python三十八期--多进程实现TCP服务端并发,互斥锁代码实操,线程理论,创建线程的多种方式等等
上周内容回顾
-
同步与异步
任务的提交方式 同步 任务提交之后原地等待任务的结果期间不做任何事 异步 任务提交之后不原地等待任务的结果(异步回调机制) -
阻塞与非阻塞
进程的执行状态 阻塞 阻塞态 非阻塞 就绪态 运行态 -
创建进程的多种方式
进程:正在运行的程序 注意不同操作系统创建的底层原理 windows mac\linux -
进程间数据默认隔离
同一台计算机上多个进程之间数据默认隔离 -
IPC机制
消息队列:支持数据存放与获取 打破进程间数据隔离的规定 -
进程join方法
主进程代码等待子进程代码运行结束之后再继续执行 -
进程对象诸多方法
1.进程号 current_process().pid os.getpid()\os.getppid() 2.终止进程 terminate() 3.判断进程是否存活 is_alive() 4.守护进程 是否存活取决于守护的对象 5.僵尸进程与孤儿进程 -
生产者与消费者模型
生产者 消息队列 消费者 -
互斥锁的概念
将并发/并行变成串行 牺牲了效率但是提升了数据的安全
今日内容概要
- 多进程实现TCP服务端并发
- 互斥锁代码实操
- 线程理论
- 创建线程的多种方式
- 线程join方法
- 守护线程
- 线程诸多方法
- GIL全局解释器锁
今日内容详细
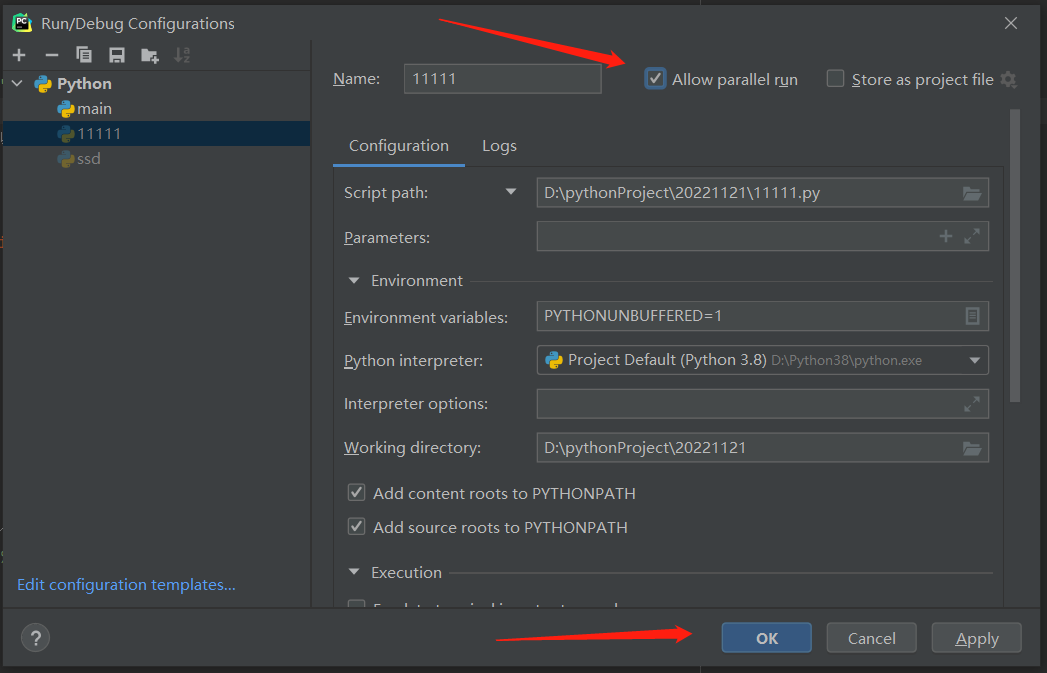
如何让客户端文件执行多次的方法,勾上允许平行运行!!!点击apply 再点击ok 就行了!!!

.
.
.
.
.
.
多进程实现TCP服务端并发的效果!!!
单进程原始代码:
服务端代码:
import socket
server = socket.socket() # 产生socket对象(具有一定功能与数据的东西)
server.bind(('127.0.0.1', 8080)) # 绑定要连接的端口
server.listen(5) # 设置监听端口的状态,设立半连接池
while True:
sock, addr = server.accept() # 链接循环
while True: # 通信循环
data = sock.recv(1024) # 收消息
print(data.decode('utf8'))
sock.send(data.upper()) # 把收到的消息转成大写再发回去!!!
---------------------------------------------------
客户端代码:
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
client.send(b'hello baby') # 先发消息给服务端
data = client.recv(1024) # 再收服务端的消息
print(data)
想让服务端做成多进程,这样其他的客户端也能与服务端进行同步的交流了!!!
也就是现在帮我运行服务端的只有一个人,现在想要多个人,每个人都运行一个服务端!!!
最好就是有几个客户端,就来几个服务端!!!
.
.
.
.
.
.
服务端优化后
(将通信循环代码放到子进程要执行的代码里面去)代码:
# 实现了服务端一个ip与端口,可以满足多个客户端与它通信
import socket
from multiprocessing import Process
def get_server():
server_obj = socket.socket()
server_obj.bind(('127.0.0.1', 8080))
server_obj.listen(5)
return server_obj
def get_talk(sock):
# 通信循环
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
if __name__ == '__main__':
server_obj = get_server()
# 连接循环
while True:
sock, addr = server_obj.accept()
# 开设多进程去聊天
p = Process(target=get_talk, args=(sock,))
p.start()
这样每出现一个客户端进行连接请求后,服务端主进程这边一旦接受连接请求后,
随即开设一个子进程,子进程里面运行通信循环的代码,这样每个客户端都可以连接上服务端,
并且服务端给每个客户端都开了子进程运行通信循环代码,与客户端互动起来了!!!
-------------------------------------------------------
优化思路:
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
注意这3行代码一定要封装起来,为什么了?
因为现在要开多进程,代码会重上往下再次执行,但服务端这几行代码是不能执行两次的!!!
因为'127.0.0.1', 8080 这个ip地址同一时间只能绑定一个服务!!!
-------------------------------------------------------
.
.
.
.
.
.
.
.
互斥锁代码实操
------------------------------------
mutex:互斥锁
Only one task may hold the mutex at a time, and only this task can unlock the mutex.
一次只能有一个任务持有互斥锁,并且只有这个任务可以解锁互斥锁。
-----------------------------------------
互斥锁的作用:将并发变成串行,牺牲了效率,但是保证了数据的安全!!
互斥锁:锁不能滥用,建议只加在操作数据的部分,否则整个程序的效率会极低!!!
-------------------------------------
还是就模拟文件里面只有一张票的情况:{"ticket_num":1}
-------------------------------------
from multiprocessing import Process, Lock
import time
import json
import random
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s查看票 目前剩余:%s' % (name, data.get('ticket_num')))
def buy(name):
# 先查询票数
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 买票
if data.get('ticket_num') > 0:
with open(r'data.json', 'w', encoding='utf8') as f:
data['ticket_num'] -= 1
json.dump(data, f)
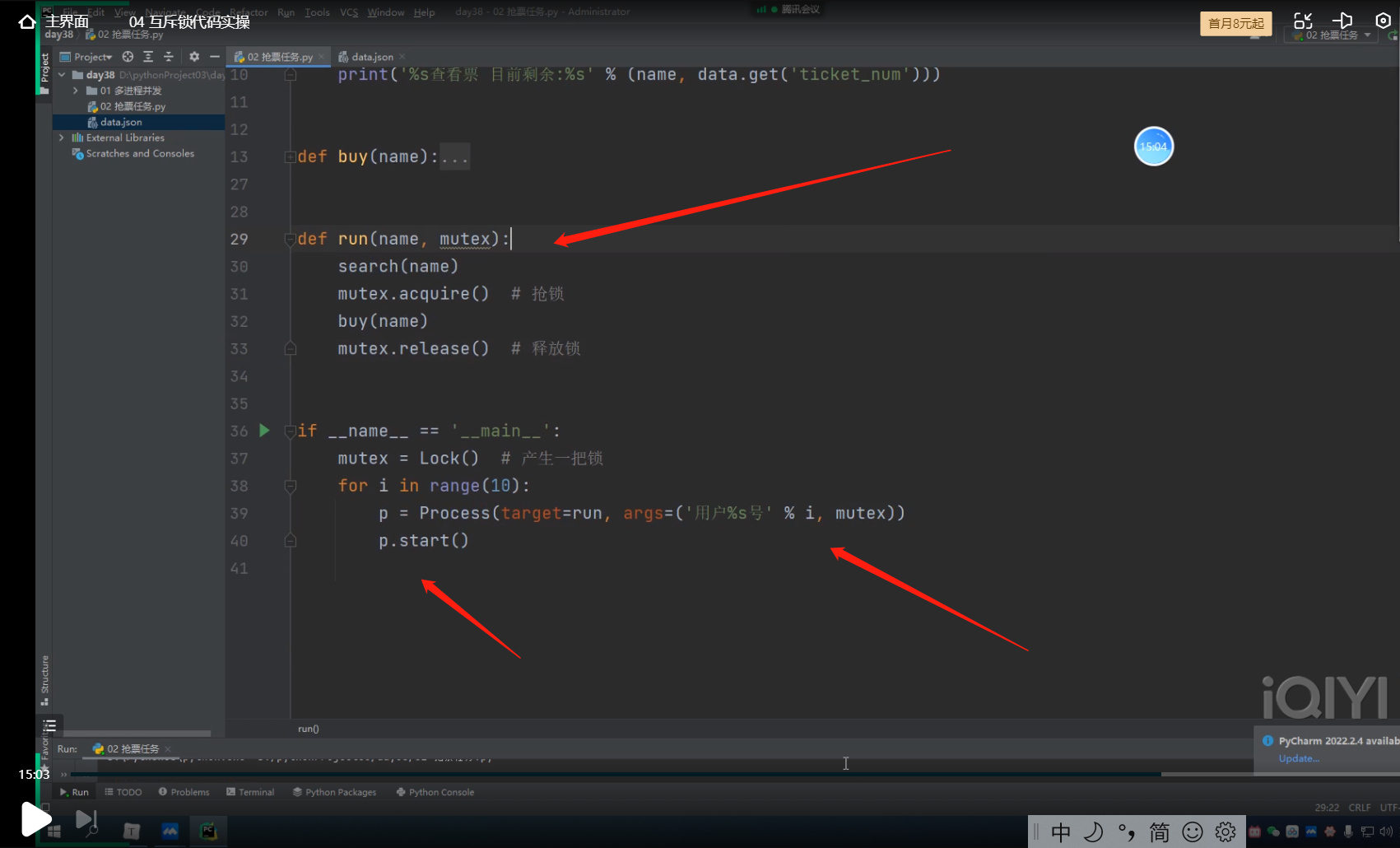
print('%s 买票成功' % name)
else:
print('%s 买票失败 非常可怜 没车回去了!!!' % name)
def run(name, mutex):
search(name)
mutex.acquire() # 抢锁操作,抢到锁才能运行下面的代码,没抢到,就只能等再次抢锁
buy(name)
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock() # 1. 产生一把锁
for i in range(10):
p = Process(target=run, args=('用户%s号' % i, mutex))
p.start()
-------------------------------------------------
mutex = Lock() 会产生一把锁,但是10个同时开启的子进程却不能同时拿到这把锁,
谁先mutex.acquire()抢到这把锁后,才能去运行抢锁下面的代码,没抢到锁就只能停下等待,
当第一个抢到锁的子进程将抢锁下面的代码运行完毕后,会将该锁释放出去,
这个时候其他的子进程再次进行抢锁操作,谁抢到就可以运行抢锁下面的代码。
依此类推,直到最后一个子进程都拿到锁运行完抢锁下面的代码,整个抢锁的操作才算结束!!!
---------------------------------------------------
锁在用的时候,只应该加在操作数据的代码上面,其他的代码部分不要加,会影响效率!!
比如我们自己写的抢票软件,抢锁操作就不应该放在查票函数的上面!!!
因为让查票功能都要抢锁没有必要,完全可以让子进程先将该功能代码运行掉!!!
---------------------------------------------------
.
.
.
.
.
.
.
.
.
线程理论
# 可以简单的理解,进程是运行的程序,线程是该运行的程序中的每一个任务!!!
-----------------------------------------------------
# 进程是操作系统资源分配的最小单元。
线程是操作系统能够进行运算调度的最小单元。它被包含在进程中,是进程中实际运行的单位。
-----------------------------------------------------
# 进程: 进程其实是资源单位,表示一块内存空间,之前的多进程操作其实就是在申请多个内存空间
# 进程的本质:PCB(Process Control Block),类似于java中的类,
# 每一个PCB对象就代表着一个实实在在运行着的程序,也就是进程。
-----------------------------------------------------
# 线程: 线程才是执行单位,表示真正的代码指令
------------------------------------------------------
我们可以将进程比喻是车间 线程是车间里面的流水线
一个进程内部至少含有一个线程
1.一个进程内可以开设多个线程
2.同一个进程下的多个线程数据是共享的
3.创建进程与线程的区别:创建进程的资源消耗要远远大于线程!!!
-----------------------------------------------------
.
.
.
.
.
.
创建线程的两种方式
创建子线程的方式1代码
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(10)
print(f'{name} is over')
"""
创建线程无需考虑反复执行的问题
"""
t = Thread(target=task, args=('jason',))
t.start() # 创建一个子线程然后运行task函数,也是一个异步操作
print('主线程')
-------------------------------------------
.
.
.
.
.
创建子线程的方式2代码
class MyThread(Thread):
def run(self): # run里面写你要创建的子线程里要执行的代码!!!
print('run is running')
time.sleep(1)
print('run is over')
obj = MyThread()
obj.start()
print('主线程')
.
.
.
.
.
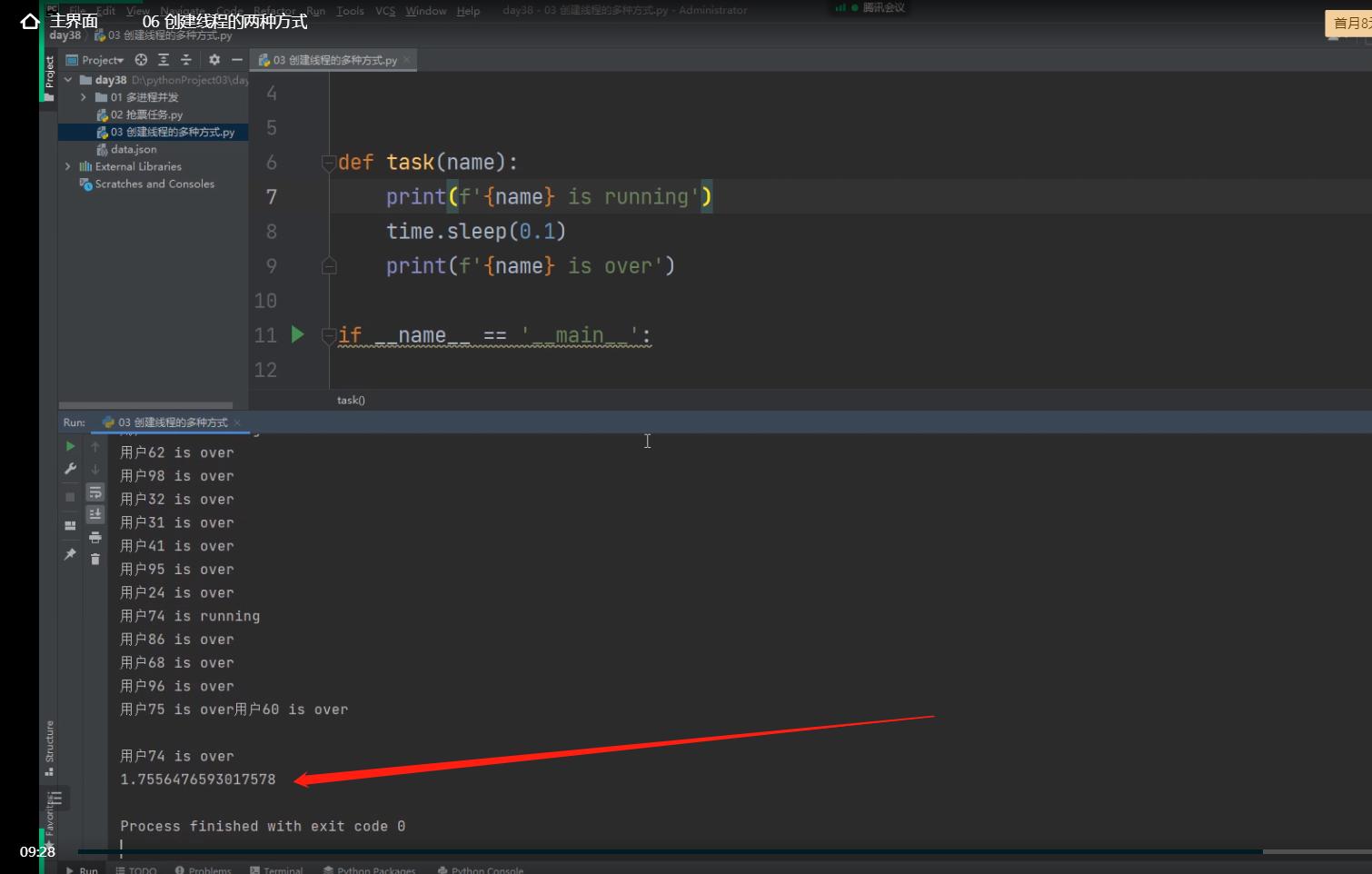
比较创建多进程与创建多线程,代码运行的快慢
创建100个进程所耗时:
----------------
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(0.1)
print(f'{name} is over')
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(100):
p = Process(target=task, args=('用户%s'%i,))
p.start() # 先让每个进程运行起来
p_list.append(p) # 此处如果p.join,就变成了所有子进程串行了!!!
for p in p_list:
p.join() # 主进程代码等待,每一个子进程都要运行结束后才能运行主进程代码,但是因为每一个进程都在运行,等一个进程实际上就是等所有的子进程!!!
print(time.time() - start_time)
1.75s左右就能创100个进程,
-------------------------------------------
-------------------------------------------
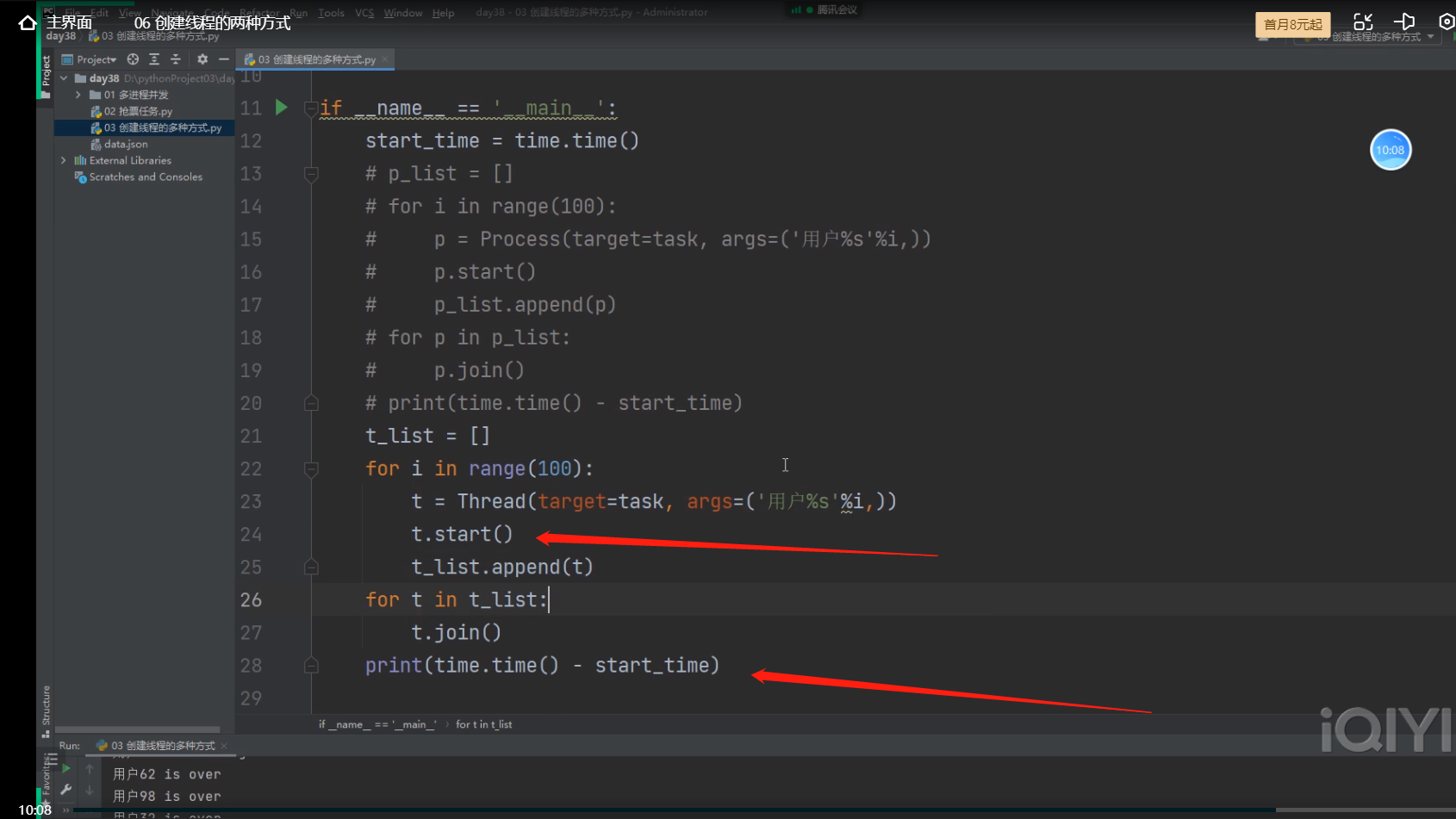
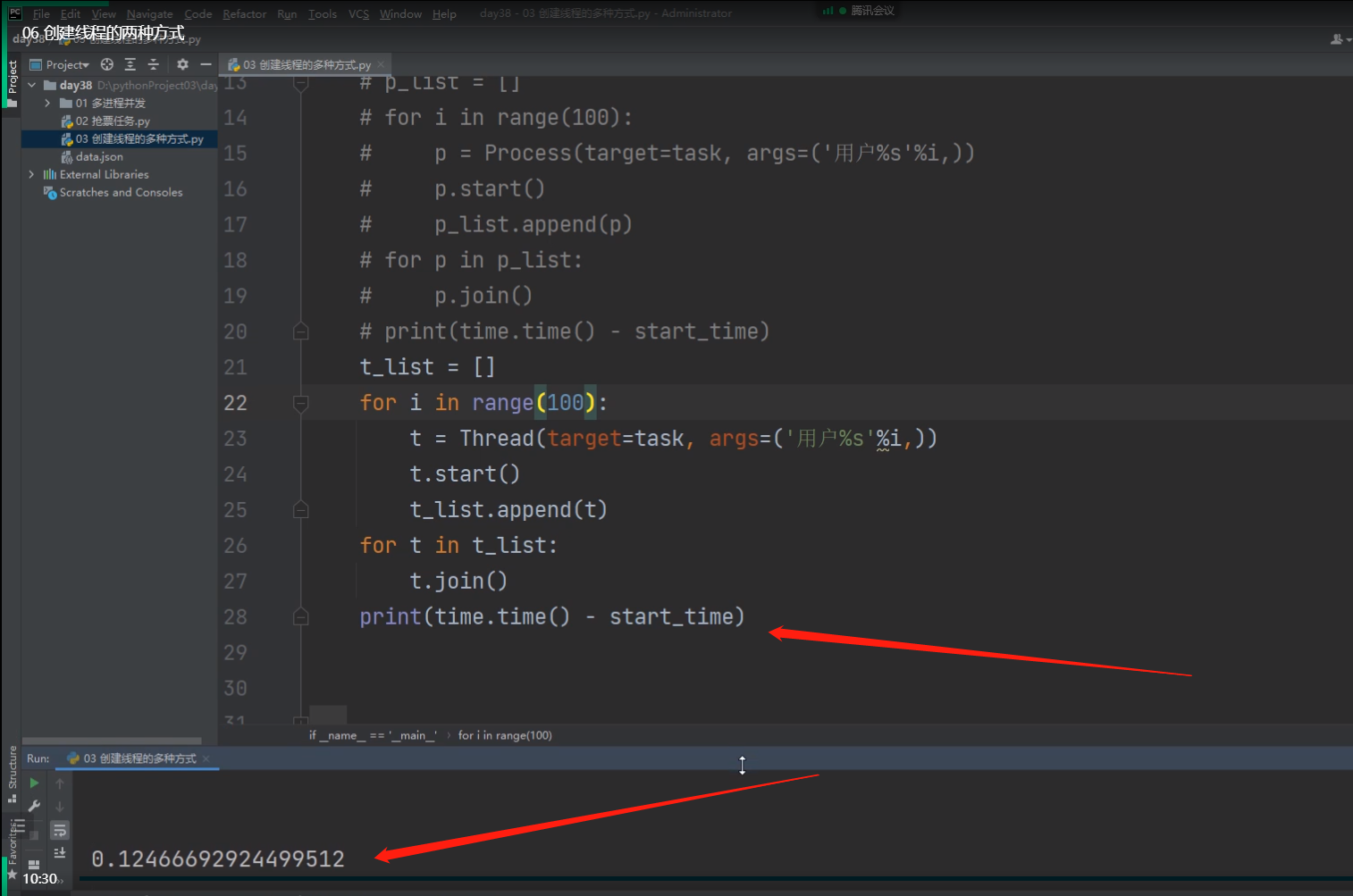
创建100个线程所耗时:
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(0.1)
print(f'{name} is over')
if __name__ == '__main__':
t_list = []
for i in range(100):
t = Thread(target=task, args=('用户%s'%i,))
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(time.time() - start_time)
0.12s 100个线程就创好了
-------------------------------------------
-------------------------------------------
创建100个进程所需要的时间
.
.
创建100个线程所需要的时间
.
.
.
.
.
.
.
线程的诸多特性
1.线程的join方法,主线程代码等待子线程代码运行结束再往下运行!!!
(和线程的join方法特性一样)
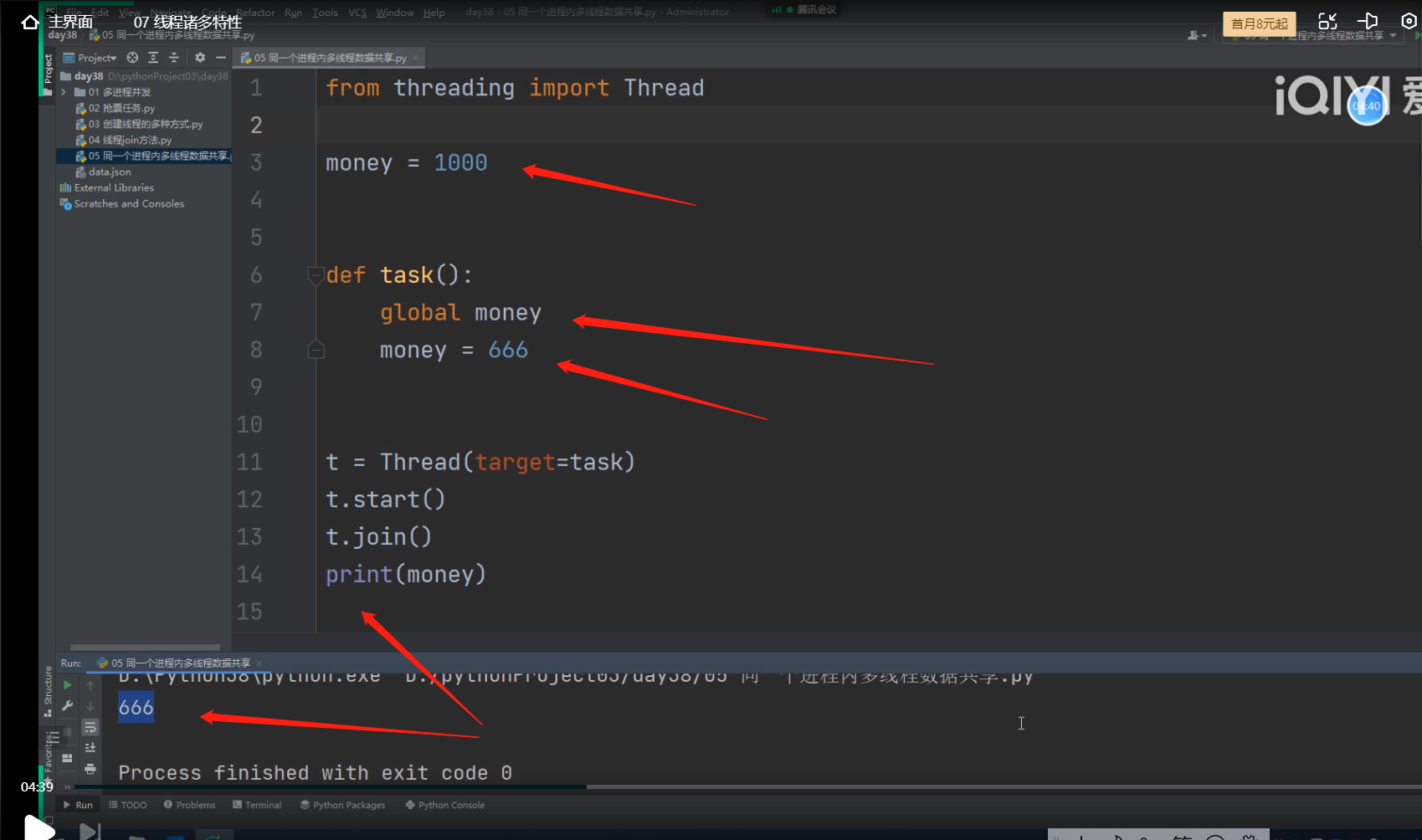
2.同一个进程内多个线程数据共享!!!
3.current_thread().name # 查看进程下的线程名
4.active_count() # 查看进程下的线程数
同一个进程内多个线程数据共享,所以子线程将主线程里面的全局变量money的值改了,
主线程与子线程都在一个进程里面,都在一个内存空间内。
.
.
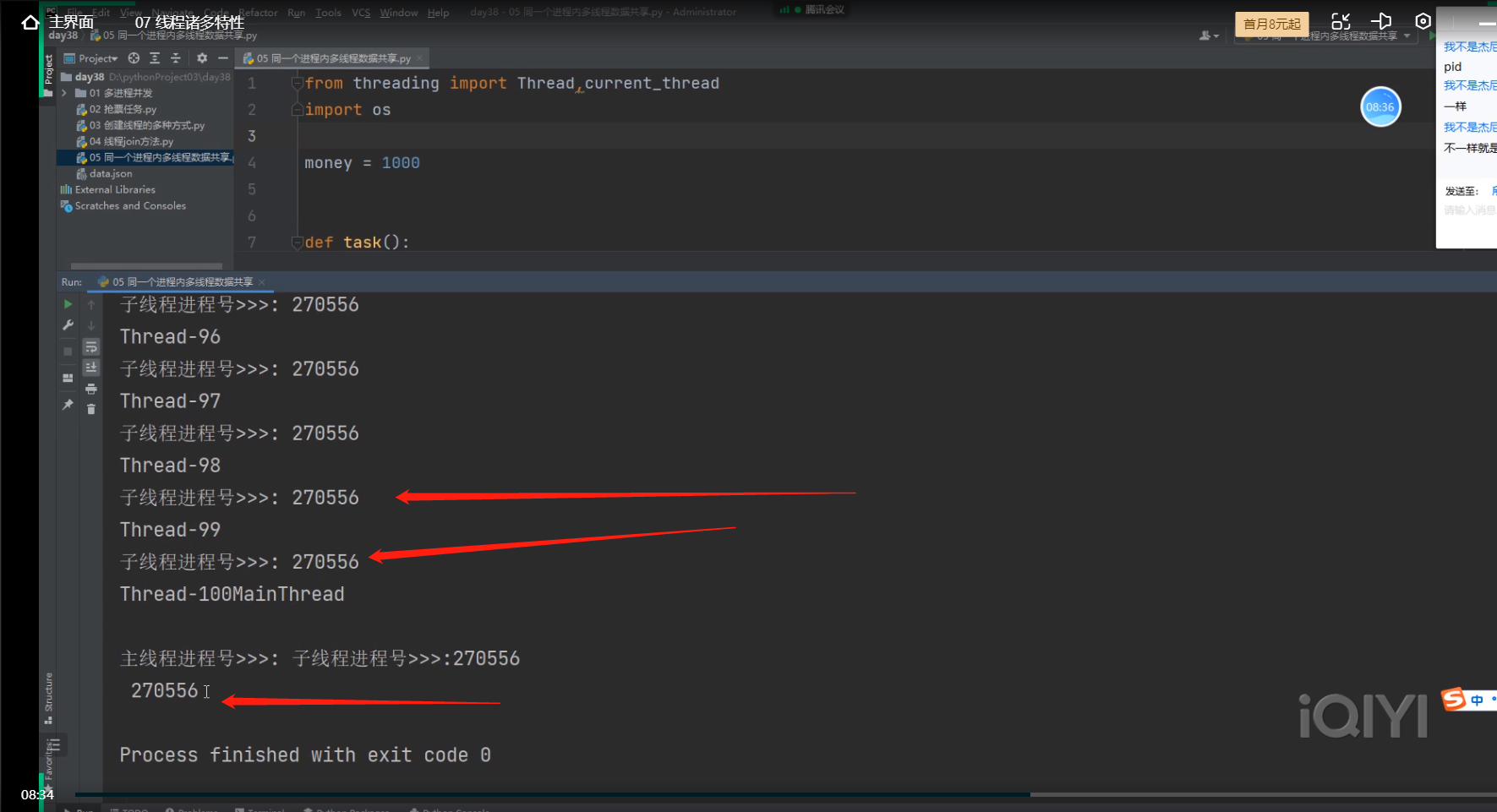
同一个进程下开设的多个线程,拥有相同的进程号。
这个地方打印的有点错乱
Tread-100后面应该是子线程进程号>>>:270556
然后下一行是
MainThread
主线程进程号>>>:270556
.
.
.
.
.
.
多线程实现TCP服务端的并发
和多进程实现TCP服务端的并发的代码几乎一样,
就把开设子进程的代码变成开设子线程的代码,就改两行代码就行了!!
from threading import Thread
import time
def task(name):
print('子线程>>德邦总管:%s' % name)
time.sleep(3)
print('子线程>>德邦总管:%s' % name)
if __name__ == '__main__':
t1 = Thread(target=task, args=('大张红',))
t1.daemon = True # 将t1这个线程做成主线程的守护线程!!!
p1.start()
time.sleep(1)
print('主线程>>恕瑞玛皇帝:小吴勇嗝屁了')
守护线程随着被守护的线程(主线程) 的结束而结束!!
.
.
.
.
.
.
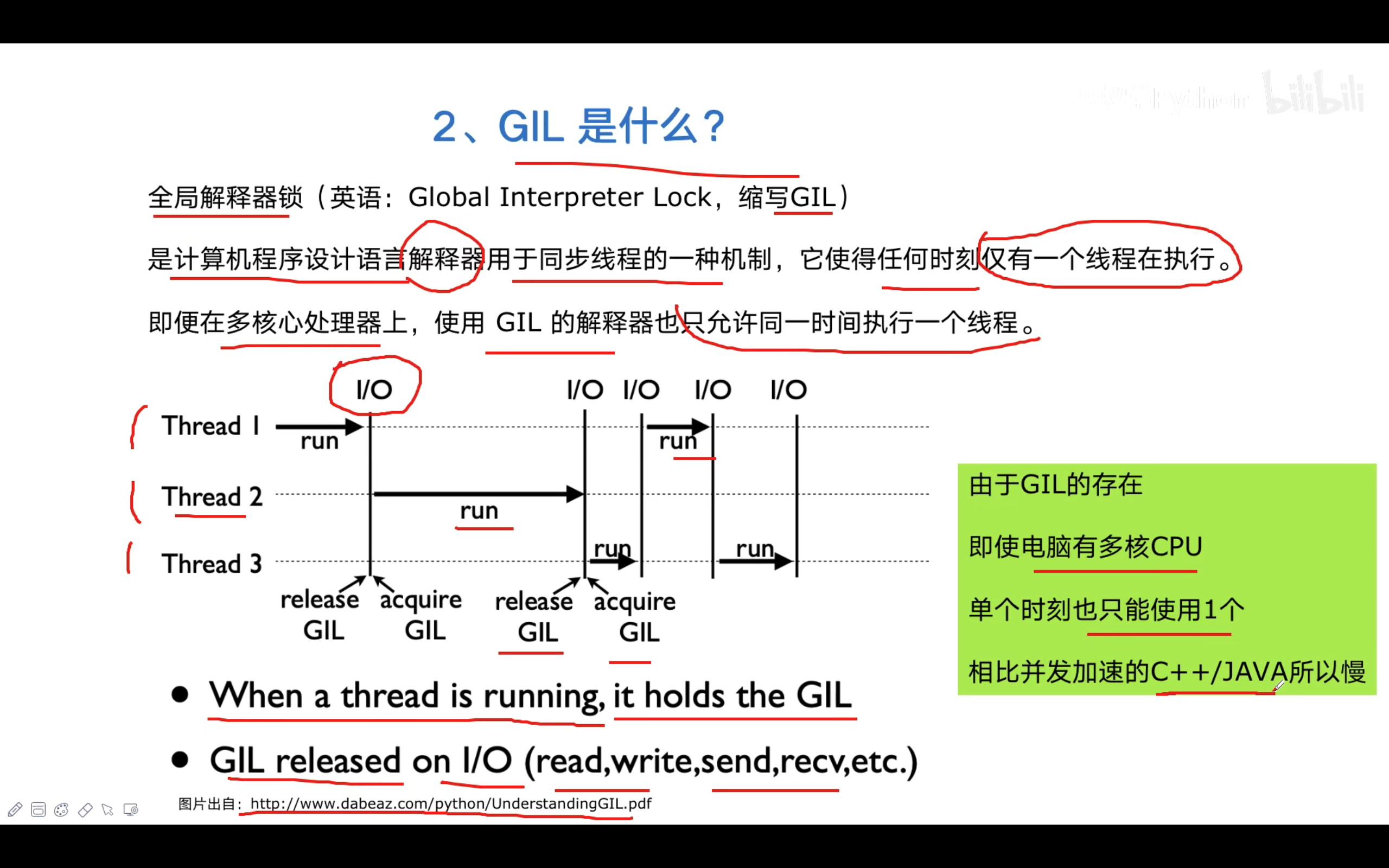
GIL全局解释器锁(global interpreter lock)
------------------------------------------------
# python中 GIL 让同一个进程里面的多个线程无法同时执行,所以即使有多核,
同一时间也只有一个cpu在运行
# 如果在其他语言里,同一个进程里面,有多个线程,只有有多核,是可以多个线程一起运行的!!!
------------------------------------------------
同一进程内,每个线程在执行的过程中都需要先获取GIL,
作用就是 使得在同一进程内,任何时刻仅有一个线程在执行。
由于GIL的存在,在Python上开启多个线程时,每个线程都会在竞争到GIL后 才会运行,
所以同一时刻,同一个进程里,只有一个线程在运行,所以只有一个cpu在运行
GIL的准则:
1.当前执行线程必须持有GIL
2.当线程遇到 IO的时、时间片到时, 才会释放GIL
------------------------------------------------
# python解释器有很多类型
CPython JPython PyPython (常用的是CPython解释器)
2.GIL本质也是一把互斥锁,用来阻止同一个进程内多个线程同时执行!!!
( 也就意味着python开多线程和没开多线程差不多,因为同一时间只有一个cpu在工作
之所以我们感觉开了多线程,速度变快了,是因为cpu的多道技术,不停的切换,与保存状态,
让我感觉好多个线程是一起运行的。)
3.GIL的存在是因为CPython解释器中针对多线程,无法保存数据的安全(垃圾回收机制)
垃圾回收机制(自动帮我们删一些数据):引用计数、标记清除、分代回收
每一个python进程都会配有一个垃圾回收机制的线程
-----------------------------------------------
-----------------------------------------------
GIL的存在,会规定同一个进程下,多个线程不能同时执行,线程必须要先抢这把GIL互斥锁,
然后才能通过解释器让cpu去运行,目的只有一个,保证垃圾回收机制的线程删数据的安全,
# 关键原因:
线程抢到锁后,除非进入IO操作了cpu才会切换,
垃圾回收机制的线程才能有机会抢锁,执行垃圾回收功能,
不可能出现,一个线程使用解释器创建数据时,还没绑定变量的间隙,
垃圾回收机制的线程也运行起来,把刚刚的线程创的没来的及绑定的数据,
根据引用计数为0当做垃圾清除掉了,导致数据值丢失。
.
.
.
.
.
.
.
.
关于GIL全局解释器锁的面试常见问题
描述Python GIL的概念, 以及它对Python多线程的影响?
编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
-----------------
回答:
GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程运行。
GIL全局解释器锁是cpython解释器的特性,和python这门语言是没有关系的!!!
多线程爬取比单线程性能有提升,因为有多道技术遇到IO阻塞会自动释放GIL锁,
爬取数据io操作偏多
io密集型用多线程是性能有提升
# 所有解释型语言,垃圾回收线程与代码执行线程,都要有锁,来解决线程同时执行的问题。
.
.
.
.
.
.
.
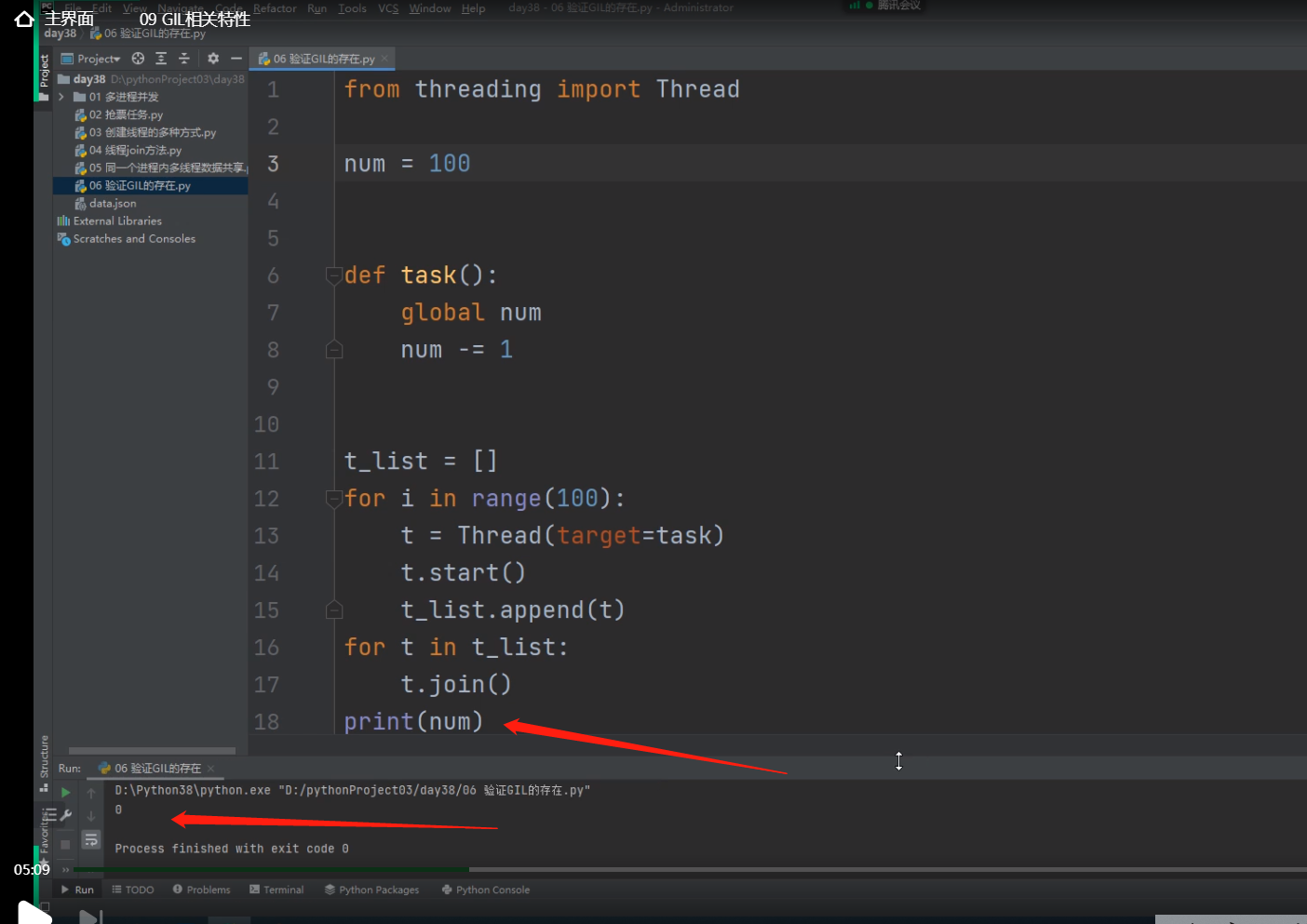
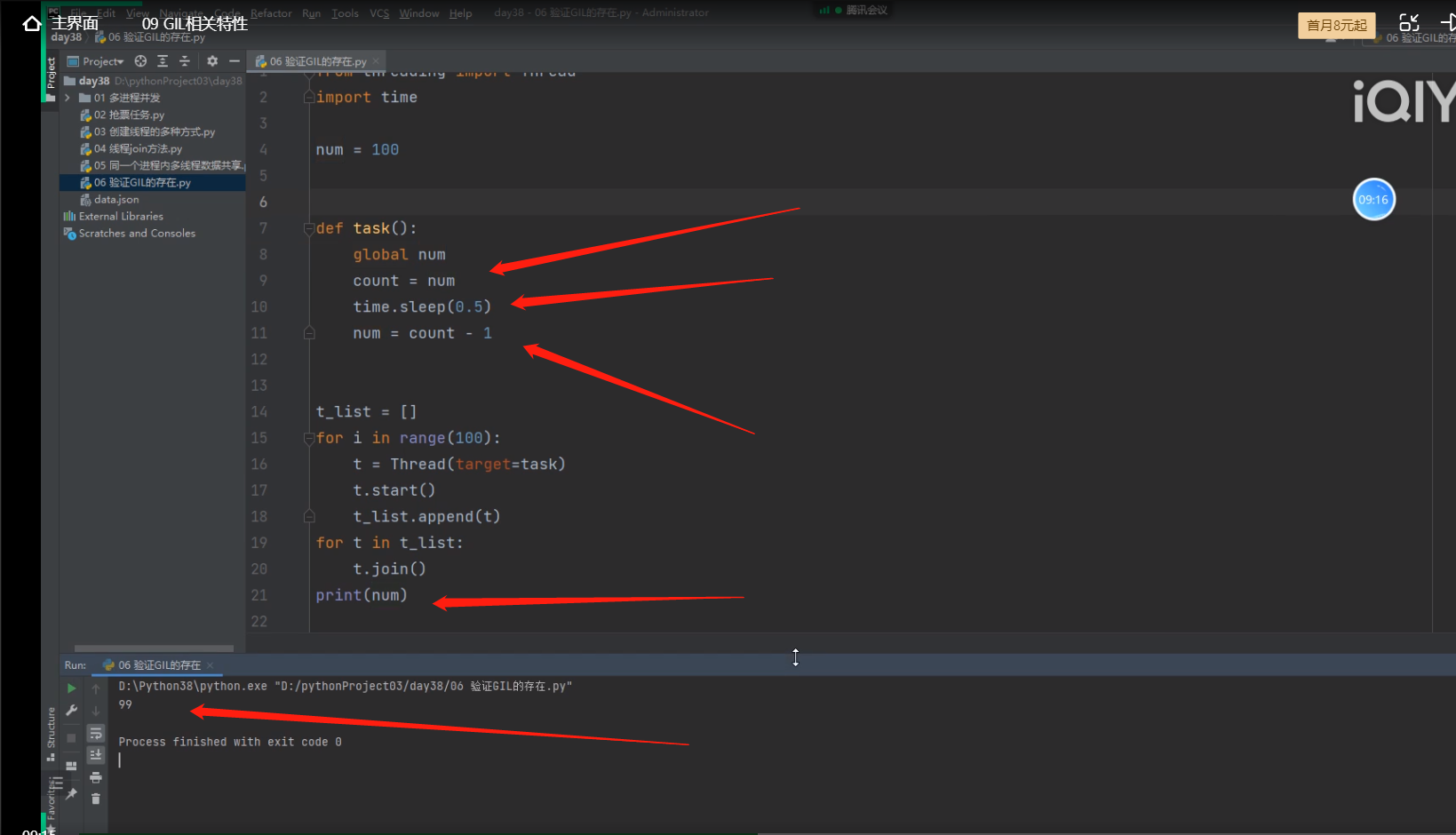
验证GIL的存在
from threading import Thread
num = 100
def task():
global num
num -= 1
t_list = []
for i in range(100): # 同时创了100个子进程
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list: # 同时给100个子线程运行join方法
t.join() # 让主线程同时等待所有子线程代码运行结束,再运行主线程代码
print(num)
# 由于有GIL的存在,同一时间只有一个子线程可以持有GIL并被cpu运行,
# 所以全局的num会被每一个抢到GIL的子线程运行task函数,将num减1 ,
# 这样100个子线程都抢完锁后,num就被减了100次1,所以结果就是0了
.
from threading import Thread
import time
num = 100
def task():
global num
count = num
time.sleep(0.5)
num = count - 1
t_list = []
for i in range(100): # 同时创了100个子进程
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list: # 同时给100个子线程运行join方法
t.join() # 让主线程同时等待所有子线程代码运行结束,再运行主线程代码
print(num)
# 由于子线程time.sleep(0.5)有IO操作,所以cpu会切换,并且GIL同时也会释放,
# 这样100个子线程都抢完锁后,拿到的count都是100,这样最后所有的子线程代码运行结束后,
# 打印的num结果就是99了
.
.
.
.
GIL与普通互斥锁
既然CPython解释器中有GIL 那么我们以后写代码是不是就不需要操作锁了!!!
--------------------------
GIL只能够确保同进程内多线程数据不会被垃圾回收机制弄乱!!!
并不能确保程序里面的数据是否安全!!!
GIL只能够确保解释器级别的数据不会错乱,
并不能保证程序里面或者说代码层面的数据不会错乱!!!
所以针对不同的数据还是要加不同的锁!!!
--------------------------
import time
from threading import Thread,Lock
num = 100
def task(mutex):
global num
mutex.acquire()
count = num
time.sleep(0.1)
num = count - 1
mutex.release()
mutex = Lock()
t_list = []
for i in range(100):
t = Thread(target=task,args=(mutex,))
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(num)
# 现在这种情况,子线程抢到GIL锁后运行task函数,又抢到主线程里面产生的一个互斥锁,
# 当运行到sleep的时候,cpu会切换,GIL会释放,其他子线程会抢GIL,但是没有用,
# 因为刚刚的子线程没有释放mutex锁,所以其他子线程抢到GIL也没有用,
# 还是会因为无法运行释放掉GIL,所以刚刚 的子线程sleep睡完后,GIL还是会到它手上,
# 继续往下运行,当子线程将mutex锁释放掉,并且把GIL锁释放掉后,其他子线程才能抢GIL锁,
# 抢到GIL的子进程才能继续去抢mutex锁。
.
.
.
python多线程是否有用
在行业内python的多线程确实很垃圾
需要分情况
---------------------------------------
同一个进程内多个线程确实无法使用到多核优势,但并不是没有用
IO密集型的情况下,多核优势并不明显,多线程有用
计算密集型的情况下,多线程效率低,多核优势明显!!
----------------------------------------
情况:
IO密集型(代码有IO操作)
计算密集型(代码没有IO)
-----------------------------------------
1.单个CPU
IO密集型
多进程
申请额外的空间 消耗更多的资源
多线程
消耗资源相对较少 通过多道技术
ps:多线程有优势!!!
----
计算密集型
多进程
申请额外的空间 消耗更多的资源(总耗时+申请空间+拷贝代码+切换)
多线程
消耗资源相对较少 通过多道技术(总耗时+切换)
ps:多线程有优势!!!
--------------------------------------------
--------------------------------------------
2.多个CPU
IO密集型
多进程
总耗时(单个进程的耗时+IO+申请空间+拷贝代码)
多线程
总耗时(单个进程的耗时+IO)
ps:多线程有优势!!!
计算密集型
多进程
总耗时(单个进程的耗时)
多线程
总耗时(多个线程耗时的总和)
ps:多进程完胜!!!
----------------------------------------------
比较计算密集型的情况下,多核的情况下,多线程与多进程的耗时差异
from threading import Thread
from multiprocessing import Process
import os
import time
def work():
# 计算密集型
res = 1
for i in range(1, 100000):
res = res*i
-------------------------------------
if __name__ == '__main__':
print(os.cpu_count()) # 查看当前计算机能用的CPU个数 12个
start_time = time.time()
p_list = []
for i in range(12): # 一次性创建12个进程
p = Process(target=work)
p.start()
p_list.append(p)
for p in p_list: # 确保所有的进程全部运行完毕
p.join()
print('总耗时:%s' % (time.time() - start_time)) # 获取总的耗时
-------------------------------------
if __name__ == '__main__':
print(os.cpu_count()) # 查看当前计算机能用的CPU个数
start_time = time.time()
t_list = []
for i in range(12):
t = Thread(target=work)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('总耗时:%s' % (time.time() - start_time)) # 获取总的耗时
-------------------------------------
"""
计算密集型
多进程:5.665567398071289
多线程:30.233906745910645
"""
也就是说如果是计算密集型的情况,优先采用多进程,耗时较少!!!
.
.
.
.
比较IO密集型的情况下,多核的情况下,多线程与多进程的耗时差异
from threading import Thread
from multiprocessing import Process
import os
import time
def work():
time.sleep(2) # 模拟纯IO操作
if __name__ == '__main__':
start_time = time.time()
t_list = []
for i in range(100):
t = Thread(target=work)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('总耗时:%s' % (time.time() - start_time))
-------------------------
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(100):
p = Process(target=work)
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('总耗时:%s' % (time.time() - start_time))
--------------------------
"""
IO密集型
多线程:0.0149583816528320
多进程:0.6402878761291504
"""
也就是说如果是IO密集型的情况,采用多线程,耗时会少一点
.
.
.
.
死锁现象
锁处理的不好很容易导致整个程序的卡死!!!
mutex.acquire()
mutex.release()
------------------------
from threading import Thread,Lock
import time
mutexA = Lock() # 产生一把锁
mutexB = Lock() # 产生一把锁
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexB.acquire()
print(f'{self.name}抢到了B锁')
mutexB.release()
print(f'{self.name}释放了B锁')
mutexA.release()
print(f'{self.name}释放了A锁')
def func2(self):
mutexB.acquire()
print(f'{self.name}抢到了B锁')
time.sleep(1)
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexA.release()
print(f'{self.name}释放了A锁')
mutexB.release()
print(f'{self.name}释放了B锁')
for i in range(10):
obj = MyThread()
obj.start()
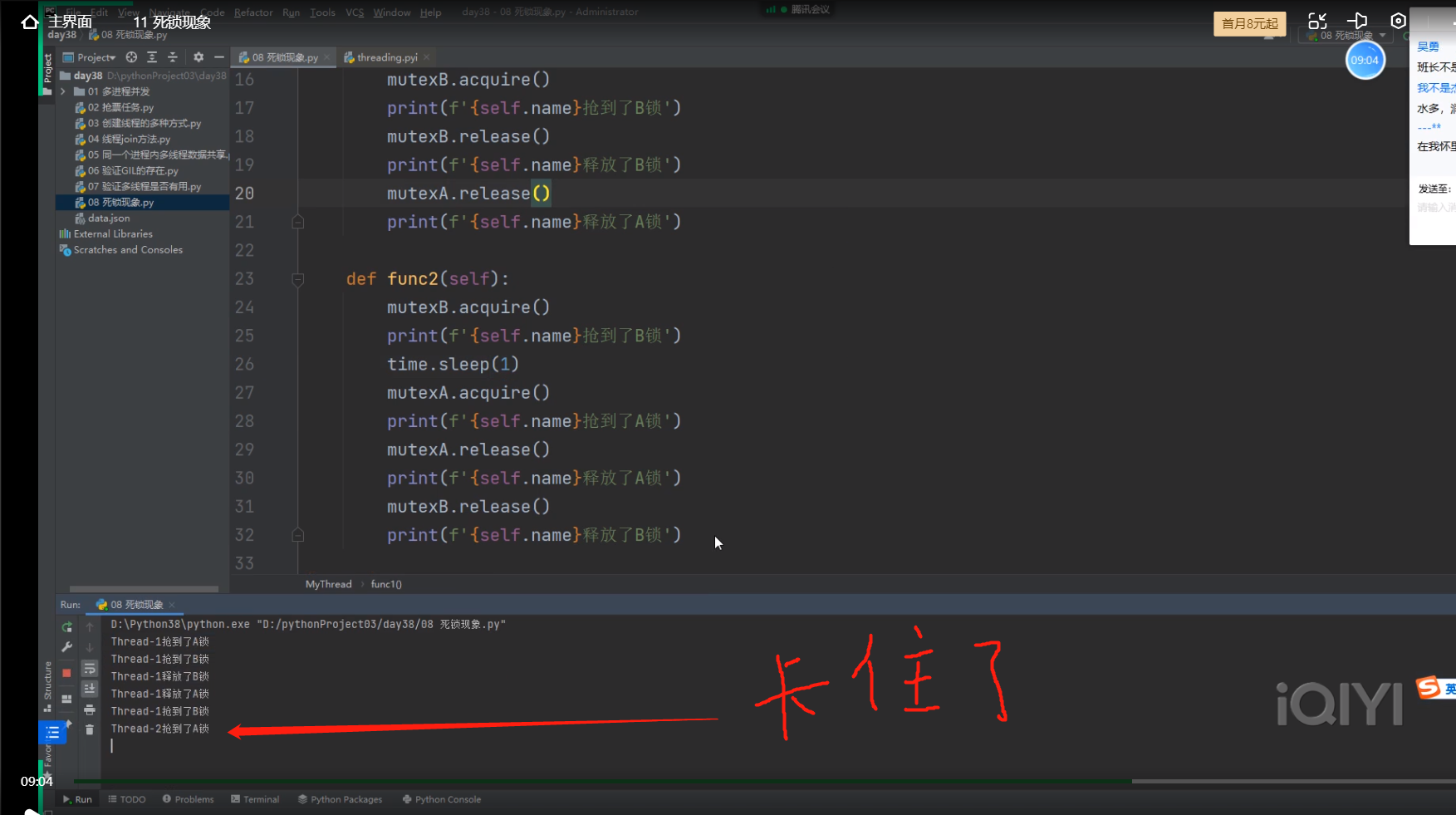
---------------------------------------
主线程同时创建了10子线程,10个子线程同时开始运行函数func1,当一个子线程抢到了A锁后,
其他的子线程就已经没资格运行A锁下面的代码了,所以该子线程可以不用抢就能拿到B锁释放B锁,
最后再释放A锁。该子线程放掉A锁后,其他的子线程会去抢A锁,但是现在情况来了,
该子线程运行完了函数func1后,继续要运行函数func2时,又要抢B锁,此时其他子线程还在抢A锁,
所以该子线程还是能顺利的抢到B锁,但这个时候睡了1s,
此时其他的子线程肯定已经有一个子线程抢到了A锁,该子线程睡醒了后,想抢A锁,
但此时A锁已经被其他子线程抢到了,而且这个抢到A锁的子线程此时也正要想抢B锁,
两个子线程都想抢对方手里的锁!!!
就卡死了!!!这就是死锁现象!!!
.
.
.
.
.
.
.
信号量(了解)
之前使用的Lock产生的是单把锁,类似于单间厕所
信号量相当于一次性创建多间厕所,类似于公共厕所
在python并发编程中信号量相当于多把互斥锁
from threading import Thread, Lock, Semaphore
import time
import random
sp = Semaphore(5) # 一次性产生五把锁
class MyThread(Thread):
def run(self):
sp.acquire()
print(self.name)
time.sleep(random.randint(1, 3))
sp.release()
for i in range(20):
t = MyThread()
t.start()
一次性产生5把互斥锁,那么开始抢锁,一次就有5个子线程能抢到锁了!!
.
.
.
.
.
.
.
event事件
子进程之间可以彼此等待彼此,或者子线程之间可以彼此等待彼此
例如:子进程A运行到某一行代码位置后,发信号告诉子进程B开始运行
也就是说比如开了两个子进程,两个子进程不是同时运行的,
有一个子进程要依赖于另一个子进程给它发信号后,才能执行。
这就叫event事件
from threading import Thread, Event
import time
event = Event() # 类似于造了一个红绿灯
def light():
print('红灯亮着的 所有人都不能动')
time.sleep(10)
print('绿灯亮了 油门踩到底 给我冲!!!')
event.set()
def car(name):
print('%s正在等红灯' % name)
event.wait()
print('%s加油门 飙车了' % name)
t = Thread(target=light)
t.start() # 开1个子线程运行light函数
for i in range(20): # 开20个子线程运行car函数
t = Thread(target=car, args=('熊猫PRO%s' % i,))
t.start()
# 当子进程或者子线程中有event.wait()代码,
# 那么一定要等某一个地方执行了event.set()后,
# event.wait()下面的代码才能继续正常运行!!!
# 否则就卡在event.wait()这不运行了!!!
# 这样就实现了一个线程控制另一个线程代码的执行
.
.
.
.
.
.
.
.
.
进程池与线程池
进程和线程能否无限制的创建 不可以
如果我们要使用多进程与多线程,并且同时开的子进程或子线程比较的多的情况下,
可以考虑使用进程池与线程池,这样代码就不会出现造成硬件意外断开的情况!!
比如这样:
for i in range(1000):
p = Process(target=work)
p.start()
-----------------------------------------------------
因为硬件的发展赶不上软件,有物理极限.
如果我们在编写代码的过程中无限制的创建进程或者线程,可能会导致计算机崩溃!!!
池的作用: 降低程序的执行效率,但是保证了计算机硬件的安全
进程池: 提前创建好固定数量的进程供后续程序的调用,超出则等待
线程池: 提前创建好固定数量的线程供后续程序的调用,超出则等待
--------------------------------------------------------
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
from threading import current_thread
# 1.产生含有固定数量线程的线程池
pool = ThreadPoolExecutor(20)
def task():
print('task is running')
time.sleep(random.randint(1, 3))
print('task is over')
# 2.将任务提交给线程池即可
for i in range(20):
pool.submit(task, 123) # 朝线程池提交任务
----------------------------------------------------
----------------------------------------------------
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
from threading import current_thread
# 1.产生含有固定数量线程的线程池
pool = ThreadPoolExecutor(10)
def task(n):
print('task is running')
time.sleep(random.randint(1, 3))
print('task is over', n, current_thread().name)
# 2.将任务提交给线程池即可
for i in range(20):
res = pool.submit(task, 123)
# 朝线程池提交任务,123是要传给task函数的参数
.
.
.
.
.
.
.
.
.
.
.
.
.
# 进程池的用法
# 建议有几个cpu就开几个进程,这样每个进程都能拿到一个cpu,这样效率最高
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
from threading import current_thread
# 1.产生含有固定数量线程的线程池 与 固定数量进程的进程池
pool = ProcessPoolExecutor(5)
def task(n):
print('task is running')
return '我是task函数的返回值'
def func(*args, **kwargs):
print('from func')
if __name__ == '__main__':
# 2.将任务提交给线程池即可
for i in range(20):
# print(res.result()) # 不能直接获取
pool.submit(task, 123).add_done_callback(func) # 朝进程池提交20个任务,是异步操作
先朝进程池提交20个任务,但是进程池只有5,
所以一次性只能运行5个子进程每个子进程运行一个任务,
一旦运行的这5个子进程里面有一个子进程运行完了,有返回值了,
立刻自动调用func函数运行,并把返回值传给该func函数
异步操作是提交完任务后,不原地等待任务的结果,任务的结果由异步回调机制自动获取并处理,add_done_callback() 就是异步回调机制
.
.
.
.
.
.
.
协程
进程:操作系统资源分配的最小单位
线程:cpu调度的最小单位
协程:单线程下实现并发效果,程序层面遇到io,控制任务的切换,从而不释放cpu
单线程下实现并发(效率极高),目的就是想尽一切办法,留住cpu,
不让cpu因为IO操作切换走。这样对cpu的利用率就越高!!!
-------------------------------------
在代码层面欺骗CPU,让CPU觉得我们的代码里面没有IO操作
实际上IO操作被我们自己写的代码检测,一旦有,立刻让代码执行别的
(该技术完全是程序员自己弄出来的,名字也是程序员自己起的)
核心:自己写代码(具有)监测IO,一旦有IO自己切换,完成切换+保存状态,自始至终欺骗cpu
---------------------------------------
协程代码示例:
import time
from gevent import monkey;monkey.patch_all()
# 固定编写 用于检测所有的IO操作(猴子补丁)
from gevent import spawn
def func1():
print('func1 running')
time.sleep(3)
print('func1 over')
def func2():
print('func2 running')
time.sleep(5)
print('func2 over')
if __name__ == '__main__':
start_time = time.time()
# func1()
# func2()
s1 = spawn(func1) # 检测代码 一旦有IO自动切换(执行没有io的操作,变向的等待io结束)
s2 = spawn(func2)
s1.join()
s2.join()
print(time.time() - start_time) # 8.01237154006958 协程 5.015487432479858
.
.
.
.
.
.
.
协程实现并发
单线程的情况下,实现并发的效果TCP并发的效果
服务端代码:
import socket
from gevent import monkey;monkey.patch_all()
# 固定编写 用于检测所有的IO操作(猴子补丁)
from gevent import spawn
def communication(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
def get_server():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept() # IO操作
spawn(communication, sock)
s1 = spawn(get_server)
s1.join()
----------------------------
客户端代码:
import socket
client_obj = socket.socket()
client_obj.connect(('127.0.0.1', 8080))
while True:
client_obj.send(b'hello baby')
data = client_obj.recv(1024)
print(data)
----------------------------
如何不断的提升程序的运行效率
多进程下开多线程 多线程下开协程
.
.
.
.
关于开子线程或子进程的一些总结
from threading import Thread
import time
def handle():
time.sleep(5)
print('end')
def haha():
t_handle = Thread(target=handle)
t_handle.start()
print('hahaha')
return 0
haha()
# hahaha
# end
# 当运行一个函数,这个函数里面开子线程,当这个函数运行结束后,
# 这个函数里面的子线程如果还没有运行结束,这个子线程还是会正常运行的,不受运行它的函数影响
----------------------------------------
同理开子进程也是一样,不受运行它的函数影响
from multiprocessing import Process
import time
def handle():
time.sleep(5)
print('end')
def haha2():
p_handle = Process(target=handle)
p_handle.start()
print('hahaha')
return 0
if __name__ == '__main__':
haha2()
# hahaha
# end
# 拓展到flask或者django项目里面,当项目起起来后是一个主进程,
# 假设我们在视图函数里面定义了开启子线程的代码,那么当请求触发了该视图函数后,
# 运行视图函数的代码,当运行到开启子线程执行子线程的代码后,由于这一步是异步的
# 视图函数继续往下执行,假设return 视图函数运行结束了
# 子线程里正在执行的代码是不受影响的,继续正常运行,直到子线程的代码都跑完,
# 子线程才正常运行结束!!!
.
.
.
开子进程的注意事项
Process(target=xxx_func)
xxx_func这个函数中涉及到无法被序列化的对象,
就会导致TypeError: cannot pickle 'weakref' object
注意开了子进程,子进程中操作的所有数据,都和主进程没有关系
主进程传的参数,也一样,子进程改变参数,和主进程没有关系!!!
.
.
.
.
.
.
.
.
.
.
作业
1.整理并发编程所有理论概念
2.预习数据库知识点MySQL


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY