
云数据库架构思维升级,看这篇就够了
近期,ArchSummit 全球架构师峰会(以下简称:AS峰会)北京站圆满落幕。AS峰会是极客邦科技旗下 InfoQ 中国团队推出的重点面向高端技术管理者、架构师的技术会议。AS峰会北京站以“升级架构思维,支撑业务发展”为目标,邀请各厂商展示先进技术在行业中的典型实践,以及技术在企业转型、发展中的推动作用。在此次AS峰会上,腾讯云数据库专家团亮相“云数据库的架构设计与技术演进”专场,由腾讯云数据库专家工程师伍鑫担任专场出品人。
数据库作为基础软件的三驾马车之一,是IT行业的必争之地。云时代下,云原生技术和数据库技术的结合,已经成为数据库行业重要发展方向。在专场中,四位讲师围绕云数据库的架构设计和技术演进,以腾讯云的数据库产品为例,针对性地解读数据库产品容器化难点、数据库统一管理、超大规模集群在线数仓架构设计等话题。

一、云原生数据库管控探索和实践
孙勇福,腾讯云数据库专家工程师

技术变革日新月异,迭代迅速。孙勇福认为,多元技术融合、多元架构形态会成为未来的常态。随着业务的不断扩大,沿用分散的管控架构模式势必会带来重复建设的问题,导致资源使用效率低下,弊端也逐渐凸显,具体如下:
- 无法利用云上 IaaS 层的资源池和弹性扩缩容的能力,以及 IaaS 层成本和性能优化的红利;
- 缺少统一的数据库 PaaS 平台,对多个产品、多个环境进行统一管控和调度;
- 业务功能复用程度低,造成人力资源浪费;
- 无法利用云原生红利,平台无法标准化,运维和交付成本比较高;
上述问题,可以归纳为资源调度和统一的流程管控问题。
得益于腾讯云上IaaS基础设施的优势,孙勇福提出了PaaS on IaaS的思考,提高数据库系统的弹性能力,实现降本增效,同时解决数据库产品发展过程中遗留的历史架构问题, 提升孵化新数据库产品的效率。
如何统一管理IaaS层的资源,是 PaaS on IaaS 面临的主要挑战。孙勇福所在的研发团队进行了各种不同的尝试,从最初的框架模式逐渐演化到平台模式,一个叫云巢(Khaos)的产品诞生了。现如今,云巢(Khaos)有状态服务PaaS平台已经可以支持各种数据库产品快速上云。
什么是有状态服务?孙勇福解释说,有状态服务是指需要将数据、会话或服务状态做持久保存,服务启动、运行和恢复时均严格依赖所保存数据的正确性和一致性的服务。数据库就是典型的有状态服务。有状态服务区别于无状态服务主要是状态两个字,有状态服务往往伴随着数据持久化,服务节点状态化( MySQL 主从节点)。
如何在复杂的状态服务中,更好的解耦业务逻辑,提供通用的平台能力是PaaS 平台设计的难点之一。在云巢的构建中,首先要明确平台的边界和业务边界,平台不仅要关心业务的具体逻辑,也必须要提供业务灵活的接入功能。
在架构设计上,云巢平台包含 Khaos Platform 和 Khaos Eros 两个子系统。Khaos Platform借助Kubernetes的标准化能力统一了不同的底座, 向上提供数据库服务实例的配置管理、生命周期管理、跨故障域调度等基础能力。除了底层资源管理之外,数据库管控系统往往还有较复杂的业务流程, 例如,对于某个数据库实例的发货流程,管控系统收到请求后,先申请底层计算、存储资源以及VIP等, 等待资源就绪之后,管控系统继续执行添加路由、设置计费策略等操作。为了降低业务流程与云巢的交互复杂度,云巢在资源管理的基础上提供了 Khaos Eros服务, 用来将底层资源平台的操作细节封装成更粗粒度的业务流程,简化使用云巢的难度。
此外,孙勇福还分享了云巢架构设计实现的具体细节,有想了解的小伙伴可入群与讲师讨论哦!
二、腾讯云数据库云上SaaS生态演进
潘怡飞,腾讯云数据库高级工程师

在实际工作中,潘怡飞通过与用户的交流发现,用户在用PaaS产品的时候经常需要定制开发,比如说数据库运维工具、数据传输工具等等。定制化工作会分散运维同学的精力,增加研发同学在业务上的研发时间。因此,SaaS产品应运而生。
腾讯云数据库提供完整的SaaS生态矩阵,潘怡飞重点分享了以下三大产品:
1. 数据传输服务DTS
DTS提供数据迁移与数据流打通服务,特点是支持在线迁移同步,满足低时延和高可靠的要求,在功能上主要包含迁移、同步和订阅三大模块。具体来看:
- DTS数据迁移是面向单次的数据库迁移上云、下云,支持常见的链路,可以实现历史全量和动态增量的迁移,同时它还支持一致性校验,可以在迁移前随时发起一致性校验,帮助客户预知迁移效果。在迁移中,DTS能够保证数据的正确性以及做到对源库无感知,潘怡飞表示这也是客户最关注的点。
- DTS数据同步是指两个数据源之间的数据长期实时同步,具有多种高级特性,例如库表重映射、DML/DDL过滤,Where条件过滤;主要适用于云上云下多活、异地多活,跨境数据同步、实时数据仓库等场景。
- DTS数据订阅是指实时按需获取数据库中关键业务的数据变化信息,将这些信息包装为消息对象推送到内置Kafka中,方便下游实时消费应用;适用于异构数据更新等。
整体来看,DTS通过迁移、同步和订阅这三个功能模块,充分打通数据链路之间的流转管理,构建双向、环形、异构、多合一等场景。这样不用客户自己去开发一些工具或定时任务来解决问题,使得客户可以更专注于自身业务,发挥优势创造价值,剩下的就交给PaaS平台或SaaS平台来做。
2. 数据智能管家DBbrain
数据库统一管理过程中有许多的难点和痛点,DBbrain正是应用于解决这些问题的一款SaaS工具。DBbrain是自动化、智能化运维统一管理平台,从前期的数据库巡检、故障发现、故障定位到后期的故障解决与系统优化,形成一套数据库全生命周期管理运维的工具。
潘怡飞列举了两个典型场景,为大家详细展示了DBbrain的功能。
第一个是慢SQL分析。DBbrain会基于多维度的统计来进行统一汇总,并实现自动排序。在性能优化这方面,利用编译器、优化器的改写来计算代价和成本,以此判断SQL是不是优质,是不是需要添加索引。另外DBbrain支持通过API的拉取分析接口,借助云上计算的优势,直接使用 SaaS 去构建自有运维平台。
第二个是异常诊断。日常诊断是根据秒级的监控,日常的巡检会有一些告警项提示,同时收集十几个维度的信息之后做汇总展示,进一步进行预警诊断。
3. 数据库安全审计
数据库安全审计是一个基于内核级别的安全审计平台,区别于一些需要旁路管控部署的方式,这种对性能和收集完整度都支持的比较好;同时可以DBbrain进行联动,针对审计日志进行汇总、分析,真正能够做到收集并使用。
SaaS的产品价值在于可以降低客户在工具或者不必要的研发上的投入,把资源聚焦于自己的业务。直接使用SaaS 工具可以帮助业务更好的创造价值。
未来,潘怡飞表示腾讯云数据库SaaS生态产品还将继续发力。DTS后续会在场景化和复杂拓扑场景深耕,支持一键创建复杂拓扑链路,比如说星型、环形、双向等一系列场景,并且实现不需要逐条配置冲突策略。DBbrain会更加智能化、AI化,可以直接基于慢SQL自动,将之前的推荐模式升级到自动创建索引,甚至实现数据库负载自动扩容、缩容;同时可以利用目前云原生数据库的快速缩扩容能力,充分结合更多产品之间的场景联动,帮助客户创造更多业务价值。
此外,潘怡飞还分享了腾讯云数据库SaaS生态的发展思路,有想了解的小伙伴可入群与讲师讨论哦!
三、大规模在线数仓技术构架分享
张倩,腾讯云数据库专家工程师

大规模在线数仓的分析性能提升,可以在自研列式存储、向量化引擎、并行执行逻辑、计算层缓存等核心技术模块做突破,张倩分享道。
数据库技术发展半个世纪,从早期对关系模型的研究到SQL语句的出现,都是不断面向业务需求和用户体验的最佳设计实践。而列存储的出现甚至可以追溯到上世纪70年代的数据库开创时代,当时人们就在讨论具体用何种存储模型来支持上层计算。
张倩提到,其实在实际使用场景中,用户业务模型并不会完全适配某一种存储类型,更多的是混合业务模型中带有OLTP或者OLAP场景的倾向性。所以数据库系统在早期针对专一场景的探索比较成熟后,近年来开始进一步探索,逐步提出混合HTAP(Hybrid Transactional/Analytical Processing)模式,希望通过一套引擎来处理混合业务类型。
大规模在线数仓整体以OLAP极致查询性能读优化RO(Read Optimize)为基础前提,保证数据库事务ACID特性,同时针对OLTP场景进行写优化WO(Write Optimize)。并且对RO/WO能力进行透明整合,为用户提供透明易用的表结构设计。
张倩基于列式存储的自研过程,为大家重点分析了其中的技术细节。列存储模块中数据块采用DSM模型每列以Silo格式独立存储保证高压缩比和最大化I/O裁剪能力支持。而每张列存储表会创建两张辅助heap表,Registry表用来存储Silo的元数据信息,Stash表用来承接Write Optimize的短事务DML数据并后台进行数据“沉降”Merge。
通过基于heap表的元数据实现,将列存的MVCC设计与行存表统一,使得列存表能够完美支持DML、分布式事务一致性、并发更新等能力。同时列存表也支持B-Tree/Hash索引,range/hash/list等多级分区表能力。用户使用起来更加方便,在选择存储类型建表后,用户基本可以无感知的进行行列混合多表关联、基于索引的点查询加速、多任务并发入库/查询。
此外,张倩还分享了腾讯云数据库在向量化引擎、并行执行逻辑、计算层缓存等技术上的优化思路,有想了解的小伙伴可入群与讲师讨论哦!
四、TDSQL升级版引擎架构和关键技术介绍
韩硕,腾讯云数据库高级工程师

随着企业业务场景的不断增长和复杂化,业务形态、业务量会不可预知性的增大。由此,业务的敏态发展对数据库底层技术也提出了需要具有敏感能力的要求。
韩硕老师分享道,在数据库投产的过程中,应对业务敏态变更的时候常常会遇到以下这些问题:
- 兼容性:建表需要手动指定shardkey;
- 运维:存储层扩容,需要DBA发起,部分事务会中断;
- 模式变更:online DDL依赖Pt等工具。
基于上述问题,腾讯云数据库升级了TDSQL新敏态存储引擎架构。韩硕老师表示,考虑到敏态业务变化较大,团队希望在TDSQL新敏态存储引擎架构中,用户可以像单机数据库一样去使用分布式数据,不需要关注存储变化,可以随时加字段、建索引,做到业务完全无感知。
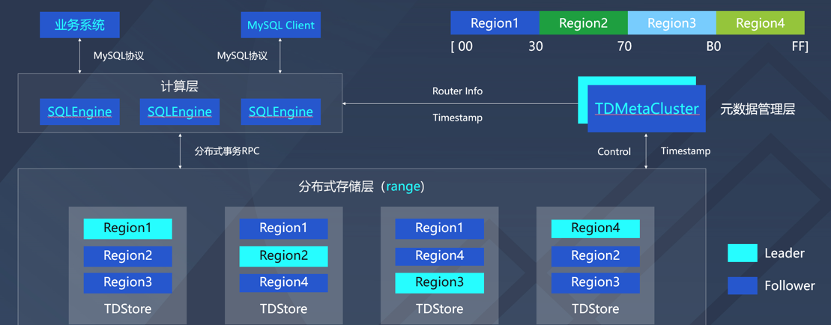
如上图所示,升级版的架构图分为计算层、元数据管理层和分布式存储层三个部分。韩硕重点分享了这三个部分的设计要点。
在计算模块SQLEngine中,内核完全兼容MYSQL8.0。计算层为多主架构,每个SQLEngine节点均可读写,SQLEngine之间通过一定方式刷新表结构变更等信息。改造是无状态化设计,移除各种有状态化的数据,多线程替换为协程框架。
在存储模块TDstore中,架构是基于LSM-tree和Multi-raft的分布式KV存储引擎。数据是Region是基于raft同步的多副本的存储管理单元,数据根据key范围分布在不同Region上;Region TDMC调度下可发生分裂、合并、迁移、切主等操作。
在管控模块TDMetacluser中,重点关注三个方面,第一是高效的生成和下发全局唯一的事务时间戳;第二是管理模块的元数据,比如TDstore和SQLEngine元数据,管理Region数据路由信息,以Region为基本单位进行负载均衡和存储的均衡调度;第三是负载均衡的调度,这个调度要考虑负载的热点,简单来讲,会把热点Region打散到不同的存储节点上,也需要兼顾性能的影响,还要对Region进程做一些合理的划分,会有跨Region的分布式事务,是两阶段提交的模型,我们会把进程通过合理的Region调度和划分,把两个阶段的事务变成一阶段的事务,从而提升效率。
韩硕将升级版引擎技术亮点总结为以下四点:
- 兼容性:具有TDSQL兼容性,升级版的架构是原生分布式结构,数据以key range打散和路由,成本比较低;存储层采用LSM-Tree结构,压缩比有量级的提升,非常适合于大规模业务量的业务。
- 可扩展性强:首先计算层是多主模式,每个SQLengine均可读写,同时是无状态化设计,可根据业务流量随时灵活添加或减少一些计算节点。存储层也是根据业务数据存储量需求,去做平滑的添加或者移除TDstore节点,通过数据自动迁移,实现容量弹性伸缩,做到业务层无感知。
- 一致性:事务模型具有全局读一致性,围绕管理层TDmetacluster统一分配全局唯一递增事务时间戳来做数据的一致性的判断。
- 支持在线变更:计算节点支持在线模式变更,目前已经支持了在线操作、索引操作等。
最后,韩硕再次将团队的愿景传递给大家:希望用户能够像使用单机数据库一样使用我们的分布式数据库,同时还能拥有无限扩展性。
此外,想了解韩硕分享的TDSQL新敏态存储引擎架构实现细节的小伙伴,可入群与讲师讨论哦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号