框架第一课---纯手撸web框架,基于wsgiref模块,代码封装优化,动静态网页,jinja2模板语法,django框架简介,django基本操作命令,django小白必会三板斧
今日内容概要
- 纯手撸web框架
- 基于wsgiref模块
- 代码封装优化
- 动静态网页
- jinja2模板语法
- python主流web框架
- django框架简介
- django基本操作命令
- django小白必会三板斧
今日内容概要
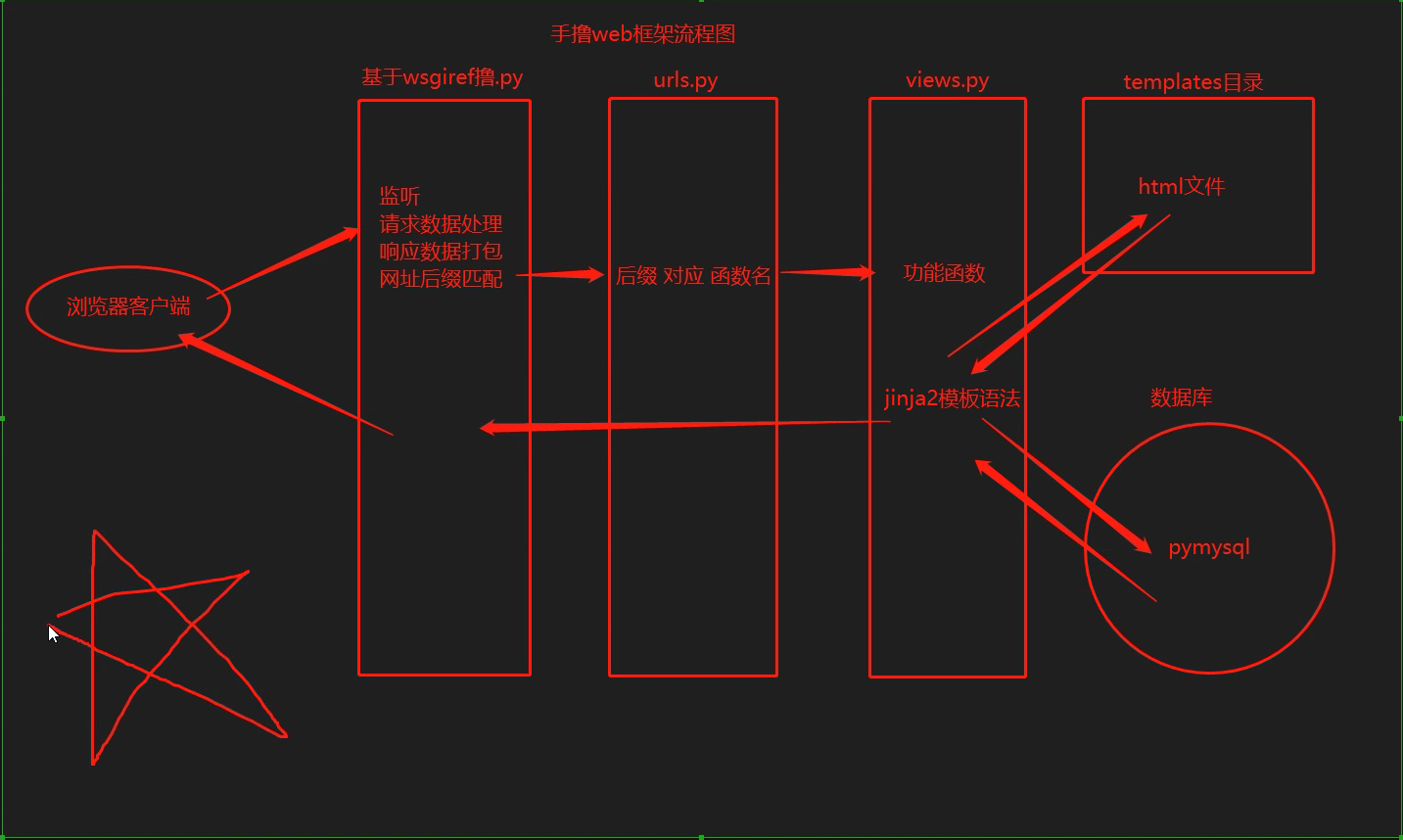
纯手撸web框架
---------------------------------------------
1.web框架的本质
理解1: 连接前端与数据库的中间介质
理解2: socket服务端
---------------------------------------------
2.手写web框架
1.编写socket服务端代码
2.浏览器访问响应无效>>>:HTTP协议
3.根据网址后缀的不同获取不同的页面内容
4.想办法获取到用户输入的后缀>>>:请求数据
5.请求首行
GET /login HTTP/1.1
GET请求
朝别人索要数据
POST请求
朝别人提交数据
6.处理请求数据获取网址后缀
-------------------------------------------
第一步:python代码创建服务端
浏览器输入 127.0.0.1:8080 就可以看到服务端发来的hello big baby消息
import socket
server = socket.socket() # TCP UDP
server.bind(('127.0.0.1', 8080)) # IP PORT
server.listen(5) # 半连接池
while True:
sock, address = server.accept() # 等待连接
data = sock.recv(1024) # 字节(bytes)
print(data.decode('utf8')) # 解码打印
sock.send(b'HTTP/1.1 200 OK\r\n\r\nhello big baby')
------------------------------------------------------------
第二步:根据网址后缀的不同获取不同的页面内容
上面的代码无论后缀敲什么,只要前面的ip与端口号对的,就一直在页面上显示的hello big baby
想实现 浏览器输入 127.0.0.1:8080/xxxx
根据ip与端口号后面的输入的 /xxxx后缀 的不同,网页实现出现不同的内容!!!
想办法在服务端获取到用户输入的后缀>>>:从接收到的客户端 请求数据 里面找!!!
用户输入的后缀 藏在请求首行里面了!!!
处理请求数据获取网址后缀,
就是现在想办法从接收到的一大串的请求数据里面精准的拿到请求首行里面藏着的网址后缀!!!
import socket
server = socket.socket() # TCP UDP
server.bind(('127.0.0.1', 8080)) # IP PORT
server.listen(5) # 半连接池
while True:
sock, address = server.accept() # 等待连接
data = sock.recv(1024) # 字节(bytes)
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
data_str = data.decode('utf8') # 先转换成字符串
target_url = data_str.split(' ')[1] # 按照空格切割字符串并取索引1对应的数据
# print(target_url) # 这样就能拿到用户输入的网址后缀了 /index /login /reg
sock.send(b'hello big baby') # 因为是流式协议,所以消息头部分开来,放上去
-----------------------------------------------------
第三步:通过判断来返回不同内容
根据拿到的后缀名,判断,然后发送不同的消息给客户端
这样就实现了用户输入的网页后缀不同,而显示不同的网页内容的效果了!!!
while True:
sock, address = server.accept() # 等待连接
data = sock.recv(1024) # 字节(bytes)
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
data_str = data.decode('utf8') # 先转换成字符串
target_url = data_str.split(' ')[1] # 按照空格切割字符串并取索引1对应的数据
if target_url == '/index':
sock.send(b'index page')
elif target_url == '/login':
sock.send(b'login page')
else:
sock.send(b'home page!')
# 浏览器有自动解二进制bytes类型数据的功能,所以网页能直接显示对应的字母信息!!!
-----------------------------------------------------------
第四步:前面只能发送二进制数据给浏览器在网页显示
想要实现返回html页面数据给浏览器
这样就实现了比如输入:127.0.0.1:8080/index
后就能将 myhtml01.html文件里面的数据在浏览器里面展示出来了!!!
while True:
sock, address = server.accept() # 等待连接
data = sock.recv(1024) # 字节(bytes)
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
data_str = data.decode('utf8') # 先转换成字符串
target_url = data_str.split(' ')[1] # 按照空格切割字符串并取索引1对应的数据
if target_url == '/index':
# sock.send(b'index page')
with open(r'myhtml01.html','rb') as f:
sock.send(f.read())
elif target_url == '/login':
sock.send(b'login page')
else:
sock.send(b'home page!')
------------------------------------------------------------
接收到的客户端的数据 符合请求格式:
请求首行 请求头(类似于报头一大堆键值对) 换行 请求体(可以不存在)
第一次什么后缀都没带的情况:
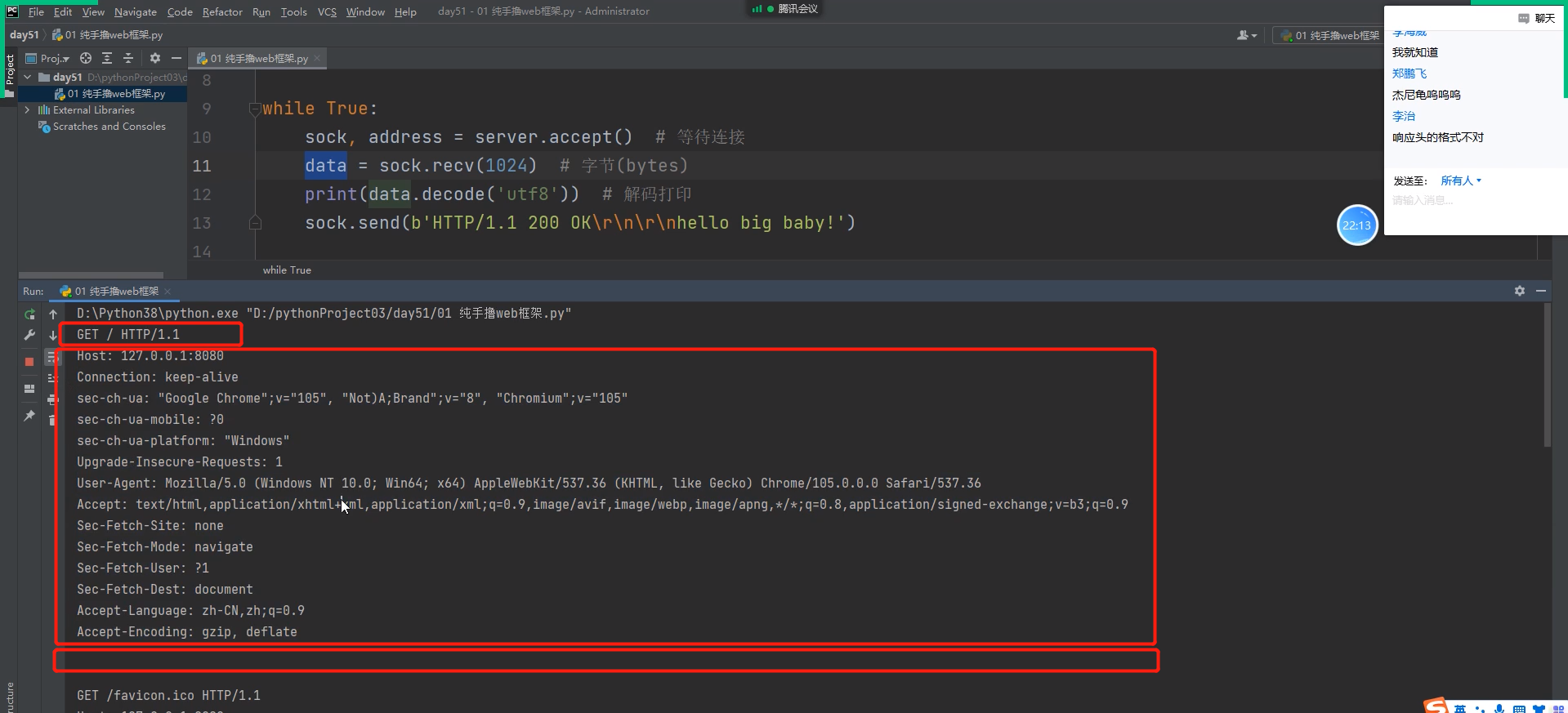
.
这个是输入带/index 后缀, 后的情况
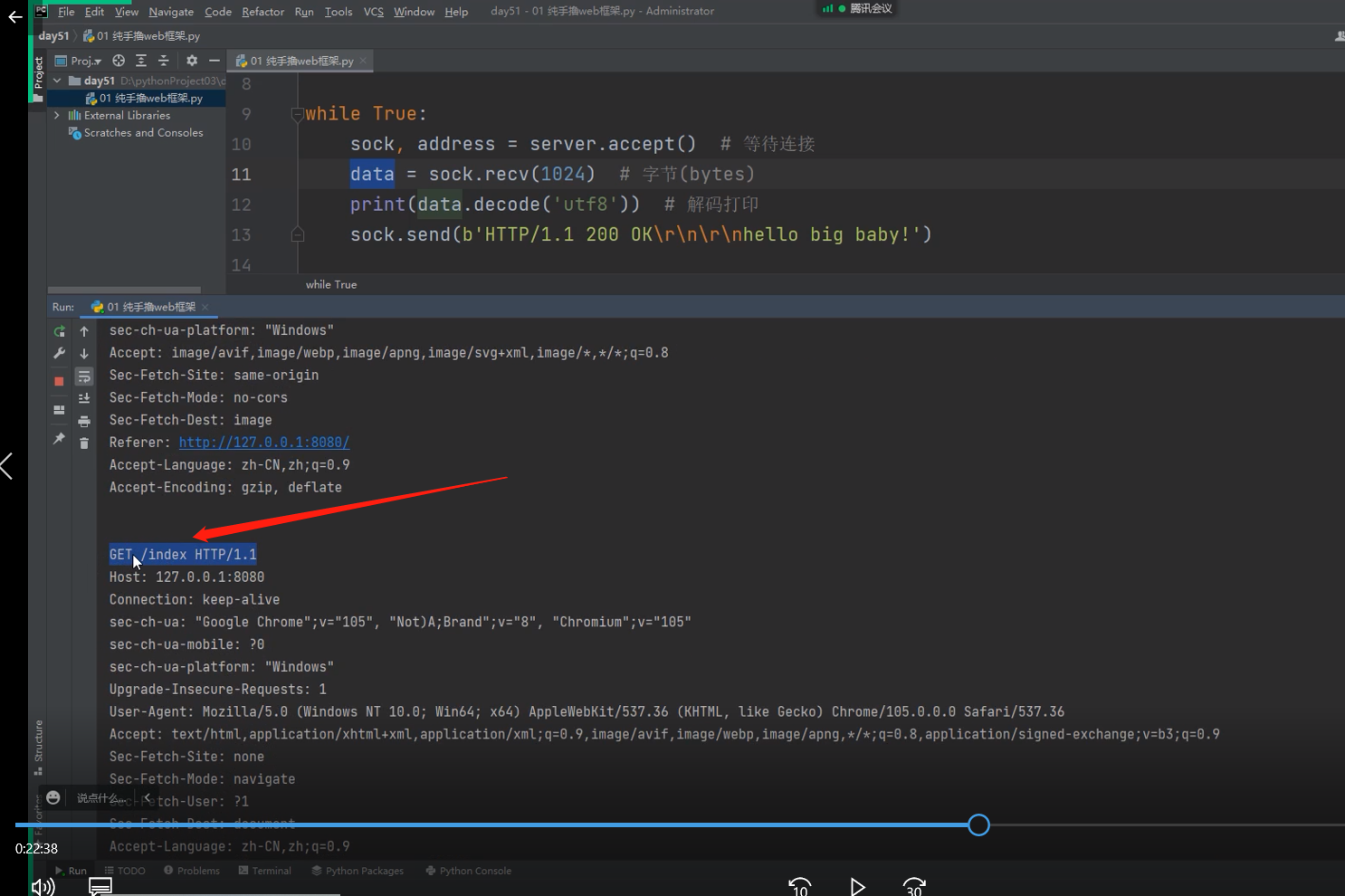
.
这个是输入带/login 后缀, 后的情况
可以看出敲什么样的后缀,最后在服务端接收到的请求数据的请求首行里面是能找到它的!!!
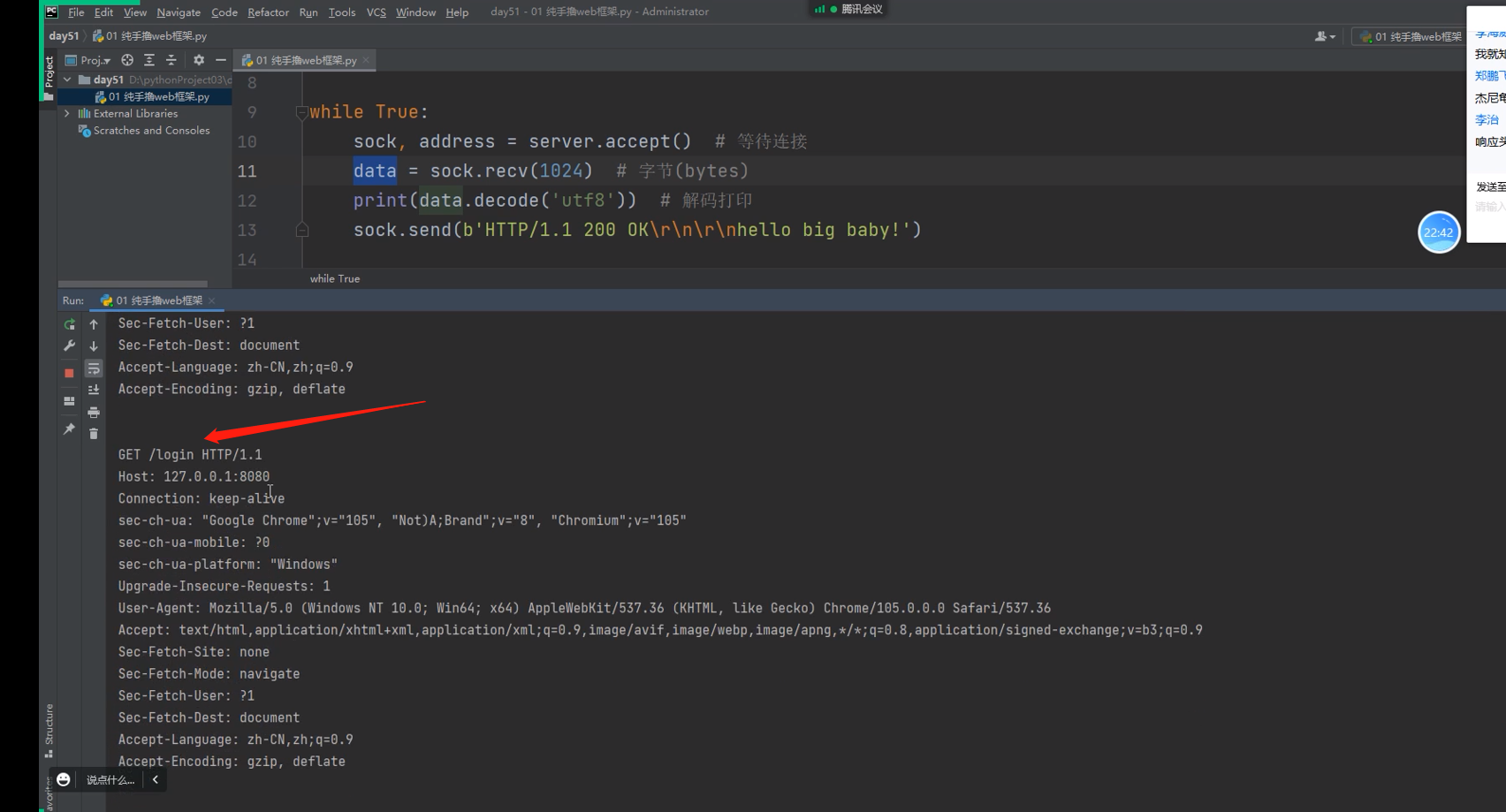
.
.
.
.
.
.
"""
1.socket代码过于重复
2.针对请求数据处理繁琐
3.后缀匹配逻辑过于LowB
"""
基于wsgiref模块
内置模块 很多web框架底层使用的模块
Web服务器网关接口(Web Server Gateway Interface,缩写为WSGI)
是为Python语言定义的Web服务器和Web应用进程或框架之间的一种简单而通用的接口。
自从WSGI被开发出来以后,许多其它语言中也出现了类似接口。
reference 参考;提及
----------------------------------
功能1:封装了socket代码!!!
功能2:处理了请求数据!!!
---------------------------------------------------
1.固定代码启动服务端
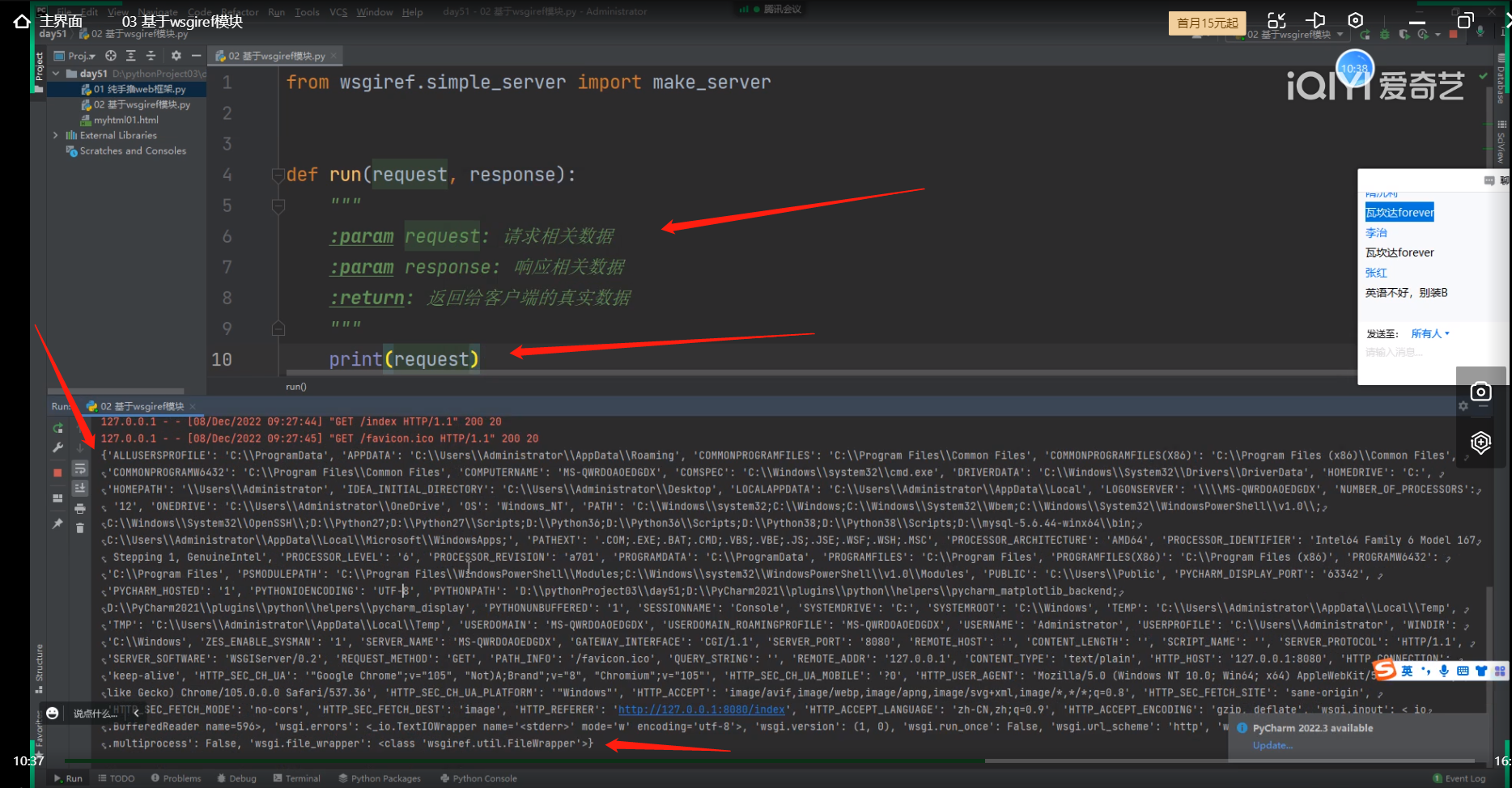
2.查看处理之后的request大字典
3.根据不同的网址后缀返回不同的内容>>>:研究大字典键值对
4.立刻解决上述纯手撸的两个问题
5.针对最后一个问题代码如何优化
----------------------------------------------------
from wsgiref.simple_server import make_server # 内置模块直接导入
def run(request, start_response):
"""
行参 request 请求相关数据
行参 response 响应相关数据
return 返回给客户端的真实数据
"""
print(request)
start_response('200 OK', []) # 固定格式 不用管它
return [b'hello wsgiref module']
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run)
# 创建服务端并实时监听127.0.0.1:8080 地址,一旦有请求过来,
# 自动给第三个参数run加括号调用,并传参数
server.serve_forever() # 永远的启动起来,就是启动服务端!!!
# 这个时候无论敲什么后缀,只要IP与端口号对,
# 网页显示的都是上面return返回的结果 hello wsgiref module
-------------------------------------------------------
-------------------------------------------------------
.
.
.
.
总结
request行参所接收到的值,是一个处理之后的大字典,
make_server服务端已经帮我们把之前毫无规则的请求数据,
处理成了字典了传给run函数里面的行参request了!!
将来在取信息的时候只需要通过字典的键就可以拿到对应值
(请求首行、请求头、请求体里面数据都已经被处理到了request的字典里面去了!!!)
.
.
.
.
.
.
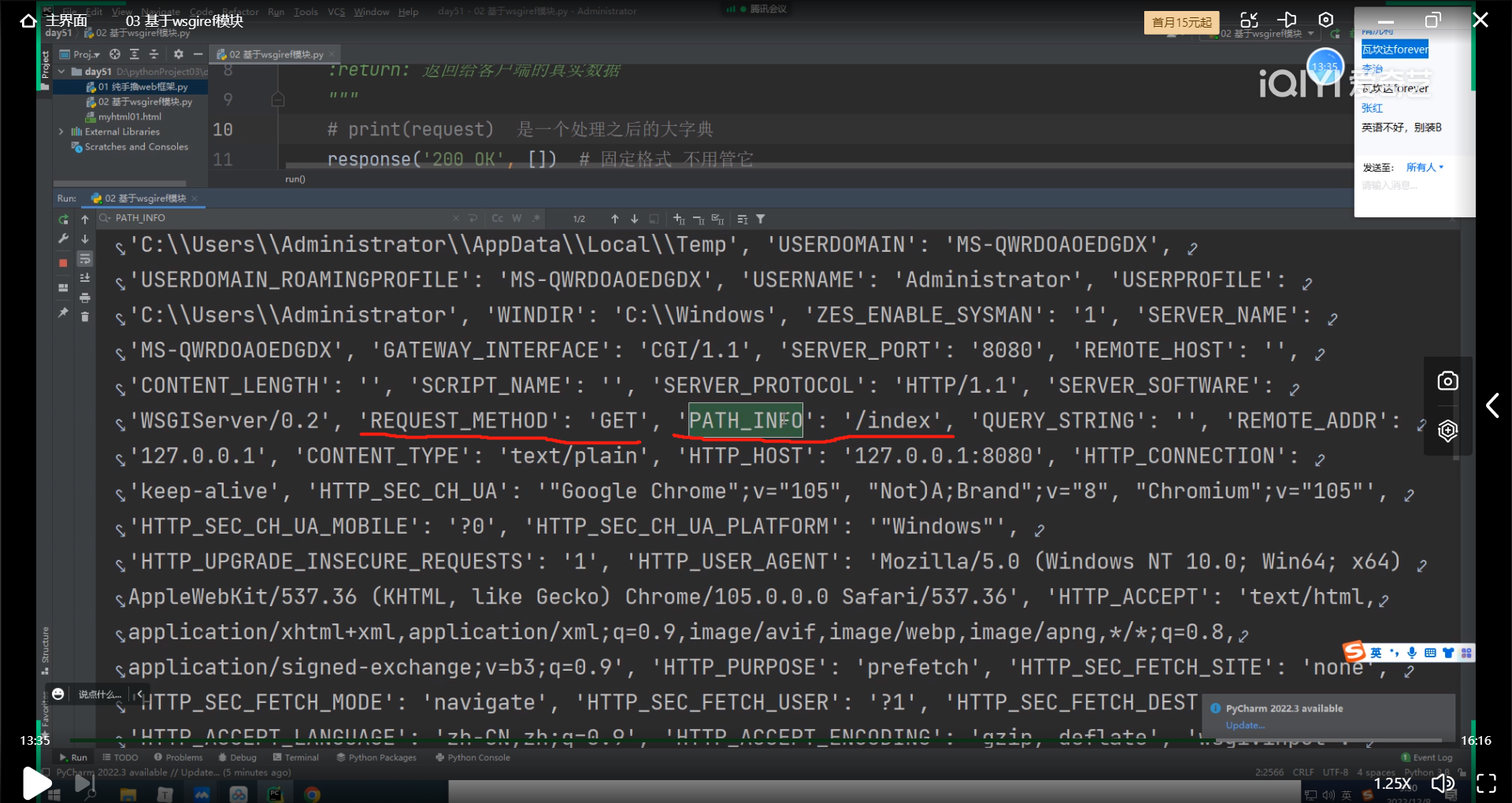
# 根据不同的网址后缀返回不同的内容>>>:研究大字典键值对
# 我们发现原来我们需要通过tcp流式协议的recv收到的data请求数据,
# 还要切割索引才拿到的后缀,已经被处理好了用'PATH_INFO'键就可以拿到了!!!
from wsgiref.simple_server import make_server # 内置模块直接导入
def run(request, response):
response('200 OK', []) # 固定格式 不用管它
path_info = request.get('PATH_INFO')
if path_info == '/index':
return [b'index']
elif path_info == '/login':
return [b'login']
return [b'hello wsgiref module']
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run)
server.serve_forever() # 永远的启动起来,就是启动服务端!!!
此时已经解决了上述纯手撸的两个问题(1.socket代码过于重复2.针对请求数据处理繁琐)
-----------------------------------------------------------
.
.
.
.
.
.
继续优化-------代码封装
1.网址后缀的匹配问题
2.每个后缀匹配成功后执行的代码有多有少,假如判断后执行的代码有很多行,
都写在一起就不对劲了!!!所以要封装成函数了!!!
面条版 函数版 模块版
3.将分支的代码封装成一个个函数
4.将网址后缀与函数名做对应关系
5.获取网址后缀循环匹配
6.如果想新增功能只需要先写函数再添加一个对应关系即可
-------------------------------------------------------
7.根据不同的功能拆分成不同的py文件
views.py 存储核心业务逻辑(功能函数)
urls.py 存储网址后缀与函数名对应关系
templates目录 存储html页面文件
---------------
8.为了使函数体代码中业务逻辑有更多的数据可用
将request大字典转手传给这个函数(可用不用但是不能没有)
.
.
.
函数的封装!!!
from wsgiref.simple_server import make_server
def index_func():
return 'index function'
def login_func():
return 'login function'
def error_func():
return '404 not found'
urls = [
('/index', index_func),
('/login', login_func),
]
def run(request, response):
response('200 OK', []) # 固定格式 不用管它
path_info = request.get('PATH_INFO')
func_name = None # 定义一个用于后续存储函数名的变量
for url_tuple in urls: # 拿到的是一个一个的元组(后缀,函数名)
if path_info == url_tuple[0]:
func_name = url_tuple[1]
break # 一旦匹配成功 后续无序匹配直接结束
if func_name:
res = func_name()
else:
# 有可能用户输入的后缀path_info不在urls列表里面,说明没有与该后缀对应的函数!!
# for循环走完,func_name也拿不到值
res = error_func()
return [res.encode('utf8')] # 统一将每个函数的返回值字符串数据转化为二进制数据
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run)
# 实时监听127.0.0.1:8080 一旦有请求过来自动给第三个参数加括号并传参数调用
server.serve_forever() # 启动服务端
这个时候run函数就已经被写活了!!!
