redis----day04(持久化方案、RDB方案、aof方案、混合方案、主从复制原理和方案、哨兵高可用、)
昨日回顾
# 悲观乐观锁:
django中如何实现
-悲观锁:mysql 行锁 表锁
-乐观锁:真正修改时,加入限制条件
django中事务如何开启
-原生sql如何开启事务:begin; commit;
-django中如何开事务:atomic() commit()
for_update是锁表还是锁行
如果查询条件用了索引/主键,那么select ..... for update就会进行行锁
如果是普通字段(没有索引/主键),那么select ..... for update就会进行锁表
# redis geo 地理位置信息---》存经纬度
-计算两点的距离
-计算方圆多少范围内的(好友)
.
.
.
.
.
.
.
今日内容
1 持久化方案
# 什么是持久化
redis的所有数据保存在内存中,把内存中的数据同步到硬盘上这个过程称之为持久化
--------------------------------------------------
# 持久化的实现方式
# 1 快照:某时某刻数据的一个完成备份
mysql的Dump
redis的RDB
# 2 写日志:任何操作都记录一个日志,要恢复数据,只要把日志重新走一遍即可 !!!
mysql的 Binlog # 日志记录
Redis的 AOF # 日志记录
# 3 混合持久化 RDB+AOF(不是两个方案同时开启,)
--------------------------------------------------
.
.
.
关redis服务端进程
# 正常关服务端进程:
在客户端敲 shutdown命令,会正常关掉服务端,关进程之前会自动save拍个快照,将内存持久化到硬盘
# 强行关redis的服务端进程:
ps aux |grep redis # 先查看并过滤出redis进程
kill -9 redis进程id号 # 强行关redis进程
.
.
.
1.1 RDB
# dump.rdb 文件在 redis/data 目录下
# rdb 持久化触发机制-主要三种方式
-----------------------------------------------------
# 方式一:通过命令----同步操作(客户端会阻塞住等待服务端返回消息,才能执行其他redis命令)
直接在redis的命令行敲save,就会生成rdb持久化文件
# 弊端就是:没来得及拍快照的数据会因为,服务端意外的停止而导致数据丢失
-----------------------------------------------------
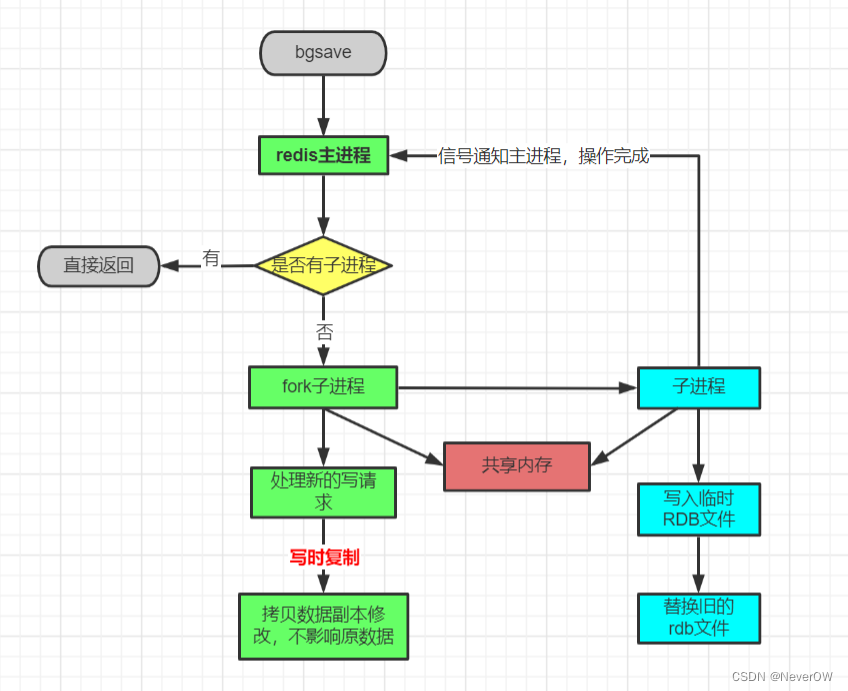
# 方式二:异步持久化----不会阻塞住其他redis命令的执行
直接在redis的命令行敲bgsave,就会生成rdb持久化文件
-----------------------------------------------------
# 方式三:配置文件配置-----满足设置条件自动触发,内部执行bgsave
save 900 1
save 300 10
save 60 20
dbfilename dump.rdb
dir "/root/redis-6.2.9/data"
# 如果60s中有20条数据修改了,自动生成rdb文件
# 如果300s中改变了10条数据,自动生成rdb文件
# 如果900s中改变了1条数据, 自动生成rdb文件
# 常用方法,启动的时候要用配置文件启动
# cd到redis目录下启动服务端 ./src/redis-server ./redis.conf
-----------------------------------------------------
# 只要是备份操作,都会先删掉data目录下的,已经存在的dump.rdb文件,
# 然后再将redis内存中的数据全部重新备份一下,
# 所以不管快照多少次,最后data目录下只有一个dump.rdb文件
-----------------------------------------------------
# RDB存在的弊端: 耗时,耗性能 可能会造成数据丢失
# 如果只是用redis来做缓存,那丢失一点也无所谓,反正数据库里有原始数据
-----------------------------------------------------
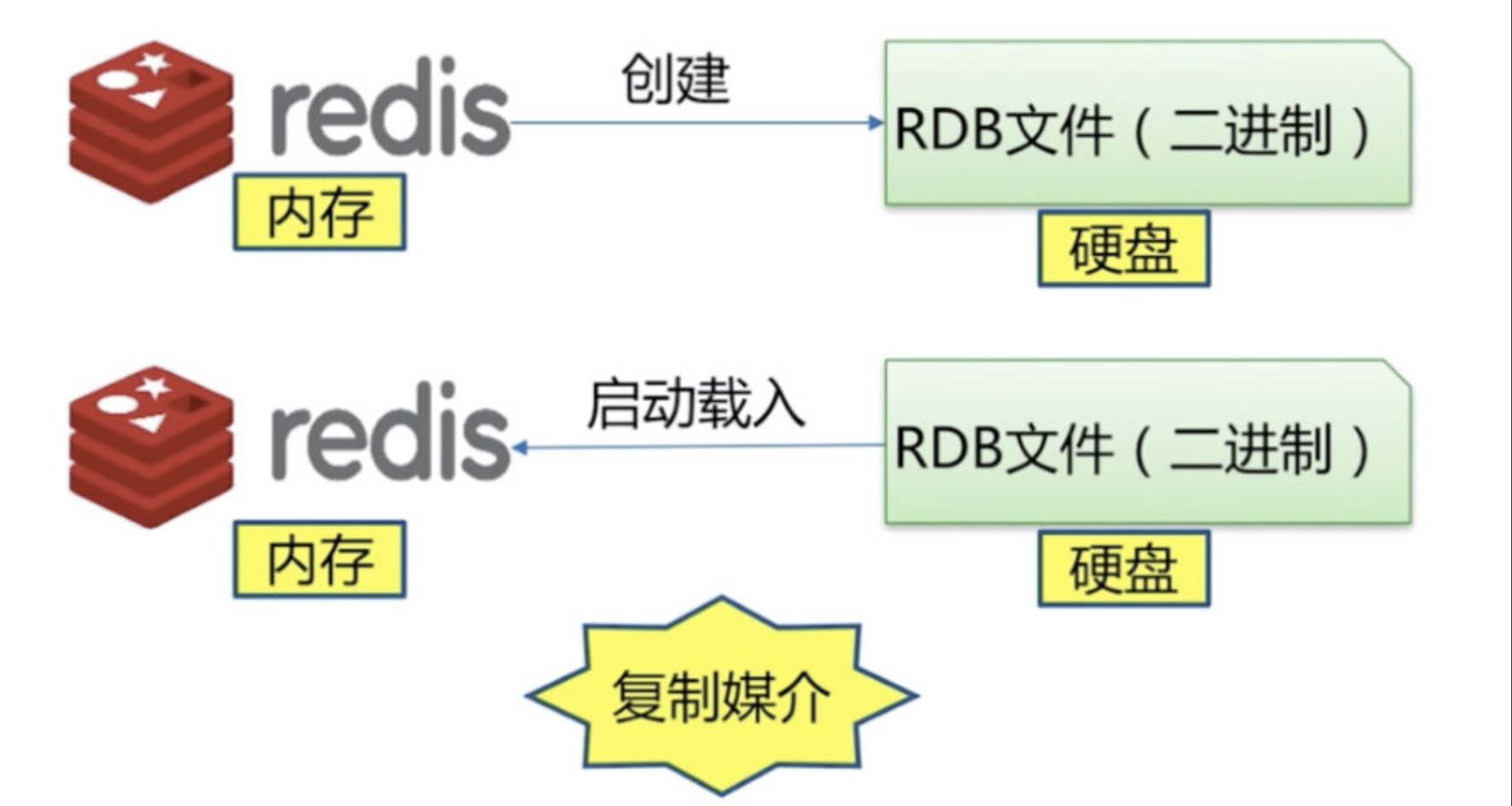
redis内存中的数据,通过快照的方式,对内存中redis的数据做了一个完整的备份,
保存到硬盘中,生成一个RDB文件,当出现断电等情况的时候,
redis重启的时候,会自动将rdb文件中载入到内存中,这样内存中就又有了!!!
但是rdb会丢数据,因为快照不是一直在拍快照,
上一次拍快照到出现意外的这段时间的数据,会因为没来的及拍快照,而丢失
.
.
.
.
.
.
.
.
1.2 aof方案
# aof是什么:
客户端每写入一条命令,都记录一条日志,放到日志文件中,对系统的性能损耗也是有的
如果出现宕机,可以将数据完全恢复
-----------------------------------------------------
# AOF的三种策略
日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上
always redis每写一条命令放到缓冲区----并刷到硬盘上---AOF文件
# 如果redis并发量大,磁盘的读写速度可能跟不上
everysec(默认策略) redis每写一条命令放到的缓冲区---每秒把缓冲区命令刷到硬盘上---AOF文件
no redis每写一条命令放到的缓冲区---操作系统决定,什么时候把缓冲区命令刷到硬盘---AOF文件
----------------------------
三种策略的优缺点:
策略 always everysec no
优点 不丢失数据 每秒缓冲区刷一次到硬盘,丢失1秒数据 不用管
缺点 IO开销大,一般的sata盘只有几百TPS 丢1秒数据 不可控
-----------------------------------------------------
-----------------------------------------------------
# AOF重写
随着命令的逐步写入,并发量的变大, AOF文件会越来越大,通过AOF重写来解决该问题
本质就是自动把过期的,无用的,重复的,可以优化的命令,来优化,
这样可以减少磁盘占用量,加速恢复速度
# AOF重写配置参数 可以同时配,两个条件同时满足才会自动触发AOF重写
auto-aof-rewrite-min-size:500mb # 不设置默认每增加64mb触发一次重写
# AOF文件第一次到了500M就会触发重写策略,下次要到了1000M会触发,再下次要1500才会触发...
auto-aof-rewrite-percentage: 增长率
# 增长率 当前aof文件的增加量x100/上次aof文件大小 默认是100 就在增量是原数据的一倍
--------------------------------------------------------------
.
.
aof持久化的配置
# 还是改redis的配置文件redis.conf 在配置文件里面添加下面这些配置
appendonly yes # 将该选项设置为yes,就是开启aof的持久化
appendfilename "appendonly.aof" # 生成的aof文件名
appendfsync everysec # 每秒将数据从缓冲区刷到硬盘的aof文件里
no-appendfsync-on-rewrite yes # 在aof重写期间,不要对aof进行追加
# 在aof重写的时候,因为aof重写消耗性能,磁盘消耗,与正常aof写磁盘有一定的冲突,所以不让追加
# aof文件是追加的形式,每次从缓冲区将数据刷到硬盘,都是将缓冲区的数据,追加到原aof的文件里
# redis持久化过程中出错了怎么恢复数据
# 重启redis就行了,redis会自动加载持久化文件到缓存里面去的
--------------------------------------------------------------
.
.
.
.
.
.
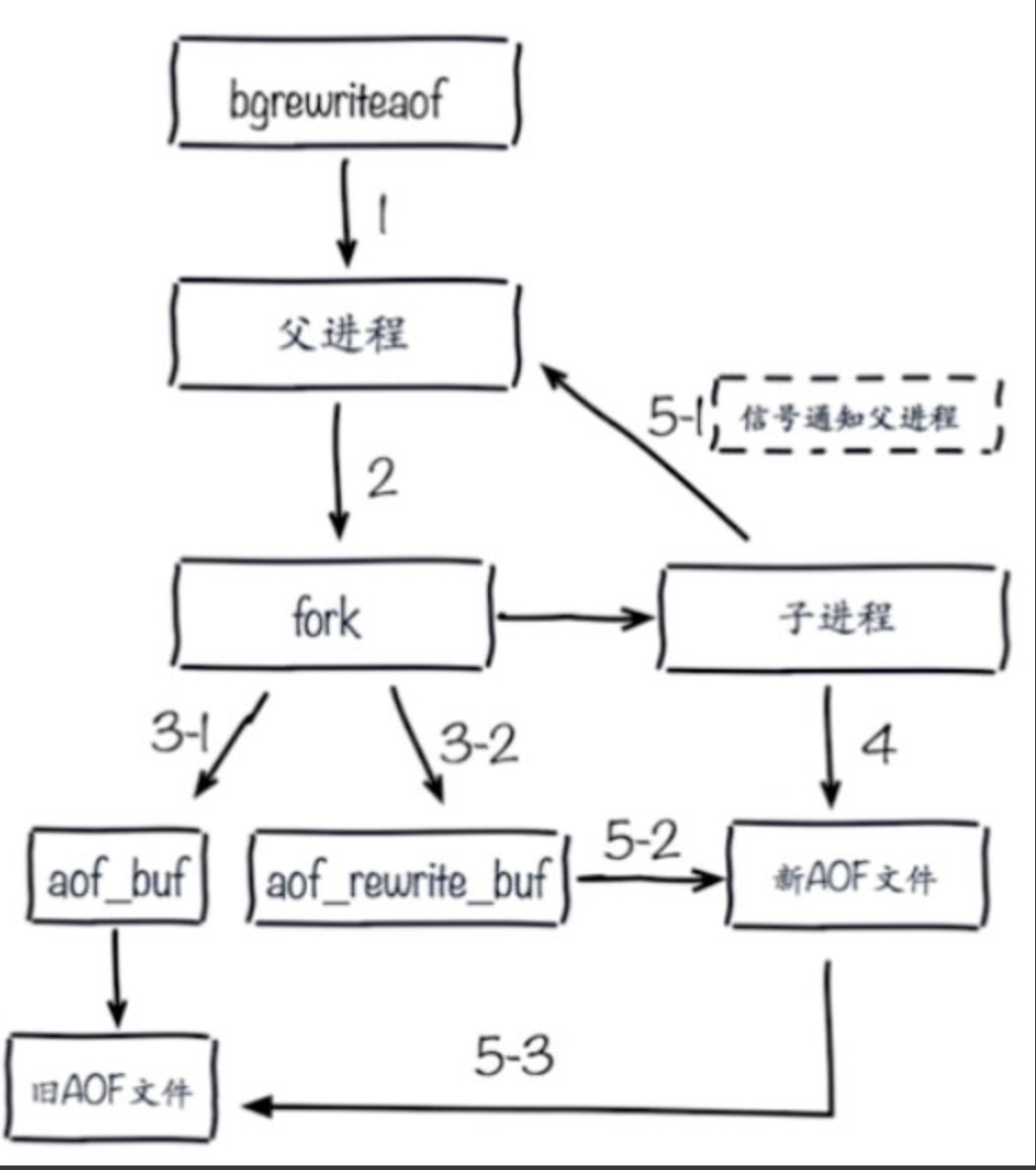
AOF重写大致流程
使用子进程进行AOF文件重写时还会存在一个问题:子进程在进行文件重写期间,
主进程依然能继续处理新的命令,如果新的命令使数据库数据发生了修改,
那么当前数据库的数据和AOF重写之后的数据将会不一致。
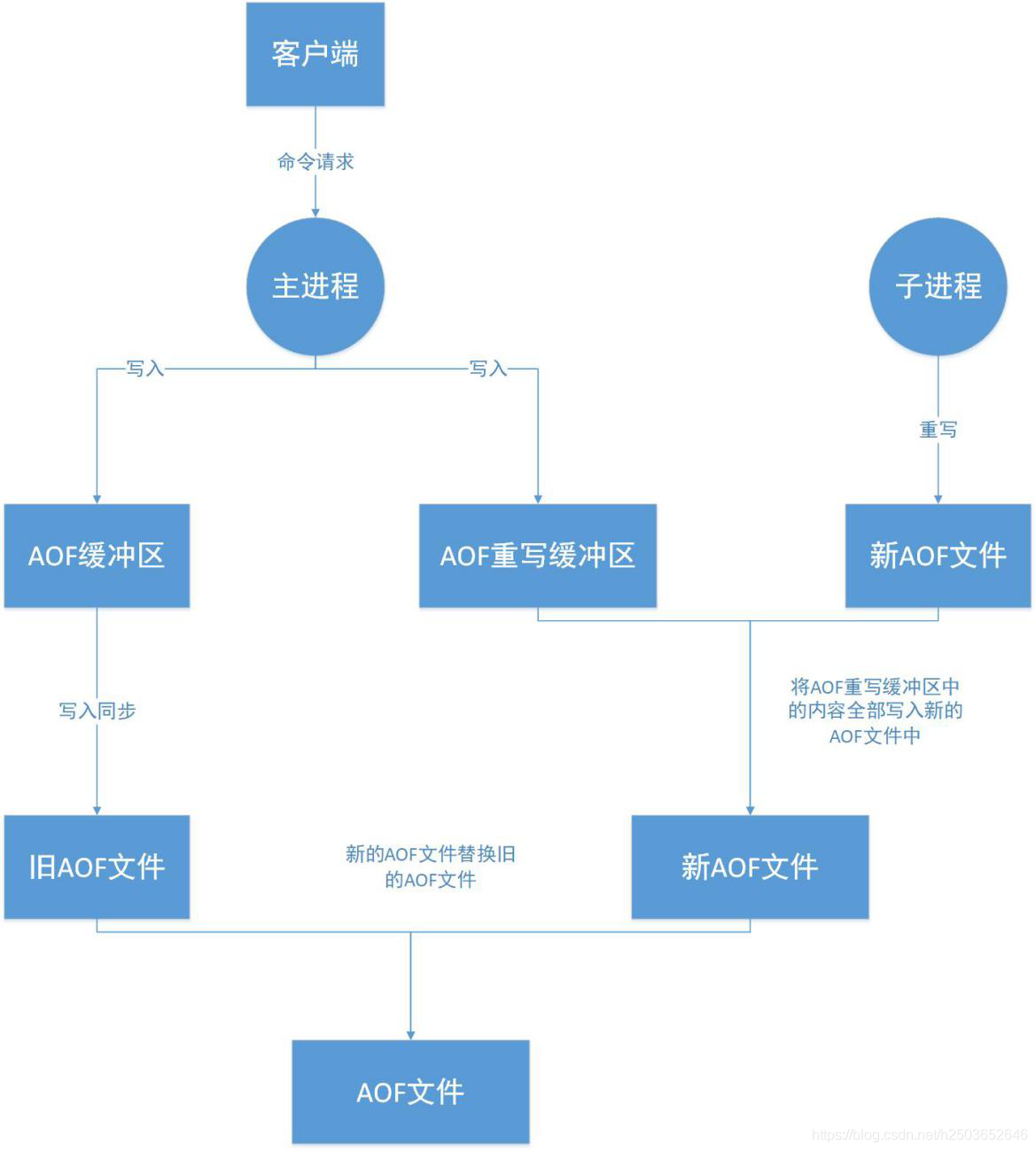
为了解决这一问题,redis增加了一个AOF重写缓冲区
这个缓冲区在fork出子进程之后开始启用,Redis服务器主进程在执行完写命令之后,
会同时将这个写命令追加到AOF缓冲区和AOF重写缓冲区
AOF缓冲区的内容会定期写入和同步到旧AOF文件中,这是为了保证旧AOF文件正常工作
创建子进程开始,主进程所处理的所有写操作都会被记录到AOF重写缓冲区,当子进程完成AOF文件重写之后
会向主进程发送一个完成信号,主进程接收到这个信号后,
会将AOF重写缓冲区中的内容全部写入新的AOF文件中,
此时的AOF文件中的数据和当前数据库数据状态一致;
对新的AOF文件进行改名覆盖原有的旧AOF文件,最终完成新旧AOF文件的替换。
.
.
.
.
.
.
.
.
1.3 混合持久化
# 可以同时开启aof和rdb持久化方案,他们是相互不影响的,但是没必要同时开启
# 非要那么做,启动redis时,需要指定加载哪个持久化文件
# 配置文件 appendonly 设置为yes,优先启用aof持久化文件恢复数据;否则启用dump.rdb文件恢复。
--------------------------------------------------
# redis 4.x以后,出现了混合持久化,其实就是aof+rdb
# 使用混合持久化的目的:
因为硬盘中的rdb的文件恢复速度快,但是存在数据丢失
AOF文件数据丢失少,但需要一条条命令的去执行,恢复速度慢
混合持久化解决的问题:加快redis重启时,将硬盘数据恢复到缓存的速度问题
--------------------------------------------------
# 开启混合持久化后,aof文件里面又有rdb的数据,又有aof的日志记录
# 简单来说RDB以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。
Redis服务器 在执行 AOF重写操作时,实际执行的是rdb操作,
将当前内存中redis的数据做了一个完整的备份生成rdb数据,并将这些数据,写入新建的AOF文件中
至于那些 在AOF重写开始之后,执行的Redis命令,则会已aof记日志的形式,
追加到刚刚新建的AOF文件中的rdb数据的后面!!!
# 换句话说,在开启了RDB-AOF混合持久化功能之后,服务器生成的AOF文件将由两个部分组成,
其中位于AOF文件开头的是RDB格式的数据,而跟在RDB数据后面的则是AOF格式的数据
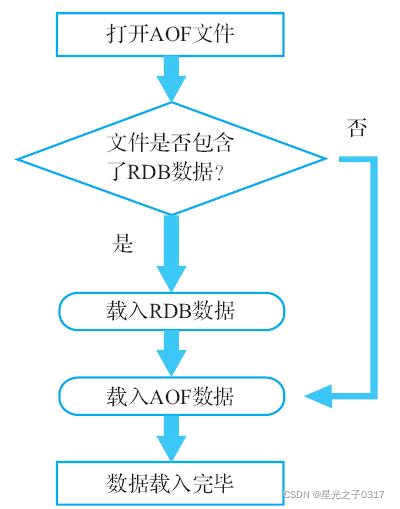
# Redis服务器启动并载入AOF文件时,它会检查AOF文件的开头是否包含了RDB格式的内容
# 如果包含,那么服务器就会先载入开头的RDB数据,然后再载入之后的AOF数据
# 如果AOF文件只包含AOF数据,那么服务器将直接载入AOF数据
--------------------------------------------------
# redis的配置文件要的 配置参数
appendonly yes # 必须先开启 aof
aof-use-rdb-preamble yes # 开启 混合持久化
auto-aof-rewrite-percentage 100 # aof重写触发条件
auto-aof-rewrite-min-size 64mb # aof重写触发条件
save "" # 关闭 rdb
# aof重写可以使用配置文件触发,也可以手动触发在redis客户端命令行直接敲命令:bgrewriteaof
----------------------------------------------------
# 注意事项:
rdb和aof文件生成,属于cpu密集型 优化:不做cpu绑定,不和cpu密集型的服务一起部署
优化:单机部署尽量少重写
不要和高硬盘负载的服务部署在一起:存储服务,消息队列
在aof重写期间,不要对aof进行追加:no-appendfsync-on-rewrite=yes
----------------------------------------------------

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2 主从复制原理和方案
# 为什么需要主从
可能会有以下问题:
1 机器故障
2 容量瓶颈
3 QPS瓶颈
# 主从解决了qps问题,机器故障问题
# 主从实现的功能
一主一从,一主多从
做读写分离
做数据副本
提高并发量
一个master可以有多个slave
一个slave只能有一个master
数据流向是单向的,从master到slave,从库只能读,不能写,主库既能读又能写
# redis主从赋值流程,原理
1. 副本(从)库通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库
2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
3. 副本库接收后会应用RDB快照,load进内存
4. 主库会陆续将中间产生的新的操作,保存并发送给副本库
5. 到此,我们主复制集就正常工作了
6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库.
7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在.
8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
# 主从同步主库是否要开启持久化?
如果不开有可能,主库重启操作,造成所有主从数据丢失!
# 启动两台redis服务
# 主从复制配置
-1 命令方式,在从库上执行
slaveof 127.0.0.1 6379 #异步
# 从库不能写了,以后只能用来读
slaveof no one # 从库:断开主从关系
-2 配置文件方式,在从库加入
slaveof 127.0.0.1 6379 #配置从节点ip和端口
slave-read-only yes #从节点只读,因为可读可写,数据会乱
autpass 123456
# 辅助配置(给主库用的)
min-slaves-to-write 1
min-slaves-max-lag 3
#那么在从服务器的数量少于1个,或者三个从服务器的延迟(lag)值都大于或等于3秒时,主服务器将拒绝执行写命令
.
.
.
.
.
.
.
.
3 哨兵高可用
# 服务可用性高
#主从复制不是高可用
#主从存在问题
#1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master --》 哨兵
#2 主从复制,只能主写数据,所以写能力和存储能力有限---》集群
# 哨兵:Sentinel 实现高可用
# 工作原理:
1 多个sentinel发现并确认master有问题
2 选举触一个sentinel作为领导
3 选取一个slave作为新的master
4 通知其余slave成为新的master的slave
5 通知客户端主从变化
6 等待老的master复活成为新master的slave
# 高可用搭建步骤
第一步:先搭建一主两从
第二步:哨兵配置文件,启动哨兵(redis的进程,也要监听端口,启动进程有配置文件)
port 26379
daemonize yes
dir /root/redis/data
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
port 26390
daemonize yes
dir /root/redis/data1
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
port 26381
daemonize yes
dir /root/redis/data2
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
第三步:启动三个哨兵
./src/redis-sentinel ./sentinal_26379.conf
./src/redis-sentinel ./sentinal_26380.conf
./src/redis-sentinel ./sentinal_26381.conf
第四步:停止主库,发现80变成了主库,以后79启动,变成了从库
.
.
.
.
.
.
.
作业
3台机器练习一下


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY