Hive概述
前边已经搭建好了hive,也通过cli登录上了hive,那我们来简单说一下hive
Hive概念
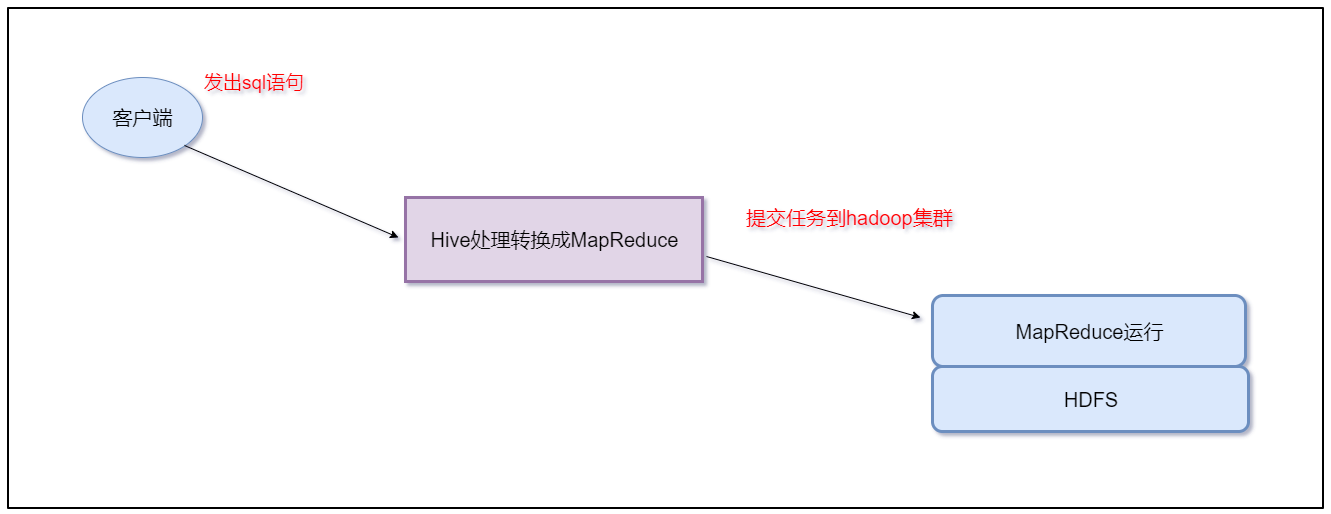
Hive是基于Hadoop的一个数据仓库工具
- 可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
- 其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储支持,也可以说hive就是一个MapReduce的客户端
![]()
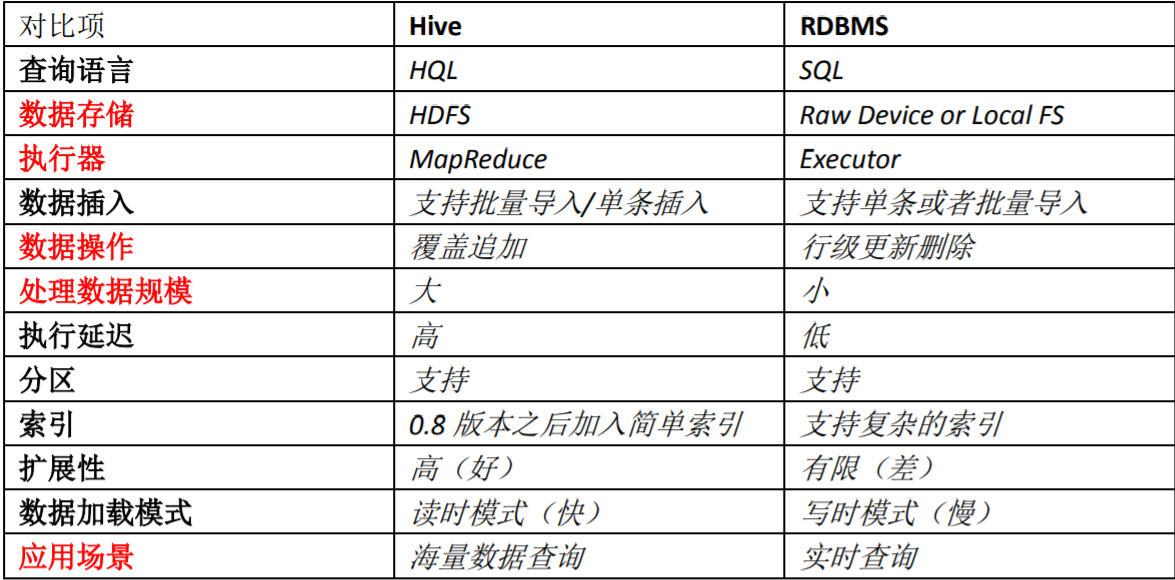
Hive与数据库的区别
Hive的优缺点
- 优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。避免了去写MapReduce,减少开发人员的学习成本。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 缺点
- Hive将SQL转换为MapReduce任务,Hive 的查询延迟很严重
- Hive 不支持事务
Hive原理
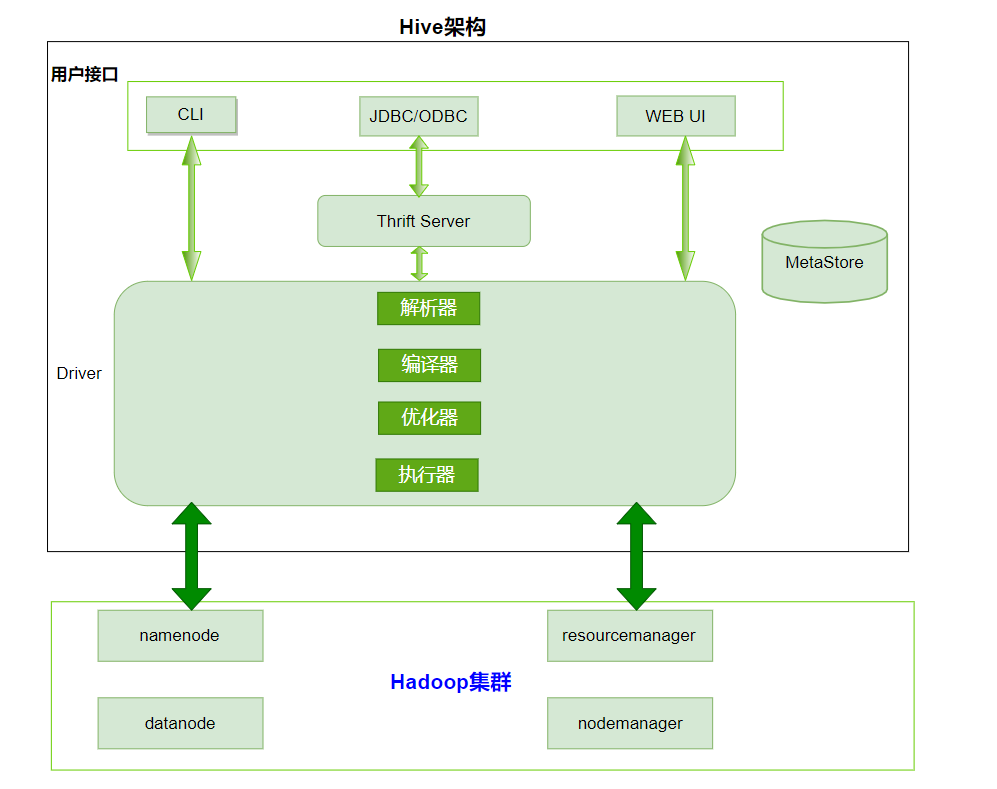
- 用户接口:Client
- CLI(hive shell)
- JDBC/ODBC(java访问hive)
- WEBUI(浏览器访问hive)
- 元数据:Metastore
- 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
- 默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- Hadoop集群
- 使用HDFS进行存储,使用MapReduce进行计算。
- Driver:驱动器
- 解析器(SQL Parser) :将SQL字符串转换成抽象语法树AST,对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
- 编译器(Physical Plan):将AST编译生成逻辑执行计划
- 优化器(Query Optimizer):对逻辑执行计划进行优化
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。
- 对于Hive来说默认就是mapreduce任务
![]()
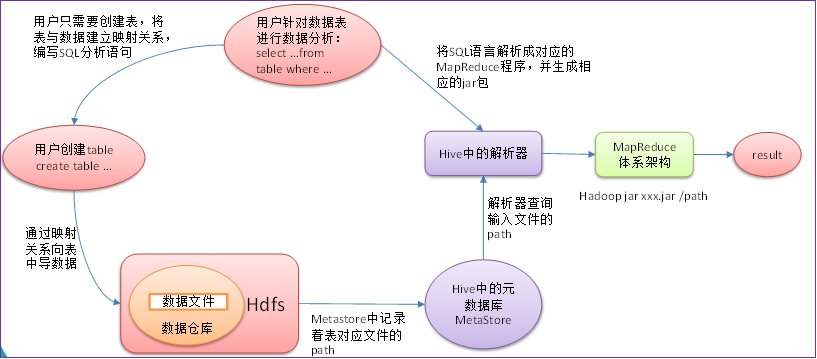
Hive的交互方式
使用Hive前需要的准备工作
- 启动hadoop集群:因为hql语句会被编译成MR任务提交到集群运行;hive表数据一般存储在HDFS上
- mysql服务:因为对hive操作过程中,需要访问mysql中存储元数据的库及表
- Hive交互shell
- 在任意路径运行hive
- Hive JDBC服务,beeline方式
- 启动hiveserver2服务,前台启动与后台启动方式二选一
hive --service hiveserver2 #前台启动hiveserver2,进行beeline登录时需要克隆一个新的窗口 或 nohup hive --service hiveserver2 & #后台启动hiveserver2- beeline连接hiveserver2服务
beeline --color=true #启动beeline beeline> !connect jdbc:hive2://hadoop02:10000 #使用JDBC登录Hive - Hive的命令
- hive -e hql语句,使用 –e 参数来直接执行hql语句
hive -e "show databases"- hive -f sql文件,使用 –f参数执行包含hql语句的文件
cd /bigdata/install/hive-3.1.4/ vi hive.sql #在hive.sql中输入以下HQL语句,保存退出 create database if not exists myhive; #执行脚本 hive -f /bigdata/install/hive-3.1.4/hive.sql
Hive的数据类型
- 基本数据类型
类型名称 描述 举例 boolean true/false true tinyint 1字节的有符号整数 1 smallint 2字节的有符号整数 1 int 4字节的有符号整数 1 bigint 8字节的有符号整数 1 float 4字节单精度浮点数 1.0 double 8字节单精度浮点数 1.0 string 字符串(不设长度) “abc” varchar 字符串(1-65355长度,超长截断) “abc” timestamp 时间戳 1563157873 date 日期 20190715 - 复合数据类型
类型名称 描述 举例 array 一组有序的字段,字段类型必须相同 array(元素1,元素2) Array(1,2,3) map 一组无序的键值对 map(k1,v1,k2,v2) Map(‘a’,1,'b',2) struct 一组命名的字段,字段类型可以不同 struct(元素1,元素2) Struct('a',1,2,0) - array类型的字段的元素访问方式
- 通过下标获取元素,下标从0开始,eg:如获取第一个元素 array[0]
- map类型字段的元素访问方式
- 通过键获取值,eg: 如获取a这个key对应的value map['a']
- struct类型字段的元素获取方式
- 定义一个字段c的类型为struct
- 获取a和b的值,使用c.a 和c.b 获取其中的元素值
- array类型的字段的元素访问方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号