ES6入门详解(三) 正则表达式
正则构造函数的变化es5中 正则有两种写法
//es5中下面两种正确写法 const reg1 = new RegExp('abc','i') const reg2 = /abc/i const reg3 = new RegExp(/abc/ig) // => reg3 = /abc/ig //es5中的错误写法 const reg4 = new RegExp(/abc/ig,'i') //上述写法在es5中是错误的 es6中对构造函数进行了重构 上述写法 第二个flag会替换掉原有的ig
u修饰符 utf-8使用双字节 也就是十六个二进制位来表示一个字符 在正则中如果超过双字节 也就是utf-16的四字节 32 二进制位 就无法识别了 es6中增加的u修饰符使用Unicode来处理utf-16 Unicode为全球通用编码可以表示所有的字符
console.log(/^\uD83D/u.test('\uD83D\uDC2A')) // =>false
console.log(/^\uD83D/.test('\uD83D\uDC2A')) // =>true
使用Unicode模式 可以识别四字节 不使用只能识别双字节
Unicode字符表示法
console.log(/^\u{61}/u.test('a'))
y修饰符 粘连模式
const r1 = /a+/g const r2 = /a+/y let str = 'aaa_aa_a' console.log(r1.exec(str)) console.log(r2.exec(str)) console.log(r1.exec(str)) console.log(r2.exec(str))
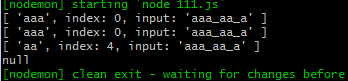
可以看到结果 g修饰符不指定下一次的索引位置 y修饰符下一次的索引位置必须是上一次索引结束字符的下一个 其实y修饰符隐含了^也就是说 y修饰符之后 匹配的字符必须绝对匹配头部 让^在全局生效
es6新增正则实例属性
reg.sticky 用来表示师傅开启了正则模式 result => boolean
reg.source 返回正则表达式 result => string
reg.flags 返回正则表达式的修饰符 result => string
s修饰符 dotAll 就是说s修饰符可以让[.]匹配一切 包括\n \r 换行符
const r1 = /^.$/su console.log(r1.test('\n')) console.log(r1.test('\r')) console.log(r1.test('𠮷'))
上述返回都为true


 浙公网安备 33010602011771号
浙公网安备 33010602011771号