Net Core使用Lucene.Net和盘古分词器 实现全文检索
Lucene.net#
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,是一个高性能、可伸缩的文本搜索引擎库。它的功能就是负责将文本数据按照某种分词算法进行切词,分词后的结果存储在索引库中,从索引库检索数据的速度非常快。Lucene.net需要有索引库,并且只能进行站内搜索。(来自百度百科)
效果图#

盘古分词#
如何使用#
将PanGu.dIl与PanGu.Lucenet.Analyzer. dl并加入到项目中
将Dict文件,拷贝到项目Bin文件夹里面
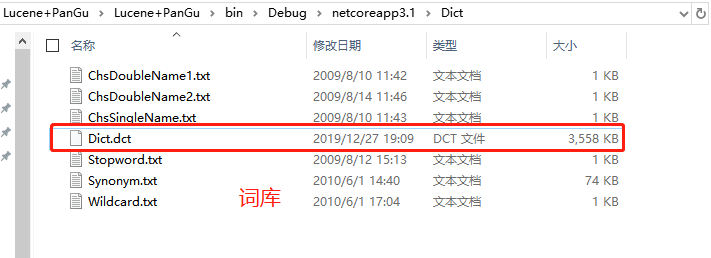
字典文件夹下载:https://pan.baidu.com/s/1HNiLp6bCcodN8vqlck066g 提取码: xydc
测试
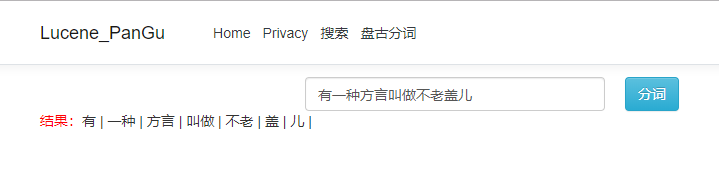
可以看到,盘古分词相对Lucene.net自带的一元分词来说,是比较好的,因为一元分词不适合进行中文检索。
一元分词是按字拆分的,比如上面一句话,使用一元分词拆分的结果是:"有","一","种","方","言","叫","做","不","老","盖","儿"。如果查找“方言”这个词,是找不到查询结果的。不符合我们的检索习惯,所以基本不使用。
拓展#
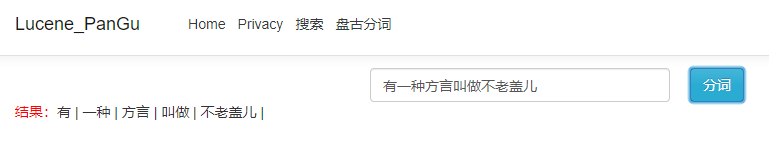
上面的"不老盖儿"(河南方言),这里想组成一个词,那么需要创建"不老盖儿"词组并添加到字典里面。
使用DictManage工具:https://pan.baidu.com/s/1Yla2DBM74kSbno8cg5kvGw 提取码:tphe
解压,运行 DictManage.exe
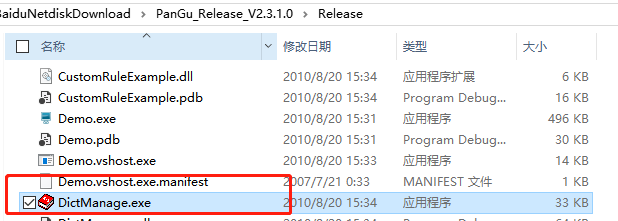
然后打开 Dict 文件下的 Dict.dct 文件,并添加"不老盖儿"词组
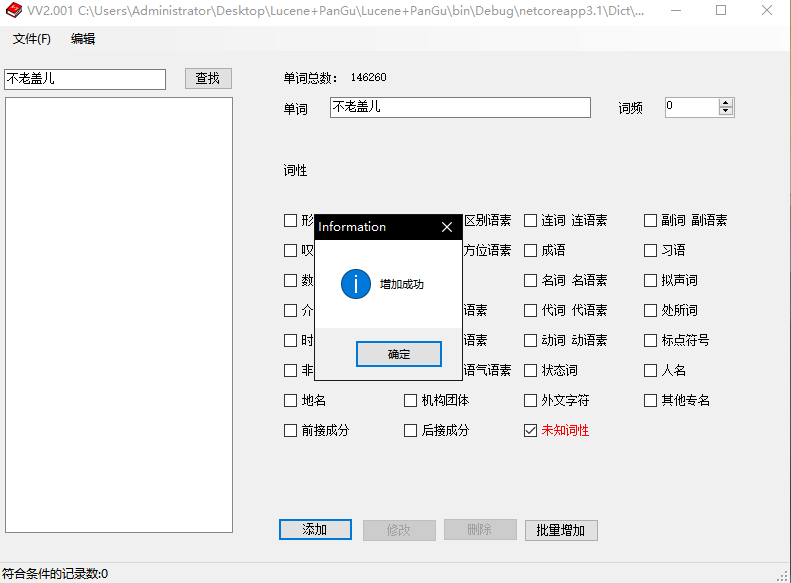
然后查找就可以看到"不老盖儿"词组
然后保存覆盖原有的 Dict.dct 文件
刷新页面或者重新打开页面看下效果
Demo文件说明#
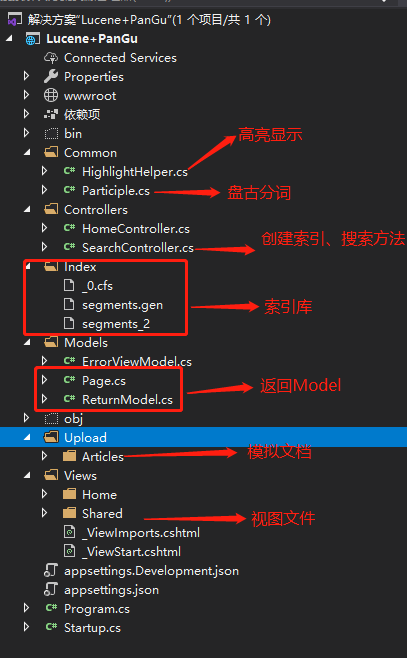
简单实现 #
创建索引核心代码#



/// <summary> /// 创建索引 /// </summary> /// <returns></returns> [HttpGet] [Route("createIndex")] public string CreateIndex() { //索引保存位置 var indexPath = Directory.GetCurrentDirectory() + "/Index"; if (!Directory.Exists(indexPath)) Directory.CreateDirectory(indexPath); FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory()); if (IndexWriter.IsLocked(directory)) { // 如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁 // Lucene.Net在写索引库之前会自动加锁,在close的时候会自动解锁 IndexWriter.Unlock(directory); } //Lucene的index模块主要负责索引的创建 // 创建向索引库写操作对象 IndexWriter(索引目录,指定使用盘古分词进行切词,最大写入长度限制) // 补充:使用IndexWriter打开directory时会自动对索引库文件上锁 //IndexWriter构造函数中第一个参数指定索引文件存储位置; //第二个参数指定分词Analyzer,Analyzer有多个子类, //然而其分词效果并不好,这里使用的是第三方开源分词工具盘古分词; //第三个参数表示是否重新创建索引,true表示重新创建(删除之前的索引文件), //最后一个参数指定Field的最大数目。 IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), true, IndexWriter.MaxFieldLength.UNLIMITED); var txtPath = Directory.GetCurrentDirectory() + "/Upload/Articles"; for (int i = 1; i <= 1000; i++) { // 一条Document相当于一条记录 Document document = new Document(); var title = "天骄战纪_" + i + ".txt"; var content = System.IO.File.ReadAllText(txtPath + "/" + title, Encoding.Default); // 每个Document可以有自己的属性(字段),所有字段名都是自定义的,值都是string类型 // Field.Store.YES不仅要对文章进行分词记录,也要保存原文,就不用去数据库里查一次了 document.Add(new Field("Title", "天骄战纪_" + i, Field.Store.YES, Field.Index.NOT_ANALYZED)); // 需要进行全文检索的字段加 Field.Index. ANALYZED // Field.Index.ANALYZED:指定文章内容按照分词后结果保存,否则无法实现后续的模糊查询 // WITH_POSITIONS_OFFSETS:指示不仅保存分割后的词,还保存词之间的距离 document.Add(new Field("Content", content, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS)); writer.AddDocument(document); } writer.Close(); // Close后自动对索引库文件解锁 directory.Close(); // 不要忘了Close,否则索引结果搜不到 return "索引创建完毕"; }
搜索代码#
/// <summary> /// 搜索 /// </summary> /// <returns></returns> [HttpGet] [Route("search")] public object Search(string keyWord, int pageIndex, int pageSize) { Stopwatch stopwatch = new Stopwatch(); stopwatch.Start(); string indexPath = Directory.GetCurrentDirectory() + "/Index"; FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory()); IndexReader reader = IndexReader.Open(directory, true); //创建IndexSearcher准备进行搜索。 IndexSearcher searcher = new IndexSearcher(reader); // 查询条件 keyWord = GetKeyWordsSplitBySpace(keyWord, new PanGuTokenizer()); //创建QueryParser查询解析器。用来对查询语句进行语法分析。 //QueryParser调用parser进行语法分析,形成查询语法树,放到Query中。 QueryParser msgQueryParser = new QueryParser(Lucene.Net.Util.Version.LUCENE_29, "Content", new PanGuAnalyzer(true)); Query msgQuery = msgQueryParser.Parse(keyWord); //TopScoreDocCollector:盛放查询结果的容器 //numHits 获取条数 TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true); //IndexSearcher调用search对查询语法树Query进行搜索,得到结果TopScoreDocCollector。 // 使用query这个查询条件进行搜索,搜索结果放入collector searcher.Search(msgQuery, null, collector); // 从查询结果中取出第n条到第m条的数据 ScoreDoc[] docs = collector.TopDocs(0, 1000).scoreDocs; stopwatch.Stop(); // 遍历查询结果 List<ReturnModel> resultList = new List<ReturnModel>(); var pm = new Page<ReturnModel> { PageIndex = pageIndex, PageSize = pageSize, TotalRows = docs.Length }; pm.TotalPages = pm.TotalRows / pageSize; if (pm.TotalRows % pageSize != 0) pm.TotalPages++; for (int i = (pageIndex - 1) * pageSize; i < pageIndex * pageSize && i < docs.Length; i++) { var doc = searcher.Doc(docs[i].doc); var content = HighlightHelper.HighLight(keyWord, doc.Get("Content")); var result = new ReturnModel { Title = doc.Get("Title"), Content = content, Count = Regex.Matches(content, "<font").Count }; resultList.Add(result); } pm.LsList = resultList; var elapsedTime = stopwatch.ElapsedMilliseconds + "ms"; var list = new { list = pm, ms = elapsedTime }; return list; }
盘古分词#
/// <summary> /// 盘古分词 /// </summary> /// <param name="words"></param> /// <returns></returns> public static object PanGu(string words) { Analyzer analyzer = new PanGuAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("", new StringReader(words)); Lucene.Net.Analysis.Token token = null; var str = ""; while ((token = tokenStream.Next()) != null) { string word = token.TermText(); // token.TermText() 取得当前分词 str += word + " | "; } return str; }
搜索结果高亮显示#
/// <summary> /// 搜索结果高亮显示 /// </summary> /// <param name="keyword"> 关键字 </param> /// <param name="content"> 搜索结果 </param> /// <returns> 高亮后结果 </returns> public static string HighLight(string keyword, string content) { // SimpleHTMLFormatter:这个类是一个HTML的格式类,构造函数有两个,一个是开始标签,一个是结束标签。 SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<font style=\"color:red;" + "font-family:'Cambria'\"><b>", "</b></font>"); // 创建 Highlighter ,输入HTMLFormatter 和 盘古分词对象Semgent Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new Segment()); // 设置每个摘要段的字符数 highlighter.FragmentSize = int.MaxValue; // 获取最匹配的摘要段 var str = highlighter.GetBestFragment(keyword, content); return str; }
对关键字进行盘古分词处理#
/// <summary> /// 对关键字进行盘古分词处理 /// </summary> /// <param name="keywords"></param> /// <param name="ktTokenizer"></param> /// <returns></returns> private static string GetKeyWordsSplitBySpace(string keywords, PanGuTokenizer ktTokenizer) { StringBuilder result = new StringBuilder(); ICollection<WordInfo> words = ktTokenizer.SegmentToWordInfos(keywords); foreach (WordInfo word in words) { if (word == null) { continue; } result.AppendFormat("{0}^{1}.0 ", word.Word, (int)Math.Pow(3, word.Rank)); } return result.ToString().Trim(); }
作者:tenghao510
出处:https://www.cnblogs.com/tenghao510/p/12069421.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?