揭秘TDSQL-A分布式执行框架:解放OLAP关联分析查询性能瓶颈
在“国产数据库硬核技术沙龙-TDSQL-A技术揭秘”系列分享中,5位腾讯云技术大咖分别从整体技术架构、列式存储及相关执行优化、集群数据交互总线、分布式执行框架设计及优化策略、以及向量化执行引擎等多方面对TDSQL-A进行了深入解读。
本期带来了系列分享中腾讯云数据库高级工程师张倩老师主题为“TDSQL-A分布式执行框架设计及优化策略”的分享的文字版。没有听直播的小伙伴,可要认真做笔记啦!
作为领先的分析型数据库,TDSQL-A是腾讯首款分布式分析型数据库,采用全并行无共享架构,具有自研列式存储引擎,支持行列混合存储,适应于海量OLAP关联分析查询场景。它能够支持2000台物理服务器以上的集群规模,存储容量能达到单数据库实例百P级。
一、执行框架总体设计
1.1 TDSQL-A架构
首先介绍TDSQL-A的总体架构,包括上层的协调节点CN、GTM事务管理器、中间的数据交互总线FN、以及下方的数据节点DN。主要介绍的是协调节点CN和数据节点DN的相关内容,包括用户的查询怎么在CN和DN上执行、最后如何返回结果给用户等问题。
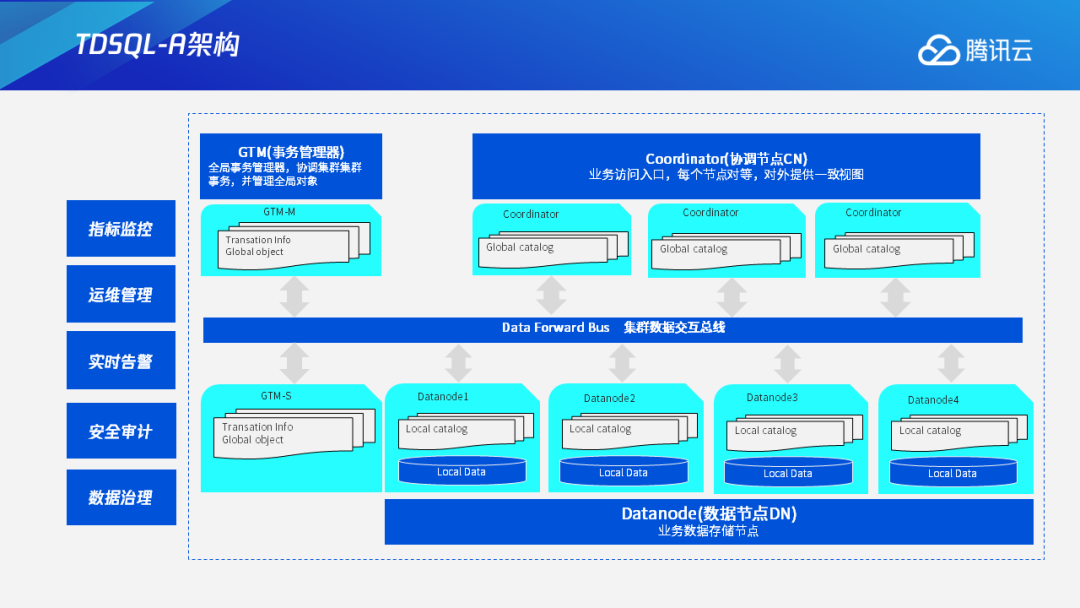
TDSQL-A采用MPP架构,其特性是share-nothing,数据分散在多个DN上,按照不同的分布键分布,并且不同的表可以自定义不同的分布键。如果CN收到了一条查询,它会将这个任务分散到多个DN上并行执行,从而提高执行效率,最后CN获得DN并行执行的最后结果,汇总之后再返回给客户端。

1.2原分布式执行框架
这里先说明一下我们的原分布式执行框架一个最主要的问题。下图是一个简单的Join查询,如果Join查询正好是在这个表的分布键上进行Join,则不涉及数据的重分布,可以直接在每个DN节点上进行Join,DN的结果汇总起来就是最终的查询结果,这是最理想的情况。
但客户的查询往往比较复杂多样,Join经常会涉及不同节点之间的数据交换,Join的两个表的Join键不一定是一个表的分布键,这种情况下就会涉及到数据的重分布。在TDSQL-A中,数据重分布是由Remote Subplan算子来执行。在执行的时候,Remote Subplan算子会并行地创建对应下层的执行进程和对应的DN连接,每个DN都会创建对应其他DN的各个链接,这就会导致链接数和进程数急剧膨胀,给服务器造成很大的压力。

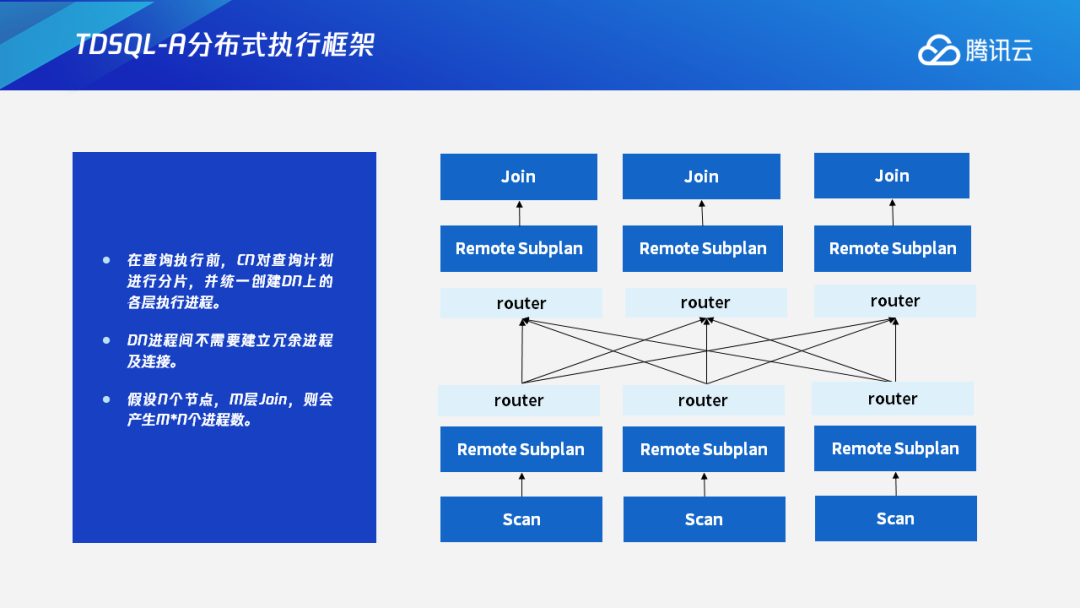
1.3 TDSQL-A分布式执行框架
针对原分布式架构的缺点,我们设计了一套全新的分布式执行框架。在这种执行框架下,查询执行前CN会对查询计划进行分片,并创建DN上的各个执行进程,每个DN的进程间不需要再建立冗余的进程及连接。这可以减少不必要的进程和连接,减轻服务器的负担,并且能够做到比较好的线性扩展性。数据交互则是通过中间的router——FN节点来进行数据交换,这是当前TDSQL-A的分布式执行框架。
二、查询计划分片策略
2.1 查询计划分片过程
之所以要对查询计划进行分片,主要是因为一个分布式的查询计划,在绝大多数情况下,必然会包含数据的重分布。在我们的执行框架中,根据数据重分布进行查询计划的划分。
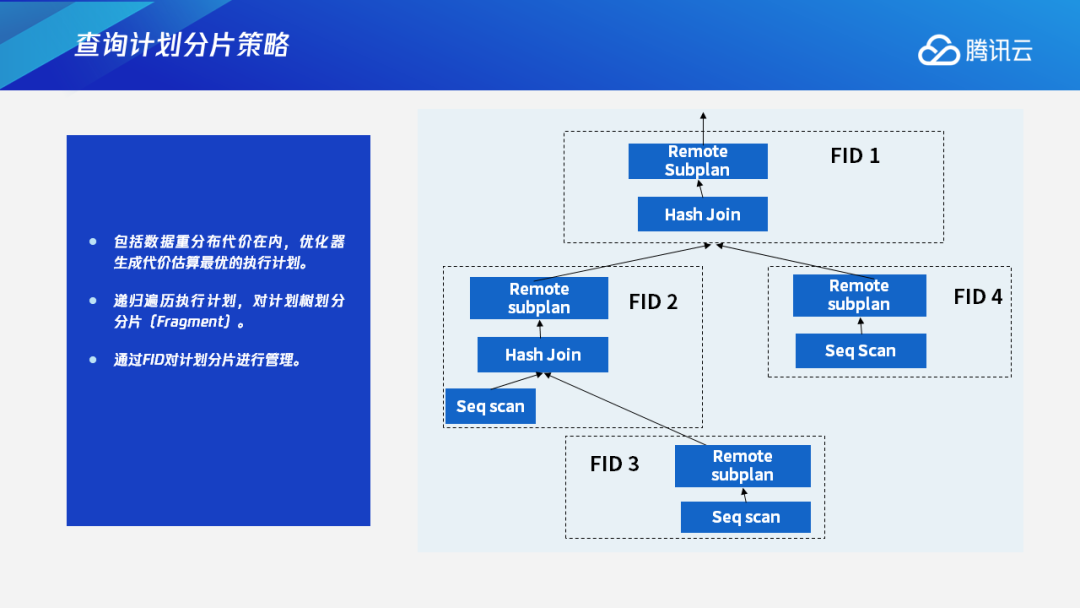
首先包括数据重分布的代价在内,优化器会生成一个代价估算最优的执行计划。在这个执行计划上,我们会做计划树的划分分片——把每一个数据重分布的节点下面的子数作为一个计划的分片,再通过FID来对每一个计划分片进行管理。
以下图为例,假设有一个两层的Hash Join,每一层涉及到一些对应的数据重分布,就会有一个四分片的查询的产生。
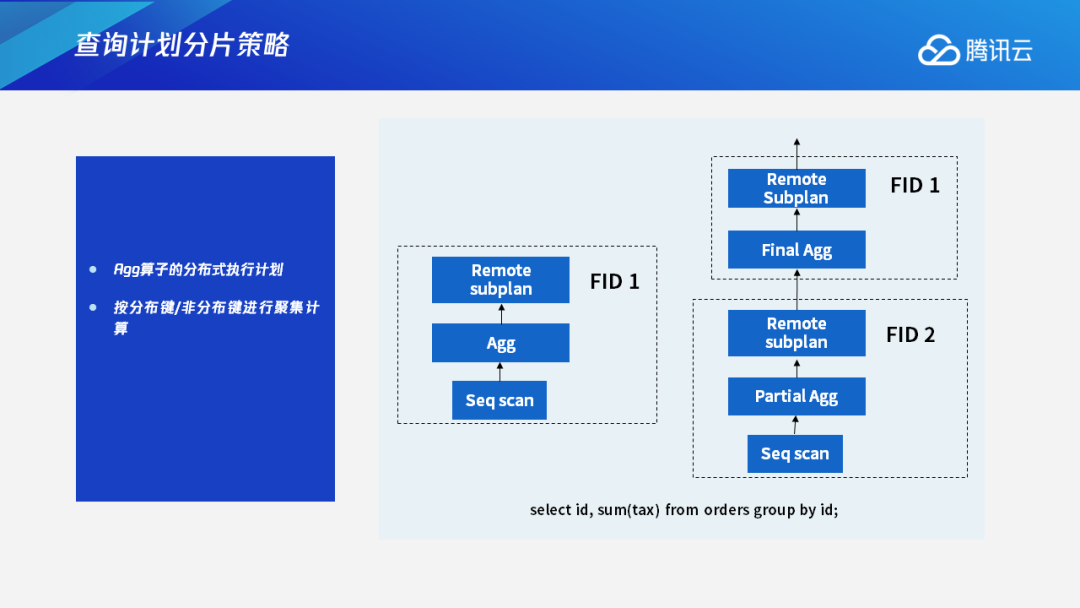
2.2 Agg算子执行计划
在分布式数据库里面,对其他的算子,也会生成一个分布式的执行计划,比如OLAP场景里面经常使用的执行聚合计算的Agg算子。在聚合计算中,比如group id正好是表的分布键的情况下,可以生成单独的分片,就像下图中FID 1这样的分片。每个Agg操作都是在DN本地执行,最后汇总到CN上得到一个最终结果。但是在有些情况下,比如聚合键不是分布键的情况下,就会在最下层的节点上做部分的聚合操作,在上层的节点经过数据重分布之后再做最后的聚合操作,得到最终结果。这就是一个分布式的Agg算子的执行计划。
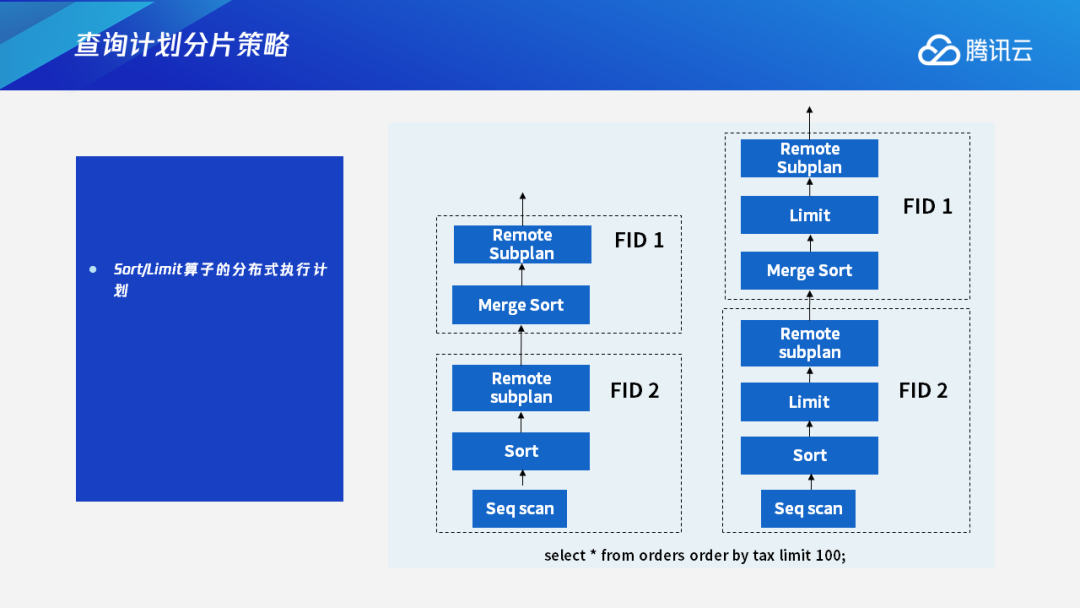
2.3 Sort算子&Limit算子执行计划
Sort算子还有Limit算子也是同样的逻辑。
对于Sort算子,我们会在DN本地先做一次排序,经过数据重分布后,在上层节点再进行归并,最后得到最终的排序结果。
对于Limit算子,我们会把它进行下推。比如说下面这个例子中,这条搜索语句是查询前100名的test order,这样的话我们会把Limit算子进行下推,每个DN只返回Limit 100条数据给上层节点,上层节点在收到结果之后再进行合并排序,最后取Limit 100的结果作为最终结果返回给上层。
三、异步执行流程控制
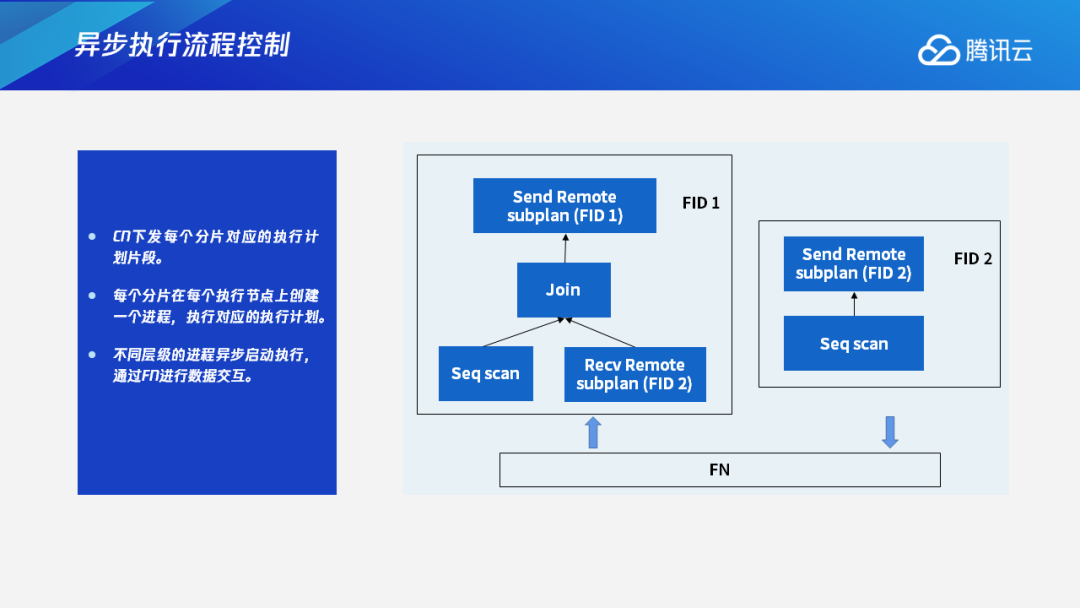
3.1 异步执行具体流程
在生成查询计划的分片后,CN会下发每个分片对应的执行计划片段,分别发送给各个DN,然后每个分片在每个执行节点上会创建一个进程,执行对应的执行计划。不同层级的进程异步启动执行,通过FN进行数据交互。
下图中可以看到,这里有两个查询,分别是简单的Join查询,以及数据重分布的Join查询。如果是传统的数据库执行流程,就会先启动下层节点,再启动上层节点。但在我们设计的这种执行框架下,FID 1和FID 2是同步启动的,它们之间通过FN来进行数据交互。
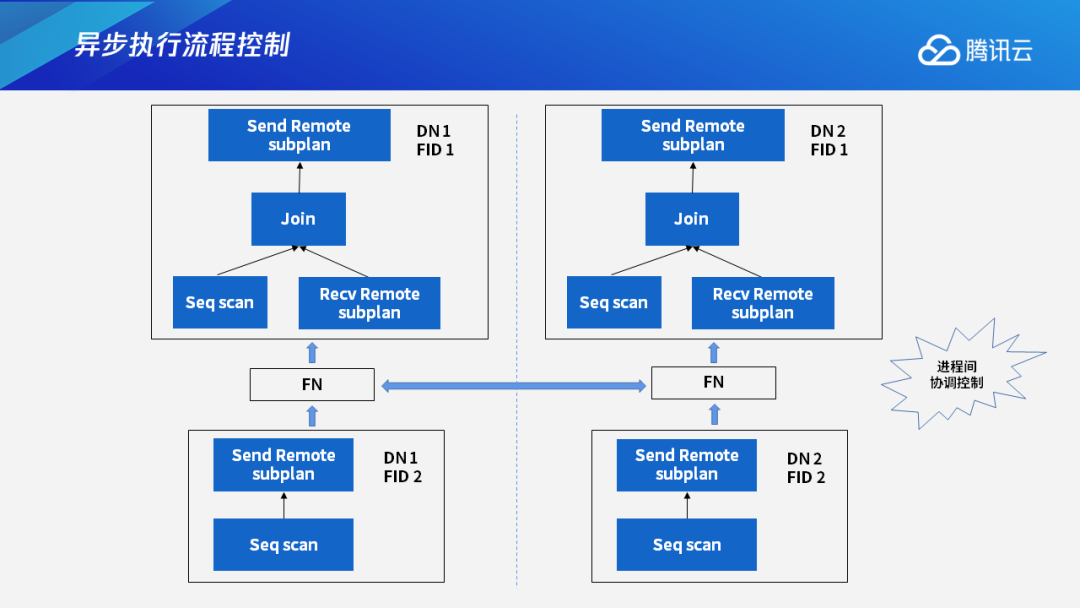
如果在有两个数据节点的情况下,Join查询怎么启动执行进程呢?因为有两个分片,还有两个数据节点,所以在执行的过程中,有四个进程在同时执行。
最下面的这两个分片,都属于FID 2,但分别在DN 1和DN 2上执行,执行对应的计划分片。对其中一个表进行扫描,再通过FN节点进行数据交换。上面的这两个分片都属于FID 1,分别在DN 1和DN 2上执行,它们分别获取自己所需要的数据,同时执行自己的执行计划分片。最终,两个FID 1的执行进程会把最终结果发送给CN。这四个进程是同步执行的,在数据交换的时候通过FN来进行。
3.2 自适应流程控制
TDSQL-A执行框架最大的难点就在于进程间如何进行协调和控制。针对这个问题,我们设计了一个具有自适应特点的异步执行的流程控制机制。它主要有以下三个方面的特点:
●灵活控制执行进度。根据实际执行情况,DN动态地控制各个进程之间的执行进度。
●根据前端设置按需执行,优化资源利用,快速响应异常。**比如前端发送Cancel请求时,能够及时响应处理。如果任何执行进程发生异常,也能够快速响应处理。
●保证分布式事务一致性。涉及修改操作的分片会开启事务,并且同步执行这个事务的提交或者回滚等操作。

下面我将分别从这三个方面来介绍一下这个异步执行流程控制机制。
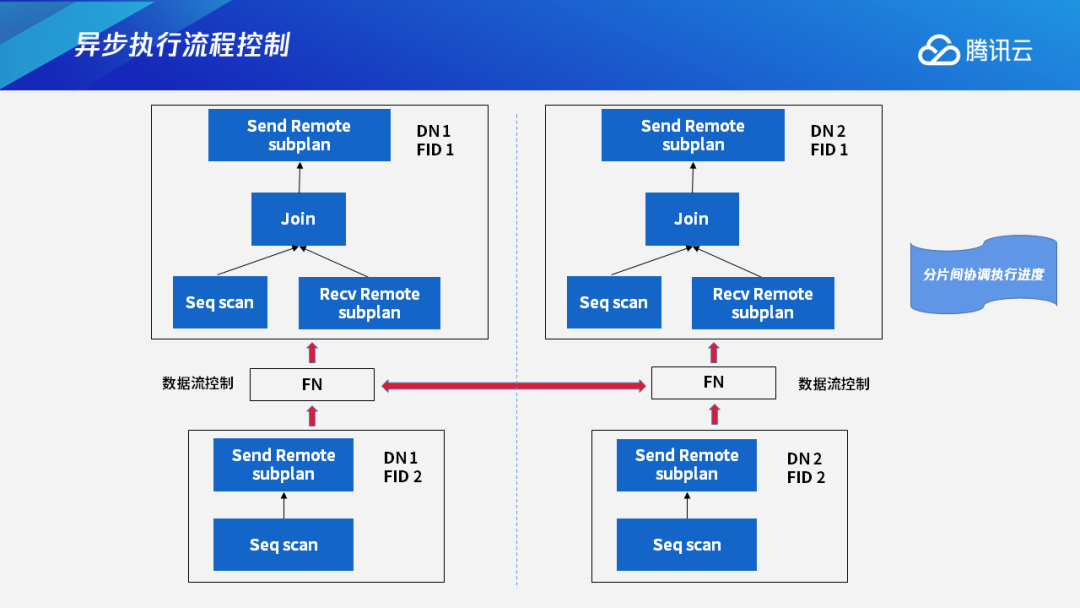
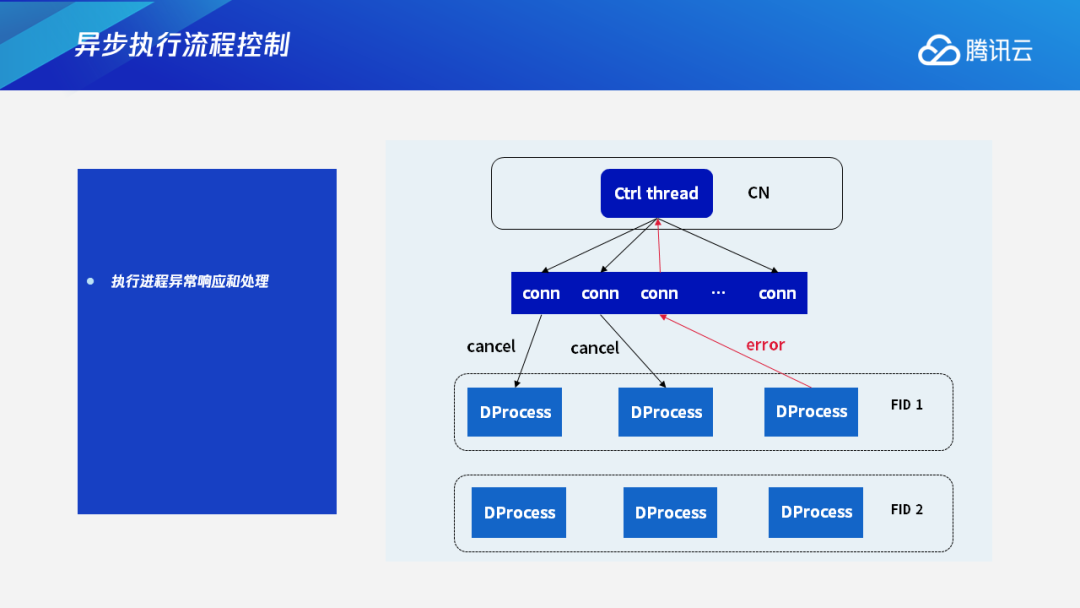
在各个进程同步执行的情况下,如果有的进程出现执行阻塞的情况,该怎样互相协调呢?
以下图为例,假设上层节点中的FID 1的这两个执行进程执行比较慢,而下层FID 2的这两个进程执行进度比较快的时候,下层FID 2的两个进程会源源不断地向上层发送它们的执行结果。如果不加控制的话,不仅会浪费下层FID 2的执行资源,而且会造成网络的阻塞。
针对这种情况,我们设计了进程间可以互相协调执行进度的控制机制,主要通过数据流控制来实现。如果上层节点的执行进度慢于预期的时候,下层节点会进行等待,等到上层节点能够继续执行时,下层节点才会继续做自己计划分片的执行,把数据发送给上层节点。这样可以在执行节点上达到资源分配和使用较优的效果,空出来的网络资源和CPU/IO资源就可以让渡给其他查询来执行。
我们的控制机制中除了数据流之外,还有控制流。由CN来监听并统一处理控制流消息。DN节点的执行进程,又叫Dprocess,在执行的过程中会随时响应控制消息。以下图为例,如果用户执行一个比较长的进程或者误执行了一个Query,在执行几分钟后,不想再执行了,就会给CN发送一个Cancel信号取消查询,这时CN会把这个信号通过链接发送给每个执行进程,DN上的执行进程收到信号后就会终止执行,及时把资源让渡出来给其他的查询使用。这是Cancel消息的处理过程。
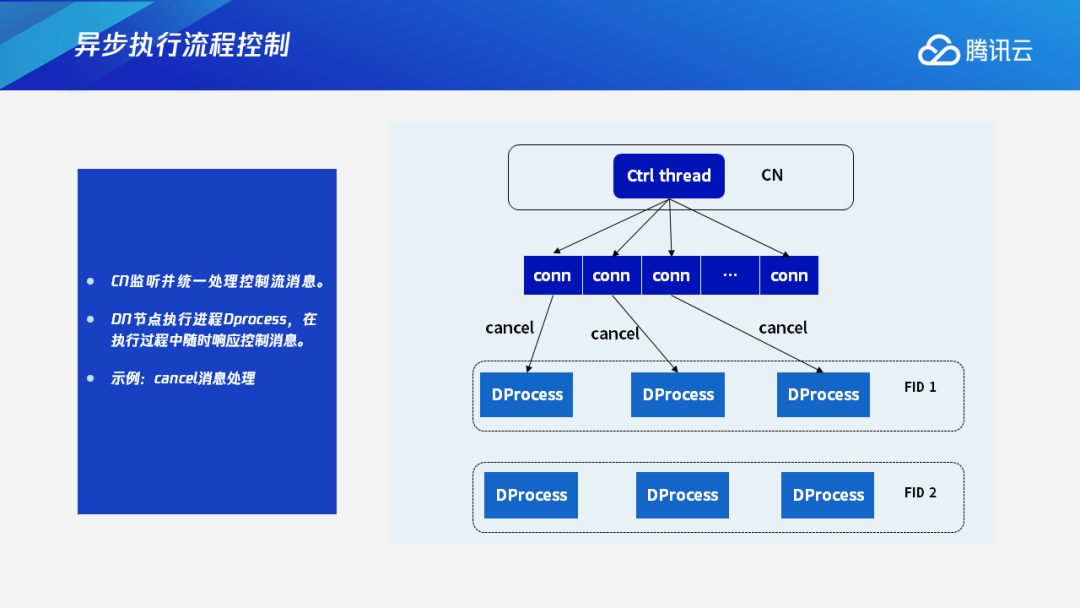
除了Cancel消息外,我们还处理Error信息。在执行进程同步执行的过程中,每个执行进程之间通过FN来进行数据交换。如果其中一个进程发生Error,比如在处理的过程中资源不足,或者在处理过程中遇到数据错误或其他错误等,这时它会报Error信号,通过链接将这个信号上报给CN。CN在收到执行进程Error消息后,会进行消息处理,然后下发给其他的执行进程,让它们终止执行。也就是说,如果任何一个并行执行的进程发生了错误,我们也能够及时取消、结束这个查询。
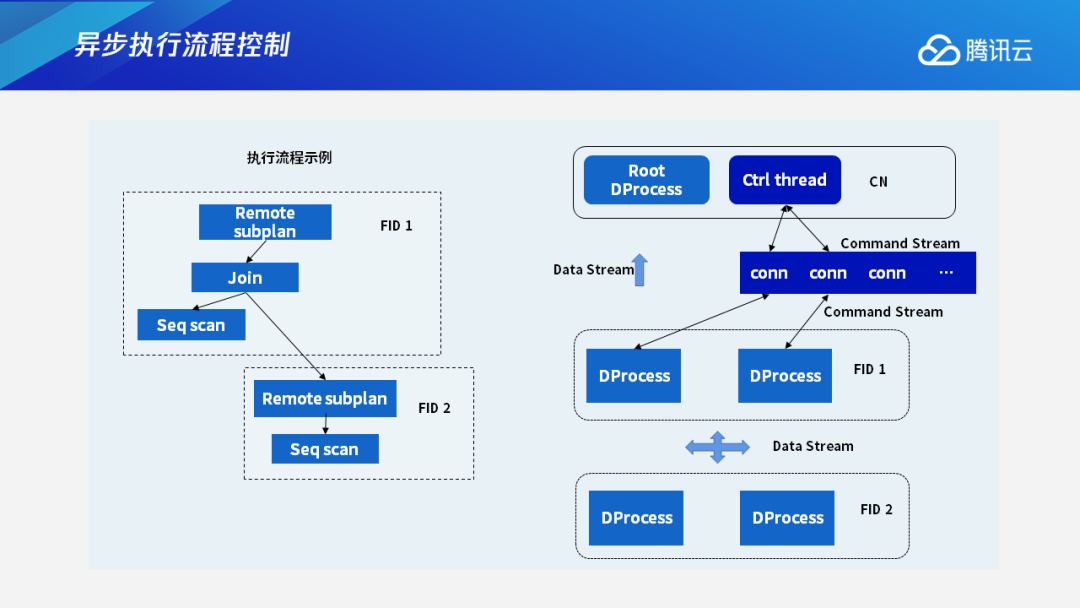
3.3 执行流程示例
下图是一个总体执行流程的示例。左侧是一个带有数据重分布的Join查询,它的整体执行流程可以用右边的这个图来表示。四个执行进程之间会有数据交换,是通过FN来交换数据流,最终结果也是通过FN数据流返还给CN,CN上还有一个后台线程,通过控制流控制各个执行进程之间的执行,这就是整体的执行构架。
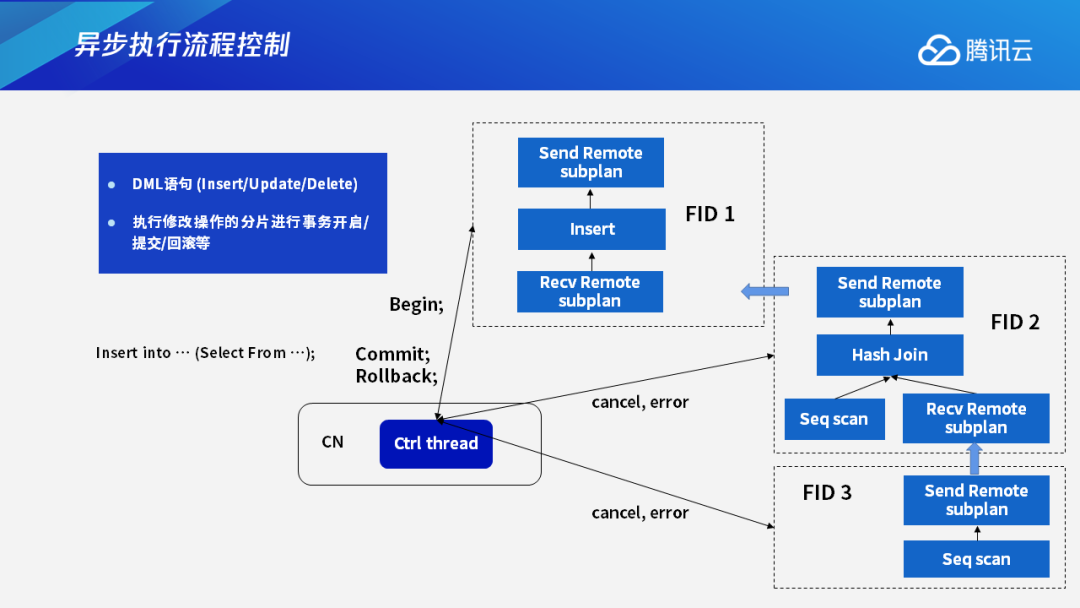
除了查询语句外,我们还会遇到DML语句。DML语句即Insert、Update、Delete语句,它们需要进行分布式执行事务的提交或者回滚操作。在执行过程中,我们主要是把修改操作集中在一个分片内,然后在执行修改操作的这个分片内进行事务的开启、提交和回滚等操作。这个事务的命令同样也是通过控制线程来进行发送,其他线程也同样是通过Cancel或者上报Error来处理控制消息。
这里举一个最典型的例子。执行Insert into语句时,如果后面跟的是Select From,也就是在其他的表中经过查询操作获得一个结果集,把这个结果集插入到一个表中,此时我们在其他分片上执行只读操作,只在第一个包含Insert的分片上执行修改操作,这个修改操作就涉及事务的提交和回滚。
3.4 中止处理流程
这里重点介绍中止处理流程,它和Cancel流程不一样。中止处理流程是CN在获取了部分的查询结果集后中止执行。典型的应用场景是把查询结果做分页展示。在很多前端的应用中,查询结果就是用分页展示的形式展现在客户端页面上的。
比如一个查询,第一页可能有1000条查询结果,下一页则是下1000条查询结果。CN在查询执行的时候,只要执行获取到1000条结果,就可以返回给前端,让前端做展示或者处理。因为前端程序处理查询结果也需要时间,在这时,后端就可以继续执行获取下1000条查询结果,这样就能实现前端和后端并行执行,取得执行效率整体最优化。
在这种执行流程下,CN会先获取前1000条结果——该数值用户可以自由设置,在获取到指定结果集之后CN先返回给前端,前端处理完之后,如果需要再获取,CN就会继续返回下一批结果。
如果前端查询取消,比如用户可能看5页或者6页之后不想再看,或者是前端应用处理到第几批数据之后不再处理直接返回,在这样的情况下,查询其实不需要再继续执行,这时CN会下发一个End query信号,然后在并行执行流程上也会及时响应这个信号来结束查询。下图就是简单的展示。
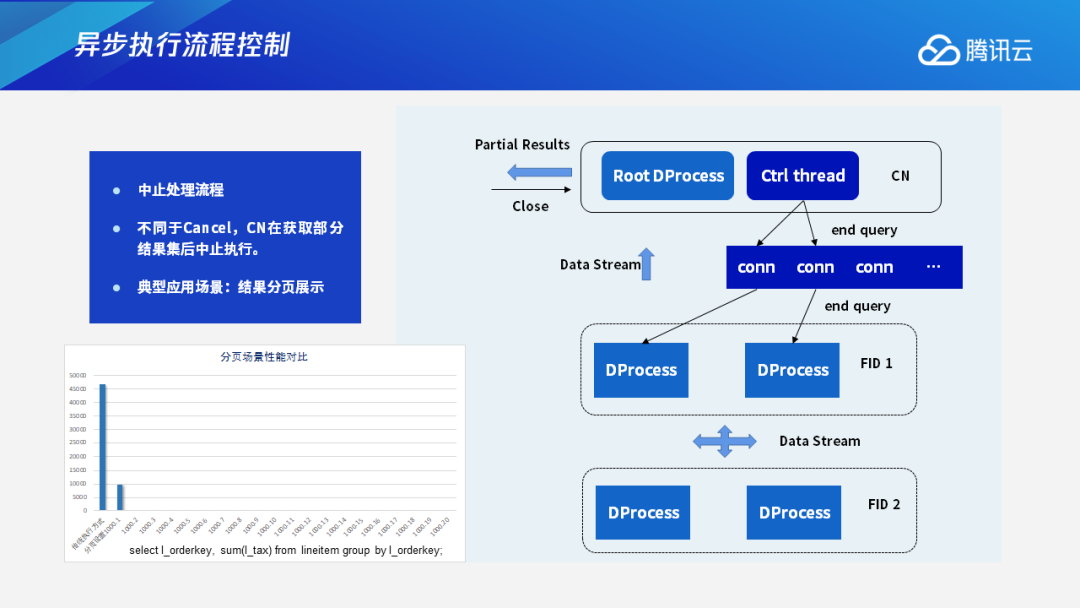
左下角是分页场景下的执行性能对比。最左边的这个柱子显示的是,如果这个查询在正常执行情况下,在返回第一条结果的时候所需要的时间,第二个柱子是如果设置了fetch size是1000条时,它所需要执行的时间。如果没有设置fetch size,在传统的执行方式下,这个查询的执行时间是非常长的,但如果我们先设置返回1000条结果,这个查询时间可以大幅缩小。同时在继续执行的时候,后续的每一批的查询结果的执行时间几乎可以忽略不计。因为前端在接受查询时,我们后端也在同时处理继续获取查询结果。
四、子查询执行优化
在OLAP场景下一些比较典型的包含有子查询的执行优化。OLAP子查询基本上可以分为两类:一类是非相关的子查询,一类是相关的子查询。
4.1 非相关子查询执行
非相关的子查询,指的是子查询的结果集是一个固定的值,跟外层的查询没有关联。对非相关子查询,我们设计了“异步执行、一次执行”的机制。子查询对我们的执行框架来说,是另外的一个分片,它跟父查询可以并行执行。当父查询需要子查询的结果时,子查询已经执行完毕了,父查询可以直接获取结果继续执行。
下图中,FID 3分片就是代表子查询的执行分片。Hash Join在执行过程中,每个分片都是并行执行的,在FID 2做扫描的时候,如果它不需要子查询的结果,就可以不用等待FID 3的执行结果。当它需要子查询的执行结果时,因为FID 3和FID 2是并行执行,就可以直接获取到这个结果并使用。这是非相关子查询的执行。

4.2 相关子查询执行
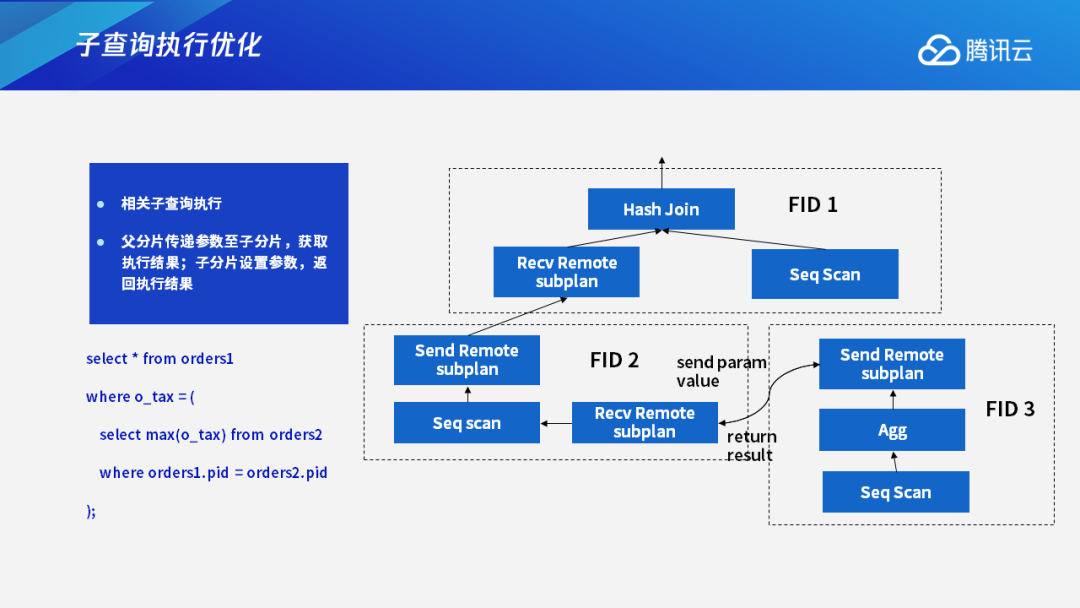
更为复杂的是相关子查询的执行。在执行过程中,相关子查询的执行结果是跟父查询的传递条件是有关系的。
以下图为例,在order 1和order 2的pid是相等的情况下,查询会从order 2这个表中取出最大的tax值。这个tax的值再和外层的order 1的tax值做等值比较,最后获取等值比较成立的那个结果,作为最终的查询结果。
相关子查询的执行,一般情况是由父分片传递参数到子分片上,子分片会设置这个参数值,然后返回查询结果。比如FID 2先做一个scan的操作,它在要获取子查询的值时,会先把order 1的pid先通过fragment之间的连接传递给FID 3,FID 3在取得并设置了order 1的pid值后,执行它本身的执行计划,最后获取的结果再传递给FID 2,然后FID 2获取结果后再继续进行计算,可以看到这是一个非并行的执行。之所以这样,主要是因为子查询FID 3的每一条执行结果其实是和FID 2下发的参数值是有关的。因此它们俩不能并行执行,这样的子查询执行效率就比较低。
针对这种情况,我们做了相关子查询的优化,会在计划生成阶段由优化器自动改写查询计划。在很多应用中,查询语句可能是由前端应用自动生成的,并且数量很大,如果都用人工来进行优化改写,工作量会非常大。在这种情况下,我们在优化器中实现了一套基于代数变换规则的自动改写,会把相关子查询,根据一定的规则改写成等价的Join查询,之后再进行其他优化,生成最后的查询计划。
经过优化后,相关子查询的性能提升非常明显。下面这个图就是在子查询改写之后,它的优化性能对比。可以看到,如果按照原来的执行方式,每个子查询每一次设置参数之后都需要执行一次,整个查询的执行时间非常长。如果改写成等价的Join查询之后,它的执行效率非常高。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号