redis----day03( 面试如何聊、redis的 GEO地理位置信息 、布隆过滤器原理、布隆过滤器使用 )
面试如何聊
----------------------------------------
# 第一面(笔试):
-办公室做题:拍照,发群里---》自己课搜,同学帮着搜----》往上写
-问不答了,可以直接面试吗?
-----------------------------------------
# 第二面:正式面试(开启手机录音,放口袋中)
-一个人,多个人坐你对面
-最重要的:自我介绍(自己提前写出来,500字,尽可能展现自己的优势)
-面试官您好,我叫xxx,来自于xx市,本科毕业于xxx,专业计算机,现在来应聘xx职位,从事python开发x年(某年某月从事python开发),python用的比较多,所以它的常用包,第三方包例如requests,sqlalchemy,框架 django,flask,fastapi都用过,看招聘需求上有fastapi,目前这个框架挺火,但是我们公司没用,我前段时间简单的看了看,写了点小东西,放到了github上,写了使用博客,平时比较喜欢写博客,一个项目开发中用的从前到后的东西,都有所涉猎,比如前端框架vue用过,我之前uniapp,研究过 mysql用的多,oracle,pg没怎么用过,不过现在好多公司在用pg,不知道咱们公司在没在用,索引,锁,事务,很清楚,原生sql也经常写,但是平时写项目orm居多,有些orm实现不了的用原生,web 框架比较清楚执行流程,像falsk蓝图,信号,都是知道的,像缓存数据库redis比较清楚,ngxin,linxu都用过,resuful规范,htpp协议。。。
如果对前端要求不是特别强,我感觉能做全栈,前段时间写了个全栈项目,最近在看xx相关的东西,最近买了本redis深度历险,在研究xx东西,我的性格比较开朗,比较活泼,思维活跃,学历能力挺强,之前写项目中遇到问题最终都能顺利解决,平时比较喜欢运动,打篮球,健身,看书,喜欢美食,我的个人介绍结束
-个人技能知识点---》只要简历里写的,一定有旁白 旁白
互斥锁
-问一些你上面没写的,python 常见面试题
-这个我知道, 实在没听过的:
-之前工作中,写项目中没有设计到这个,对这个不是很清楚
-之前很久之前了解过,现在忘了,记不起来了因为好久没看了
-开放性问题:各凭本事,想到啥聊啥
-现在面试时间比较紧迫,之前一直在写公司业务,对这方面研究没有那么透彻,我平时如果遇到难搞的问题,我会搜索,看官方文档,跟同事,同学交流,最终把问题解决,现在您问的这个问题由于比较紧,又没有太多参考,所以回答的不太好,如果给我更多时间,我一定会给你一个满意的答案
-问项目:准备1-2个,流程非常清楚,其他的别人问就说,写过比较久了,之前就说参与开发,更多的细节记不清了
-你有什么想问我们的?
-咱们公司做什么业务? 用什么技术栈?用户群体是什么?用户量多少,项目并发量多少,数据库用的什么数据,大约有多少表?
-我感觉您技术水平很高,工作经验很丰富,我最近遇到一个这个问题
-我这人对技术很有追求,不会的我一定要搞懂,刚刚您问我一个问题,我倒现在没有好的方案,您能给我讲解一些吗?
-我感觉行业经验很丰富,您能给我一些中肯的建议吗?
----------------------------------------
第三面:更高级技术,老板
-跟上面差不多
-捧它
-有深度的技术:适可而止
-老板不懂技术:你给他画饼
----------------------------------------
第四面:hr面
-谈薪资:为什么离职,为什么来上海,之前工资多少,之前上班通勤多长时间
-平时加班多,大小周吗
-工资构成是什么 13薪 固定工资
-社保,公积金。。
-本科学历
-她先出:您给个范围 取中间 还可以再聊
----------------------------------------
.
.
.
.
.
.
.
.
.
.
.
.
今日内容
1 GEO地理位置信息
# GEO(地理信息定位):存储经纬度,计算两地距离,范围等
根据经纬度--------确定具体地址的
比如有高德或者百度都有开放的api
用requests模块,带着经纬度等数据去请求,会返回具体地址
遇到的问题, 记录地理位置信息,存到数据库中,有可能会有一些误差
如果遇到用经纬度请求接口,返回的地址不准确,可以多用几家的api试一下
把返回的地址不太一样的,做个标记,后续人工去审一下
-----------------------------------------------------
# redis 可以存储经纬度,存储后可以做运算,
比如:两个经纬度之间距离 (直线距离)
比如:统计某个经纬度范围内有哪些好友,餐馆
# 经纬度如何获取 ?
跟后端没关系:后端只需要存就行了
app有定位功能,就能够获取到经纬度,调接口传给后端
网页集成了高德地图,就实现了定位功能
js代码就能获取经纬度(百度下)
---------------------------------------------------
# redis存储
geoadd key 经度 纬度 名字
# 添加
geoadd cities:locations 116.28 39.55 beijing
# 查看位置信息
geopos cities:locations beijing #获取北京地理信息
#计算两个点距离
geodist cities:locations beijing tianjin km
# 计算附近的 xx
georadiusbymember cities:locations beijing 150 km
# 5大数据类型的 : 有序集合
.
.
.
.
.
布隆过滤器原理
# 用途
为了防止缓冲穿透而使用了布隆过滤器,
在写入数据时,将键使用布隆过滤器进行标记(相当于设置白名单)
查询业务请求发现,缓存中无对应数据时,可先通过查询布隆过滤器,
判断数据是否在白名单内,如果不在白名单内,则直接返回空或失败,不让走数据库了!!!
垃圾邮件过滤,对每一个发送邮件的地址进行判断是否在布隆的黑名单中
# 布隆过滤器用在黑名单机制上,判断数据存在,会有点误差!!!
--------------------------------
简单来说,布隆过滤器(BloomFilter)是一种数据结构
# 特点是存在性检测,如果布隆过滤器中不存在,那么实际数据一定不存在!!!
# 如果布隆过滤器中存在,实际数据不一定存在!!!
# 布隆过滤器本身就是基于位图bitmap的
相比于传统数据结构(如:List、Set、Map等)来说,
它更高效,占用空间更少。缺点是它对于存在的判断是具有概率性。
布隆过滤器的数据结构,它是一个bit数组。如下图所示:
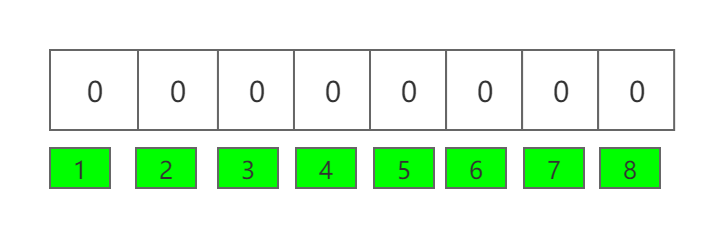
如果我们想要映射一个值到布隆过滤器中,怎么操作呢?
首先是使用多个不同的哈希函数生成多个哈希值,再把哈希值指向的bit位置设为1。
例如:我们要将值“baidu”映射到布隆过滤器上
假如我们使用三个不同的哈希函数生成了三个哈希值分别是:1、3、6,
那么上图就转变为下图这样:
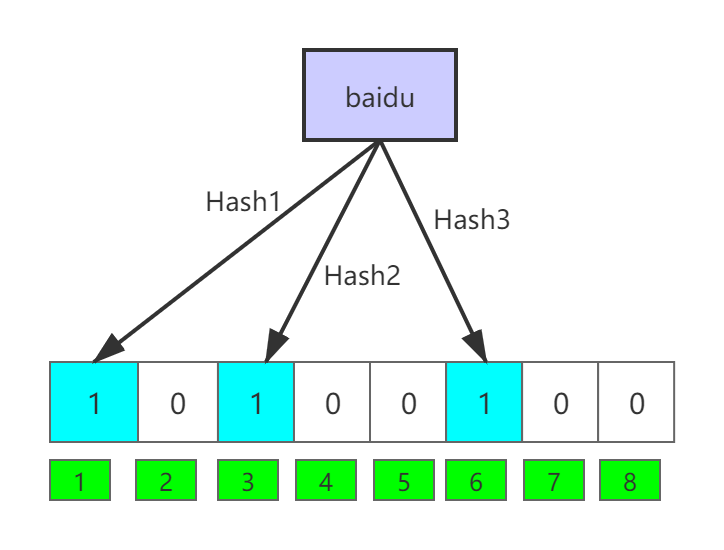
标有浅蓝色的bit位的值都被置为1,表示该数据已经映射上了
接着我们再把值“alibaba”和三个不同哈希函数生成的值:2、6、8映射到上面布隆过滤器中,
它就会变为下图的样子:
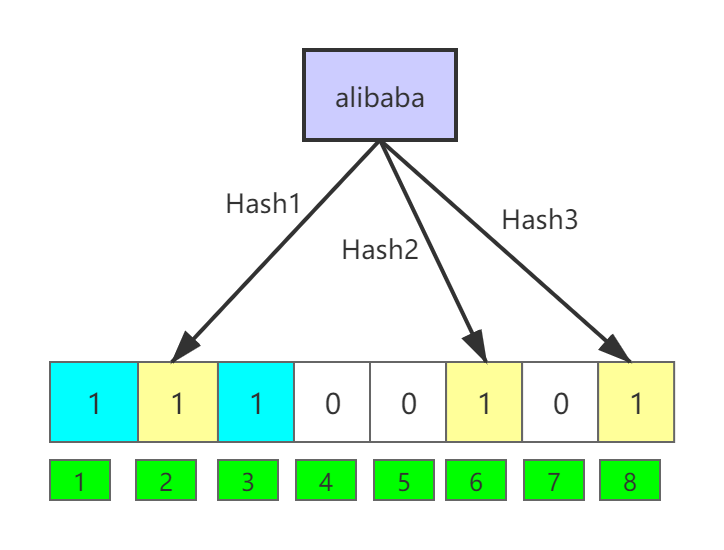
很显然,它把之前映射的哈希值6覆盖了,这就是布隆过滤器是有误报率的一个因素。
如果这时候,我们想拿一个值“aaa”查询它是否在上面布隆过滤器中存在。
该怎么操作呢?把值“aaa”用上面三个不同哈希函数生成三个哈希值分别是:1、3、8;
再去布隆过滤器上找这三个值对应的bit位的值是否都是1,
如果都是1说明“aaa”可能在布隆过滤器上存在
如果生成三个哈希值分别是:1、4、8 发现4对应的bit位为0,
说明“aaa”一定不可能在布隆过滤器上存在,
# 所以布隆过滤器可以精准的判断一个数据不存在!!!
---------------------------------------
很显然,长度过小的布隆过滤器很快所有的bit位都被置为1了,查询任意值都会返回“可能存在”
这样就起不到过滤的目的。说明,布隆过滤器的长度越小,其误报率就越高,
# 布隆过滤器的长度越长,误报率越低。
----------------------------------------
如果哈希函数的个数越多,布隆过滤器bit位置为1的速度就越快,且效率就会越低;
# 如果哈希函数个数越少,bit位置为1的速度就越慢,但是误报率就越高了。
-----------------------------------------
布隆过滤器的长度,哈希函数的个数,误报率以及期望插入元素的个数4者之间存在着关系
# capacity:布隆过滤器的初始容量,即期望添加到布隆过滤器中的元素的个数
-----------------------------------------
.
.
.
.
python中布隆过滤器如何使用
pip install pybloom_live # 下载第三方模块
from pybloom_live import ScalableBloomFilter, BloomFilter
# 可自动扩容的布隆过滤器 一般就用它
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001)
url1 = 'http://www.baidu.com'
url2 = 'http://www.zhihu.com'
bloom.add(url1)
print(url1 in bloom) # True
print(url2 in bloom) # False
------------------------------------------------
# BloomFilter 是定长的
bf = BloomFilter(capacity=1000)
bf.add(url1)
print(url1 in bf) # True
print(url2 in bf) # False
------------------------------------------------
# 上面方法有个致命的问题是,布隆过滤器的数据是在内存里的
# 一旦项目报错,或停掉,布隆过滤器的,数据就全没了
----------------------------------------------
# python 用redis实现简易版本的布隆过滤器
import math
import redis
import mmh3
# python 用redis实现简易版本的布隆过滤器
# 该布隆过滤器可以实现添加数据到布隆过滤器与检测数据在不在布隆过滤器功能的解耦合
# 而且就算项目崩掉停掉,只要redis里面的布隆过滤器的位图还在,
# 后续还是可以继续判断原来放进布隆过滤器的值存不存在的
error_rate = 0.001
capacity = 100
# 内置100个随机种子
SEEDS = [543, 460, 171, 876, 796, 607, 650, 81, 837, 545, 591, 946, 846, 521, 913, 636, 878, 735, 414, 372,
344, 324, 223, 180, 327, 891, 798, 933, 493, 293, 836, 10, 6, 544, 924, 849, 438, 41, 862, 648, 338,
465, 562, 693, 979, 52, 763, 103, 387, 374, 349, 94, 384, 680, 574, 480, 307, 580, 71, 535, 300, 53,
481, 519, 644, 219, 686, 236, 424, 326, 244, 212, 909, 202, 951, 56, 812, 901, 926, 250, 507, 739, 371,
63, 584, 154, 7, 284, 617, 332, 472, 140, 605, 262, 355, 526, 647, 923, 199, 518]
# 需要的总bit位数
bit_size = int(-capacity * math.log(error_rate) / (math.log(2) ** 2))
# 需要的哈希函数的数量 或者说需要最少的hash次数
hash_num = int((bit_size / capacity) * math.log(2))
# 需要的内存量M
neicun = math.ceil(bit_size / 8 / 1024 / 1024)
# 添加数据到布隆过滤器后,获取所有哈希函数求出的索引位置
def get_offsets(value):
seeds = SEEDS[0: hash_num]
offsets = []
for seed in seeds:
hash_value = mmh3.hash(value, seed)
offsets.append(hash_value % bit_size)
return offsets
def add(value):
for index in get_offsets(value):
conn.setbit('bloomfilter', index, 1)
# 判断是否存在
def contains(key):
for offset in get_offsets(key):
if not conn.getbit('bloomfilter', int(offset)):
print(offset)
print(conn.getbit('bloomfilter', int(offset)))
return False
return True
conn = redis.Redis(host='127.0.0.1', port=6379)
# 添加数据到布隆过滤器的代码 可以在其他文件里执行
url1 = 'http://www.baidu.com'
name = 'lqz3'
add(url1)
add(name)
# 下面检测数据的代码可以在其他文件里运行
print(contains('http://www.baidu.com')) # True
print(contains(name)) # True
print(contains('hhh')) # False
-------------------------------------
.
.
.
还可以直接用redis的布隆过滤器
# 还可以直接用redis的布隆过滤器 就是一个redis 加了布隆过滤器功能,多了一些命令
# redis的其他功能还是能正常用的
一 Docker安装
RedisBloom需要先进行安装,推荐使用Docker进行安装,简单方便:
docker pull redislabs/rebloom:latest
docker run -p 6380:6379 --name redis-redisbloom redislabs/rebloom:latest
docker exec -it redis-redisbloom bash
# redis-cli
# 127.0.0.1:6379> bf.add tiancheng hello
# 由于不知道镜像的配置文件在哪,所以容器里的只能暂时用6379端口起服务端了
二 或者直接编译
当然也可以直接编译进行安装:
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
make //编译 会生成一个rebloom.so文件 # 这个地方编译好像有点小问题
redis-server --loadmodule /path/to/rebloom.so
redis-cli -h 127.0.0.1 -p 6379
三 基本命令
bf.add 添加元素到布隆过滤器
bf.exists 判断元素是否在布隆过滤器
bf.madd 添加多个元素到布隆过滤器,bf.add只能添加一个
bf.mexists 判断多个元素是否在布隆过滤器
例如:
bf.add url www.baidu
bf.exists rurl www.baidu # 结果是 1
bf.madd url www.sougou www.jd
bf.mexists url www.jd www.taobao # 结果是 1 0 一个存在一个不存在
-----------------------------------
布隆过滤器在第一次add的时候自动创建基于默认参数的过滤器 比较小
默认的error_rate是0.01, capacity:即期望添加到布隆过滤器中的元素的个数是100
可以自己默认值 bf.reserve tiancheng 0.001 10000 # redis命令行里就这样敲命令即可
import redis
client = redis.Redis(host='10.0.0.200',port=6380)
num = 1000
count = 0
client.execute_command("bf.reserve", "lqz", 0.001, 10000) # 新增
for i in range(num):
client.execute_command("bf.add", "lqz", "xxx%s" % i)
result = client.execute_command("bf.exists", "lqz", "xxx%s" % (i + 1))
if result == 1:
print(i)
count += 1
# 打印错误率的,执行完一次之后,必须要先把resdis里面的数据删掉,再执行,看错误率才行
print(f"size: {size} , error rate: { round(count / num * 100, 5)}%")
.
.
.
.
.
.
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号