
TDSQL-C 数据库架构
,TDSQL-C Serverless 在去年年底发布,补充了MySQL生态下 Serverless 的空缺。开发者不再需要去权衡规格和费用,不用担心过多的扣费,也不用担心购买很小的规格就扛不住突发流量。其实最大的特点是三个,按负载自动扩缩容,进一步以实际负载进行计费,再进一步做到不使用的时候不付费。
TDSQL-C如何做到以上特点?首先看整体架构,其实TDSQL-C分为两款产品,for MySQL、for PostgreSQL。今天主要讲前者,它的整体是计算层和存储层分离的架构,设计原则是尽可能地复用云上组件。计算层用了腾讯云数据库内核团队TXSQL技术,跟社区的MySQL是完全兼容的,且能复用社区版bugfix和特性;主从之间通过redo进行复制;另外,本地不会存数据或者日志文件,日志文件下放到存储层。在存储层上利用了云硬盘基于CBS打造的 HiSTOR 存储平台,保证数据的复制以及GB级的回档能力,以及提供了SSD、混存、多种性能和成本的选择方案。在存储层平台里,我们自己增加了DBStore的组件,来接收计算层的日志、进行数据库的日志回放以及存储,以及提供算子下推的数据库能力。大家如果对数据库不是很了解,也不要被这些名词吓到。使用TDSQL-C之后,跟用MySQL几乎是一致的。只是我们内部做了存储分离,分离之后可以对整个计算层做非常灵活和自由的资源分配,这也是我们实现 Serverless 最重要的基础。
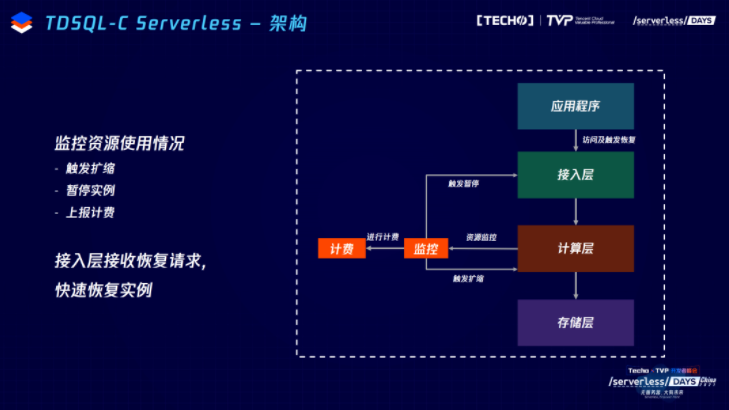
Serverless 是基于监控的方式实现,通过CPU和内存的资源消耗进行计费。如果发现使用资源过多或过少则触发自动扩缩容,没有连接时,会触发暂停的逻辑,就把计算层资源回收,因此不再计费。之后我们会通知这个接入层,MySQL内核已经不再计费,用户访问接入层会触发恢复逻辑。计算层重新恢复之后,提供数据库服务给应用程序。
再提一下之前说的三个特点,自动扩缩容、按使用计费和不使用不计费,如何做到更高要求?
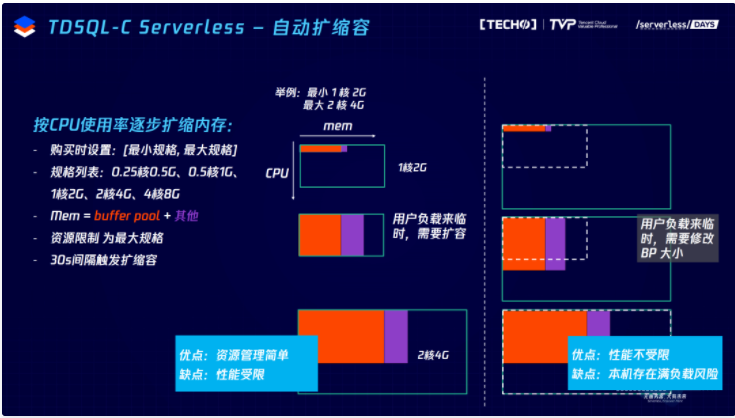
首先,自动扩缩容。****我们希望扩缩容速度是秒级的,而且扩缩容的过程是用户无感知的。用户购买一个 Serverless 的时候,需要指定一个扩缩容的范围,最小规格和最大规格,即指定CPU内存资源的概况。比如用户指定一个最小规模1核2G最大规格2核4G,图中纵轴方向是CPU,横轴方向是内存。左边的矩形框是对资源的限制,限制在1核2G的最小规格上。这种方案下,如果用户直接把负载打满,就是用满一核的CPU,此时用户就无法用到更多的CPU。监控发现后,就会扩成2核4G,这时候用户就可以用更多的CPU,内存也可以用得更多。这种方式下的缺点在于存在CPU使用的限制,并不能立刻到最大的CPU。最终我们采用右边的方案,一开始就限定到最大的规格2核4G,用户负载来临的时候,可以直接用到超过一核甚至两核的CPU,我们根据CPU使用量动态扩缩缓存的大小。右边的方案优点在于CPU使用不再受限,可以立刻用到最大的CPU资源。缺点在于存在一个整机满负载的风险,当然通过很多运维手段和智能调度的算法来避免这样的情况发生。
**
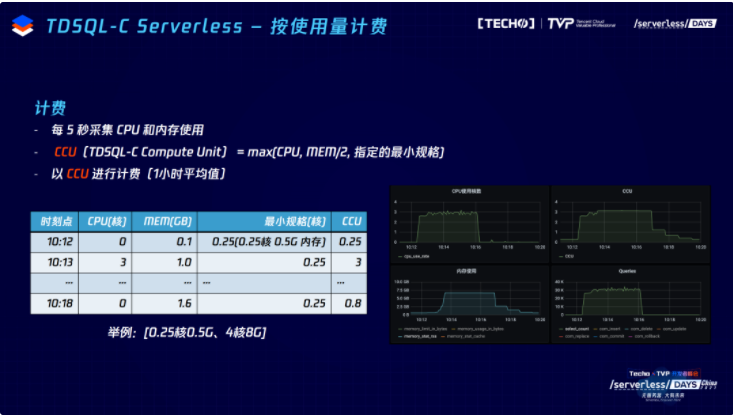
第二点,按使用量计费,我们希望秒级别,而不是目前大部分云数据库提供的是按一小时内最大的规格进行按量计费的方案。另外一个特点,是以任意单位的资源计费,不是不足一核按一核收费,而是用户用了0.6核那就按0.6来收费。我们每5秒采集一次CPU和内存的消耗,根据计算得到的CCU算力进行计费,CPU、内存的二分之一和最小规格取最大值就是算力单位CCU,每一个点都会作为一个小时的帐单的一部分,1小时出一次帐单。以这张图为例,用户刚开始的时候没有任何负载,刚开始是0.25 CCU,也就是最小规格,用户负载来的时候,可能CPU立刻到达3核,内存的调整没有跟上的话,就按照CCU为3计费;当负载过去之后,BG调整慢慢缩小,这时候内存最大,就是按0.8 CCU进行收费。
不使用不收费的话,我们希望做到的是不使用的时候成本极低,从使用到不使用判断的时间非常短。从不使用到使用存在恢复时间,也就是刚才说的冷启动时间,是秒级的。也是因为整个计算存储分离的架构,完成不使用不收费的能力是水到渠成的事情。

运行中的实例,监控发现10分钟没有请求,就会转为暂停的实例,接入层负责接收后续的用户请求。用户请求之后,会迅速地唤起计算进程提供服务。数据库场景下,冷启动优化有很多问题需要解决,比如获取之前的连续日志位点,以及进行BP和事务系统的并行处理化,在内核上以及管控系统上我们做了非常多改进。目前我们的冷启动时间是2秒,在关系型 Serverless 数据库里面目前是领先的,但还是不够,目前还在优化当中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号