问题1-6已经被解决了!!!
此时如果要新增一个函数,只需要定义好函数体代码,
并在urls的列表里面写好网址后缀与函数名的对应关系就好了!!!
--------------------------------
.
.
.
最后
7.根据不同的功能拆分成不同的py文件
核心的功能函数叉到 views.py 文件里面去
网址后缀与函数名对应关系urls列表 叉到 urls.py 文件里面去
html页面文件 叉到 templates文件夹里面去
然后把该用的导入一下就好了
----------------------------------------------------
views.py 存储核心业务逻辑(功能函数)
urls.py 存储网址后缀与函数名对应关系
templates目录 存储html页面文件
-----------------------------------
启动文件代码:
from wsgiref.simple_server import make_server
from views import *
from urls import urls
def run(request, response):
response('200 OK', []) # 固定格式 不用管它
path_info = request.get('PATH_INFO') # /index
func_name = None # 定义一个用于后续存储函数名的变量
for url_tuple in urls: # 拿到的是一个一个的元组(后缀,函数名)
if path_info == url_tuple[0]:
func_name = url_tuple[1]
break # 一旦匹配成功 后续无序匹配直接结束
if func_name:
res = func_name(request)
else:
# 有可能用户输入的后缀path_info不在urls列表里面,说明没有与该后缀对应的函数!!
# for循环走完,func_name也拿不到值
res = error_func(request)
return [res.encode('utf8')] # 统一将每个函数的返回值字符串数据转化为二进制数据
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run)
# 实时监听127.0.0.1:8080 一旦有请求过来自动给第三个参数加括号并传参数调用
server.serve_forever() # 启动服务端
------------------------------------------------
urls.py文件代码:
from views import *
urls = [
('/index', index_func),
('/login', login_func),
('/reg', reg_func),
('/logout', logout_func),
]
------------------------------------
views.py文件代码:
def index_func(request):
return 'index function'
def login_func(request):
with open(r'templates/myhtml02.html', 'r', encoding='utf8') as f:
return f.read()
def reg_func(request):
return 'reg function'
def error_func(request):
return '404 Not Found'
def logout_func(request):
return 'logout function'
.
.
.
.
.
.
动静态网页
-------------------------------------------
动态网页
页面数据来源于后端
静态网页
页面数据直接写死
-------------------------------------------
需求1:
访问某个网址后缀,后端代码获取当前时间,并将该时间传到html文件上,再返回给浏览器展示给用户看
读取html内容(字符串类型) ,然后利用字符串替换 , 最后再返回给浏览器!!!
-----------------------------------
需求2:
将字典传递给页面内容 , 并且在页面上还可以通过类似于后端的操作方式操作该数据
模板语法>>>:jinja2模块
(能把后端的数据类型,传递到html文件上,并且能够支持在html页面上拿到数据后,
还能够去点一些后端的方法,来操作该数据)
------------------------------------
.
.
.
需求1代码实现
html文件
<body>
<h1>展示请求时间</h1>
<p>当前时间:XXXXXX</p>
</body>
--------------------------------
urls = [('/get_time', get_time_func),]
--------------------------------
views.py文件
def get_time_func(request):
import time
ctime = time.strftime('%Y-%m-%d %X')
with open(r'templates/get_time_page.html', 'r', encoding='utf8') as f:
data = f.read()
# 在后端先把数据通过字符串的替换,传递到文件内容上,之后再发送给浏览器
res = data.replace('XXXXXX', ctime)
return res
这样就可以实现,当用户输入网址与后缀后,网页上显示当前时间了!!!
------------------------------
.
.
.
.
jiaja2简介
jinja2是默认的模仿Django模板的一个模板引擎, 由flask的作者开发 它速度快 被广泛使用,
并且提供了可选的沙箱模板来保证执行环境安全
--------------------
Jinja2是基于python的模板引擎,作为一个模板系统,它还提供了特殊的语法,
我们按照它支持的语法进行编写之后,就能使用jinja2模块进行渲染。
---------------
.
.
.
jinja2模块终端下载
pip3.8 install jinja2
pip是python解释器里面专门用来来载模块的工具,
后面跟的数字,是因为我们一个电脑上可能有不同版本的解释器,
所有之前我们把不同版本解释器里面的scripts文件夹里面原始的pip.exe文件
复制了一份重命名为比如pip3.8.exe,而且scripts文件目录的环境变量我们之前配过,
所以可以直接在命令行输入pip3.8 install jinja2
就会在运行python38解释器里面的scripts文件夹里面pip3.8.exe文件,进行下载模块操作!!
或者也可以在pycharm里面下载
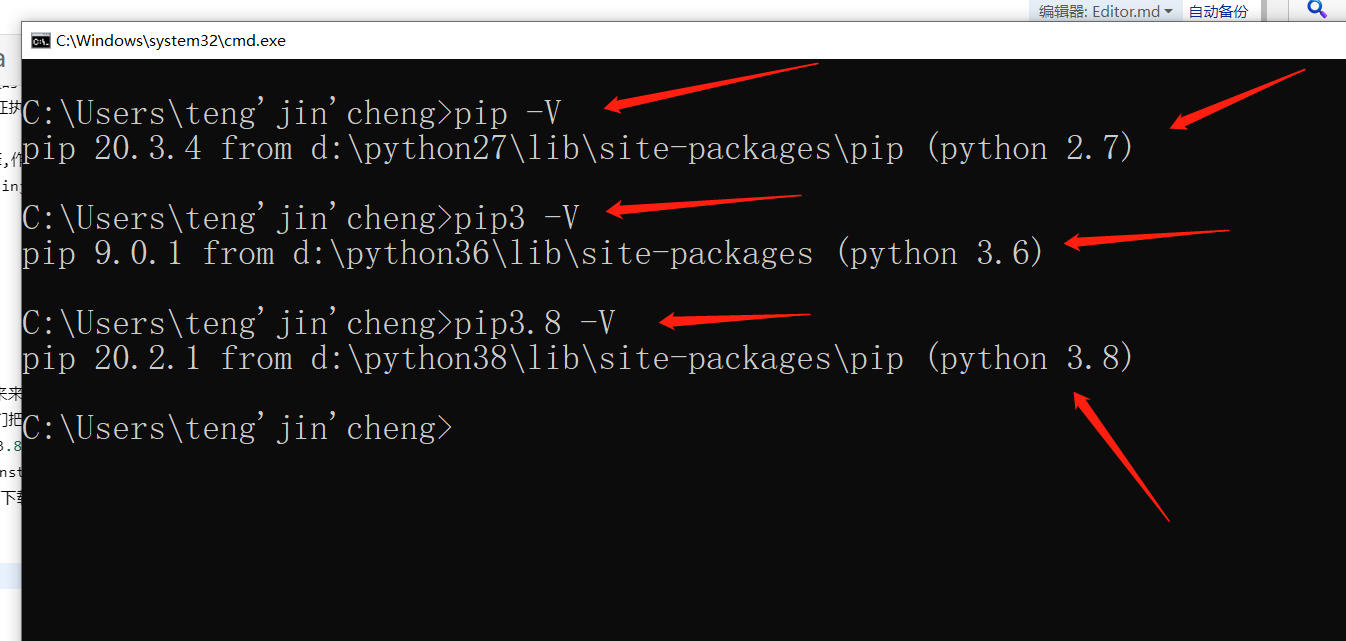
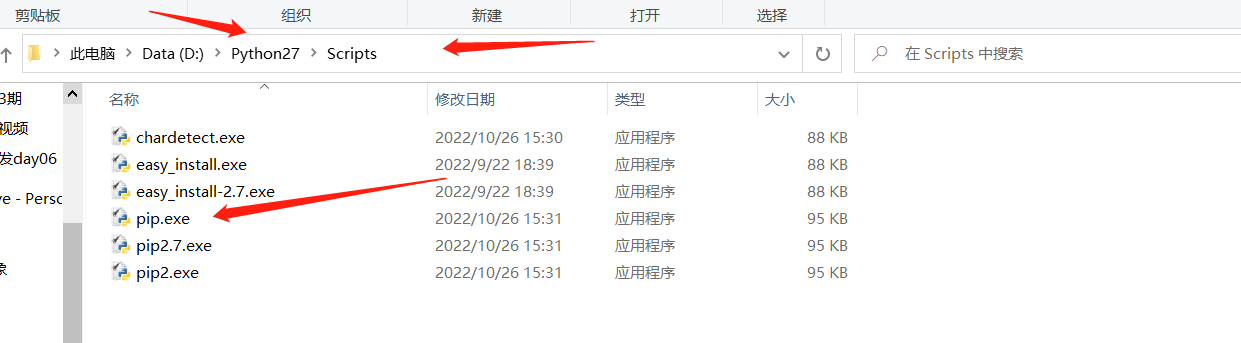
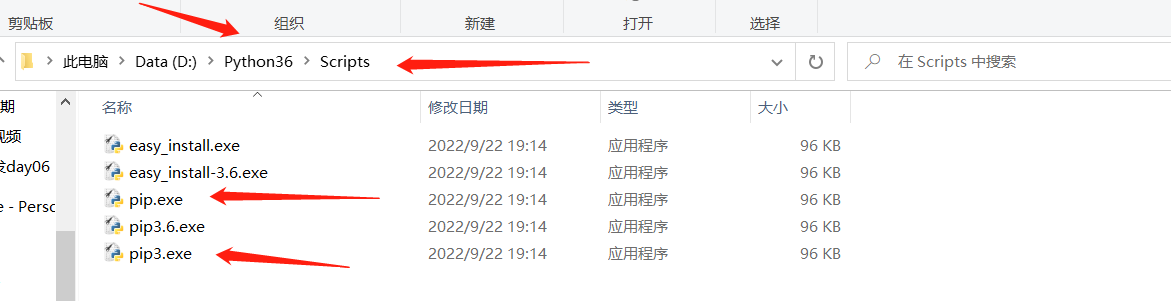
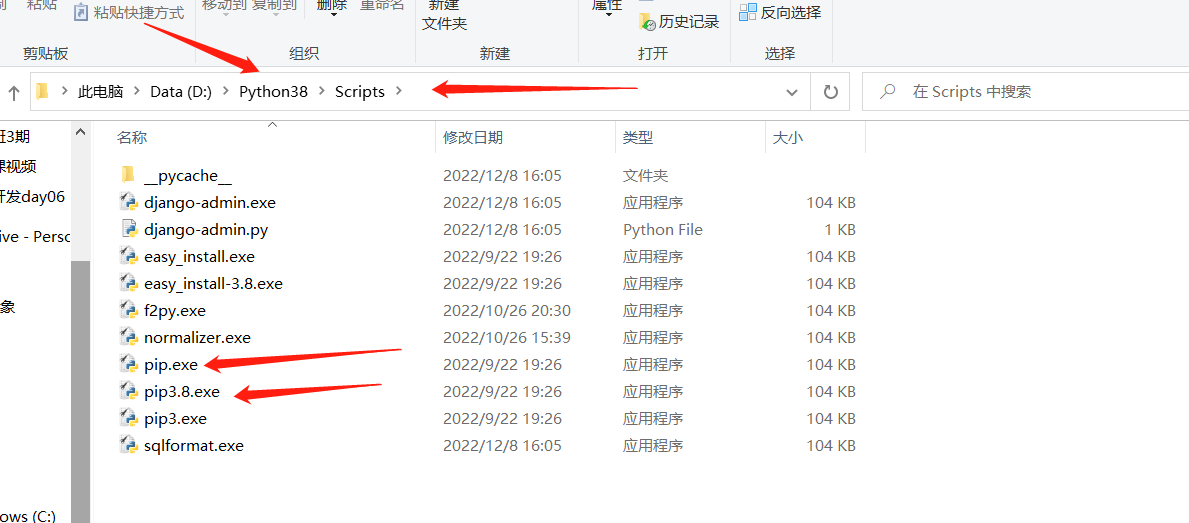
为什么会出现这种情况???pip -V 显示python2.7版本
pip3 -V 显示python3.6版本 pip3.8 -V 显示python2.7版本
.
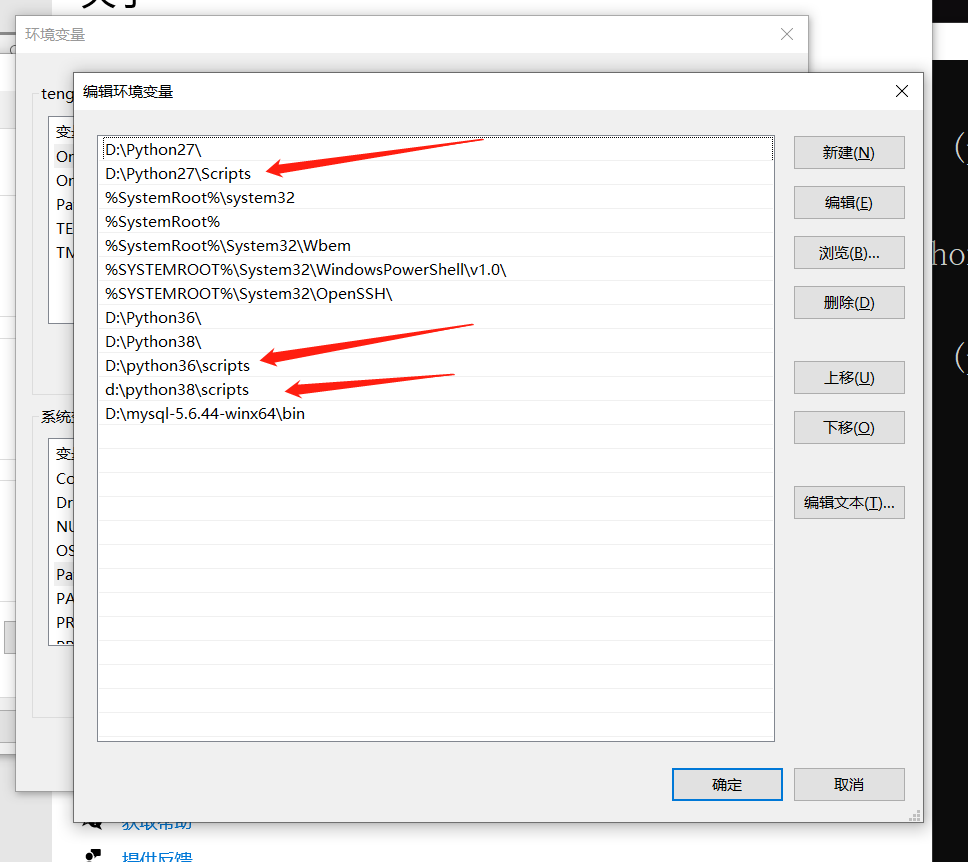
因为环境变量 D:\Python27\Scripts 在最前面 所以输pip直接找到python2.7里面去了
D:\Python36\Scripts 在中间 所以输pip3直接找到python3.6里面去了
D:\Python38\Scripts 在最后 所以只有输pip3.8才能找到python3.8里面去了
.
.
.
.
.
.
.
jinja2模块语法
Template 模板(n)
jinja2模板的作用:
能够将python后端的一些数据,传递到html文件上,然后在文件上用一些特殊的语法,把数据给操作好,数据弄好后,发送给前端浏览去展示!!!
---------------------------------------------------
html文件是不支持后端任何语法的,只支持html css js 语法
--------------------------------------------
需求2代码实现
html文件
<body>
<h1>获取字典数据</h1>
<p>{{ d1 }}</p> # 拿到user_dict字典整体了
<p>{{ d1.name }}</p> # 拿到user_dict字典里面name对应的值了
<p>{{ d1['age'] }}</p>
<p>{{ d1.get('person_list') }}</p>
</body>
--------------------------------
urls = [('/get_dict', get_dict_func),]
--------------------------------
views.py文件
from jinja2 import Template
def get_dict_func(request):
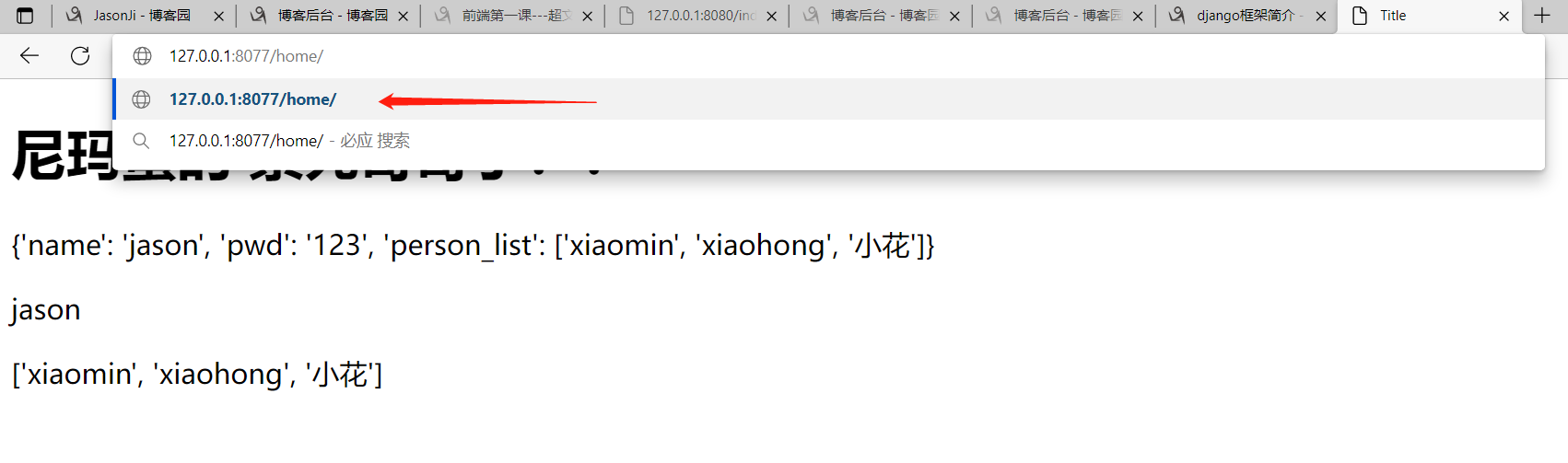
user_dict = {'name': 'jason', 'age': 18, 'person_list': ['阿珍', '阿强', '阿香', '阿红']}
with open(r'templates/get_dict_page.html', 'r', encoding='utf8') as f:
data = f.read()
temp_obj = Template(data) # 将页面数据交给模板处理
res = temp_obj.render({'d1': user_dict})
# render方法支持给html页面传一些东西!!!
# 比如:变量名是d1,值是user_dict字典数据的数据!!!
return res
.
.
.
.
.
前端、后端、数据库三者联动!!!
需求:
前端浏览器访问get_user 后端连接数据库查询user表中所有的数据,
传递到某个html页面,弄好样式,再发送给浏览器展示。
sql语句:
mysql -uroot -p
222
create database day51;
use day51;
create table userinfo (id int primary key auto_increment,name varchar(32),age int );
insert into userinfo(name,age) values('jason,',18),('tony',28),('kevin',32),('jastin',33),('axiang',18);
select * from userinfo;
-----------------------------------------
urls = [('/get_user', get_user_func),]
-----------------------------------------
views.py文件
from jinja2 import Template
import pymysql
def get_user_func(request):
# 连接数据库操作数据
conn = pymysql.connect(
user='root', # sql 账号
password='222', # sql 密码
host='127.0.0.1',
port=3306, # sql服务端 端口号
database='day51', # 想操作的sql数据库
charset='utf8',
autocommit=True # 针对增 删 改 自动确认(直接配置)
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql1 = "select * from userinfo;"
cursor.execute(sql1) # 发送sql语句
user_data = cursor.fetchall() # fetchall拿到的是列表套字典数据 [{},{},{},{}]
# 读取页面数据
with open(r'templates/get_user_page.html', 'r', encoding='utf8') as f:
data = f.read()
temp_obj = Template(data)
# 把页面数据交给jinja2模板语法Template去管理一下
# 因为只有它才能支持你在页面上通过后端的语法来快速的操作一些数据
res = temp_obj.render({'user_data_list': user_data})
# 给render传值,要想在页面上用到user_data里面的数据,必须要用键名来指代它,
# 然后在html页面上就可以通过键名来用user_data了!!!
return res
--------------------------------------------
html文件
<body>
<div class="container"> # 先搞一个布局容器
<div class="row">
<h1 class="text-center">数据展示</h1>
<a href="/index">点我试试</a>
<div class="col-md-8 col-md-offset-2">
<table class="table table-hover table-striped">
<thead>
<tr>
<th>ID</th>
<th>Name</th>
<th>Age</th>
</tr>
</thead>
<tbody>
<!--此时后端语句传过来一个列表套字典的数据了user_data_list [{},{},{},{} ]-->
<!--jinja2语法也支持for循环语法,拿到一个一个字典,每个字典就是数据库表里面的一条数据-->
{% for user_dict in user_data_list %}
<tr>
<td>{{ user_dict.id }}</td>
<td>{{ user_dict.name }}</td>
<td>{{ user_dict.age }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
</body>
--------------------------------------------
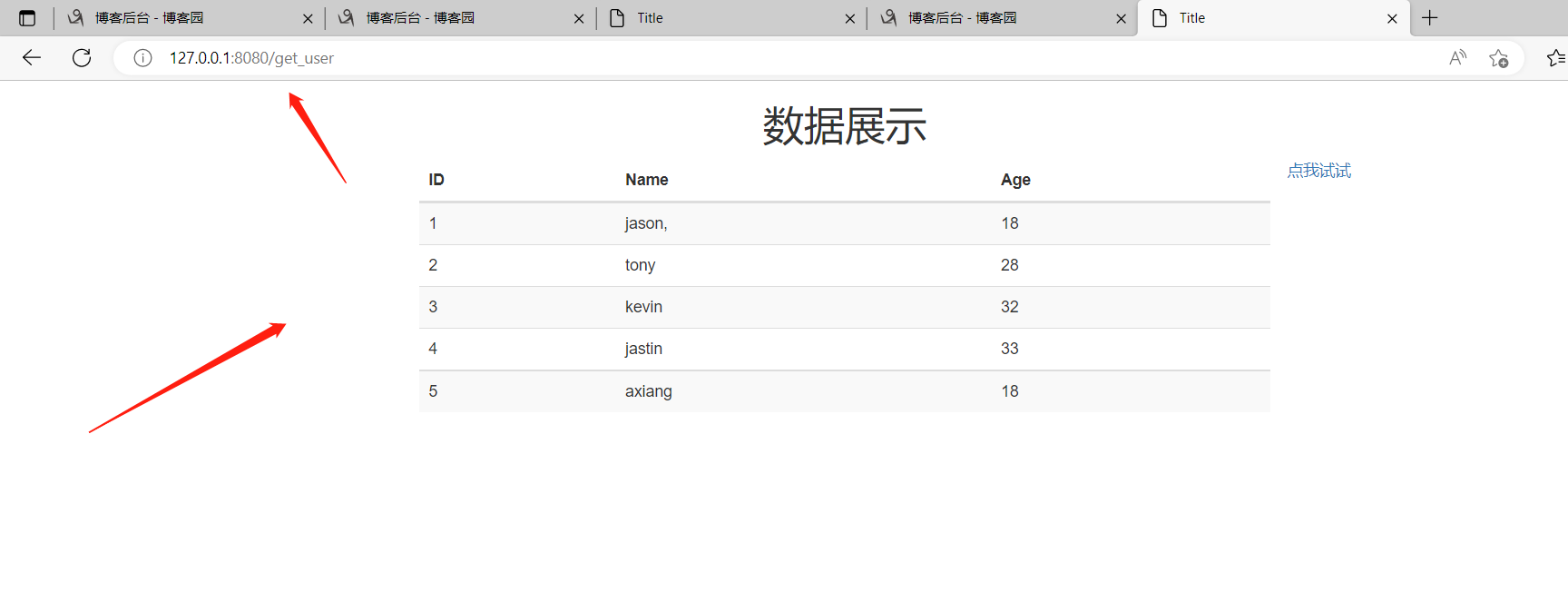
三者联动就实现了!!!!
前端浏览器访问http://127.0.0.1:8080/get_user
后端连接数据库查询use表中所有的数据!!!
传递到某个html页面,弄好样式,再发送给浏览器展示!!!
--------------------------------------------
.
.
.
.
.
.
.
python主流web框架
"""
作为小白的你 初学阶段不要混着学 很容易走火入魔
"""
1.django
大而全 自身自带的功能组件非常的多 类似于航空母舰
2.flask
小而精 自身自带的功能组件非常的少 类似于游骑兵
几乎所有的功能都需要依赖于第三方模块
3.tornado
异步非阻塞 速度极快效率极高甚至可以充当游戏服务端
ps:sanic、fastapi...
.
.
.
.
django简介
1.版本问题
django1.X:同步 1.11
django2.X:同步 2.2
django3.X:支持异步 3.2
django4.X:支持异步 4.2
ps:版本之间的差异其实不大 主要是添加了额外的功能
--------------------------------------------------------
2.运行django注意事项:
1.django项目中所有的文件名目录名不要出现中文
2.计算机名称尽量也不要出现中文
3.一个pycharm页面,尽量就是一个完整的项目(不要嵌套 不要叠加)
4.不同版本的python解释器与不同版本的django可能会出现小问题
-----------------------------------------------------------
不同版本解释器对不同版本的django可能会出现一些小问题!!!
启动如果报错,根据提示找到修改widgets.py文件第152行源码,删除最后的逗号即可!!!

.
.
.
.
.
.
.
django基本使用
-----------------------------------------------------
1.下载
pip3.8 install django 默认最新版
pip3.8 install django==版本号 指定版本
pip3.8 install django==2.2.22
pip下载模块会自动解决依赖问题(会把关联需要用到的模块一起下了)
也可以在pycharm里面settings---project---python interpreter---
点加号---搜索栏输入django
----------------------------------------------------
2.验证ajango有没有下载好指令:django-admin
只要django下载好了,
django会自动在python解释器文件夹的script文件夹里面创建一个django-admin文件,
之前script的路径我们添加过系统的环境变量,
所以在命令行直接敲django-admin 能找直接找到该文件并运行它。
----------------------------------------------------
3.常见命令:
1.创建django项目(就是一个ajango文件夹,里面自动包含了一些py文件!!!)
django-admin startproject 项目名
注意如果直接在D盘的目录下输入该命令,django文件夹就创在D盘目录下了
如果想要像python文件一样放到python的项目文件里面去,这样操作:
cd pythonProject
django-admin startproject 项目名
比如:django-admin startproject djangoday01
这样就在了pythonProject目录下,创建了djangoday01项目了!!!
---------------------------------------
2.启动django项目 cmd命令
cd 项目名
python38 manage.py runserver
# 如果项目起不来,可能端口占用了,默认的是8000的端口
python38 manage.py runserver ip:port # 指代一个新的端口号
----------------------------------------------------
启动django项目 出现的报错信息:
django-admin startproject mysite
cd mysite
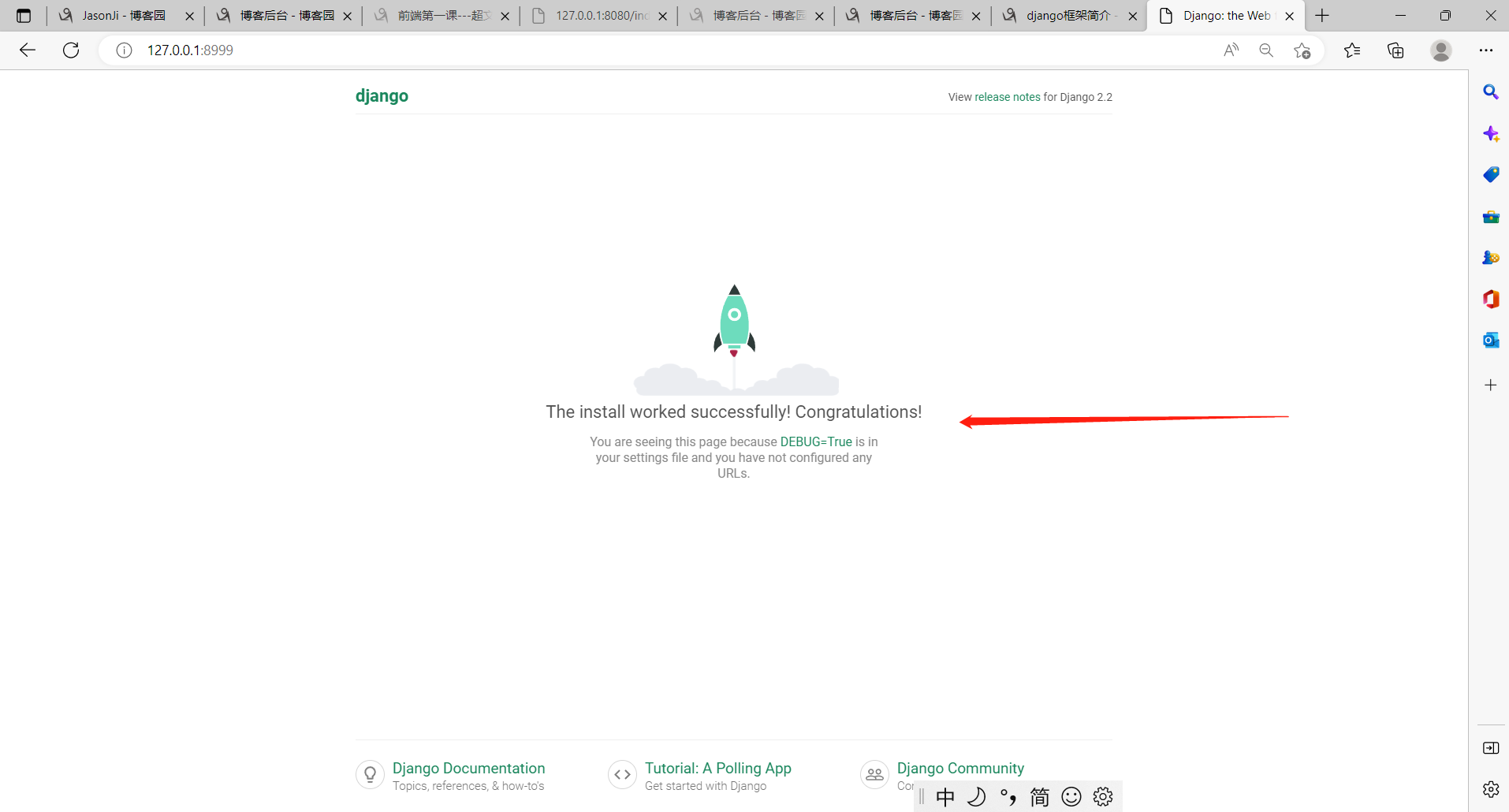
python38 manage.py runserver
Starting development server at http://127.0.0.1:8000/
Quit the server with CTRL-BREAK.
Error: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试。
------------------
这个时候换个端口就行了
python38 manage.py runserver 127.0.0.1:8999
-----------------------------------------------------
-----------------------------------------------------
4.pycharm自动创建django项目
会自动创建templates文件夹!!!
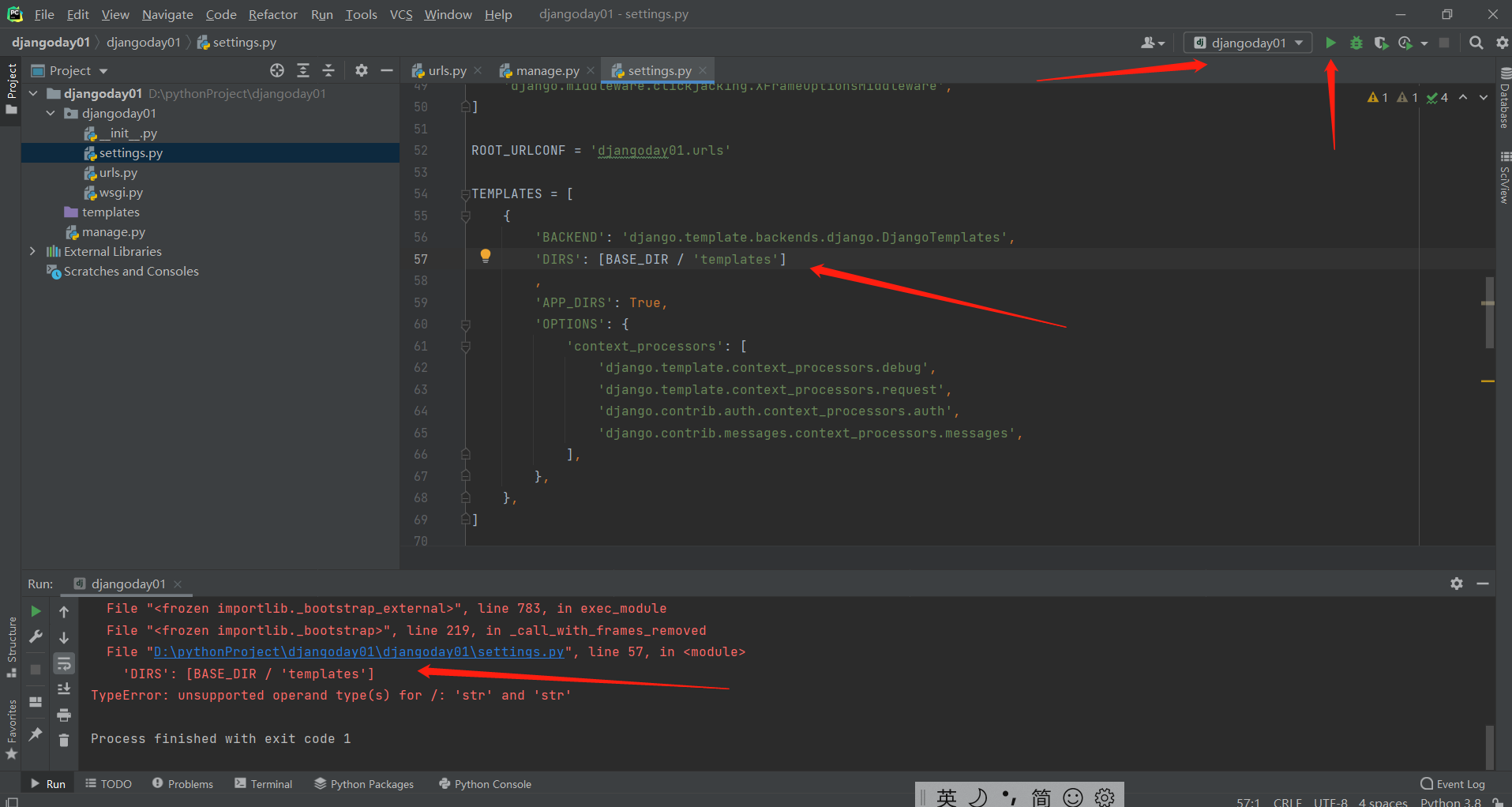
但是配置文件中可能会报错!!!
os.path.join(BASE_DIR,'templates')
----------------------------------------------------
django-admin
.
ajango项目正常启动后的样子
.
pycharm自动创建django项目
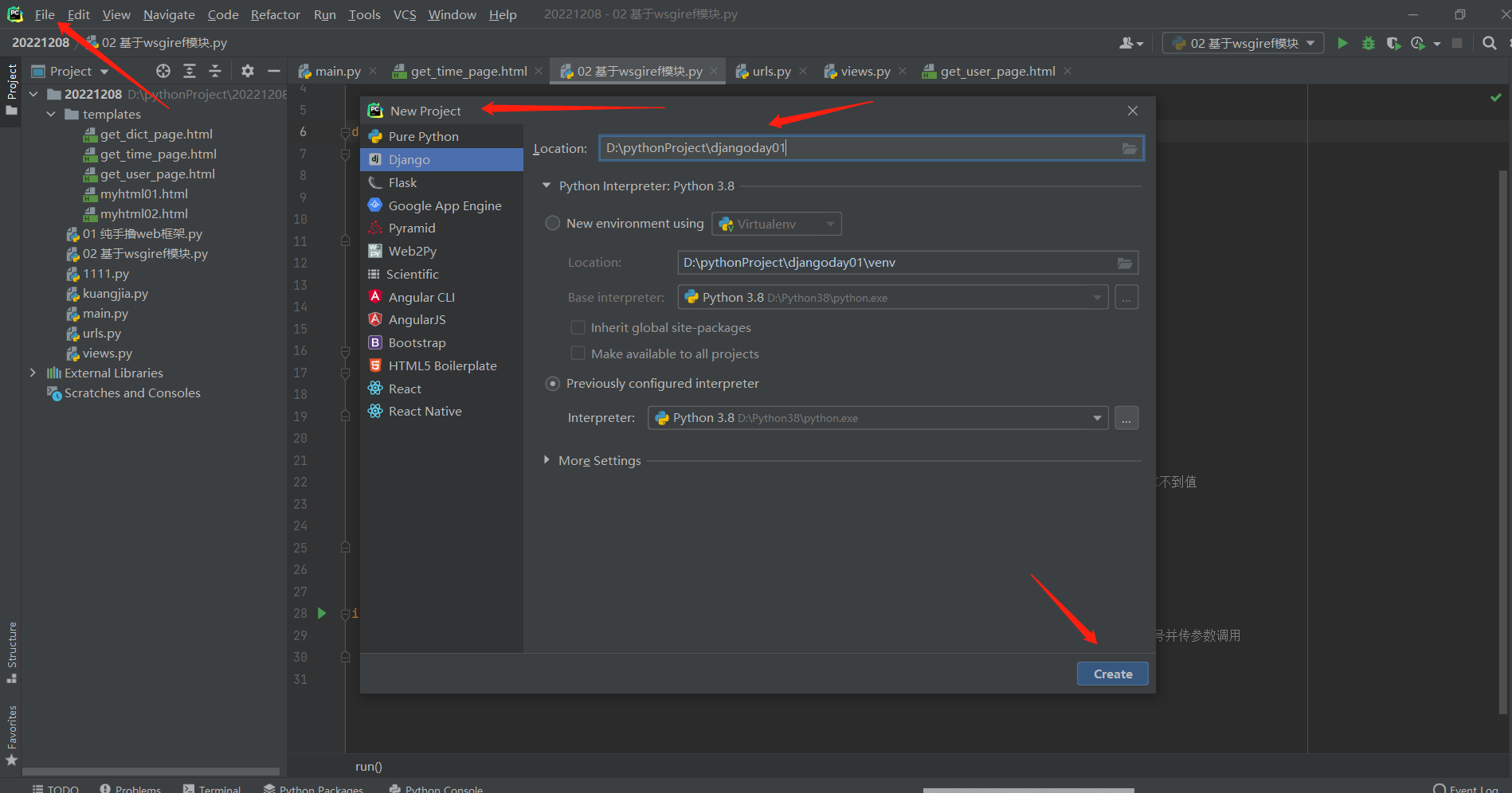
在pythonProject文件夹创了一个django项目了!!!
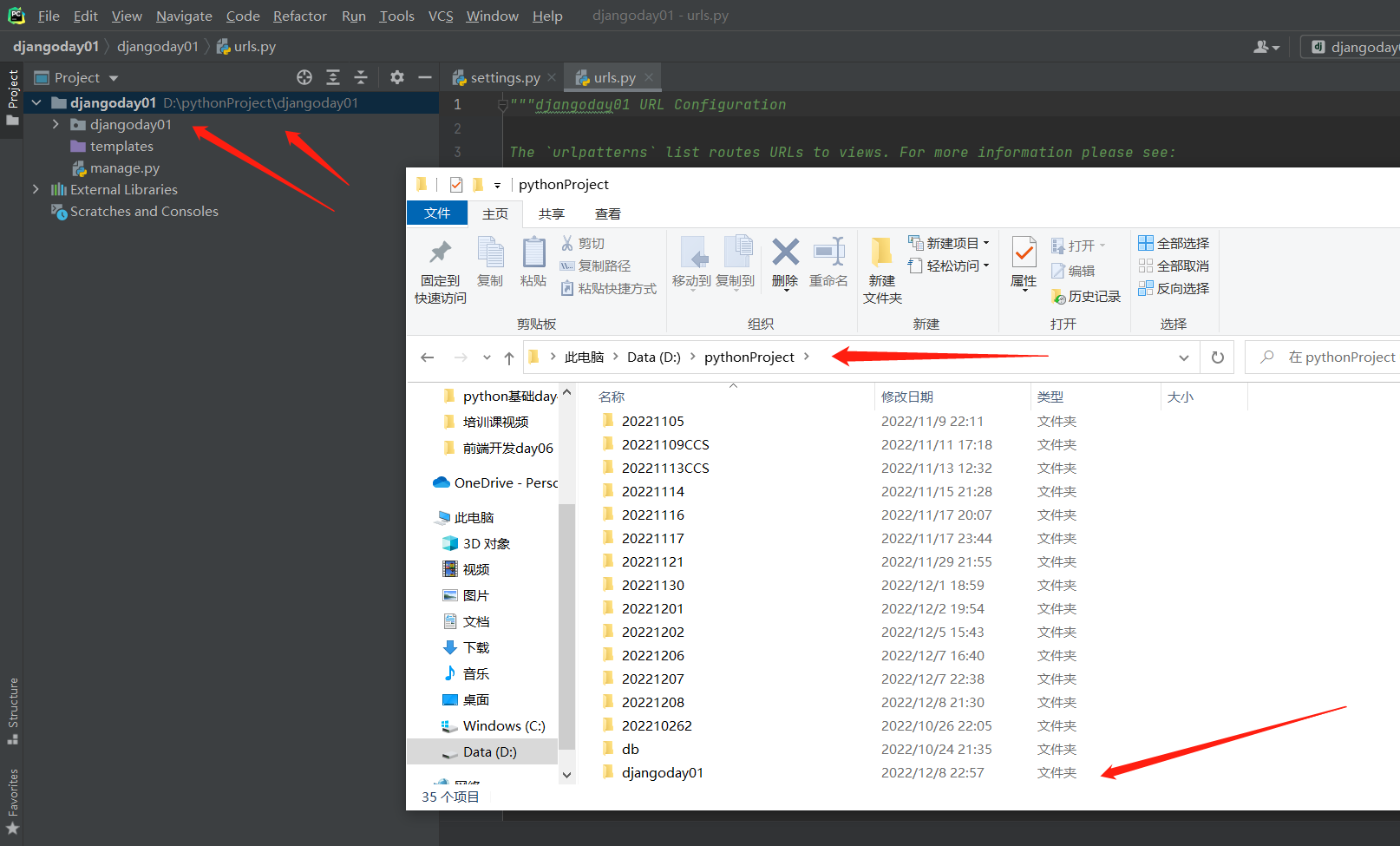
.
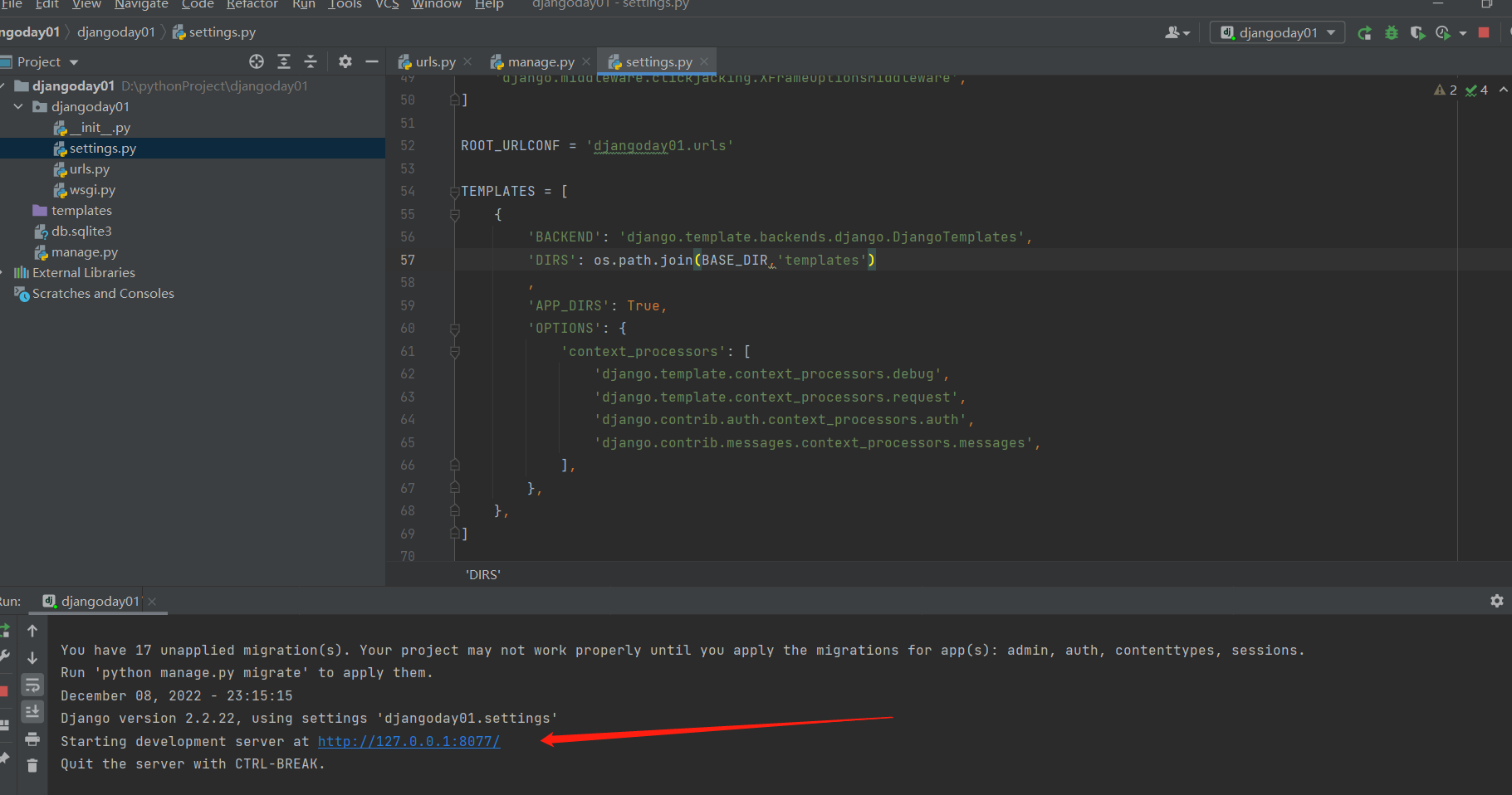
这个时候点右上角绿色小按钮启动项目会报错,因为settings里面的路径拼接的有问题,要手动改一下 改成 os.path.join(BASE_DIR,'templates') 就行了!!!
.
要是想改端口的话,点击右上角 edit configurations 键 里面改端口号!!
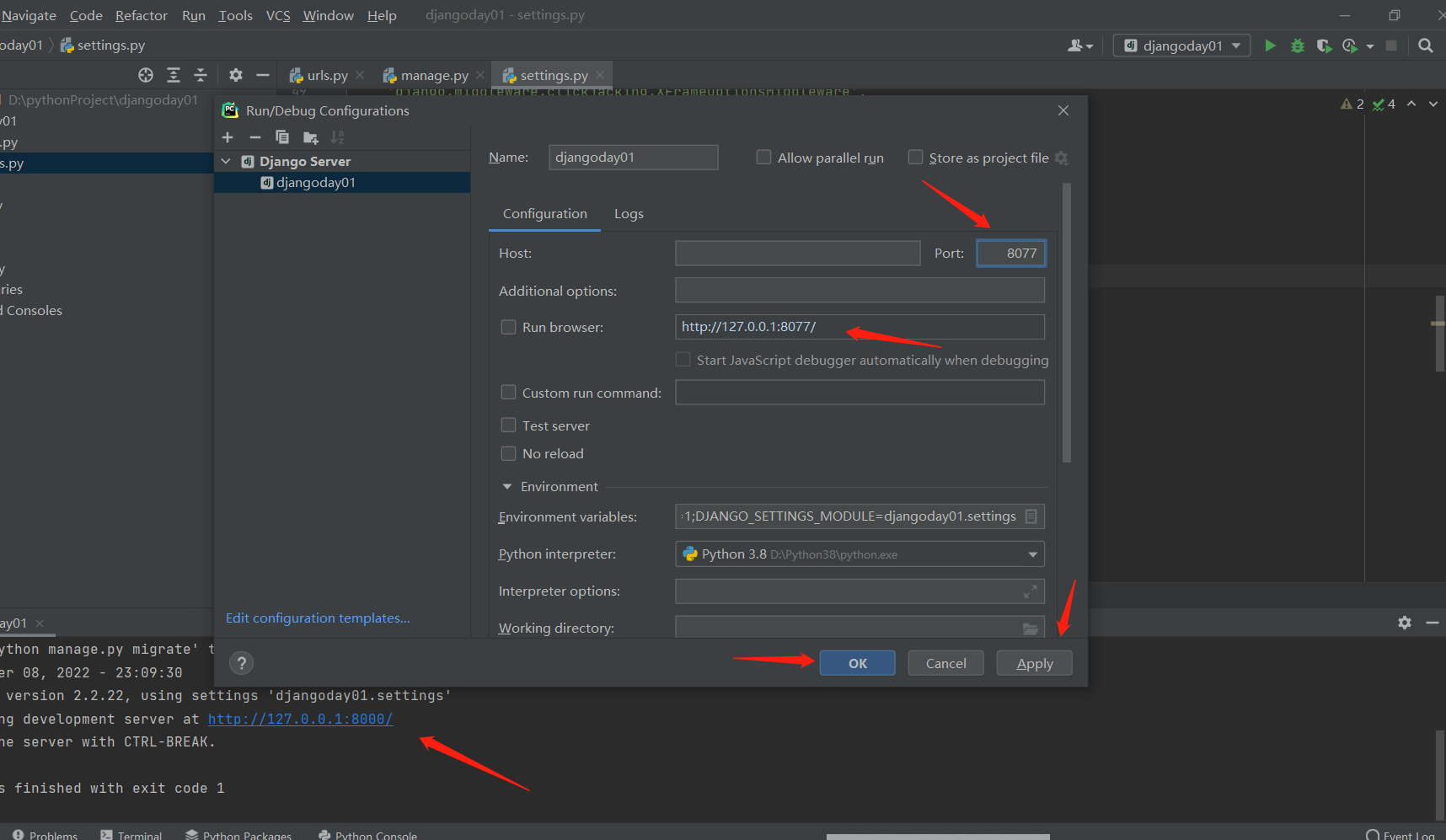
.
.
.
.
.
.
.
.
django app的概念
django项目文件夹相当于是空壳子,如果想写功能必须要用它的app
django类似于是一所大学 app类似于大学里面的各个学院
--------------------------------------------------------
一个app就相当于一个功能模块!!!
django里面的app类似于某个具体的功能模块
user app 所有用户相关的都写在user app下
goods app 所有商品相关的都写在goods app下
--------------------------------------------------------
一个app就是一个应用,每一个应用都是各自独立的互相不干扰!!!
怎么在django项目里面创建一个个app:
命令行创建应用
python38 manage.py startapp 应用名
-------------------------
pycharm创建应用
新建django项目可以默认创建一个 并且自动注册
-----------------------------------
.
.
.
.
.
注意:一定要去settings.py中注册!!!!!
除非是一开始创建项目的时候自带的一个app已经注册好了
否则其他创建的app应用文件
一定要去settings.py中注册后,才能生效!!!
------------------------------------------
否则浏览器一打开网址就报错:
TemplateSyntaxError
xxxx is not a registered tag library
------------------------------------------
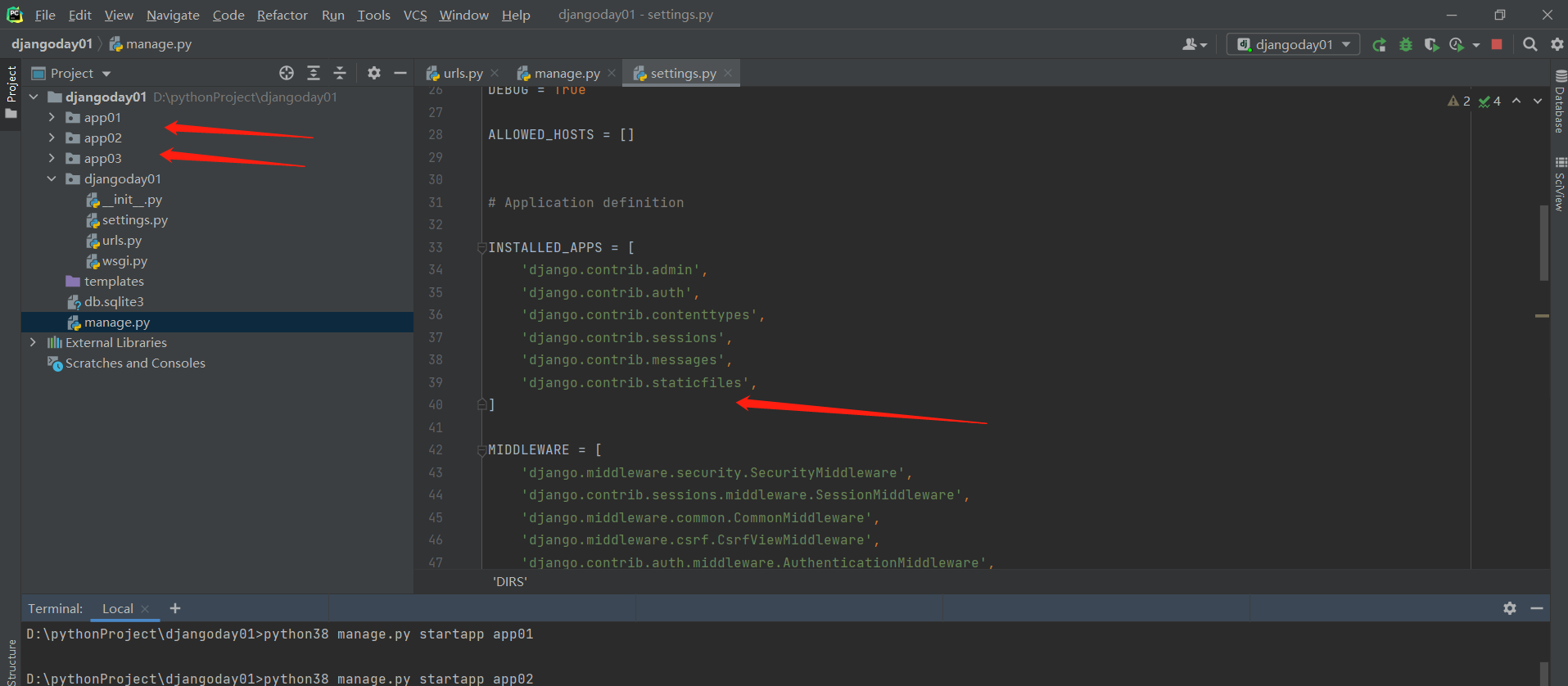
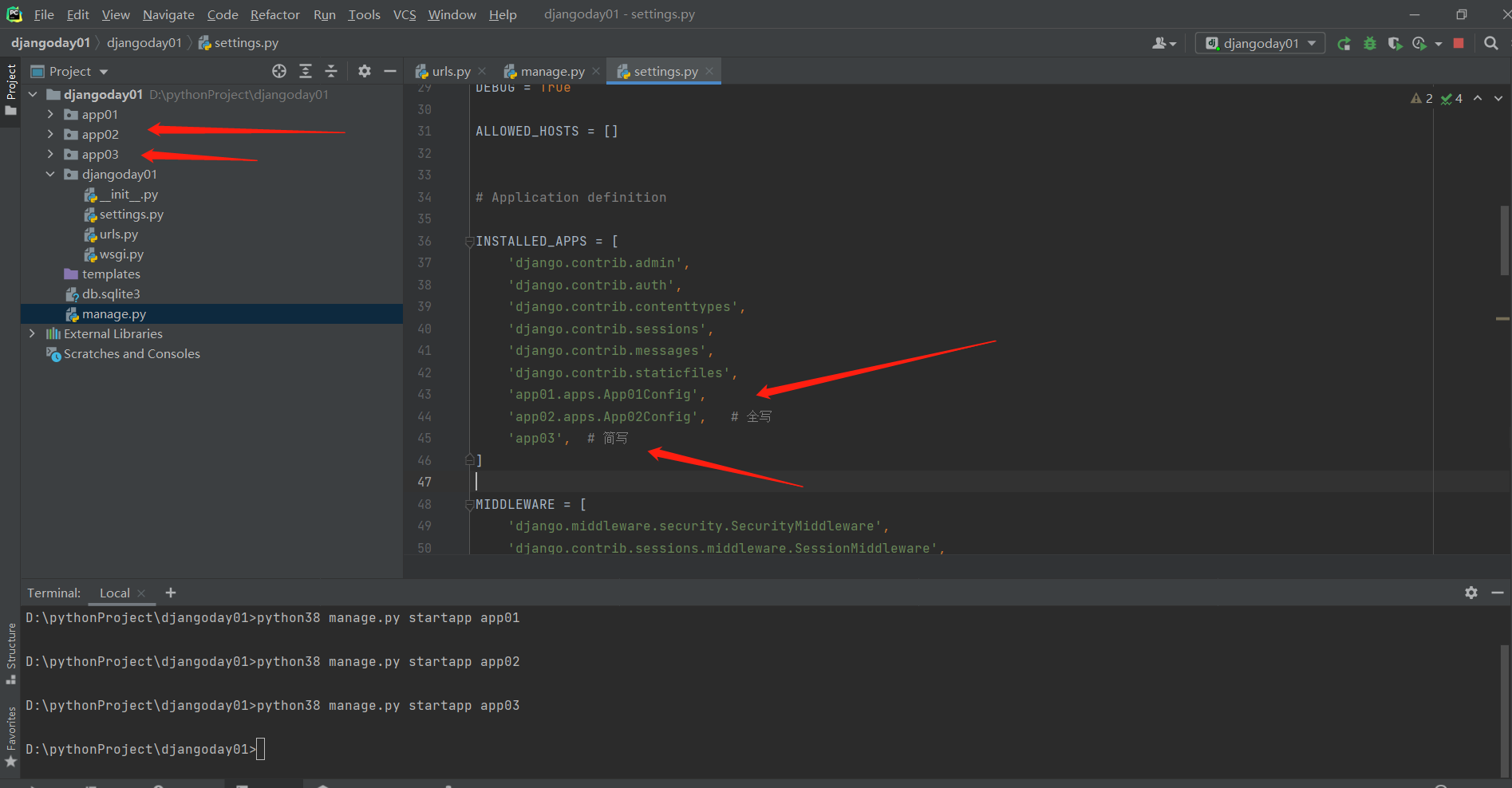
INSTALLED_APPS = [
'app01.apps.App01Config',
'app02.apps.App02Config',
'app03'
]
-----------------------------------------------
命令行创建应用 python38 manage.py startapp app01
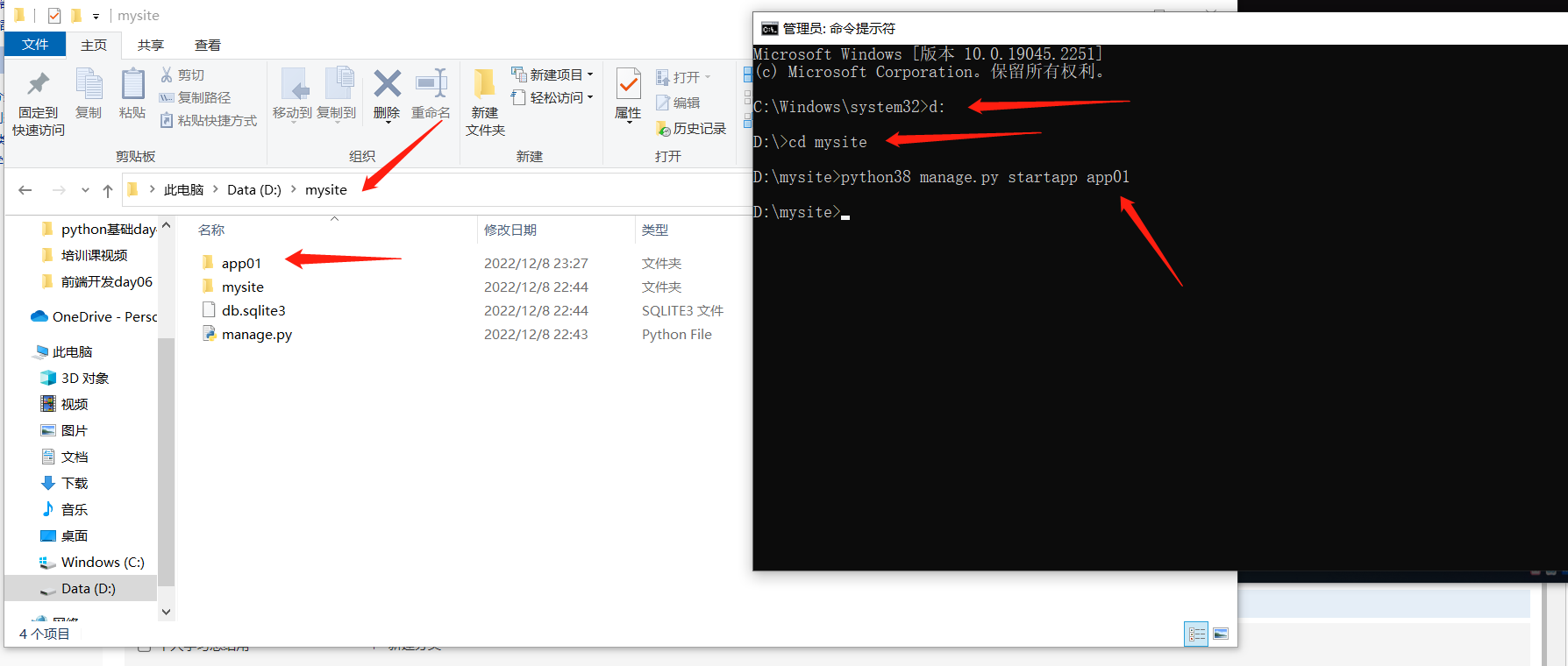
.
pycharm创建应用 terminal 里面敲命令 python38 manage.py startapp app01
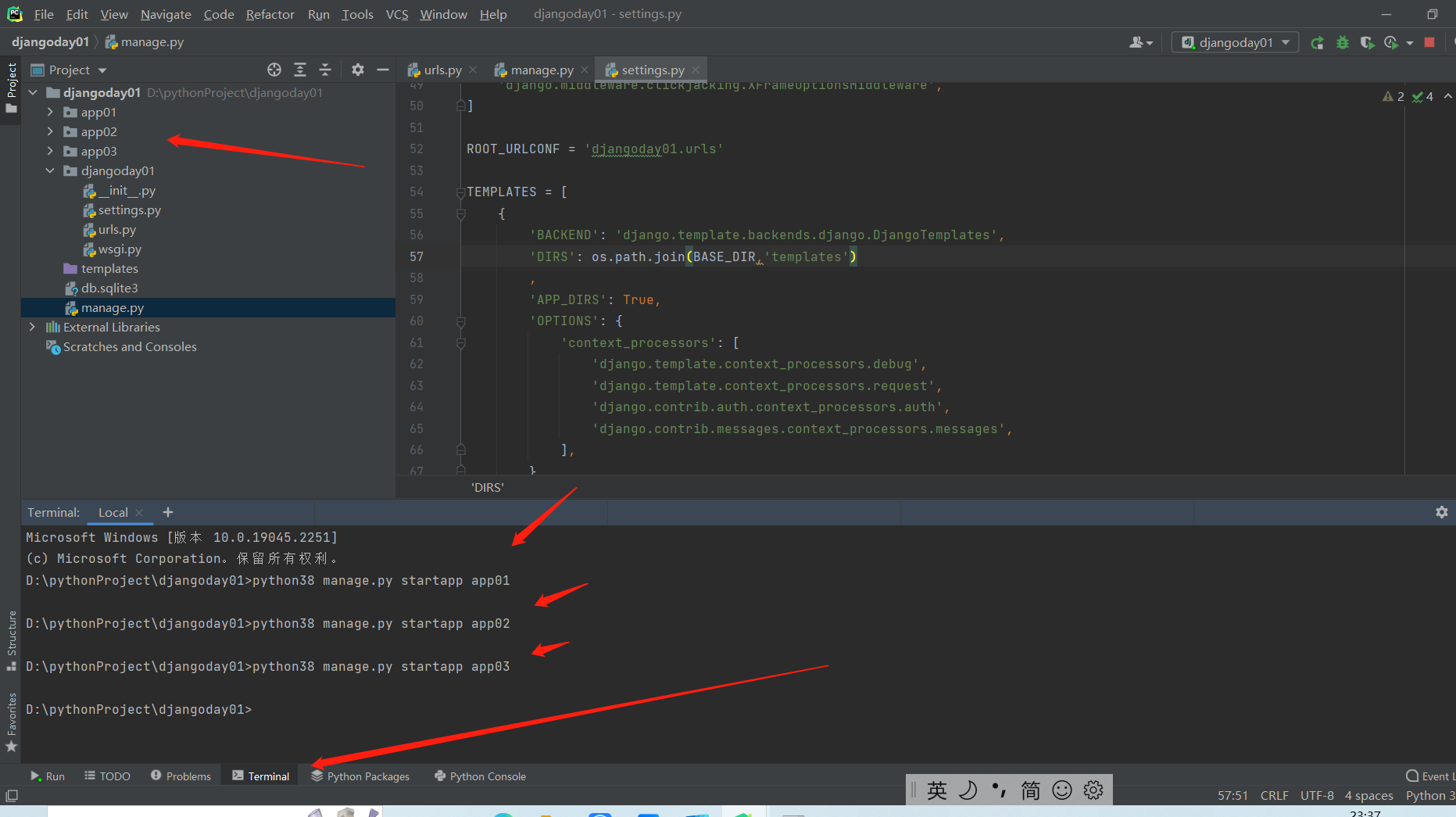
.
创建django项目的时候,也可以支持创建一个app,但只能创一个
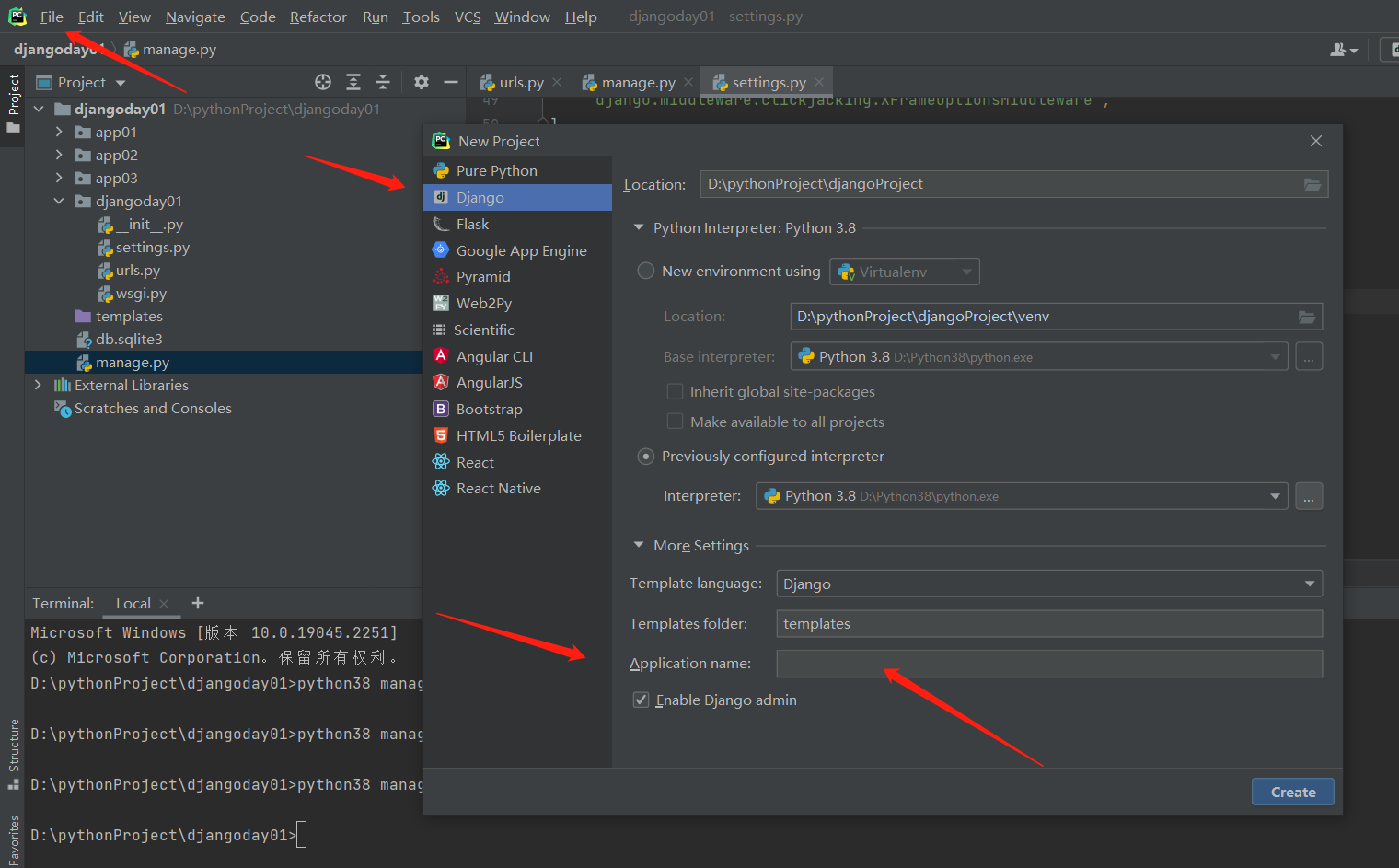
.
.
.
还有一个简单的创app的方法,有快捷命令,暂时不熟不要用!!!
.
.
.
.
.
django主要目录结构
django项目目录名(文件夹名)
-------------------------------------------------------
django项目同名目录
settings.py 配置文件
urls.py 存储网址后缀与函数名对应关系(不严谨)
wsgi.py wsgiref网关文件
------------------------------------------
db.sqlite3文件 django自带的小型数据库(项目启动之后才会出现)
------------------------------------------
manage.py 入口文件(命令提供)
------------------------------------------
app应用目录
migrations目录 存储数据库相关记录
admin.py django内置的admin后台管理功能
apps.py 注册app相关
models.py 与数据库打交道的(非常重要!!)
tests.py 测试文件
views.py 存储功能函数(不严谨)
-------------------------------------------
templates目录 存储html文件(命令行创建项目时,不会自动创建templates目录 pycharm会)
可以在命令行里面手动创一个
切换的项目文件夹下,输入命令 mkdir templates 就能创建一个文件夹了
-------------------------------
mkdir 文件夹名 cmd固定命令 在对应的目录下创文件夹
------------------------------
配置文件中还需要配置路径
'DIRS': [os.path.join(BASE_DIR,'templates'),]
--------------------------------------------
"""
网址后缀 路由
函数 视图函数
类 视图类
------------------------------------
重要名词讲解
urls.py 路由层
views.py 视图层
models.py 模型层
templates 模板层
"""
---------------------------------------------
.
.
.
.
django小白必会三板斧
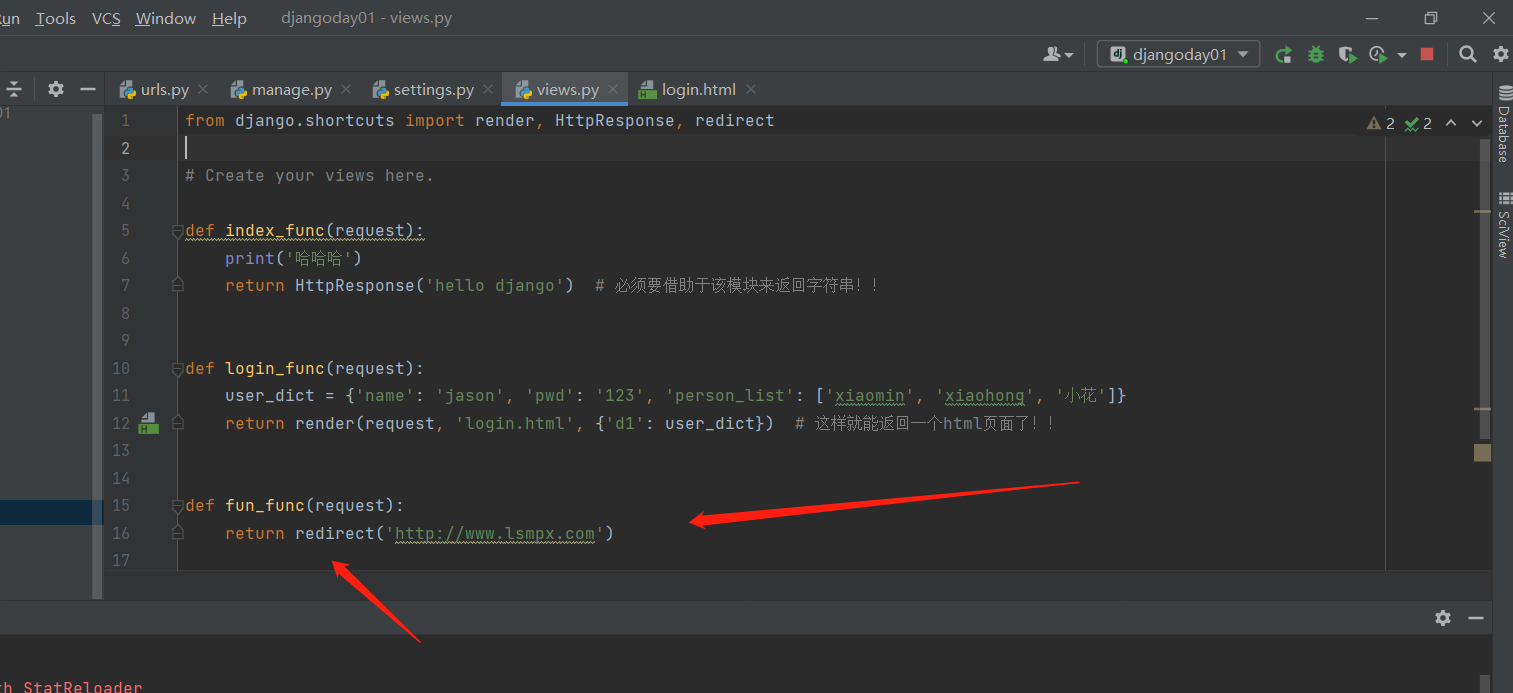
HttpResponse 负责 返回字符串类型的数据
render 负责 返回html页面并且支持传值
redirect 负责 重定向可以到指定的网址,也能到自己的网址!!
-------------------------------------------
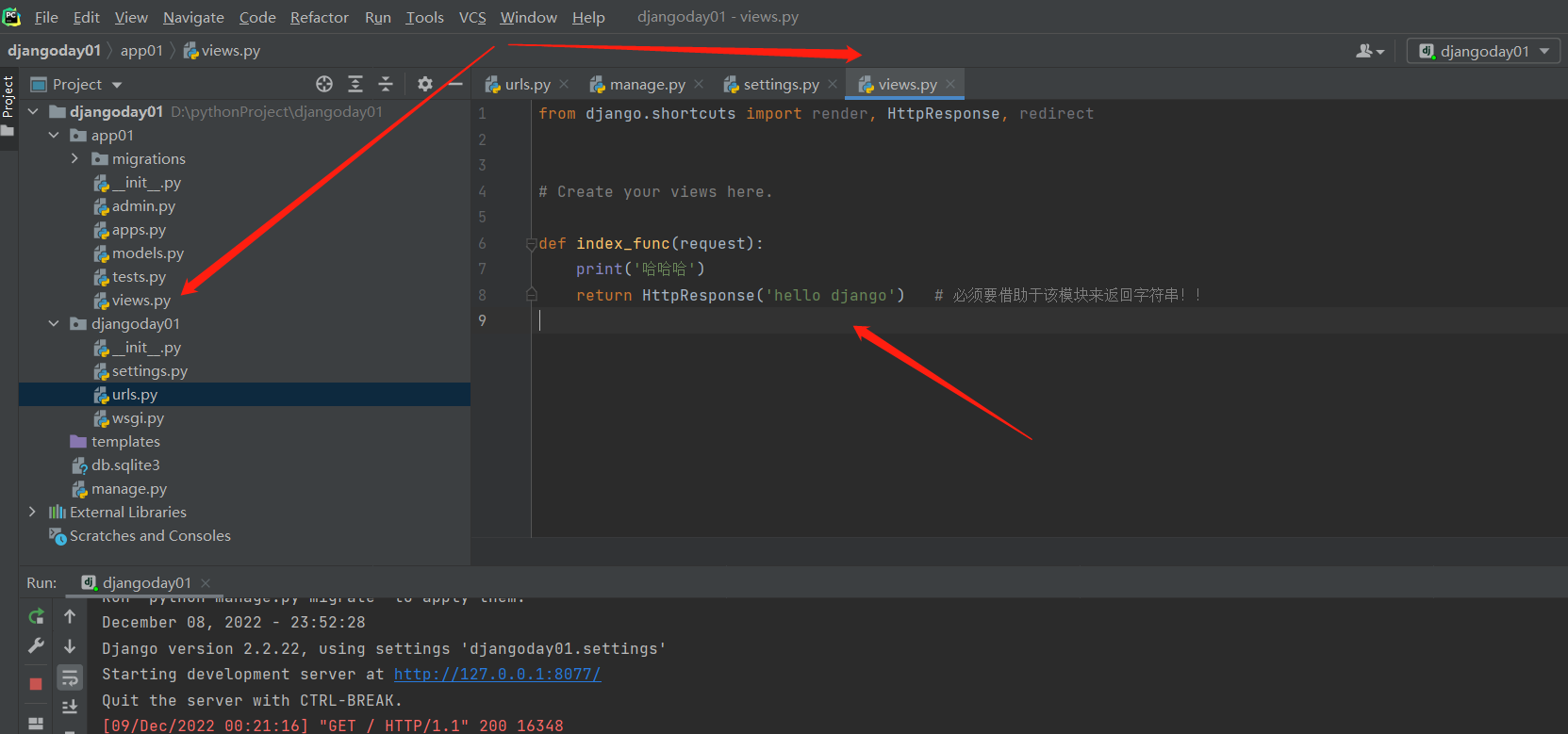
views.py 文件
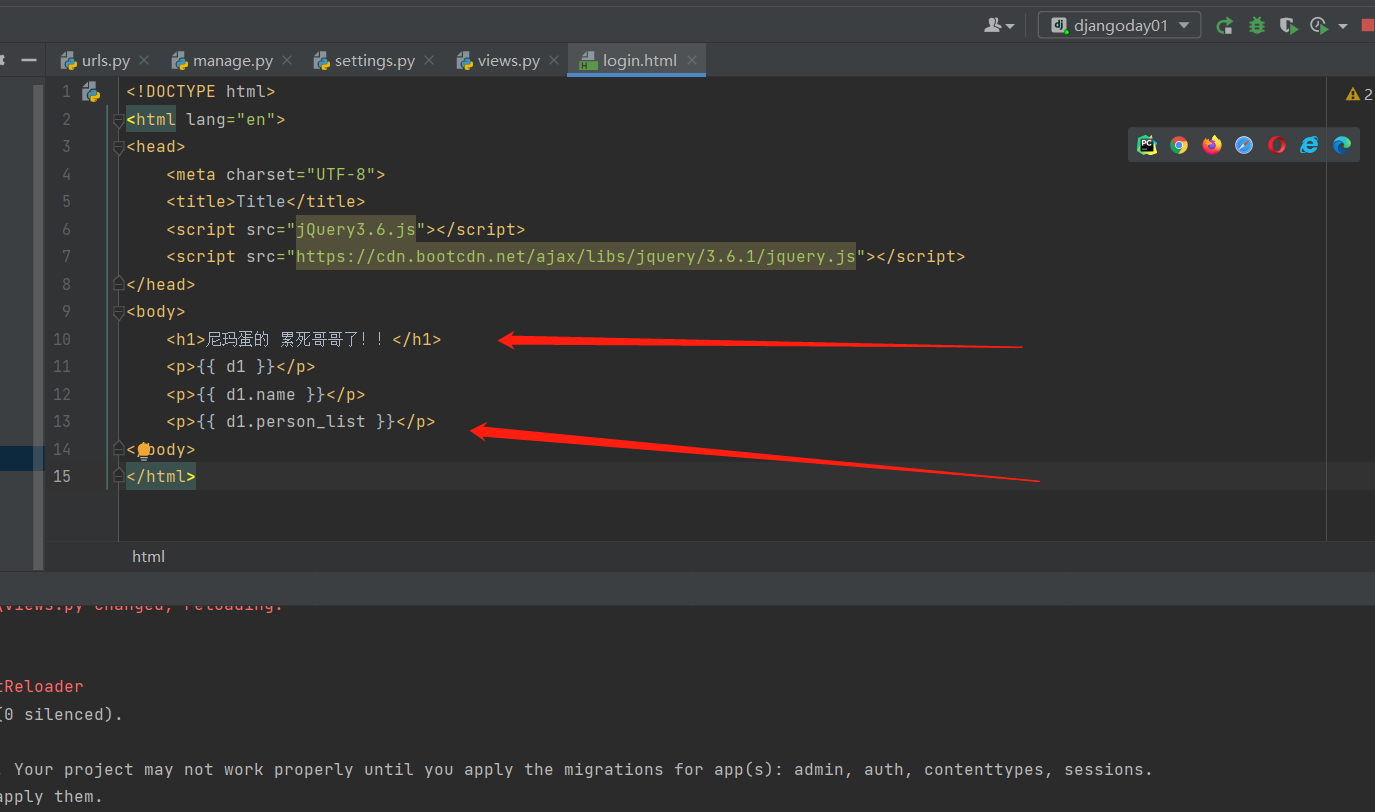
from django.shortcuts import render,HttpResponse,redirect
# Create your views here.
def index_func(request):
print('哈哈哈')
return HttpResponse('hello django') # 必须要借助于该模块来返回字符串!!
------------------------------------------
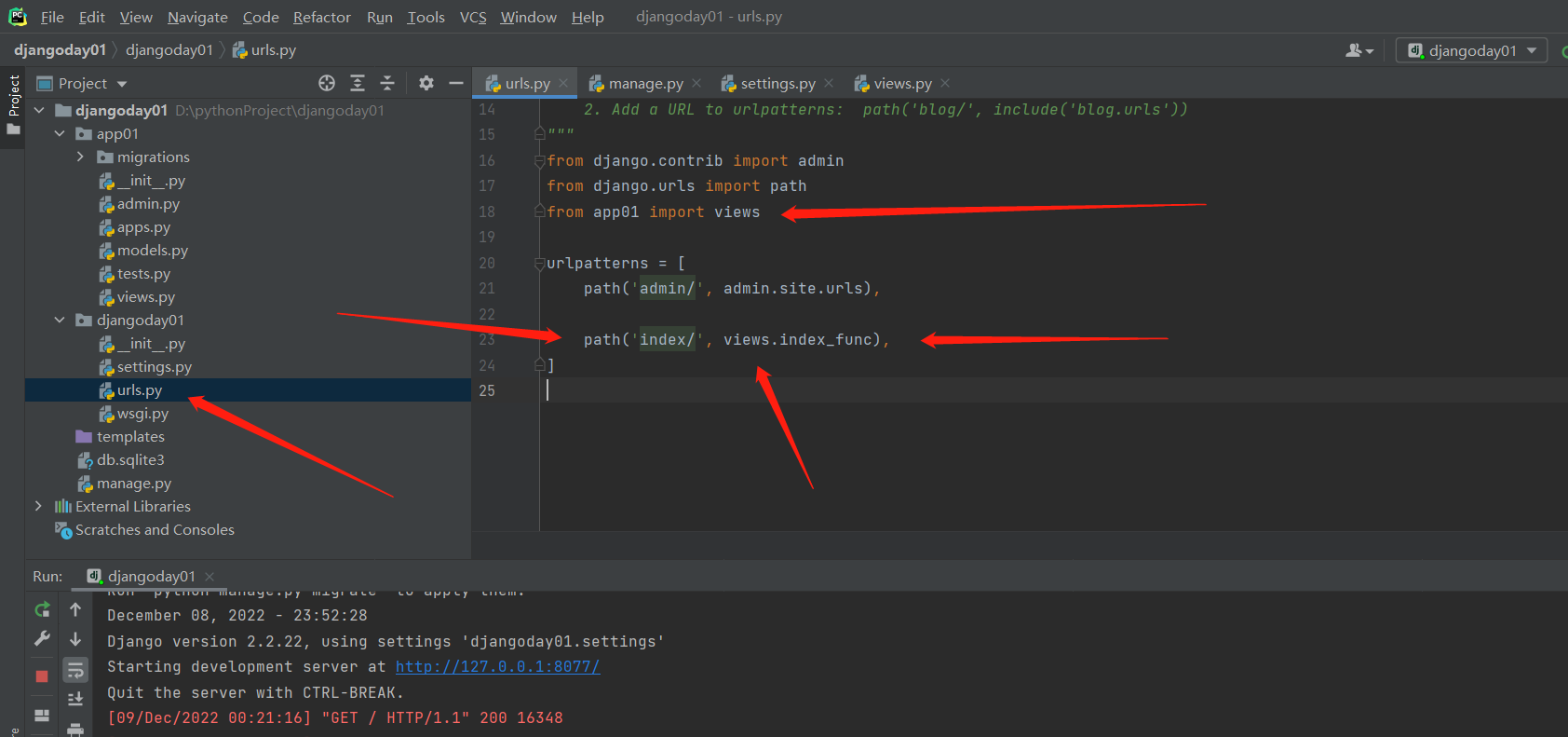
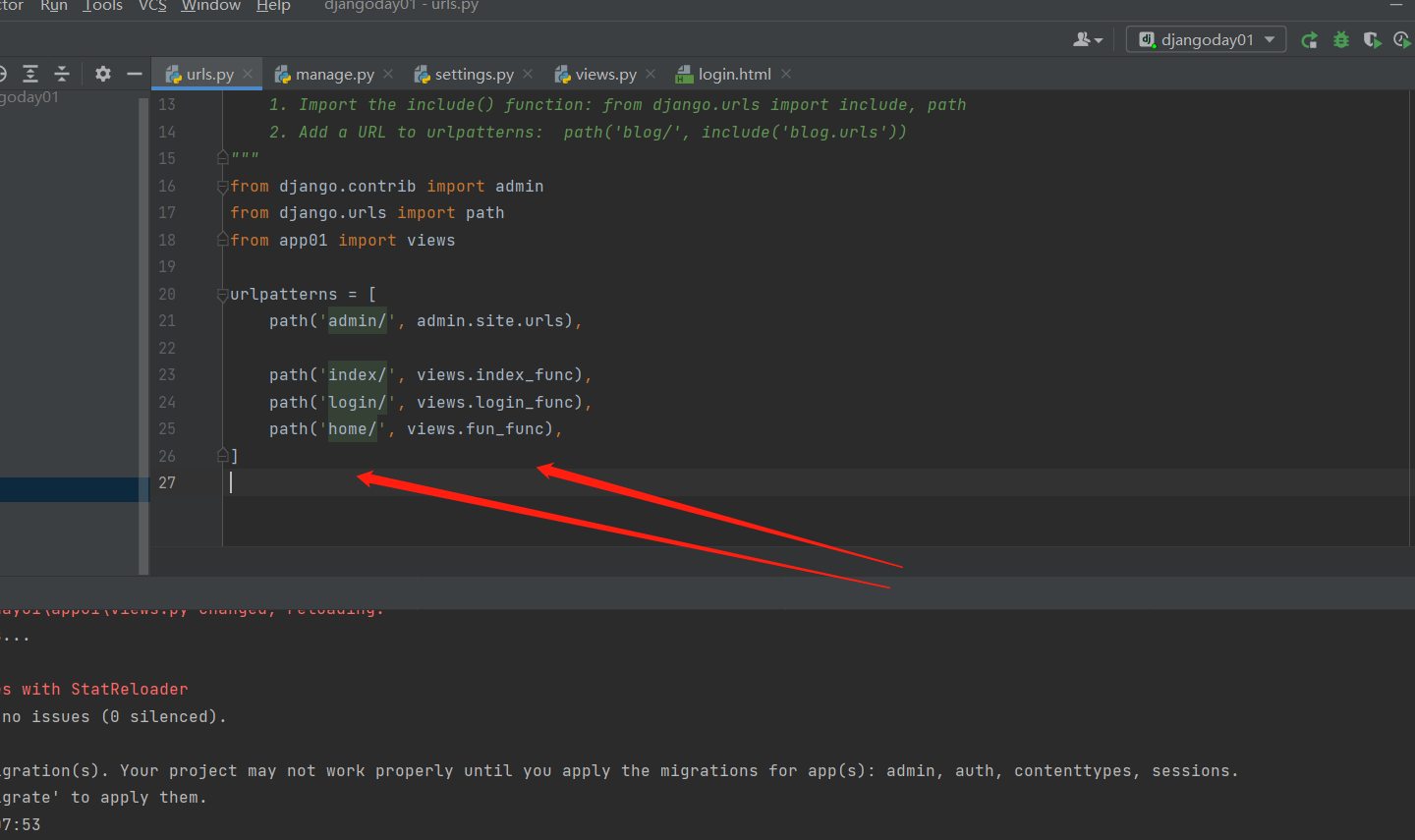
项目目录下的urls.py 文件
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('index/', views.index_func),
]
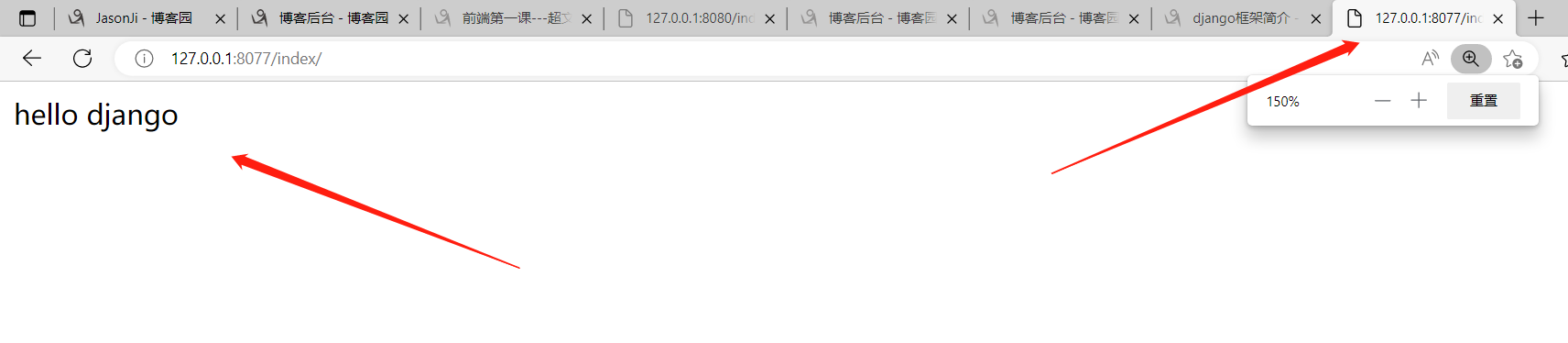
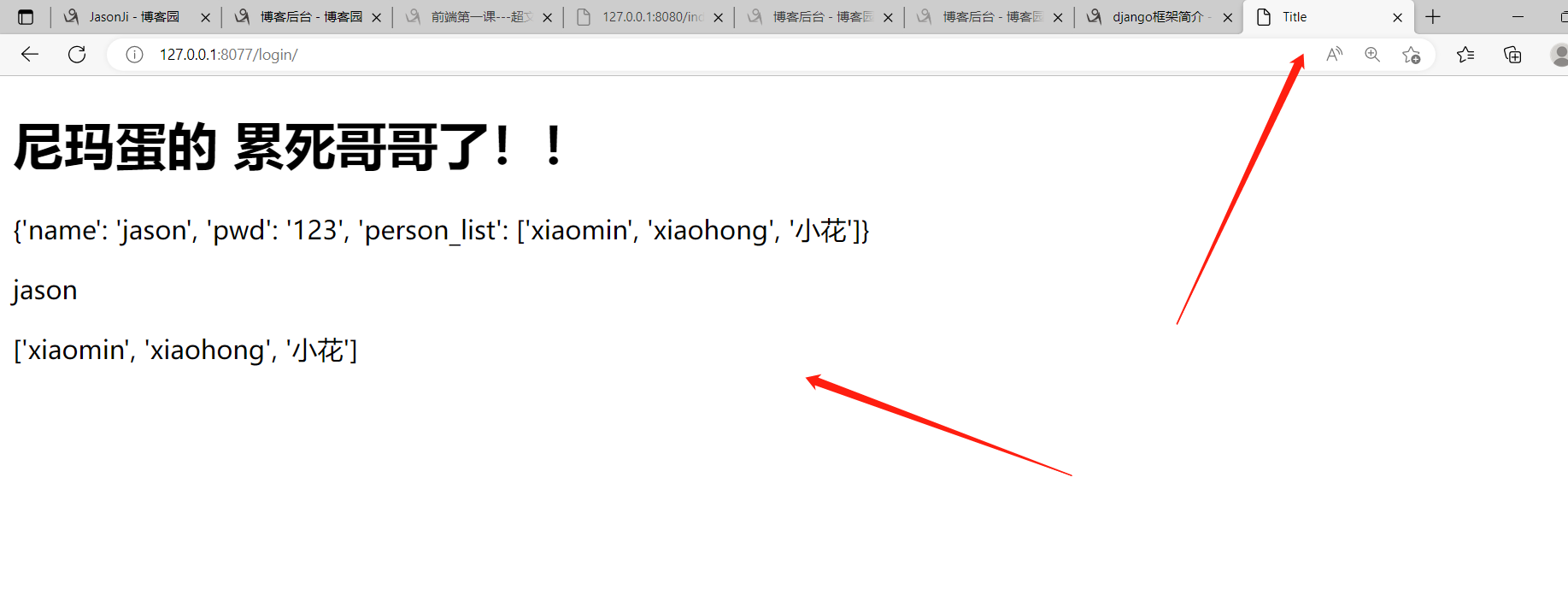
这两个文件一些 在浏览器里面输入ip端口/index 就能看到hello django 了!!!
--------------------------------------
.
.
.
.
.
.
.
.

.
重定向到自己的网址:重定向到自己的网址时,就可以简写,写上需要跳转的对应的路由就行了!!

.
.
.
作业
1.整理今日及博客
2.尝试使用django完成数据库数据展示
.
.
.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY