

python+request+excel实现接口自动化
一、说明
该接口自动化测试时基于python+requests库+excel进行实现的,没有选用python+requests+uniitest+htmltestrunner或者python+requests+pytest+htmltestrunner框架:这两个框架的好处整个框架结构全部都封装好了,只需要往里面添加业务逻辑即接口测试py文件即可,但是有个致命的缺陷,就是测试用例的易维护性不是很好,当接口发生变化,就要去直接修改业务逻辑的py文件,而且测试数据都是写死在每一个函数中,或者持久化在数据库中,需要直接修改py文件,所以就没有才这两个框架,只选取了其中必要的组成部分:python+requests,然后自己完成后续业务逻辑;
二、接口测试框架的拆解
现有框架是根据HTTP请求的请求、响应的生命周期来进行规划框架的目录结构的;
1、HTTP请求的生命周期
1.1、建立连接;
1.2、接收请求;
1.3、处理请求;
1.4、访问资源;
1.5、构建响应;
1.6、发送响应;
1.7、记录事务处理过程;
2、框架目录结构
2.1、base包:封装请求方法
base包下new_test.py文件,主要用于封装常规的请求方法;
http请求方式中主要有8种常见的请求方式:GET,POST,HEAD,OPTIONS,PUT,DELETE,TRACE,CONNECT方法,这几种请求方式详细使用方式请自行百度;
我只封装了其中最常见的四种方式:GET,POST,DELETE,PUT方式,因为项目中只用到了这四种方式;
new_test.py:


1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 import requests,json 4 ##原主程序:将data及headers的为空的情况考虑进去,就会报错404 5 class Runmethod: 6 ###get方法不会有data,查询参数都是跟在url后面的;需要后再进行优化; 7 def getmain(self,url,data=None,headers=None): 8 res = None 9 if headers !=None: ####正常的get请求; 10 if data == None: 11 res = requests.get(url=url, headers=headers) 12 else: 13 res = requests.get(url=url, data=data, headers=headers) 14 15 else: ##非常规的get请求,如本身是get请求,为了保证数据的安全性直接使用get方法,将原本卸载url中的参数全部写在data里面; 16 if data == None: 17 res = requests.get(url=url) 18 else: 19 res = requests.get(url=url, data=data) 20 return res 21 22 def postmain(self,url,data=None,headers=None): 23 res = None 24 if headers !=None: ####正常的post请求; 25 if data ==None: 26 res = requests.post(url=url,headers=headers) 27 else: 28 res = requests.post(url=url, data=data, headers=headers) 29 else: ##非常规的post请求,如本身是get请求,为了保证数据的安全性直接使用post方法,将原本卸载url中的参数全部写在data里面; 30 if data == None: 31 res = requests.post(url=url) 32 else: 33 res = requests.post(url=url,data=data) 34 return res 35 def runmain(self,method,url,data=None,headers=None): 36 res = None 37 if method == "GET": 38 res = self.getmain(url,data=None,headers=None) 39 elif method == "POST": 40 res = self.postmain(url,data=None,headers=None) 41 return res 42 ##测试类:只考虑正常情况,不考虑空值, 43 class Runmethod2: 44 def getmain(self,url,data,headers): 45 res = requests.get(url=url, data=data, headers=headers) 46 return res 47 def postmain(self,url,data,headers): 48 res = requests.post(url=url, data=data, headers=headers) 49 return res 50 def runmain(self,method,url,data,headers): 51 res = None 52 if method == "GET": 53 res = self.getmain(url, data, headers) 54 elif method == "POST": 55 res = self.postmain(url, data, headers) 56 return res 57 58 ##只考虑data是否是未空,前两种方式在调试过程中有问题; 59 class Runmethod3: 60 ###get请求方式 61 def getmain(self,url,headers = None): 62 res = None 63 if headers !=None: 64 res = requests.get(url=url,headers = headers) 65 else: 66 res = requests.get(url=url) 67 return res.json() 68 ##post请求方式 69 def postmain(self,url,data=None,headers=None): 70 res = None 71 if headers != None: 72 res = requests.post(url=url,data=data, headers=headers) 73 else: 74 res = requests.post(url=url,data=data) 75 return res.json() 76 def putmain(self,url,data=None,headers =None): 77 res = None 78 if headers != None: 79 res = requests.post(url=url, data=data, headers=headers) 80 else: 81 res = requests.post(url=url, data=data) 82 return res.json() 83 def deletemain(self,url,data=None,headers = None): 84 res = None 85 if headers != None: 86 res = requests.delete(url=url,data = data, headers=headers) 87 else: 88 res = requests.delete(url=url, data=data) 89 return res.json() 90 91 def runmain(self,method,url,data=None,headers=None): 92 res = None 93 if method == "GET": 94 res = self.getmain(url,headers = headers) 95 elif method == "POST": 96 res = self.postmain(url, data=data, headers=headers) 97 # return json.dumps(res,indent=2,ensure_ascii=False) 98 elif method == "PUT": 99 res = self.putmain(url,data=data,headers=headers) 100 print(type(res)) 101 elif method == "DELETE": 102 res = self.deletemain(url,data=data,headers=headers) 103 return json.dumps(res,indent=2,ensure_ascii=False)
2.2、main包:主程序执行入口
根据读取到的测试用例excle表中相关字段的信息进行判断进行相关的处理;
2.2.1、获取到整个测试用例excel表,取到每行数据即每一条测试用例,取到每条测试用例中的每个字段,然后根据每个字段的相关信息执行每条用例;
2.2.2、主程序执行:判断是否执行-判断是否有依赖-判断依赖类型,根据依赖类型执行不同的方法-获取到正确的依赖数据后执行用例-获取响应报文与与预期结果对比,回写测试执行结果-最后检查是否需要清除测试数据-发送测试报告给对应人员;
#!/usr/bin/env python # -*- coding:utf-8 ###下面添加系统路径是因为代码部署在服务器上、在windows cmd命令行下运行报错提示找不到models添加的; import os,sys base_dir = os.path.dirname(os.path.abspath(__file__)) base_dir_file = os.path.dirname(base_dir) sys.path.append(base_dir) sys.path.append(base_dir_file) sys.path.append(os.path.abspath(__file__)) # print(sys.path) print(base_dir,base_dir_file) # import sys # import os # # curPath = os.path.abspath(os.path.dirname(__file__)) # rootPath = os.path.split(curPath)[0] # PathProject = os.path.split(rootPath)[0] # sys.path.append(rootPath) # sys.path.append(PathProject) """ # 导入绝对路径""" # sys.path.append("D:/untitled/autotest") # sys.path.append("D:/untitled/autotest/utils") print(sys.path) from base.new_test import Runmethod,Runmethod2,Runmethod3 from data.get_data import getdata import json from utils.common import * from utils.op_excel import Oper_excel from data.data_config import global_var from data.depend_data import depentdata from utils.send_email import sendemail1,sendemail2 from utils.op_database import database_handler from utils.op_file import op_file_handle ###按照此时的写法post是通了,但是get报错了,get返回的是html文件,而程序是用json去解析的 class runtest: def __init__(self): self.run_method = Runmethod3() self.data = getdata() self.obj_iscomtent = commonutil() self.obj_op_excel = Oper_excel() self.obj_sendemail = sendemail1() self.obj_sendemail2 = sendemail2() self.obj_file_handle =op_file_handle() # print("========================================>>>>这是op_excel实例化打印的路径:%s" %self.obj_op_excel) ##主程序执行 def run(self): result = [] total_run = 0 pass_count = [] fail_count = [] #统计接口测试用例数量 print("===================>>>主程序开始执行") row_counts = self.data.get_case_Lines() print("================>>>>测试用例总计:%s <<<<======================" %(row_counts-1)) ###for循环下直接return是有坑的,在第一次循环的时候就直接返回了,没有进行后续的循环; for i in range(1,row_counts): url = self.data.get_url(i) mehtod = self.data.get_request_method(i) data = self.data.get_request_datajson(i) # print("=====================???",data) # if data != None: # data = json.dumps(data) # data = self.data.get_request_datajson(i) headers = self.data.header_is_run(i) ###判断是否运行 is_run = self.data.get_is_run(i) expect = self.data.get_expect_data(i) depend_type = self.data.get_depeed_type(i) print("执行%s条用例" %i,url,mehtod,data,is_run) # print(headers) ###判断接口用例是否执行 if is_run: total_run+=1 ###判断执行接口用例是否需要依赖数据 # depend_case_id = self.data.is_depend(i) depend_case_id = self.data.get_depend_id(i) print("=========!!!!!!!依赖id",depend_case_id) if depend_case_id != None: ##获取依赖的响应数据 # try: # self.obj_dependdata = depentdata(self.data.get_depend_id(i)) # depend_response = self.obj_dependdata.get_dependentdata(i) # except Exception as e: # print("========>>>执行第%s条依赖用例失败,请检查依赖用例\r\n %s" %(i,e)) ###获取数据依赖的key self.obj_dependdata = depentdata(self.data.get_depend_id(i)) depend_response = self.obj_dependdata.get_dependentdata(i) print("============>>我正在打印依赖用例的响应报文", depend_response) depend_key = self.data.get_depend_field(i) ###根据依赖类型进行依赖数据处理 """ 依赖数据可能会存在以下几种方式:1、header中依赖,如token;2、请求body中的参数依赖; 现在写的逻辑是直接认为是body依赖,没有考虑header依赖,我现在座的就是header依赖 """ if depend_response != None: access_type = "Bearer" ###header_depend需要依赖登录接口,获取token if depend_type == "header_depend": ####header依赖数据的处理逻辑,因为我的系统header依赖为token,所以我就直接做的token依赖处理 token = access_type + depend_response print("===============>>>这是token",token) headers[depend_key] = token ###将登录获取到的token写入到cfg.py文件中 self.obj_file_handle.write_file_token_handler(token) elif depend_type == "body_depend": pass elif depend_case_id == None: if depend_type == "header_depend_token": # headers[depend_key] = self.obj_file_handle.read_file_token_handler() headers[depend_key] = self.obj_file_handle.read_file_handler("Authorization") print(headers[depend_key]) print("++++++++++++++header_depend_token分支的这是处理依赖后的headers:",headers) # res = self.run_method.runmain(mehtod,url,data,headers) ###判断请求方式,根据请求方式执行请求想 # if mehtod == "GET": # res = self.run_method.runmain(mehtod,url) # elif mehtod == "POST": # res = self.run_method.runmain(mehtod, url, json.dumps(data), headers) res = self.run_method.runmain(mehtod,url, data = json.dumps(data), headers = headers) print("==========>>>>:这是返回的报文类型:",type(res)) if self.obj_iscomtent.iscomtent(expect,res): # print("测试通过") self.data.write_exact_res(i,'pass') pass_count.append(i) print("********************这是在清理测试数据是否执行sql语句", self.data.get_clean_testdata(i)) if self.data.get_clean_testdata(i) == "YES": clean_sql = self.data.get_clean_sql(i) print("================>>>>这是需要执行的sql语句",clean_sql,type(clean_sql)) ##执行sql语句 if clean_sql != "None": try: obj_database_hendler = database_handler() sql_excute_res = obj_database_hendler.cleantestdata(clean_sql) print("=====================>>>>这是执行的sql的结果:",sql_excute_res) ###写入清除数据sql执行结果 self.data.write_sql_excute_res(i, sql_excute_res) except Exception as e: self.data.write_sql_excute_res(i, e) else: # print("测试失败") self.data.write_exact_res(i,res) fail_count.append(i) result.append(res) # print(res.text) ###清除测试数据 ###获取是否需要清除测试数据 # return json.dumps(res.json(),ensure_ascii=False,indent=2) print("========测试通过的测试用例数量:%s" %len(pass_count)) print("========测试失败的测试用例数量:%s" %len(fail_count)) print("========总计执行的测试用例数量:%s" %total_run) print("========总计未执行测试用例数量:%s" %(row_counts-1-total_run)) print("========总计测试用例数量:%s" %(row_counts-1)) # print(pass_count,fail_count) try: self.obj_sendemail2.send_main(pass_count,fail_count) except Exception as e: print("========================》》》发送测试邮件失败,请检查网络配置:%s" %e) return result if __name__ == "__main__": print("===============================>>>>>>当前执行路径:%s" %os.path.abspath(__file__)) print("=======================?????执行shell命令:%s" %os.popen("pwd").read()) print("=======================?????执行shell命令:%s" %os.popen("cd ..").read()) print("=======================?????执行shell命令:%s" %os.popen("pwd").read()) obj_run = runtest() res = obj_run.run() # for i in res: # print(i)
2.3、utils包:工具包,用于存放操作类方法
2.3.1、common.py主要是用于判断预期结果与实际结果是否一致及根据业务需要编写特定逻辑类;
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 ###检查接口是否正确,并检查响应报文是否正确 4 class commonutil: 5 def iscomtent(self,str_one,str_two): 6 """ 7 判断一个参数是否在另一个参数中 8 str_one:查找参数 9 str_two:被查找参数 10 """ 11 flag = None 12 ##可以对str_one进行数据格式的验证 13 if str_one in str_two: 14 flag = True 15 else: 16 flag = False 17 return flag 18 19 if __name__ == "__main__": 20 a = "a" 21 b = "adb" 22 res = commonutil().iscomtent(a,b) 23 print(res)
2.3.2、op_database.py主要是用于数据库操作用于检查测试数据是否正确,以及清除测试数据;
该类直接使用的原生sql语句
1 ####主要用户数据库操作 2 import pymysql 3 ###清除测试数据 4 class database_handler: 5 ###实例化就连接数据库并获取游标当前位置 6 def __init__(self): 7 self.conn = pymysql.connect(host='*****', port=3306, user='****', passwd='*****..', db='*****') 8 ###游标,当前位置 9 self.cursor = self.conn.cursor() 10 ###清除测试数据 11 # def cleantestdata(self,table,feild,data): 12 # try: 13 # sql = "delete from %s where %s = '%s'" %(table,feild,data) 14 # # sql = "delete from tbl_user where user_name = 'autotest002'" 15 # print(sql) 16 # res=self.cursor.execute(sql) 17 # self.conn.commit() 18 # print(res) 19 # except Exception as e: 20 # print(e) 21 # self.conn.close() 22 23 def cleantestdata(self, sql_list): 24 res ="" 25 try: 26 # sql = "delete from %s where %s = '%s'" % (table, feild, data) 27 # sql = "delete from tbl_user where user_name = 'autotest002'" 28 for sql in eval(sql_list): 29 result = self.cursor.execute(sql) 30 print("========>>>这是SQL语句的详细情况" ,sql) 31 self.conn.commit() 32 res = "====================>>清除测试数据成功:%s" %result 33 except Exception as e: 34 res = e 35 self.conn.close() 36 return res 37 38 if __name__ == "__main__": 39 # sql = ["update tbl_user set `enable`= 1 where id = 585"] 40 sql = ["delete from tbl_robot where robot_id = '12345678901234567890'","delete from tbl_user_robot where robot_id = '12345678901234567890';"] 41 42 print(type(sql)) 43 obj= database_handler() 44 print(obj.cleantestdata(sql))
2.3.3、op_excel.py主要用于操作excel表-用例表,读取数据以及写入测试数据
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 import xlrd 4 from xlutils.copy import copy 5 from data.data_config import * 6 class Oper_excel: 7 def __init__(self,data_path=None): 8 if data_path: 9 self.data_path = data_path 10 self.data_sheet = 0 11 else: 12 self.data_path = "../data_file/auto_test_case.xls" 13 self.data_sheet = 0 14 self.data = self.get_excel_data() 15 #读取excel表的数据 16 def get_excel_data(self): 17 # print(self.data_path,self.data_sheet) 18 book = xlrd.open_workbook(self.data_path) 19 # sheet = book.sheet_by_index(self.data_sheet) 20 sheet = book.sheet_by_index(self.data_sheet) 21 # for i in sheet.get_rows(): 22 # print(i) 23 return sheet 24 ###获取单元格行数 25 def get_line(self): 26 tables = self.data 27 return tables.nrows 28 # return tables.ncols 29 ###获取某个单元格的内容 30 def get_cell_value(self, row, col): 31 return self.data.cell_value(row, col) 32 ###写入实际结果:就是修改excel表格 33 def update_data(self,row,col,value): 34 """ 35 写入excel表数据 36 :param row: 37 :param col: 38 :param value: 39 :return: 40 """ 41 book = xlrd.open_workbook(self.data_path) 42 # sheet = book.sheet_by_index(self.data_sheet) 43 pre_data = copy(book) 44 sheet_data = pre_data.get_sheet(self.data_sheet) 45 sheet_data.write(row,col,value) 46 pre_data.save(self.data_path) 47 ###根据caseid查找对应行的内容 48 def get_row_data(self,caseid): 49 row_num = self.get_row_num(caseid) 50 return self.get_row_values(row_num) 51 ###根据对应的caseid找到对应的行号 52 def get_row_num(self,caseid): 53 num = 0 54 colsdata = self.get_col_data() 55 # print(colsdata) 56 for coldata in colsdata: 57 if caseid in coldata: 58 return num 59 num+=1 60 ##获取某一列的内容 61 def get_col_data(self,colid=None): 62 if colid !=None: 63 cols = self.data.col_values(colid) 64 else: 65 cols = self.data.col_values(0) 66 return cols 67 68 ##根据行号找到该行的内容 69 def get_row_values(self,row): 70 tables = self.data 71 row_data =tables.row_values(row) 72 return row_data 73 74 #excel表写入数据 75 # print(Oper_excel) 76 if __name__ == "__main__": 77 data = Oper_excel() 78 print(data.get_line(),type(data.get_line())) 79 for i in range(data.get_line()): 80 print(i,data.get_cell_value(i,get_case_expect())) 81 print(data.get_row_data("web_api_002"))
####处理配置文件 class op_file_handle: def __init__(self,data_path=None,para=None): if data_path: self.data_path = data_path else: self.data_path = "../data/" if para: self.para = para else: self.para = "cfg.text" def write_file_token_handler(self,token): ###将配置文件读取出来 src_f = open(self.data_path+self.para,'r',encoding="utf-8") comtent = src_f.readlines() src_f.close() ###修改配置文件 dst_f = open(self.data_path+self.para,'w',encoding="utf-8",newline="") for data in comtent: if data.startswith("Authorization"): # dst_f.write(re.sub("Authorization = \d","Authorization ="+token,data,0)) data_split = data.split("=") data_split[1] = token print("========>>>这是写入的token",data_split[1]) dst_f.write("%s = %s\n" %(data_split[0].strip(),data_split[1].strip())) else: dst_f.write(data) dst_f.close() ###读取token配置文件,对token的处理 def read_file_token_handler(self): with open(self.data_path+self.para,'r',encoding="utf-8") as f: for data in f.readlines(): if data.startswith("Authorization"): data_split = data.split("=") print(data_split[1].strip()) return data_split[1].strip() ###依次读取配置文件,处理配置文件信息 def read_file_handler(self,para): with open(self.data_path+self.para,'r',encoding="utf-8") as f: for data in f.readlines(): if data.startswith(para): data_split = data.split("=") # print(data_split[0].strip(),data_split[0].strip()) return data_split[1].strip() ###读取邮件要发送的附件; class op_excel_handle: def __init__(self, data_path=None, para=None): if data_path: self.data_path = data_path else: self.data_path = "../data_file/" if para: self.para = para else: self.para = "auto_test_case.xls" ###读取邮件需要发送的附件 def read_file_email_handler(self): with open(self.data_path+self.para,'rb') as f: cont = f.read() return cont if __name__ == "__main__": obj_op_file_handle= op_file_handle() # obj_op_file_handle.write_file_handler("测试写入") obj_op_file_handle.read_file_token_handler()
2.3.5、op_json.py:主要是用于操作json文件;json文件主要是存放请求body地方,存放格式是json格式
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 import json 4 class data_read_handle: 5 def __init__(self,data_path=None,para=None): 6 if data_path: 7 self.data_path = data_path 8 else: 9 self.data_path = "../data_file/" 10 if para: 11 self.para = para 12 else: 13 self.para = "usermanagement.json" 14 self.data = self.json_data_read() 15 def json_data_read(self): 16 f = open(self.data_path+self.para,encoding='utf-8') 17 data = f.read() 18 data = json.loads(data) 19 # print(type(data)) 20 f.close() 21 # f = open(self.data_path+self.para) 22 # data = json.load(f) 23 return data 24 ###重写json文件 25 # def json_data_reload(self,data): 26 # f = open(self.data_path+self.para,"w",encoding="utf-8") 27 # json.dump(data,f,ensure_ascii=False,indent=4) 28 def taskmanagement_data_read(self): 29 pass 30 ##根据参数获取对应的body 31 def get_data_read(self,para): 32 if para == None: 33 return None 34 return self.data[para] 35 36 if __name__ == "__main__": 37 data_read_handler= data_read_handle() 38 print(data_read_handler.data["login"])
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 """ 4 邮件发送中的坑:qq可以向qq及163邮箱发送邮件; 5 163向qq发送邮件会被邮件服务器退回,可能原因是qq邮箱在接收邮件的时候按照某种规则进行校验处理了的; 6 而且一定要小心过期教程的坑; 7 后期可对邮件发送的类进行重新整合,将两个类合并为一个类,做兼容性的处理; 8 """ 9 import smtplib ###发送邮件的库 10 from email.mime.text import MIMEText ###邮件格式的库 11 import time 12 from exchangelib import DELEGATE, Account, Credentials, Message, Mailbox, HTMLBody,FileAttachment 13 import os 14 """ 15 1、sendemail1:使用的是smtplib库,可用于常规邮箱如qq、163邮箱的邮件发送; 16 2、sendemail2:使用的是exchangelib库,可以用来发送小众邮箱如公司级的邮箱的邮件发送; 17 """ 18 from utils.op_file import op_file_handle,op_excel_handle 19 class sendemail1: 20 def __init__(self): 21 pass 22 ##发送邮件 23 global send_user,email_host,password 24 send_user = "tengjiang@countrygarden.com.cn" 25 # email_host = "smtp.countrygarden.com.cn" 26 email_host = "smtp-mail.outlook.com" 27 ###授权密码 28 password = "654#@!qaz1" 29 def send_mail(self,user_list,sub,content): ###接收邮件的用户list;主题;内容 30 user = "我有才2号"+"<"+send_user+">" 31 message = MIMEText(content,_subtype='plain',_charset='utf-8') 32 message['Subject'] = sub 33 message['From'] = user 34 message['To'] = ";".join(user_list) 35 ##连接邮件服务器 36 try: 37 server = smtplib.SMTP() 38 server.connect(email_host) 39 server.login(send_user,password) 40 server.sendmail(user,user_list,message.as_string()) 41 server.close() 42 print("发送邮件成功") 43 except smtplib.SMTPException as e: 44 print(e) 45 def send_main(self,pass_list,fail_list): 46 now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) 47 pass_num = len(pass_list) 48 fail_num = len(fail_list) 49 count_num = pass_num+fail_num 50 pass_rate = "%.2f%%" %(pass_num/count_num*100) 51 fail_rate = "%.2f%%" %(fail_num/count_num*100) 52 # user_list = ["18502337958@163.com", "309072057@qq.com"] 53 user_list = ["yeweichao@countrygarden.com.cn"] 54 sub = "这是我司测试部关于线上环境接口监测情况报告" 55 content ="%s 此次运行接口测试用例总计:%s,通过用例:%s,失败用例:%s,通过率为:%s,失败率为:%s" %(now,count_num,pass_num,fail_num,pass_rate,fail_rate) 56 self.send_mail(user_list,sub,content) 57 class sendemail2: 58 def __init__(self): 59 self.obj_op_file_handle = op_file_handle() 60 self.obj_op_excel_handle = op_excel_handle() 61 62 ###发送邮件 63 def send_email(self, to, subject, body): 64 creds = Credentials( 65 # username='tengjiang@countrygarden.com.cn', 66 # password='654#@!qaz1' 67 username=self.obj_op_file_handle.read_file_handler("username"), 68 password = self.obj_op_file_handle.read_file_handler("password") 69 ) 70 account = Account( 71 # primary_smtp_address='tengjiang@countrygarden.com.cn', 72 primary_smtp_address = self.obj_op_file_handle.read_file_handler("sender"), 73 credentials=creds, 74 autodiscover=True, 75 access_type=DELEGATE 76 ) 77 m = Message( 78 account=account, 79 subject=subject, 80 body=HTMLBody(body), 81 to_recipients=[Mailbox(email_address=to)] 82 ) 83 ###邮件附件 84 # with open(os.path.abspath(r"../data_file/auto_test_case.xls"), "rb") as f: 85 # with open(r"../data_file/auto_test_case.xls", "rb") as f: 86 cont = self.obj_op_excel_handle.read_file_email_handler() 87 attch_file = FileAttachment(name = "auto_test_case.xls",content=cont) 88 m.attach(attch_file) 89 m.send() 90 ##生成发送内容并发送邮件 91 def send_main(self, pass_list, fail_list): 92 now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) 93 pass_num = len(pass_list) 94 fail_num = len(fail_list) 95 count_num = pass_num + fail_num 96 pass_rate = "%.2f%%" % (pass_num / count_num * 100) 97 fail_rate = "%.2f%%" % (fail_num / count_num * 100) 98 # user_list = ["18502337958@163.com", "309072057@qq.com"] 99 # send_list = ["tengjiang@countrygarden.com.cn", "179984387@qq.com", 100 # "18502337958@163.com"] 101 # "yeweichao02@countrygarden.com.cn", 102 send_list = eval(self.obj_op_file_handle.read_file_handler("recv_list")) 103 subject = "这是我司测试部关于线上环境接口监测情况报告" 104 body = "%s 此次运行接口测试用例总计:%s:\r\n通过用例:%s;\r\n失败用例:%s;\r\n通过率为:%s;\r\n失败率为:%s;" \ 105 % (now, count_num, pass_num, fail_num, pass_rate, fail_rate) 106 for send_to in send_list: 107 self.send_email(send_to, subject, body) 108 109 110 if __name__ == "__main__": 111 sen = sendemail2() 112 sen.send_main([1,2,3,4],[8,5,7,8])
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 from utils.op_json import data_read_handle 4 class global_var: 5 case_id = 0 ##用例编号 6 case_model = 1 ##测试模块 7 case_pre = 2 ##请求前置条件 8 case_urlpath = 3 ##请求URL 9 case_method = 4 ##请求方式 10 case_run = 5 ##接口是否运行 11 case_msg = 6 ##接口备注说明 12 case_header = 7 ##请求头数 13 case_depend_type = 8 14 case_dependid = 9 ##依赖caseID 15 case_dependdata = 10 ##依赖数据 16 case_dependfileld = 11 ##依赖数据所属字段 17 case_dataid = 12 ##请求数据 18 case_expect = 13 ##预期结果 19 case_exact = 14 ##实际结果 20 case_clean_testdata = 15 ### 是否清除测试数据 ###由于系统做的都是逻辑删除; 21 case_clean_sql = 16 22 case_is_sql_success = 17 ###获取执行结果 23 ###获取每一条接口测试用例的每个字段 24 def get_case_id(): 25 return global_var.case_id 26 def get_case_model(): 27 return global_var.case_model 28 def get_case_pre(): 29 return global_var.case_pre 30 def get_case_urlpath(): 31 return global_var.case_urlpath 32 def get_case_method(): 33 return global_var.case_method 34 def get_case_run(): 35 return global_var.case_run 36 def get_case_msg(): 37 return global_var.case_msg 38 def get_case_header(): 39 return global_var.case_header 40 def get_case_depend_type(): 41 return global_var.case_depend_type 42 def get_case_dependid(): 43 return global_var.case_dependid 44 def get_case_dependdata(): 45 return global_var.case_dependdata 46 def get_case_dependfileld(): 47 return global_var.case_dependfileld 48 def get_case_dataid(): 49 return global_var.case_dataid 50 def get_case_expect(): 51 return global_var.case_expect 52 def get_case_exact(): 53 return global_var.case_exact 54 def get_case_headers_data(): 55 # data_headers = { 56 # "Host": "10.8.202.148:10084", 57 # "Connection": "keep-alive", 58 # # "Content-Length": "81", 59 # "Accept": "*/*", 60 # "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36", 61 # "Content-Type": "application/json", 62 # # "Origin": "http://10.8.202.148:10000", 63 # # "Referer": "http://10.8.202.148:10000/robot-management/login.html", 64 # "Accept-Encoding": "gzip, deflate", 65 # "Accept-Language": "zh-CN,zh;q=0.9", 66 # # "Authorization": "Bearer 22db77cb-9647-448c-923f-8b3c7e8e576e" 67 # } 68 obj_op_json = data_read_handle(para="header.json") 69 print(obj_op_json.json_data_read()) 70 data_headers = obj_op_json.get_data_read(para="normal_headers") 71 return data_headers 72 def get_case_clean_testdata(): 73 return global_var.case_clean_testdata 74 def get_case_clean_sql(): 75 return global_var.case_clean_sql 76 def get_is_sql_success(): 77 return global_var.case_is_sql_success 78 if __name__ == "__main__": 79 print(get_case_headers_data())
2.4.2、depend_data.py:主要用处理测试依赖数据,测试依赖数据:依赖类型、依赖ID(依赖哪一条用例)、依赖数据(匹配的模式)、依赖数据所属字段(是哪个字段需要依赖数据);该py文件主要用于执行依赖用例,然后对依赖用例的响应报文进行解析获取依赖数据;将依赖的内容获取到拼接到依赖的地方;
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 from utils.op_excel import Oper_excel 4 from data.get_data import getdata 5 import json 6 from base.new_test import Runmethod3 7 from jsonpath_rw import jsonpath,parse 8 from utils.common import commonutil 9 class depentdata: 10 """ 11 通过caseid去获取整航数据 12 """ 13 def __init__(self,caseid): 14 self.caseid = caseid 15 self.opexcel = Oper_excel() 16 self.data = getdata() 17 self.run = Runmethod3() 18 19 ###根据caseid去获取该caseid的整行数据 20 def get_case_line_data(self): 21 return self.opexcel.get_row_data(self.caseid) 22 ###执行依赖数据的测试用例 23 def run_dependent(self): 24 row = self.opexcel.get_row_num(self.caseid) 25 url = self.data.get_url(row) 26 mehtod = self.data.get_request_method(row) 27 data = self.data.get_request_datajson(row) 28 if data != None: 29 data = json.dumps(data) 30 headers = self.data.header_is_run(row) 31 res = self.run.runmain(mehtod, url, data, headers) 32 print("正在执行依赖用例:%s" %res) 33 return res 34 ###根据规则key提取依赖数据的响应报文中的特定的数据,然后返回 35 def get_dependentdata(self,row): 36 res = self.get_dependentdata_excute(row) 37 return res 38 def get_dependentdata_excute(self,row): 39 depend_data = self.data.get_depend_key(row) 40 print("============>>依赖用例的数据", depend_data) 41 ###依赖用例执行的响应报文 42 response_data = self.run_dependent() 43 print("============>>依赖用例的响应报文", response_data) 44 ###依赖测试的预期结果 45 expect_data = self.data.get_expect_data(row) 46 print(expect_data) 47 obj_commonutil = commonutil() 48 print("判断预期实际结果",obj_commonutil.iscomtent(expect_data,response_data)) 49 if obj_commonutil.iscomtent(expect_data,response_data) == True: 50 print("++++++++++++,判断预期响应报文包含在实际响应报文中" ) 51 print(depend_data) 52 print(response_data) 53 try: 54 json_exe = parse(depend_data) 55 madle = json_exe.find(json.loads(response_data)["data"]) 56 res = [math.value for math in madle][0] 57 print(res) 58 return res 59 except Exception as e: 60 return e 61 else: 62 print("预期的响应报文不包含在实际报文中") 63 return None 64 65 66 67 68 69 if __name__ == "__main__": 70 ###excel中的提取规则运行有问题,需要后续检查 71 obj_depentdata = depentdata("web_api_002") 72 print(obj_depentdata.get_dependentdata(3))
1 #!/usr/bin/env python 2 # -*- coding:utf-8 3 from utils.op_excel import Oper_excel 4 from data.data_config import * 5 from utils.op_json import * 6 from utils.op_file import * 7 8 class getdata: 9 def __init__(self): 10 self.oper_excel = Oper_excel() 11 ##去获取excel表里面的case行数 12 def get_case_Lines(self): 13 return self.oper_excel.get_line() 14 ###获取程序是否运行 15 def get_is_run(self,row): 16 flag = None 17 col = get_case_run() 18 run_model = self.oper_excel.get_cell_value(row,col) 19 if run_model == "YES": 20 flag = True 21 else: 22 flag = False 23 return flag 24 ###是否携带header 25 def header_is_run(self,row): 26 col = get_case_header() 27 header = self.oper_excel.get_cell_value(row,col) 28 if header == "YES": 29 return get_case_headers_data() 30 else: 31 return None 32 ###获取请求方式 33 def get_request_method(self,row): 34 col = get_case_method() 35 request_method = self.oper_excel.get_cell_value(row,col) 36 return request_method 37 ###获取URL 38 def get_urlpath(self,row): 39 col = get_case_urlpath() 40 url = self.oper_excel.get_cell_value(row,col) 41 return url 42 ###获取请求数据关键字 43 def get_request_dataid(self,row): 44 col = get_case_dataid() 45 dataid = self.oper_excel.get_cell_value(row,col) 46 if dataid == '': 47 dataid = None 48 return dataid 49 ###通过关键字获取请求数据 50 def get_request_datajson(self,row): 51 obj_op_json =data_read_handle() 52 data = obj_op_json.get_data_read(self.get_request_dataid(row)) 53 # data = obj_op_json.data 54 return data 55 ###获取预期结果 56 def get_expect_data(self,row): 57 col = get_case_expect() 58 data = self.oper_excel.get_cell_value(row,col) 59 if data == '': 60 data = None 61 return data 62 ###写入实际结果 63 def write_exact_res(self,row,value): 64 col = get_case_exact() 65 self.oper_excel.update_data(row,col,value) 66 ###获取依赖数据key 67 def get_depend_key(self,row): 68 col = get_case_dependdata() 69 data = self.oper_excel.get_cell_value(row,col) 70 if data == '': 71 data = None 72 return data 73 ###判断是否有数据依赖 74 def is_depend(self,row): 75 col = get_case_dependdata() 76 data = self.oper_excel.get_cell_value(row, col) 77 if data == '': 78 data = None 79 return data 80 ####判断数据依赖类型:header_depend:header依赖;body_depend:body依赖 81 def get_depeed_type(self,row): 82 col = get_case_depend_type() 83 data = self.oper_excel.get_cell_value(row,col) 84 if data == '': 85 data = None 86 return data 87 ###获取数据依赖字段 88 def get_depend_field(self,row): 89 col = get_case_dependfileld() 90 data = self.oper_excel.get_cell_value(row, col) 91 if data == '': 92 data = None 93 return data 94 ###获取依赖ID 95 def get_depend_id(self,row): 96 col = get_case_dependid() 97 data = self.oper_excel.get_cell_value(row, col) 98 if data == '': 99 data = None 100 return data 101 ###获取配置文件中的url_ip并且将绝对URL拼接出来 102 def get_url(self,row): 103 obj_op_file_handle = op_file_handle() 104 url_ip = obj_op_file_handle.read_file_handler("url_ip") 105 """ 106 协议版本:http/https这儿暂不做处理,后期有需要在进行处理 107 """ 108 url_path = self.get_urlpath(row) 109 url = "http://"+eval(url_ip)+url_path 110 return url 111 ###获取是否清除测试数据 112 def get_clean_testdata(self,row): 113 col = get_case_clean_testdata() 114 data = self.oper_excel.get_cell_value(row, col) 115 if data == 'NO': 116 data = None 117 elif data == 'YES': 118 return data 119 ###获取清除数据sql 120 def get_clean_sql(self,row): 121 col = get_case_clean_sql() 122 data = self.oper_excel.get_cell_value(row, col) 123 if data == '': 124 data = None 125 return data 126 ###写入清除数据sql执行结果 127 def write_sql_excute_res(self,row,value): 128 col = get_is_sql_success() 129 print(col) 130 self.oper_excel.update_data(row,col,value) 131 if __name__ == "__main__": 132 obj_getdata = getdata() 133 # print(obj_getdata.get_case_Lines()) 134 # ###根据请求id到json文件中拿到请求数据 135 # for i in range(1,obj_getdata.get_case_Lines()): 136 # print(obj_getdata.get_request_datajson(i)) 137 # print(obj_getdata.get_depend_key(3)) 138 print(obj_getdata.get_request_datajson(3))
2.4.4、cfg.text:配置文件,存放常用的变量,以及可以对特定的变量进行修改;
1 ###服务器主机名 2 url_ip = "****" ###127.0.0.1:8080 3 ###token 获取到token持久化,后续token依赖都到配置文件中取值; 4 ###token刷新或者过期重新持久化 5 Authorization = Bearer2e4c4b2e-93d1-45fd-9201-8d778e4f841c 6 ###测试报告邮件登录账号 7 username =**** ##111111111@qq.com 8 ###测试报告邮件登录密码 9 password = **** 10 ###测试报告邮件发送人地址 11 sender =**** ##111111111@qq.com 12 ###测试报告邮件接收人地址 13 recv_list = ["****", "****","****"]
2.5、data_file包:用于存放测试用例及json文件
2.5.1、auto_test_case.xls:存放接口测试用例;
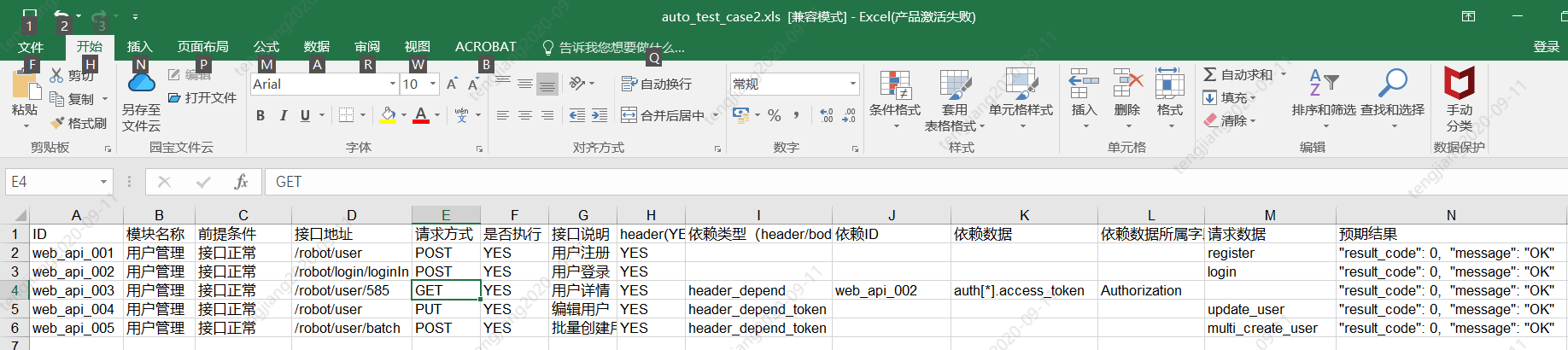

接口测试用例表每个字段备注:
2.5.2、header.json:主要用于存在常规通过的headers

2.5.3、usermanagement.json:用于存放请求body,json格式,可以根据不同的模块创建不同的json文件;
三、项目部署
1、python3环境的部署
python3在Linux系统上的在线部署网上到处有,今天主要记录一下离线安装;
1.1、离线安装python解释器
a、python官网上:https://www.python.org/downloads/source/ 上下载tar.gz压缩包;
b、通过smtp上传到服务;
c、解压;
d、编译:
1 cd Python-3.7.2 # 进入python3安装包目录 2 ./configure --prefix=/usr/local/python3 # 将python3安装在这个目录 3 make && make install # 编译和安装
e、创建软连接
1 ln -s /usr/local/python3/bin/python3 /usr/bin/python3 # 创建python3软连接 2 ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3 # 创建pip3的软连接
备注:为何要创建这样的软连接:
Linux系统中编译安装python3创建软连接其实和windows上添加环境python3的环境变量是一样作用的,Linux在/usr/bin/ 目录下创建软连接就类似于将python3添加到环境变量中;
不信,你可以使用echo打印一下当前环境变量:echo $PATH,当前用户的环境变量如下;

1.2、离线安装python3插件
a、运行python程序,找到报错原因,确定报错原因是否是缺少插件造成的;
b、复制报错中的插件,进入官网:https://www.python.org/ 搜索对应的插件;或者搜索引擎中直接输入python3+包名;

c、下载成功上传到服务器上,下载下来的插件有几种格式:tar.gz/zip/whl
d、安装对应的插件,这是我离线下载的python插件,报错提示缺什么就对应下载什么插件;

对于不同格式的插件安装方式有所不同;
d.1、tar.gz、zip包直接解压,进入目录,对于这类插件,目录里都有setup.py文件,直接python3 setup.py install即可安装成功,直接将插件安装到虚拟运行环境sites-packages目录下;
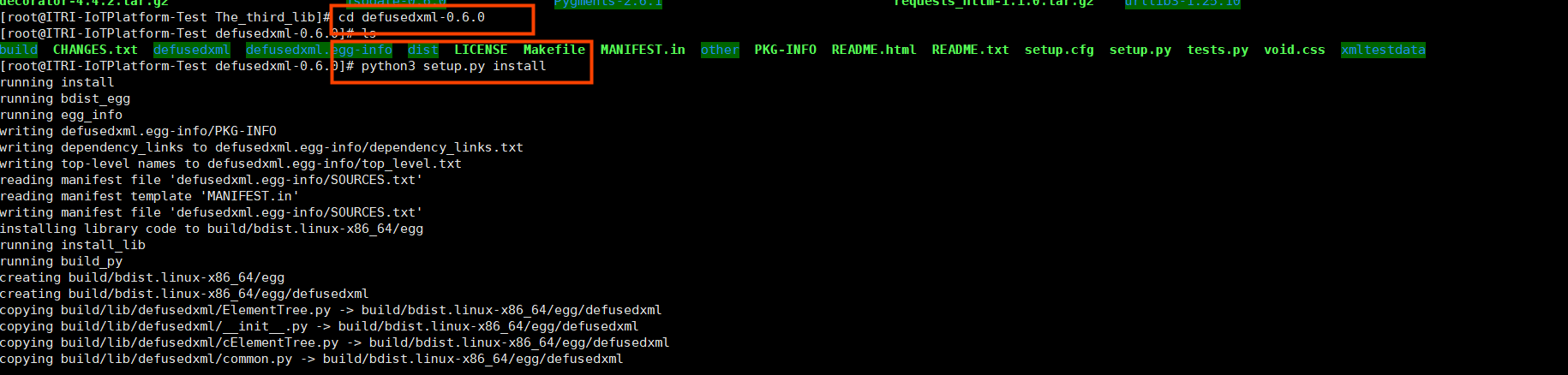
d.2、whl格式的插件安装,直接 pip3 install 对应的whl文件即可,也是直接将插件安装到虚拟运行环境sites-packages目录下;

到目前为止只遇到这两个方式安装python3的插件;
2、jenkins部署
2.1、jenkins安装
到目前为止接触到两种方式:war包放在tomcat下运行;jar包直接运行,需要依赖java;
2.2、jenkins构建工程;
中间过程中的jenkins插件安装及配置就不做说明了,网上大把资源等着你去搜索;主要详细记录一下jenkins工程构建过程;
环境配置说明:因为公司已经使用堡垒机登录,不允许直接通过终端程序登录远程服务器,所以jenkins,原计划是jenkins在A服务器上,接口测试项目在B服务器上,因此就直接将jenkins服务和接口自动化的项目放在同一服务器上;
本次部署的构建工程非常简单:
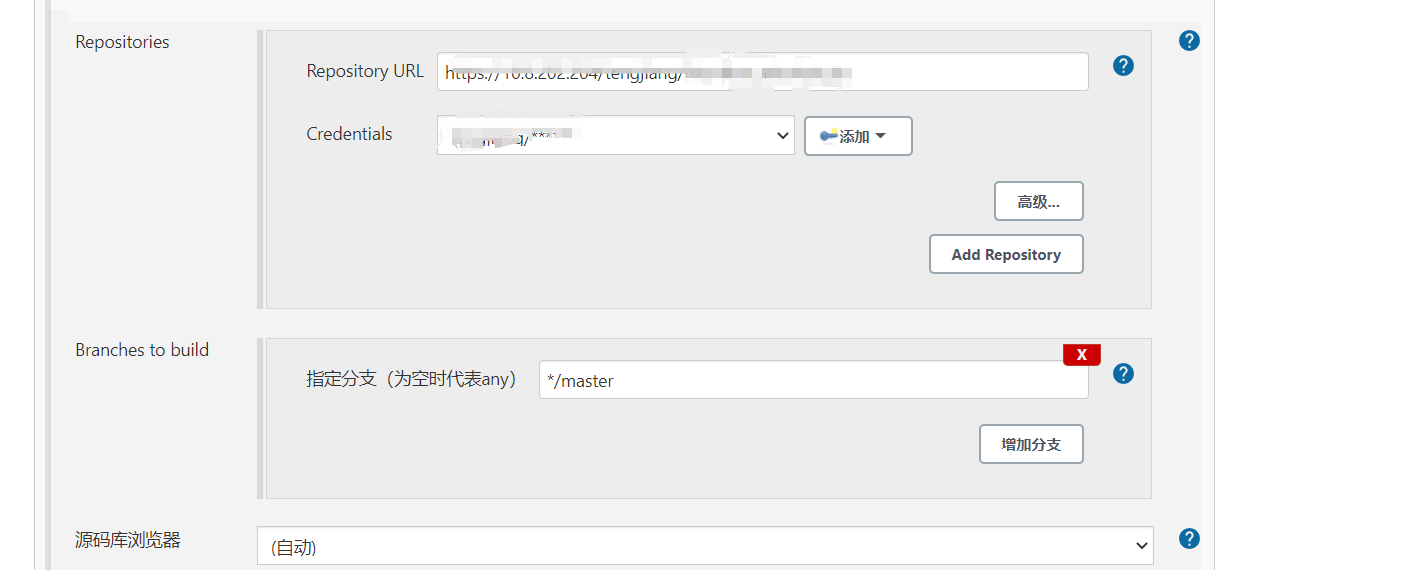
a、源码管理,因为代码通过公司自搭建的git管理,配置git参数后,可以直接将配置仓库的指定分支代码拉到jenkins的工作目录下;
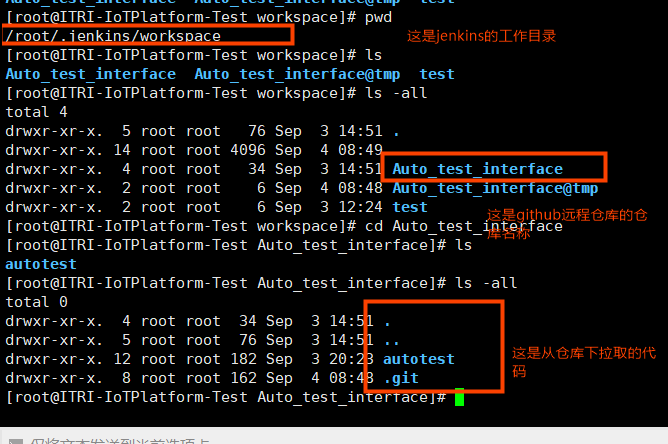
b、构建、直接选择执行shell;代码拉到jenkins的工作目录下,没有进行打包解压编译、清除文件、记录日志等相关操作,所以直接在工作目录下直接运行的程序;
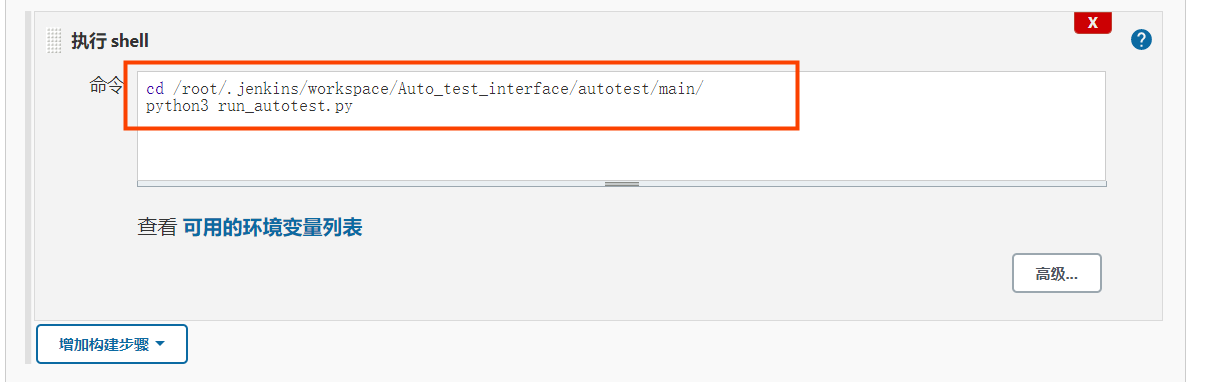
就这样完成了初级的jenkins拉取远程仓库的指定分支的代码,然后在服务器上运行的操作;
3、接口自动化测试项目部署
其实接口自动化测试项目在服务器上的部署就是前面python环境的部署已经jenkins构建工程的相关操作,哈哈!
