python第八课--用户登录系统代码详解,字典元组集合相关操作及字符编码理论
昨日内容回顾
-
作业讲解
1.前期不熟练的情况下一定要先写注释 2.一定要仔细思考每一行代码的含义 3.自己不会的代码或者不熟练的代码一定要多敲多练 -
数据类型内置方法简介
所有的数据类型基本上都自带了一些操作以及通过点的方式调用自带的方法 注意数据类型的转化时,用的方法 int float str 等转换时,不需要再这些英文前加.点号 -
整型相关操作
类型转换 int() 十进制转其他进制 bin() oct() hex() 其他进制转十进制 int() -
浮点型相关操作
类型转换 float() python对数字不敏感 -
字符串相关操作
类型转换 str() 字符串必须要掌握的操作 1.索引取值 s1[0] 2.切片操作 s1[1:5] 3.间隔、方向、步长 s1[1:5:2] 4.统计字符串中字符的个数 len() 5.移除字符串首尾指定的字符 .strip() .lstrip() .rstrip() 6.按照指定的字符切割字符串 切割出来的每个小字符串共同组成一个列表。 从左往右切.split() 从右往左切.rsplit()
括号里面还可以放入最大切割数 例如 s1.split('|', maxsplit=1)
7.字符串格式化输出 比如将aa与bb替换到模板里面取
第一种 'xx{}xx{}xx'.format(aa, bb) 常用与%s的用法类似
第二种 'xx{0}xx{1}xx{1}xx'.format(aa, bb) 常用
第三种 'xx{name1}xx{age1}xx'.format(name1 = aa, age1 = bb) 传参,不常用。
第四种 f'xxx {name} xxx {age}' 最常用,但是必须提前把想插入的字符或输入的字符用变量名绑定一下!!!后才能把变量名往花括号里面一放。
* 字符串必须要了解的操作
```python
1.大小转换与判断
大小转换 .upper() .lower() 大小判断 .isupper() .islower()
2.判断字符串中是否是纯数字 .isdigit()
3.判断字符串的开头或者结尾 .startswith('123') .endswith('12')
4.统计字符串中字符出现的次数 .count() .count('12')
5.替换字符串中指定的字符!!! .replace(,) .replace('jason', 'tony')
6.字符串拼接!!!
.join() '|'.join(['aa', 'aa', '123'])
或者 + ss1 + '$$$' + ss2
7.索引相关操作找到字符在字符串里面第一个找到的一样的值的索引值 .index() .find()
8.补充操作
.title() 将整个字符串中所有单词的首字母大写
.swapcase() 将整个字符串的所有字母大小写翻转
.capitalize() 将整个字符串的第一个字母大写
- 列表相关操作
其他类型转换为列表 list() 例如 list('hello')
必须要掌握的操作!!!!!!
1.索引取值 l1[0]
2.切片操作 l1[0:5]
3.间隔、方向、步长 l1[-1:-3:-1]
4.统计列表中数据值的个数 len() len(l1)
5.索引修改列表数据值!!!!!!
比如 l1[0] = 新值 就把原列表里面索引0对应的数据值改为新值了。 注意与字符串的修改操作的区别,字符串 修改字符用的.replace(老值,新值)
6.列表添加数据值!!!!!!
列表.append(数据值) 在列表的最后添加数据值 l1.append('干饭')
列表.insert(索引值,数据值) 在列表的对应索引值处添加数据值,原数据不改变,相应的往后整体移一格。 l1.insert(0, 'jason')
列表1.extend(列表2) 扩展列表或者叫合并列表(for循环+append) l1.extend(l2)
列表1+列表2 扩展列表或者叫合并列表 l1 + l2
7.列表删除数据值!!!!!!
del l1[0] 按索引取值删除 实际上解除数据值与索引值的关系
l1.remove(数据值) 按数据值删除 l1.remove(444)
11.pop(0) 按索引取值将数据值从列表中跳出 l1.pop(3)
8.排序
.sort() l1.sort() 列表里面数据从小到大排序
.sort(reverse=True) l1.sort(reverse=True) 列表里面数据从大到小排序
9.翻转.reverse() l1.reverse() 将列表里面的数据从头到尾顺序颠倒一下。
ss = [54, 99, 55, 76, 12, 43, 76, 88, 99, 100, 33]
ss.reverse()
print(ss)
[33, 100, 99, 88, 76, 43, 12, 76, 55, 99, 54]
10.统计列表中数据值出现的次数 .count() l1.count(111)
* 可变与不可变类型
```python
可变类型 列表 元组
值改变 内存地址不变
不可变类型 字符串
值改变 内存地址肯定变
今日内容概要
- 作业讲解
- 字典相关操作
- 元组相关操作
- 集合相关操作
- 字符编码(理论)
今日内容详细
作业讲解
1. 基于字符串充当数据库完成用户登录(基础练习)
data_source = 'jason|123' 只有一个用户数据的情况下
将上述数据拆分,获取用户用户名和密码 ,并校验用户信息是否正确
代码实现:
data_source = 'jason|123' # 定义用户真实数据
username = input('username>>>:').strip()
password = input('password>>>>:').strip() # 1.获取用户名和密码
real_name, real_pwd = data_source.split('|') # 2.切割字符串 获取真实用户名和密码
if username == real_name and password == real_pwd: # 3.校验用户名和密码是否正确
print('登录成功')
else:
print('用户名或密码错误')
2. 基于列表充当数据库完成用户登录(拔高练习) 多个用户数据的情况下
data_source = ['jason|123', 'kevin|321','oscar|222']
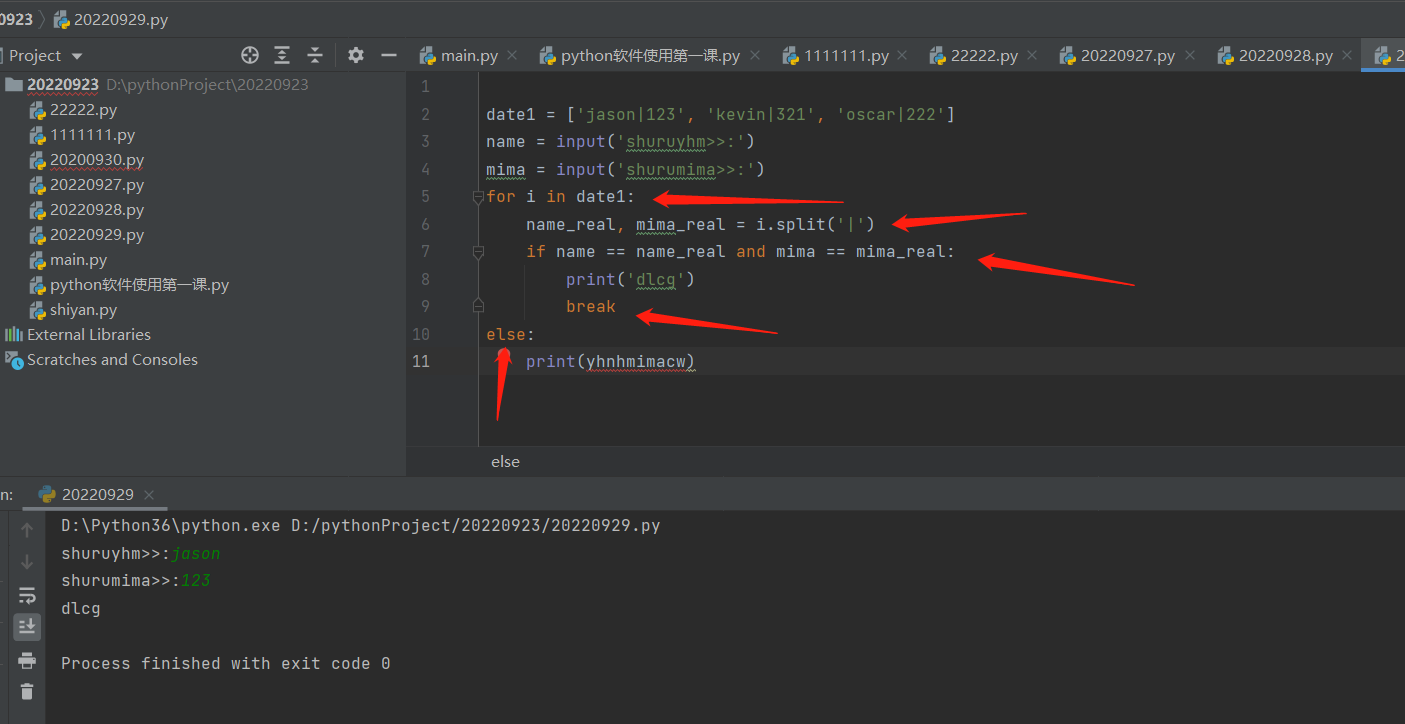
第一种方法:将输入的用户名与密码,与利用for循环与切割的知识的到数据一个一个的比对最终得出用户名与密码是否正确。
data_source = ['jason|123', 'kevin|321', 'oscar|222']
username = input('username>>>:').strip()
password = input('password>>>>:').strip() # 1.先获取用户输入的用户名和密码
for data in data_source: # 2.循环获取列表中每一个数据'jason|123' 'kevin|321' 'oscar|222'
real_name, real_pwd = data.split('|') # 3.将循环获取的每一个数据用split方法劈开形成一个一个的列表['jason', '123']
if username == real_name and password == real_pwd: # 4.校验用户名和密码是否正确
print('登录成功')
break # 若登录成功,此处跳出整个for循环。
else: # 注意此处的else一定不要和if处在同一个缩进位上
print('用户名或密码错误')
为什么else不能与if在同一个缩进位上?一旦在同一缩进位上就会出现,当不满足if的条件时,程序就和执行else的子代码,但是for循环又是一个一个的遍历取值,假设用户输入的用户是oscar 密码是222,那么for循环取出列表里面的第一个数据值'jason|123'并进行切割后形成的列表解压赋值给real_name, real_pwd,然后进行一个判断(用户名和密码是否正确),如果else与if在同一个缩进位,此时的程序就学会先打印两次(用户名或密码错误),然后当for循环取值到第三个数据值时,经过切割、解压赋值、判断用户名和密码一致后,猜打印登录成功。显然程序是有问题的。
所以else不是与if平行的,而是与for平行的。根据for else 连用的用法,只有在没有被break强制结束的情况下,for循环运行完毕之后,才运行else的子代码,否则不运行else的子代码。所以else与for平行后,就不会出现输入的是oscar与222,出现两次用户名或密码错误,最后再出现登录成功的现象了。此时else的子代码的作用是,当for循环将列表里面的字符串一个一个的取出来,再劈开形成小列表,再解压赋值给real_name, real_pwd,最后再比较与输入的用户名与密码是否一致。当发现每一个字符串劈开解压后与用户输入的结果都不一致的时候,此时for循环已经结束了,说明用户名与密码肯定有一个错了。此时执行else的子代码完全合理了。
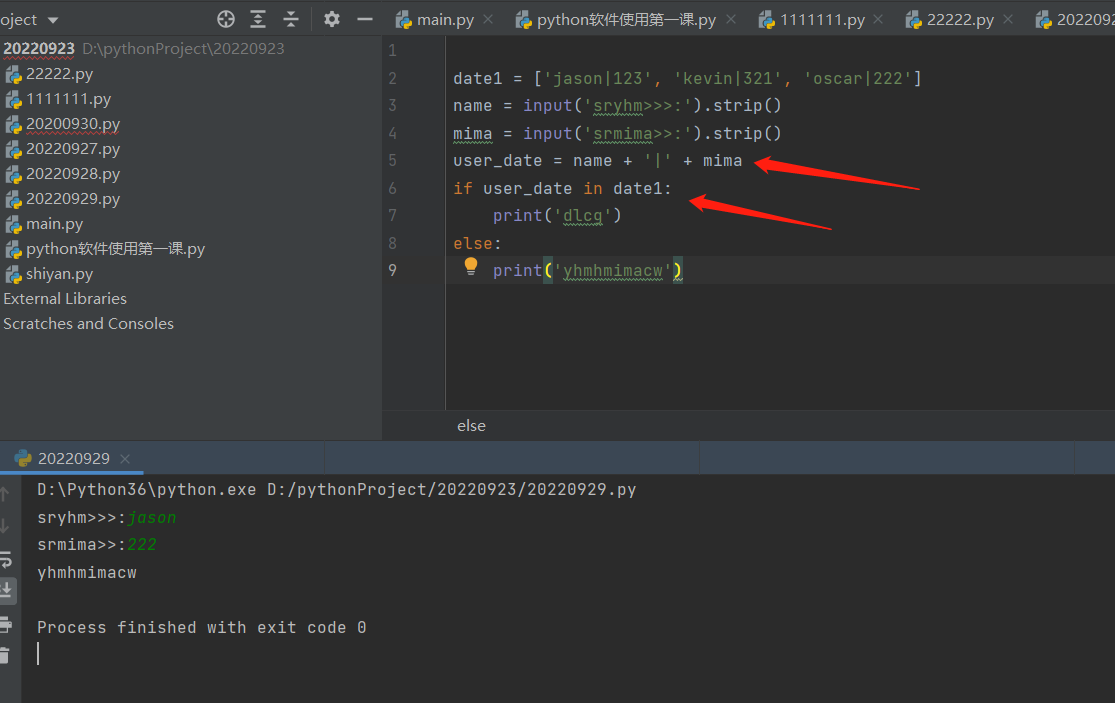
第二种方法:利用将用户输入的用户名与密码的拼接为一个字符串,再利用成员运算判断拼接的字符串是否在给的列表里,从而判断出用户输入的用户名与密码是否正确。
data_source = ['jason|123', 'kevin|321', 'oscar|222']
username = input('username>>>:').strip()
password = input('password>>>:').strip()
user_data = f'{username}|{password}' #此处用不用格式化输出都行,最简单就这样 username + '|' + password
if user_data in data_source:
print('登录成功')
else:
print('用户名或密码错误')
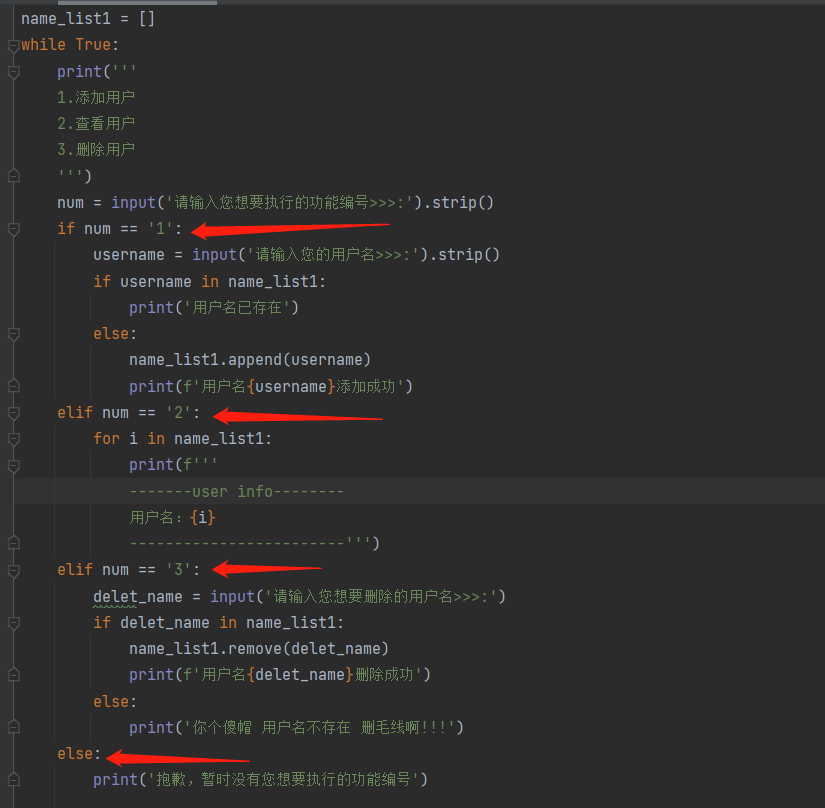
3.利用列表编写一个员工姓名管理系统 这个代码重要要多看!!!
输入1,执行添加用户名功能
输入2,执行查看所有用户名功能
输入3,执行删除指定用户名功能
分析:
首先:考虑如何在输入1、2、3后,代码能执行不同的功能,肯定要有if的3分支结构实现输入不同数字执行不同子代码的功能。
其次:思考如何让程序循环起来,因为这种添加用户名,查看用户名,删除用户名的功能不可能就运行一次就结束的。
所以程序的整体结构应该是 大的while循环里面嵌套了if的分支结构
考点有:
1、定义一个空列表
2、往列表里面添加数据、删除数据要用到.append() .remove()
3、查看列表里面的数据肯定要用到print(),当要查看多个数据时,最好的方法就是for循环遍历出列表里面一个一个的数据再放到固定的字符串里面格式化输出打印出来。
代码实现:
data_list = [] # 1.先定义一个专门存储用户名的列表
while True: # 2.添加循环结构
print(""" # 注意: 利用三引号可以实现输出多行文本,用单引号实现不了换行
1.添加用户
2.查看用户
3.删除用户
""") # 3.先打印项目功能 供用户选择
choice_num = input('请输入您想要执行的功能编号>>>:').strip() # 4.获取用户想要执行的功能编号
if choice_num == '1': # 5.根据不同的功能编号执行不同的分支代码
username = input('请输入您的用户名>>>:').strip() # 6.获取用户输入的用户名
if username in data_list: # 7.判断当前用户名是否已存在
print('用户名已存在')
else:
data_list.append(username) # 8.列表添加用户名
print(f'用户名{username}添加成功')
elif choice_num == '2':
for name in data_list: # 9.for循环打印每一个用户数据 这步很重要!!for循环的子代码里面是一个格式化输出的字符串,这样就可以达到将列表里面的每一个数据都放到一个固定的字符串里面取进行一个格式化输出!!!
print(
f"""
------------user info---------
用户名:{name}
------------------------------
""")
elif choice_num == '3':
delete_username = input('请输入您想要删除的用户名>>>:').strip() # 10.获取用户想要删除的用户名
if delete_username in data_list: # 11.先判断用户名是否存在
data_list.remove(delete_username)
print(f'用户名{delete_username}删除成功')
else:
print('你个傻帽 用户名不存在 删毛线啊!!!')
else:
print('很抱歉 暂时没有您想要执行的功能编号')
.
.
.
.
.
.
.
.
.
字典相关操作
1.其他数据类型转字典
dict(其他数据类型)
通常情况下,字典的转换一般不使用关键字 而是自己动手转
.
.
.
.
2.字典必须要掌握的操作
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
2.1. 按k取值(不推荐使用)
print(user_dict['username']) # jason
print(user_dict['phone']) # k不存在,代码会直接报错
2.2. 按内置方法.get() 取值(推荐在字典取值时使用!!!)
print(user_dict.get('username')) # jason
print(user_dict.get('age')) # 如果键不存在会报None,不会报错。
None
print(user_dict.get('username', '没有哟 嘿嘿嘿')) # 键存在的情况下获取对应的值,不会管逗号后面的数据。
jason
print(user_dict.get('phone', '没有哟 嘿嘿嘿')) # 键不存在默认返回None 可以通过第二个参数自定义返回的结果。
没有哟 嘿嘿嘿
.
.
.
.
3. 修改字典的值数据 字典也是可变数据类型 重要!!!
user_dict = {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']}
print(id(user_dict))
2928401732160
user_dict['username'] = 'tony'
print(id(user_dict))
2928401732160 # 可见字典也是可变数据类型,值改变内存地址并没有变。
print(user_dict)
user_dict = {
'username': 'tony', # 键存在则修改对应的值
'password': 123,
'hobby': ['read', 'music', 'run']
}
.
.
.
.
4. 字典新增键值对
与修改字典值的语法一致
user_dict['age'] = 18 # 键不存在,则在字典末尾新增一组键值对
print(user_dict)
.
.
.
.
5.删除数据
del user_dict['username']
print(user_dict) # 只需要给一个键就可以将 这一组键值对都删除了
res = user_dict.pop('password')
print(user_dict) # 还是一样只要给一个键,就可以将 这一组键值对都都弹出字典了,只是没有直接删除掉,而是先保留了不像del直接删除了。
print(res) # 所以这个地方跳出的是123
123
.
.
.
.
6.统计字典中键值对的个数
print(len(user_dict))
3
.
.
.
.
.
7. 字典三剑客 这3个对字典处理过后的数据都是在列表里面!!!
所以支持对被三剑客处理后的数据进行for循环,取出列表里面的每一个值
.keys() 取字典里面的键
.values() 取字典里面的值
.items() 取字典里面的键值对数据
user_dict = {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']}
print(user_dict.keys()) # 一次性获取字典所有的键
dict_keys(['username', 'password', 'hobby'])
print(user_dict.values()) # 一次性获取字典所有的值
dict_values(['jason', 123, ['read', 'music', 'run']])
for i in user_dict.values():
print(i)
'jason'
123
['read', 'music', 'run']
print(user_dict.items()) # 一次性获取字典的键值对数据
dict_items([('username', 'jason'), ('password', 123), ('hobby', ['read', 'music', 'run'])])
这个比较特殊,每一组键值对最后都会变成一个小元组,都放在列表里面。
8.字典常见操作
user_dict = {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']}
for i in user_dict.items(): # 先通过for循环遍历出每一个键值对,再把每一个键值对变成一个一个的元组。
print(i)
k, v = i # 再把i解压赋值给变量名K与V 也就是把每一个小元组解压赋值给变量k与V
print(k, v)
('username', 'jason') # 先通过for循环遍历出每一个键值对,并打印
username jason # 每一个键值对再解压赋值给变量名K与V,并打印
('password', 123)
password 123
('hobby', ['read', 'music', 'run'])
hobby ['read', 'music', 'run']
.
.
.
.
.
9. 补充说明
- .fromkeys([],[]) 快速生成值相同的字典 用法注意!!!
- .setdefault()
print(dict.fromkeys(['name', 'pwd', 'hobby'], [123]) # 快速生成值相同的字典,当然中括号里面也可以不写数字也可以生成值为空列表的字典
{'name': 123, 'pwd': 123, 'hobby': 123}
面试题:
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
print(res)
注意这个时候如果想把信息添加到对应的空列表里面去,不能如下操作!!!!!
'''
1. 中括号里面数据是前面所有的键共用的数据值,通过任何一个键修改都会影响所有的键对应的值,所有键对应的都是一个值。
2. 当第二个公共值是可变类型的时候 一定要注意!!! 通过任何一个键修改都会影响所有!!
'''
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
{'name': [], 'pwd': [], 'hobby': []} # 这是第一个print打印的结果哦
{'name': ['jason', 123, 'study'], 'pwd': ['jason', 123, 'study'], 'hobby': ['jason', 123, 'study']} # 这是利用append方法将数据加到空列表后的结果,改一个键对应的值,所有键对应的值都改了。
****.formkeys() 这个地方是个坑,注意!!!
user_dict = {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']}
res = user_dict.setdefault('username','tony')
print(user_dict, res) # 当键存在,值不一样也不修改, 获取的结果还是键对应的值
{'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']} jason
这个用的很少:
res = user_dict.setdefault('age',123)
print(user_dict, res) # 当键不存在,则新增键值对, 获取的结果是新增的值
{'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run'], 'age': 123} 123
res = user_dict.popitem() # 弹出键值对 哪个数据值后进的,就先弹出
print(user_dict)
print(res)
{'username': 'jason', 'password': 123} # 第一个print打印结果
('hobby', ['read', 'music', 'run']) # 第二个print打印结果
.
.
.
.
.
.
元组相关操作
1. 其他数据类型转换成元组 tuple(其他数据类型)
ps:支持for循环的数据类型都可以转成元组
2. 元组必须掌握的方法 与列表的操作一致
t1 = (11, 22, 33, 44, 55, 66)
1.索引取值
2.切片操作
3.间隔、方向
4.统计元组内数据值的个数
print(len(t1)) # 6
5. 统计元组内某个数据值出现的次数
print(t1.count(11))
6. 统计元组内指定数据值的索引值
print(t1.index(22))
7. 注意!!!元组内如果只有一个数据值那么逗号不能少 比如('aaa',) 逗号不写就变成了该单个数据对应的数据类型了。
8. 元组内索引绑定的内存地址不能被修改!!!(注意区分 可变与不可变)
9. 元组不能新增或删除数据!!!
10. 只有在元组所绑定的数据是可变数据类型时,元组里面绑定的数据才能修改,否则也不能改。比如:元组里面如果套了一个列表,那么套的这个列表是可以改的。
.
.
.
.
.
集合相关操作
1. 其他数据类型转换为集合 set(其他数据类型)
集合内数据必须是不可变类型(整型 浮点型 字符串 元组)
集合内数据也是无序的 没有索引的概念
2. 集合需要掌握的方法
去重
关系运算
ps:只有遇到上述两种需求的时候才应该考虑使用集合
3. 去重
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1)
l1 = list(s1)
print(l1)
[33, 11, 22]
注意!!!'''集合的去重无法保留原先数据的排列顺序'''
4. 关系运算 交集& f1-f2 并集| 并集扣掉交集^
群体之间做差异化校验
eg: 两个微信账户之间 有不同的好友 有相同的好友
f1 = {'jason', 'tony', 'jerry', 'oscar'} # 用户1的好友列表
f2 = {'jack', 'jason', 'tom', 'tony'} # 用户2的好友列表
1. 求两个人的共同好友 &
print(f1 & f2)
{'jason', 'tony'}
2. 求用户1独有的好友 -
print(f1 - f2)
{'jerry', 'oscar'}
3. 求两个人所有的好友 |
print(f1 | f2)
{'jason', 'jack', 'tom', 'tony', 'oscar', 'jerry'}
4. 求两个人各自独有的好友 ^
print(f1 ^ f2)
{'oscar', 'tom', 'jack', 'jerry'}
5. 父集 子集
print(f1 > f2) # 判断f1是不是能够包含f2
False
print(f1 < f2) # 判断f1是不是属于f2
False
.
.
.
.
.
字符编码理论
该知识点理论特别多 但是结论很少 代码使用也很短
1. 字符编码只针对文本数据
2. 回忆计算机内部存储数据的本质
3. 既然计算机内部只认识01 为什么我们却可以敲出人类各式各样的字符,肯定存在一个数字跟字符的对应关系 存储该关系的地方称为>>>:字符编码本
4. 字符编码发展史
4.1. 一家独大
计算机是由美国人发明的 为了能够让计算机识别英文
需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符
4.2. 群雄割据
中国人 GBK码:记录了英文、中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人 shift_JIS码:记录了英文、日文与数字的对应关系
韩国人 Euc_kr码:记录了英文、韩文与数字的对应关系
每个国家的计算机使用的都是自己定制的编码本
不同国家的文本数据无法直接交互 会出现"乱码"
4.3. 天下一统
unicode万国码
兼容所有国家语言字符
起步就是两个字节来表示字符
utf系列:utf8 utf16 ...
专门用于优化unocode存储问题
英文还是采用一个字节 中文三个字节!!!!!!
正常都是utf8的
.
.
.
.
字符编码实操
1. 针对乱码不要慌 切换编码慢慢试即可
2. 编码与解码
编码:将人类的字符按照指定的编码编码成计算机能够读懂的数据
字符串.encode() 括号里面写你要指定的编码名称,比如将字符串转为由utf8编码成的二进制数据。括号里面就写'utf8'就可以了。
例如:
info = '节假日快乐'
print(info.encode('utf8'))
b'\xe8\x8a\x82\xe5\x81\x87\xe6\x97\xa5\xe5\xbf\xab\xe4\xb9\x90'
# 这个字符串的前面的字母b,代表的是这串字符的数据类型是bites数据类型。bites数据类型在python中可以直接看成二进制数据类型即可。
# 数据在基于网络传播的时候也只能是二进制的
解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂
bytes类型数据.decode()
info = '节假日快乐'
res = info.encode('utf8')) # 用utf8字符编码表将字符串编码成bites数据类型,模拟网络数据
res1 = res.decode('utf8') # 将bites数据类型用utf8字符编码表解码成,人能看懂的字符串。
print(res1)
节假日快乐
3. python2与python3差异
python2是很早开发的,那个时候还没有unicode,所有默认的字符编码表是ASCII码,所以python2只认识英文,不认识中文。
所以如果针对python2开发软件编写代码要做到:
1. 加一个文件头 必须在代码最上面一行加一个文件头注释 # encoding:utf8
作用是:告诉运行这个文件的人,下面的代码统一给我使用utf8进行解析,而不再使用py2默认的字符编码表进行解析。
2. 在字符串前面加u 比如 u'你好啊'
u的意思是让解释器在针对这种字符串的数据全部采用unicode来翻译
这是python2解释器遗留下来的问题,暂时就只能这样了。
python3默认的编码是utf系列(unicode)
.
.
.
.
.
作业
1.优化员工管理系统
拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写不会没有关系)
2.去重下列列表并保留数据值原来的顺序
eg: [1,2,3,2,1] 去重之后 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]
3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
4.统计列表中每个数据值出现的次数并组织成字典战士
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY