
记一次迭代中历史数据持久化
项目背景:现项目主要是做关于机器人的调度系统,涉及到web端、移动端、小程序及服务端和实体机器人端;
迭代背景:采用的敏捷开发,迭代周期为两周,本次迭代的US为机器人在地图上位置显示及路径显示,主要涉及到地图、设备状态、设备位置、电梯等状态信息展示;
记录方向:记录历史数据持久化的一个过程;
记录时间:20200104,测试阻塞,反补测试功能点及测试用例后;
备注:该方案为项目组中的大佬写的,我偷偷摸摸的搬运过来贴在这儿,方便后续可能会使用到;说实话该方案作为测试的我真没看懂该方案,需要在后续的工作中继续积累才行;
=================以下就是原文
说明
设备需要将所有的轨迹数据进行持久化,以便提供机器人的运动轨迹查询和后续数据分析使用。
数据上报
目前机器人的轨迹随机器人的状态数据一起上报,如下为相关说明:
- 上报方式:MQTT
- 上报频率:1Hz
- 上报Topic:/robot/${device_id}/device/status/put
- 内容简要说明:上报消息主要分为消息头和payload两部分组成。消息头中包含机器人id、序号、发送时间戳和topic主题。payload中包含机器人工作方式、电池信息、机器人位置信息、清洁模式、当前执行的任务、机器人自身状态、系统开机时间、网络配置信息、云平台的接入设置、自动补给信息和告警信息。
由于payload中包含的数据较多,大部分数据变化频率低,机器人仅在该部分数据变化时才上报变化的数据。
持久化方案
数据库选项
数据库采用mongodb 4.2.2进行存储,mongodb采用复制集集群模式部署。
存储策略
- 每台机器人数据先按照上报数据中的时间戳取分钟级在redis中进行缓存,redis存储Key格式:device:${device_id}:status:${时间戳,精度到分} ,redis缓存使用HashMap进行存储,hashMap的key为当前接受到的数据的序列号;
- 数据补全,由于机器人可能仅上报变化的数据,为了保持每条报文的完整性,后端在接收到机器人上报的报文后先根据redis中之前数据的缓存对新收到的数据进行补全,之后再写入到redis缓存中供后续持久化;
- mongodb文档字段说明:
|
字段
|
类型
|
说明
|
|---|---|---|
| device_id | String | 机器人id |
| start_timestamp | Long | 数据包找那个第一条数据的开始时间戳,保留原精度 |
| pack_timestamp | Long | 打包时间,缓存中的分钟级时间戳 |
| context | List<Object> | 报文列表,存储这一分钟内接收到的所有数据包,数据包按序号排序 |
持久化策略
持久化用于将缓存中的数据落盘保存到mongodb中。提供定时持久化和被动持久化两中持久化策略。
- 定时持久化
使用xxl-job提供分布式定时任务,每分钟将该分钟前的记录持计划到数据库中。持久化时使用redis的scan按照通配符获取所有机器需要持计划的数据,之后批量插入mongodb。
- 被动持久化
- 除了定时持久化外,在设备离线1分钟后触发主动持久化操作。延时1分钟可以避免设备因为异常情况出现频繁重启上下线带来的数据持久化风险。延时触发操作可以使用RabbitMQ的延时队列实现。
- 每次后端接收到数据之后触发持久化检查,如果需要持久化就主动进行持久化操作;
- 缓存清理
因为数据暂存于redis缓存中,为了避免缓存异常,需要提供如下相关实现:
- 每个缓存key创建时默认设定30分钟的超时时间(时间可配置),在每次向缓存中插入数据时主动重置缓存的有效期;
- 在每次数据进行持久化后立刻删除缓存key,删除操作使用redis的scan配合通配符方式进行删除;
数据标签
数据标签用于标识数据为同一类业务数据。数据标签为字符串的列表,每一个数据包都可以包含多个不同的标签,标签可以根据不同的业务场景进行添加和查询使用。数据标签以“标签类型_标签标识”的方式命名,类型和标识的取值命名中只能包含小写字母、数字,下划线只作为类型和标识的分隔符出现。标签类型用于区分不同类型的标签,标签标识用于区分当前标签类型下的不同标签。目前已分配的标签类型定义如下:
|
标签类型
|
说明
|
描述
|
|---|---|---|
| path | 路径标签 | 用于将路径划分成不同的分段。 |
路径分段标签
平台在做机器人路径持久化时会按照路径分段策略为同一段路径的数据添加相同的标签。目前路径分段标签的流程图如下:
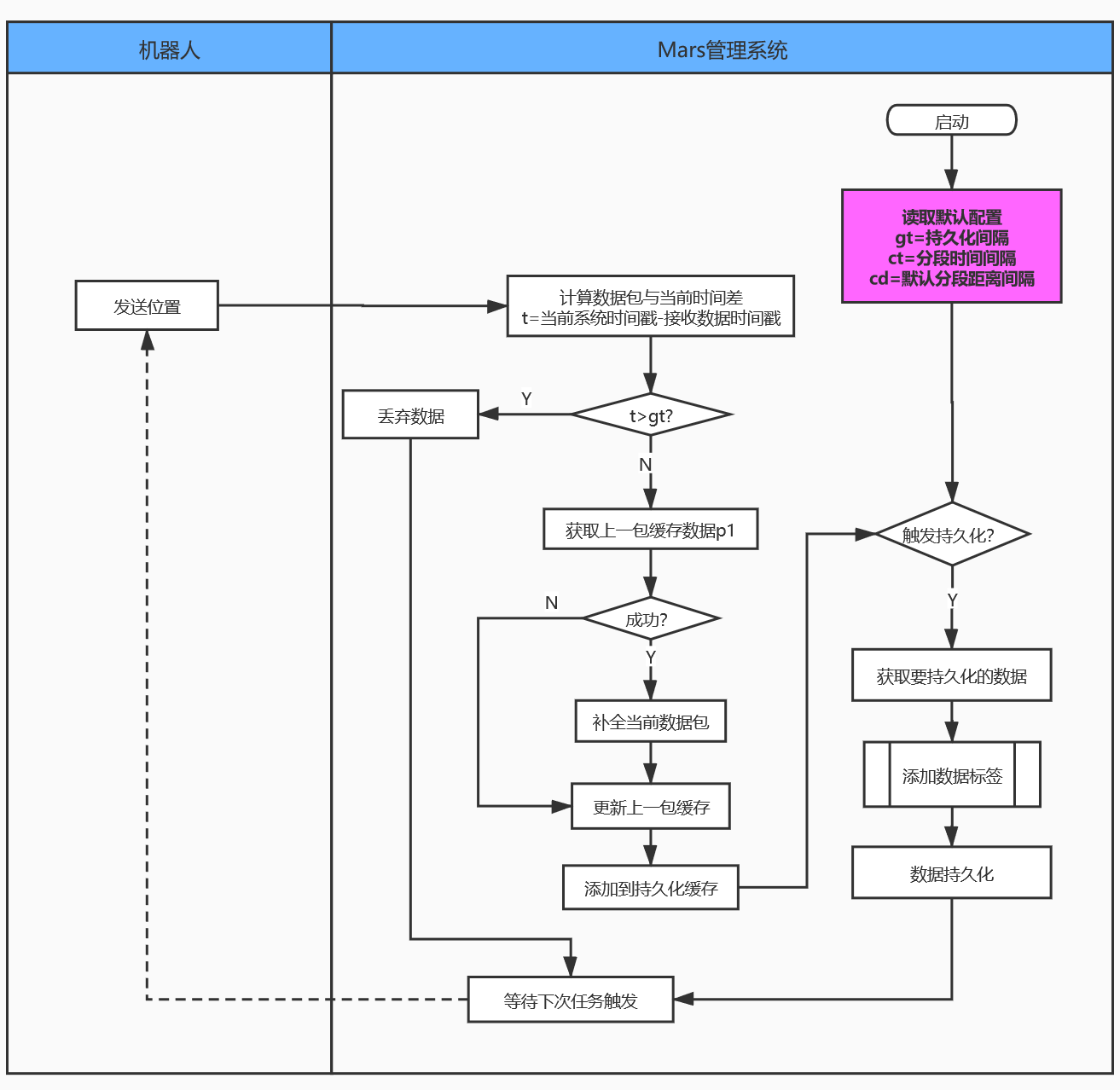
流程说明:
- 平台在首次部署启动时从配置文件获取后续数据添加标签需要的配置,之后配置会在运行过程中按照每个机器人实际上报的数据做动态计算调整;
- 由于考虑多副本部署时的并发消费可能导致短时间服务消费到的数据不一致而造成标签混乱的问题,数据添加标签的操作主要在持久化触发时执行,该部分的数据流向图如下:
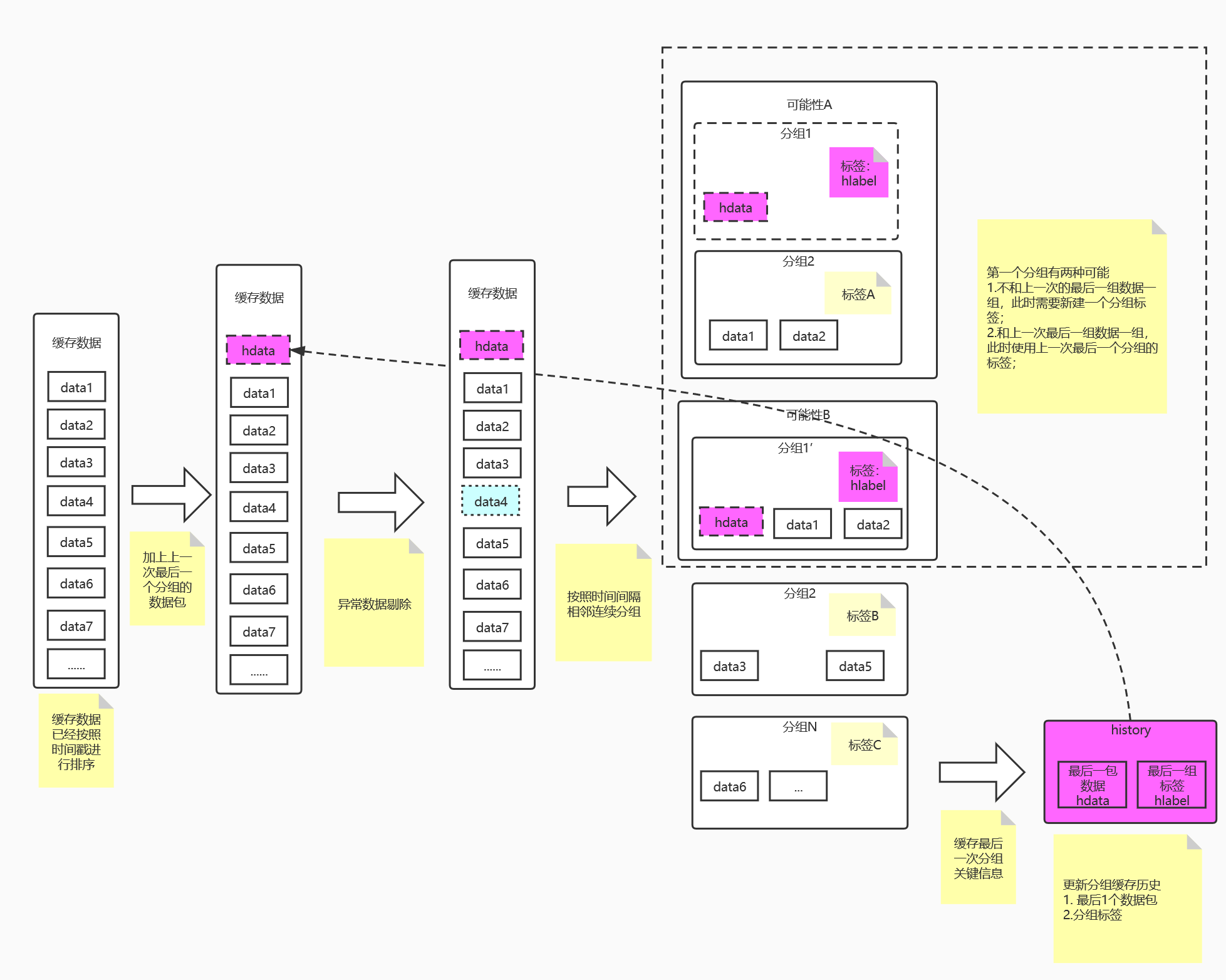
- 步骤1:持久化时先从Redis中取出本次需要持久化的数据并将数据按照时间戳接收时间戳从小到大进行排序;
- 步骤2:在进行完成数据的排序之后获取上一次数据添加标签时最后一个缓存的历史数据信息,将该信息的数据添加到排序后的数据顶部,由此可以保障第二次数据分组时连续的数据和第一组分配到相同的标签,保障数据的连续性,如果没有获取到缓存的分组历史则认为是新的分组;
- 步骤3:对步骤2得到的数据进行异常数据剔除,将其中不和规则的数据剔除,剔除纬度主要依靠和上一个数据点的在一个时间周期内的距离之差,该部分流程设计:
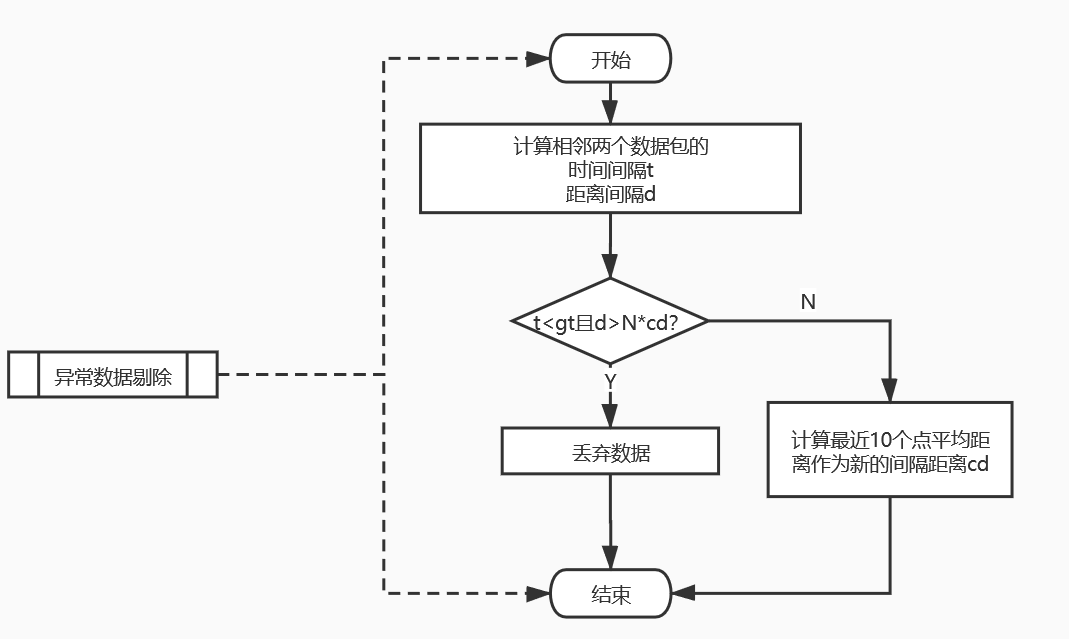
- 步骤4:对步骤3处理后的数据按照“时间间隔相邻连续”的方式进行分组,如果两个数据接收的时间点之差小于gt(gt从配置文件中获取,默认值为1分钟)并且两个点间隔小于N倍cd(N从配置文件获取,默认为1分钟正常上报的位置数据包数;’cd首次部署从配置文件获取,之后在每次数据跳过剔除时根据滑动时间窗口算法计算最近10个点的距离平均值作为最新的cd)则归为同一个路径的数据,将所有数据添加相同标签,否则新建不同的数据标签。注意:第一组数据分组完成后需要将添加的历史缓存数据移除,否则会出现数据点重复!
- 步骤5:在处理完数据标签添加之后将最后一组数据的最后一个数据包的内容和标签更新到分组的历史缓存(步骤2中获取的缓存内容),以备下一次数据分组时使用;
查询方案
数据合并
查询的数据包含持久化到数据库中的数据和在缓存中的数据,数据库中包含了设备历史数据,缓存中包 含最近几分钟设备的实时数据,在获取完成后需要对数据进行合并。
数据压缩
如果按天纬度查询时时间越长数据数据较大,相近时间的坐标点可能差异不大,此时可以对数据进行相似剔除压缩以减少数据量。数据压缩算法可以评估参考使用JTS java库中提供的道格拉斯-普克算法算法。算法相关说明:https://blog.csdn.net/foreverling/article/details/78066632

