python第二十课--正则表达式相关知识
昨日内容回顾
-
统计指定类型的文件个数
1.列举指定目录下所有的内容名称 2.然后获取想要统计的文件后缀名 3.循环遍历所有符合指定后缀名的文件个数 ps:只需要遍历第一层级即可 -
动态展示指定文件的内容
1.获取一个指定目录路径 2.列表该路径所有的内容名称 3.循环展示所有文件内容并带有编号 4.针对编号有一系列小的判断 5.根据正确的编号利用索引取值获取指定的文件名称 6.根据文件名称拼接文件的完整路径 7.根据完整路径读取文件内容并展示 -
购物车程序
# 1.项目框架搭建 空函数 功能字典 循环动态匹配 # 2.项目注册功能 1.获取用户名和密码 并且针对密码需要二次确认 2.用户数据需要注册(保存到一个固定的位置) 获取执行文件所在的项目目录路径(根目录 bin目录) 自动拼接存储用户数据的db目录路径(是否存在并动态创建) 3.拼接用户文件的绝对路径 判断绝对路径是否存在 如果存在表示用户已注册 如果不存在则使用json模块序列化 # 3.项目登录功能 1.获取用户名和密码 2.根据用户名获取文件路径 判断是否存在 3.如果存在则获取用户字典数据 判断密码是否正确 4.由于项目中一些功能需要登录的用户才可以执行 所以要保存登录状态 # 4.项目校验用户是否登录装饰器 1.无参装饰器模板 def login_auth(func_name): def inner(*args, **kwargs): res = func_name(*args, **kwargs) return res return inner 2.全局变量存储登录用户相关的信息 # 5.项目添加购物车功能 1.获取商品信息并循环展示给用户选择 2.用户选择对应编号的商品 商品编号校验问题(小校验) 3.综合考虑 针对购物车数据的保存 在添加购物车功能结束一次保存 在循环展示商品之前 创建一个临时购物车字典 4.临时购物车添加键值对数据 注意字典中可能已经存在一些数据 不能替换保存 如果商品已经存在则修改商品个数 如果商品不存在则新增键值对 5.退出购物车程序之前需要一次性修改当前登录用户购物车数据 注意用户购物车字典中可能也已经存在一些数据 不能替换保存 如果商品已经存在则修改商品个数 如果商品不存在则新增键值对 # 6.项目结算购物车功能 1.根据全局变量获取当前登录用户文件路径 2.读取登录用户的购物车数据 3.循环遍历购物车数据并计算总额 4.判断总额是否超出用户余额 5.如果没有超出 则完成扣款 清空购物车 并保存
今日内容概要
- 正则表达式前戏
- 正则表达式之字符组
- 正则表达式之量词
- 正则表达式之特殊符号
- 正则表达式之课堂练习
- 正则表达式之贪婪与非贪婪匹配
- 正则表达式之实战应用
- python正则模块之re
今日内容详细
正则表达式前戏
案例:京东注册手机号校验
基本需求:手机号必须是11位、手机号必须以13 15 17 18 19开头、必须是纯数字
'''纯python代码实现'''
while True:
# 1.获取用户输入的手机号
phone_num = input('请输入您的手机号>>>:').strip()
# 2.先判断是否是十一位
if len(phone_num) == 11:
# 3.再判断是否是纯数字
if phone_num.isdigit():
# 4.判断手机号的开头
if phone_num.startswith('13') or phone_num.startswith('15') or phone_num.startswith(
'17') or phone_num.startswith('18') or phone_num.startswith('19'):
print('手机号码输入正确')
else:
print('手机号开头不对')
else:
print('手机号必须是纯数字')
else:
print('手机号必须是11位')
'''python结合正则实现'''
import re
phone_number = input('please input your phone number: ')
if re.match('^(13|14|15|18)[0-9]{9}$', phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
"""
正则表达式是一门独立的技术 所有编程语言都可以使用
它的作用可以简单的概括为:利用一些特殊符号(也可以直接写需要查找的具体字符)的组合产生一些特殊的含义然后去字符串中筛选出符合条件的数据
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
作用:
筛选数据(匹配数据)!!!!!!
"""
字符组 就是中括号里面放一些内容的正则表达式
注意!!!!!!
没有量词修饰!!!
字符组默认匹配方式是对要匹配的数据挨个匹配!!!!!!就是对被匹配的数据,一个一个匹配,只要符合正则表达式,就是符合筛选的数据!!!
而且中括号[]里面任意一个数据只要符合被匹配的数据,那么这个被匹配的数据就算,符合筛选的数据!!!!!!
所以字符组内所有的数据默认都是或的关系!!!!!!
[0123456789] 匹配0到9任意一个数(全写),就是0-9数字都符合正则要求
[0-9] 匹配0到9任意一个数(缩写)
[a-z] 匹配26个小写英文字母
[A-Z] 匹配26个大写英文字母
[0-9a-zA-Z] 可以匹配数字,大小写形式的a~f,可用来验证十六进制字符
特殊符号
注意:!!!
特殊符号默认匹配方式是挨个挨个匹配!!!!!!
. 匹配除换行符以外的任意字符!!!!!!
\w 匹配数字、字母、下划线!!!
\W 匹配非数字、非字母、非下划线
\d 匹配数字!!!
^ 匹配字符串的开头!!! 匹配行首!!!
$ 匹配字符串的结尾!!! 匹配行尾!!!
两者组合使用可以非常精确的限制匹配的内容
a|b 匹配a或者b(管道符的意思是或)
() 给正则表达式分组 不影响表达式的匹配功能
[] 字符组 内部填写的内容默认都是或的关系!!!
[^] 取反操作 匹配除了字符组里面的其他所有字符
注意上尖号在中括号内和中括号意思完全不同
量词
'''正则表达式默认情况下都是贪婪匹配>>>:尽可能多的匹'''
* 匹配零次或多次 默认是多次(无穷次)
+ 匹配一次或多次 默认是多次(无穷次)
? 匹配零次或一次 作为量词意义不大主要用于非贪婪匹配
{n} 重复n次
{n,} 重复n次或更多次 默认是多次(无穷次)
{n,m} 重复n到m次 默认是m次
--------------------------------------------------------
.
.
ps:量词必须结合表达式一起使用 不能单独出现 并且只影响左边第一个表达式!!!
jason\d{3} 只影响\d
used? 只影响d 也就是匹配时d可以匹配一次或者零次 换句话说就是d可有一次,也可以没有!!!
ab*c 只影响b 也就是匹配时b可以匹配零次或者多次 换句话说就是b可以有多次,也可以没有,b不可以有一次!!!
ab+c 只影响b 也就是匹配时b可以匹配一次或者多次
ab{6}c 只影响b 也就是在匹配时,a与c之间, b的匹配6次只能为6次!!!
(ab)*c 影响ab 也就是在匹配时,ab可以匹配零次或者多次!!!
-------------------------
a(cat|dog) 可以匹配a cat 或者 a dog
.
.
特殊组合!!
.*? 是非贪婪匹配,会把满足正则的尽可能少匹配,意思就是每一次匹配的内容尽可能少,第一次遇到结尾字段就会切分,每一次匹配都不贪多。
------------
.* 是贪婪匹配,会把满足正则的尽可能多的往后匹配,意思就是每次匹配的内容会一直检索到更后面,只要更后面能匹配到结尾字段,哪怕中间也有结尾字段也会一直匹配下去直到遇到最后一次结尾字段,每一次匹配都尽可能贪最多的内容。
------------
举例说明:
文本 <h2>TXT文本</h2><h2>word文档</h2>
<h2>(.*?)</h2> 匹配的结果是 <h2>TXT文本</h2> 与 <h2>word文档’</h2>
<h2>(.*)</h2> 匹配的结果是 <h2>TXT文本</h2><h2>word文档</h2>
----------------------------------------------------
。
。
。
课堂练习
参考博客即可
贪婪匹配与非贪婪匹配
"""所有的量词都是贪婪匹配如果想要变为非贪婪匹配只需要在量词后面加问号"""
待匹配的文本
<script>alert(123)</script>
待使用的正则(贪婪匹配)
<.*>
请问匹配的内容
<script>alert(123)</script> 一条
# .*属于典型的贪婪匹配 使用它 结束条件一般在左右明确指定
待使用的正则(非贪婪匹配)
<.*?>
转义符
"""斜杠与字母的组合有时候有特殊含义"""
\n 匹配的是换行符
\\n 匹配的是文本\n
\\\\n 匹配的是文本\\n
ps:如果是在python中使用 还可以在字符串前面加r取消转义
正则表达式实战建议
1.编写校验用户身份证号的正则
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
2.编写校验邮箱的正则
3.编写校验用户手机号的正则(座机、移动)
4.编写校验用户qq号的正则
'''很多时候 很多问题 前人已经弄好了 你只需要花点时间找一找就可以'''
ps:能够写出简单的正则 能够大致看懂复杂的正则
re模块
常见操作方法!!!!!!
在python中如果想要使用正则 可以考虑re模块
# 常见操作方法
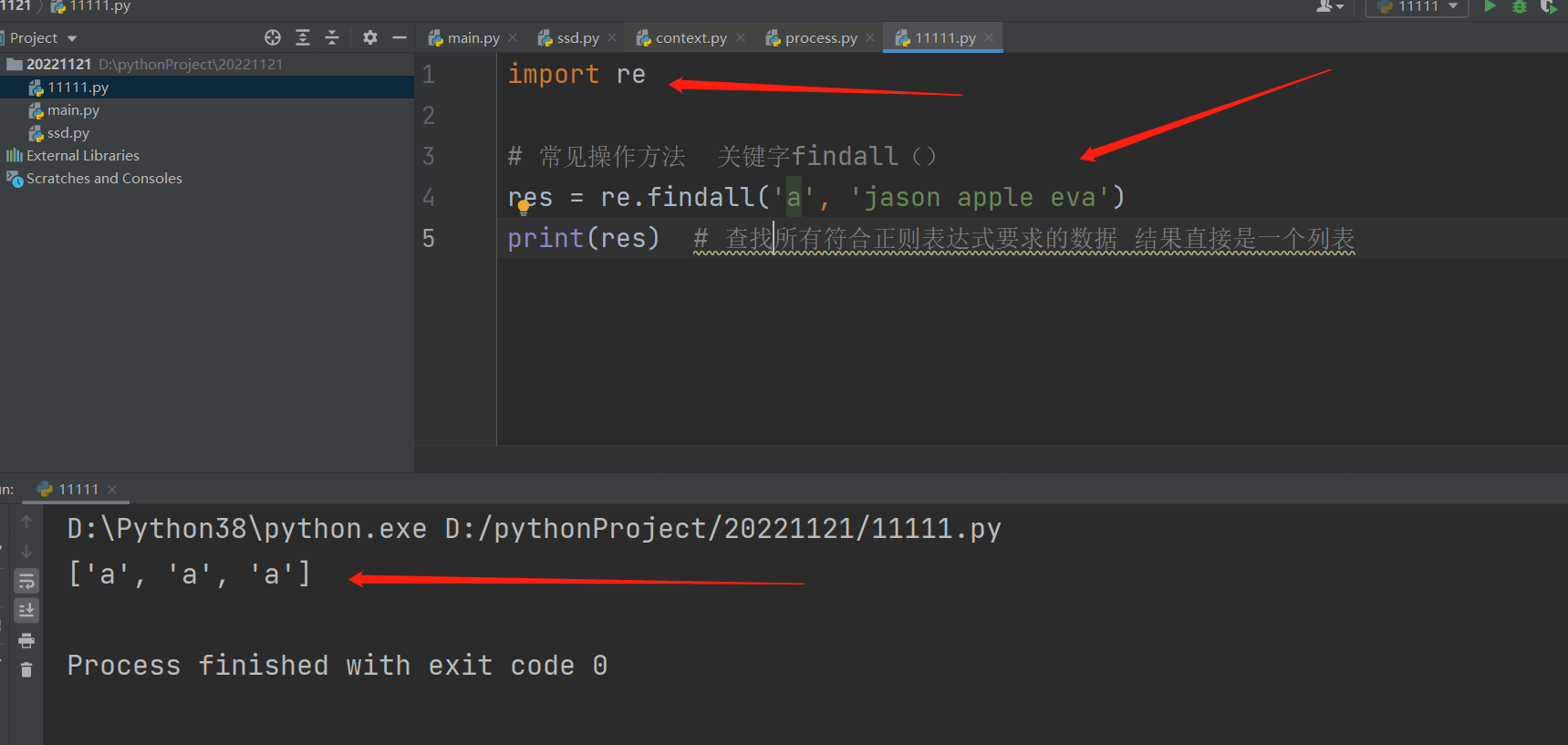
import re
res = re.findall('a', 'jason apple eva') # 两各参数(正则表达式,待匹配的文本)
print(res)
re.findall() 查找所有符合正则表达式要求的数据,结果直接是一个列表
----------------------------------------------------------
res = re.finditer('a', 'jason apple eva')
print(res)
re.finditer() 作用:查找所有符合正则表达式要求的数据,结果直接是一个迭代器对象(就是迭代器)可以用for循环把里面数据一个一个循环出来!!!
----------------------------------------------------------
res = re.search('a', 'jason apple eva')
print(res)
# <re.Match object; span=(1, 2), match='a'>
# re.search()方法匹配到一个符合条件的数据就立刻结束。
print(res.group())
# a 要调用.group()方法才能看到结果
-----------------------------------------------------------
res = re.match('a', 'jason apple eva')
print(res) # None
# 从字符串的开头开始匹配,如果不符合后面不用看了!!!
# 相当于自动给正则表达式加了一个上尖号。匹配到开头符合条件的数据,一个就结束
print(res.group())
# 要调用.group()方法才能看到结果
-------------------------------------------------------------
.
.
.
obj = re.compile('\d{3}') # 当某一个正则表达式需要频繁使用的时候 我们可以做成模板
res1 = obj.findall('23423422342342344')
res2 = obj.findall('asjdkasjdk32423')
print(res1, res2)
------------------------------------------------
ret = re.split('[ab]', 'abcd') # 'abcd' 是文本
# 先按'a'切割得到''和'bcd',在对''和'bcd'分别按'b'切割
print(ret) # ['', '', 'cd']
------------------------------------------------
ret = re.sub('\d', 'H', 'eva3jason4yuan4', 1)
# 将文本中,符合正则表达式的'\d'的数据替换成'H',参数1表示只替换1个
这样的话正则表达式不仅仅可以实现数据的筛选,还可以实现赛选的数据的替换了!!!
print(ret) # evaHjason4yuan4
------------------------------------------------
ret = re.subn('\d', 'H', 'eva3jason4yuan4')
# 将文本中,符合正则表达式的'\d'的数据替换成'H',并返回元组(替换的结果,替换了多少次)
print(ret) # ('evaHjasonHyuanH', 3)
re模块补充说明
1.分组优先!!!!!!!
1.分组优先
# res = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(res) # ['oldboy']
# findall分组优先展示:优先展示括号内正则表达式匹配到的内容
# res = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
# print(res) # ['www.oldboy.com']
# res = re.search('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(res.group()) # www.oldboy.com
# res = re.match('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(res.group()) # www.oldboy.com
2.分组别名
res = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
print(res.group('content')) # oldboy
print(res.group(0)) # www.oldboy.com
print(res.group(1)) # oldboy
print(res.group(2)) # .com
print(res.group('hei')) # .com
网络爬虫简介
网络爬虫:通过编写代码模拟浏览器发送请求获取数据并按照自己指定的要求筛选出想要的数据
小练习:利用正则表达式筛选出红牛所有的分公司数据并打印或保存
公司名称:
公司地址:
公司邮编:
公司电话:
作业
1.整理今日内容及博客
2.思考红牛分公司数据爬取
3.每人完成购物车五遍代码编写


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY