sqlalchemy与flask-sqlalchemy 用法(相关的关键字的使用注意事项,连表操作一些具体细节总结,filter查询语句的总结,)
.
.
参考博客 https://blog.csdn.net/weixin_40547993/article/details/105857937
.
.
.
.
# flask的orm语句查询的时候,只要还没有点all或者first,只要还是个query,
# 底层就还没有真正执行sql查询语句!!!
.
.
.
.
.
.
.
query关键字的使用
# db_session.query() query的括号里面可以放字段,但是要用表名点字段
res = db_session.query(User).all()
# 对应的sql语句 SELECT * FROM `user` 只是上面orm语句把每行查询的数据做成了一个对象
# 可以认为query括号里面如果直接写表名,相当于把该表的所有的字段都放到括号里面去了
res1 = db_session.query(User.name,User.age_id).all()
# 对应的sql语句 SELECT NAME,age_id FROM `user`
-----------------------------------------------------------------
# query括号里面可以放多个表名,相当于把每个表的所有字段都写在括号里面了
# 这样如果执行连表操作后,返回结果是一个大列表里面套了一个个元祖,
# 每一个元祖里面是对应的连表的一个个表记录对象
res = db_session.query(User, Age).join(Age, User.age_id == Age.id).all()
print(res) [(User_obj1,Age_obj1),(User_obj2,Age_obj2),(User_obj3,Age_obj3),]
res = db_session.query(User.name, Age.age).join(Age, User.age_id == Age.id).all()
print(res) # [('lihua', 55), ('lqz', 56), ('haha', 57), ('haha2', 58)]
-----------------------------------------------------------------
.
.
.
代码示范
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_session
from models import User
# 第二步 生成引擎
engine = create_engine(
'mysql+pymysql://root:222@127.0.0.1:3306/teng?charset=utf8',
max_overflow=0, # 超过连接池大小后,还可以再创建的连接数
pool_size=10, # 连接池大小,sqlalchemy自带连接池!!!!!
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=10, # 连接被用10次后,对该连接的回收,再创一个新的连接,-1表示线程不回收一直用
)
# 第二步 用sessionmaker类产生一个Session类,传入engin
Session = sessionmaker(bind=engine)
# db_session = Session()
db_session = scoped_session(Session)
res = db_session.query(User).all() # 结果是个普通列表
print(res) # 列表里面,放一个个查到的对象
for i in res:
print(i.name) # 没循环出一个对象,打印对象的name属性
res1 = db_session.query(User.name,User.age_id).all()
print(res1) # [('lihua', 1), ('lqz', 2), ('jason', 3), ('chris', 4)]
.
.
.
.
.
.
all first one one_or_none scalar 关键字用法
.all() # 返回一个列表
.first() # 不管查询的对象有几个,只会取查到的第一个对象,没查到就返回none
.one() # 如果查到一个对象,就正常返回, 查到多个或没查到都会报错!!!
.one_or_none() # 查到一个对象或没查到都正常返回, 查到多个会报错!!!
.scalar() # 返回查询结果的第一个标量值!!! 这个后续有空补充!!!暂时可以先简单认为和first差不多!!!
.
.
.
.
.
.
过滤不需要外键的!
age_obj = db_session.query(Age).filter(Age.id == 1).first()
res2 = db_session.query(User.name,User.age_id).filter(User.age_id == Age.id).first()
print(res2) # ('lihua', 1) 可以正常过滤出来
.
.
.
.
.
.
连表操作也是不需要外键的!
# 企业里面一般两张关联表,不建立真实的物理外键,都是逻辑的外键
# 连表操作也是能正常执行的!!!
res = db_session.query(User.name, Age.age).join(Age, User.age_id == Age.id).all()
print(res) # [('lihua', 55), ('lqz', 56), ('haha', 57), ('haha2', 58)]
# 如果两个表有外键关联,连表的语句可以简化成
res = db_session.query(User.name, Age.age).join(Age, ).all()
# join 是内连接
------------------------------------------
# 如何左连接或右连接,右连接就拿右边的表作为起始表即可!!!
res = db_session.query(User.name, Age.age).outerjoin(Age,User.age_id == Age.id).all()
print(res)
# [('lihua', 55), ('lqz', 56), ('jason', 57), ('jack', 58), ('jocker', None)]
res = db_session.query(User.name, Age.age).join(Age,User.age_id == Age.id,isouter=True).all()
print(res)
# [('lihua', 55), ('lqz', 56), ('jason', 57), ('jack', 58), ('jocker', None)]
# 左连接 以左表为基准 展示左表所有的数据!!! 右表如果没有对应项则用NULL填充!!!
# 还可以这样写,指定起始表名,一般在多张表连接的时候,习惯这样写,能够让结构更清晰!!!
res = db_session.query(User.name, Age.age).select_from(User).outerjoin(Age,User.age_id == Age.id).all()
# [('lihua', 55), ('lqz', 56), ('jason', 57), ('jack', 58), ('jocker', None)]
--------------------------------------------------------------
.
.
.
.
.
关于连表的一些小总结
@project_blueprint.route('/', methods=["GET", ])
def index():
user_obj_list = db_sqlalchemy.session.query(TestUser.username, TestAge.age, TestPassword.password) \
.select_from(TestUser) \
.outerjoin(TestAge, TestUser.id == TestAge.user_id) \
.outerjoin(TestPassword, TestAge.id == TestPassword.age_id) \
.all()
print(user_obj_list)
return 'This is project Module !'
# 打印的结果为
[('lihua', 11, 'qqq'), ('lqz', 12, 'www'), ('jason', 13, 'eee'), ('rocky', 14, None), ('lola', None, None)]
--------------------
可以看到用户表5条数据,年龄表4条数据,密码表3条数据 这种情况下查所有,
3张表连起来最后的样子是这样的:
[
(1, 'lihua', 1, 11, 1, 1, 'qqq', 1),
(2, 'lqz', 2, 12, 2, 2, 'www', 2),
(3, 'jason', 3, 13, 3, 3, 'eee', 3),
(4, 'rocky', 4, 14, 4, None, None, None),
(5, 'lola', None, None, None, None, None, None)
]
# 先以起始表开始,左连接age表,age表如果没有对应项则用Null填充
# 所以连到第5条数据的时候,发现age表没有对应数据,用Null填充,变成这样
[
(1, 'lihua', 1, 11, 1, ),
(2, 'lqz', 2, 12, 2,),
(3, 'jason', 3, 13, 3, ),
(4, 'rocky', 4, 14, 4, ),
(5, 'lola', None, None, None,)
]
# 在该基础上继续连表操作 outerjoin(TestPassword, TestAge.id == TestPassword.age_id)
# 还是一样以左表为基础,右表没有就用null填充
----------------------------------------
# query里面只写表名的时候,
@project_blueprint.route('/', methods=["GET", ])
def index():
user_obj_list = db_sqlalchemy.session.query(TestUser, TestAge, TestPassword) \
.select_from(TestUser) \
.outerjoin(TestAge, TestUser.id == TestAge.user_id) \
.outerjoin(TestPassword, TestAge.id == TestPassword.age_id) \
.all()
print(user_obj_list)
return 'This is project Module !'
# 打印的结果为
[
(<TestUser 1>, <TestAge 1>, <TestPassword 1>),
(<TestUser 2>, <TestAge 2>, <TestPassword 2>),
(<TestUser 3>, <TestAge 3>, <TestPassword 3>),
(<TestUser 4>, <TestAge 4>, None),
(<TestUser 5>, None, None)
]
不要在意表结构的合理性,只是为了演示
我们用user表作为左连接的起始表,
左连接特性 以左表为基准 展示左表所有的数据!!! 右表如果没有对应项则用NULL填充!!!

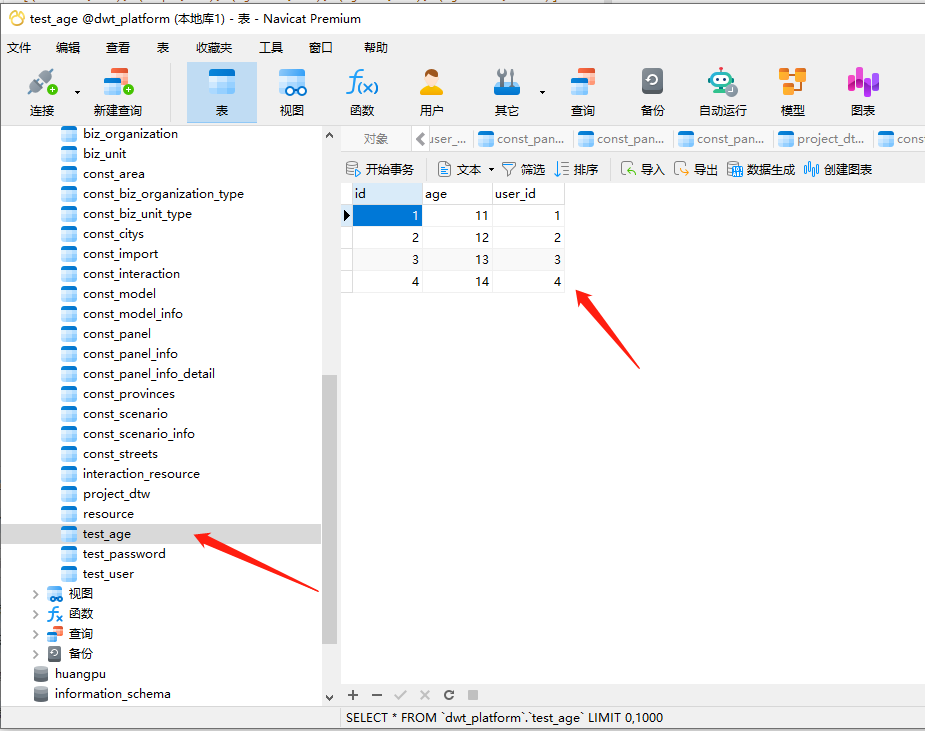

.
.
.
.
.
这种情况下,可以看到age表里面的最下面的两条数据是没有和user表里的数据关联的
所以虽然age表里面的最下面的两条数据和password表里的有关联,没有用



.
.
# 第一次连表.outerjoin(TestAge, TestUser.id == TestAge.user_id) 后的结果
[
(1, 'lihua', 1, 11, 1),
(2, 'lqz', 2, 12, 2),
(3, 'jason', 3, 13, 3),
(4, 'rocky', 4, 14, 4),
(5, 'lola', None, None, None)
]
# 在该基础上再连表.outerjoin(TestPassword, TestAge.id == TestPassword.age_id)后的结果
[
(1, 'lihua', 1, 11, 1, 1,'qqq', 1),
(2, 'lqz', 2, 12, 2, 2,'www', 2),
(3, 'jason', 3, 13, 3, 3,'eee', 3),
(4, 'rocky', 4, 14, 4, None, None, None),
(5, 'lola', None, None, None, None, None, None)
]
# 还是一样 由于Password表里面没有age_id等于age表里面的id=4的关联数据, 所以用None填充
# 同理Password表里面没有age_id等于age表里面的id=none的关联数据,所以用None填充
# 所以就是最后的样子了!!!
---------------------------------------------------
.
.
.
.
.
连表的时候,需要连多对多的表的时候,结果是什么样子的



.



.
.
obj_list = db_sqlalchemy.session.query(
TestUser.id, TestUser.username,
TestAge.id,TestAge.age,TestAge.user_id,
TestPassword.id,TestPassword.password,TestPassword.age_id,
TestUserBook.user_id, TestUserBook.book_id,
TestBook.id, TestBook.name,TestBook.publish_id,
TestPublish.id, TestPublish.name
) \
.select_from(TestUser) \
.outerjoin(TestAge, TestUser.id == TestAge.user_id) \
.outerjoin(TestPassword, TestAge.id == TestPassword.age_id) \
.outerjoin(TestUserBook, TestUser.id == TestUserBook.user_id) \
.outerjoin(TestBook, TestUserBook.book_id == TestBook.id) \
.outerjoin(TestPublish, TestBook.publish_id == TestPublish.id) \
.all()
print(obj_list)
# 搞了一个用户与书的多对多表后,一个用户对多本书,一本书对多个用户,书表 出版社表 一对一
# 查所有后是这样的结果
[
用户表 年龄表 密码表 用户与书多对多表 书表 出版社表
(1, 'lihua', 1, 11, 1, 1, 'qqq', 1, 1, 1, 1,'金瓶每1', 1, 1, '北京出版社'),
(1, 'lihua', 1, 11, 1, 1, 'qqq', 1, 1, 2, 2,'金瓶每2', 2, 2, '南京出版社'),
(2, 'lqz', 2, 12, 2, 2, 'www', 2, 2, 3, 3,'金瓶每3', 3, 3, '西京出版社'),
(3, 'jason', 3, 13, 3, 3, 'eee', 3, 3, 4, 4,'金瓶每4', 4, 4, '东京出版社'),
(4, 'rocky', 4, 14, 4, N, N, N, 4, 4, 4,'金瓶每4', 4, 4, '东京出版社'),
(5, 'lola', N, N, N, N, N, N, 5, 4, 4,'金瓶每4', 4, 4, '东京出版社')
]
none 用 N 简单表示了
# 连表规律总结:
# 可以看到当连表的时候,还是一样连表的时候,左表为基准,右表没对应的数据,就用none填充
# 多张表一起连的时候,按照代码的连表顺序,每连一次,生成的表,作为继续往后连表时的左表
# 当涉及到一对多,多对多的时候,可以看到:
# 当没有和多对多表连表的时候总共只有5个元组
[
(1, 'lihua', 1, 11, 1, 1,'qqq', 1),
(2, 'lqz', 2, 12, 2, 2,'www', 2),
(3, 'jason', 3, 13, 3, 3,'eee', 3),
(4, 'rocky', 4, 14, 4, None, None, None),
(5, 'lola', None, None, None, None, None, None)
]
# 连了多对多的 用户与书表后,就会把第一个元组有复制了一份,其实这样也好理解
# 原来一对一所有数据都在一行,一对多的时候,多的数据怎么放,只有把一的数据复制多份
# 每一份对应一个多的数据!!!
# 同理书是1 用户是多的情况,也一样,将书的数据复制多份,每份对应一个用户数据!!!
.
.
.
.
.
注意 连表的时候,以哪个表作为起始表,是有讲究的
打个比方user表有3条数据 user1 user2 user3
角色表有2条数据 role1 role2
假设user1对应role1 user2与user3 对应的是role2
那么现在以user表做起始表连role表,会得到[(user1,role1),(user2,role2),(user3,role2)]
以role表作为起始表连user表,会得到[(role1,user1),(role2,user2),(role2,user3)]
感觉没什么区别
但是如果这样
user1 user2 user3 user4
role1 role2 role3
以user表做起始表连role表,会得到[(user1,role1),(user2,role2),(user3,role2),(user4,None)]
以role表作为起始表连user表,会得到[(role1,user1),(role2,user2),(role2,user3),(role3,None)]
# 所以一般当你需要连表,又想要得到所有的user对象的时候,那就以user表作为起始表!!!
# 同理如果需要,得到所有的role对象的时候,那就以role表作为起始表!!!
.
.
.
.
join的注意事项
# join, 默认是inner join, 自动按外键关联 join括号里面要放,要连接的表的表名
# 别放成起始表的表名!!!
select * from Person inner join Hobby on Person.hobby_id=Hobby.id; # 原生sql语句
res = db_session.query(Person).join(Hobby,).all() # 自动按外键关联,有外键关联才能这样写
res = db_session.query(Person).join(Hobby,Person.hobby_id==Hobby.id).all() # 一样的
---------------------------------------------
# isouter=True 外连, 没有右连接,反过来即可
select * from Person left join Hobby on Person.hobby_id=Hobby.id; # 原生sql语句
res = db_session.query(Person).join(Hobby, isouter=True).all() # 表示Person左连接Hobby表
res = db_session.query(Person).outerjoin(Hobby,).all() # 也可以这样写
# outerjoin相当于LEFT OUTER JOIN 左外连接;outerjoin( ) 返回结果有null
# 注意query括号里面放表名,代表的是要查询该表里的所有字段!!!!
# 还可以这样写,指定起始表名,一般在多张表连接的时候,习惯这样写,能够让结构更清晰!!!
res = db_session.query(Person).select_from(Person).outerjoin(Hobby,Person.hobby_id=Hobby.id).all()
.
.
.
.
.
.
.
.
查询出的结果只要没有点all或者点first,就还是个query对象,还可以继续过滤
query = db_session.query(User.name, User.age_id).filter(User.id > 2)
print(query.first()) # ('jason', 3)
user_obj = query.filter(User.age_id > 3).first()
print(user_obj) # ('chris', 4)
.
.
.
.
.
flask-sqlalchemy模块 比 sqlalchemy模块的好处是
Flask-SQLAlchemy 是一个 Flask 扩展,它在 SQLAlchemy 的基础上提供了更多的便利和集成。
下面是一些 Flask-SQLAlchemy 相对于 SQLAlchemy 的优点:
1. 简化配置:Flask-SQLAlchemy 简化了与 Flask 应用程序的集成过程。它提供了一个简洁的接口,
让你能够轻松地配置和连接数据库。
2. 上下文管理:Flask-SQLAlchemy 提供了上下文管理器,使得在 Flask 应用程序中使用 SQLAlchemy 更加方便。
它自动处理数据库连接的打开和关闭,并确保每个请求都有一个独立的数据库会话。
3. ORM集成:Flask-SQLAlchemy 与 SQLAlchemy 的对象关系映射(ORM)集成得非常紧密。
它简化了数据库模型的定义和查询操作,并提供了方便的数据库迁移工具。
4. 基于 Flask 的扩展:Flask-SQLAlchemy 是为 Flask 应用程序设计的扩展,它与 Flask 的生态系统完美结合。
你可以利用 Flask 的特性,如上下文变量和请求钩子,与 Flask-SQLAlchemy 一起使用,从而更好地管理数据库操作。
5. 内置的表单支持:Flask-SQLAlchemy 提供了与 Flask-WTF 扩展的无缝集成。
这使得在处理表单数据时能够更方便地与数据库交互。
总体而言,Flask-SQLAlchemy 提供了更高层次的抽象和更方便的集成方式,使得在 Flask 应用程序中使用 SQLAlchemy 更加简单和灵活。它的设计目标是为了让开发人员能够更快速地构建和管理数据库相关的功能。
.
.
.
.
db_session 数据库的会话对象到底是个什么东西?
数据库会话是与数据库交互的主要接口之一。它允许你执行数据库查询、插入、更新和删除等操作。
会话对象负责管理数据库连接的生命周期,并提供了一些方法和属性来执行这些操作。
db_session 并不是直接代表数据库连接池的一个连接,而是一个数据库会话对象。
在 SQLAlchemy 中,数据库连接池是由 create_engine 函数创建的。这个连接池管理着多个数据库连接,
用于处理与数据库的实际通信。
而 db_session 则是基于连接池创建的会话对象
会话对象是在连接池的基础上提供了更高级别的接口,用于执行数据库操作。
当你在代码中使用 db_session 来执行查询、插入、更新或删除等操作时,
它会从连接池获取一个数据库连接,执行相应的操作,然后将连接返回给连接池。
所以,db_session 并不是一个直接的数据库连接,而是通过连接池管理的会话对象。
可以将 db_session 视为一个封装了连接池和会话功能的高级对象,
它提供了方便的方法来执行数据库操作,并且在每个请求或线程中都能保持正确的会话状态。
.
.
.
.
.
.
.
Session = sessionmaker(bind=engine) 这句话里Session接收的是一个对象还是一个类?
在这句代码中,Session 接收的是一个类。
sessionmaker 是 SQLAlchemy 提供的一个工厂函数,用于创建会话类。
当你调用 sessionmaker(bind=engine) 时,它返回一个会话类,而不是一个会话对象。
在 SQLAlchemy 中,通过调用会话类,你可以创建具体的会话对象来执行数据库操作。
在给定的代码中,Session 就是会话类,它使用 bind=engine 参数来绑定会话类与特定的数据库引擎(即 engine 对象)。
这样,当你使用 Session() 创建一个会话对象时,它将与指定的数据库引擎关联。
.
.
.
.
使用flask_sqlalchemy的时候注意事项
视图函数里面如果要用flask_sqlalchemy的db对象去操作数据库,
就一定要把该db对象注册到app中区
db.init_app(app) # 将db注册到app中 一般写在蓝图注册代码的下面
-----------------------------
如果在一些特殊的场景下,不需要app对象或者不是在视图函数里面,使用db对象的时候怎么办?
还是要用flask类产生app对象,然后
from src import db
from src.models.flasksqlalchemy_models_app import *
from src import create_app
app = create_app()
@app1.task
def celery_upload(big_list, rec_upload_obj_id):
with app.app_context():
rec_upload_obj = db.session.query(RecUpload).filter(RecUpload.id == rec_upload_obj_id).first()
# 这样就能正常用db了
----------------------------------------------------
.
.
.
使用sqlalchemy模块的注意事项
# sqlalchemy模块产生的db对象操作数据库,需要你手动的去关连接对象,不关后续可能会报错
# 推荐使用with来管理
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy import create_engine
engine = create_engine(db_uri(DB_CONF),
convert_unicode=True,
pool_size=20,
pool_timeout=60,
pool_recycle=1800,
max_overflow=10,
pool_pre_ping=True
)
db_session = scoped_session(sessionmaker(autoflush=False, autocommit=False, bind=engine))
# 这样在with下面写数据库操作的代码,这样就不用手动close关db对象了
# 就不会出现什么timeout 这类的报错了
with db_session() as session:
user_obj_list = session.query(AuthUser).limit(2).all()
---------------------------------------------------------
.
.
.
.
.
.
falsk里模型表的参数意思
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
orders = db.relationship("Order", backref="user")
class Order(db.Model):
id = db.Column(db.Integer, primary_key=True)
total_price = db.Column(db.Float)
user_id = db.Column(db.Integer, db.ForeignKey("user.id"))
user = User.query.first()
orders = user.orders
for order in orders:
print(order.total_price)
在这个示例中,User和Order模型之间建立了一对多关系。
User模型中通过db.relationship定义了一个名为orders的属性。
在Order模型中通过user_id列的外键来关联User模型。
同时,backref参数定义了子对象如何访问父对象。
在这个示例中,我们可以通过user.orders访问该用户的所有订单
db.relationship写在“一”方,“一”方通过该属性可以取出一个列表,
列表元素为所有对应的“多”方的对象。
db.relationship中的backref是“多”方使用的。
“多”方通过该属性(即backref传入的字符串)可以访问到其对应的“一”方对象。
-----------------------------------------------------------
.
.
.
创建多对多关系
多对多关系是指两个对象之间相互关联,一个对象可以有多个子对象,
同时一个子对象也可以归属于多个对象。
在Flask中,可以通过db.relationship和secondary参数来定义多对多关系。
在这种关系中需要创建一个关联表,用来保存多对多的关系。
association_table = db.Table(
'association', db.Model.metadata,
db.Column('user_id', db.Integer, db.ForeignKey('user.id')),
db.Column('project_id', db.Integer, db.ForeignKey('project.id')))
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
projects = db.relationship("Project", secondary=association_table, backref="users")
class Project(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
user = User.query.first()
projects = user.projects
for project in projects:
print(project.name)
User和Project模型之间建立了多对多关系。User模型中定义了名为projects的属性。
在User模型中通过secondary参数来指定关联表。在示例中,
我们可以通过user.projects访问该用户所参与的所有项目,并通过for循环遍历打印每个项目的名字。
同样我们可以通过Project对象点users获得该项目的所有用户对象!!!
.
.
.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY