框架第五课---模板层之标签,自定义过滤器、标签及inclusion_tag(了解),模板的继承与导入,模型层之ORM常见关键字
昨日内容回顾
-
路由分发
总路由不再直接参与路由与视图函数/类的匹配关系 总路由 path('app01/',include('app01.urls')) 子路由 path('index/',views.index_func) -
名称空间
主要用于路由分发之后别名冲突反向解析无法准确的情况 总路由 namespace 反向解析 {% url 'app01:index_view' %} reverse('app01:index_view') 只要保证整个项目中别名不冲突就可以不使用名称空间 应用名作为别名前缀 -
虚拟环境
给不同的python项目提供准确的独一无二的开发环境 1.pycharm创建 2.命令行创建 python -m venv 解释器名称 激活、关闭(scripts) ps:requirements.txt -
视图层之三板斧
视图函数或者视图类中绑定方法(处理网络请求)最后都必须返回HttpResponse对象 from django.shortcuts import HttpResponse,render,redirect -
视图层之JsonResponse
from django.http import JsonResponse """ class JsonResponse: def __init__(self,data,json_dumps_params=None,safe=True): if json_dumps_params == None: json_dumps_params = {} json.dumps(data,**json_dumps_params) """ -
视图层之获取文件数据
form标签携带文件数据需要注意的两个地方 method改为post enctype改为multiple/form-data django后端获取数据 request.POST 普通数据 request.FILES 文件数据 -
视图层之FBV与CBV
FBV 基于函数的视图 path('index/',视图函数的函数名) def index_func(request):return HttpResponse() CBV 基于类的视图 path('func/',视图类名.as_view()) from django import views class MyFuncView(views.View): def get(self,request): return HttpResponse() def post(self,request): return HttpResponse() CBV会根据不同的请求方法自动匹配类中定义的方法并执行 -
CBV源码剖析
1.CBV路由匹配 path('func/',视图类名.as_view()) class View: @classonlymethod def as_view(cls): def view(): pass return view path('func/',view) # 本质还是FBV的匹配方式 2.路由一旦匹配到了func就会自动触发view函数的执行 def view(): obj = cls() return obj.dispatch() 3.执行dispatch方法(可以拦截并扩展) def dispatch(): handler = getattr(obj,request.method.lower()) return handler() -
模板层之模板传值
render(request,'login.html',{'name':'jason','age':18}) render(request,'login.html',locals()) -
模板层之传值特性
1.python基本数据类型及文件名、对象名都可以传递 2.函数名和类名会自动加括号调用(不支持传参) -
模板层之过滤器
|add |length |slice |date |truncatewords |truncatechars |filesizeformat |safe
今日内容概要
- 模板层之标签
- 自定义过滤器、标签及inclusion_tag(了解)
- 模板的继承与导入
- 模型层之ORM常见关键字
- 模型层之外键字段
- 模型层之外键字段数据增删改查
今日内容详细
模板层之标签
if语法使用
{% if 条件1(可以自己写也可以用传递过来的数据) %}
<p>今天又是周三了</p>
{% elif 条件2(可以自己写也可以用传递过来的数据) %}
<p>百日冲刺</p>
{% else %}
<p>没多少时间了!</p>
{% endif %}
-----------------------------------------------
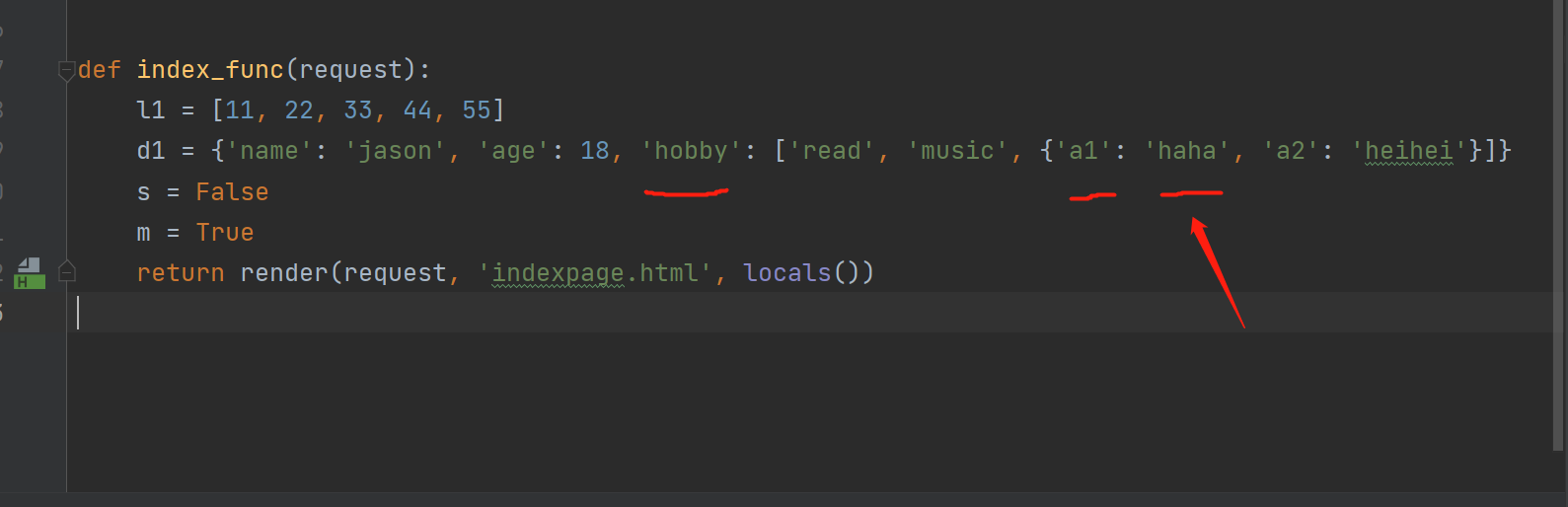
def index_func(request):
l1 = [11, 22, 33, 44, 55]
d1 = {'name': 'jason', 'age': 18}
s = False
m = True
return render(request, 'indexpage.html', locals())
<body>
{% if s %}
<p>今天又是周三了!!</p>
{% elif m %}
<p>百日冲刺</p>
{% else %}
<p>没多少时间了!!</p>
{% endif %}
</body>
---------------
.
.
for循环语法使用
-------------------------------------
{% for k in d1 %}
<p>{{ k }}</p>
{% endfor %}
for 循环字典 只能拿到字典的键!
-------------------------------------
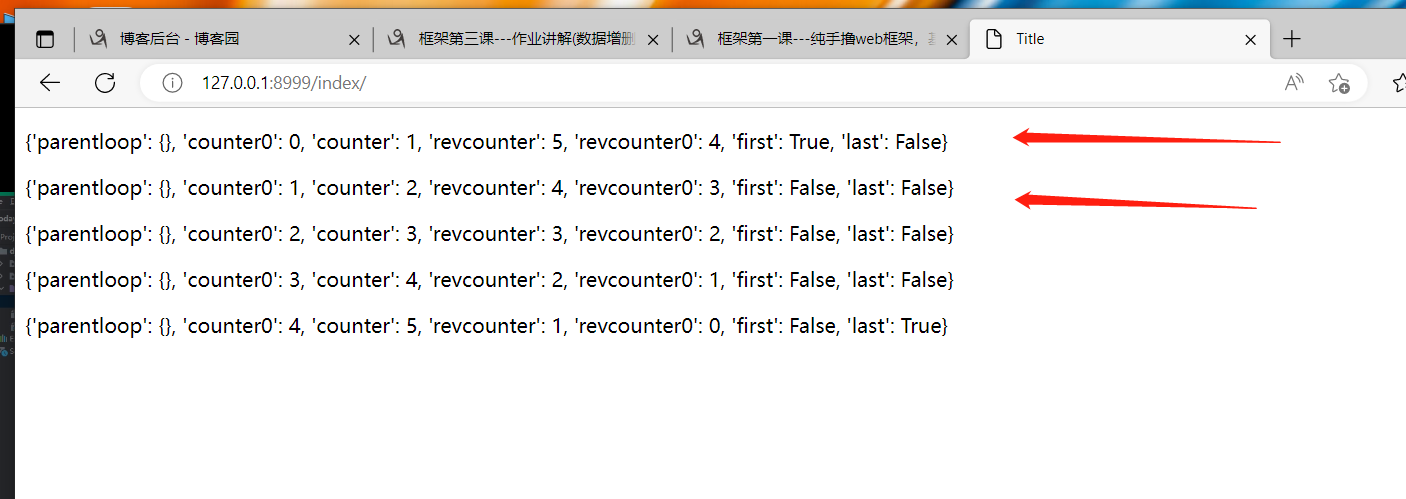
{% for k in l1 %}
<p>{{ forloop }}</p>
{% endfor %}
forloop关键字能将for循环出的每一个数据弄成一个大字典
可以通过对判断forloop对象里面的first的值与last值,确定循环的开始与结束,从而可以在for循环开始前与结束后做一些事!!!
-------------------------------------
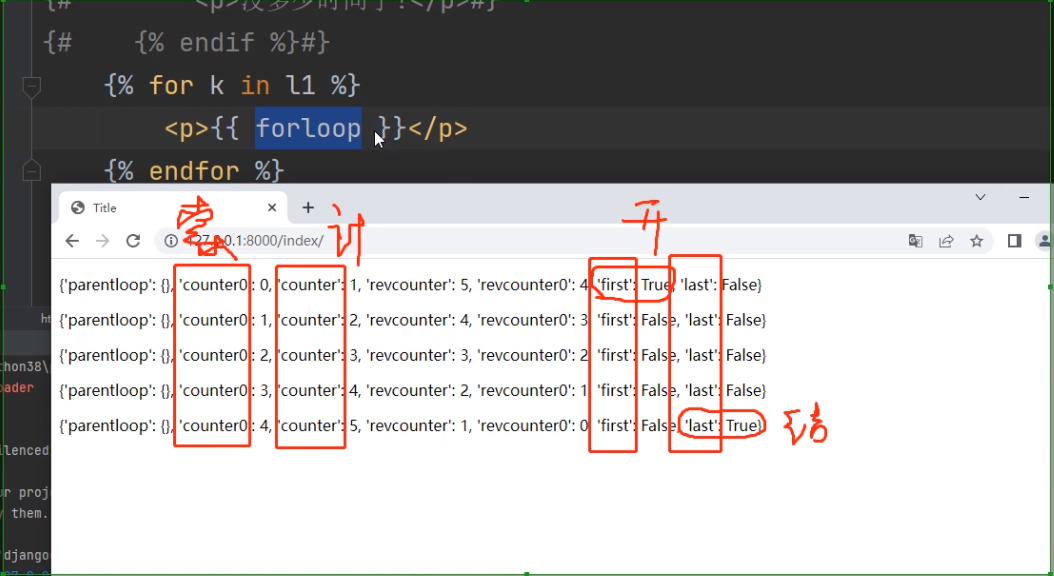
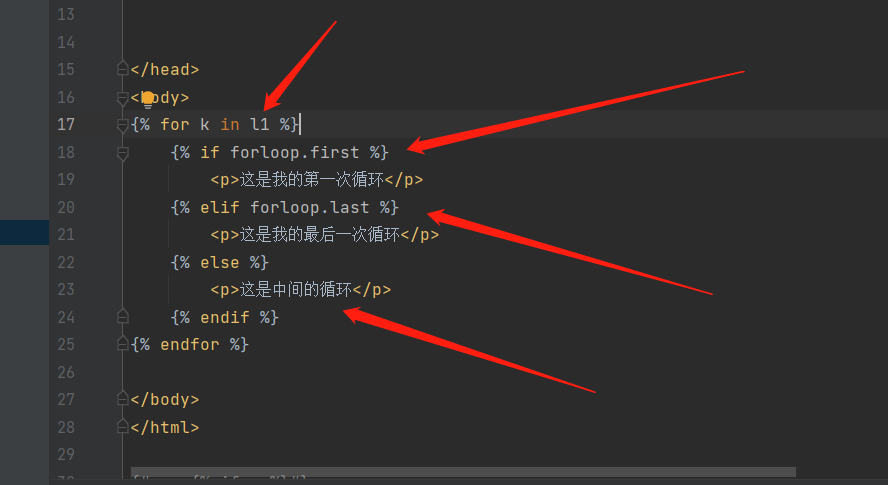
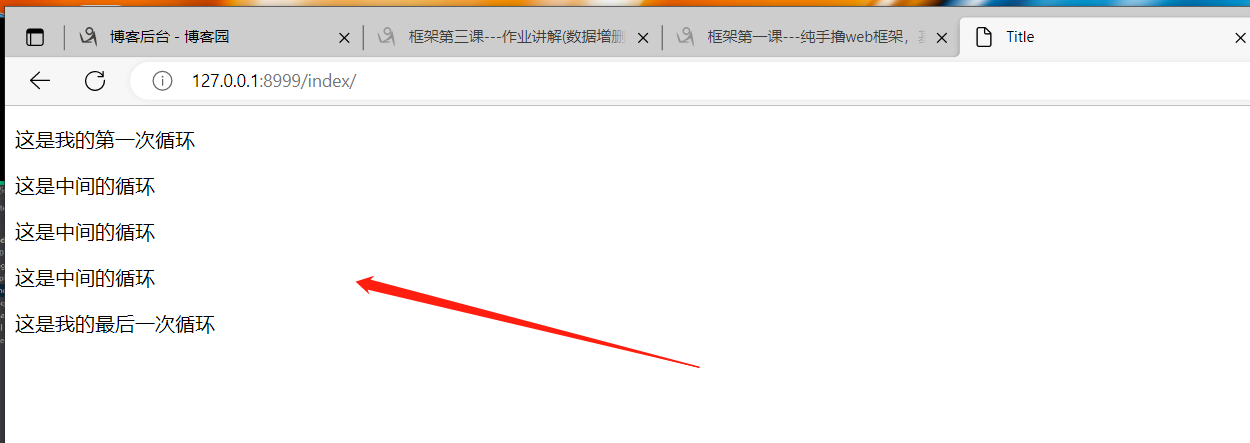
{% for k in l1 %}
{% if forloop.first %}
<p>这是我的第一次循环{{ k }}</p>
{% elif forloop.last %}
<p>这是我的最后一次循环{{ k }}</p>
{% else %}
<p>这是中间循环{{ k }}</p>
{% endif %}
{% empty %}
<p>你给我传的数据是空的无法循环取值(空字符串、空列表、空字典)就走empty下面的代码!!</p>
{% endfor %}
-----------------------------------------------
for 循环字典 只能拿到字典的键!
.
forloop关键字能将for循环出的每一个数据弄成一个大字典
.
.
.
django模板语法取值操作
django模板语法取值操作>>>:只支持句点符
-----------------------------------
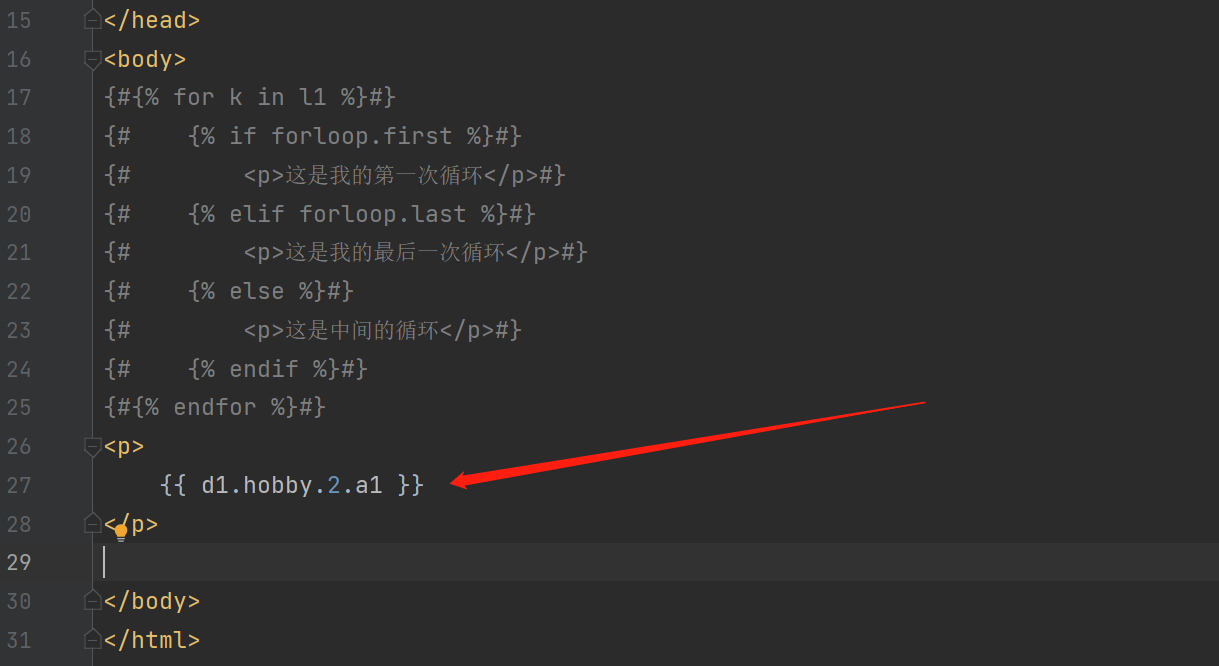
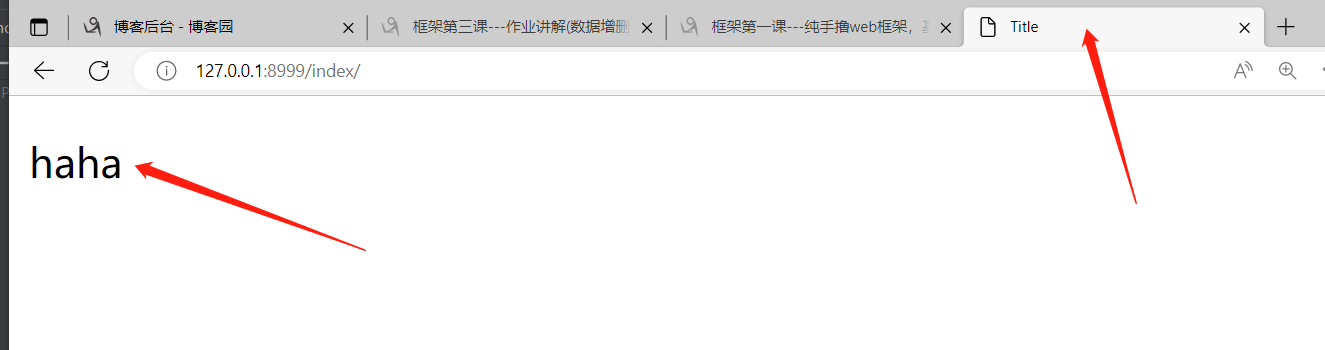
1. 句点符既可以点索引也可以点键
<p>
{{ d1.hobby.2.a1 }}
</p>
-----------------------------------
2.数据可以起别名:
<p>
{% with d1.hobby.2.a1 as h %}
<a href="">{{ h }}</a>
{% endwith %}
</p>
# 该别名仅限于在with的这个语法里使用!!出去就用不了了!!!
# 复杂操作获取到的数据,之后需要反复使用可以起别名!!这样后面就可以用别名了!
句点符既可以点索引也可以点键!!!
.
.
.
.
自定义过滤器、标签、及inclusion_tag(了解)
tag 是标签!
如果想要自定义一些模板语法 需要先完成下列的三步走战略
1.在应用下创建一个名字必须叫templatetags的目录!!!
2.在上述目录下创建任意名称的py文件,比如mytags.py
3.在上述py文件内先编写两行固定的代码:
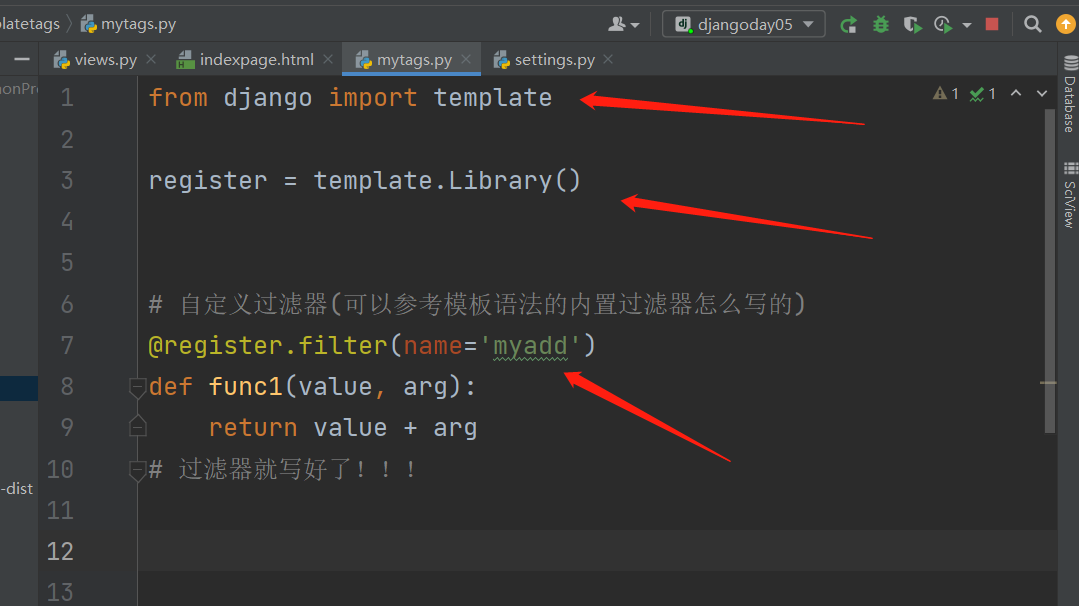
from django import template
register = template.Library()
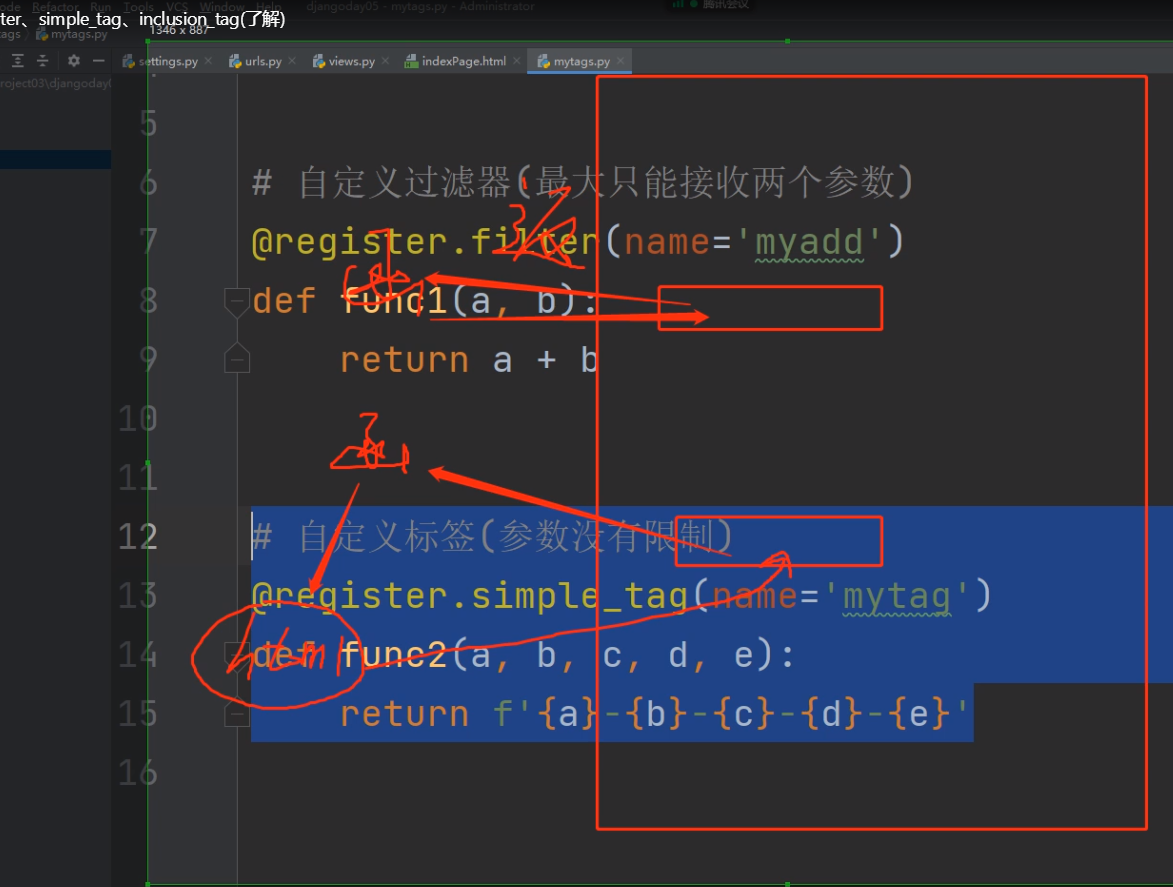
1. 自定义过滤器
# 自定义过滤器(固定的 最大只能接收两个参数)
# value是竖杠左边的值 arg是竖杠右边的值
from django import template
register = template.Library()
views.py里代码:
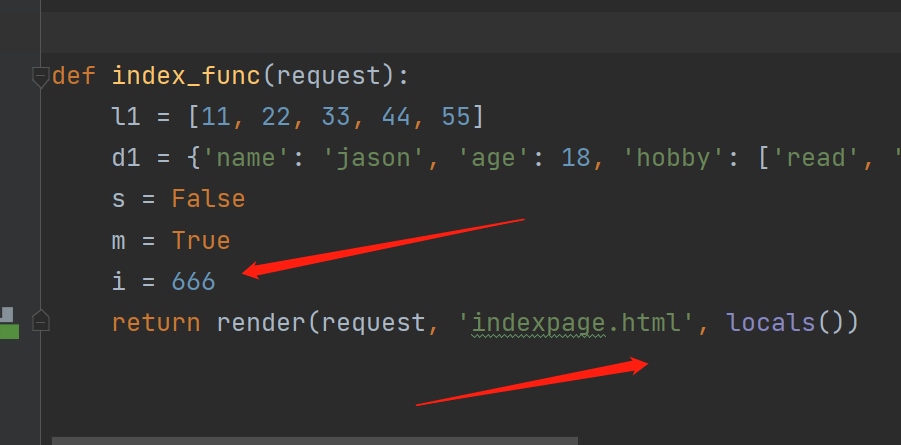
def index_func(request):
i = 666
return render(request, 'indexpage.html', locals())
----------------------
mytags.py里代码:
@register.filter(name='myadd')
def func1(value, arg):
return value + arg
-------------------------
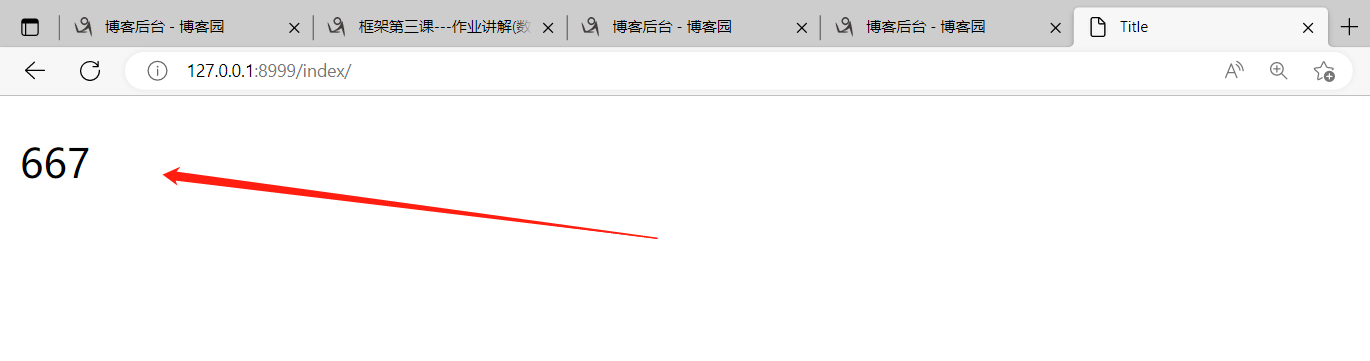
html文件里代码:
{% load mytags %} # 这个相当于在导模块文件!!!
<p>{{ i|myadd:1 }}</p>
-----------------------
最后页面的结果就是667
----------------------------------------
.
.
2. 自定义标签
# 自定义标签(有点像自定义函数,行参可以有多个!比过滤器好用点)
from django import template
register = template.Library()
@register.simple_tag(name='mytag888')
def func2(a, b, c, d, e):
return f'{a}-{b}-{c}-{d}-{e}'
----------------------
{% load mytags %} # 导mytags.py模块文件!!!
{% mytag888 'jason' 'kevin' 'oscar' 'tony' 'lili' %}
-----------------------
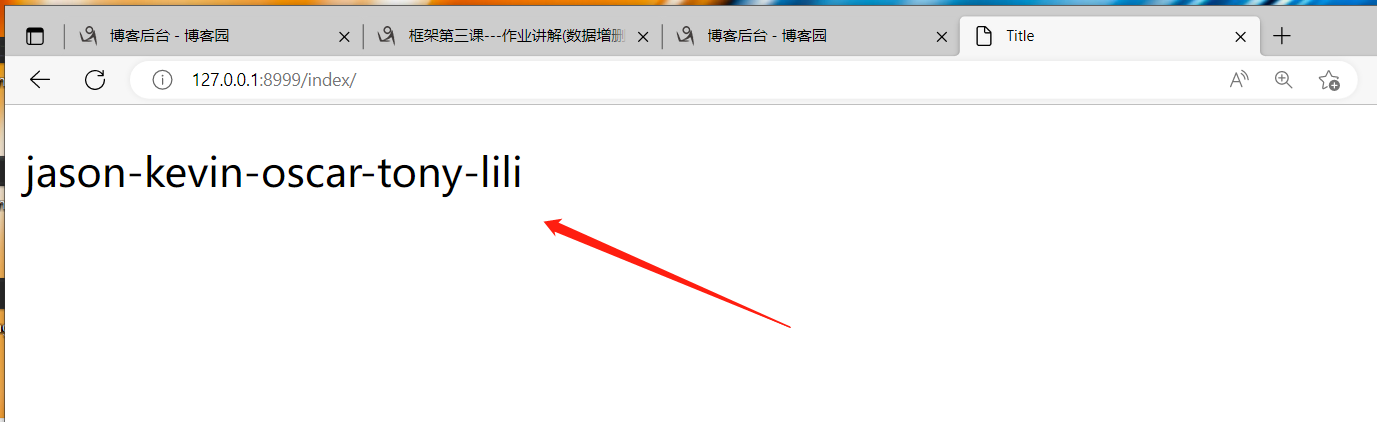
.
.
.
自定义过滤器与自定义标签特点:都是在html页面上通过特殊的语法调用我们自己写的py文件里面对应的自定义函数,然后把函数的返回值放到html文件中调用自定义过滤器或自定义标签的位置
.
自定义inclusion_tag特点:还是在html页面上通过特殊的语法调用我们自己写的py文件里面对应的自定义函数,但是该函数的返回值,传给另一个html页面(该页面不能是一个完整的页面,只能是一个局部的小页面)并渲染好后,然后把该页面放到调用inclusion_tag的位置!!
.
3. 自定义inclusion_tag(了解)
# 自定义inclusion_tag(局部的html代码)
mytags_py里面代码:
from django import template
register = template.Library()
@register.inclusion_tag('menu.html',name='mymenu')
def func3(n):
html = []
for i in range(n):
html.append('<li>第%s页</li>'%i)
return locals()
主html页面
{% load mytags %}
{% mymenu 10 %} # 触发自己写的maytags.py文件里面mymenu对应的函数
# 触发自己写的maytags.py文件里面mymenu别名对应的函数,并将参数10传给函数!!
# 函数的运行又会将数据传给局部的html页面渲染,被渲染的数据最后又传给主html页面的调用inclusion_tag的位置!!!
.
.
.
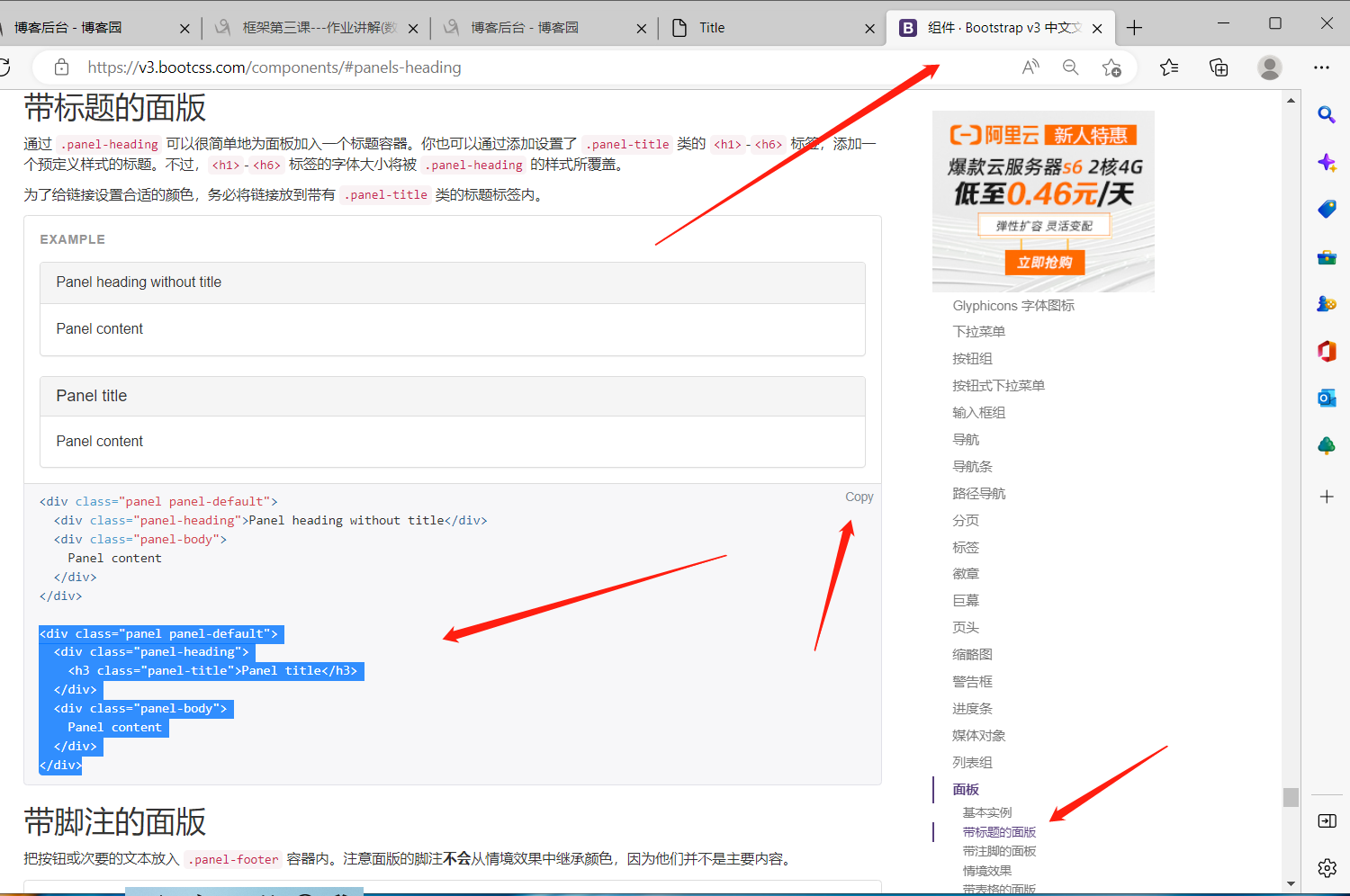
模板的继承与导入 重点!!!
母板的继承(重要)
多个页面有很多相似的地方,可以采取下列方式:
方式1:传统的复制粘贴
----------------------------------------------
方式2:母板的继承:
1.在母板中提前使用block划定子板以后可以修改的区域
{% block 区域起个名称 %}
子模版可以修改的代码
{% endblock %}
2.子板继承模板(子模版要首先把系统自带的代码全部删掉)
{% extends 'home.html' %} # 完全继承模板的代码
{% block 模板申明的可改区域名称 %}
子板自己的内容
{% endblock %}
----------------------------------------------
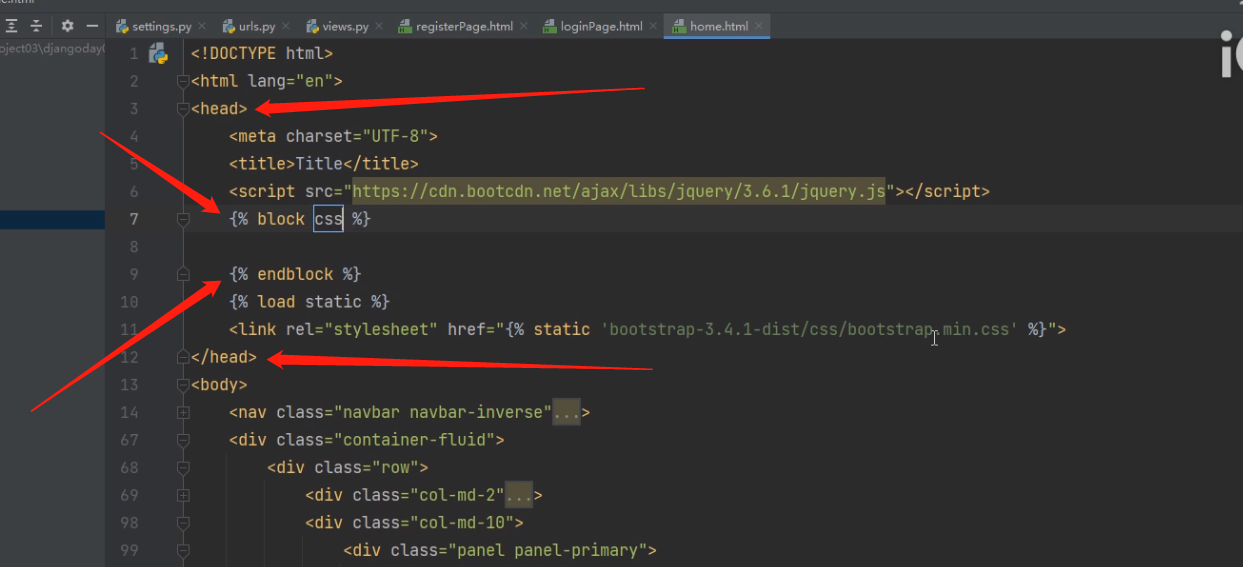
母板中至少应该用block划定三个区域:页面内容区、css样式区、js代码区
母板中应该预留出给子版编写页面的区域,也应该预留出可以给子板编写css代码与js代码的区域
---------------------------------------------
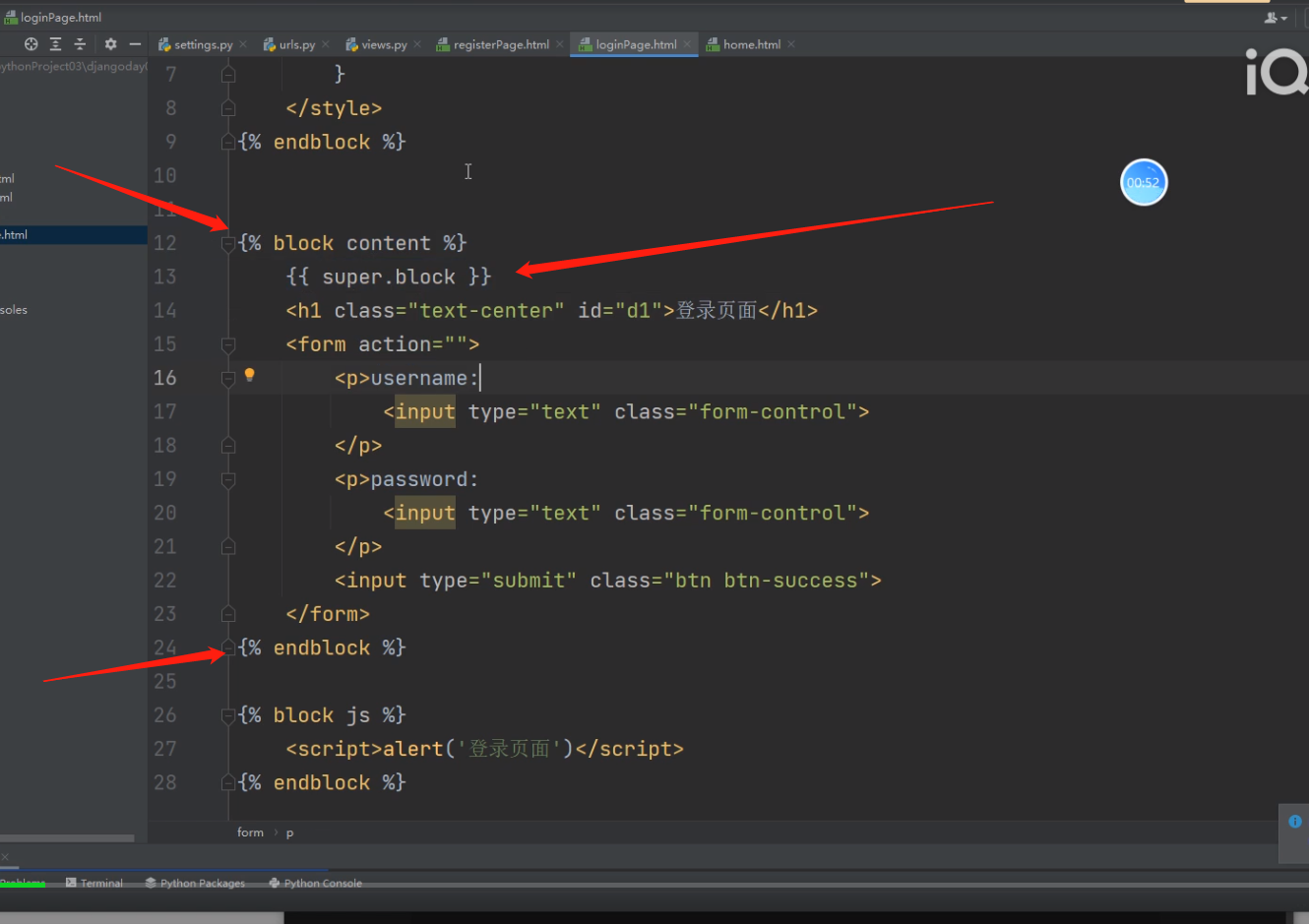
补充:子板也可以继续使用模板的内容
{{ block.super }}
----------------------------------------------
模板的导入(了解)
将某个html的部分提前写好 之后很多html页面都想使用就可以导入
{% include 'myform.html' %}
导航条代码的复制
.
左边区域代码的复制
.
.
.
页头
.
.
母板中应该预留出给子版编写页面的区域,也应该预留出可以给子板编写css代码与js代码的区域

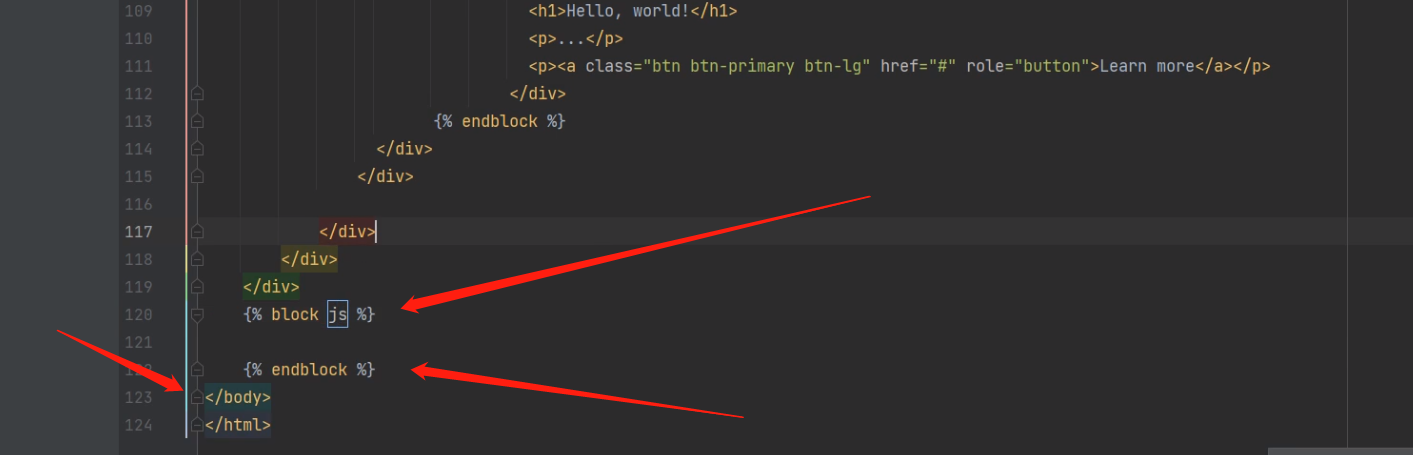
.
子板也可以继续使用模板的内容 {{ block.super }}
.
把一个一段html页面(不能是是一个完整的html页面)的代码导入到另一个html页面上去
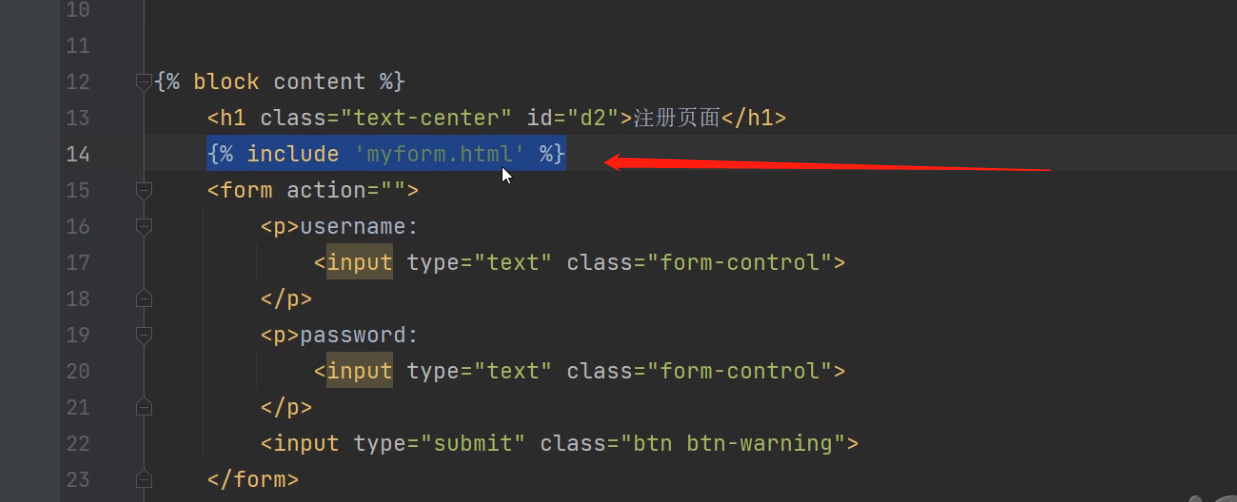
.
.
.
.
模型层之前期准备 重要!!!
from django.db import models
# Create your models here.
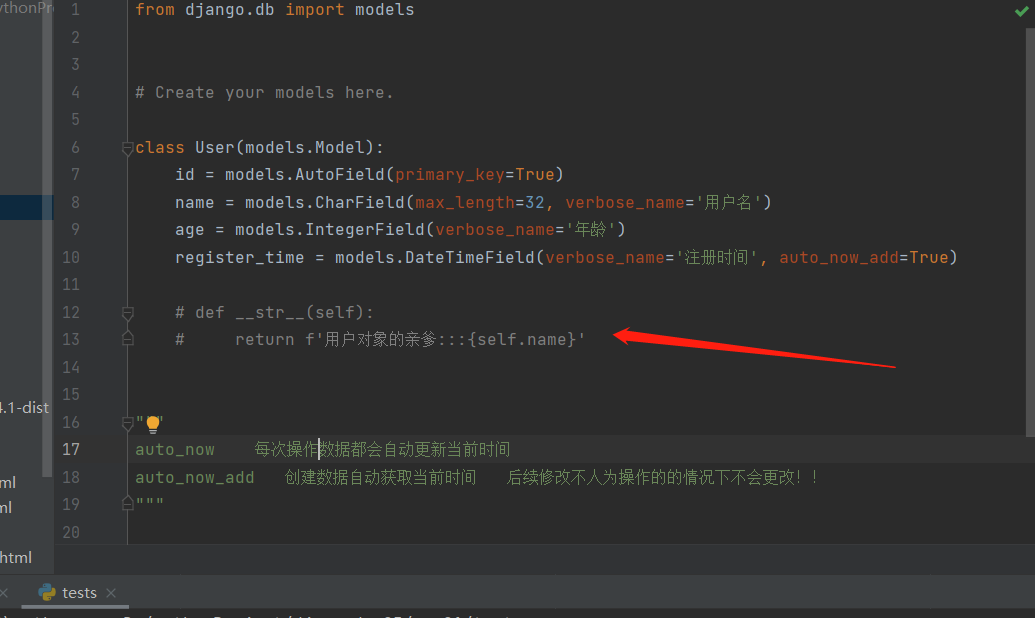
class User(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32, verbose_name='用户名')
age = models.IntegerField(verbose_name='年龄')
register_time = models.DateTimeField(verbose_name='注册时间', auto_now_add=True)
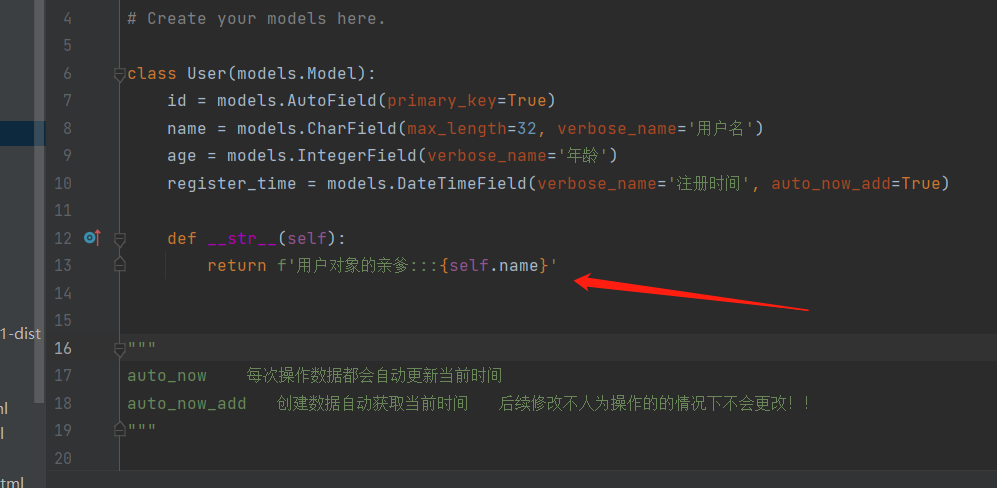
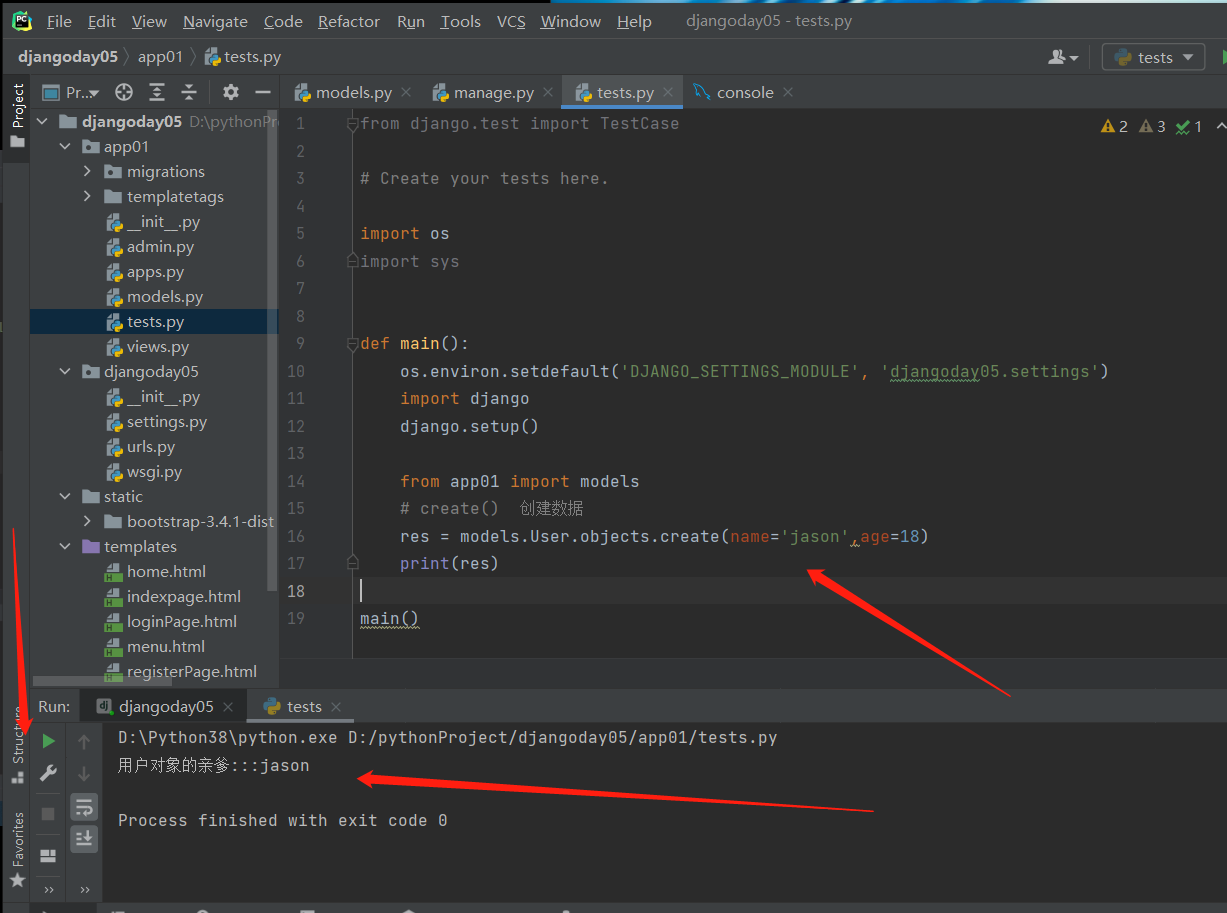
def __str__(self):
return f'用户对象的亲爹{self.name}'
"""
auto_now 每次操作数据都会自动更新当前时间
auto_now_add 创建数据自动获取当前时间, 后续修改不人为操作的的情况下不会更改!!
"""
.
1.自带的sqlite3数据库对时间字段不敏感,有时候会展示错乱!!!
所以我们习惯切换成常见的数据库比如MySQL
django orm并不会自动帮你创建库,所以需要提前准备好!!!
-------------------------------------------------
2.单独测试django某个功能层
默认不允许单独测试某个py文件,必须先建路由对应关系,然后在视图函数里面才能执行ORM语句
如果想要测试某个单独的ORM语句怎么办?
--------------------------------
测试环境1:pycharm提供的python console
但有个不好,代码写完没法保存!!
----------
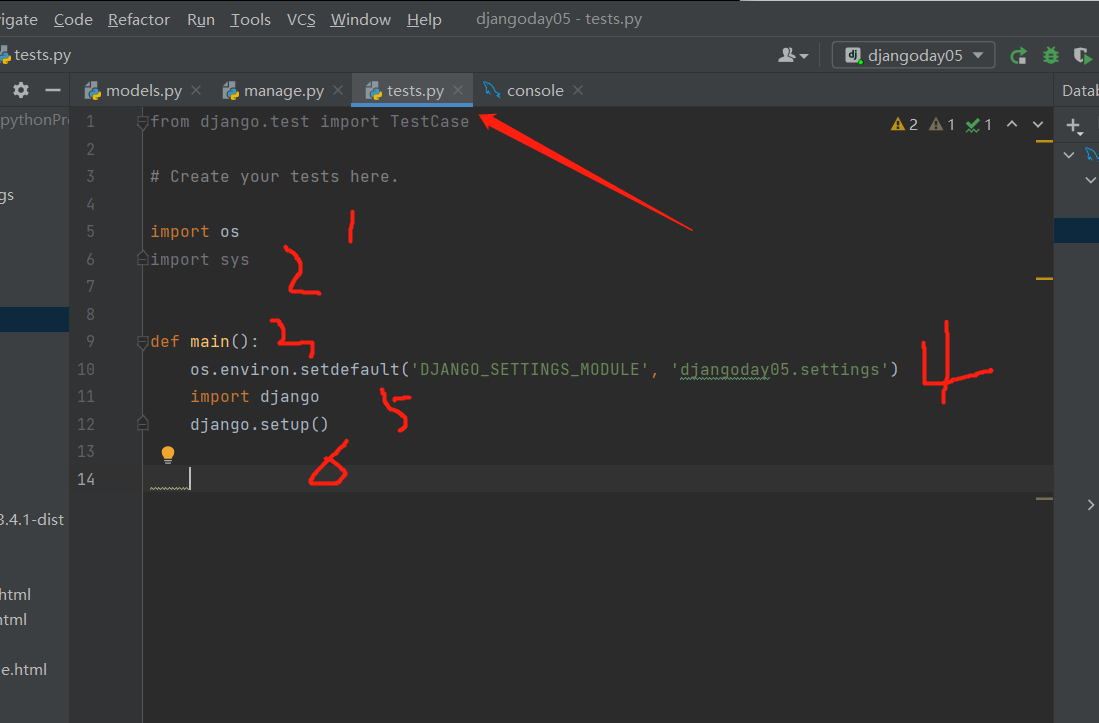
测试环境2:自己搭建(自带的test或者自己创建)
1.拷贝manage.py前四行
2.自己再加两行
import django
django.setup()
-----------------------------------------------
-----------------------------------------------
测试环境的搭建,所有代码都走完后,才能去导入模型层
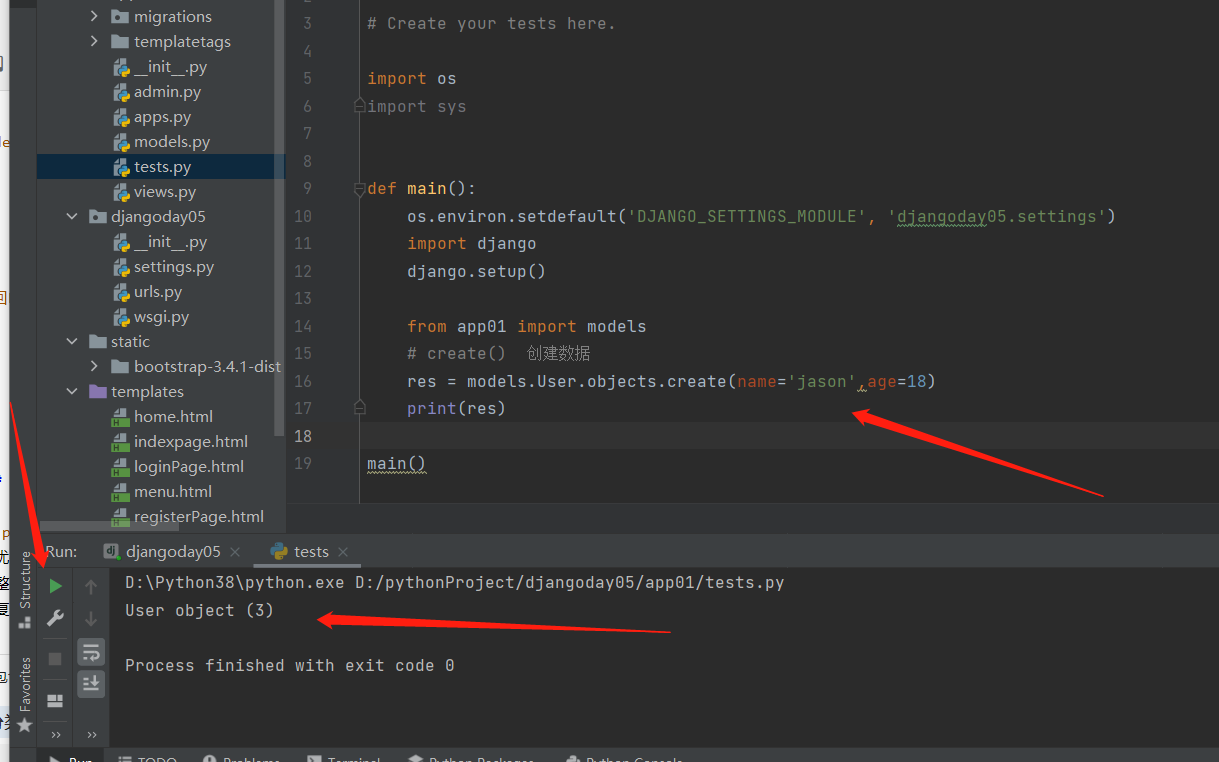
.
.
可以看出,不给类加个双下str的方法,打印的就是 User object ()
加了双下str的方法后,打印的就是str的方法的返回值,返回值里面我们有点了对象的名字,所以最后根据名字就能看出来这个对象是哪一个对象了!!
.
.
.
.
.
ORM常用关键字
---------------------------------------
ORM底层还是sql语句!!!
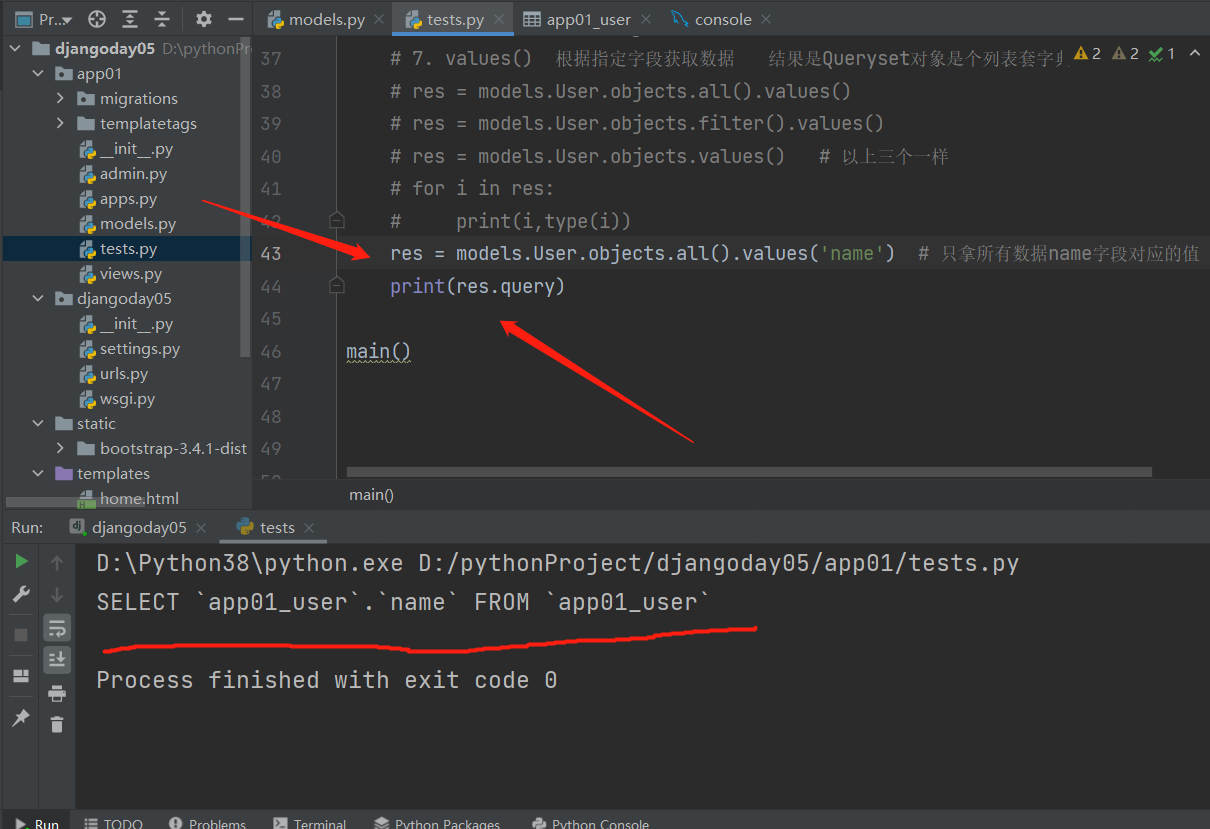
django orm底层还是SQL语句 我们是可以查看的
如果我们手上是一个QuerySet对象 那么可以直接点query查看SQL语句
---------------------------------------
如果想查看所有orm底层的SQL语句也可以在配置文件添加日志记录
这个东西实际上就是日志模块!!!
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
.
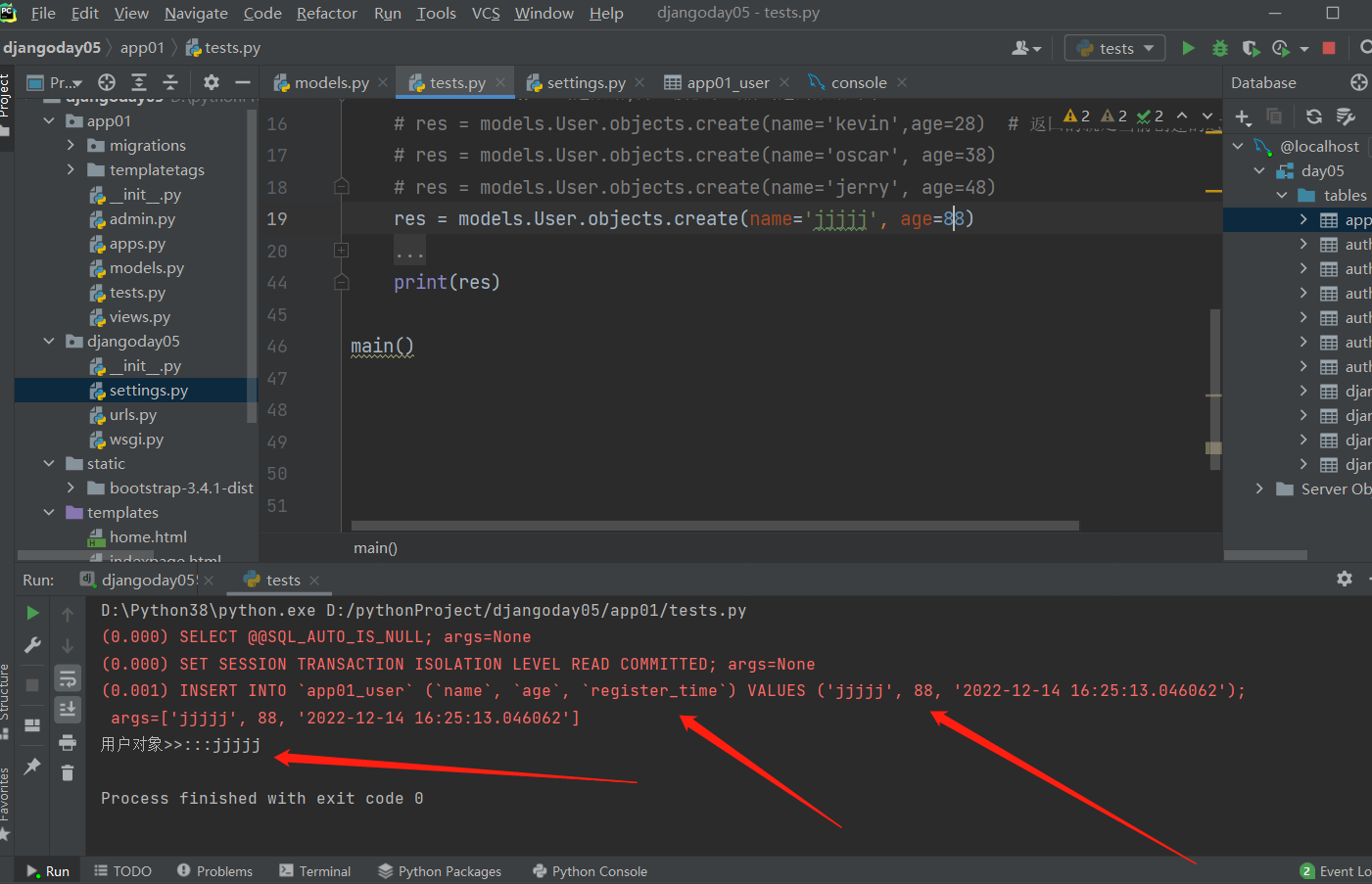
# 1.create() 创建数据并直接获取当前创建的数据对象
# res = models.User.objects.create(name='阿兵', age=28)
# res = models.User.objects.create(name='oscar', age=18)
# res = models.User.objects.create(name='jerry', age=38)
# res = models.User.objects.create(name='jack', age=88)
# print(res)
------------------------------------
# 2.filter() 根据条件筛选数据 结果是QuerySet [数据对象1,数据对象2]
# res = models.User.objects.filter()
# res = models.User.objects.filter(name='jason')
# res = models.User.objects.filter(name='jason', age=19)
# 括号内支持多个条件但是默认是and关系
------------------------------------
# 3.first() last() QuerySet支持索引取值但是只支持正数 并且orm不建议你使用索引
# res = models.User.objects.filter()[1]
# res = models.User.objects.filter(pk=100)[0] # 数据不存在索引取值会报错
# res = models.User.objects.filter(pk=100).first() # 数据不存在不会报错而是返回None
# res = models.User.objects.filter().last() # 数据不存在不会报错而是返回None
------------------------------------
# 4.update() 更新数据(批量更新)
# models.User.objects.filter().update() 批量更新
# models.User.objects.filter(id=1).update() 单个更新
------------------------------------
# 5.delete() 删除数据(批量删除)
# models.User.objects.filter().delete() 批量删除
# models.User.objects.filter(id=1).delete() 单个删除
------------------------------------
# 6.all() 查询所有数据 结果是QuerySet [数据对象1,数据对象2]
# res = models.User.objects.all()
------------------------------------
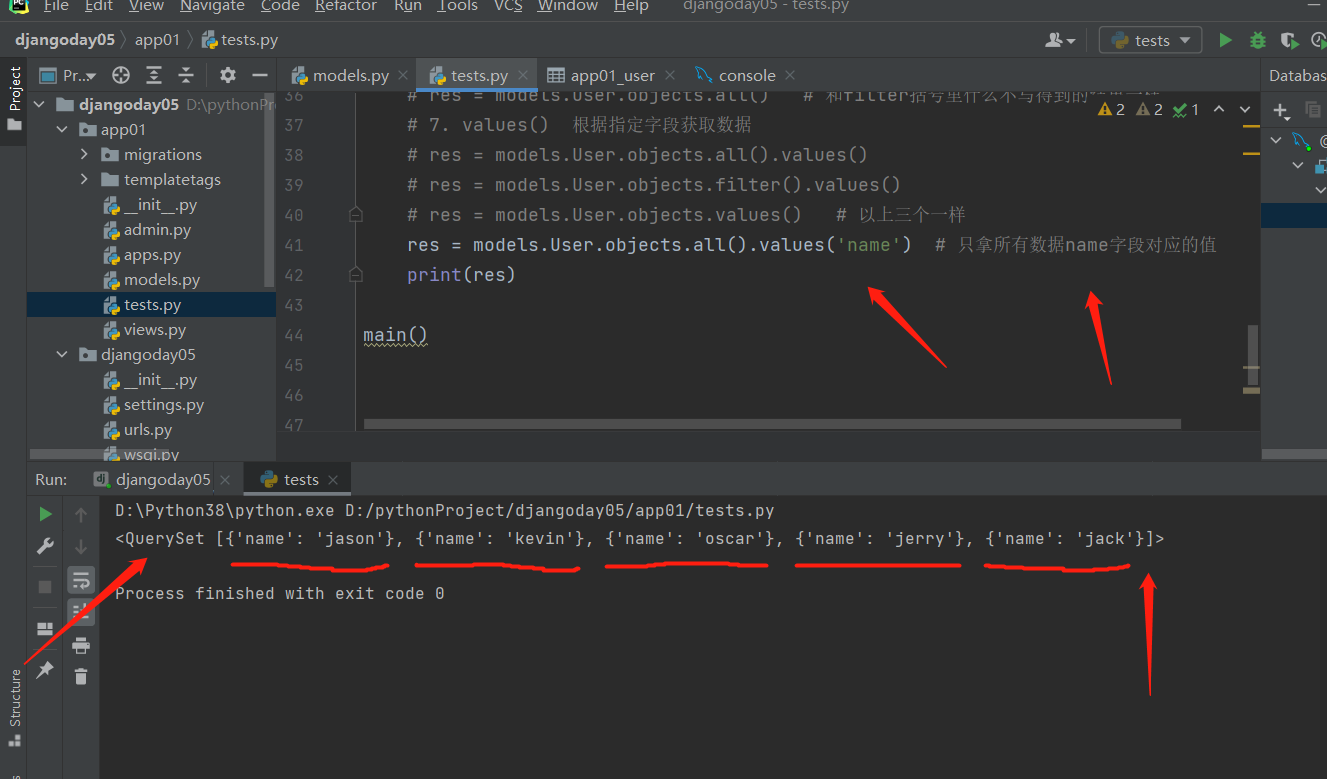
# 7.values() 根据指定字段获取数据 结果是QuerySet [{},{},{},{}]
# res = models.User.objects.all().values('name')
# res = models.User.objects.filter().values()
# res = models.User.objects.values()
------------------------------------
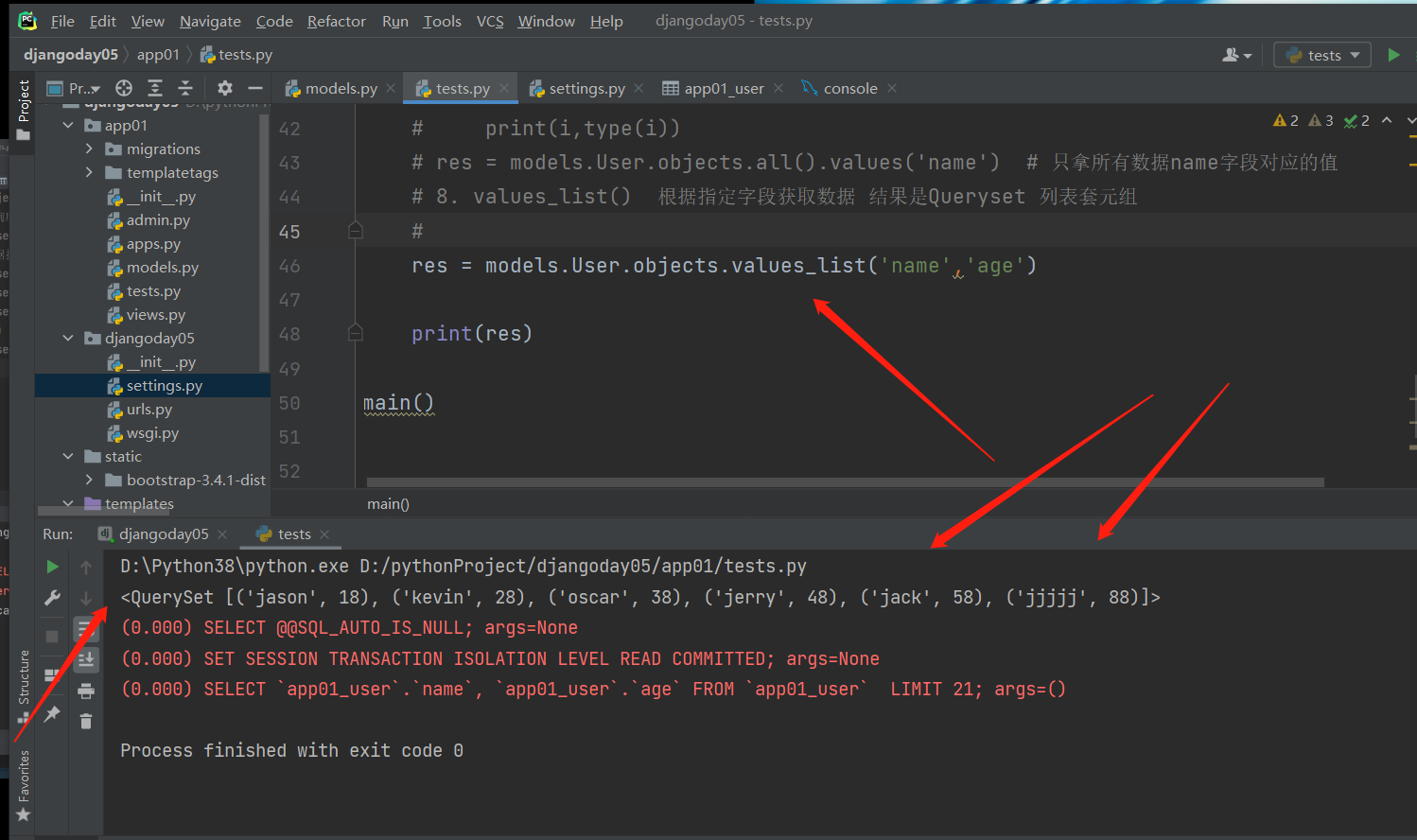
# 8.values_list() 根据指定字段获取数据 结果是QuerySet [(),(),(),()]
# res = models.User.objects.all().values_list('name','age')
------------------------------------
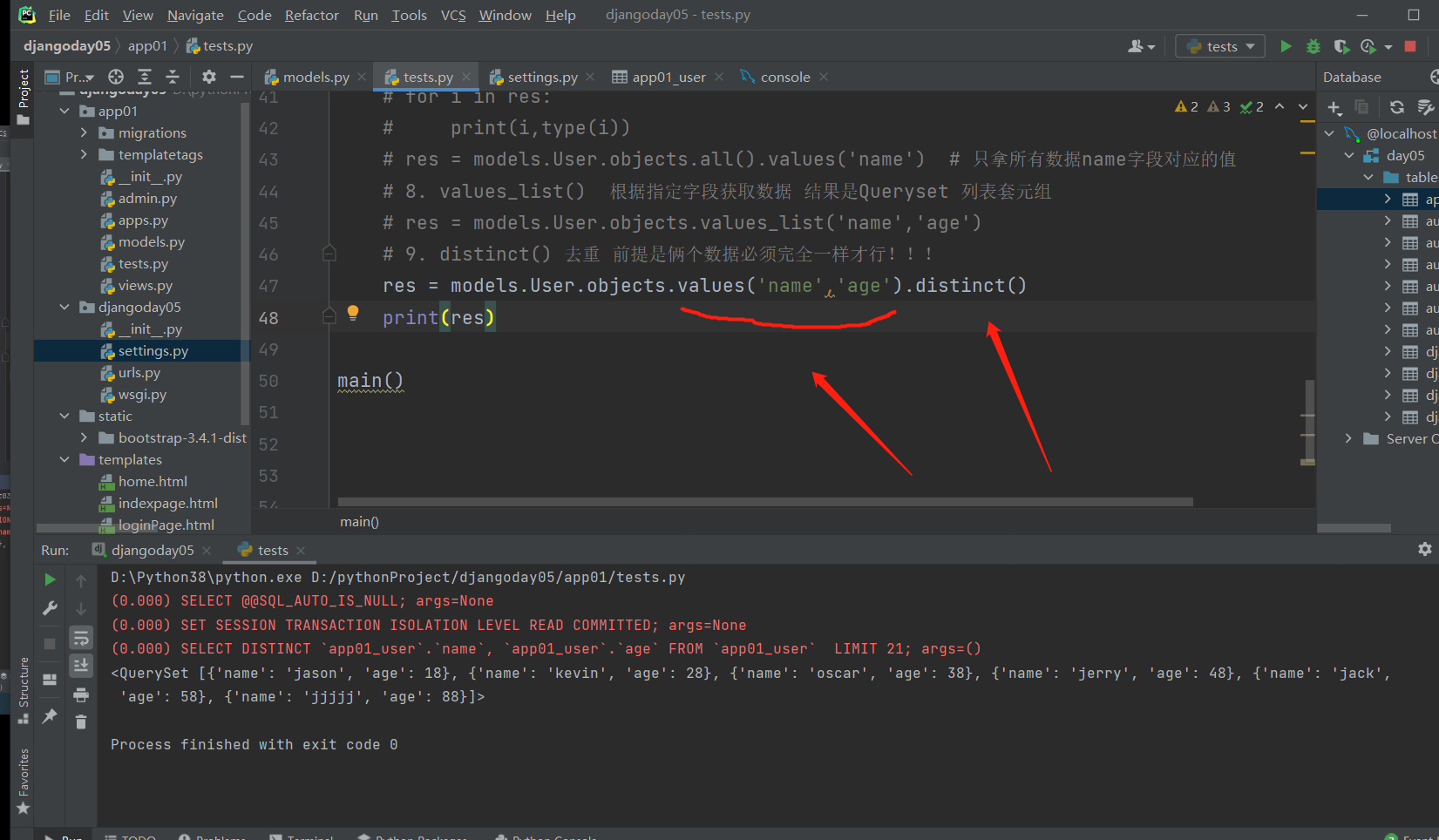
# 9.distinct() 去重 数据一定要一模一样才可以 如果有主键肯定不行
# res = models.User.objects.values('name','age').distinct()
------------------------------------
# 10.order_by() 根据指定条件排序 默认是升序 字段前面加负号就是降序
# res = models.User.objects.all().order_by('age')
# print(res)
------------------------------------
11.get() 根据条件筛选数据并直接获取到数据对象!!
一旦条件不存在会直接报错 不建议使用!!!
res = models.User.objects.get(pk=1)
print(res) # 直接获取到数据对象
res = models.User.objects.get(pk=100, name='jason')
print(res) # 报错!!
------------------------------------
12.exclude()
# 它包含了与所给筛选条件不匹配的对象,相当于filter的取反操作
res = models.User.objects.exclude(pk=1)
print(res) # pk不等于1的所有对象
------------------------------------
# 13.reverse() 颠倒顺序(被操作的对象必须是已经排过序的才可以)
# res = models.User.objects.all()
# res = models.User.objects.all().order_by('age')
# res1 = models.User.objects.all().order_by('age').reverse()
# print(res, res1)
------------------------------------
14.count() # 统计QuerySet结果集中的对象数量!!!
res = models.User.objects.all().count()
print(res)
------------------------------------
15.exists()
# 判断结果集中是否含有数据 如果有则返回True 没有则返回False
res = models.User.objects.all().exists()
print(res)
res1 = models.User.objects.filter(pk=100).exists()
print(res1)
------------------------------------
Queryset对象有很多种类型!!!
.
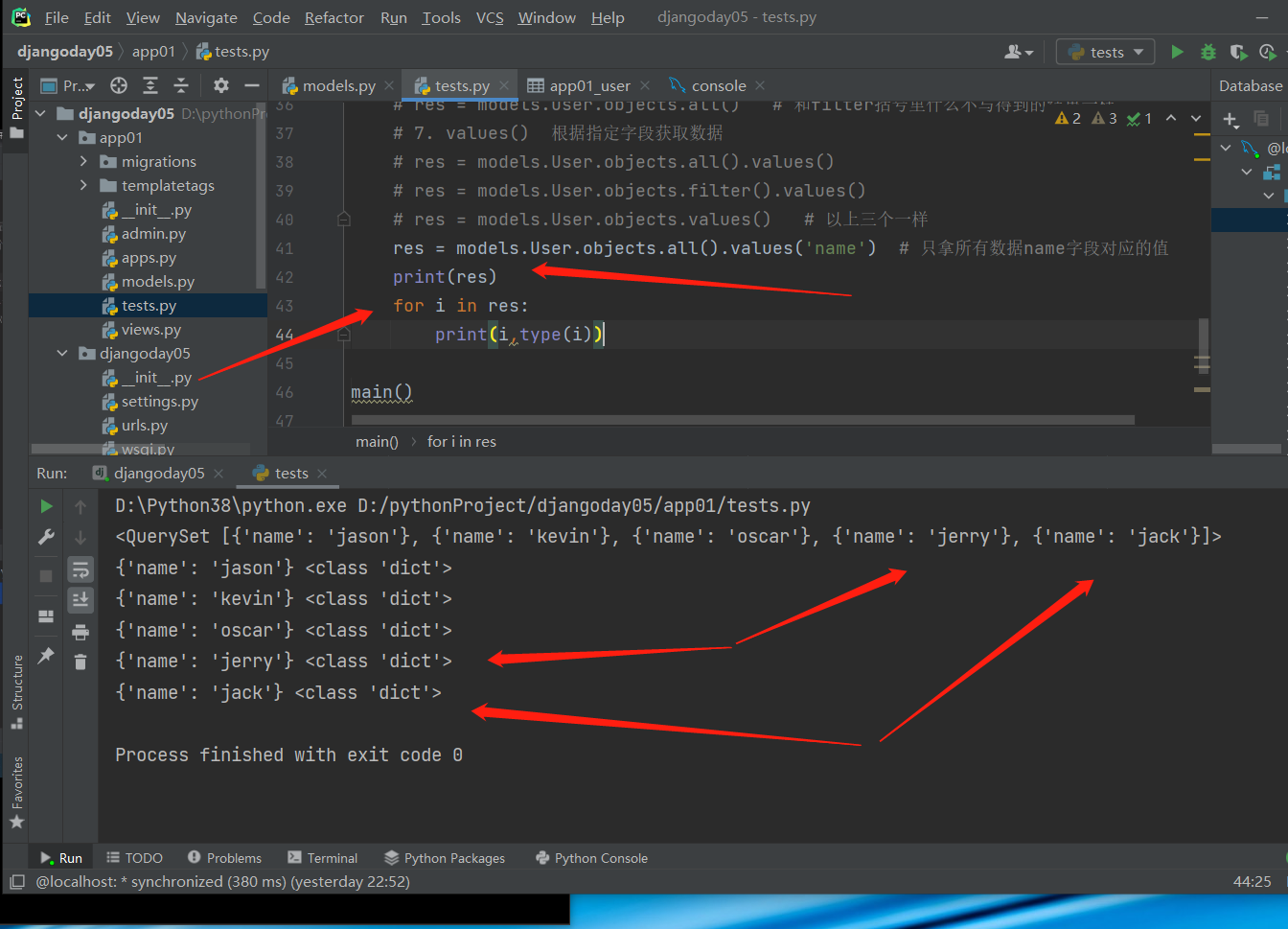
res = models.User.objects.all().values('name')
拿到的还是Queryset对象是个列表套字典,支持for循环!!!
.
.
如果我们手上是一个QuerySet对象 那么可以直接点query查看SQL语句
.
.
通用方法,配置文件加一个日志模块,只要运行ORM语句日志器就会打印对应的sql语句!!
.
.
res = models.User.objects.all().values('name')
根据指定字段获取数据 结果是QuerySet [(),(),(),()]
.
.
去重操作尽量先选好字段名,不要带主键字段,因为主键是非空且唯一的,那么就无法去重了!!!
res = models.User.objects.values('name','age').distinct()
.
.
.
.
作业
1.优化用户增删改查功能页面 使用上模板的继承等操作
2.整理今日内容及博客
3.复习MySQL相关查询语句


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY