BBS仿博客园代码总结3---个人站点的页面搭建,左边侧边栏的搭建
个人站点的页面搭建
首页样式搭建好后,就要开始着手个人站点页面的搭建了,当我们在首页看到一篇篇的文章后,当点击文章下面的作者后,自动跳到该用户的个人站点下,该个人站点展示的是该作者的所有写的文章!!!整体样式和首页样式差不多,只是左边由广告栏变成侧边文章分类栏,标签分类栏,日期分类栏!!!
.
.
个人站点的路由设计
查看博客园的个人站点的路由设计,就是ip与端口后,接一个用户名称,组成一个路由,对应个人站点的视图函数。
---------------------------------
但是用户名是动态的,每个用户的用户名都不一样,所以就要使用到路由的动态匹配了,要么使用正则,要么使用转化器。我们这边就使用转换器来进行路由的动态匹配
# 个人站点接口
path('<str:username>/', views.site_func),
---------------------------------
.
.
.
当用户输入一个不存在的用户名的对应的路由时,博客园系统是要报404的
图片防盗链技术
所以当后端视图函数拿到个人站点的用户名称时,首先要判断该个人站点的用户名称存不存在,
没有的话,我们也要模仿博客园一样,返回一个404的错误页面出来
---------------------------------
def site_func(request, username):
# 查询个人站点是否存在,用双下魔法方法跨表查询
site_obj = models.Site.objects.filter(userinfo__username=username).first()
if not site_obj:
return render(request, 'error.html')
---------------------------------
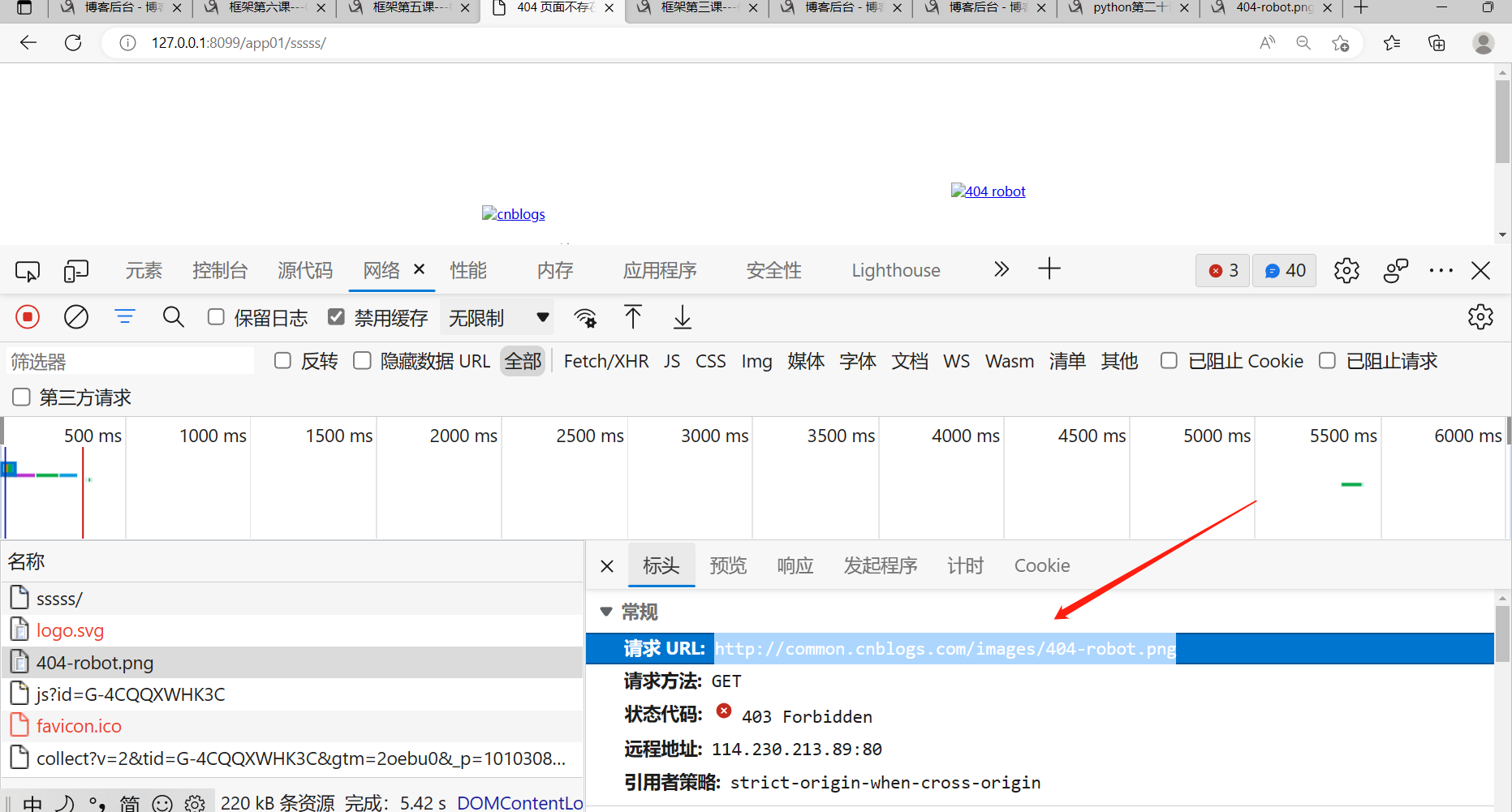
由于有图片防盗链技术所以我们不能直接用博客园网站里面的在线图片,要把博客园的图片先下载到本地,放到django里面的media目录里面去,才行
图片防盗链的工作原理:当客户端想要向博客园服务端要某一个图片资源的时候,服务端会先查看客户端从哪你来的,如果客户端是从别的网站来的,就不让该客户端拿该图片资源,如果客户端时从博客园的网站来的,就允许该客户端获取到该图片资源
对应的就是请求里面的一个参数Referrer Policy 用来标识客户端从哪个网站来的
---------------------------------
图片防盗链
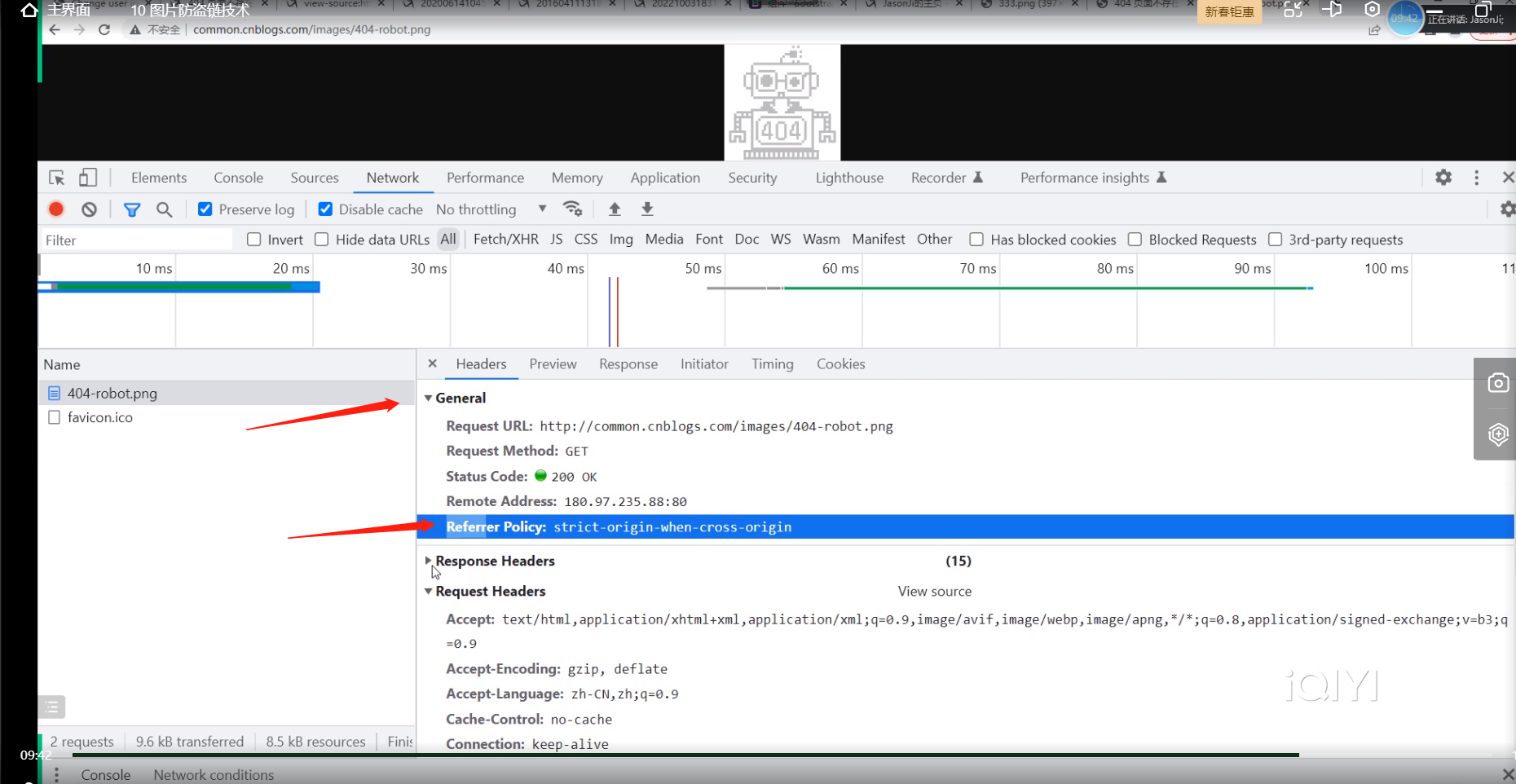
当我们直接复制博客园里面的源码的时候,Referer对应的是我们本地的ip与端口号,所以博客园不给你拿
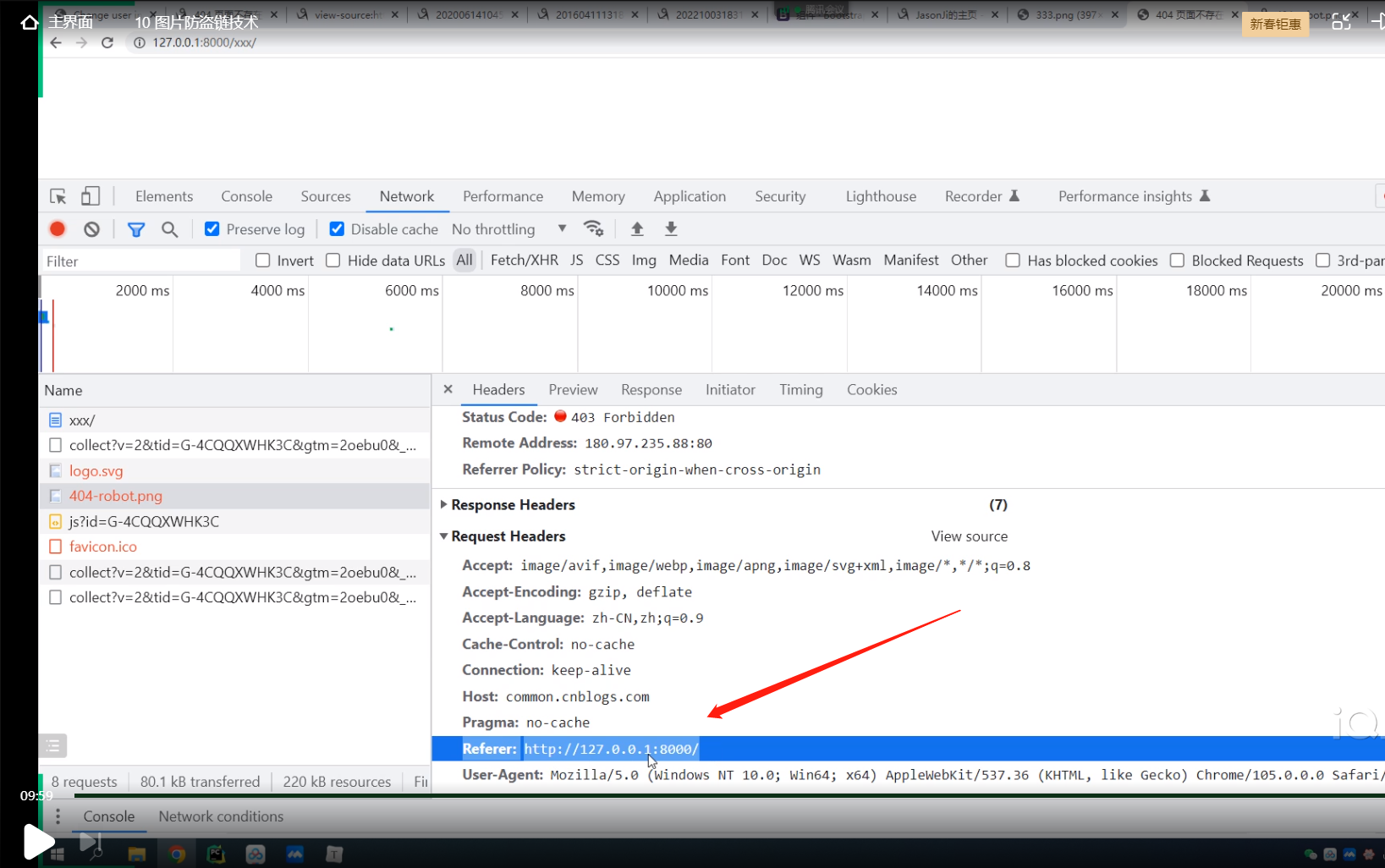
.
我们再看博客园的自己的404页面里面源码,Referer对应的是博客园自己的网站,所以就能正常拿到图片资源
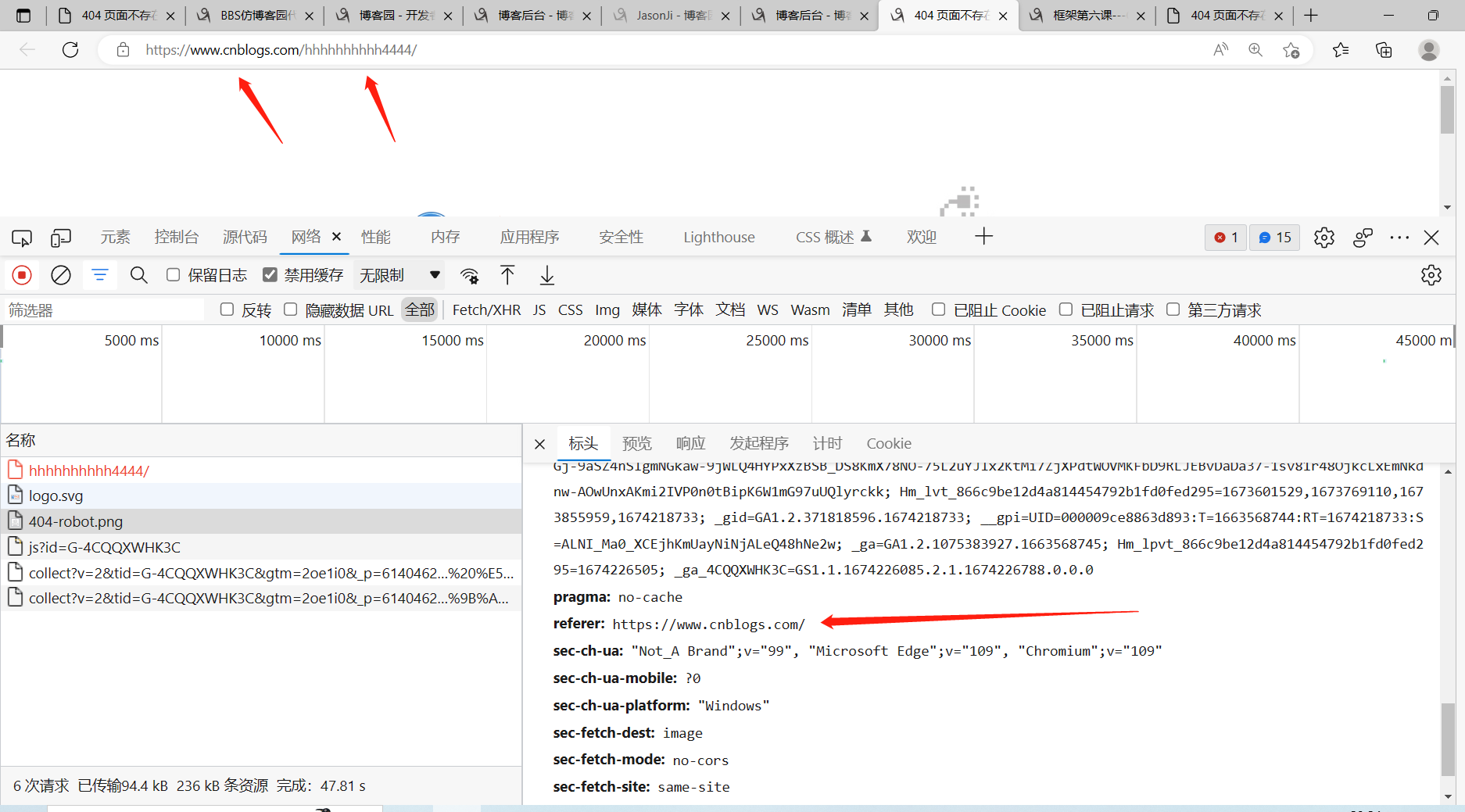
.
.
.
.
博客园404页面样式
.
.
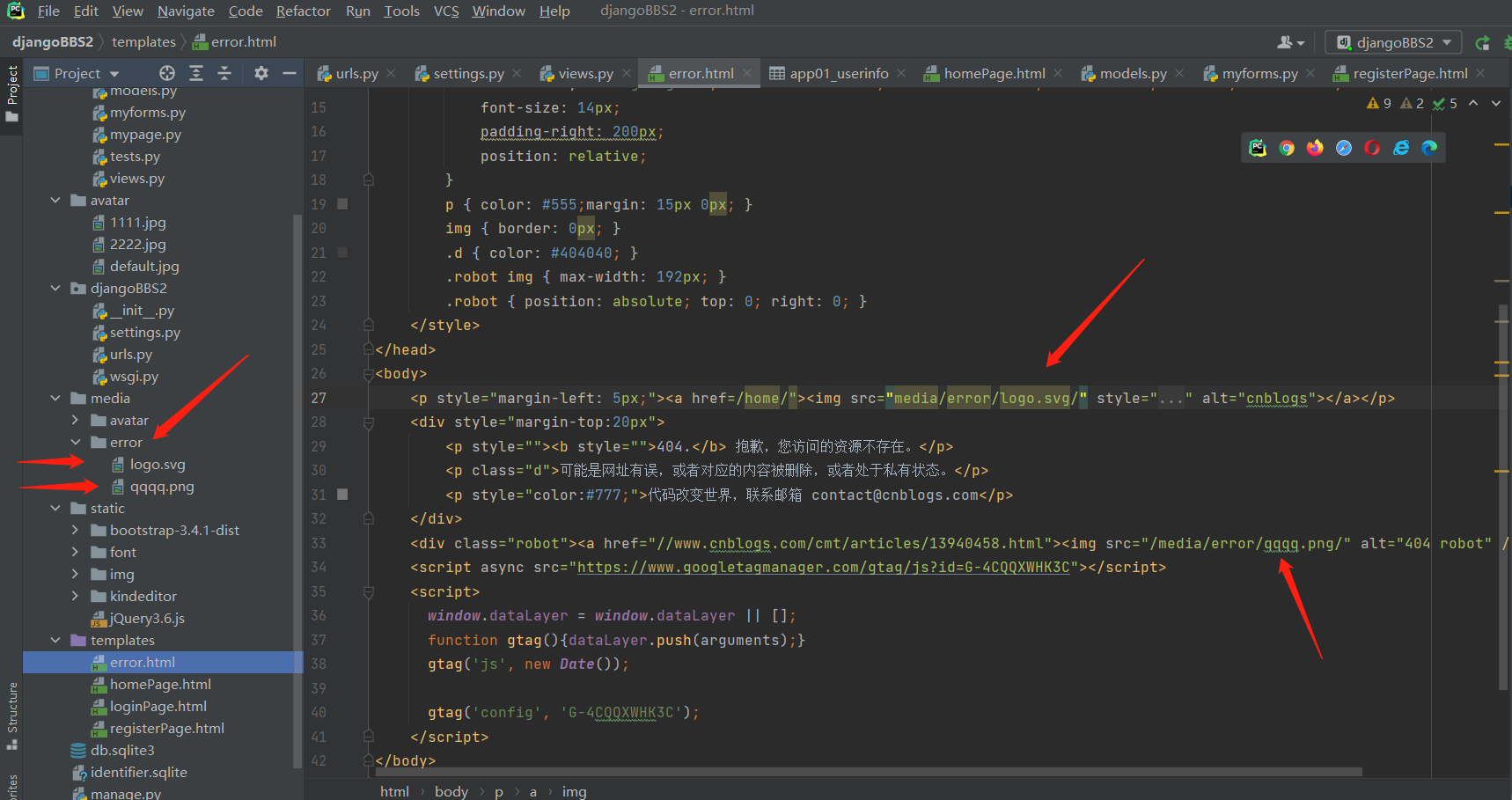
鼠标右击查看网页源代码,直接复制博客园的404页面的网页源码
.
.
但是图片还是显示不出来,因为有图片防盗链技术.
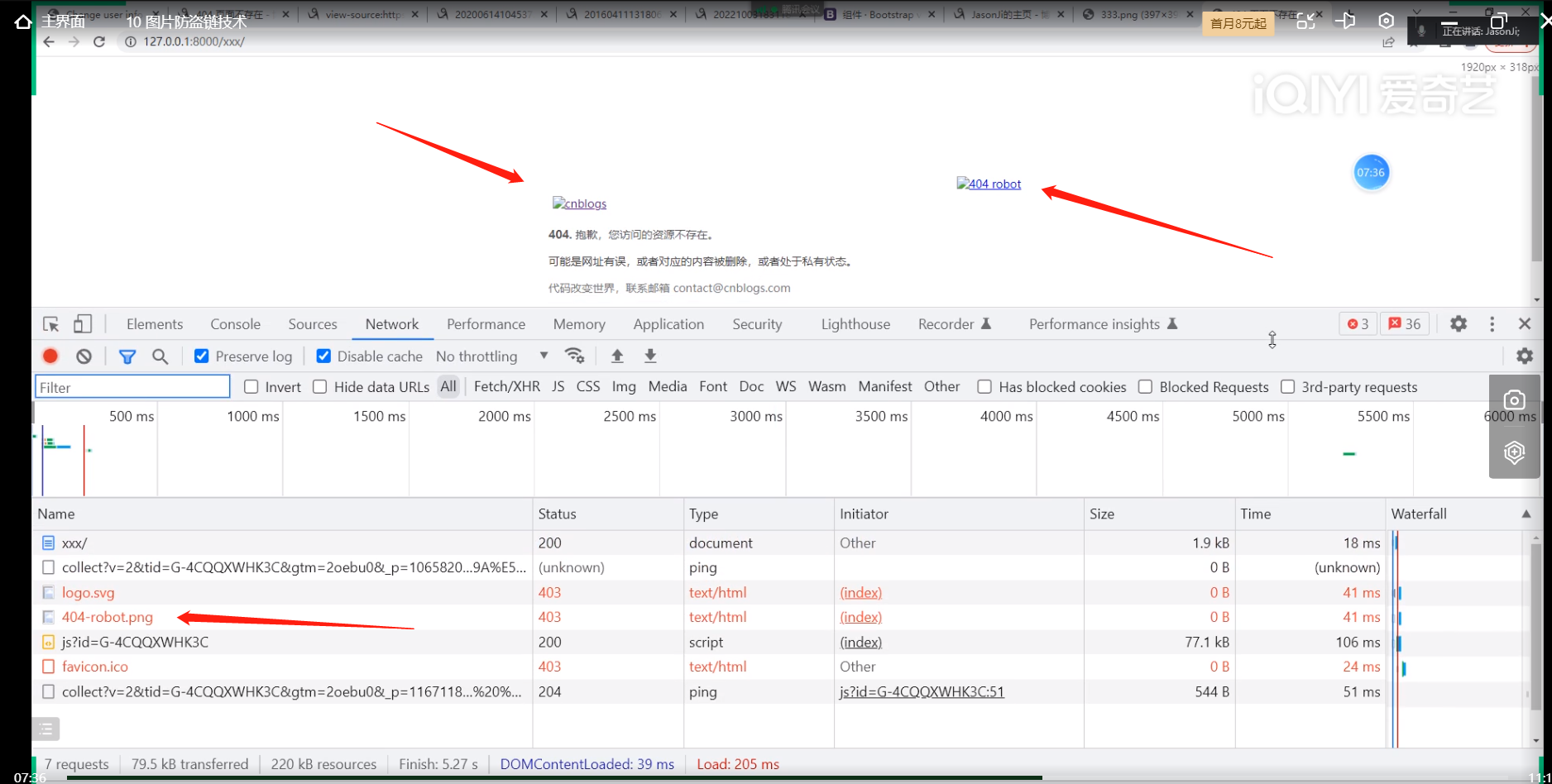
.
.
复制该禁止访问的图片网址,把图片扣下来,放到项目的文件夹下
.
.
博客园图片就扣过来了
.
.
.
.
.
个人站点的代码编写思路
首先我们要知道是博客园是如何跳到个人站点的路由的,是在主页home页面,展示的所有文章时,我们通过点击文章简介的左下角的文章作者的a标签触发个人站点的视图函数,跳转对应的用户名个人站点的页面的。
所以a标签的跳转路由为:<a href="/{{ article_obj.site.userinfo.username }}/">{{ article_obj.site.userinfo.username }}</a>
通过文章对象拿到文章的作者名称,以文章的作者名称作为个人站点的路由
该路由在路由层经过路由匹配,被转化器接收,作为关键字参数传给视图函数,
---------------------------------
个人站点视图函数的功能:
通过路由匹配到的用户名,传给视图函数后,先根据用户名查到对应的个人站点。
然后查询该个人站点所关联的所有文章。
现在个人站点里面就不再是展示所有用户的文章,而是展示的每一个用户所写的文章。后端代码初步实现
def site_func(request, username):
# 查询个人站点是否存在,用双下魔法方法跨表查询(反向查询表名小写!)
site_obj = models.Site.objects.filter(userinfo__username=username).first()
if not site_obj:
return render(request, 'error.html')
# 基于个人站点,查询个人站点下所有的文章
article_queryset = models.Article.objects.filter(site=site_obj)
return render(request, 'sitePage.html', locals())
---------------------------------
个人站点的前端页面可以继承home页面,提前在home页面里面用block包裹住可以替换的代码块
head标签里面塞一个空的
{% block css %}
{% endblock %}
导航条不动,导航条下面的内容区,全部用block包裹住
{% block content %}
{% endblock %}
body标签的最后塞一个空的
{% block js %}
{% endblock %}
---------------------------------
.
.
.
侧边栏分类标签的功能实现
模仿博客园的个人站点样式与功能:
左边是该用户名所写的所有文章的标签与分类栏,我们通过点击不同的标签与分类,在右侧看到对应所属的文章!!!!!
标签对象的主键值,作为了后续文章对象的依据
@login_required
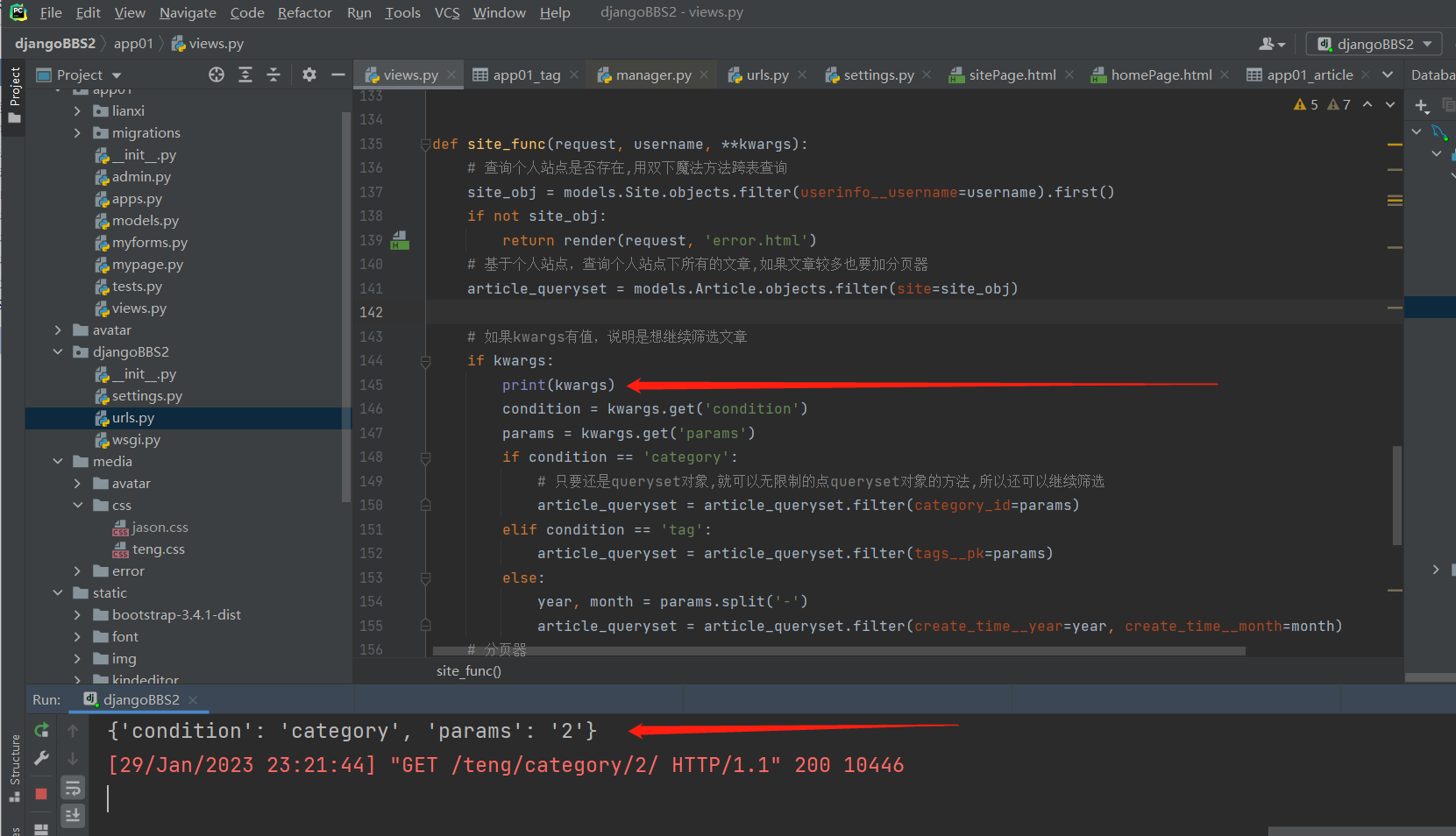
def site_func(request, username, **kwargs):
site_obj = models.Site.objects.filter(userinfo__username=username).first()
if not site_obj:
return render(request, 'error.html')
# 基于个人站点,查询个人站点下所有的文章
article_queryset = models.Article.objects.filter(site=site_obj)
if kwargs:
condition = kwargs.get('condition')
params = kwargs.get('params')
if condition == 'category':
article_queryset = article_queryset.filter(category_id=params)
elif condition == 'tag':
article_queryset = article_queryset.filter(tags__pk=params)
else: # 年-月
year, month = params.split('-')
# 神奇的双下划线查询自动按字段信息里面的年与月查询!!
article_queryset = article_queryset.filter(create_time__year=year, create_time__month=month)
# 查询个人站点下所有的分类名称以及每个分类下的文章数
category_queryset = models.Category.objects.filter(site=site_obj).annotate(article_num=Count('article__pk')).values(
'name', 'article_num', 'pk')
# 查询个人站点下所有的标签名称以及每个标签下的文章数
tag_queryset = models.Tag.objects.filter(site=site_obj).annotate(article_num=Count(
'article__pk')).values('name', 'article_num', 'pk')
# 查询个人站点下所有文章的产生日期,并按照年月分组并统计个数
from django.db.models.functions import TruncMonth
date_queryset = models.Article.objects.filter(site=site_obj).annotate(month=TruncMonth('create_time')).values(
'month').annotate(article_num=Count('pk')).values('month', 'article_num')
return render(request, 'sitePage.html', locals())
.
.
左边侧边栏搭建思路
我们模仿博客园的个人站点样式,想要实现一个效果
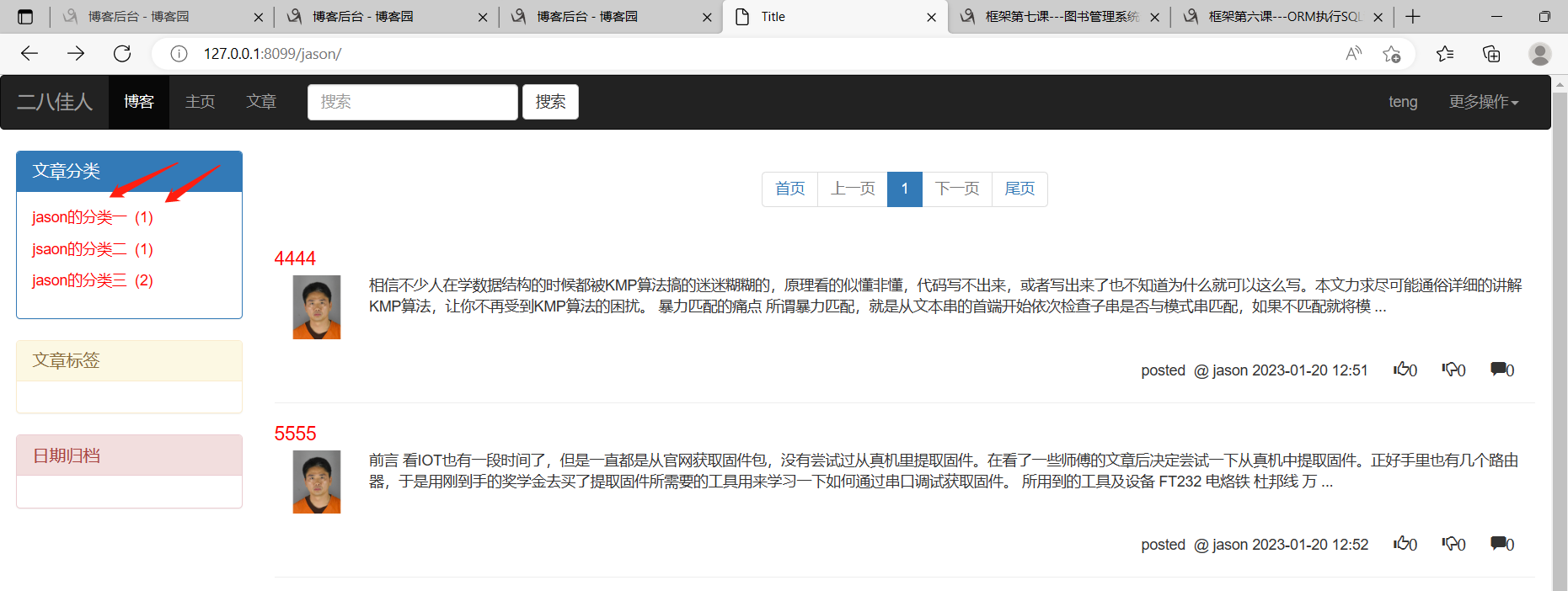
左边侧边栏分为(文章分类、文章标签、日期归档)为3个标签框
文章分类框里面展示:当前个人站点下所有的文章的分类名称以及每个分类下对应的文章数!!!
文章标签框里面展示:当前个人站点下所有的文章的标签名称以及每个标签下对应的文章数!!!
日期归档框里面展示:当前个人站点下所有的文章所属的年月以及每一个年月分类下对应的文章数!!!
--------------------------------------
文章分类框里面展示
怎么样在后端拿到当前该用户写的所有文章的分类名称,以及每个分类名称下对应的文章数
在后端利用ORM语句的分组查询以及分组查询配合使用聚合函数
对分类表进行分组,filter里面进行筛选出属于该站点对象的分类对象
然后再用分组查询与聚合函数用count,对反向表名小写拿到的文章表的主键值进行计数, 求出每一个分类下的文章数!!!
# 查询个人站点下所有文章的分类名称,以及每一个分类下的文章数
category_queryset = models.Category.objects.filter(site=site_obj).annotate(article_num=Count('article__pk')).values('name', 'article_num')
将category_queryset传到html页面,在左侧菜单栏展示出来即可
--------------------------------------
<div class="panel-body">
{% for category_obj in category_queryset %}
<p>
<a href="#">{{ category_obj.name }}({{ category_obj.article_num }})</a>
</p>
{% endfor %}
</div>
--------------------------------------
先给分类名称与对应的文章数整体套一个a标签,因为我们想要的结果是当点击该a标签后,展示的是该分类下对应的文章!! 暂时先用一个"#"顶一下跳转路由。
.
.
文章标签框里面展示
和上面的分类的ORM语句差不多
# 查询个人站点下所有的标签名称,以及每一个标签下的文章数
tag_queryset = models.Tag.objects.filter(site=site_obj).annotate(article_num=Count('article__pk')).values('name','article_num')
--------------------------------------
<div class="panel-body">
{% for tag_obj in tag_queryset %}
<p>
<a href="#">{{ tag_obj.name }}({{ tag_obj.article_num }})</a>
</p>
{% endfor %}
</div>
--------------------------------------
.
.
日期归档框里面展示
我们现在是想要对文章表里面的create_time字段进行分组,但是create_time里面的时间是年月日时分秒的形式,但是我们想要以年月来分组,原来的学的语法是实现不了的!!!
------------------------------------------
django官网提供了针对日期字段的切割处理
id content create_time month(这是我们想要的样子)
1 111 2020-11-11 2020-11
2 222 2020-11-12 2020-11
3 333 2021-10-13 2021-10
4 444 2021-11-14 2021-11
5 555 2021-12-15 2021-12
-------------------------------------------
django官网提供的一个orm语法
from django.db.models.functions import TruncMonth # 导入以月份为最小节选单位的模块
Sales.objects
.annotate(month=TruncMonth('timestamp'))
# Truncate to month and add to select list
# 将年月截选出来,添加到查询表里面去,相当于表里面又多了一个年月的字段出来了!!!
.values('month') # Group By month
.annotate(c=Count('id')) # Select the count of the grouping
.values('month', 'c')
# (might be redundant, haven't tested) select month and count
-------------------------------------------
时区问题报错
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = False
-------------------------------------------
-------------------------------------------
-------------------------------------------
后端代码
# 年月分组并统计文章个数
from django.db.models.functions import TruncMonth
date_queryset = models.Article.objects.filter(site=site_obj).annotate(month=TruncMonth('create_time')).values('month').annotate(article_num=Count('pk')).values('month', 'article_num')
--------------------------------------
前端代码
<div class="panel-body">
{% for date_obj in date_queryset %}
<p>
<a href="#">{{ date_obj.month|date:'Y年m月' }}({{ date_obj.article_num }})</a>
</p>
{% endfor %}
</div>
后端的年月字段还要用过滤器|date:'Y年m月' 转化一下
.
.
.
.
.
侧边栏筛选功能代码实现
1.先研究博客园三种情况下的筛选特性
分类筛选路由特性: 站点名称/category/数据主键值
标签筛选路由特性: 站点名称/tag/数据主键值
日期筛选路由特性: 站点名称/archive/文章年月
--------------------------------------------
2.研究路由开设接口
多个路由使用相同的视图函数, 因为个人站点的文章和侧边栏筛选的文章互为父子集
# 侧边栏筛选接口
path('<str:username>/category/<int:category_id>/', views.site_func),
path('<str:username>/tag/<int:tag_id>/', views.site_func),
path('<str:username>/archive/<str:yearAndmonth>/', views.site_func),
# 有点问题,当执行site_func函数的时候,实参不固定
# 当触发个人站点接口的时候,会传两个实参给site_func
# 当触发侧边栏筛选接口的时候,会传三个实参给site_func
# 而且还有一个问题,转化器都是将匹配到的内容以category_id=xxx或者tag_id=yyy关键字参数的形式传给视图函数
# 但是视图函数的括号里面的位置行参怎么写?不可能把category_id、tag_id都写进去的,位置行参写了就必须要传值!!不然就报错!!!
---------------------------------------------------------
# 上述三个路由可以合并成一个路由
re_path('^(?P<username>\w+)/(?P<condition>category|tag|archive)/(?P<params>.*?)/', views.site_func)
---------------------------------------------
但现在有点问题,视图函数的行参怎么兼容(侧边栏筛选接口与个人站点的接口)
site_func函数至少需要两个行参request与username,或者需要4个行参request与username与condition与params
可以在site_func函数的两个行参request与username后面加一个**kwargs **接收多余的关键字参数,组织成字典的形式赋值给** 号后面的变量名kwargs
在site_func函数里面通过判断kwargs是否有值,从而能够知道用户是想要访问某个人的个人站点,还是想在某个人的个人站点下继续筛选一些文章!!!
当路由是个人站点的时候kwargs为空字典,当路由是/teng/category/2/ 这种类型的时候
kwargs就变成了{'condition': 'category', 'params': '2'}
---------------------------------------------
只要还是queryset对象,就可以继续点queryset对象的方法,所以还可以继续筛选
# 如果kwargs有值,说明是想继续筛选文章
if kwargs:
print(kwargs)
condition = kwargs.get('condition')
params = kwargs.get('params')
if condition == 'category':
# 只要还是queryset对象,就可以无限制的点queryset对象的方法,所以还可以继续筛选
article_queryset = article_queryset.filter(category_id=params)
elif condition == 'tag':
article_queryset = article_queryset.filter(tags__pk=params)
else:
year, month = params.split('-')
article_queryset = article_queryset.filter(create_time__year=year, create_time__month=month)
---------------------------------------------
这个时候再来补上面的侧边栏a标签的跳转路由
{% for category_obj in category_queryset %}
<p>
<a href="/{{ username }}/category/{{ category_obj.pk }}/">{{ category_obj.name }} ({{ category_obj.article_num }})</a>
</p>
{% endfor %}
---------
{% for tag_obj in tag_queryset %}
<p>
<a href="/{{ username }}/tag/{{ tag_obj.pk }}/">{{ tag_obj.name }} ({{ tag_obj.article_num }})</a>
</p>
{% endfor %}
---------
{% for date_obj in date_queryset %}
<p>
<a href="/{{ site_obj.site_name }}/archive/{{ date_obj.month|date:'Y-m' }}/">{{ date_obj.month|date:'Y年m月' }} ({{ date_obj.article_num }})</a>
</p>
{% endfor %}
注意由于路由需要category_id与tag_id 所以后端还要再补一下,在原来的category_queryset与tag_queryset的ORM语句里面的values括号里面再加一个'pk'主键字段,这样前端就能用到了!!!
---------------------------------------------
个人站点下左边侧边栏筛选文章的功能的本质就是对个人站点下所有的文章再筛选一次!!!
---------------------------------------------
.
.
.
.
这个视图函数有点东西的,个人站点下展示所有该用户的文章,所以个人站点的前端用的category_queryset是后端
article_queryset = models.Article.objects.filter(site=site_obj)
得来的
但是当我们点击左边的分类栏标签时,比如我们点击文章分类的标签的时候,不管点的是哪一个文章分类的标签,都会触发对应的a标签,从而再次触发个人站点的视图函数的运行,
但是此时与一开始,从主页点击文章的姓名跳到个人站点展示该用户的所有文章不同了
因为现在不在展示个人所有文章了,而是要在个人所有文章的基础上再次筛选,得到只具有该分类的文章!!!
利用的就是先判断kwargs有没有值,从而先确定是要查个人站点的所有文章还是要继续筛选
在判断kwargs是否有值前,先得到个人站点对应的文章的对象article_queryset
如果kwargs没有值,不走if里面的子代码,正常返回文章的对象给前端
但是kwargs有值,走if里面的子代码,我们进行对文章的对象article_queryset再次筛选,并且筛选后的对象还是用变量名article_queryset接收
这样只要走了if的子代码,最后返给前端的article_queryset实际上已经是被再次筛选后的article_queryset了!!!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY