mysql的使用相关(字符集,常用命令,分表的思路)
.
.
.
create database 库名;
drop database 库名; # 删库跑路
重置表里面的id
alter table yourTableName auto_increment = 1;
# 使用navicat可以直接清空表,而且表里面的主键字段也归零,从新计数了
右键表名---截断表 就能,直接清空表,且主键字段也归零
----------------------------------------------------------------
# 命令行转储与运行sql文件!!!
# 在mysql客户端
先进入对应的库
source sql文件的路径 # 运行该转储的sql文件,将数据同步到该数据库
# 将所有的库数据,转储成一个叫all.sql的文件
mysqldump -h主机名 -P端口 -u用户名 -p密码 -A > D:/haha/all.sql
mysqldump -h127.0.0.1 -P3306 -uroot -p222 -A > D:/haha/all.sql
# 将单独的一个aaa库数据,转储成一个叫aaa.sql的文件
mysqldump -h127.0.0.1 -P3306 -uroot -p222 aaa > D:/hahaha/aaa.sql
----------------------------------------------------------------
.
.
.
.
.
.
创库的时候的时候注意事项
关于创库的时候的字符集与排序规则的选择
----------------------------------------------------------
# 用navicat创库的时候,字符集就设置成Utf8mb3就行了,排序规则就选utf8mb3_general_ci 即可
如果字符集设置成Utf8mb4 那么不选排序规则的时候,就会默排序规则 utf8mb4_0900_ai_ci
# 坑就来了 假设该库的数据转储成sql文件后
远程的服务器要创库,create database 库名; 默认的字符集是utf8mb3
所以该命令要写成
create database sina default character set utf8mb4 collate utf8mb4_unicode_ci;
如果collate后面写成utf8mb4_0900_ai_ci 库都创不了
所以用字符集设置成Utf8mb4 后,排序规则要指定为utf8mb4_unicode_ci 才行
------------------------------------------------------------
远程的服务器的mysql运行转储的sql文件的命令!!!
use db_name; # 先进到对应的数据库
source file_name.sql; # 运行转储的sql文件
# 如果出现报什么文件不存在的信息,直接打开sql文件,按报错的信息提示,找到对应的位置
# 比如看看 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci 字符集与排序规则对不对
# 有时候会出现这样 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci
# 就要把改成上面的utf8mb3 与 utf8mb3_general_ci
# 不然你直接创的数据库默认utf8mb3字符集,运行转储文件的时候,就会说该文件不存在!!!
----------------------------------------------------------
.
.
.
.
.
.
关于分表的一点思路
# 由于数据库表里面的数据,随着时间的累积越来越多,就会带来查询效率的变低,
# 历史的数据查询的场景并不多,都放在一张表里面并不合理,如何分表?
# 简单一点,把当前使用的表里面的数据,先用查询语句,过滤出比如表里面去年一年的数据
# 然后在navicat里面点导出结果,
用过滤条件,查出你想要导出的数据!!!
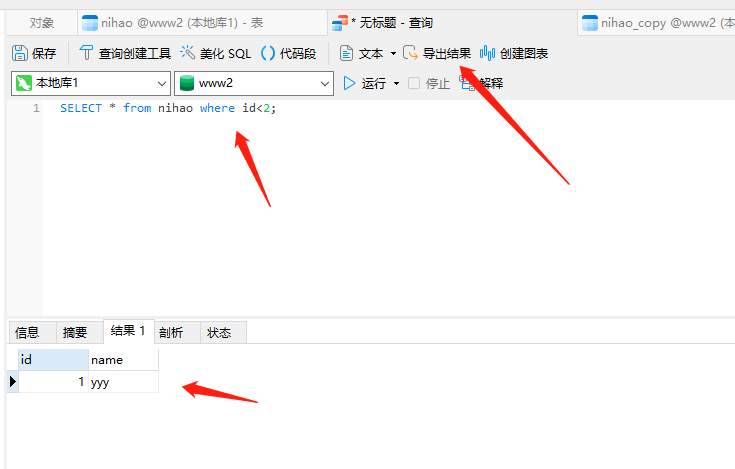
.
选择导出成excel 下一步 生成的excel文件名 指定一下 一路下一步 最后关闭

.
然后就可以把当前的这张表,转储成sql文件---仅结构------这时候最关键的操作来了
千万不要 右键点击当前库或表图标,右键运行,这个转储成仅结构的sql文件,为什么???
会直接把你当前的数据库的该表清空掉,有点危险,所以建议,单独先搞个测试库出来
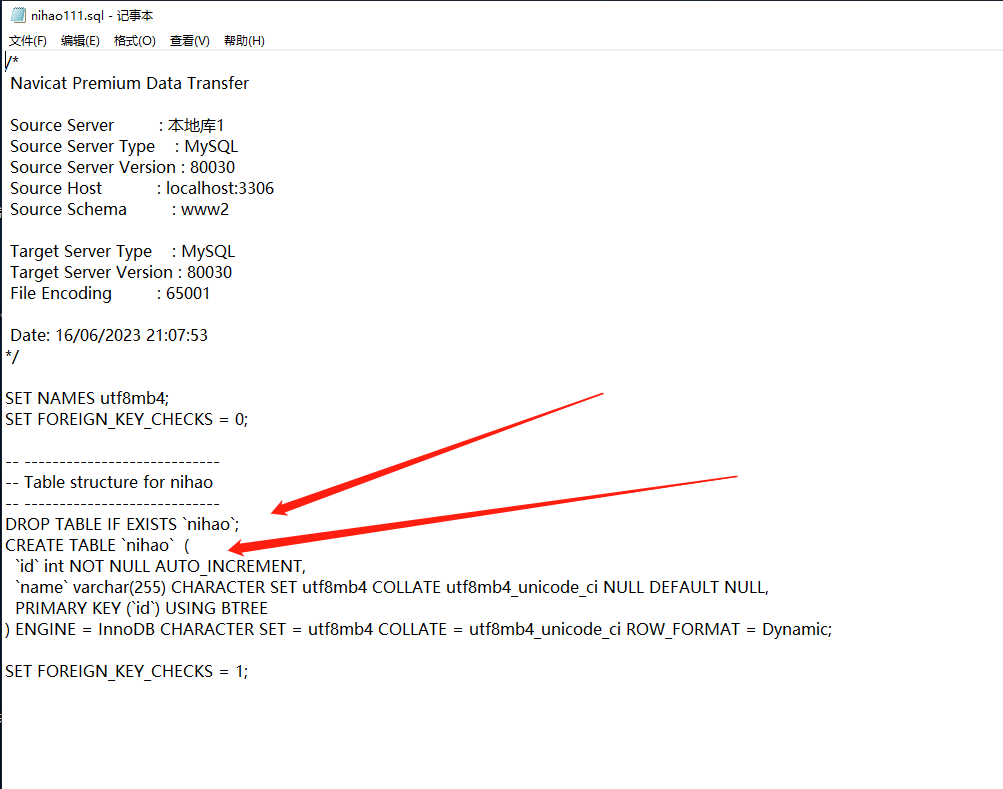
.
然后把这个sql文件里,表名先改下,然后到测试库里面,运行下该转储文件
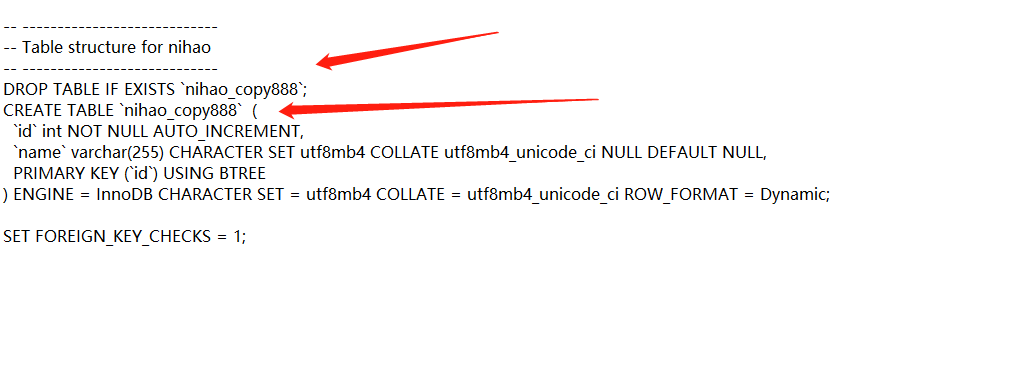
.
没问题了,再把测试库里面的该表转储成sql文件,再到当前库里面执行下,运行该转储的sql文件
最后再导入下,刚刚导出的excel文件,这样你查询出的去年一年的数据就复制到另一张表里面去了!!!
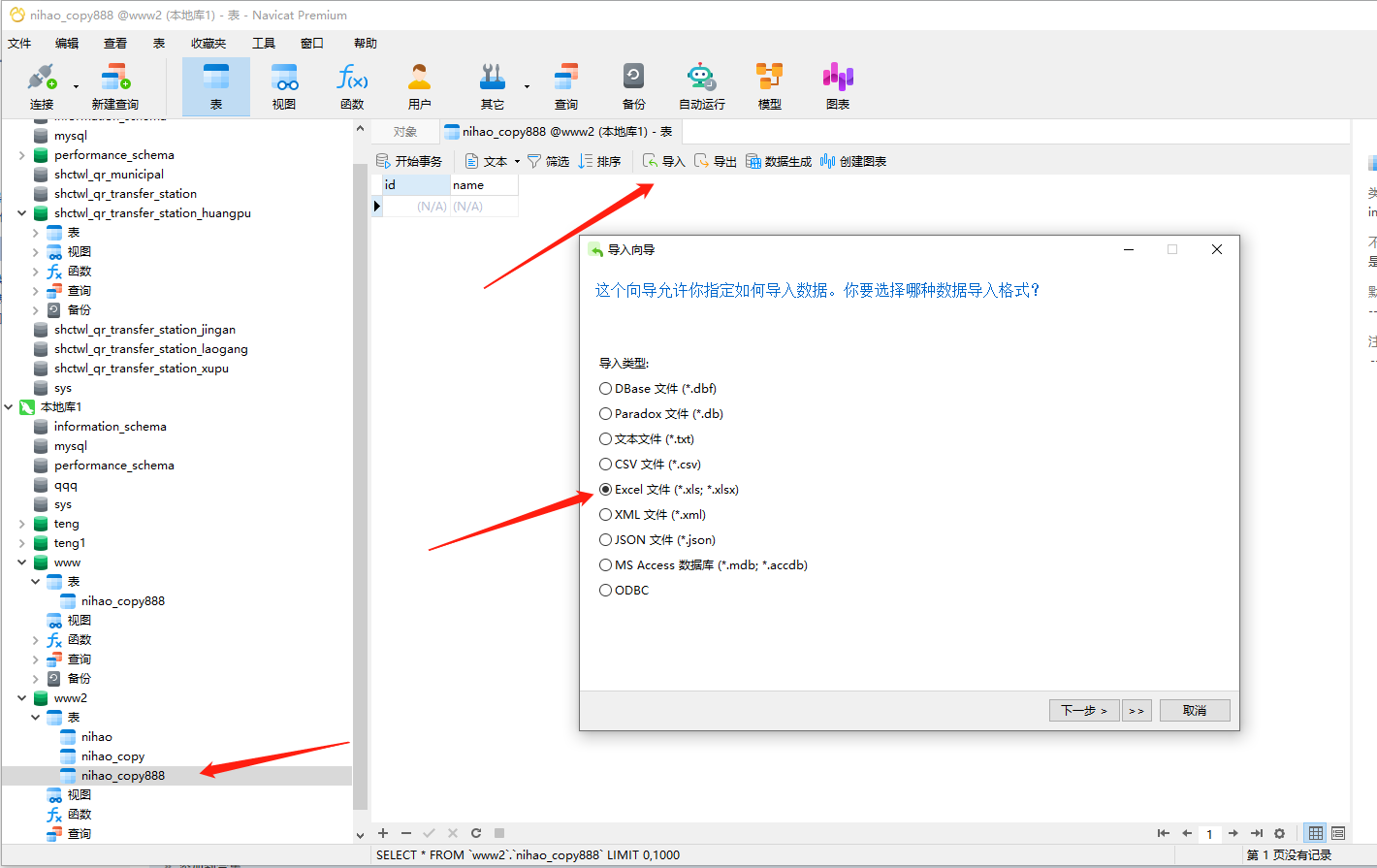
.
一路下一步,excel表里面的数据就导到该表里面去了!!!
.
.
# 最后就是要把当前表里面的已经导出的数据,从当前表里面删掉,还是先稳点,把当前表的数据再转储备份一份
# 然后 delete from 表名 where 条件 删除的过滤条件一定是和开始查询的过滤条件是一样的!!!
# 这样当前表里面去年一年的数据就移到另一张表里面去了,
# 如果开始的时候,想的就是项目不停,那么就可以在写项目的时候,让前端在调用查询接口的时候,
# 根据要查询的年份,是当前年份,调用默认的查询接口,如果查询的不是今年的数据,调用历史数据查询接口
# 这样当前的查询接口,里就可以使用orm语句来进行查询
# 历史数据查询接口,可以用原生的sql语句去查询 !!!
# 这样项目就可以一直不停,我们只要在后端,去按年操作一下数据库,把去年的数据转移一下就行了
# 分出的表的表名就叫 原表名_年份 比如 nihao_2019
# 这样一个查历史数据接口,根据前端传的年份,和原表名_ 拼接一下 就是要查的表了
# 就很方便了!!!
.
.
.
.
.
.
.
.
.
.
分表的代码示范
def create_RecQualityRecognition_with_tablename(table_name):
class DynamicModel(db.Model):
__tablename__ = table_name
__table_args__ = (
db.Index('filtersIndex', 'device_id', 'work_start_time', 'count_detected_pic', 'garbage_type'),
)
id = db.Column(db.BigInteger, primary_key=True)
batch_no = db.Column(db.String(50))
compress_stall_id = db.Column(db.BigInteger)
# 表字段没有全部写
return DynamicModel
# 你想对那个表做分表操作,在模型类里面对应的表模型下面,搞个函数,函数里面就定义一个类
# 然后这个类里面的内容就直接复制上面的模型类里面的内容,把表名改成参数即可
# 这样只要调用该函数,传对应的表名,就可以生成一个和模型表同样字段的类,并且该__tablename__属性等于传入的表名
-----------------------------------------------
-----------------------------------------------
def rolling_rec_quality_recognition_table():
with app.app_context():
current_year = datetime.now().year
create_table_sql:str = db.session.execute('SHOW CREATE TABLE rec_quality_recognition;').fetchall()[0][1]
create_table_sql = create_table_sql.replace('rec_quality_recognition',f'rec_quality_recognition_{str(current_year-1)}')
db.session.execute(create_table_sql)
db.session.execute(f'INSERT INTO rec_quality_recognition_{str(current_year-1)} SELECT * FROM rec_quality_recognition')
db.session.execute('TRUNCATE TABLE rec_quality_recognition;')
db.session.execute('alter TABLE rec_quality_recognition auto_increment=1;')
# 直接改表名可能会造成数据丢失等意外情况
sched = BlockingScheduler()
sched.add_job(rolling_rec_quality_recognition_table,'cron', month=1, day=1, hour=0, minute=0, second=1)
sched.start()
# 搞个定时任务,每年的1月1号0点后,启动任务
# 现在的逻辑是先创一个当前库结构一样,库名加去年年份后缀的一个空库
# 然后把当前表里面的所有数据导入到,新创的空表里面去
# 然后清空截断当前的表
# 为什么不直接将当前库改名,然后再创一个空库名字改成当前库的名字? 直接改表名可能会造成数据丢失等意外情况
-----------------------------------------------
-----------------------------------------------
# 根据前端传的对应的年份,去对应的年份表里面去查找数据
# 大致的逻辑是前端传的year字段对应的值,如果小于当前现在的年份,先判断前端传的对应的年份在不在字典里面,如果在里面,
# 说明已经对应年份表的对象模型已经创建了!!! 就不用再创了,直接拿到对应年份的表模型类
# 如果没创,顺势创一个对应年份的表模型类,并以年份为键加到字典里面去!!!
# 后续的orm查询语句,就
rec_quality_recognition_year_dict = dict() # 生成一个空字典
filters_list = list() # 生成一个空列表
if 'year' in request.json.keys():
current_year = datetime.now().year
year = request.json['year']
if year < current_year:
if year in rec_quality_recognition_year_dict.keys():
RecQualityRecognitionYear = rec_quality_recognition_year_dict[year]
else:
RecQualityRecognitionYear = create_RecQualityRecognition_with_tablename(f'rec_quality_recognition_{year}')
rec_quality_recognition_year_dict[year] = RecQualityRecognitionYear
else:
RecQualityRecognitionYear = RecQualityRecognition
else:
RecQualityRecognitionYear = RecQualityRecognition
# 上面整体就是根据前端传入的year字段对应的数据,最终决定要使用哪个模型类!!!写活了
# 要查哪年的数据,就到对应的年的记录表里面去查!!!
for key in request.json.keys():
if key in ['id'] and request.json[key] != '':
# 这里就是将前端传的id数据转化为过滤条件,然后放到过滤条件的列表里面去!!!
filters_list.append(value_equal_filter(RecQualityRecognitionYear.id,request.json[key]))
elif key in ['device_id'] and request.json[key] != '':
filters_list.append(value_equal_filter(RecQualityRecognitionYear.device_id,request.json[key]))
elif key in ['if_show_ignored_pic'] and type(request.json[key]).__name__ == 'bool':
if_show_ignored_pic = request.json[key]
print(filters_list)
record = db.session.query(RecQualityRecognitionYear,
AssetGarbageTruck,
ConstDistrict,
PlaceBase,
ConstGarbageType,
AssetQrCamera,
NodeObject,
NodeLocation,
BizOrganization,
PlaceCompressStall,
PlaceTransferStation,
SysServer)\
.select_from(RecQualityRecognitionYear)\
.outerjoin(AssetGarbageTruck,RecQualityRecognitionYear.truck_plate_no == AssetGarbageTruck.plate_number)\
.outerjoin(ConstDistrict,AssetGarbageTruck.work_in_district_id == ConstDistrict.id)\
.outerjoin(ConstGarbageType,AssetGarbageTruck.garbage_type == ConstGarbageType.id)\
.outerjoin(AssetQrCamera,RecQualityRecognitionYear.device_id == AssetQrCamera.id)\
.outerjoin(NodeObject,AssetQrCamera.node_object_id == NodeObject.id)\
.outerjoin(NodeLocation,NodeObject.node_location_id == NodeLocation.id)\
.outerjoin(BizOrganization,NodeObject.biz_organization_id == BizOrganization.id)\
\
.outerjoin(PlaceCompressStall,RecQualityRecognitionYear.compress_stall_id == PlaceCompressStall.id)\
.outerjoin(PlaceTransferStation,PlaceCompressStall.tansfer_station_id == PlaceTransferStation.id)\
.outerjoin(PlaceBase,PlaceTransferStation.base_id == PlaceBase.id)\
\
.outerjoin(SysServer,RecQualityRecognitionYear.storage_server_id == SysServer.id)\
\
.filter(*filters_list).one_or_none()
.
.
.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY