python入门第五课--垃圾回收与流程控制
今日内容概要
- 作业讲解
- 垃圾回收机制
- 流程控制理论(重要)
- 流程控制之分支结构(重要)
- 流程控制之循环结构(重要)
今日内容详细
作业讲解
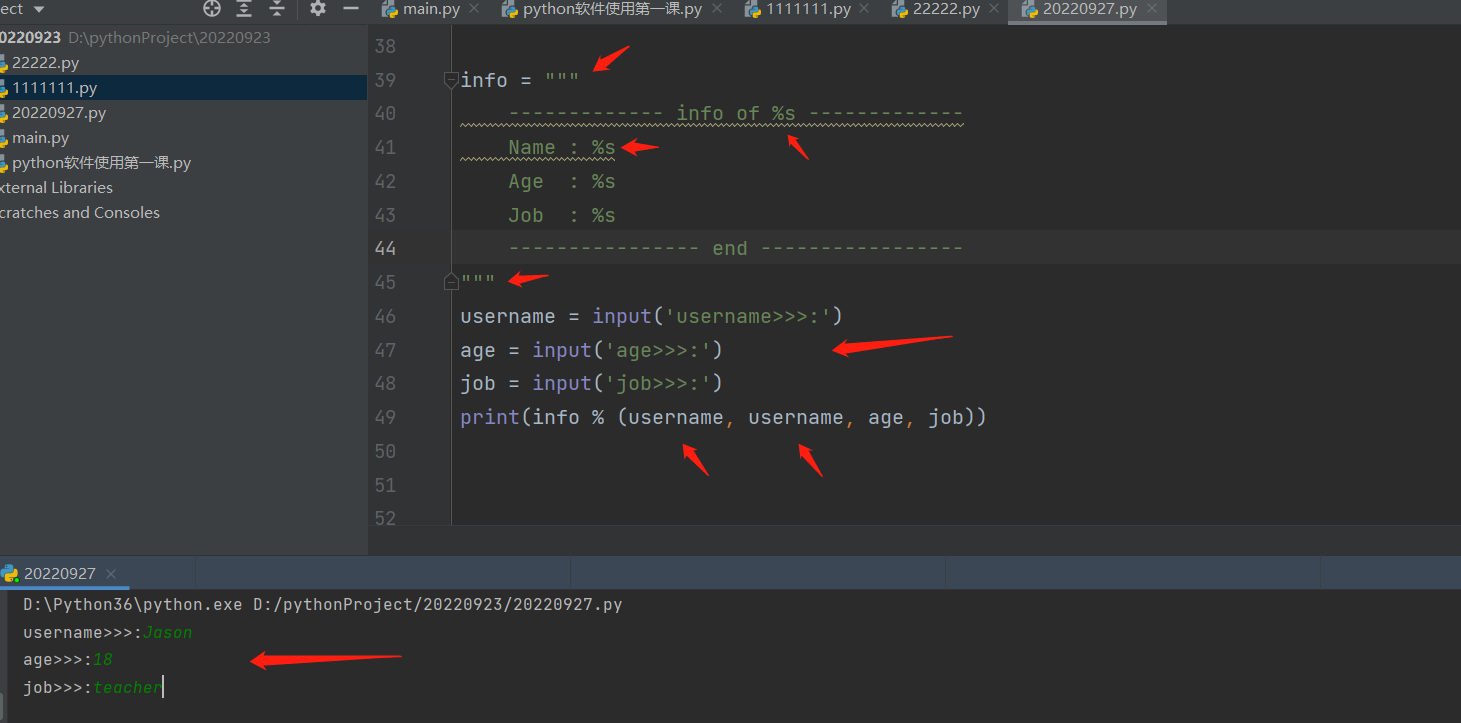
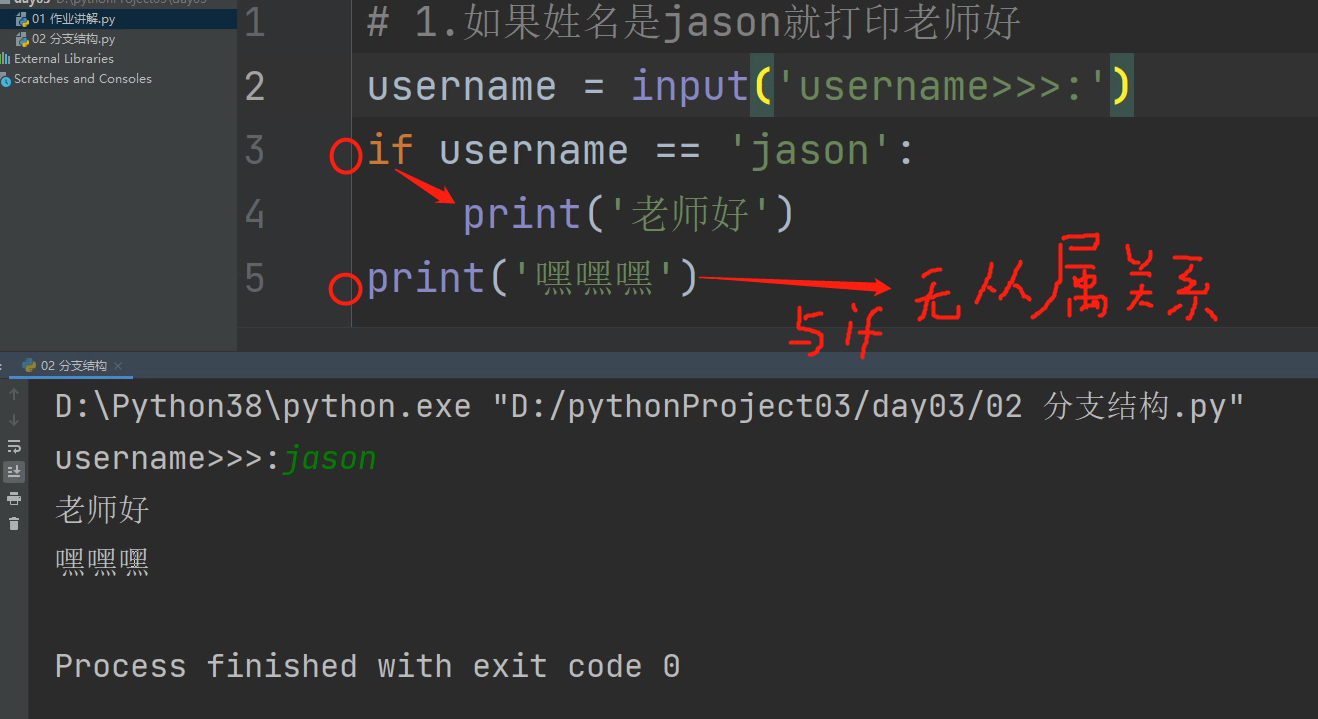
- 获取用户输入并打印成下列格式
------------ info of Jason -----------
Name : Jason
Age : 18
Job : Teacher
---------------- end -----------------
考察内容:考察的是格式化输出,与用户交互知识的结合使用。
解题思路:
- 首先只要有用户输入肯定有 变量名 = input(),只有这样才能通过变量名提取到输入的信息。
- 其次对于固定格式只需要改少量内容的数据,肯定是采用格式化输出较为方便。所以需要建立一个固定内容的字符串模板。具体如下:
.
1. 先制定一个打印的模板(利用格式化输出,建立一个固定内容的字符串模板,然后将需要输入信息的地方改为 %s )
info_demo ="""
------------ info of %s -------------
Name : %s
Age : %s
Job : %s
---------------- end -----------------
"""
2. 将需要输入的数据值,利用input()绑定一个变量名,获取用户输入,
username = input('username>>>:') # ()括号里面可以写一些提示输入的信息
age = input('age>>>:')
job = input('job>>>:')
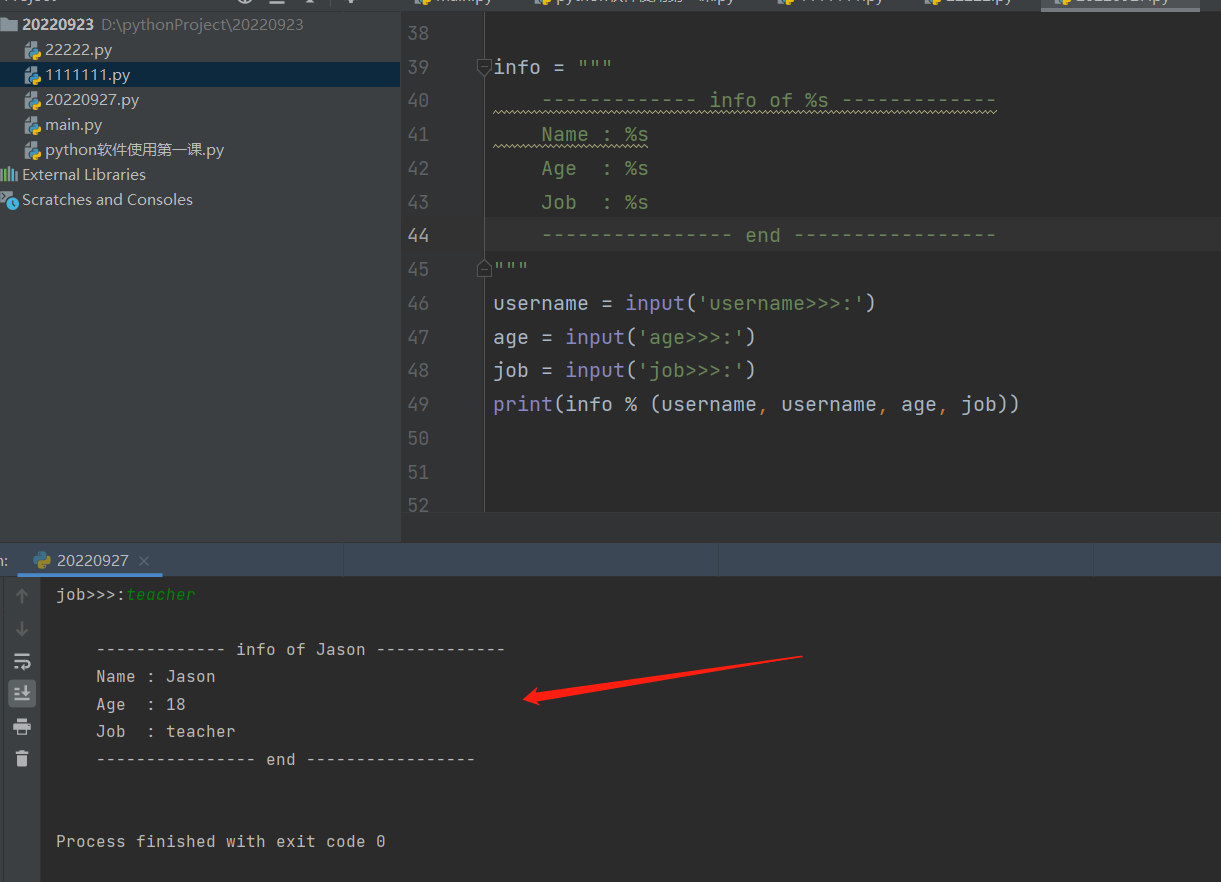
print(info_demo % (username, username, age, job)) # 3.格式化输出
注意:username变量的数据值,在格式化模板里要用两个,所以格式化输出的代码要写两次。按下回车后,依次输入变量名绑定的input所需要输入的数据信息后,按下回车键
.
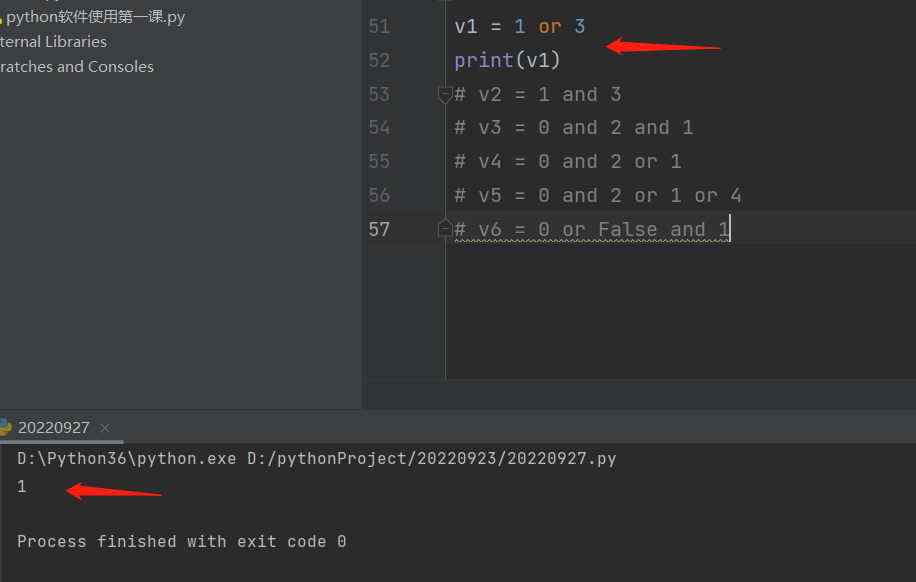
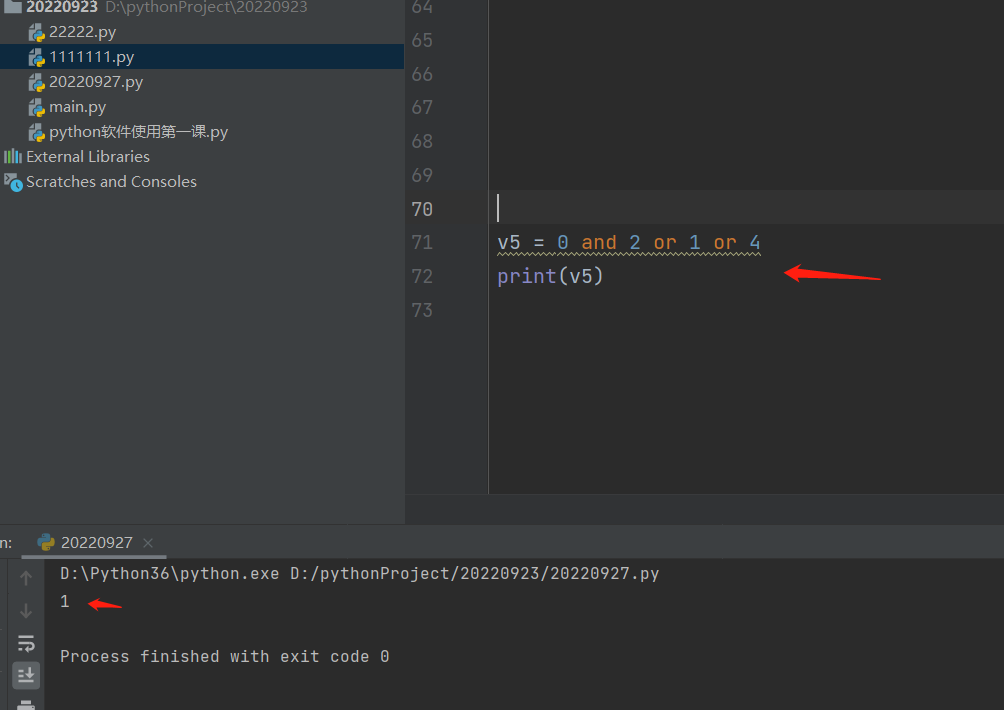
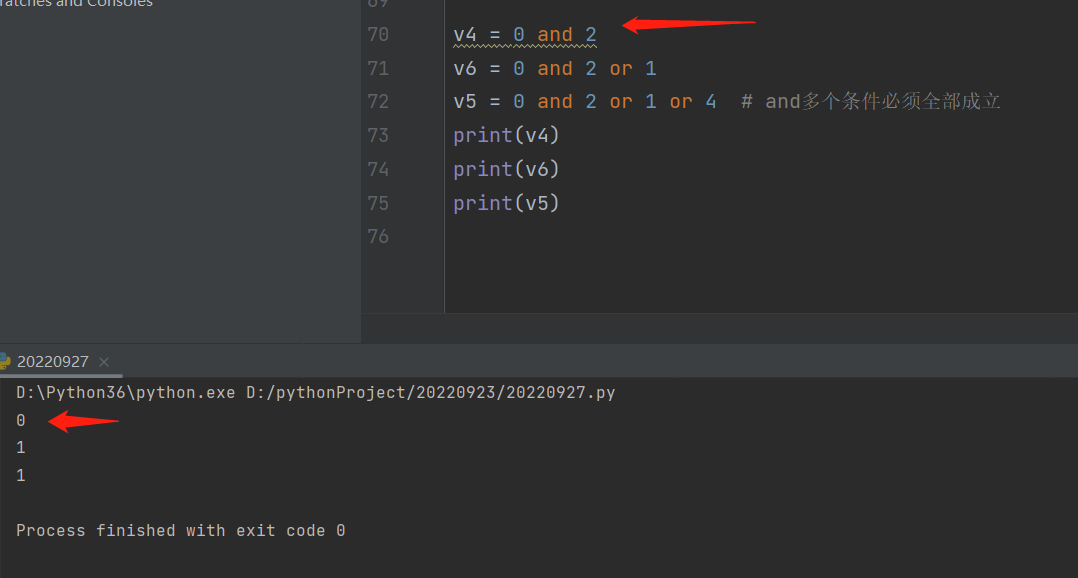
2.准备说出下列变量名v绑定的结果 先算not,再算and,最后算or
注意:0的布尔值虽然是false代表不成立,但是仍然还是输出0。
v1 = 1 or 3
v5 = 0 and 2 or 1 or 4 # 0和2输出0,0or1输出1,1or4输出1
v6 = 0 or False and 1 # False and 1输出false,0orfalse输出false
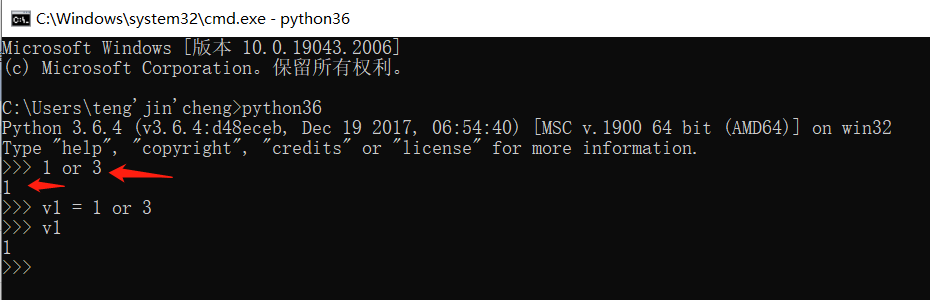
可以用python解释器,或者pycharm软件运算。
python解释器不需要输入print,输入变量名,就会直接读出变量所绑定的结果。或者直接输入一个包含逻辑运算的数据,解释器自动帮你算出,运算后的结果。
.
.
.
.
垃圾回收机制 针对的是数据值,不是变量名
一些编程语言,内存空间的申请和释放都需要程序员自己写代码才可以完成。
但是python却不需要 通过垃圾回收机制自动管理。
python的垃圾回收采用的是 引用计数机制为主加上标记-清除 和 分代回收机制 为辅的结合机制组成的.当对象的引用计数变为0时,对象将被销毁,除了解释器默认创建的对象外。(默认对象的引用计数永远不会变成0)
* 流程:
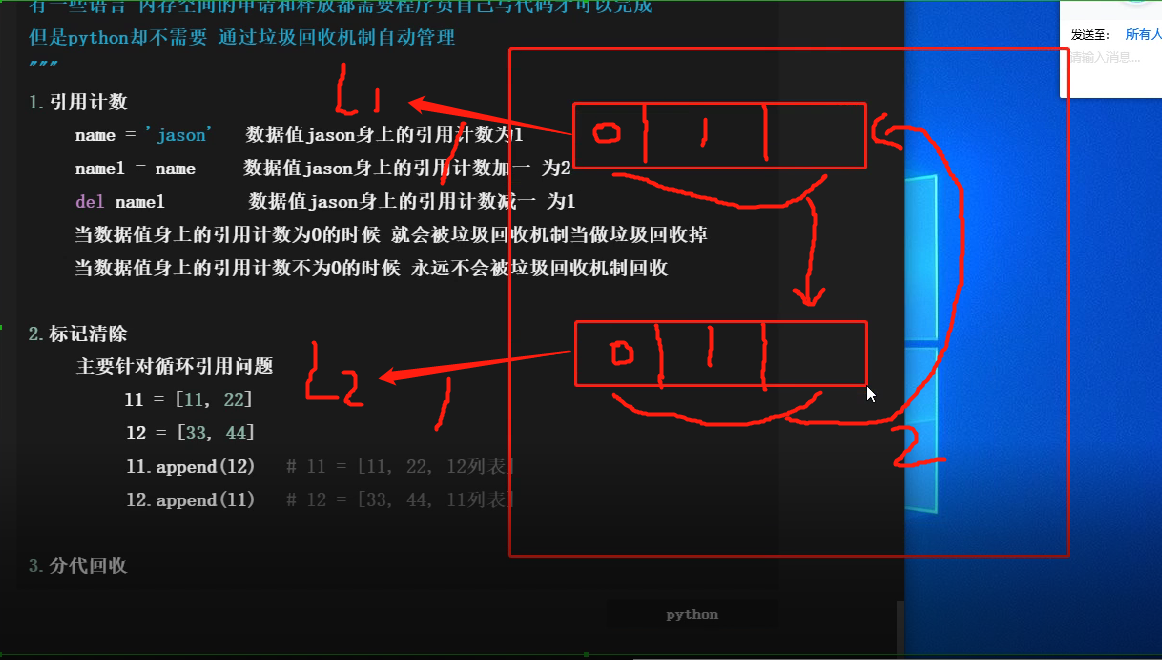
1.1 引用计数
name = 'jason' 数据值jason身上的引用计数为1
name1 = name 数据值jason身上的引用计数加1 为2
del name1 数据值jason身上的引用计数减1 为1
当数据值身上的引用计数为0的时候 就会被垃圾回收机制当做垃圾销毁掉,从而释放空间。
当数据值身上的引用计数不为0的时候 永远不会被垃圾回收机制回收。
1.2. 标记清除
主要针对循环引用问题
l1 = [11, 22] # 引用计数为1
l2 = [33, 44] # 引用计数为1
l1.append(l2) # 这个代码的意思l2的列表作为数据加到l1列表里去。l1 = [11, 22, l2列表] 引用计数为2
l2.append(l1) # l2 = [33, 44, l1列表] 引用计数为2
del l1 # del后面加一个变量名表示:断开变量名l1与数据值列表的绑定关系 引用计数为1
del l2 # 断开变量名l2与列表的绑定关系 引用计数为1
* 此时两个变量名已经与两个列表断开关系,可以认为这两个列表的数据为垃圾数据了,但此时这两个列表的引用计数仍然为1。这种现象就叫做循环引用,对于程序员来说是不希望看到这种现象的。
* 当内存占用达到临界值的时候 程序会自动停止, 然后扫描程序中所有的数据,并给只产生循环引用的数据打上标记 之后一次性清除
由于垃圾回收机制的频繁运行也会损耗各项资源,所以发展了分代回收的手段。
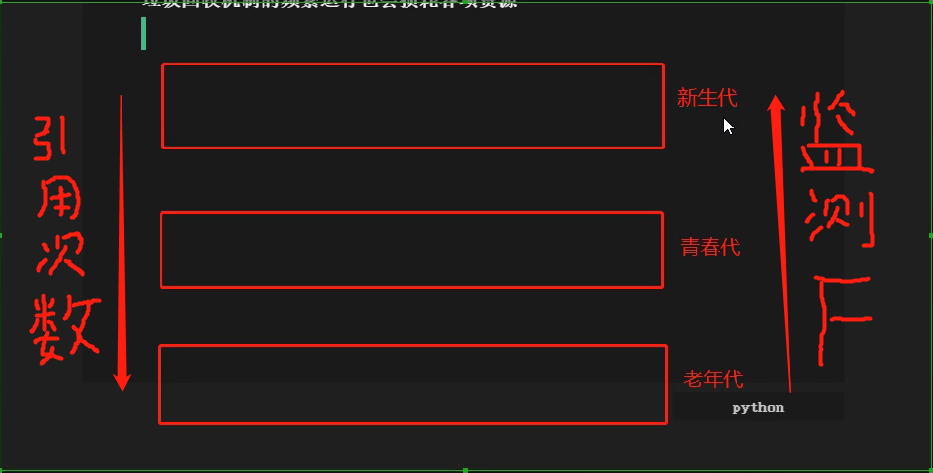
2. 分代回收,把所有的数据分类或者叫分代,一般分3代
新生代 (程序运行刚开始产生的数据都放在第一代,垃圾回收机制对于这些数据采用同样的监测机制,比如每个5分钟看下这些数据的引用计数是几,通过一段时间的监测后,将引用计数变多的数据往下一代放)
青春代 (同样的原理只是监测的频率变低,还是一段时间的监测后,将引用计数变多的数据往下一代放)
老年代 (越往下检测频率越低,引用次数越高)
.
.
流程控制理论
1.流程:就是计算机执行代码的顺序
2.流程控制:对计算机代码执行的顺序进行有效的管理,只有流程控制才能实现在开发当中的业务逻辑。
事物执行流程总共可以分为三种
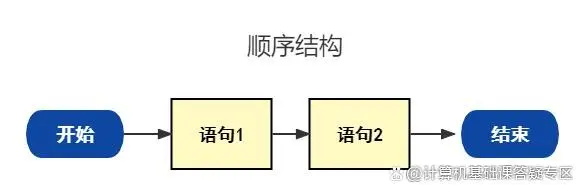
1. 顺序结构
就是代码一种自上而下的执行结构,也是python默认的流程
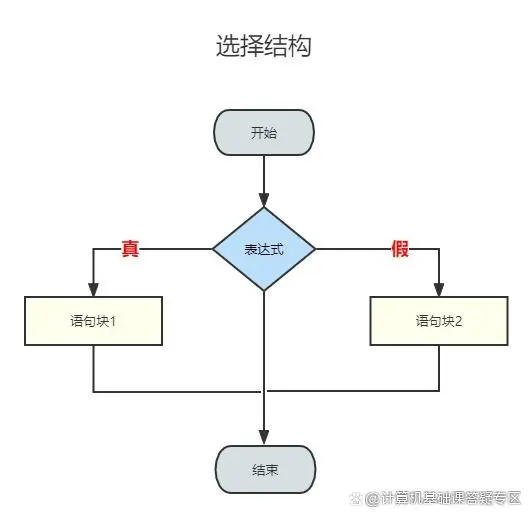
2.分支结构
* 根据在某一步的判断,有选择的去执行相应的逻辑的一种结构
3.循环结构
* 在满足一定条件下,一直重复的去执行某段代码的逻辑的一种结构
ps:在代码的世界里 很多时候可能会出现三者混合
提示:作为小白 在学习流程控制的时候 建议做到代码和图形的结合
.
.
.
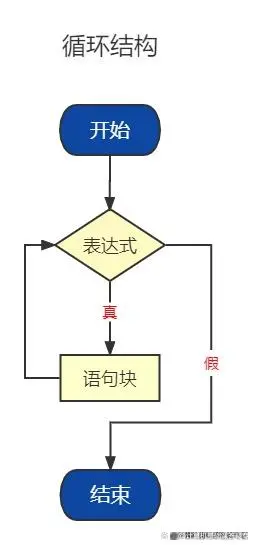
流程控制必备知识
1.python中使用代码的缩进来表示代码的从属关系,如果两行代码缩进相同,就认为两代码属于平行关系,执行完上一行代码,就执行下一行代码。
2.并不是所有的代码都可以拥有缩进的子代码。
可以拥有缩进的子代码的代码有: if关键字
3.如果有多行子代码属于同一个父代码,那么这些子代码需要保证相同的缩进量
4.python中针对缩进量没有具体的要求,但是推荐使用四个空格(windows中tab键)
5.当某一行代码需要编写子代码的时候,那么这一行代码的结尾肯定需要冒号:
6.相同缩进量的代码彼此之间平起平坐,按照顺序结构依次执行。
.
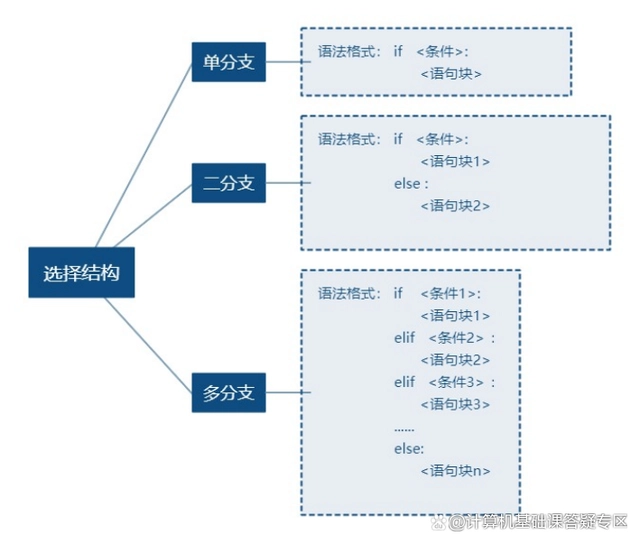
分支结构(就是选择结构)的代码编写
1. 单if分支结构
if 语法的核心都是一个值为True或False的表达式或者是数据
也就是说if后面的表达式或数据的结果是True就执行if下面的代码,是False就不执行if下面的代码,比如if后面就是一个数据值False,那么就不走if下面的代码了。
if后面可以不加条件判断的表达式,直接跟一个变量名,甚至是一个数据值!!!!!!
.
if 条件: 条件成立之后才会执行代码,条件不成立不会执行下面的代码,直接结束。
子代码
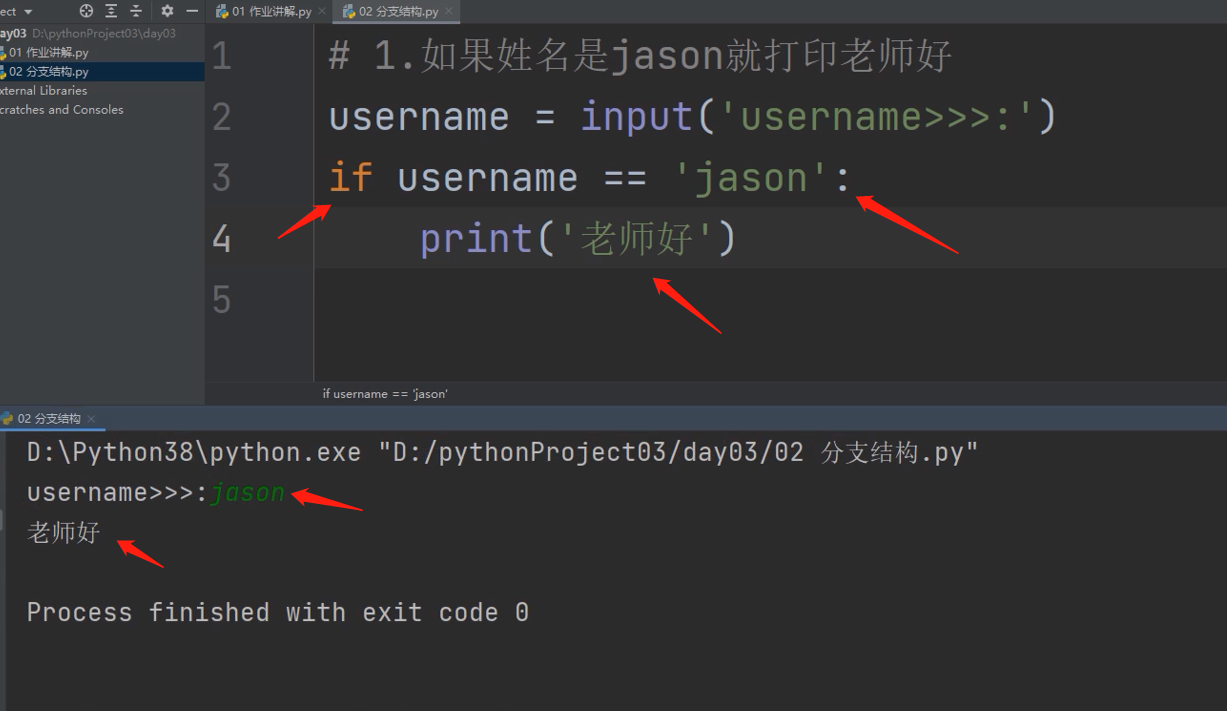
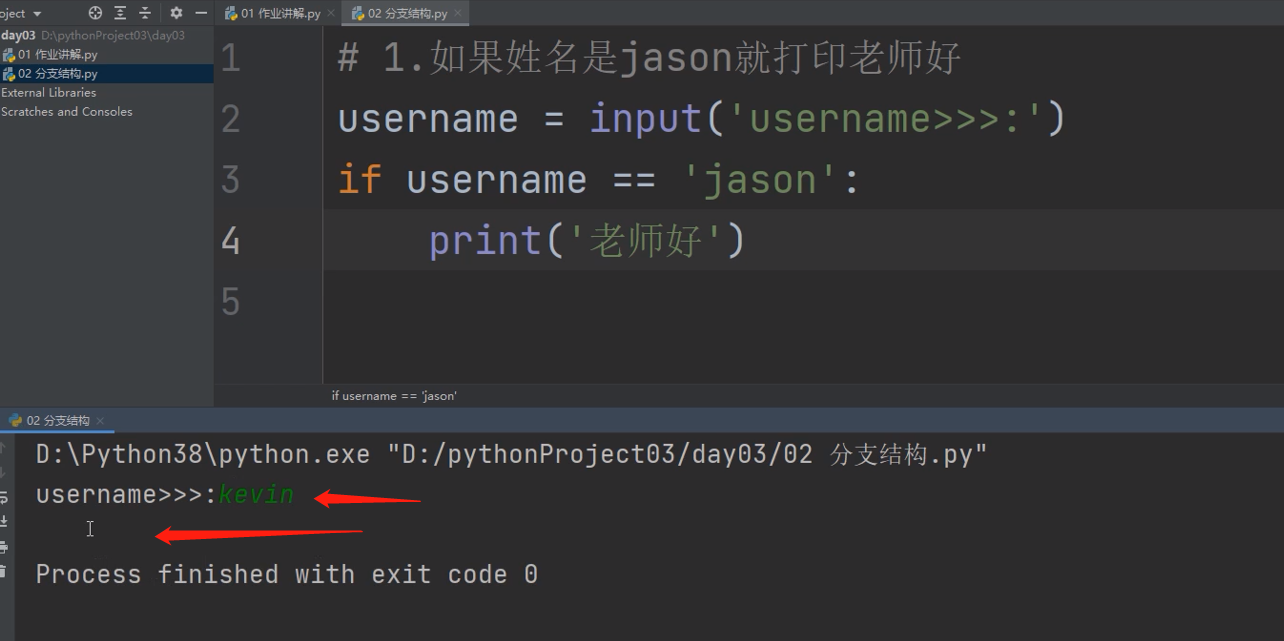
username = input('username>>>:')
if username == 'jason':
print('老师好')
条件成立执行:
.
条件不成立结束,不打印了:
.
2. if...else...分支结构
if 条件: 条件成立之后执行的子代码
子代码1
else: 条件不成立执行的子代码
子代码2
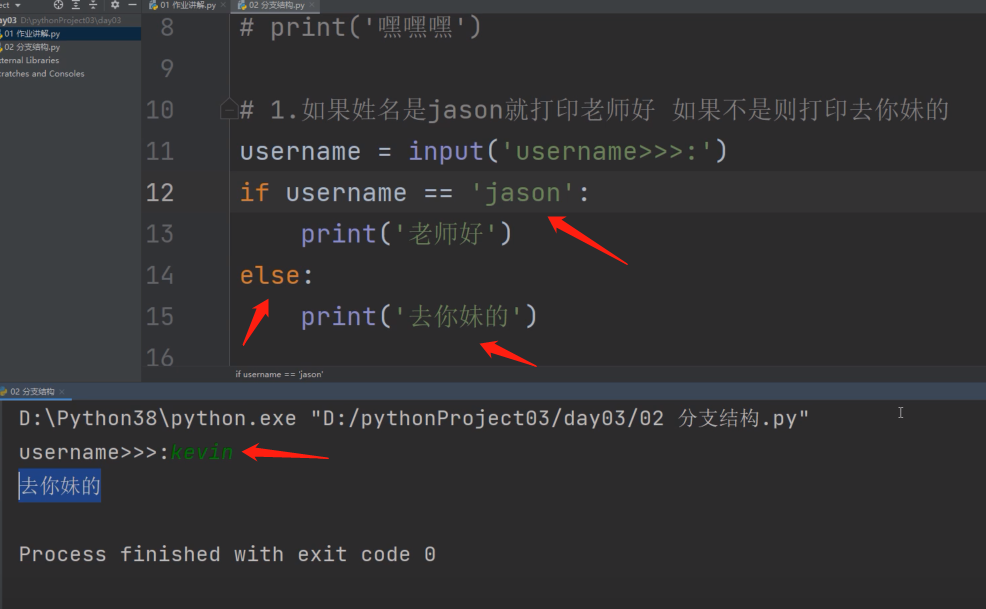
username = input('username>>>:')
if username == 'jason':
print('老师好')
else:
print('去你妹的')
输入条件成立,打印'老师好',不成立执行'去你妹的'
3.if...elif...else分支结构
if 条件1: # 条件1成立之后执行的子代码
子代码1
elif 条件2: # 用了elif就默认上面的所有条件都不成立,也就是虽然只写了条件2,但是还隐藏了一个条件1不符合的子代码,条件2成立,执行的子代码
子代码2
elif 条件3: # 同样隐藏了条件1和2都不成立的子代码 ,条件3成立,执行的子代码
子代码3
else: # 上述条件都不成立 ,执行的子代码
ps:elif的条件可以写多个、但是只要是在if语句里面所有代码永远只会走一个。就是说数据符合if条件就走if的子代码,符合elif条件1的,就走条件1对应的代码。符合那个条件走哪个的子代码。如果一个数据符合if语句里面的多个条件,那么你的if语句语法设置的就有问题了。
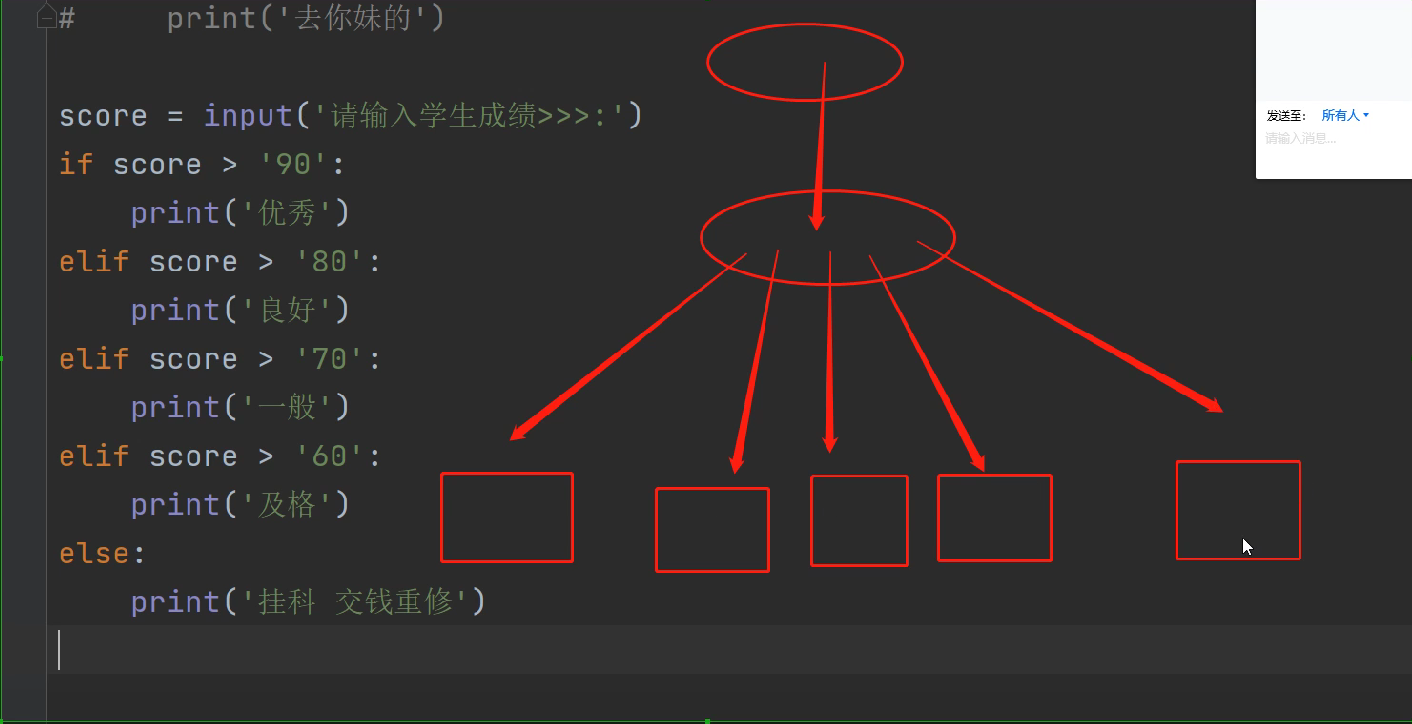
score = input('请输入学生成绩>>>:') # input输入的数据都会转成字符串
score = int(score) # 所以将字符串的整数转换成整型的整数
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('一般')
elif score >= 60:
print('及格')
else:
print('挂科 交钱重修')
.
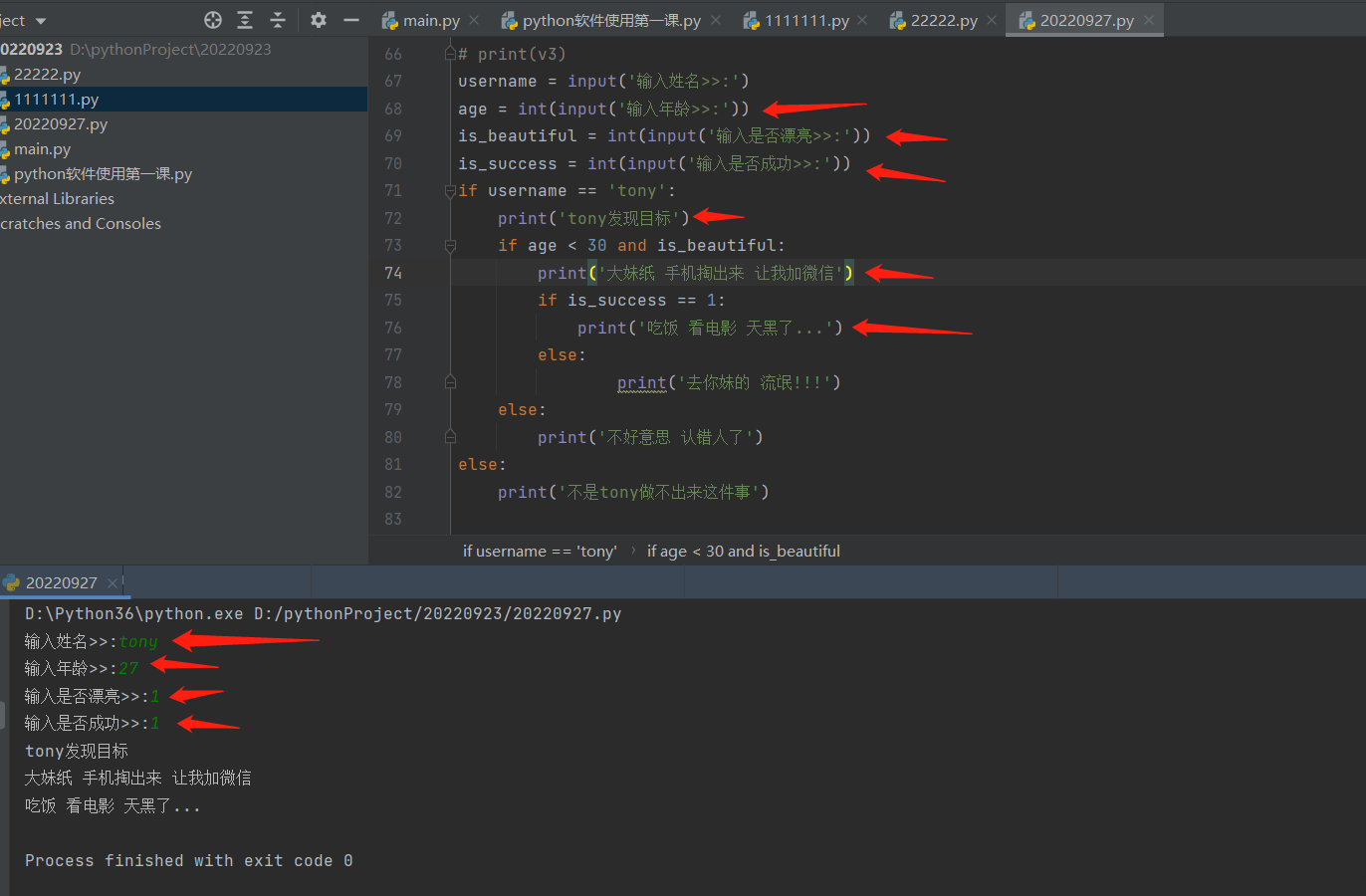
4.if的嵌套使用(有点难)
username = input('输入姓名>>:')
age = int(input('输入年龄>>:'))
is_beautiful = int(input('输入是否漂亮>>:'))
is_success = int(input('输入是否成功>>:'))
if username == 'tony':
print('tony发现目标')
if age < 30 and is_beautiful:
print('大妹纸 手机掏出来 让我加微信')
if is_success == 1:
print('吃饭 看电影 天黑了...')
else:
print('去你妹的 流氓!!!')
else:
print('不好意思 认错人了')
else:
print('不是tony做不出来这件事')
输入的都是符合的条件:
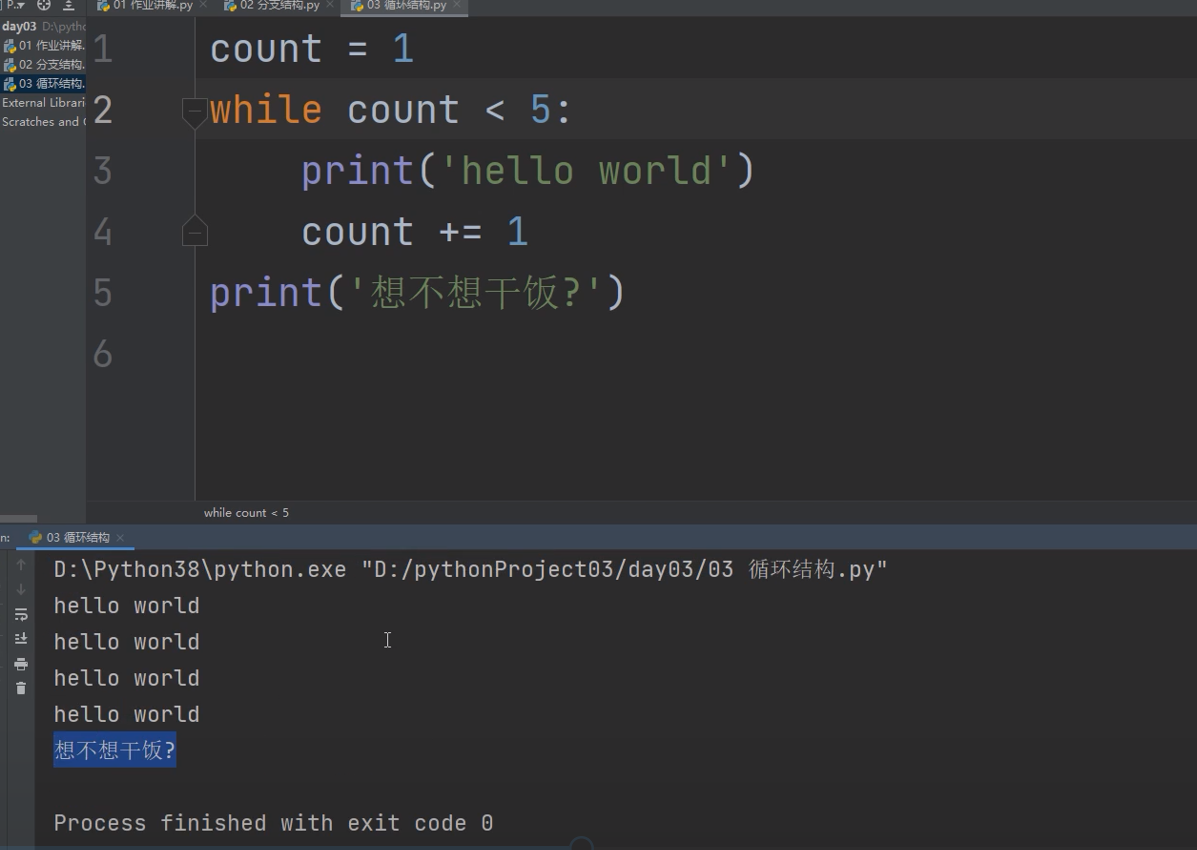
循环结构的代码编写 while条件:
就是想让一些代码反复的执行
while 条件: # 条件成立之后执行的子代码(循环体代码)
1. 先判断条件是否成立
2. 如果成立则执行循环体代码
3. 循环体代码执行完毕后再次回到条件判断处 判断条件是否成立
4. 如果成立 则继续执行循环体代码
5. 按照上述规律依次执行 直到条件不成立才会结束循环体代码的执行
count = 1
while count < 5: # count只要小于5就一直运行循环的子代码
print('hello world')
count += 1 # count = count + 1
print('想不想干饭?')
break 强行结束循环体
while循环体代码一旦执行到break会直接结束循环。强制结束循环体。不管break在while的哪一级的子代码里面。
# 遇到break就会,直接结束break所在的while循环,跳出while的循环,按顺序执行与while同级别的代码。
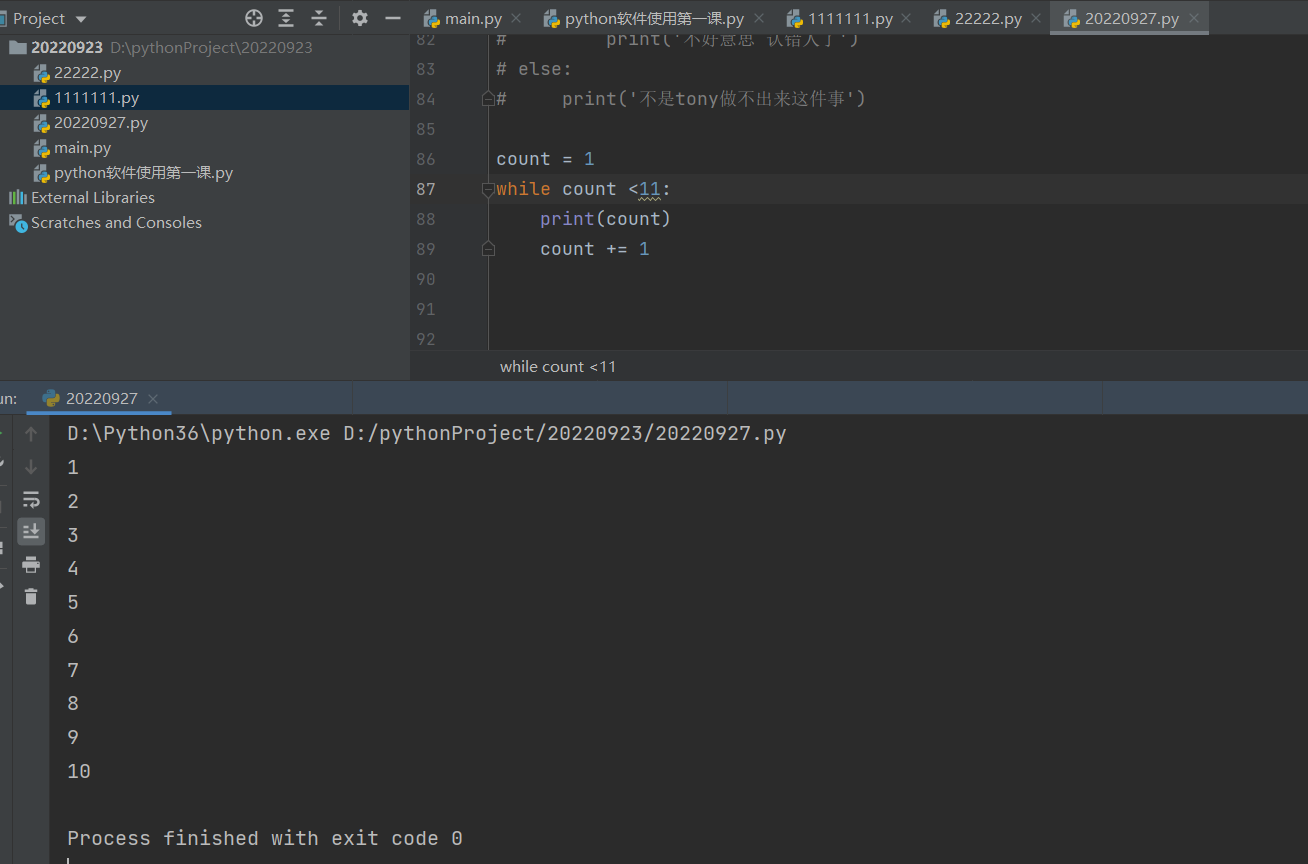
循环打印1-10
循环打印1-10,走到5直接结束循环。利用 while if break 三个语法
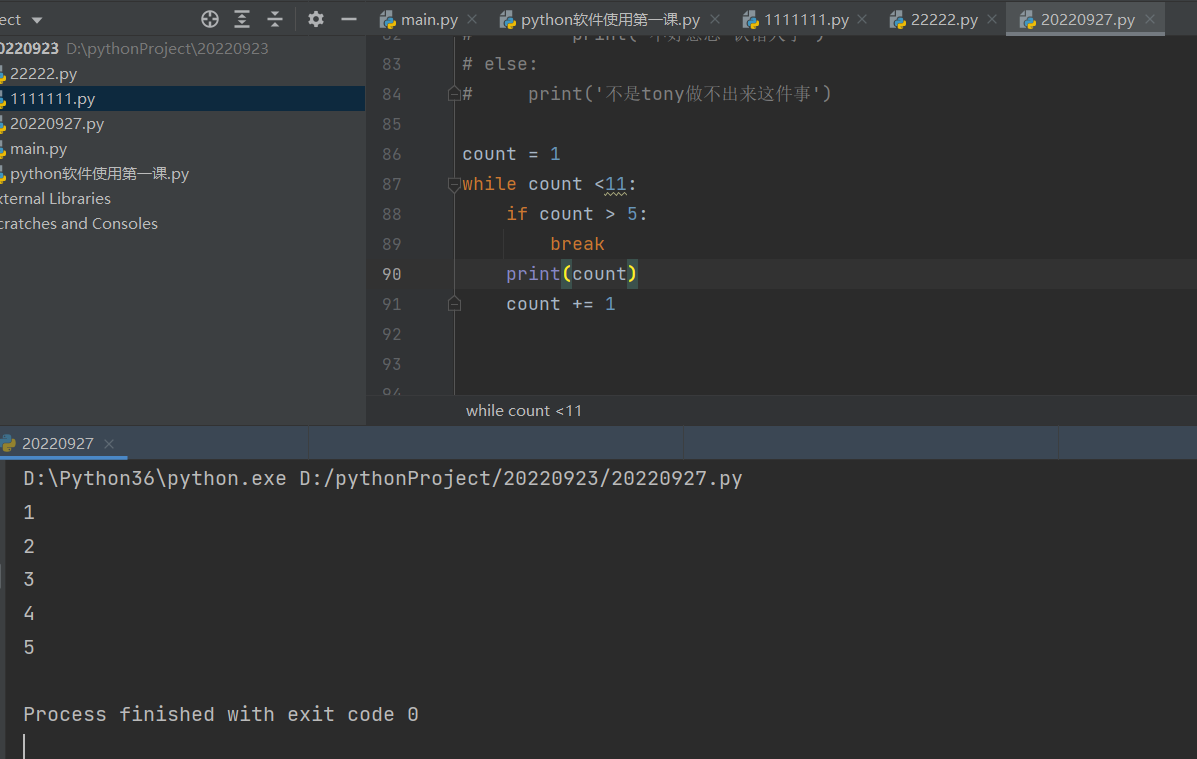
。
循环打印1-10,遇到4跳过。
错误示范,这地方出了一个问题,当count等于4时,根据if的语句,执行continue,结束循环返回条件处,没有打印数字,和数字加1,所以只打到3结束了。
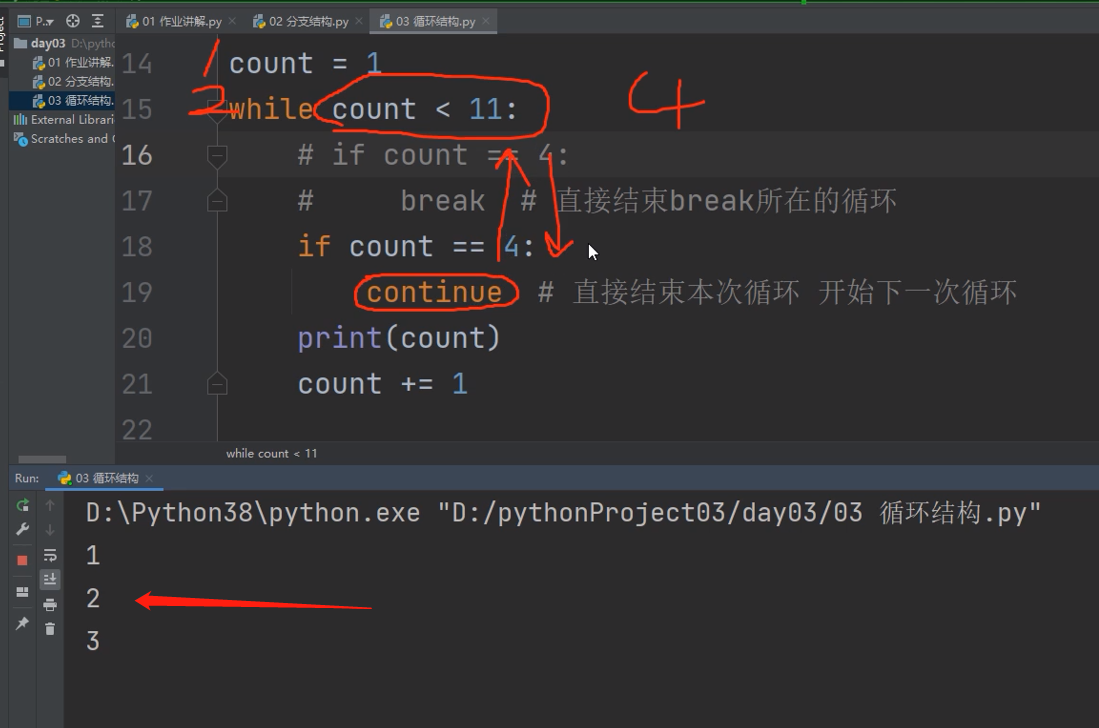
.
正确示范 就在上面的代码continue上面再加一行输入一个n=n+1的结构。让4加完1后再进入循环。再利用if的条件
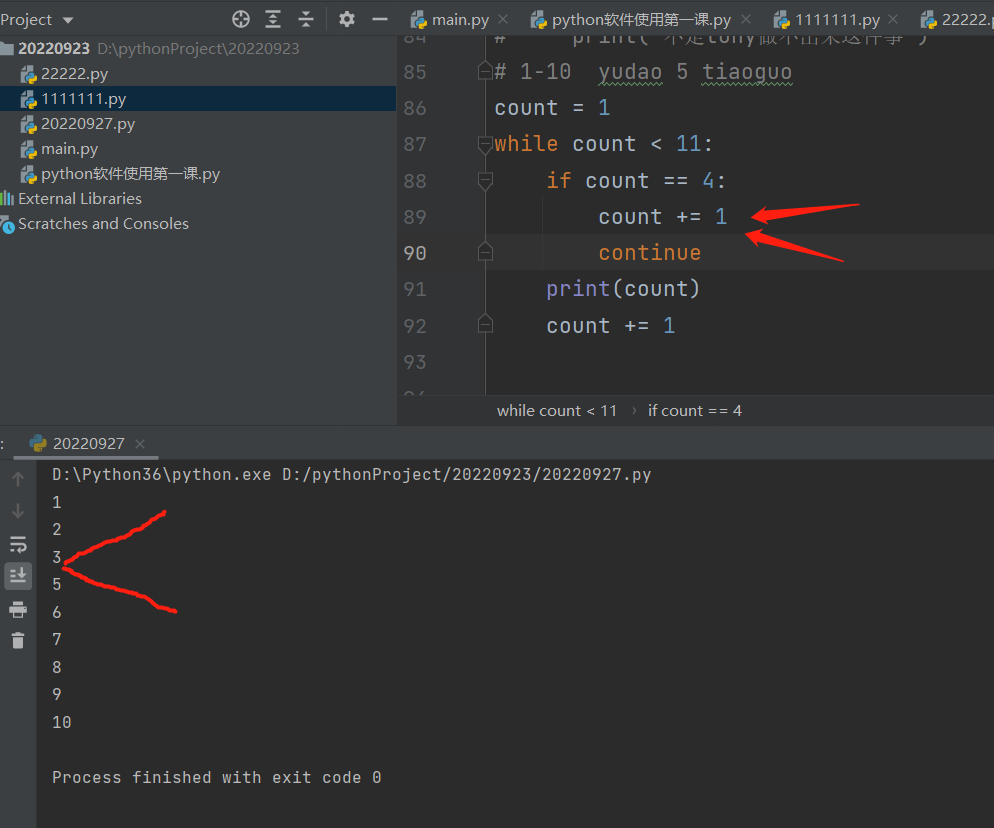
continue 直接跳到条件判断处
while循环体代码一旦执行到continue会结束本次循环,直接回到条件判断出,开始下一次循环。
while与else连用情况:
while 条件:
循环代码
else:
循环体代码没有被强制结束的情况下, 执行完毕后,就会执行else子代码,如果循环体代码被break强行结束,那就不执行else的子代码。
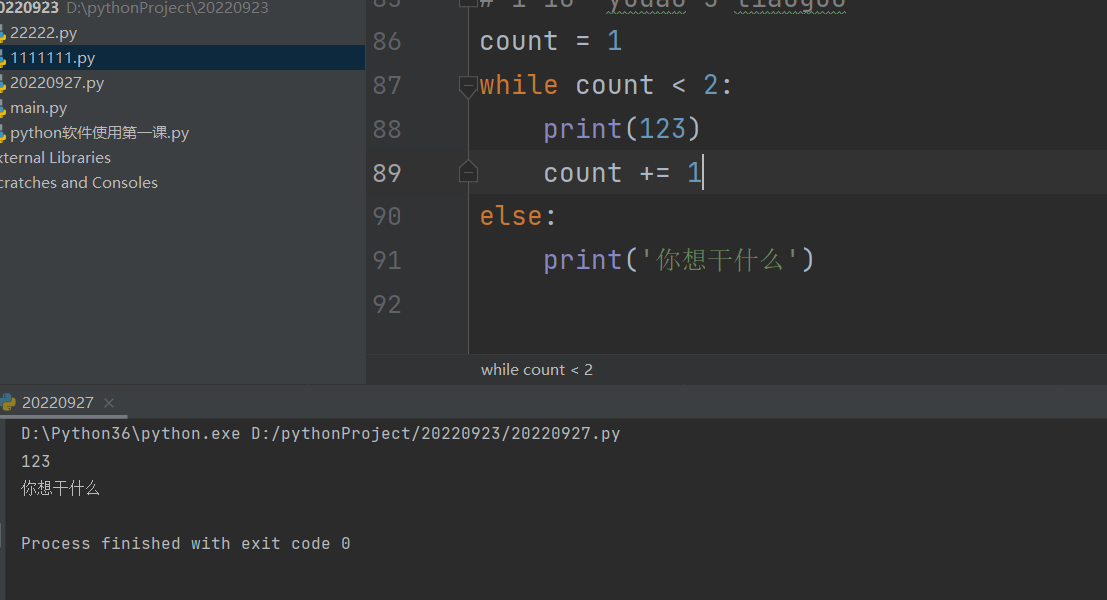
while循环补充说明
1.死循环
真正的死循环是一旦执行 CPU功耗会急速上升 直到系统采取紧急措施
尽量不要让CPU长时间不间断运算
2.嵌套及全局标志位
强调:一个break只能结束它所在的那一层循环
强调:有几个while的嵌套 想一次性结束 就应该写几个break
强调:如果不想反复写break 可以使用全局标志位
is_flag = True # 1. 这个就是全局标志位
while is_flag:
username = input('username>>>:')
password = input('password>>>:')
if username == 'jason' and password == '123':
while is_flag:
cmd = input('请输入您的指令>>>:')
if cmd == 'q':
is_flag = False # 2. 这个就是全局标志位起作用的原因
print('正在执行您的指令:%s' % cmd)
else:
print('用户名或密码错误')
.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY