python第九课 员工管理系统代码讲解 文件类型及读写模式于操作模式 重要!!!
上周内容回顾
字典内置方法
1. 类型转换 dict()
2. 重要操作
dict1[key]
.get(key)
dict1[key] = value 常用!!!
修改与新增字典的键值对 键存在则修改对应的值 不存在,则在字典末尾新增一组键值对
del dict1[key] 只需要给一个键就可以将 这一组键值对都删除了
dict1.pop(key) 还是一样只要给一个键,就可以将 这一组键值对都都弹出字典了,只是没有直接删除掉,而是先保留了不像del直接删除了。
.update() 键存在则修改键值对 键不存在则新增键值对
.fromkeys([],[]) 快速生成值相同的字典,当然中括号里面也可以不写数字也可以生成值为空列表的字典
ps:字典内键值对默认是无序的
.
.
.
.
.
元组内置方法
1.类型转换 tuple()
2.重要操作
索引取值
元组内索引绑定的内存地址不能被修改(注意面试题)
集合内置方法
1.类型转换 set()
2.重要操作
去重
关系运算
ps:集合内数据值也是无序的
字符编码理论
主要针对文本文件
字符编码>>>:内部记录了人类的字符与数字的对应关系
字符编码表发展史
ASCII码
A-Z 65-90
a-z 97-122
GBK、shift_JIS、Euc_Kr
unicode、utf家族(utf8 utf16 utf32)
ps:英文字符采用一个字节 中文字符采用三个字节甚至更多
.
.
.
字符编码实操
1.解决文本文件乱码的核心就是当初以什么编码存的就以什么编码取
2.编码与解码
编码:人类字符>>>计算机字符
.encode() 括号里面写你要指定的编码表名称
解码:计算机字符>>>人类字符
.decode() 括号里面写你要指定的字符编码表,用于解码用
ps:在python中bytes类型可以看成是二进制数据 b''
3.python2解释器差异
文件头: # encoding:utf8
字符串: u''
今日内容概要
作业讲解
文件操作
利用python代码的编写来读写文件
1.文件的概念
2.文件的操作方式
3.文件读写模式
4.文件操作模式
5.文件诸多方法
6.文件内容修改
7.文件光标移动
今日内容详细
作业讲解
1.优化员工管理系统
拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写不会没有关系)
员工的信息有:用户名 年龄 岗位 薪资...
员工管理系统:注册、查看(单个员工、所有员工)、修改薪资、删除员工
'''
数据存储的方式1
{
'jason':[18, 'teacher', 10],
'kevin':[28, 'sale', 90]
}
数据存储的方式2
{
'jason':{'age':18, 'job':'teacher', 'salary':8000},
'kevin':{'age':28, 'job':'sale', 'salary':9000}
}
数据存储的方式3
{
'1':{'name':'jason','age':18, 'job':'teacher', 'salary':8000},
'2':{'name':'kevin','age':28, 'job':'sale', 'salary':9000},
'3':{'name':'jason','age':18, 'job':'teacher', 'salary':8000},
}
'''
首先思考以上哪一种的字典的存储数据的方式比较合理,显然第3种的字典内的数据存储是最合理的。
第一种 每一个值的列表里面的数据指示的不不清楚。
第二种 如果用户名存在重名的情况就不太好操作,字典里面的键名称是不能一样的。
第三种 对每一个用户编一个数字代号作为键,这样只要知道键的数字就可以将该用户名的所有信息都拿到了。这种字典里面套了字典的结构是最合理的。
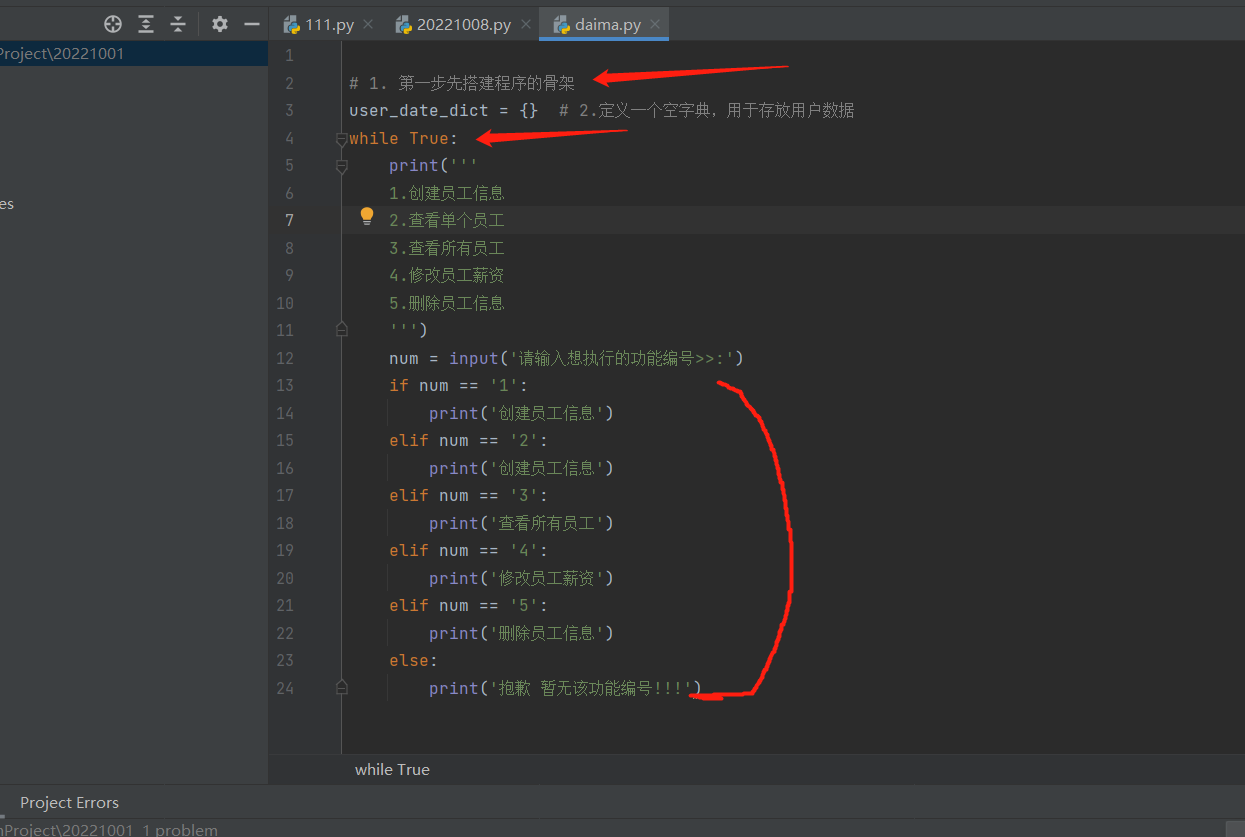
还是一样,写代码前先想一想,代码的整体框架,先把整体框架主体功能搭好,后面就一个一个的小模块写就好了。
# 1. 第一步先搭建程序的骨架
user_date_dict = {} # 2.定义一个空字典,用于存放用户数据
while True:
print('''
1.创建员工信息
2.查看单个员工
3.查看所有员工
4.修改员工薪资
5.删除员工信息
''')
num = input('请输入想执行的功能编号>>:') # 3.获取员工想执行的功能编号,用num接收
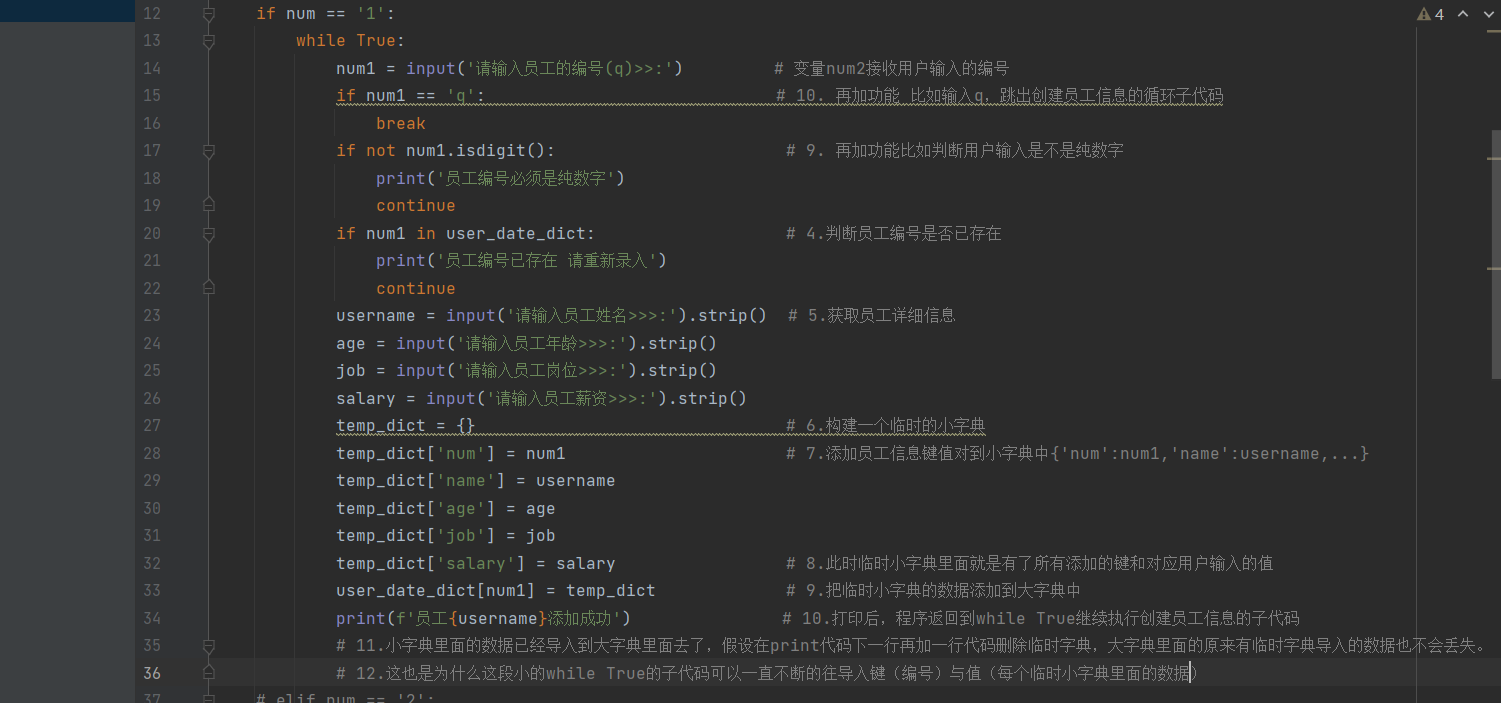
if num == '1':
while True:
num1 = input('请输入员工的编号(q)>>:') # 变量num2接收用户输入的编号
if num1 == 'q': # 10. 再加功能 比如输入q,跳出创建员工信息的循环子代码
break
if not num1.isdigit(): # 9. 再加功能比如判断用户输入是不是纯数字,不是纯数字执行子代码,注意if后多了not
print('员工编号必须是纯数字')
continue
if num1 in user_date_dict: # 4.判断员工编号是否已存在
print('员工编号已存在 请重新录入')
continue
username = input('请输入员工姓名>>>:').strip() # 5.获取员工详细信息
age = input('请输入员工年龄>>>:').strip()
job = input('请输入员工岗位>>>:').strip()
salary = input('请输入员工薪资>>>:').strip()
temp_dict = {} # 6.构建一个临时的小字典
temp_dict['num'] = num1 # 7.添加员工信息键值对到小字典中{'num':num1,'name':username,...},就是利用字典的键存在则修改值,键不存在则新增键值对。
temp_dict['name'] = username
temp_dict['age'] = age
temp_dict['job'] = job
temp_dict['salary'] = salary # 8.此时临时小字典里面就是有了所有添加的键和对应用户输入的值
user_date_dict[num1] = temp_dict # 9.把临时小字典的数据添加到大字典中
print(f'员工{username}添加成功')
# 10.打印后,程序返回到while True继续执行创建员工信息的子代码
# 11.小字典里面的数据已经导入到大字典里面去了,假设在print代码下一行再加一行代码删除临时字典,大字典里面的原来有临时字典导入的数据也不会丢失。这也是为什么这段小的while True的子代码可以一直不断的往导入键(编号)与值(每个临时小字典里面的数据)
# 12.这里大字典里面的键是员工编号,为什么在大字典的值小字典里面还要重复的放入员工编号,是为了后续再第3个代码块打印所有用户信息时,为了更方便的在字符串格式化输出里面将每一个员工对应的编号输出出来。临时字典里面不导入员工编号,后续的打印所有用户信息的时候,在for循环取出每一个大字典里面的键值对中的值的,此时小字典里面是没有员工编号的是无法调用的,直接拿大字典里面的键时肯定要for循环大字典键值对,就于上面的for循环取出大字典的键值对中的值的操作有冲突了,在执行一个格式化输出前,同时执行两个不同的for循环,比较有难度。
# 空一行方便区分代码块
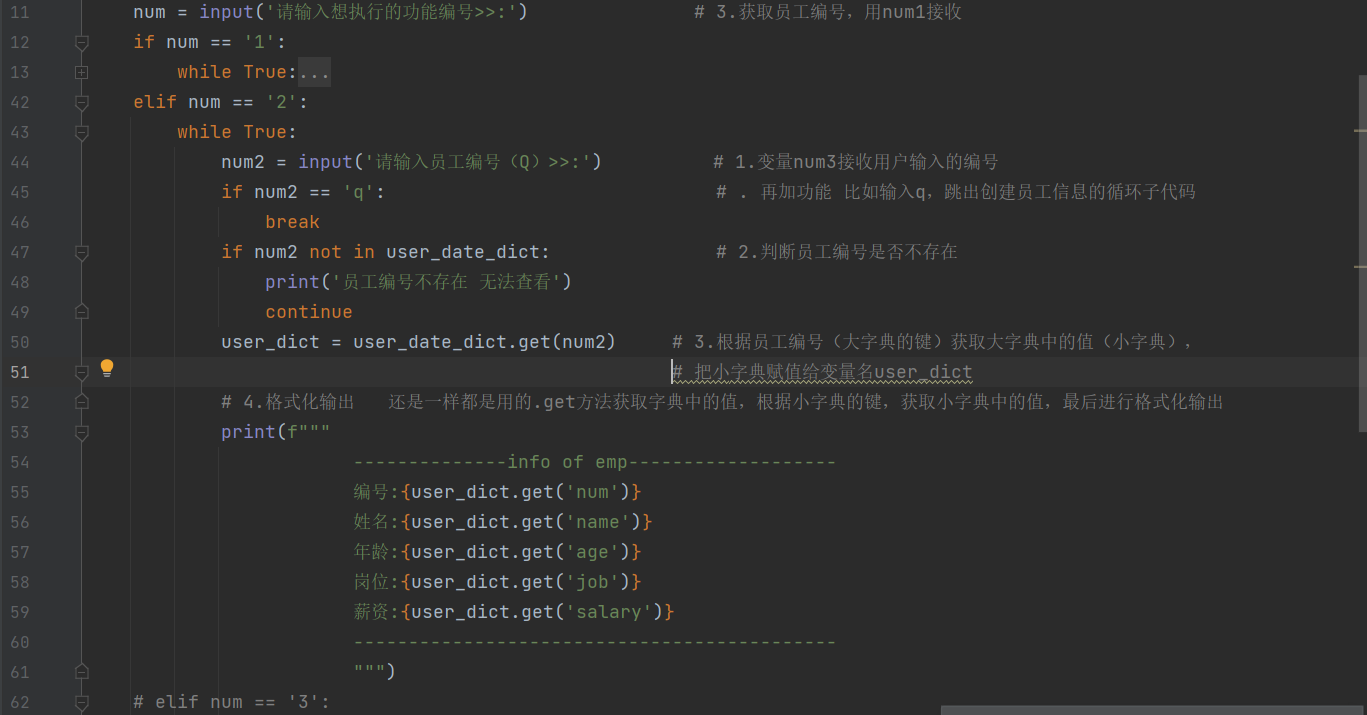
elif num == '2':
while True:
num2 = input('请输入员工编号(Q)>>:') # 1.变量num3接收用户输入的编号
if num2 == 'q': # 再加功能 比如输入q,跳出创建员工信息的循环子代码
break
if num2 not in user_date_dict: # 2.判断员工编号是否不存在
print('员工编号不存在 无法查看')
continue
user_dict = user_date_dict.get(num2) # 3.根据员工编号(大字典的键)获取大字典中的值(小字典),把小字典赋值给变量名user_dict
# 4.格式化输出 还是一样都是用的.get方法获取字典中的值,根据小字典的键,获取小字典中的值,最后进行格式化输出
print(f"""
--------------info of emp-------------------
编号:{user_dict.get('num')}
姓名:{user_dict.get('name')}
年龄:{user_dict.get('age')}
岗位:{user_dict.get('job')}
薪资:{user_dict.get('salary')}
--------------------------------------------
""")
# 空一行方便区分代码块
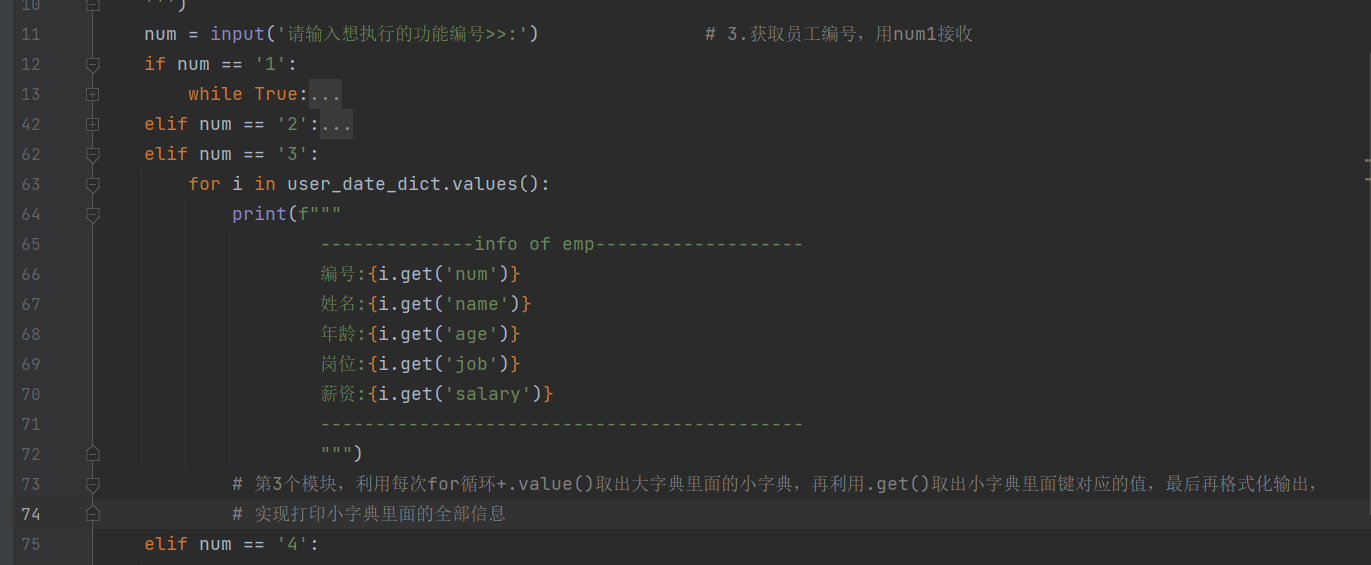
elif num == '3':
for i in user_date_dict.values():
print(f"""
--------------info of emp-------------------
编号:{i.get('num')}
姓名:{i.get('name')}
年龄:{i.get('age')}
岗位:{i.get('job')}
薪资:{i.get('salary')}
--------------------------------------------
""")
# 第3个模块,利用每次for循环+.value()取出大字典里面的小字典,再利用.get()取出小字典里面键对应的值,最后再格式化输出,
# 实现打印小字典里面的全部信息
# 空一行方便区分代码块
elif num == '4':
print('修改员工薪资')
while True:
num4 = input('请输入您想要修改的员工编号(q)>>>:').strip() # 1.先获取想要修改的员工编号
if num4 == 'q': # 7.再加小功能 比如输入q,跳出创建员工信息的循环子代码
break
if num4 not in user_date_dict: # 2.判断用户输入的编号不在大字典的所有的键里面,不需要在大字典后面加.keys()了
# 此处成员运算符默认的就是判断字典的键。
print('员工编号不存在')
continue
new_salary = input('请输入该员工的新薪资待遇>>>:').strip() # 3.执行到这行说明编号一定存在,再获取新的薪资数据
if not new_salary.isdigit(): # 8.再加小功能 比如判断薪资是不是纯数字
print('薪资只能是纯数字')
continue
user_dict = user_date_dict.get(num4) # 4.利用.get(键)获取大字典中的小字典(值),并赋值给user_dict
user_dict['salary'] = new_salary # 5.根据用户输入new_salary,修改小字典中'salary'(键)对应的数据(值),
# 比如用户input的new_salary为:321 那么小字典中'salary'对应的原来的数据就改为321了
user_date_dict[num4] = user_dict # 6.通过大字典的键修改大字典的值,将已修改的小字典,通过大字典的键(num4)
# 替换了大字典原来对应的值
print(user_date_dict.get(num4)) # 9.最后打印已修改的大字典的值,就是小字典员工信息。
# 空一行方便区分代码块
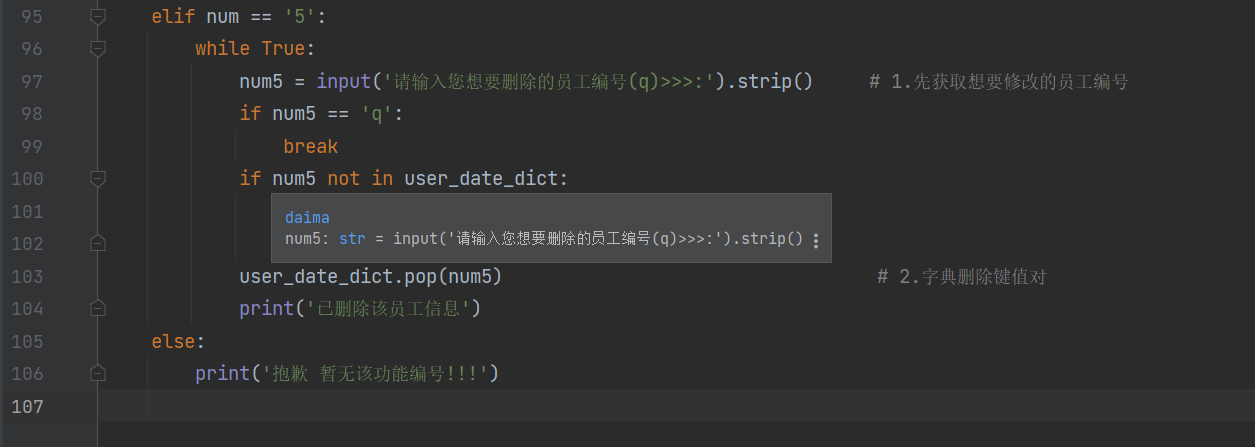
elif num == '5':
while True:
num5 = input('请输入您想要删除的员工编号(q)>>>:').strip()
# 1.先获取想要修改的员工编号
if num5 == 'q':
break
if num5 not in user_date_dict:
print('员工编号不存在')
continue
user_date_dict.pop(num5) # 2.字典删除键值对
print('已删除该员工信息')
else:
print('抱歉 暂无该功能编号!!!')
- 先搭框架
- 第一个功能写好了
- 第二个功能写好了
- 第三个功能写好了
- 第四个功能写好了

- 第五个功能写好了
.
. - 去重下列列表并保留数据值原来的顺序
eg: [1,2,3,2,1] 去重之后 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]
第一种:
不考虑顺序的情况下 去重
s1 = set(l1)
l2 = list(s1)
print(l2)
[1, 2, 3, 4, 5, 6]
第二种:
考虑顺序的情况下 去重
new_list = [] # 先定义一个空列表
for i in l1: # 利用for循环遍历出列表里的每一个值
if i not in new_list: # 再利用成员运算判在不在列表里面
new_list.append(i) # 不在的执行将数据添加到列表里面的操作
print(new_list) # 当判断数据在列表里面时,不执行if的子代码,继续for循环取值,最终实现保留顺序的情况下,去重。
[2, 3, 1, 4, 5, 6]
.
3. 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
代码实现:
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
print(pythons & linuxs)
print(pythons | linuxs)
print(pythons - linuxs)
print(pythons ^ linuxs)
.
.
4. 统计列表中每个数据值出现的次数并组织成字典展示
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
代码实现:
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
data_dict = {} # 1.先定义结果集空字典
for i in l1: # 2.循环遍历出列表中每一个数据值
if i not in data_dict: # 3.判断当前数据值是否在字典的键中,字典的成员运算默认的是判断键
data_dict[i] = 1 # 4.如果不在,新增键值对
else:
data_dict[i] += 1 # 5.如果在,则修改键对应的值,相当于 data_dict[i] = data_dict[i] + 1
print(data_dict)
{'jason': 2, 'kevin': 3, 'oscar': 1, 'tony': 1}
.
.
.
.
.
.
文件基础操作
# 注意文件的打开是打开的操作,读是读的操作,写是写的操作,
# 打开操作里面要选定好什么模式打开文件,只读、只写、还是追加模式打开。
只读模式打开,后续只能读,.read()后文件不存在就会报错。
括号里面不写,默认从头读到最后,程序重新运行后还是从开头读到最后,
但是如果先运行一个读,再运行一个读,第二个读就读不到东西了!!!!!!
只写模式打开,后续只能写,.write()后,会先清空原文件里的数据,如果原文件不存在,会自动添加一个
追加模式打开,后续只能写,.write()后,是在末尾追加数据,不会清空原文件数据,如果原文件不存在,
会自动添加一个
.
.
.
.
1. 文件的概念: 就是操作系统暴露给或者叫提供给用户操作硬盘的快捷方式
eg:双击一个文件 其实是从硬盘将数据加载到内存
ctrl+s保存文件 其实是将内存中的数据刷到硬盘保存
.
.
.
.
.
通过代码打开文件的两种方式 重要!!!!!
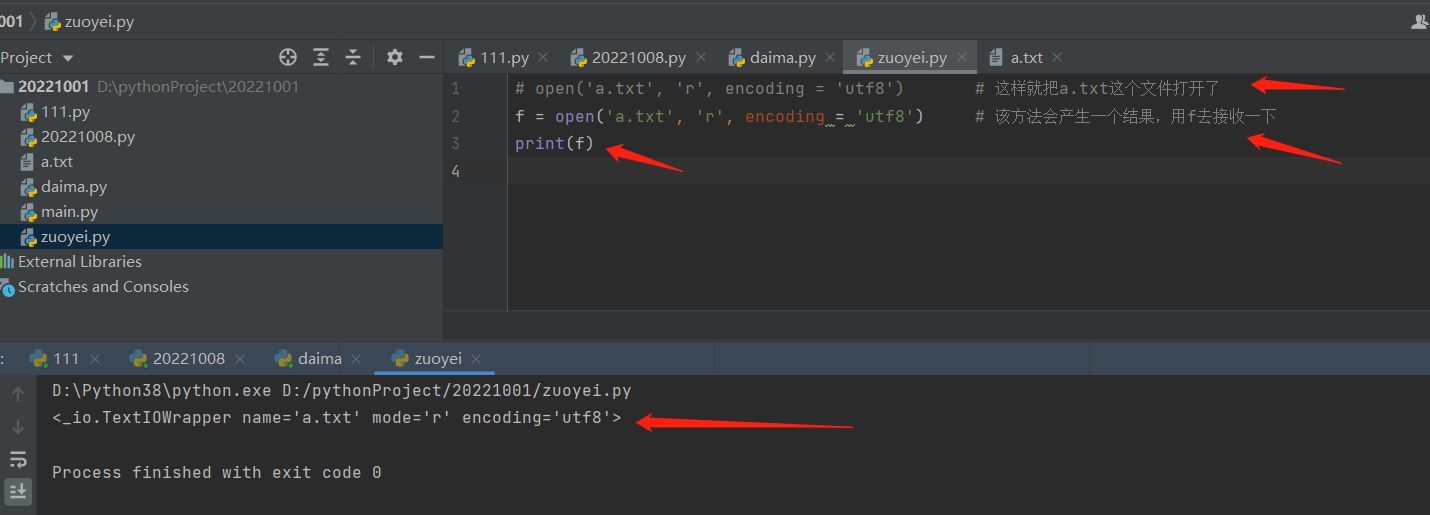
# 方式1:不常用
f = open('文件路径','读写模式',encoding='utf8') # 通过代码打开文件
print(f.read()) # 通过代码读取文件
f.close() # 通过代码立刻关闭刚刚打开的文件资源
# 可以这么理解:首先操作系统将文件从硬盘读到内存上,py的代码文件也在内存上的一块独立空间运行起来了,
变量f指向的就是文件在内存上的资源,然后执行f.read(),相当于把文件的内容交给程序去查看了。
当py文件程序运行结束后,这些变量会自动被垃圾回收机制回收掉,
但系统打开的文件在内存里的数据不会立即就清掉。如果频繁的大量的执行open操作而不执行close操作,
内存可能会爆了导致崩掉。
打印的是文件对象
.
.
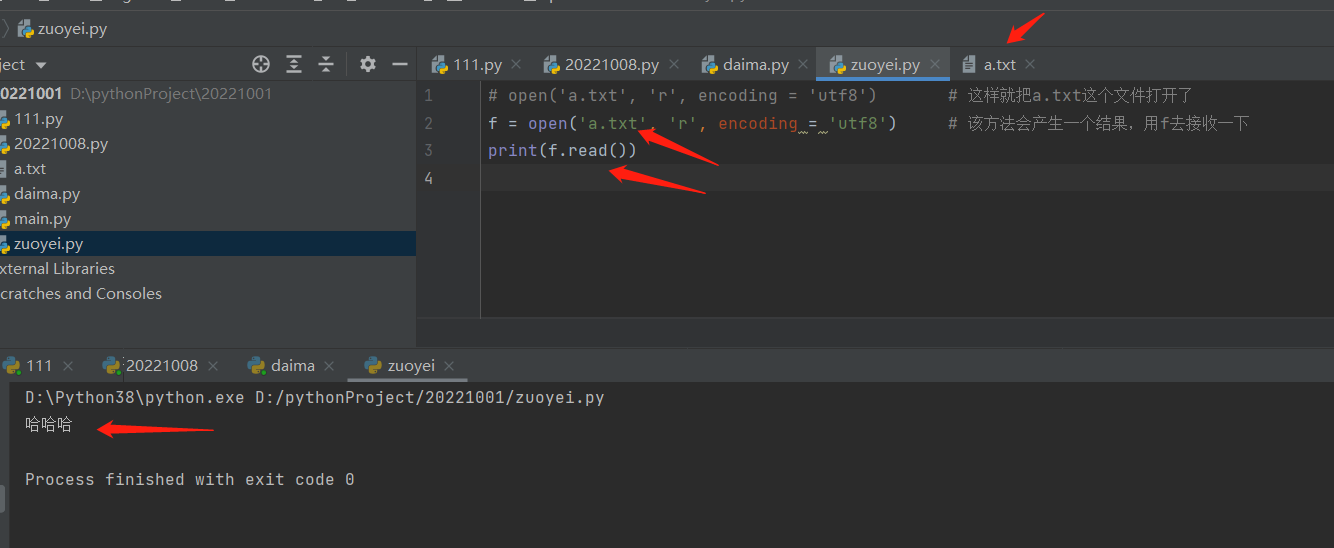
# 方式2代码打开文件更方便 : 常用重要!!!!!
# f 就是打开的这个文件的文件对象
with open('a.txt', 'r', encoding='utf8') as f:
print(f.read())
与操作1的操作结果是一样的,就是省略了一行关闭的代码,关闭的功能已经包含在里面了。
with这种语法的好处在于,with子代码运行结束,会自动调用close方法关闭资源!!!!
当文件较大时,直接f.read() 可能对内存不友好, 可以f.chunks() 分块读取
.
.
.
.
注意事项 :
# 注意打开文件的时候,要么是绝对路径,如果想要用相对路径,
# 该路径必须和你打开操作所在的文件在同一个目录下才行,你就算在外面已经添加了环境变量也不行!!!
## 1. open('文件路径','读写模式',encoding参数)
encoding参数在默认情况下就是'utf8'
在写文件路径时一定要写全了,具体到文件的名称。
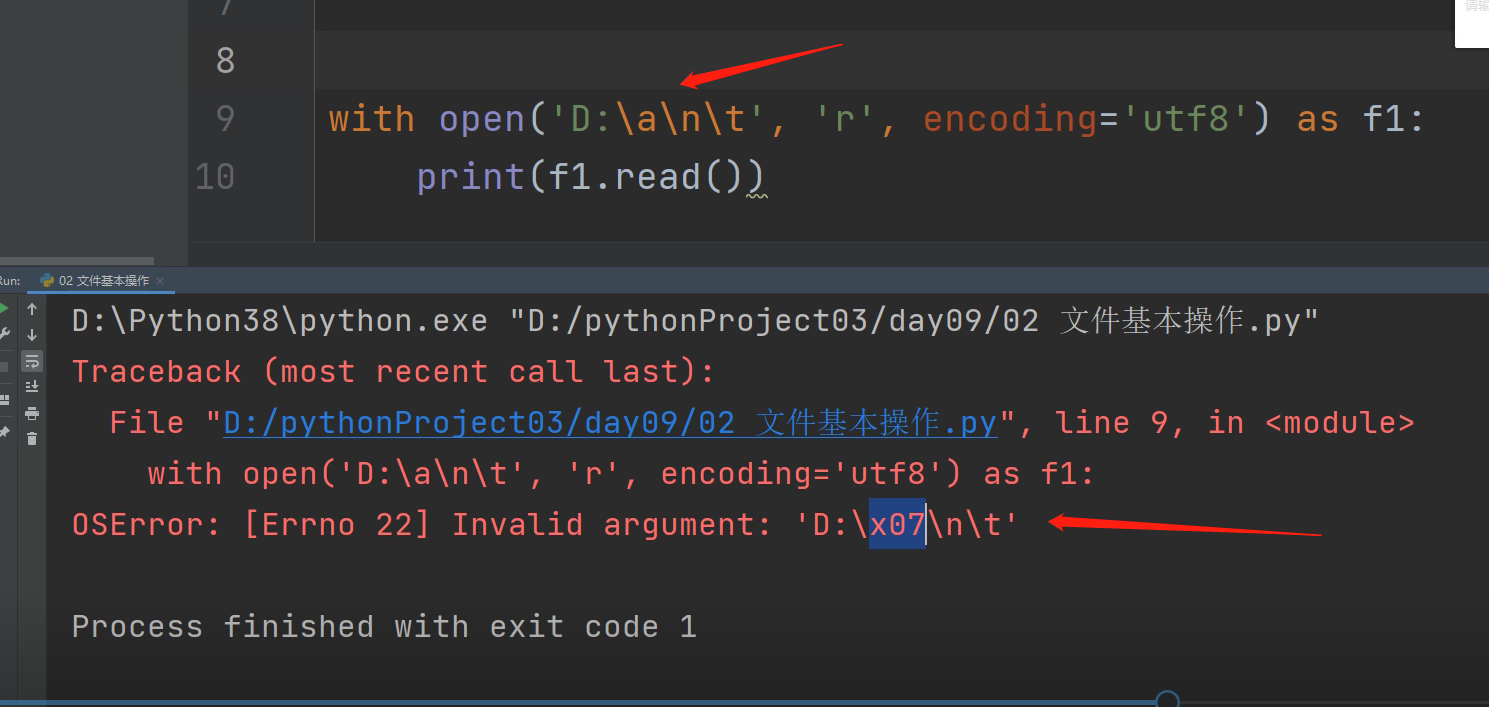
## 2. open方法的第一个参数是:文件路径
在输入文件路径时比如 D:\a\n\t 撬棍\与一些字母的组合会产生特殊的含义,会导致路径查找混乱。
解决办法:在字符串的路径前面加字母r 取消转义符 符号就变成单纯的符号,没有特殊含义了
r'D:\a\n\t' 文件路径的字符串前面加了r,就是告诉电脑这个字符串是原字符串。
### 以后涉及到路径的填写 推荐直接加上r
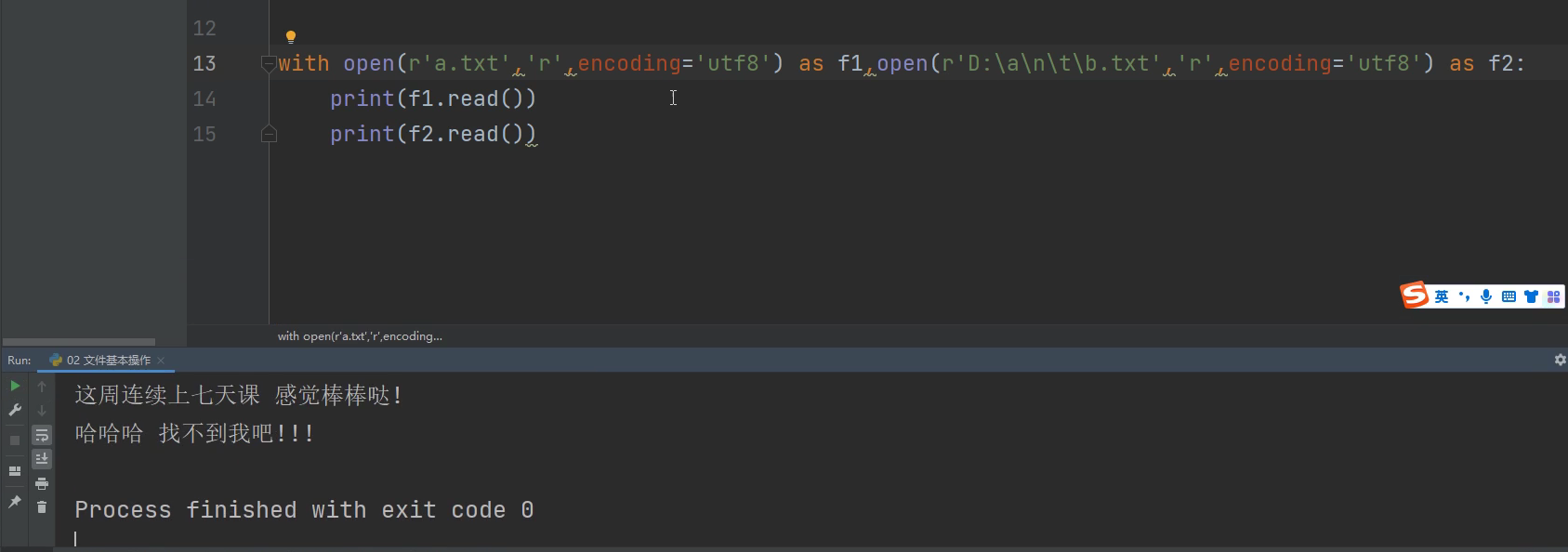
### 3. with语法支持一次性打开多个文件,只要中间逗号隔开就行了。比如:
with open(r'a.txt','r',encoding='utf8') as f1, open(r'D:\t\b.txt','r',encoding='utf8') as f2:
子代码
.
.
.
.
.
.
文件读写模式
# 1. 只读模式:只能读不能写 'r'
with open(r'b.txt','r',encoding='utf8') as f:
print(f.read()) # 1.文件路径不存在,用只读模式是打不开的,会直接报错
with open(r'a.txt', 'r', encoding='utf8') as f:
print(f.read()) # 2.文件路径存在:正常读取文件内容
--------------------------------------------
# 2. 只写模式:只能写不能看 'w'
with open(r'b.txt', 'w', encoding='utf8') as f: # 1.文件路径不存在:自动创建文件
pass
# 2.文件路径存在:先清空文件内容之后!!!,再写入
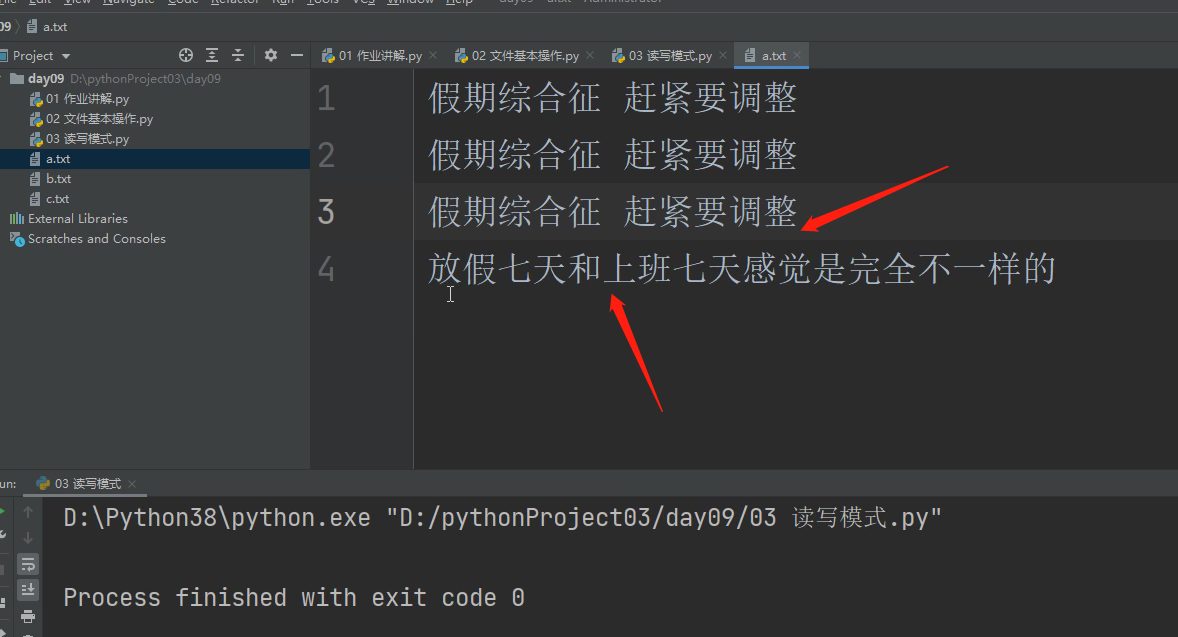
with open(r'a.txt', 'w', encoding='utf8') as f:
f.write('假期综合征 赶紧要调整\n')
f.write('假期综合征 赶紧要调整\n') #.write()就是写的方法
f.write('假期综合征 赶紧要调整\n')
# 注意!!!:
当想写多行文字时,换行符需要自己添加,不添加换行符\n,不然就会连着写,不换行。
并且在后续数据读取比对的时候,也一定要注意它的存在!!!
--------------------------------------------
# 3. 只追加模式:文件末尾添加数据 'a'
with open(r'c.txt', 'a', encoding='utf8') as f:
pass # 文件路径不存在:也不报错,也自动创建文件
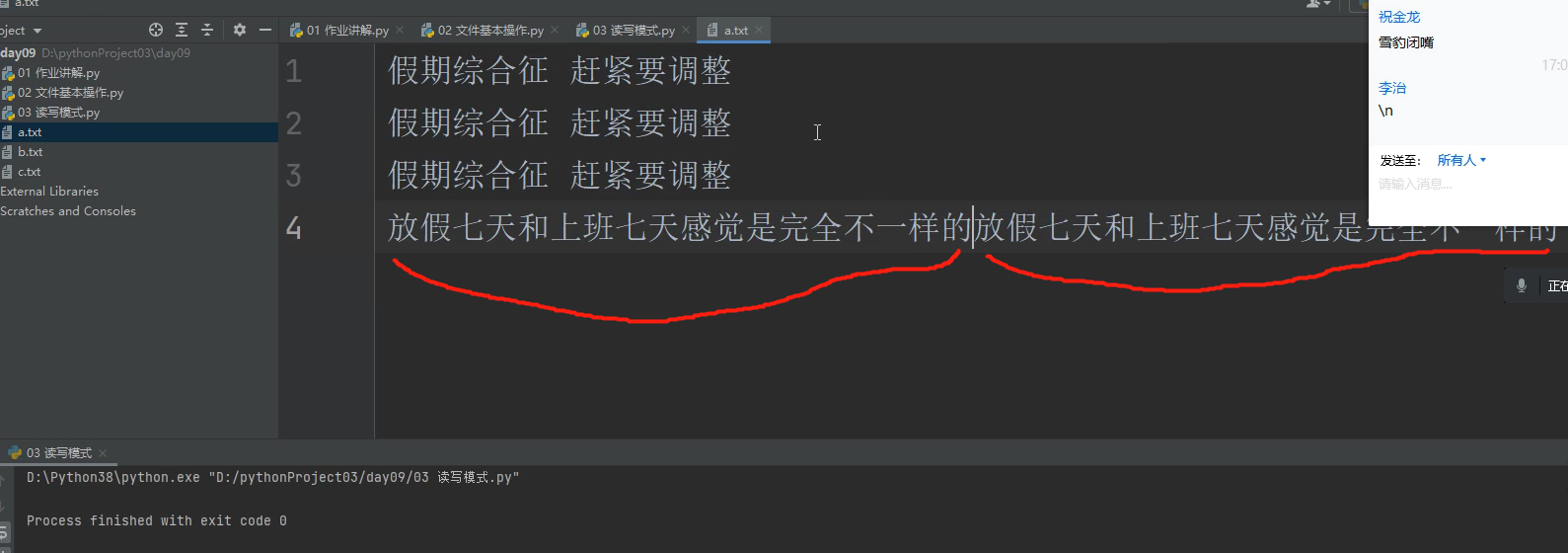
with open(r'a.txt', 'a', encoding='utf8') as f:
f.write('放假七天和上班七天感觉') # 文件路径存在:自动在末尾等待追加内容
--------------------------------------------
这个地方之所以这段换自动换行了,是因为在上面的只写模式里面写了3行代码都带有换行符,
所以换行追加了,否则会在文件内容的末尾直接追加。
.
代码再执行一次就变为了:
文件的操作模式
-------------------------------------------
# 文本模式 t
# 我们上面所写的r w a其实全称是 rt wt at
文本模式的特点:
1.只能操作文本文件!!!
2.读写都是以字符为单位!!!
3.需要指定encoding参数!!! 如果不指定,则会采用计算机默认的编码,可能会出问题,所以最好指定一下。windos底层默认的编码表是GBK,苹果的底层默认的可能是ASCII码
-------------------------------------------
# 二进制模式 b(bytes模式) 就直接看成是二进制模式就行了
不是默认的模式 需要自己指定
二进制只读模式rb 二进制只写模式wb 二进制只追加模式ab
------------------
# 二进制模式的特点:
1.可以操作任意类型的文件!!!
2.读写都是以bytes为单位!!!
3.不需要指定encoding参数 因为它已经是二进制模式了 不需要再指定编码表了
------------------
# 二进制模式用法示例:
比如:下代码就会把上面a.txt文件里面的内容用二进制只读模式读出来
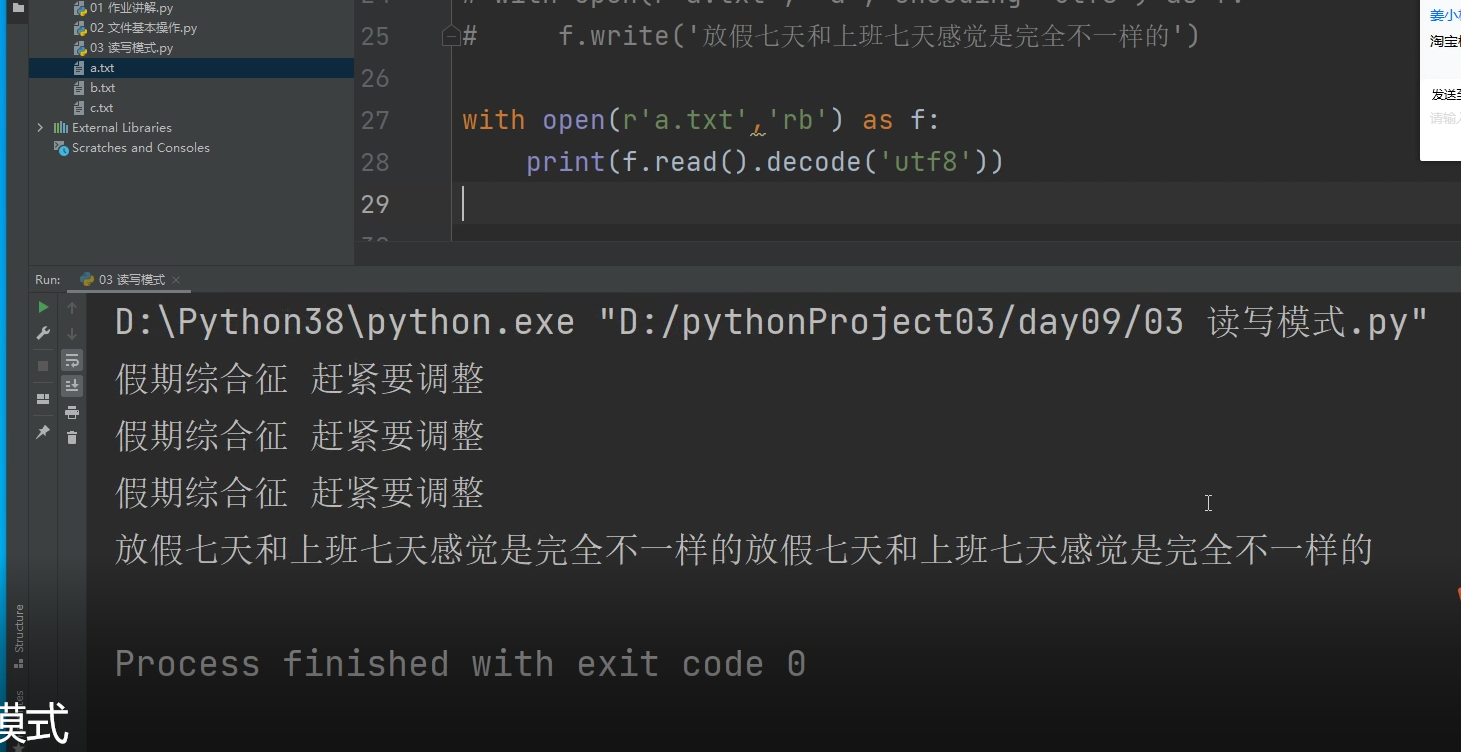
with open(r'a.txt', 'rb') as f:
print(f.read())
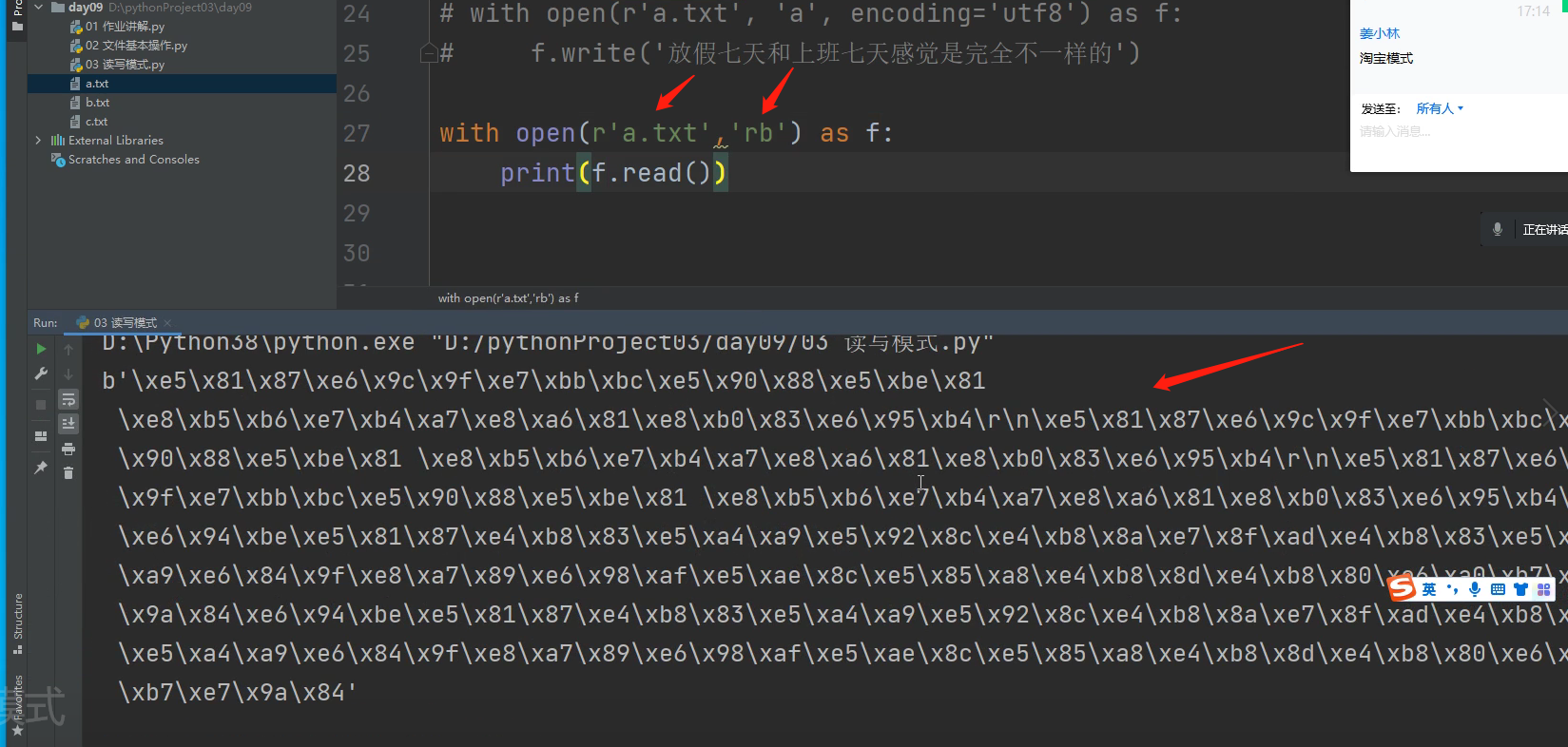
.
还可以再利用.decode()方法解码成,人能读的字符
.
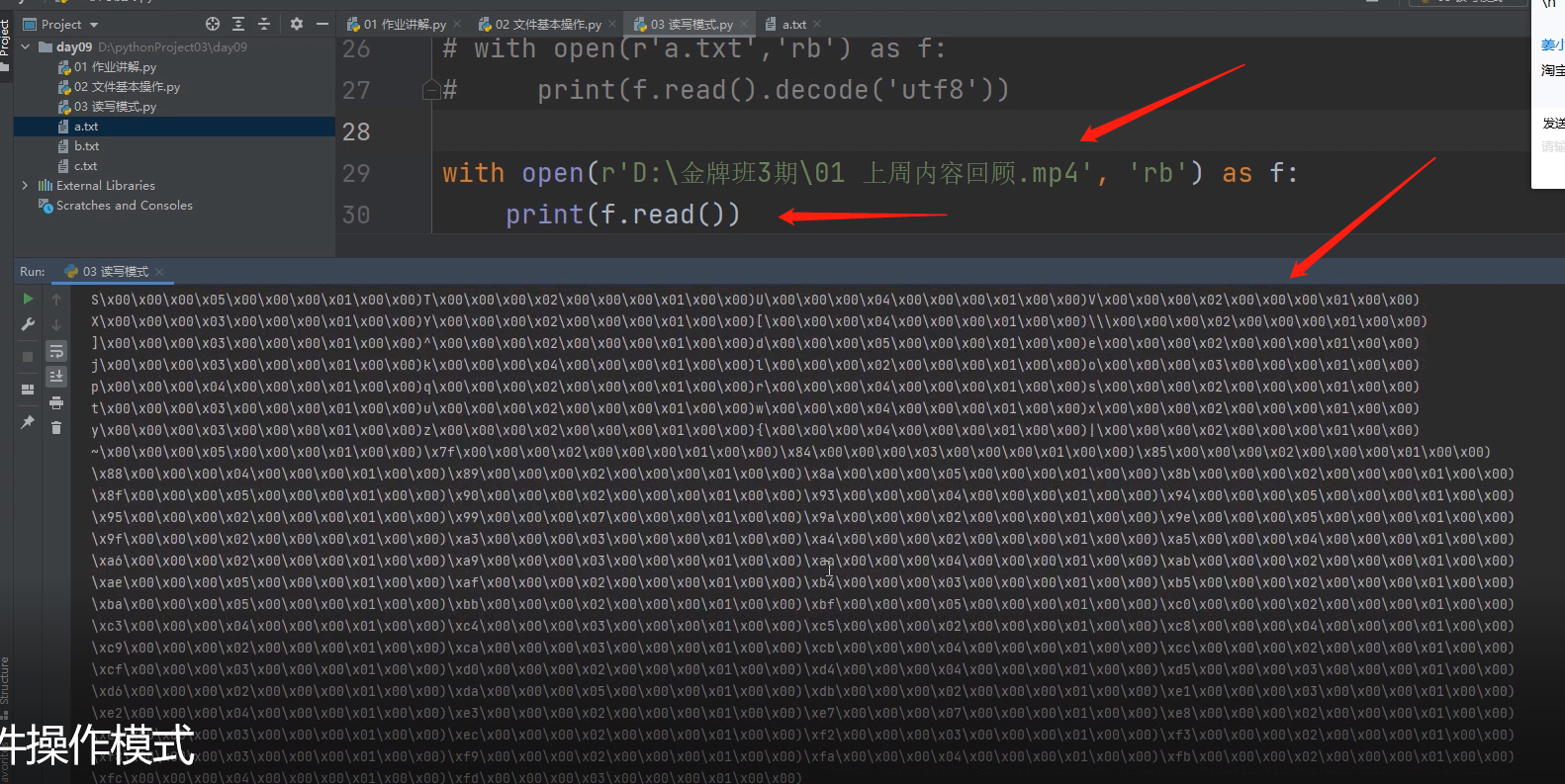
还可以打开其他类型的文件,比如读取视频文件的数据,因为不是普通文本,不能直接解码开,要用视频软件才能解开。
.
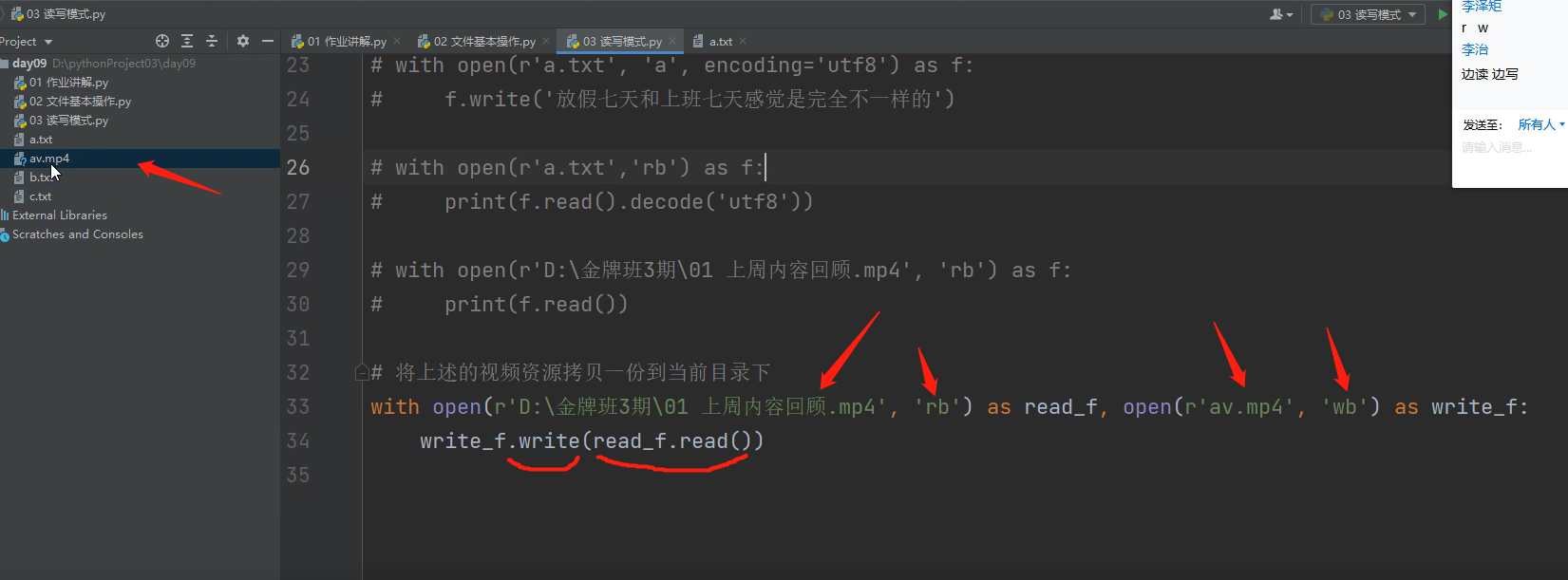
将视频资源拷贝一份到当前的python文件目录下,也就是计算机底层复制粘贴是怎么实现的:
先将视频文件的内容用二进制只读模式取出来后,然会用二进制只写模式生成一个新的文件,最后再把数据往新的文件里面写。
.
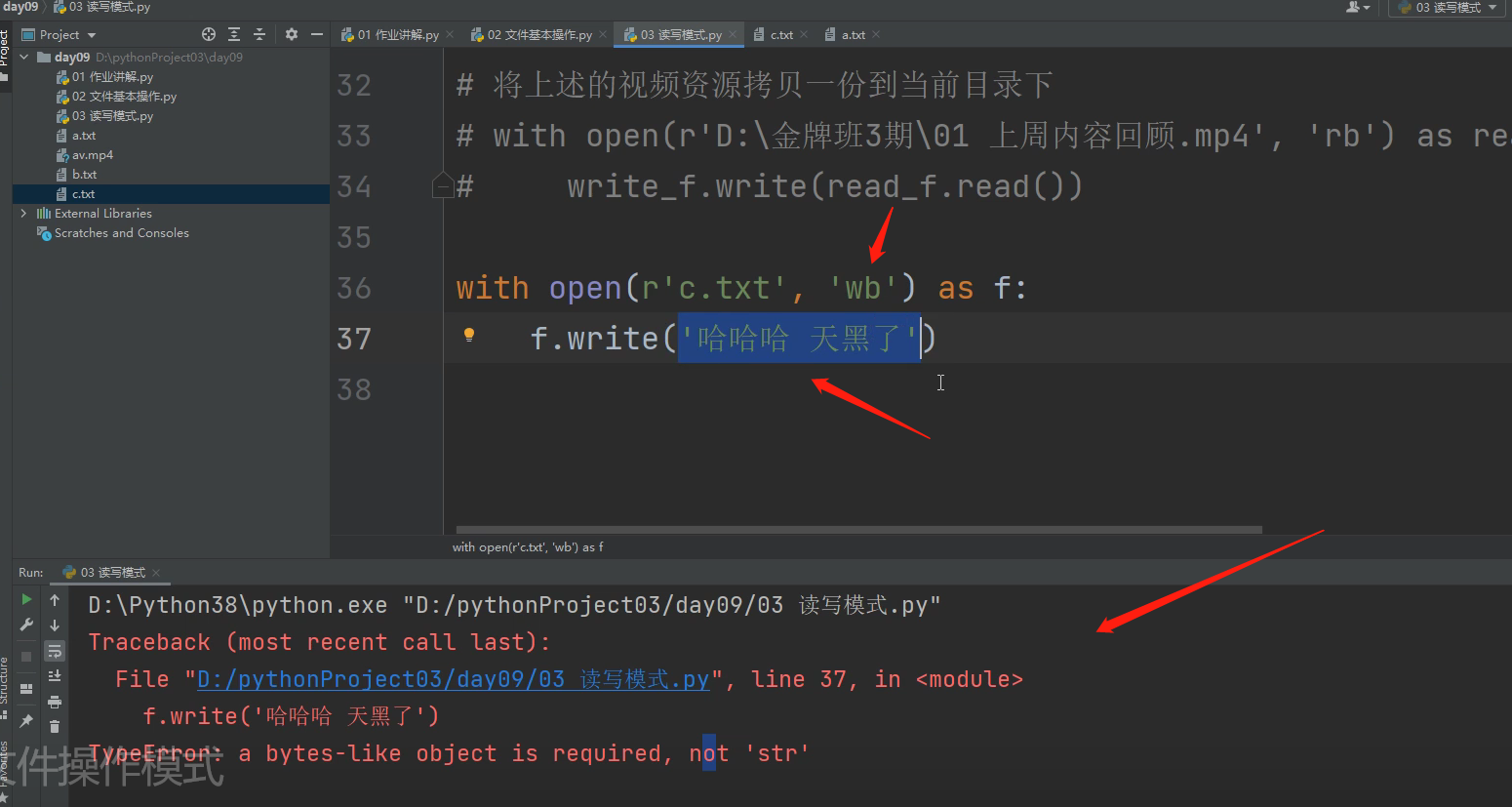
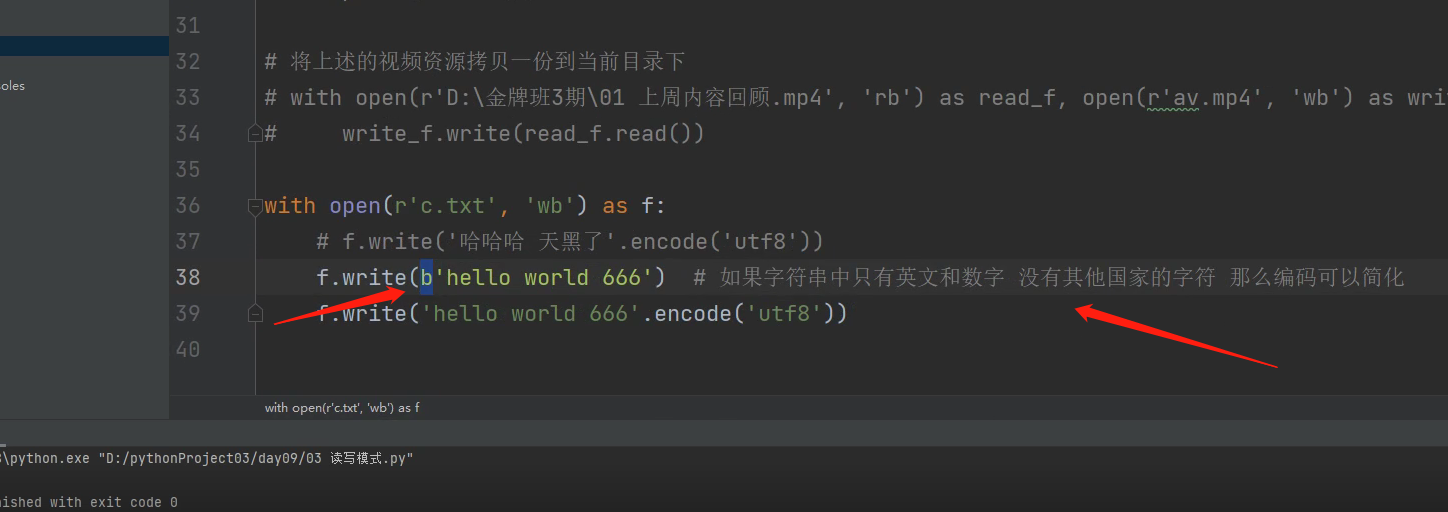
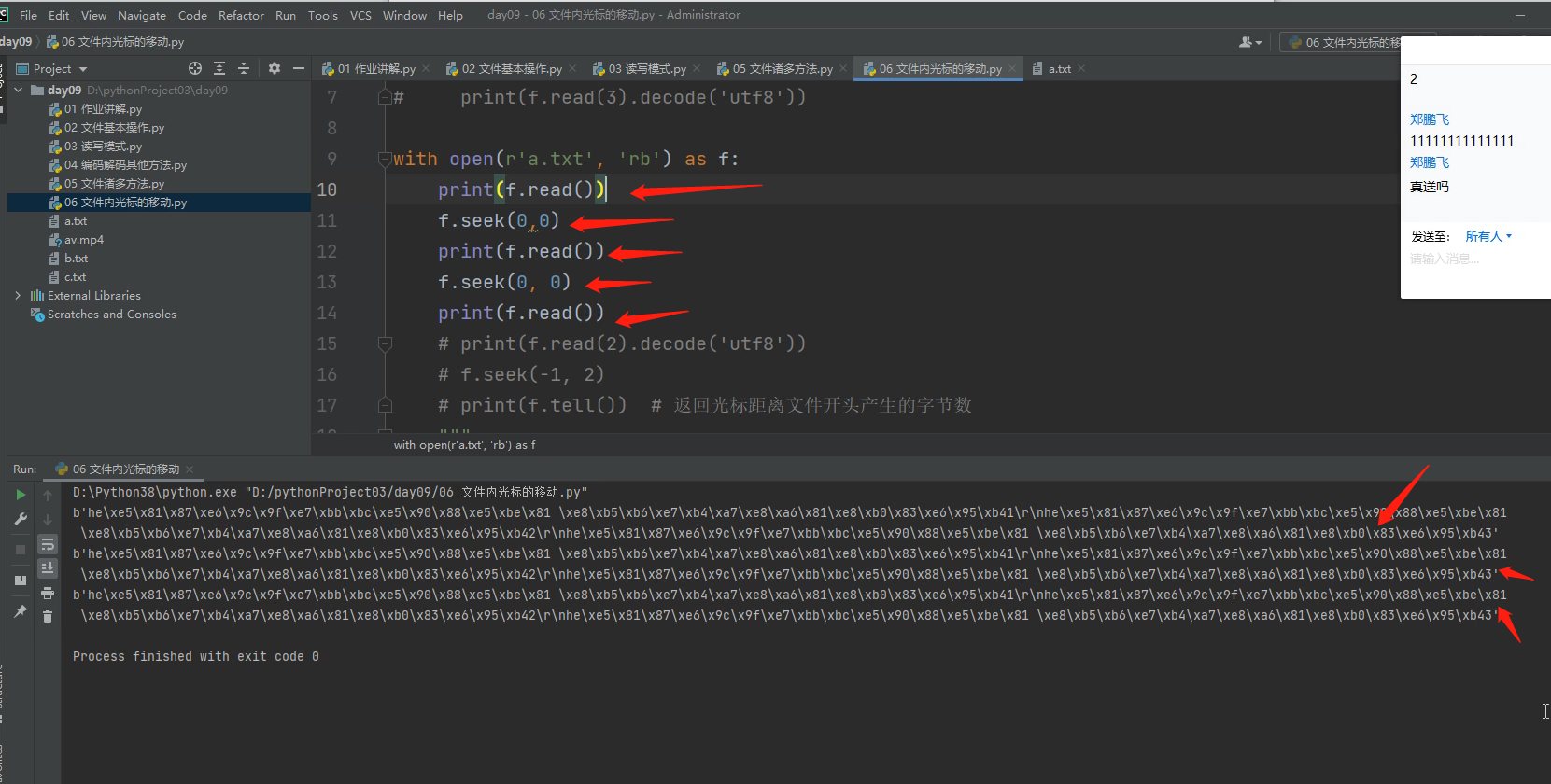
注意:在二进制只写模式下,是写不进去中文的!!!!,必须把字符串转成二进制模式才能写进去。
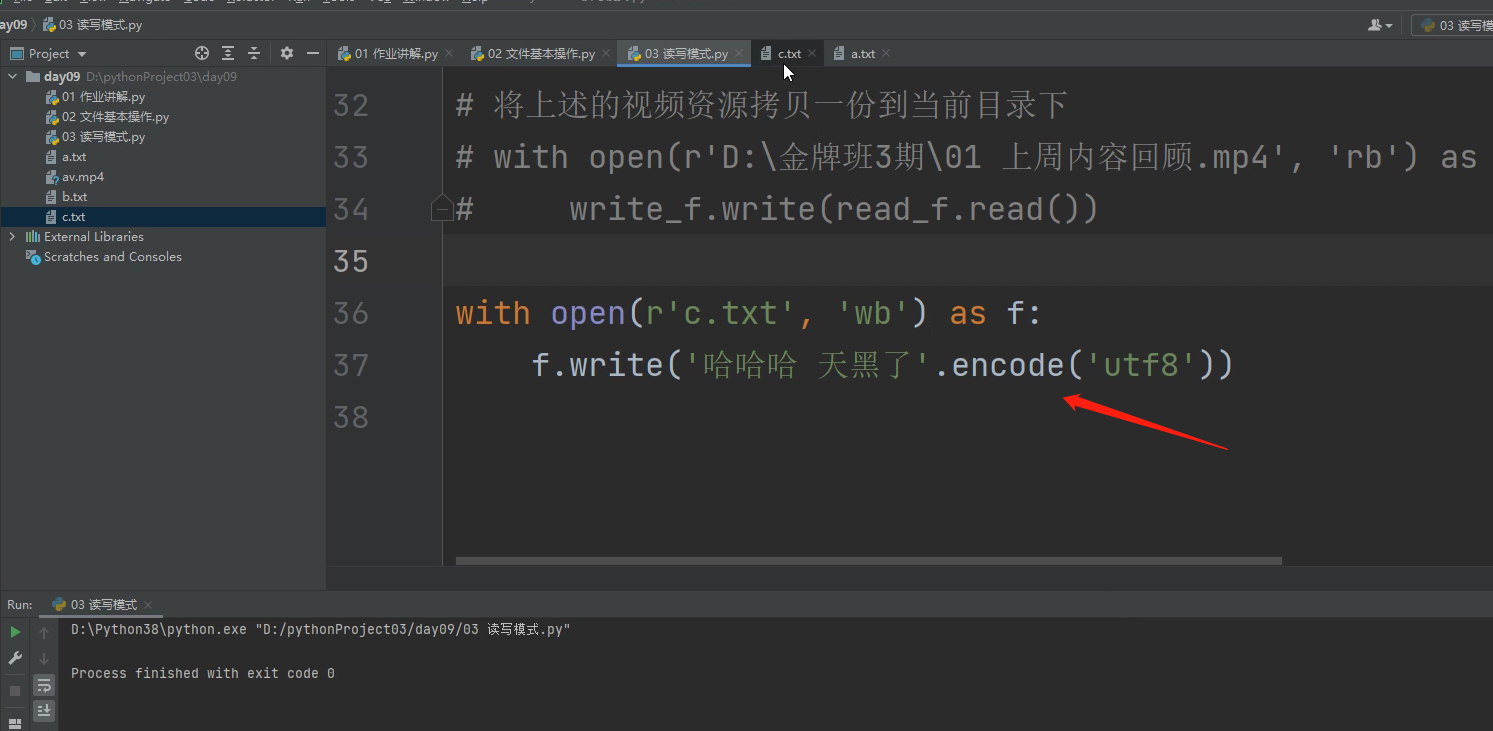
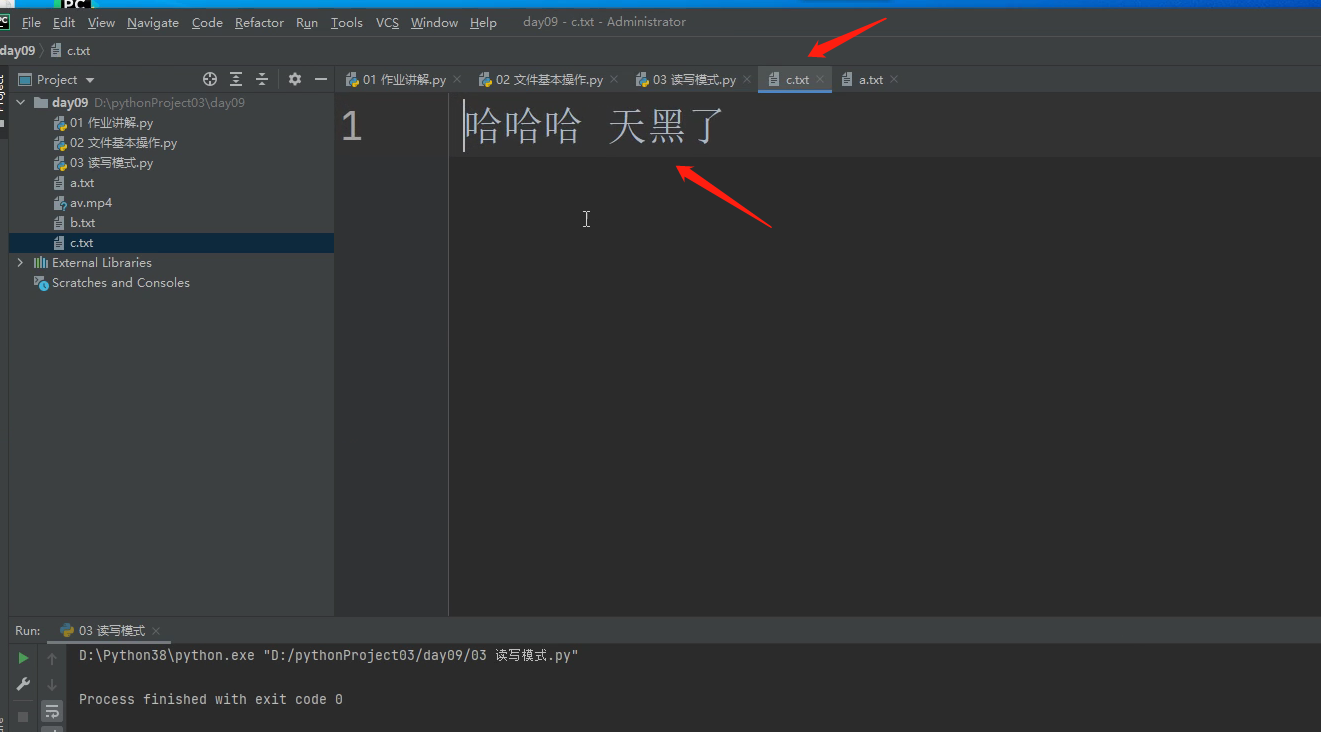
如果字符串里面没有中文,可以在字符串前面直接加b,相当于自动帮你调用了.encode(utf8) 这是个简写操作。
.
.
.
.
.
.
.
扩展知识
中文转化为二进制的方法有.encode()
还有一种用bytes方法把中文转化为二进制的方法如下:
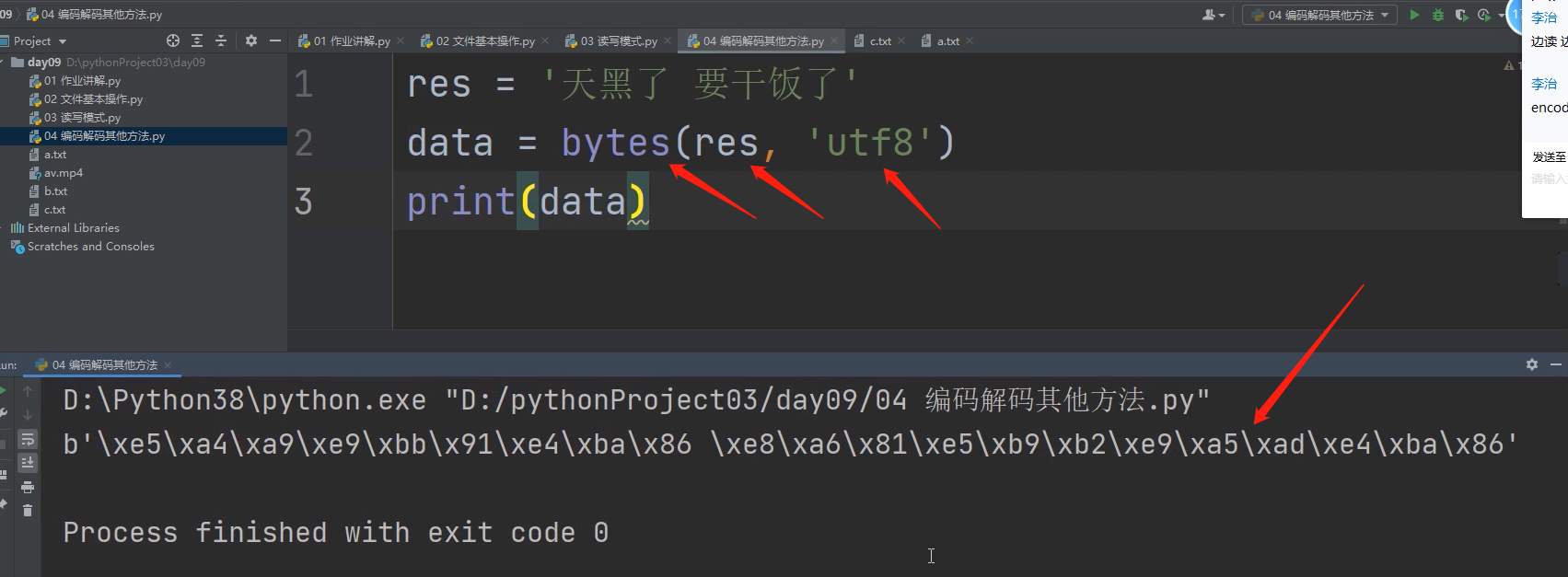
将二进制数据转化为中文也有另一种方法如下:
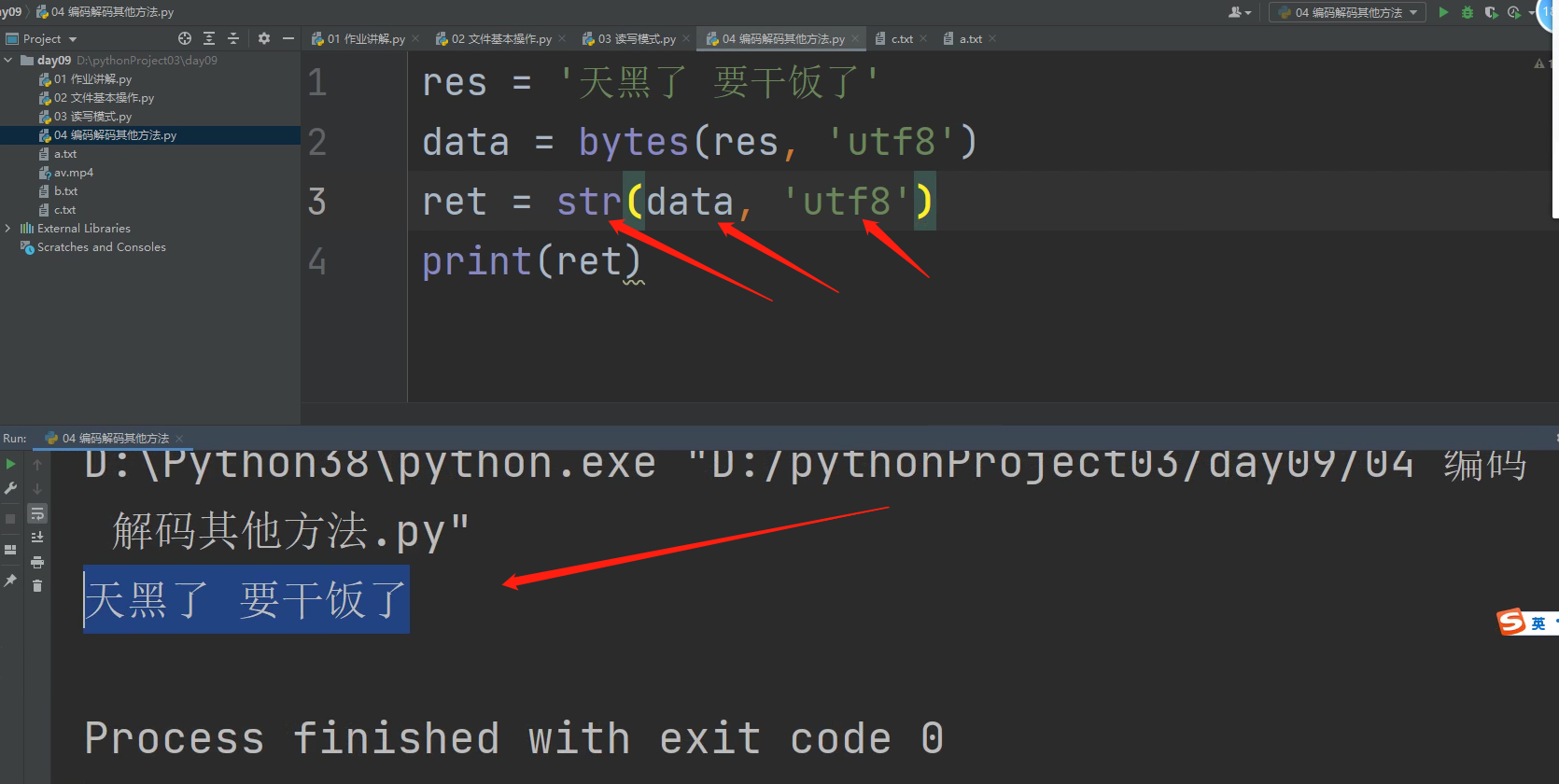
.
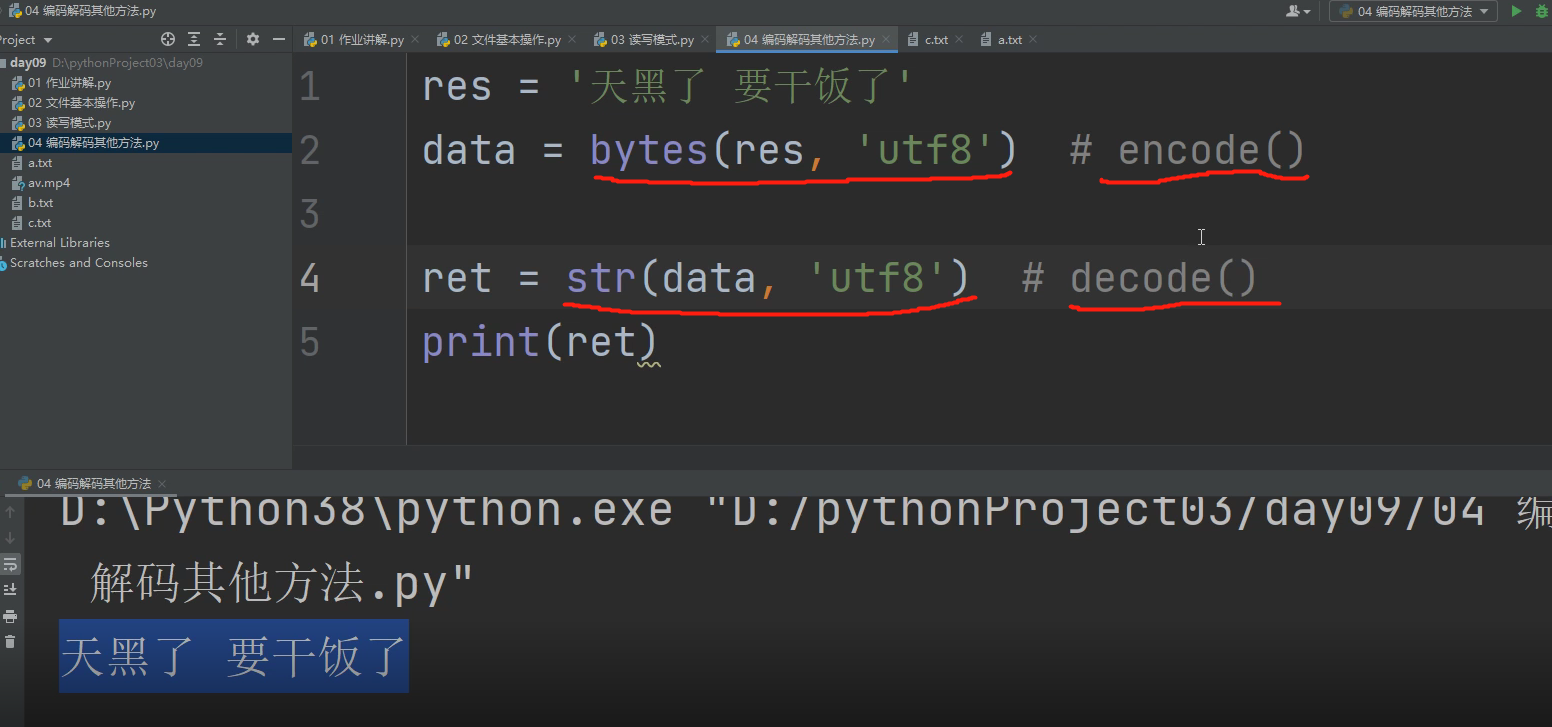
.
.
.
.
.
.
文件诸多方法
r系列:
记住read相关的读取操作都和光标的位置有关,
都是从左往右读的,读完了光标就停在了你读的数据的最后面。
readline方法也是一样,每次只读一行,读完光标已经在第一行的末尾了,
再读只能读从第二行开始读一行了,依次类推。
---------------------------------------
.
.
1 .read()
# 1 .read() 读的方法有光标的概念
# .read()方法括号里面什么都不写,默认一次性读取文件全部内容,并且光标从开头跳到末尾,
# 并且停留在文件末尾!!!
光标已经在末尾后,继续读取则读不出内容!!!
当然如果程序重新运行光标还是从开头开始一直读到最后!!!
------------------------------------------------------------------------
.read() 括号内还可以填写数字!!!
在文本模式下 数字是几,则表示读取几个字符,
如果是在二进制模式下,数字是几就代表读取几个字节数!!!
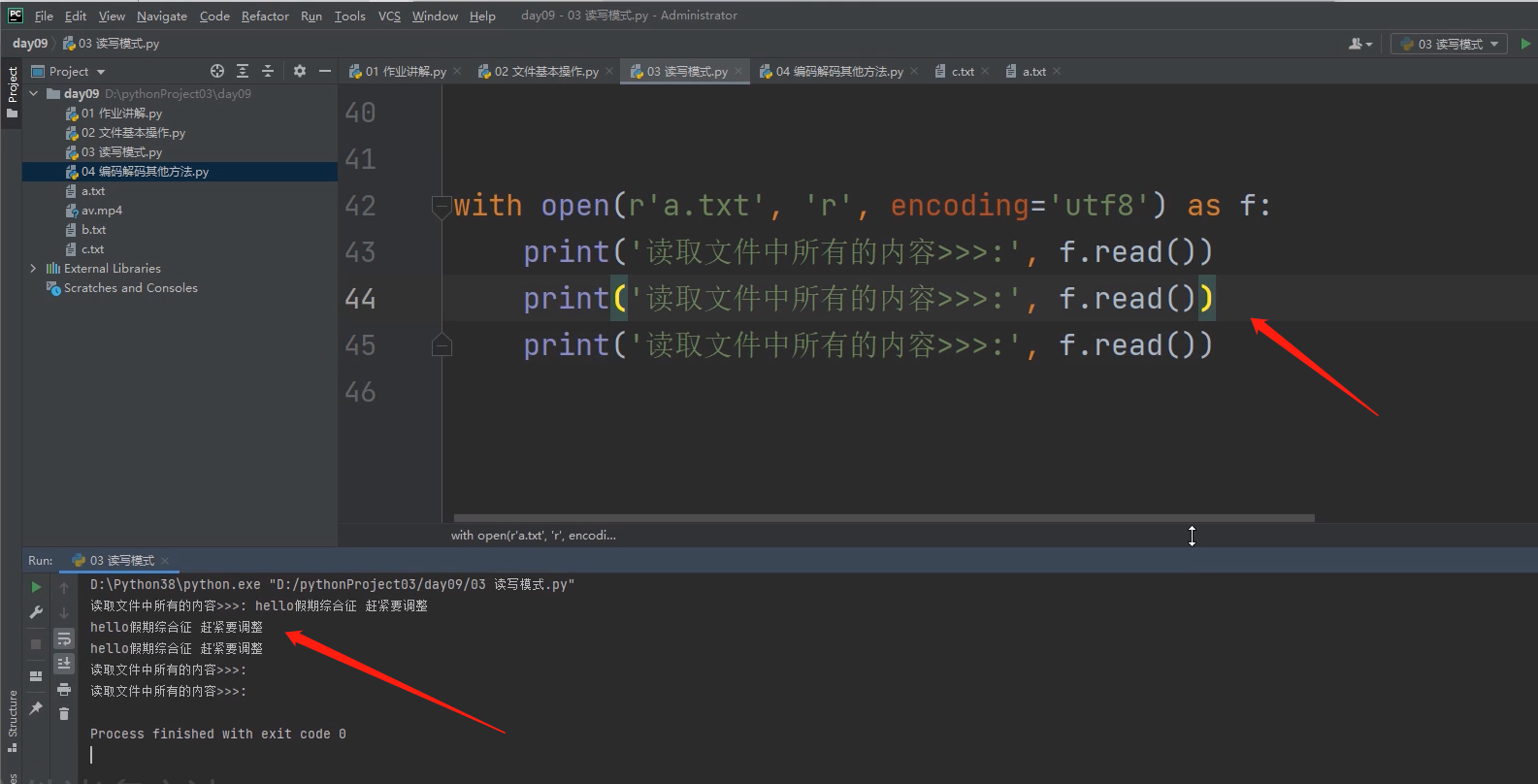
.
.
.
.
2 for循环读取 重要!!!
当文件内容较多的时候,可以通过for循环一行一行的读取。
一行行读取文件内容 避免内存溢出现象的产生
with open()打开文件后,
for i in f: # 这个时候的for循环就已经包含了.read读的方法了,每循环一次读一行
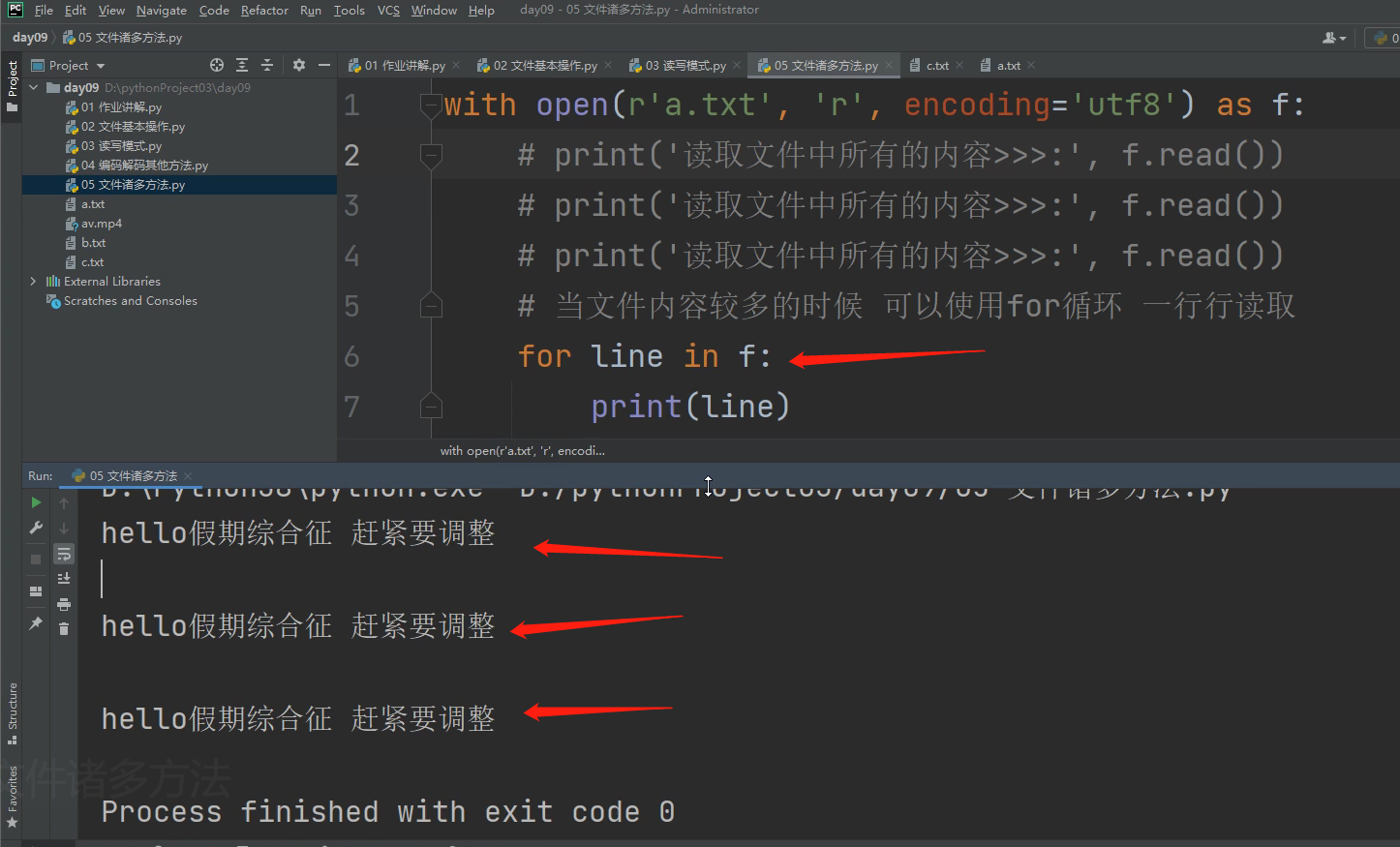
.
.
.
.
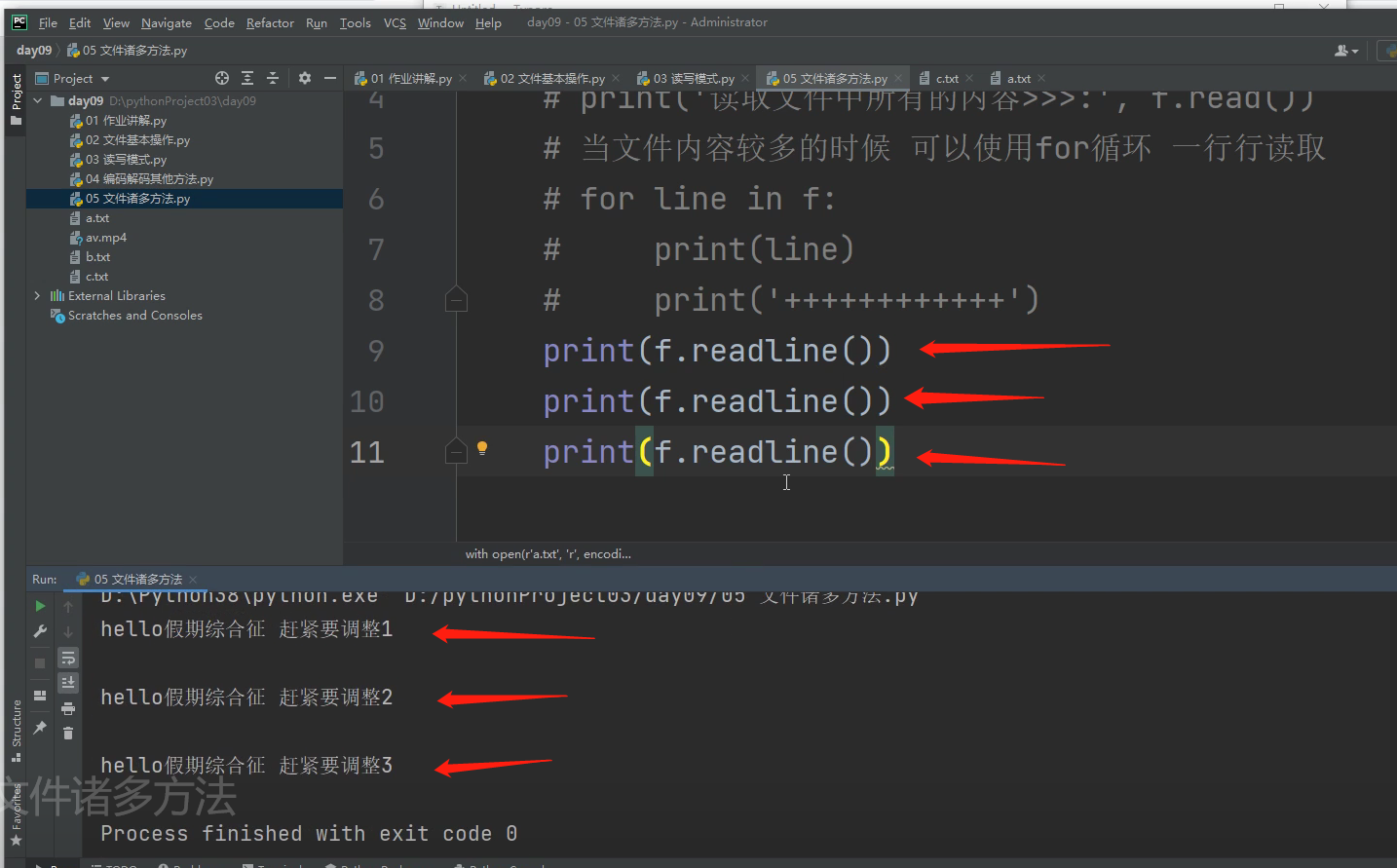
3 .readline()
一次只读一行内容
这里是这样的,a.txt文件里面有3行文字,每行文字的末尾加了一个数字区分的。连续读3此结果如下:
.
.
.
.
4 .readlines() 了解该方法就行了
一次性读取文件的所有内容,会按照行数,将数据值组织成一个列表,列表的每一个数据值就是文件的每行内容
.
.
.
.
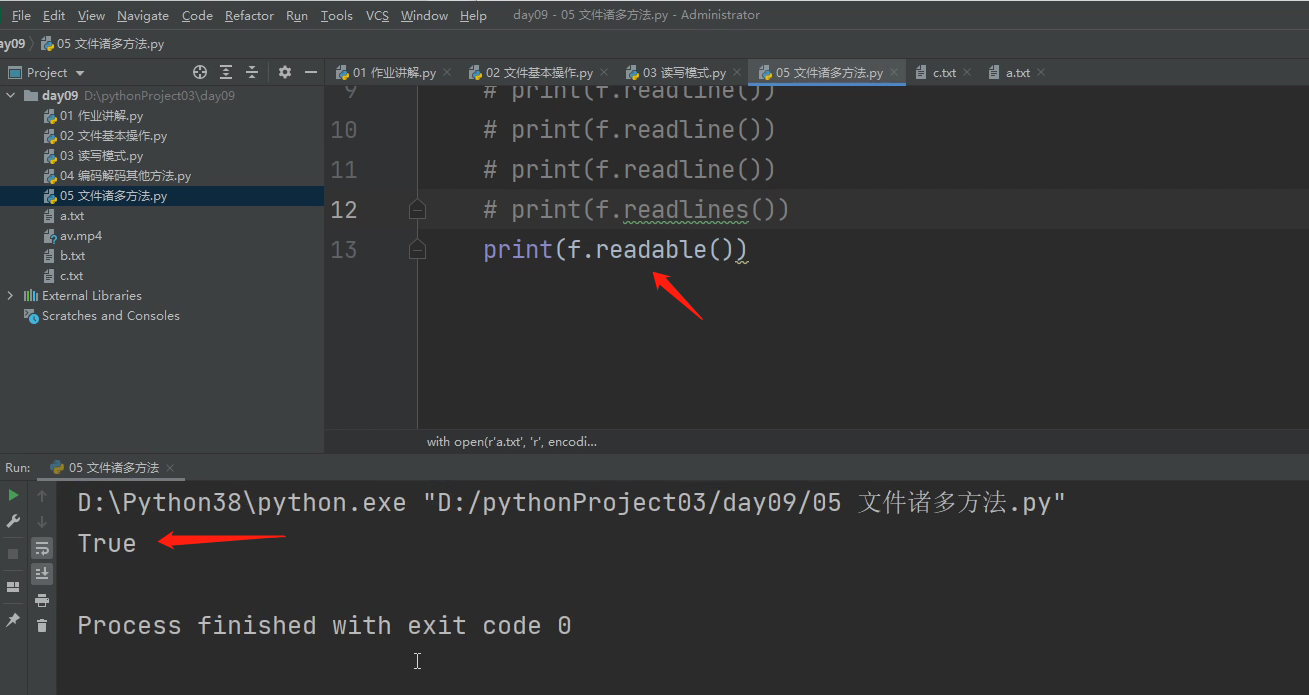
5 .readable()
判断文件是否具备读数据的能力,并输出一个布尔值。如果文件的打开模式是只写模式'W'那么就会输出个False 出来
.
.
.
.
W系列
6 .write() # 写入数据
.
.
7 .writeable()
判断文件是否具备写数据的能力
.
.
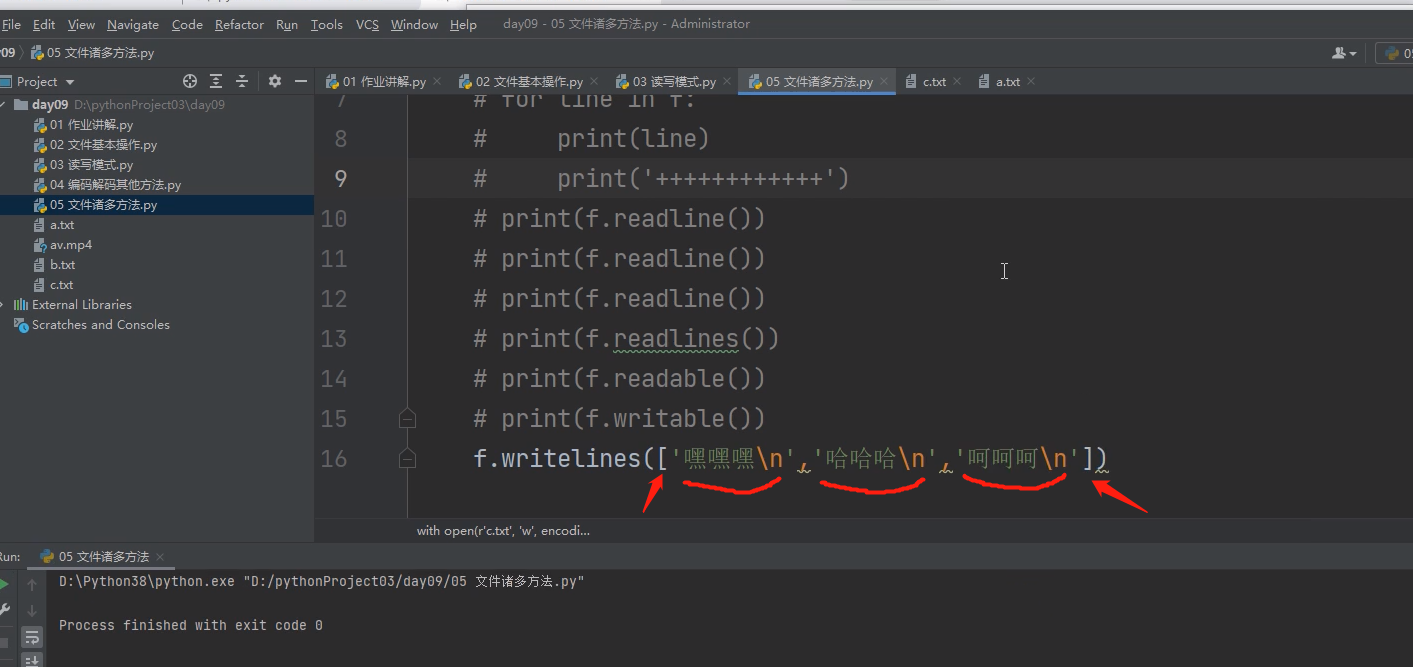
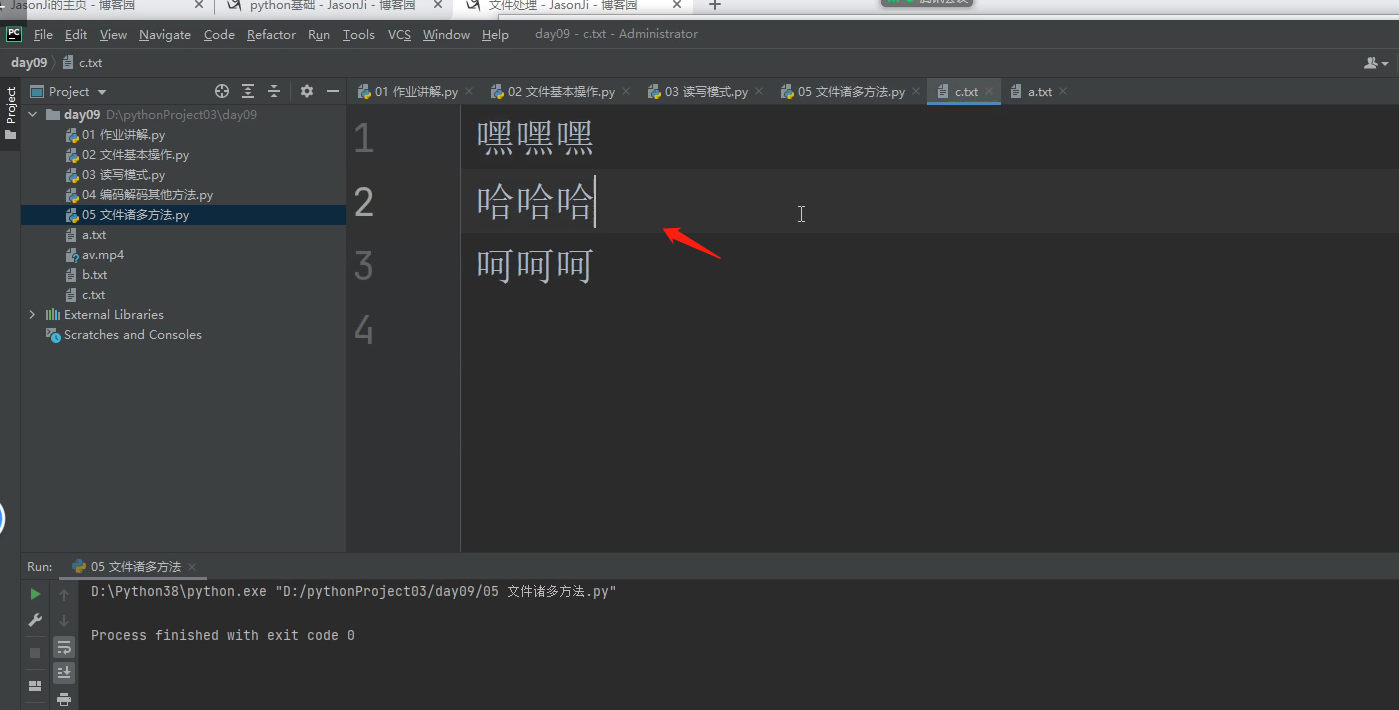
8 .writelines()
可以直接在括号里面写一个列表 一次性将列表中所有的数据值写入
9 .flush()
将内存中文件数据立刻刷到硬盘 等价于ctrl + s 强制保存
.
.
.
.
.
文件内光标的移动 了解
一个中文是3个字节,一个英文字母或数字是一个字节
在二进制模式下.read()括号里面的数字代表要读的字节数
在文本模式下.read()括号里面的数字代表要读的字符数 注意两者的区别!!
.
.
.
.
总结:
.tell() 方法的作用是:获得当前光标距离文件开头产生的字节数
.seek()方法是控制光标用的
.seek(offset, whence)
offset是向右的位移量,无论什么模式下打开,光标只能以字节为单位移动,不能以字符为单位移动!!!
whence是模式 0 1 2
0是基于文件开头, 文本和二进制模式都可以使用
1是基于当前位置, 只有二进制模式可以使用,在文本模式打开seek括号里面模式写1,程序会直接报错
2是基于文件末尾, 只有二进制模式可以使用,在文本模式打开seek括号里面模式写2,程序会直接报错
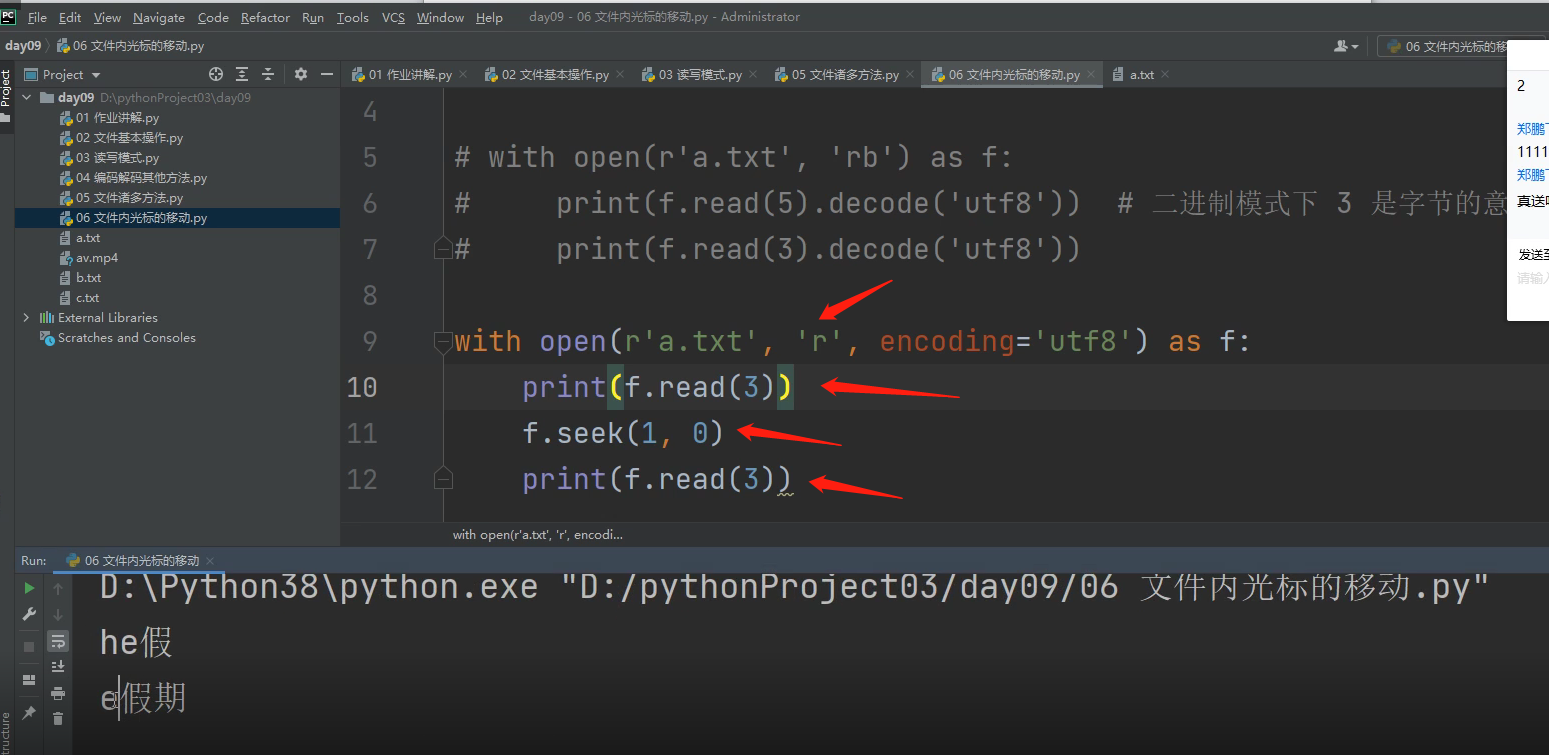
在文本只读模式下打开,再用.read(3)读取,光标直接从数据开头读3个字符,结果就是he假
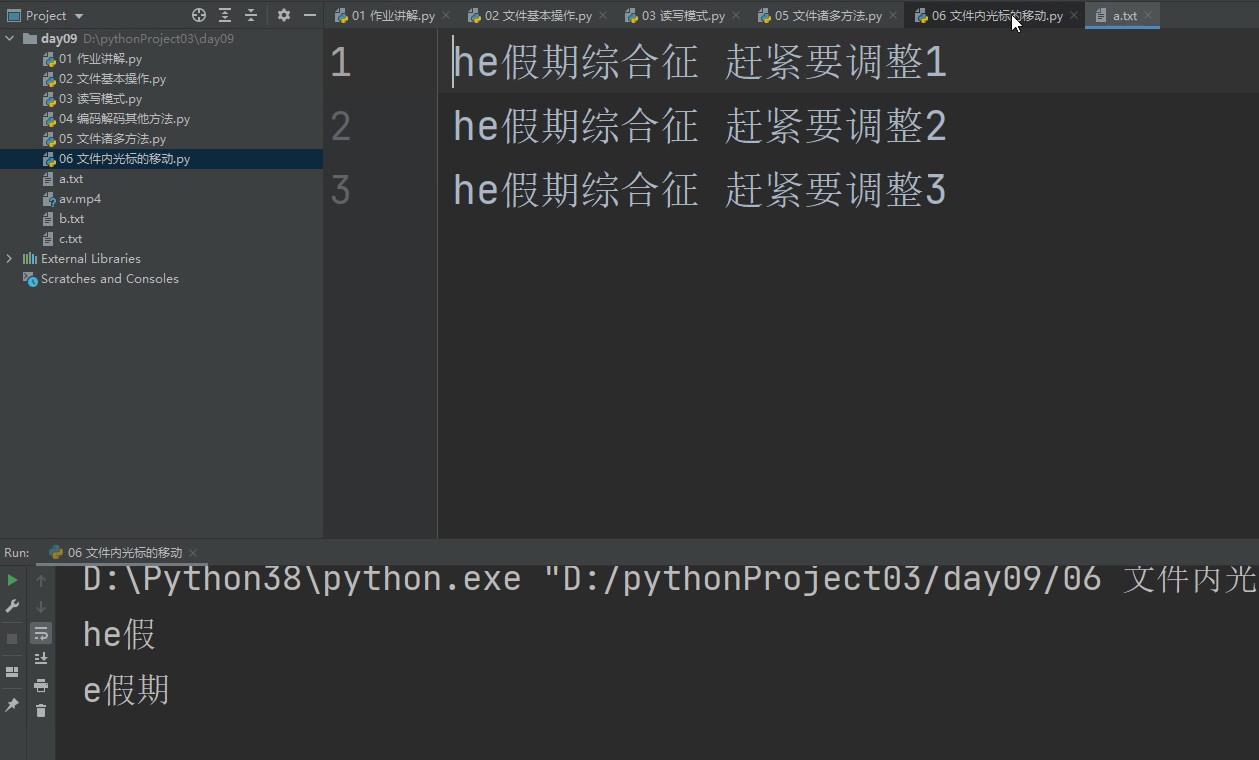
.seek(1, 0) 0模式下光标回到开头,然后向右移动一个字节,后.read(3)光标开始读3个字符,结果就是 e假期
.
.
.
.
当想用.read()方法i重复读取文件里面的数据时,
可以在.read()代码的下一行,写一行.seek(0,0)代码就可以将光标又返回到文件开头了。
.
.
.
.
.
.
作业
1.编写简易版本的拷贝工具
自己输入想要拷贝的数据路径 自己输入拷贝到哪个地方的目标路径
任何类型数据皆可拷贝
ps:个别电脑C盘文件由于权限问题可能无法拷贝 换其他盘尝试即可
2.利用文件充当数据库编写用户登录、注册功能
文件名称:userinfo.txt
基础要求:
用户注册功能>>>:文件内添加用户数据(用户名、密码等)
用户登录功能>>>:读取文件内用户数据做校验
ps:上述功能只需要实现一次就算过关(单用户) 文件内始终就一个用户信息
拔高要求:
用户可以连续注册
用户可以多账号切换登录(多用户) 文件内有多个用户信息
ps:思考多用户数据情况下如何组织文件内数据结构较为简单
提示:本质其实就是昨天作业的第二道题 只不过数据库由数据类型变成文件
.
.
.
.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY