部署hadoop集群环境前的准备
本文使用Linux版本为centos7,准备3个节点,来部署hadoop集群前要做一些准备工作
具体分配规划如下所示:
| 节点名称 | 节点IP |
| ----------|------------|
| hadoop01 | 192.168.56.10 |
| hadoop02 | 192.168.56.20 |
| hadoop03 | 192.168.56.30 |
使用终端工具secureCRT链接上3台机器,切换成root用户进行如下配置:
-
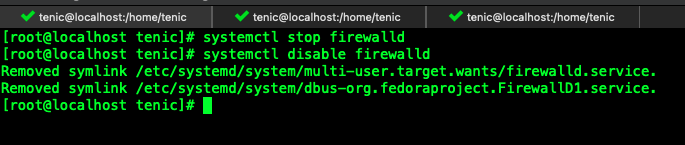
关闭防火墙
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #禁止防火墙启动
![]()
-
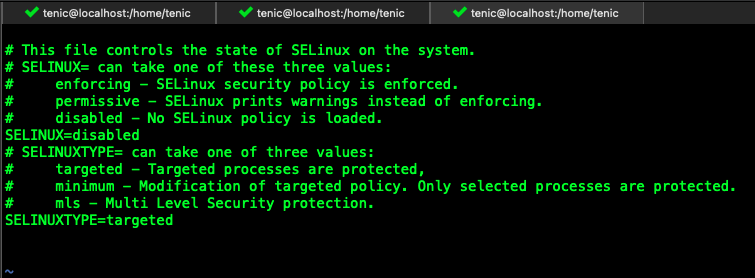
关闭selinux
编辑 /etc/sysconfig/selinux 文件 ,修改SELINUX=disabled
![]()
-
修改主机名称
编辑 /etc/hostname文件,3台机器分别修改成自己规划的名称
第一台 hadoop01
第二台 hadoop02
第三台 hadoop03 -
修改主机映射文件和名称
编辑 /etc/hosts文件,添加其他机器的配置信息到映射文件里
192.168.56.10 hadoop01
192.168.56.20 hadoop02
192.168.56.30 hadoop03 -
同步三台机器时间,使用阿里云时间同步器
三台机器都安装ntpdate
yum -y install ntpdate阿里云时钟同步服务器
ntpdate ntp4.aliyun.com创建一个定时任务,这样就可以自动帮我们同步到阿里云的时钟服务的时间
crontab -e
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
- 添加一个专门用来处理大数据相关的用户,例如我们设置账号为hadoop ,密码为123456,那就分别在3台机器上进行如下操作:
useradd hadoop
passwd hadoop,输入一个密码,123456
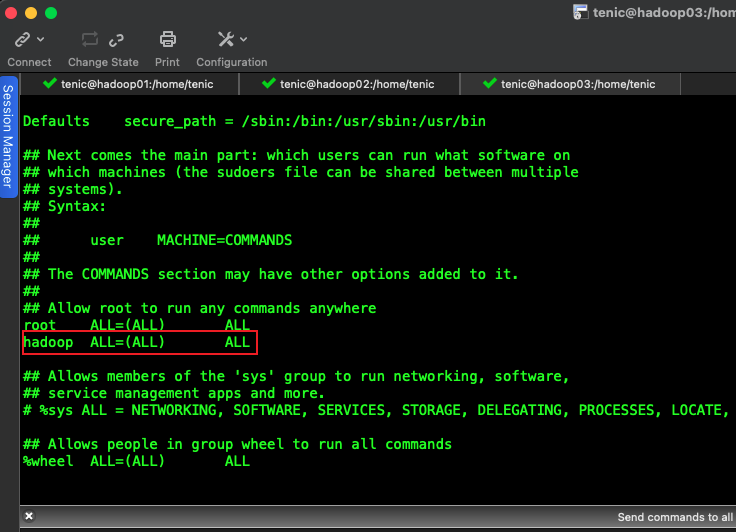
新增用户,添加root权限,省去执行权限问题
visudo
新增如下内容
hadoop ALL=(ALL) ALL
我们为这个账号创建2个文件夹,方便以后我们对的工具或者代码的管理,例如我们在根目录创建一个bigdata文件夹,
下边创建一个soft,用于放置我们上传的安装包,代码等。再创建一个install,用于放置我们安装的软件。
注意要对这2个文件夹分配所属人到我们新增加的账户 hadoop
mkdir -p /bigdata/soft
mkdir -p /bigdata/install
chown -R hadoop:hadoop /bigdata
-
免密登陆准备
由于是3台服务搭建集群,hadoop启动以后,namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的,所以我们需要配置一下免密登陆
三台机器上都生成密钥信息
ssh-keygen -t rsa,然后是3个回车Enter现在是3台机器都生成了各自的密钥,我们在其中1台上复制粘贴其他2台的密钥,我们3台都同时执行下边命令来进行复制
ssh-copy-id hadoop01
然后在复制这个密钥文件到其他2台就可以实现3台有相同的密钥文件
scp authorized_keys hadoop02:$PWD
scp authorized_keys hadoop03:$PWD验证一把,在hadoop01上输入ssh hadoop02,查看是否当前机器变成了hadoop02
-
安装JDK
我们将本地的jdk文件上传到hadoop01,并对其进行解压和配置profile文件
cd /bigdata/soft
tar -zxf jdk-8u141-linux-x64.tar.gz -C /bigData/install将hadoop01机器上的jdk复制到其他机器上去
scp -r /bigdata/install/jdk1.8.0_141 hadoop@hadoop02:/bigdata/install
scp -r /bigdata/install/jdk1.8.0_141 hadoop@hadoop03:/bigdata/install编辑配置文件,执行命令 sudo vim /etc/profile
export JAVA_HOME=/bigdata/install/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin激活一下profile文件 source /etc/profile

 浙公网安备 33010602011771号
浙公网安备 33010602011771号