python三十六期---粘包解决方案、UDP基本代码使用、并发编程理论等
昨日内容回顾
- TCP与UDP协议
TCP
可靠协议
三次握手建立链接
1.洪水攻击
2.消息反馈
四次挥手断开链接
1.time_wait
UDP
不可靠协议
"""
TCP类似于打电话
UDP类似于发短信
"""
- 应用层协议简介
HTTP\HTTPS\FTP...
- socket套接字简介
socket套接字作用于应用层与其他层之间 承上启下类似于操作系统的作用
- socket基本使用
服务器端: 客户端:
import socket import socket
se = socket.socket() 产生socket对象 cl = socket.socket()
se = bind(()) 绑定地址
se = listen() 半连接池
sock,adr = accept() 接受客户端链接 cl.connect(()) 链接服务端请求
data = sock.recv(1024) 接收消息 cl.send('你好'.encode('utf8'))
print(data.decode('utf8'))
sock.send('滚蛋'.encode('utf8'))发送消息 data = cl.recv(1024) 接收消息
print(data.decode('utf8'))
sock.close() 关闭双向通道 cl.close() 断开与服务端的链接
se.close() 关闭服务端
.
.
.
-
socket代码优化
1.通信循环 2.链接循环 3.发送的消息不能为空、mac电脑反复重启服务端可能会报错地址错误、服务端利用异常捕获增加健壮性 -
半连接池概念
缓解服务端与客户端建立链接的压力
今日内容概要
- 黏包现象
- 解决黏包逻辑思路
- 代码实操
- UDP基本代码使用
- 并发编程理论之操作系统发展史
- 多道技术
- 进程理论及调度算法
今日内容详细
TCP协议------------黏包现象
1.服务端连续执行三次recv
2.客户端连续执行三次send
问题:服务端一次性接收到了客户端三次的消息 该现象称为"黏包现象"
--------------------------------------
黏包现象产生的原因:
1.收消息的时候,不知道每次接收的数据到底有多大!!!!!!
recv()括号里面规定了每次收消息的字节数,所以如果客户端连续发几次消息,但是总字节数小于括号里面规定收消息的字节数
2.TCP也称为流式协议:数据像水流一样,没有间隔。
TCP里面有一个算法会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送,服务端就会一次性全都接收到!!!
---------------
避免黏包现象的核心思路\关键点:
如何明确即将接收的数据具体的字节数有多大!!!!!!
---------------
ps:如何将长度变化的数据全部制作成固定长度的数据??????
.
.
补充
------------------
3、字符串前加 b
例如: b'Hello World!' b'XXX' 表示XXX这是一个 bytes 对象
也就是说此时b'XXX' 整体就代表'xxx'字符串已经转化成一个二进制数据了,只是为了让我看着方便没有写成01的格式
-------------------
2、字符串前加 r
例:r'\n\n\n\n' 表示一个普通生字符串 \n\n\n\n,而不表示换行了,取消掉转义符的意思,表示就是纯字符串,没有其他额外的意思!!!
------------------
.
.
.
.
.
.
.
.
struct模块
将非固定字节长度的数字,打包成固定字节长度的数字,并且可以反向解析出打包前的数字!!!
把非固定字节长度的数字,打包成固定字节长度的数字!!!
import struct
info = b'hello big baby'
print(len(info)) # 数据真实的字节长度(bytes) 14
---------------------------------------------------
res = struct.pack('i', len(info))
# res就是报头!将数据打包成固定长度的数据!!
# i是打包方法,一般就用该打包方法 注意这个时候报头就已经是二进制类型的数据了!!!
# 数字用i方法打包,就会打包成一个固定长度为4个字节的二进制数据
print(len(res)) # 打包之后字节长度为(bytes) 4
--------------------------------------------------
real_len = struct.unpack('i', res) # 根据固定长度的报头 解析出真实数据的长度
print(real_len) # (14,) 结果是一个元组
在发真实长度数据之前,先发一个为固定长度的报头,让对方根据报头解析出真实数据的长度
这样对方就可以准备接收真正的数据长度了!!!
---------------------------------------------------
desc = b'hello my baby I will take you to play big ball'
print(len(desc)) # 数据真实的字节长度(bytes) 46
res1 = struct.pack('i', len(desc))
print(len(res1)) # 打包之后字节长度为(bytes)
real_len1 = struct.unpack('i', res1) # 根据固定长度的报头 解析出真实数据的长度
print(real_len1) # (46,) 注意:字节长度字节长度在元组里面!!
---------------------------------------------------
报头的作用:客户端拿着制作好的报头,发给服务端,
因为报头的字节长度服务端能提前知道,所以服务端能够精准的接收到报头的数据。
这样服务端再将报头解析一下,就拿到了客户端要准备发送的真实数据的字节长度。
这样根据字节长度,就能精准的接收真实的数据了!!!
.
.
.
.
.
.
.
解决黏包问题
解决黏包问题初次版本:
客户端
1.将真实数据转成bytes类型并计算长度
2.利用struct模块将真实长度制作一个固定长度的报头
3.将固定长度的报头先发送给服务端 服务端只需要在recv括号内填写固定长度的报头数字即可
4.然后再发送真实数据
------------
服务端
1.服务端先接收固定长度的报头
2.利用struct模块反向解析出真实数据长度
3.recv接收真实数据长度即可
-----------------------------------------------
问题1:struct模块无法打包数据量(字节长度)较大的数据 就算换更大的模式也不行!!!!!!
res = struct.pack('i', 12313213123) # 数字超过10位,struct.pack方法打包就会报错了
print(res)
------
问题2:报头能否传递更多的信息
比如电影大小 电影名称 电影评价 电影简介
-------------------------------------------------------------
终极解决方案:字典用json模块转为字符串再打包成报头后,效果更好,数字更小!!!
---
import struct
import json
data_dict = {
'file_name': 'xxx老师教学.avi',
'file_size': 123132131232342342423423423423432423432,
'file_info': '内容很精彩 千万不要错过',
'file_desc': '一代神作 私人珍藏'}
data_json = json.dumps(data_dict) # 利用json模块将字典序列化成字符串!!
print(len(data_json.encode('utf8'))) # 真实字典的长度 252
res = struct.pack('i', len(data_json.encode('utf8')))
# json字符串编码成二进制,并用len()方法求出字节长度,并打包成固定长度的数据
print(len(res)) # 4
------------------------------------------------
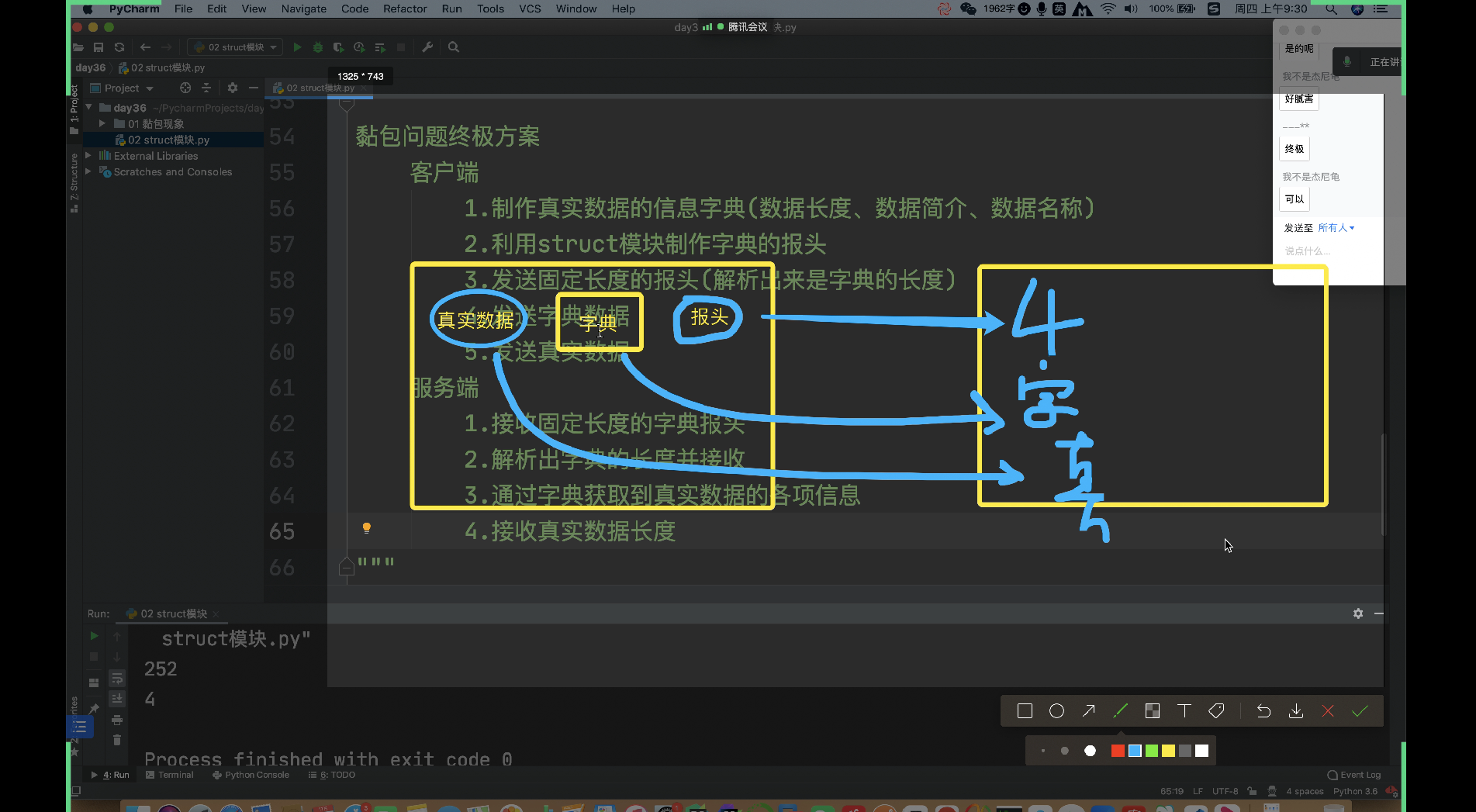
黏包问题终极方案
客户端
1.制作真实数据的信息字典(数据长度、数据简介、数据名称)
2.利用struct模块制作字典的报头
3.发送固定长度的字典报头(解析出来是字典的长度)
4.发送字典数据
5.发送真实数据
服务端
1.接收固定长度的字典报头
2.解析出字典的长度并接收字典数据
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
.
.
.
.
.
.
.
整体思路就是:
客户端发送固定长度的字典报头给服务端,服务端拿到字典包头后解析出字典的字节长度。
客户端发送字典数据,服务端此时已经知道字典的长度了往recv()括号里面一放,
直接接收字典数据就行了!!
服务端通过字典数据拿到字典里面写的要发的真实数据的的字节长度。
客户端发真实数据,服务端已经知道该数据的长度了,还是往recv()里面一放,
直接接收真实数据就行了!!!
.
.
.
.
.
.
.
黏包代码实战
将一个比较大的数据通过客户端发送给服务端
服务端代码
import socket
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
sock, addr = server.accept()
data_dict_head = sock.recv(4) # 1.接收固定长度的字典报头
# 2.根据报头解析出字典数据的字节长度,并拿到该字节长度!!
data_dict_len = struct.unpack('i', data_dict_head)[0]
data_dict_bytes = sock.recv(data_dict_len) # 3.接收字典数据(二进制的字符串格式)
data_dict = json.loads(data_dict_bytes)
# 这个地方按理说应该是将二进制的字典数据先转化成json格式的字符串字典数据后,
# 再反序列化还原成真实的字典,但是loads有自动将二进制转成json格式的字符串,
# 然后再反序列化成真实字典数据的功能
# 4.获取真实数据的各项信息!!!!!!!
total_size = data_dict.get('file_size')
---------
简单粗暴法:
with open(data_dict.get('file_name'), 'wb') as f:
f.write(sock.recv(total_size))
-----------------------
比较合理的方法:因为如果一次性发的数据内存很大,超过内存时,是无法直接一次性接收那么大的数据的,
但是由于是流式协议,所以分批接收!!!
接收真实数据的时候 如果数据量非常大
recv括号内直接填写该数据量 不太合适
我们可以每次接收一点点 反正知道总长度
-----------------------
total_size = data_dict.get('file_size') # 拿到要接收数据的总字节长度!!!
recv_size = 0 # 循环外面,先定义接收数据的字节长度的变量为0
with open(data_dict.get('file_name'), 'wb') as f: # w模式打开文件
while recv_size < total_size: # 如果定义的收的字节长度小于数据的总的字节长度时,开始循环
data = sock.recv(1024)
f.write(data)
recv_size += len(data) # 这个地方直接就写自增1024应该也行!!!
print(recv_size)
print('文件接收成功!!')
# 注意while循环判断时,不能加等于,加个等于会出现,最后一次循环时,recv_size自增后
# 这个时候已经没有数据接收了,但是此时recv_size等于total_size,循环还会继续走!!
# 继续走循环时,已经收不到东西了!!!
.
.
.
.
.
.
.
客户端代码
'''任何文件都是下列思路 图片 视频 文本 ...'''
import socket
import os
import struct
import json
client = socket.socket()
client.connect(('127.0.0.1', 8081))
# 1.获取真实数据大小
file_size = os.path.getsize(r'/Users/jiboyuan/PycharmProjects/day36/xx老师合集.txt')
# 2.制作真实数据的字典数据
data_dict = {
'file_name': '有你好看.txt',
'file_size': file_size,
'file_desc': '内容很长 准备好吃喝 我觉得营养快线挺好喝',
'file_info': '这是我的私人珍藏'
}
# 3.制作字典的报头
# 字典序列化成json格式字符串后,再转成二进制!! 求出二进制字符串的字节长度后,打包成固定长度的报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_head = struct.pack('i', len(data_dict_bytes)) # 字节长度为4的报头数据
# 4.发送字典报头
client.send(data_dict_head) # 报头数据本身也是bytes类型 字节数是4
# 5.发送字典
client.send(data_dict_bytes) # send发送的一定是二进制数据!!!
# 6.最后发送真实数据
with open(r'/Users/jiboyuan/PycharmProjects/day36/xx老师合集.txt', 'rb') as f:
for line in f: # 一行行发送 和直接一起发效果一样 因为TCP流式协议的特性
client.send(line)
import time
time.sleep(10)
# 看情况如果客户端发送完,服务端如果还没接收完,客户端就断开了,就会导致服务端没有将数据收完,
# 所以看情况,要不要让客户端代码再停一下!!!
.
.
.
.
.
.
.
.
.
.
UDP协议(了解)
UDP协议做聊天软件比较方便!!!
1.UDP服务端和客户端'各自玩各自的'
2.UDP不会出现多个消息发送合并
-----------------------------
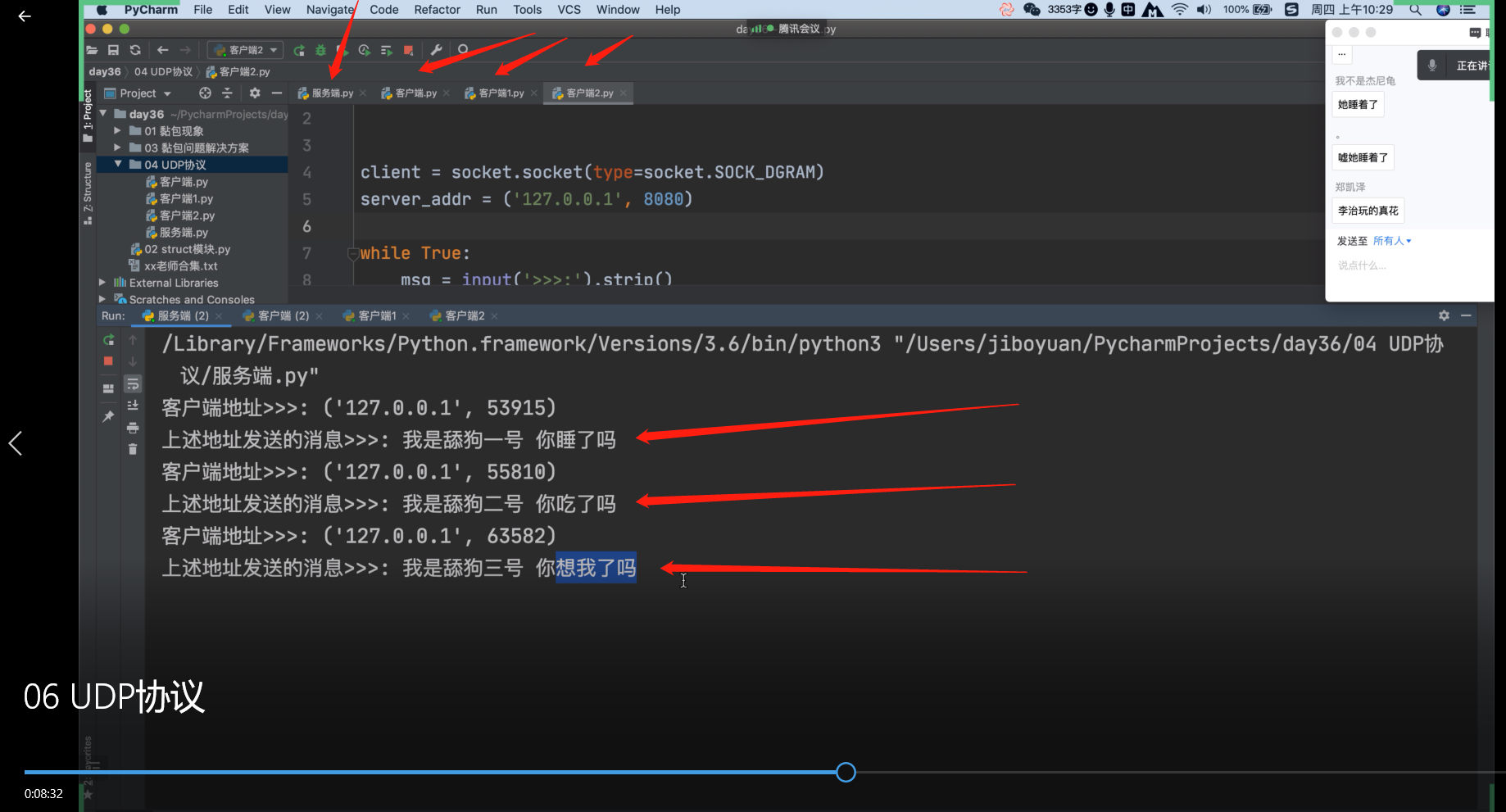
当同时又多个客户端时,服务端可以同时接收多个客户端发的消息!!!
TCP做不到,TCP服务端同时只能和一个客户端连接并进行互发消息!!!
.
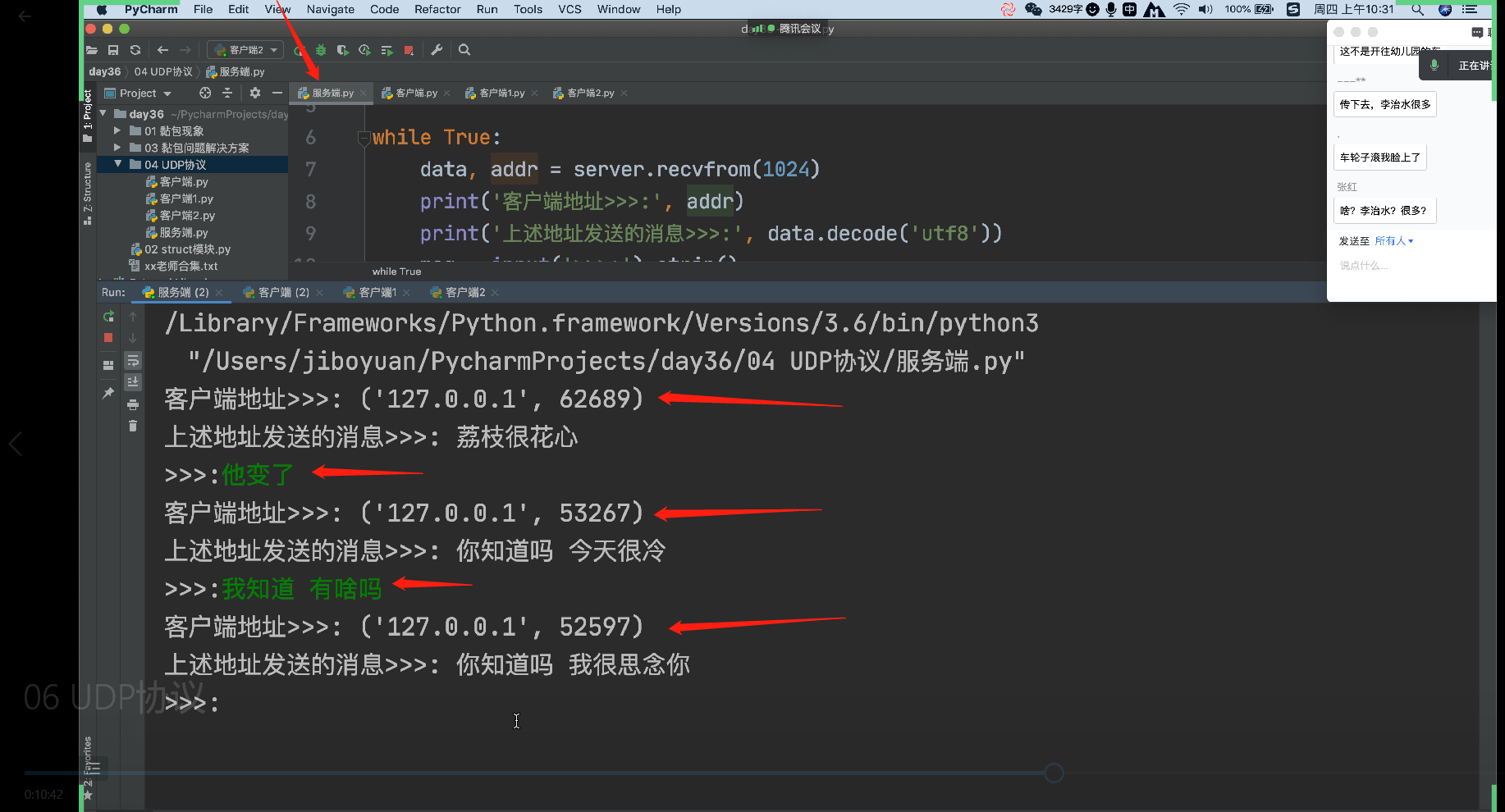
多个客户端同时给一个服务端,服务端回一个客户端,就能收到另一个客户端发来的消息!!!
.
.
.
.
服务端代码
import socket
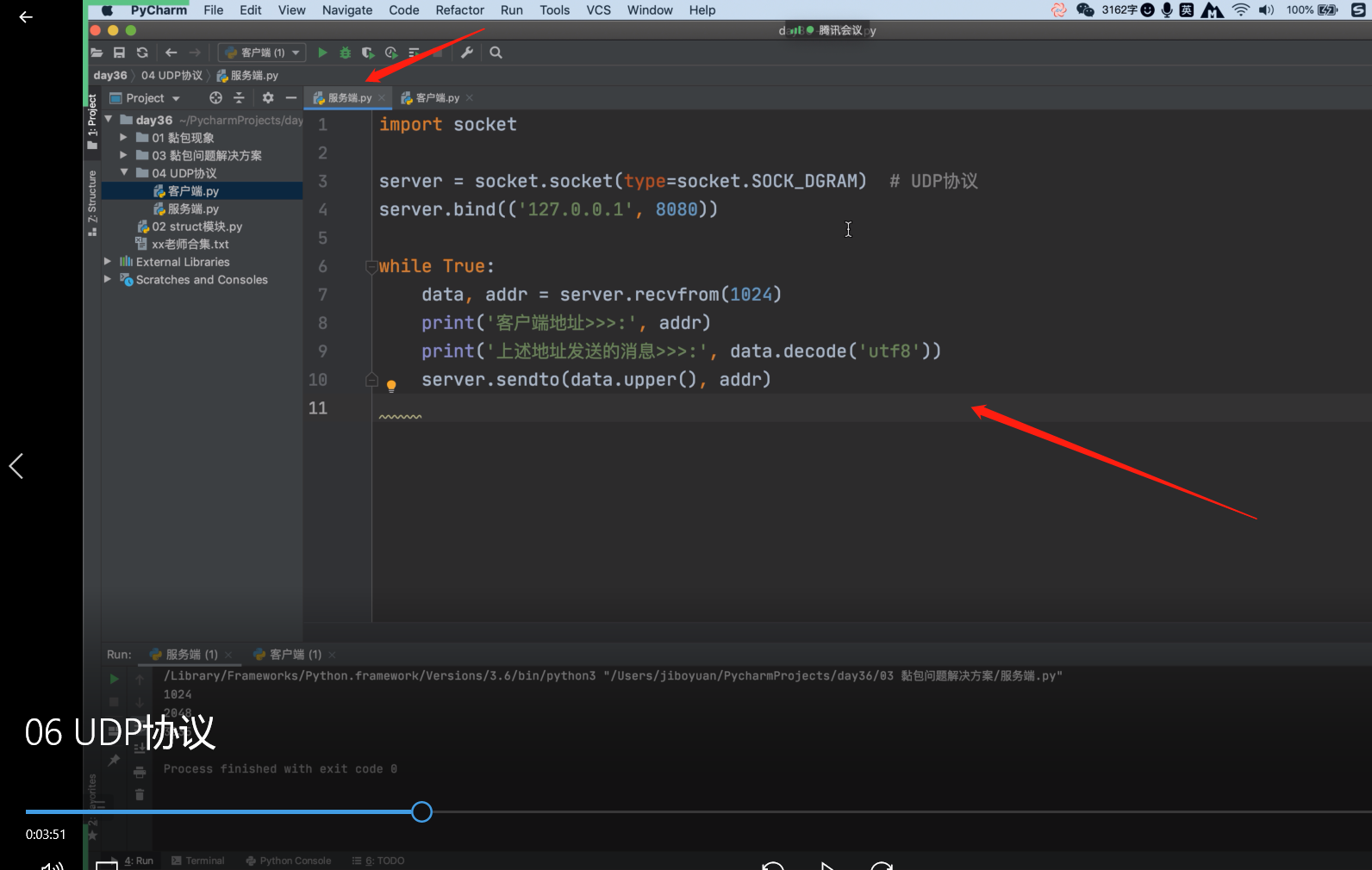
server = socket.socket(type=socket.SOCK_DGRAM) # UDP协议
server.bind(('127.0.0.1', 8080))
while True:
data, addr = server.recvfrom(1024)
print('客户端地址>>>:', addr)
print('上述地址发送的消息>>>:', data.decode('utf8'))
msg = input('>>>:').strip()
server.sendto(msg.encode('utf8'), addr) # 消息后面跟一个客户端地址,就能实现与不同客户端一起聊天了!!!
.
.
.
.
客户端代码
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
server_addr = ('127.0.0.1', 8080)
while True:
msg = input('>>>:').strip()
client.sendto(msg.encode('utf8'), server_addr) # sendto
data, addr = client.recvfrom(1024)
print(data.decode('utf8'), addr)
.
服务端代码:
.
.
.
.
.
.
.
.
.
操作系统发展史
为什么要使用操作系统呢?
程序员无法把所有的硬件操作细节都了解到,管理这些硬件并且加以优化使用是非常繁琐的工作,
这个繁琐的工作就是操作系统来干的,有了他,程序员就从这些繁琐的工作中解脱了出来,
只需要考虑自己的应用软件的编写就可以了,应用软件直接使用操作系统提供的功能来间接使用硬件。
--------------
三、操作系统的两大作用
1.为应用程序提供如何使用硬件资源的抽象
2.把多个程序对硬件的竞争变得有序化(管理应用程序)
.
.
.
.
.
计算机中真正干活的是CPU
---------------------------------------------
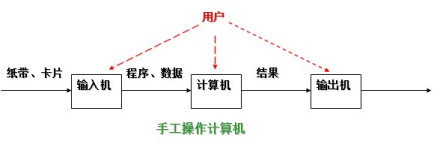
1.穿孔卡片阶段
计算机很庞大 使用很麻烦 一次只能给一个人使用 期间很多时候计算机都不工作
好处:程序员独占计算机 为所欲为
坏处:计算机利用率太低 浪费资源
出现人机矛盾:手工操作的慢速度和计算机的高速度之间形成了尖锐矛盾,手工操作方式已严重损害了系统资源的利用率(使资源利用率降为百分之几,甚至更低),不能容忍。唯一的解决办法:只有摆脱人的手工操作,实现作业的自动过渡。这样就出现了成批处理。
----------------------------------------------
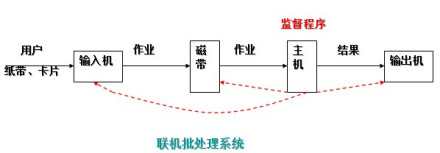
批处理系统:加载在计算机上的一个系统软件,在它的控制下,计算机能够自动地、成批地处理一个或多个用户的作业(这作业包括程序、数据和命令)。
首先出现的是联机批处理系统,即作业的输入/输出由CPU来处理。
----------------------------------------------
2.联机批处理系统
提前使用磁带一次性录入多个程序员编写的程序,然后交给计算机执行
CPU工作效率有所提升 不用反复等待程序录入
----------------------------------------------
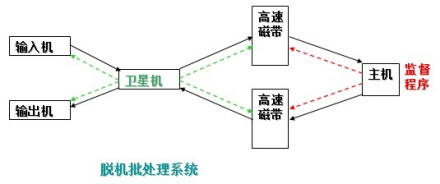
为克服与缓解:高速主机与慢速外设的矛盾,提高CPU的利用率,又引入了脱机批处理系统,即输入/输出脱离主机控制。
这种方式的显著特征是:增加一台不与主机直接相连而专门用于与输入/输出设备打交道的卫星机。这样,主机不是直接与慢速的输入/输出设备打交道,而是与速度相对较快的磁带机发生关系,有效缓解了主机与设备的矛盾。主机与卫星机可并行工作,二者分工明确,可以充分发挥主机的高速计算能力。
3.脱机批处理系统
极大地提升了CPU的利用率
总结:CPU提升利用率的过程
----------------------------
.
.
.
脱机批处理系统:它极大缓解了人机矛盾及主机与外设的矛盾。
不足:每次主机内存中仅存放一道作业,每当它运行期间发出输入/输出(I/O)请求后,
高速的CPU便处于等待低速的I/O完成状态,致使CPU空闲。
为改善CPU的利用率,又引入了多道程序系统。
.
.
.
.
.
.
.
.
.
多道技术
在学习并发编程的过程中 不做刻意提醒的情况下 默认一台计算机就一个CPU(只有一个干活的人)
----------------------------------------------------
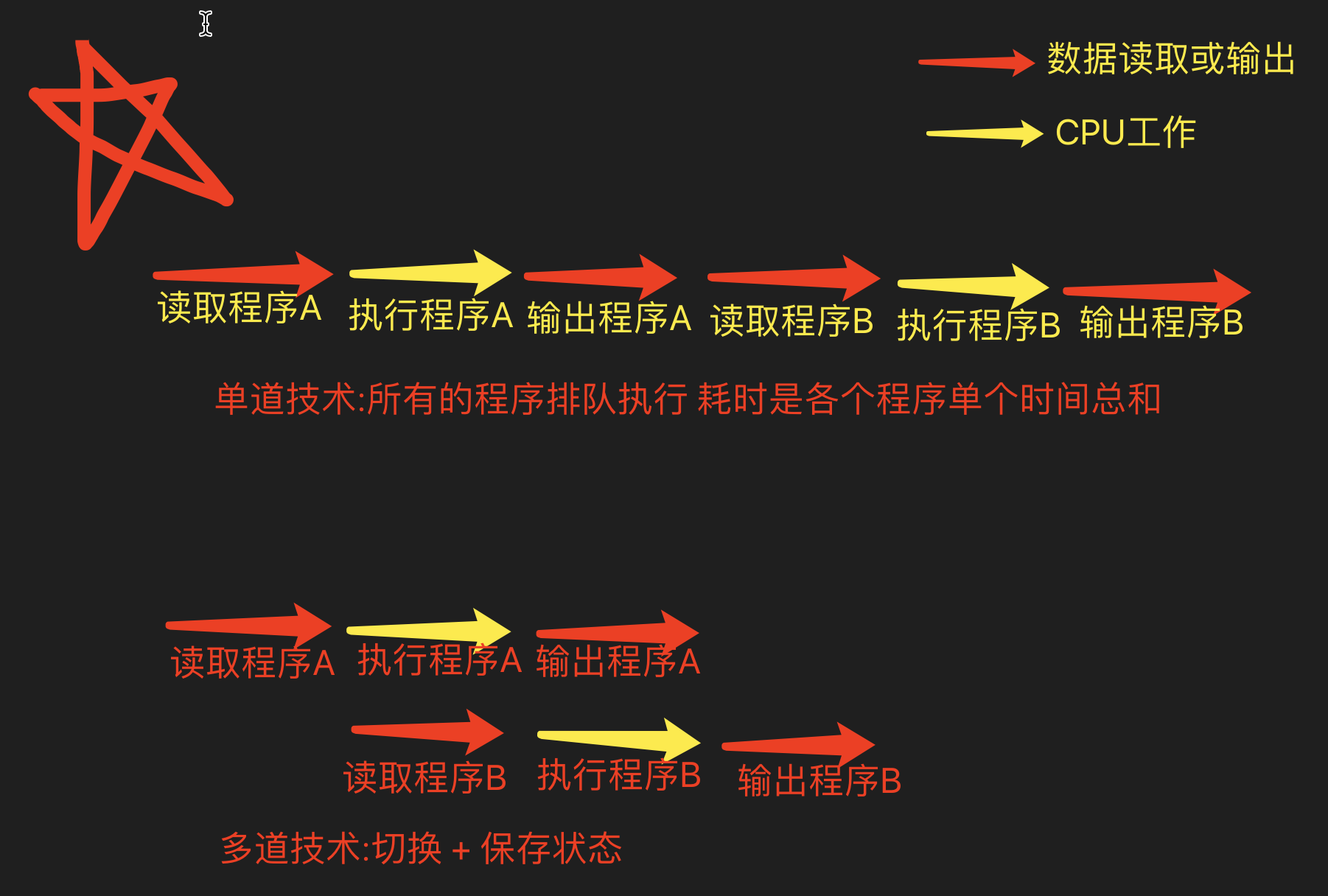
多道技术:(指的是多道/个程序)
1.空间上的复用:内存要支持同时跑进多个程序
2.时间上的复用:多个程序要让它们能切换(什么时候要切?一个程序占用的时间过长要切;当CPU遇到IO阻塞时,等待的时间要切)
----------------------------------------------------
单道技术
所有的程序排队执行 过程中不能重合
多道技术
利用空闲时间提前准备其他数据 最大化提升CPU利用率
--------------------------------------------------
多道技术详细
1.切换
计算机的CPU在两种情况下会切换(不让你用 给别人用)
1.程序有IO操作
输入\输出操作
input、time.sleep、read、write
2.程序长时间占用CPU
我们得雨露均沾 让多个程序都能被CPU运行一下
--------------------------------------------------
2.保存状态
CPU每次切换走之前都需要保存当前操作的状态 下次切换回来基于上次的进度继续执行
--------------------------------------------------
开了一家饭店 只有一个服务员 但是同时来了五桌客人
请问:如何让五桌客人都感觉到服务员在服务他们
让服务员化身为闪电侠 只要客人有停顿 就立刻切换到其他桌 如此往复
--------------------------------------------------
程序的I/O操作:
I:就是input 、O:就是output ;称为:输入输出流。
IO操作,就是将数据写入内存或从内存输出的过程,也指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。
常见IO操作,一般指内存与磁盘间的输入输出流操作。
.
.
.
.
.
.
.
进程理论
进程与程序的区别
程序:一堆死代码(还没有被运行起来)
进程:正在运行的程序!!!!!!
-------------------------------------
进程的调度算法(重要)
1.FCFS(先来先服务)
对短作业不友好
-------------------------------------
2.短作业优先调度
对长作业不友好
-------------------------------------
3.时间片轮转法+多级反馈队列(目前还在用)!!!!!!!!!!
将时间均分 然后根据进程时间长短再分多个等级
等级越靠下表示耗时越长 每次分到的时间越多 但是优先级越低
-------------------------------------
.
.
.
.
.
.
进程的并行与并发
并行
多个进程同时执行!!!
必须要有多个CPU参与,单个CPU无法实现并行!!!
并发
多个进程看上去像同时执行!!!
单个CPU可以实现,多个CPU肯定也可以!!!
-------------------------------------
判断下列两句话孰对孰错:
我写的程序很牛逼,运行起来之后可以实现14个亿的并行量
并行量必须要有对等的CPU才可以实现,所以这句话是错的!!!
---------
我写的程序很牛逼,运行起来之后可以实现14个亿的并发量
合情合理 完全可以实现 以后我们的项目一般都会追求高并发
ps:目前国内可以说是最牛逼的>>>:12306
.
.
.
.
.
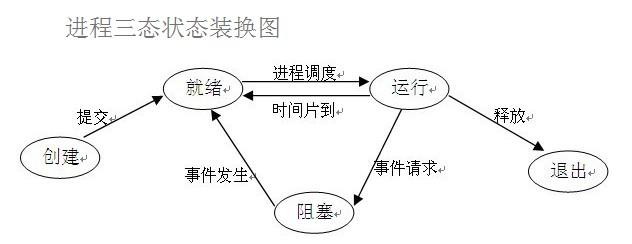
进程的三状态
运行一个程序首先要双击一下,就表示提交了一个任务,被双击的程序会先进入一个就绪态!!
告诉cpu它已经准备好了!!利用cpu的进程调度算法,拿到一个时间片,到了这个时间片,
cpu就会执行该程序了,就会进入运行态了,当程序处于运行态后,当在时间片内,该程序已经跑完了,就
正常退出运行,释放内存空间。如果在时间片内程序仍然没有运行完也没有I/O操作,那就再次返回就绪态,
如果有I/O操作就会进入阻塞态!!cpu会立刻离开该程序,并保存当前的操作状态!!
当I/O操作执行结束后,该程序才会从阻塞态转为就绪态并排队!!!
----------------------------------------------
就绪态
所有的进程在被CPU执行之前都必须先进入就绪态等待
运行态
CPU正在执行
阻塞态
进程运行过程中出现了IO操作,阻塞态无法直接进入运行态,需要先进入就绪态排队才能变成运行态
-------------
也就是如果让程序尽可能多的在运行态与就绪态来回切回,那么该程序的cpu的利用率就比较高了
.
.
.

.
.
.
.
.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY