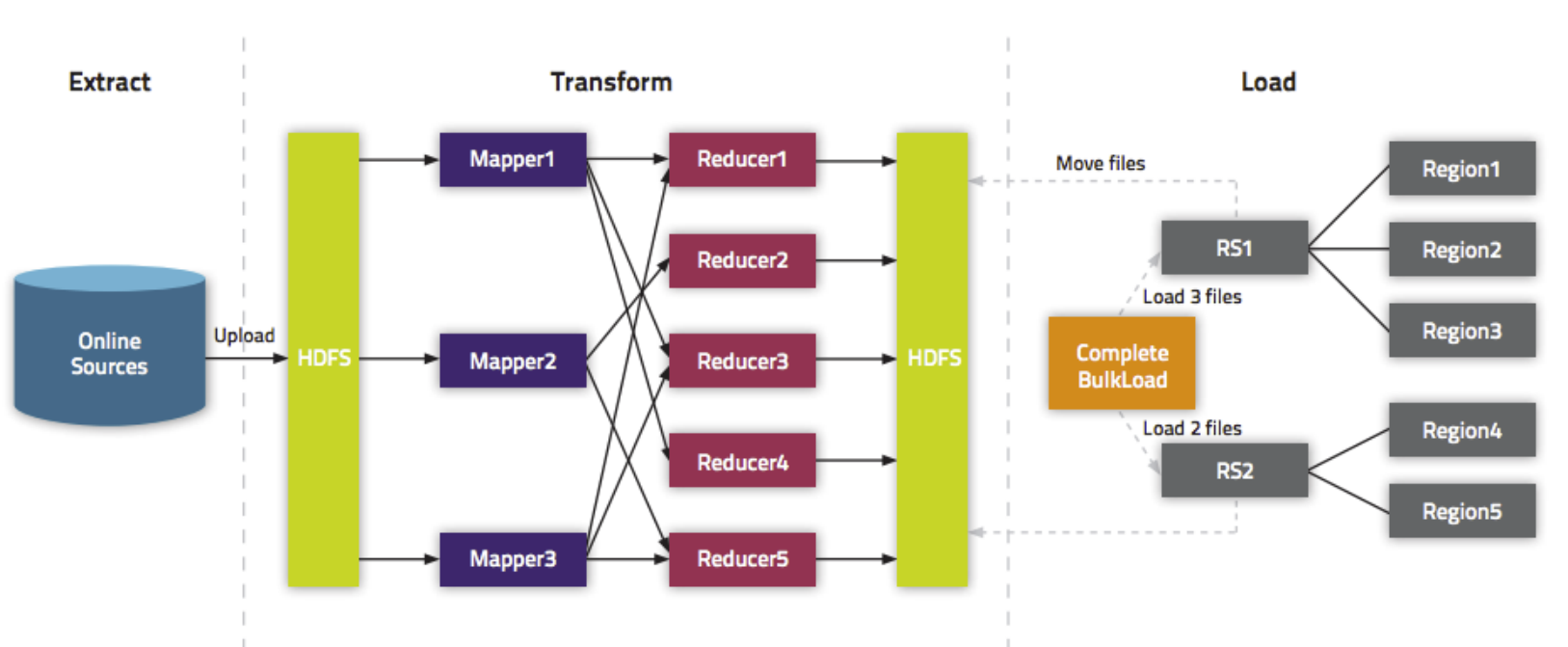
实现方式三
- HDFS上面的这个路径/hbase/input/user.txt的数据文件,转换成HFile格式,然后load到person1这张表里面去
- 1、开发生成HFile文件的代码
- 自定义map类
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// 四个泛型中后两个,分别对应rowkey及put
public class BulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
// 封装输出的rowkey类型
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(split[0].getBytes());
// 构建put对象
Put put = new Put(split[0].getBytes());
put.addColumn("info1".getBytes(), "name".getBytes(), split[1].getBytes());
put.addColumn("info1".getBytes(), "age".getBytes(), split[2].getBytes());
context.write(immutableBytesWritable, put);
}
}
- 程序main
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseBulkLoad extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
//设定zk集群
configuration.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
int run = ToolRunner.run(configuration, new HBaseBulkLoad(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(HBaseBulkLoad.class);
TextInputFormat.addInputPath(job, new Path("hdfs://hadoop01:8020/hbase/input/user.txt"));
job.setMapperClass(BulkLoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf("person1"));
//使MR可以向myuser2表中,增量增加数据
HFileOutputFormat2.configureIncrementalLoad(job, table, connection.getRegionLocator(TableName.valueOf("person1")));
//数据写回到HDFS,写成HFile -> 所以指定输出格式为HFileOutputFormat2
job.setOutputFormatClass(HFileOutputFormat2.class);
HFileOutputFormat2.setOutputPath(job, new Path("hdfs://hadoop01:8020/hbase/out_hfile"));
//开始执行
boolean b = job.waitForCompletion(true);
return b? 0: 1;
}
}
-
3、观察HDFS上输出的结果
![]()
-
4、加载HFile文件到hbase表中
- 方式一:代码加载
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.tool.BulkLoadHFiles; public class LoadData { public static void main(String[] args) throws Exception { Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03"); // 获取数据库连接 Connection connection = ConnectionFactory.createConnection(configuration); // 获取表的管理器对象 Admin admin = connection.getAdmin(); // 获取table对象 TableName tableName = TableName.valueOf("person1"); Table table = connection.getTable(tableName); // 构建BulkLoadHFiles加载HFile文件 hbase2.0 api BulkLoadHFiles load = BulkLoadHFiles.create(configuration); load.bulkLoad(tableName, new Path("hdfs://hadoop01:8020/hbase/out_hfile")); }



 浙公网安备 33010602011771号
浙公网安备 33010602011771号