游戏业务安全实时计算集群:云原生资源优化实践
「毛东方,腾讯后台开发工程师,负责IEG-业务安全部的后台实时系统Kubernetes相关的开发与运营,目前主要致力于提高集群的资源利用率,减少机器成本。」
背景
随着公司内部上云的呼声越来越高,越来越多的团队已经完成业务上云的进程。
然而,本人所在平台的应用部署上云后,在资源管理方面依然出现了一系列的问题,这些问题或多或少都对成本优化或应用的服务质量造成了一定程度的影响。
a. 应用资源使用设置不合理
云原生的资源管理方式要求应用在部署之前,提前设置好 CPU、内存、磁盘的最小和最大资源使用量,并且之后不能改动(除非重建所有实例),这要求应用在正式上线之前预估其资源需求。线上的资源需求可以通过压测来模拟,但难免和实际情况有出入;此外应用上线之后,其资源使用会随着业务、策略等的动态更新而发生变化,因此在创建之初设置的资源使用量并不能很好地反映实际的资源需求,容易造成资源浪费或资源不足。
b. 相同类型的 Pod,各项资源使用有差异
在实际运行过程中,我们发现即使是相同的 Pod,其 CPU、内存、磁盘、网络等监控指标也会有很大的差异,极端情况下会相差60%。有时会遇见大部分 Pod 的 CPU 利用率都很低,个别 Pod 的 CPU 利用率却长期在90%以上,最稳妥的解决方式为扩容,但是这样却会造成资源的大量浪费。例如下图为一段线上环境相同 Pod 的 CPU 利用率监控,可以看到不同的 Pod 其 CPU 使用也存在几倍的差距。
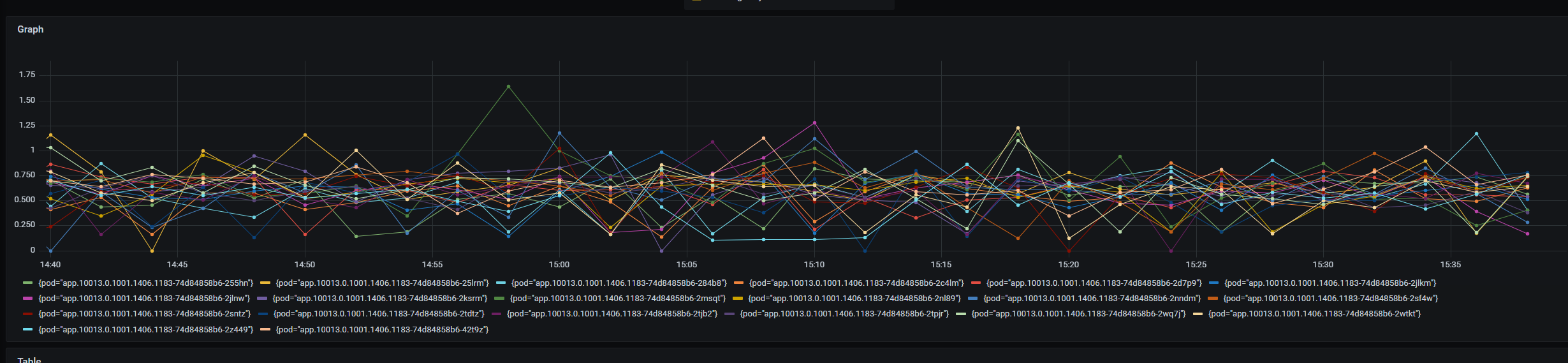
经过进一步分析,出现该现象的原因有以下几点:
Pod 部署的节点性能不同 Pod 部署的节点各项资源的消耗不同 Pod 在细粒度的时间单位内,占用的资源不均衡
c. 多维度空闲资源碎片化严重
集群在运行一段时间后,随着节点不断上架下架,Pod 不断扩缩容,会有越来越多的空闲资源分散在整个集群,并且这样的闲散资源同时存在多个维度(例如节点 CPU 耗尽,但是内存还剩很多)。这样的多维度闲散资源通常难以集中并下架,也会造成资源的浪费。
d. 突发流量洪峰导致资源不足
游戏安全服务在正常运行时有着明显的周期性,并且周期与周期之间峰值变化不大,一般情况下晚上九十点流量最高,后半夜流量最低。但是在某些突发情况下(突发性热点、大型节假日等),服务的请求量会在短时间内大幅上涨,造成资源不足,影响服务正常运行产生告警。
e. 资源维度有限
原生的调度策略只会基于 CPU、内存、磁盘这三个维度判断节点资源是否充足。然而实际情况下,磁盘 IO、网络 IO、连接数等维度同样是决定业务是否正常运行的关键。因此资源维度的匮乏会对业务正常的保障造成影响。
## 现有解决方案上述提到的问题在上云的实践过程中几乎遇到,因此前人在遇到这些问题时已经提出了一些解决方案,具体如下:
HPA:基于业务实际运行的性能指标(一般为 CPU),自动变更 Pod 数量 反亲和性:设置 Pod 反亲和属性,使得相同 Pod 尽量部署在不同节点,优化均衡性 在线离线混布:在同一集群混合部署在离线业务,离线业务在在线业务的低峰期扩容,提高低峰期利用率 Descheduler:定期扫描节点资源和部署情况,通过驱逐 Pod 平均节点负载以及均衡 Pod 部署 Dynamic Scheduler:基于节点实际负载调度 Pod,优先调度到低负载节点,优化均衡性 高低水位线:设置高低水位线,扩容时 Pod 优先调度到负载处于高低水位线之间的节点,缩容时优先缩容部署在低水位线下节点的 Pod
这些解决方案对上述问题的效果如下表:
| 解决方案 | 资源设置不合理 | 相同 Pod 资源使用有差异 | 多维度空闲资源碎片化 | 突发流量 | 资源维度有限 |
|---|---|---|---|---|---|
| HPA | × | × | × | √ | × |
| 反亲和性 | × | √ | × | × | × |
| 在离线混布 | × | × | √ | × | × |
| Descheduler | × | √ | × | × | × |
| Dynamic Scheduler | × | √ | × | × | × |
| 高低水位线 | × | √ | √ | × | × |
从表中可以看出,上述解决方案只是解决了部分问题,没有解决资源设置不合理、资源维度有限这两个问题。此外,缺少一个整体的解决方案来对上述所有问题进行统一优化。因此,后文将分享一些本团队对上述问题的解决方案。
## 优化方案基于历史监控的预测值 predicts 替代 requests
对于游戏安全的实时计算业务,其资源使用往往具备明显的周期性,并且周期之间变动不会太大,因此可以基于 Pod 的历史监控数据预测未来的资源使用情况,并且准确度较高,以此解决资源设置不合理问题。
### 预测模型预测模型旨在基于 Pod 的历史多个周期监控数据,预测下个周期的资源使用数据(一般为基于历史一个月预测未来一周)。主要有以下几种预测方式:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 直接使用历史数据 | 1. 逻辑简单 2. 可解释性好 | 1. 准确率低 2. 相同类型 Pod 预测结果相同 |
| 周期因子法 | 1. 逻辑简单 2. 可解释性好 | 1. 只适合周期性场景 2. 无法预测趋势 3. 对节假日、活动等特殊场景无法建模 |
| Prophet | 1. 预测准确率高 2. 综合考虑趋势项、周期项、节假日项 3. 可处理异常值和缺失值 | 1. 预测结果存在波动,鲁棒性差 2. 复杂度高,计算速度慢 |
我们基于真实场景的数据进行了测试,输入为历史两周的小时级别的 CPU 利用率,输出为未来一周小时级别的 CPU 使用率,评价指标为 MAPE(Mean Absolute Percentage Error),具体结果见下图。
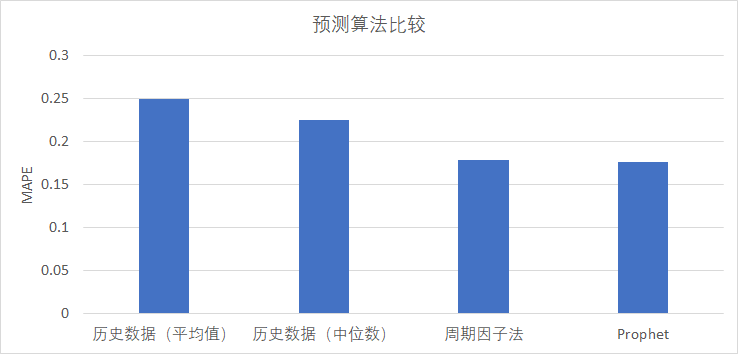
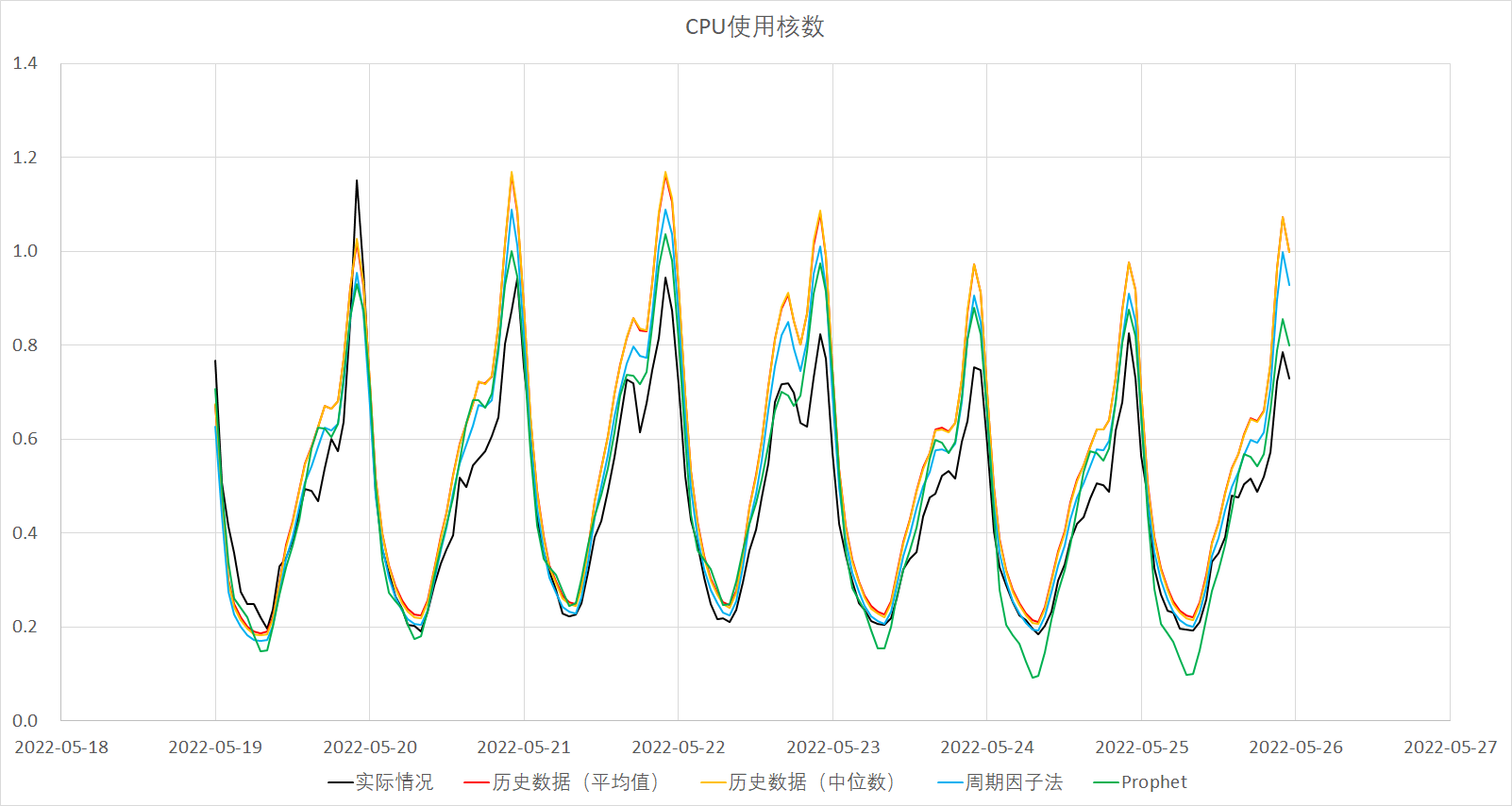
根据各算法得出的预测结果比较见下图:
云原生的调度方式是基于 requests 进行的,为了实现基于 predicts 调度,需要对调度器的功能进行扩展,这里推荐云原生提供的 Scheduling Framework,用插件化的方式添加用户自定义的功能。
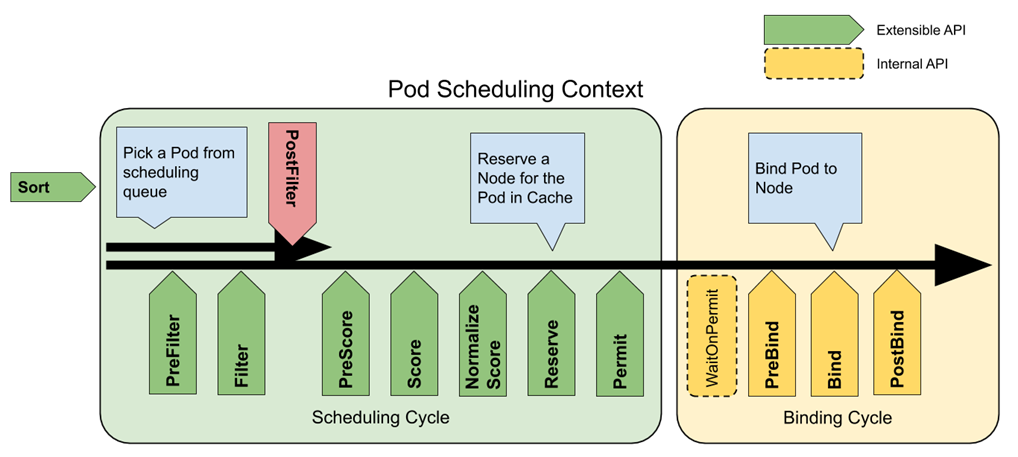
该框架将调度过程划分成排序、过滤、评分、批准、绑定,共五个阶段,具体功能如下:
排序:对调度队列中的 Pod 进行排序 过滤:过滤掉不满足 Pod 运行需求的节点 评分:对通过过滤阶段的节点进行打分 批准:选取评分最高的节点,并判断是否绑定 绑定:将 Pod 调度到最终选定的节点
上述每个阶段都支持用户添加自定义的插件。为了实现基于 predicts 调度,需要添加一个过滤插件,计算节点已绑定 Pod 的 predicts 和待调度的 Pod predicts 之和,并过滤掉不满足资源需求的节点。
### 支持多维度资源针对业务安全现有的服务,除了 CPU、内存和磁盘大小外,磁盘 IO、网络 IO 对于业务运行也非常重要。所以在收集 Pod 监控数据时,额外收集了这两个维度的数据,在调度时也会计算在内。同时如果业务有其他额外的资源维度,也可以很方便的扩展。这样解决了资源维度有限的问题。
### 整体编排资源均衡性是解决相同 Pod 资源使用有差异的重要方法,这里的资源均衡性要考虑多个维度的资源均衡性。如果仅仅在 Pod 需要调度时才考虑均衡性,那么在 Pod 调度之后,随着集群整体的部署情况变动,均衡性也会被破坏。因此,为了实现集群整体长期的资源均衡性,需要定期对集群整体进行重新规划编排。这样的整体编排同时也可以解决多维度空闲资源碎片化问题。整体编排主要分为两个步骤:
基于 Pod predicts 计算出资源均衡的部署方案,使用尽可能少的节点满足当前 Pod 的资源需求; 将计算出的部署方案应用到集群;
部署方案主要需要实现两个目标:
压缩多个维度的资源 在节点层面均衡分布多个维度的资源
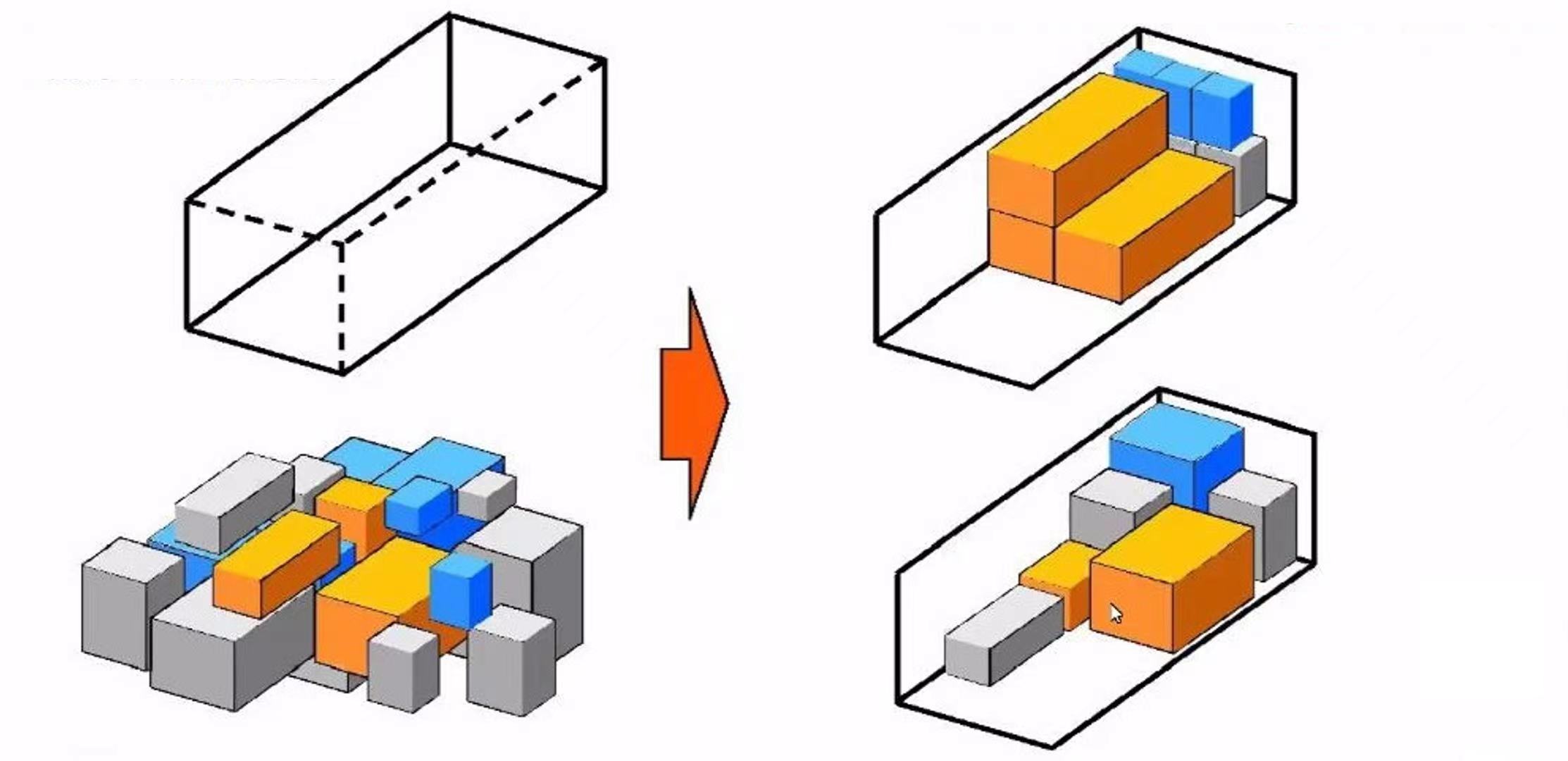
上述目标抽象来讲即为一个多维装箱问题,同时要求在装箱的同时维护多维度的均衡。对于这一类问题,主要有以下几种算法解决:
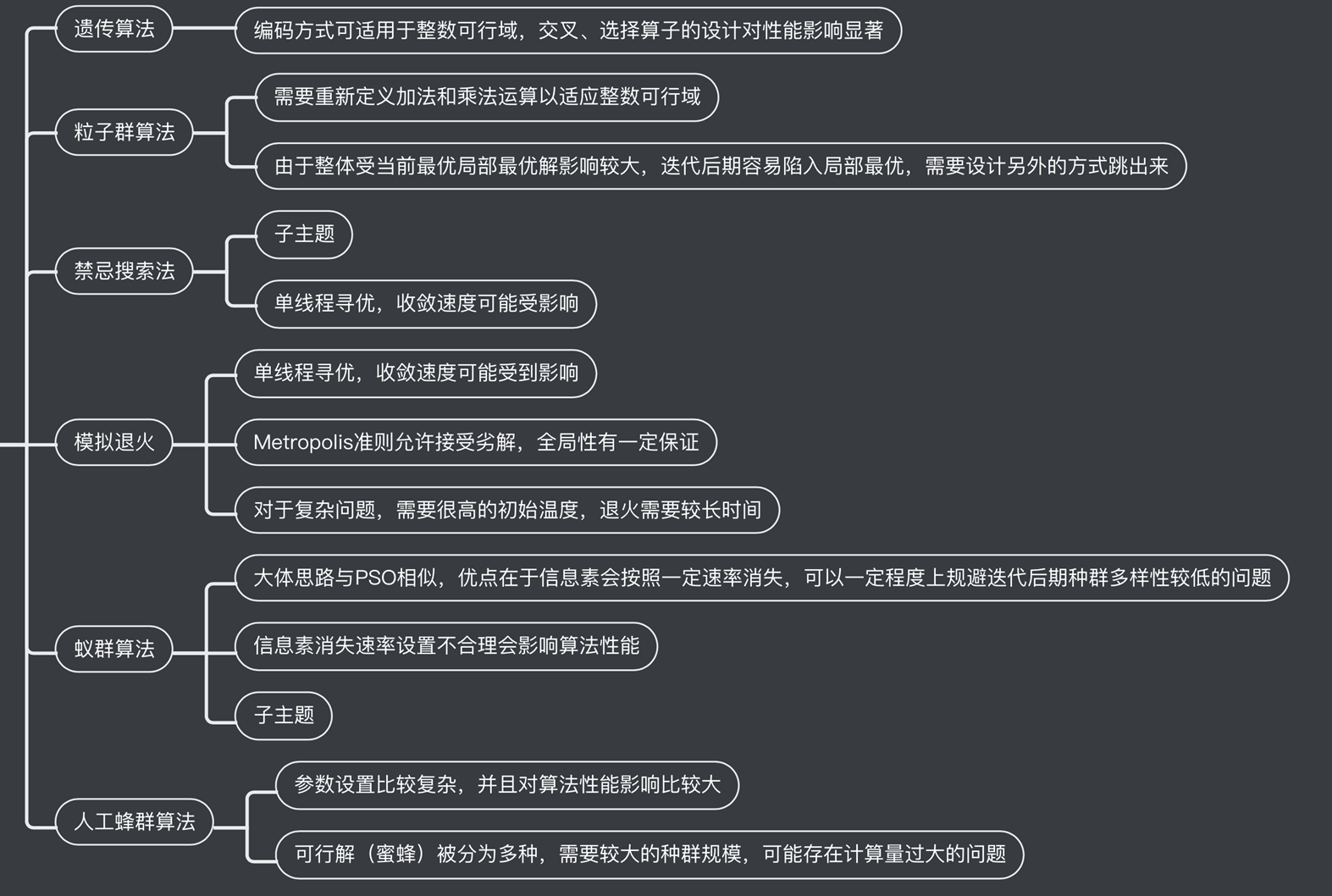
多维装箱问题的一个难点是求解容易陷入到局部最优解,另外集群中的 Pod 数量一般上万,对于装箱问题来讲规模较大,因此综合考虑,决定采用遗传算法(GA)来求解最佳部署方案,因为其具有能跳出局部最优解的特性,同时相对来讲对于大规模求解有着更好的性能。
对于遗传算法,多维装箱问题的可行解可以被设计成一个染色体。
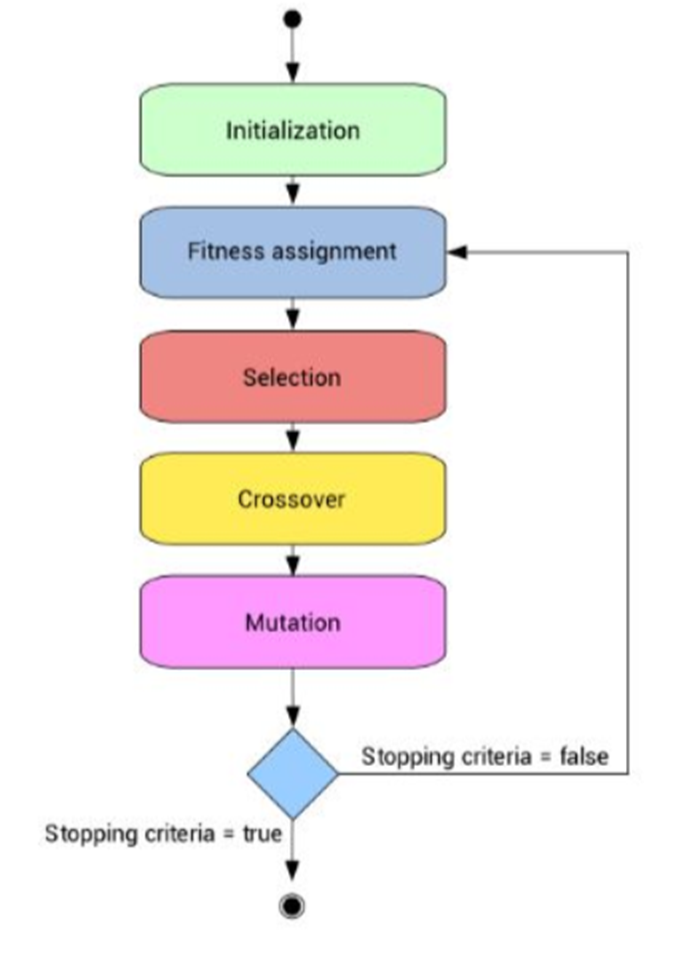
算法整体流程大致如下:
以我们线上环境的重庆集群为例,当前集群使用了69个节点,在计算部署方案之后,只需要使用27个节点即可满足所有 Pod 的运行,机器成本下降**61%**。并且为了保证服务质量,计算部署方案时节点各维度资源的最高利用率设置为不超过80%,因此有进一步压缩的可能。同时各资源维度也实现了较好的均衡性,下图以 CPU、内存为例,展示部署方案中资源的均衡性。
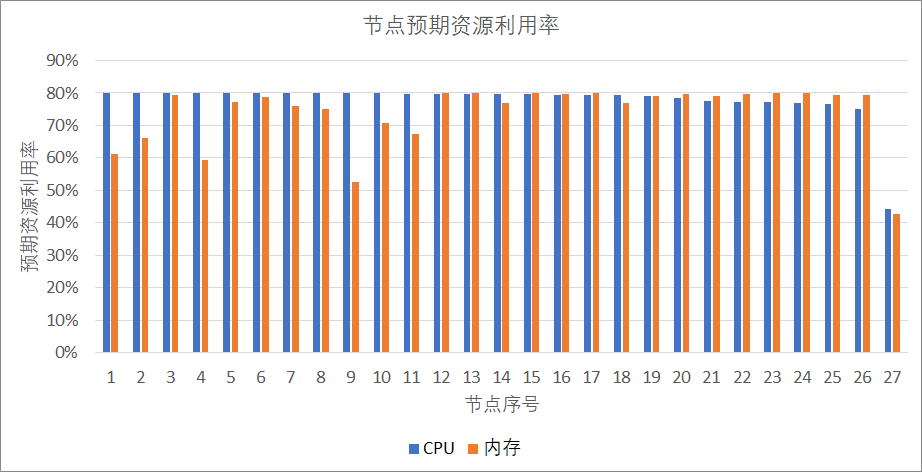
从图中可看出,除了最后一个节点没有布满,其他节点都接近我们的目标80%利用率。内存方面,大部分节点也都在60%-80%的区间内。
### 部署方案应用部署方案旨在使用最少的节点容纳当前所有 Pod,将资源使用尽可能压缩。这样会将节点分成两部分:
热节点:在方案中部署 Pod 的节点 冷节点:在方案中被腾出空间的空闲节点,可下架或用于冗余
对于大型集群而言,实施部署方案是一个耗时较长的过程,在这期间原先的 Pod 会有变动,例如扩缩容。对于缩容,只是会使原本压缩的资源使用没有那么紧密;对于扩容或者新业务部署,我们需要预留一批节点资源来容纳这些新创建的 Pod。这里建议实际使用时先评估未来的使用量,然后从冷节点中把这部分预留资源划分出来,剩余的冷节点禁止新的 Pod 调度上去,这样在部署方案应用之后,可以避免上一步腾出来的空闲节点被新产生的 Pod 占用,从而无法直接下架。
除此之外,将部署方案实际应用到节点还面临两大挑战:
如何将 Pod 调度到方案指定的节点 调度 Pod 时如何保证不影响业务正常运行
和之前相似,要想控制 Pod 的调度结果,也需要对 K8s 调度器进行功能扩展。此处仍然推荐使用云原生提供的 Scheduling Framework 实现,具体不在赘述。此处实现需要分别添加一个过滤插件和评分插件:
过滤:根据待调度 Pod 的部署方案,过滤掉已有足够 Pod 数量的节点 评分:增加热节点的评分,降低冷节点评分,使 Pod 优先调度到热节点
应用部署方案难免会对集群中的部分 Pod 进行重建,而这里的核心目标除了实现部署方案,还需要保证不影响业务的正常运行。不影响业务正常运行的一个重要前提是服务网格的改造,这方面的内容已经在IEG-大规模游戏安全实时计算服务的上云实践 的3.2节做了简单介绍,这里不再赘述。
此外,为了保证调度不影响业务的正常运行,需要根据业务的不同类型实施不同的调度策略。
## 无状态服务无状态服务指 Pod 即使立即停止也对当前业务没有影响。针对这一类型服务,需要保证的是同一时刻有指定比例的 Pod 正常提供服务。这可以通过设置就绪探针和存活探针实现,同时要求业务侧支持灰度,确保开始调度下一批 Pod 时,新启动的 Pod 已经可以正常提供服务。
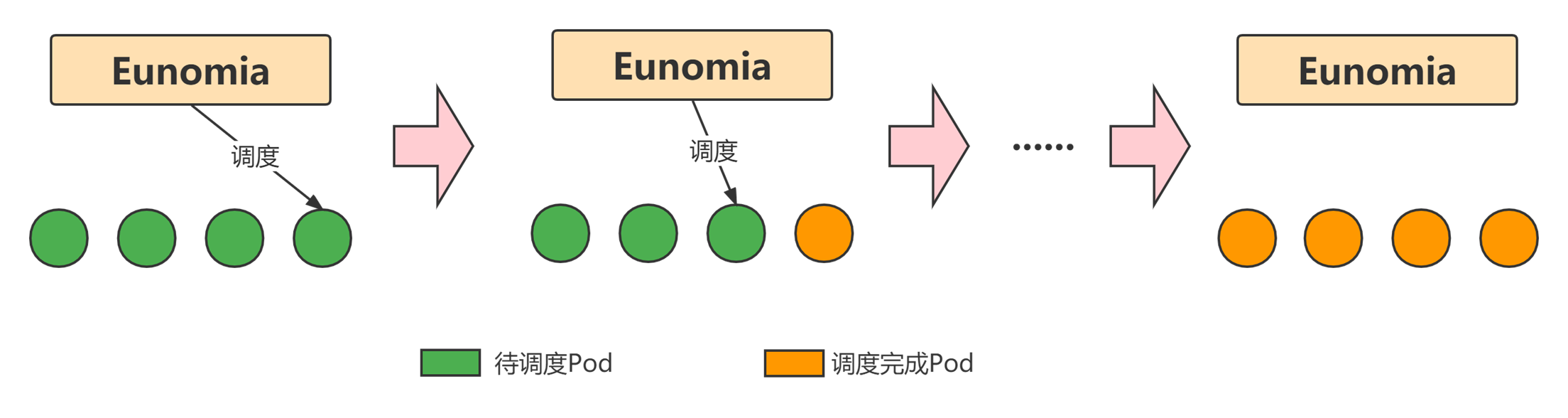
弱状态服务指 Pod 立即停止对当前业务有一定影响,但不致命。对于该种服务,可以通过在服务访问量较小的时段调度(例如凌晨3-6点)来进一步优化。
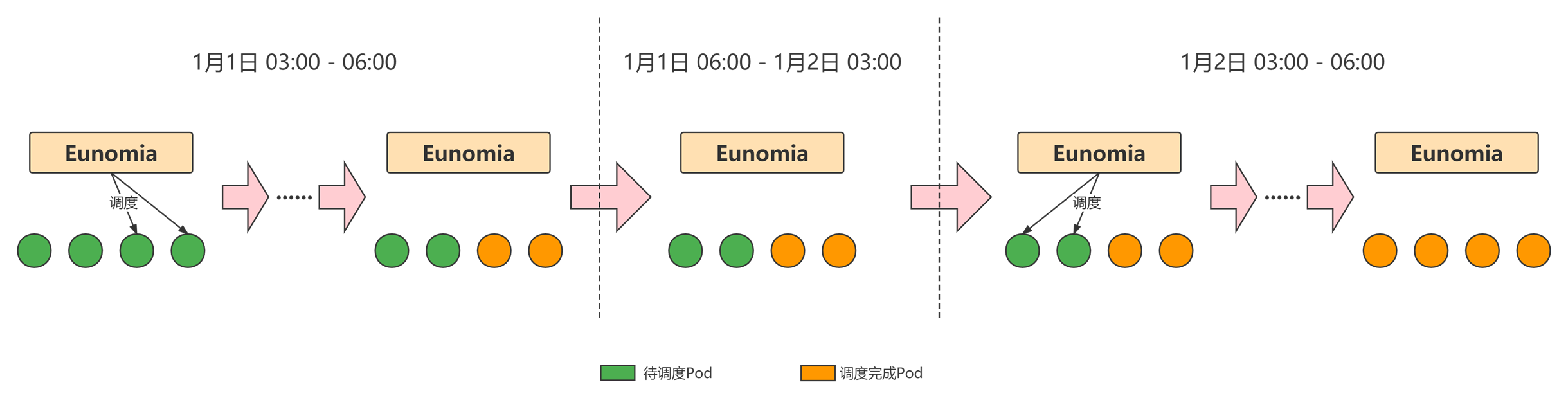
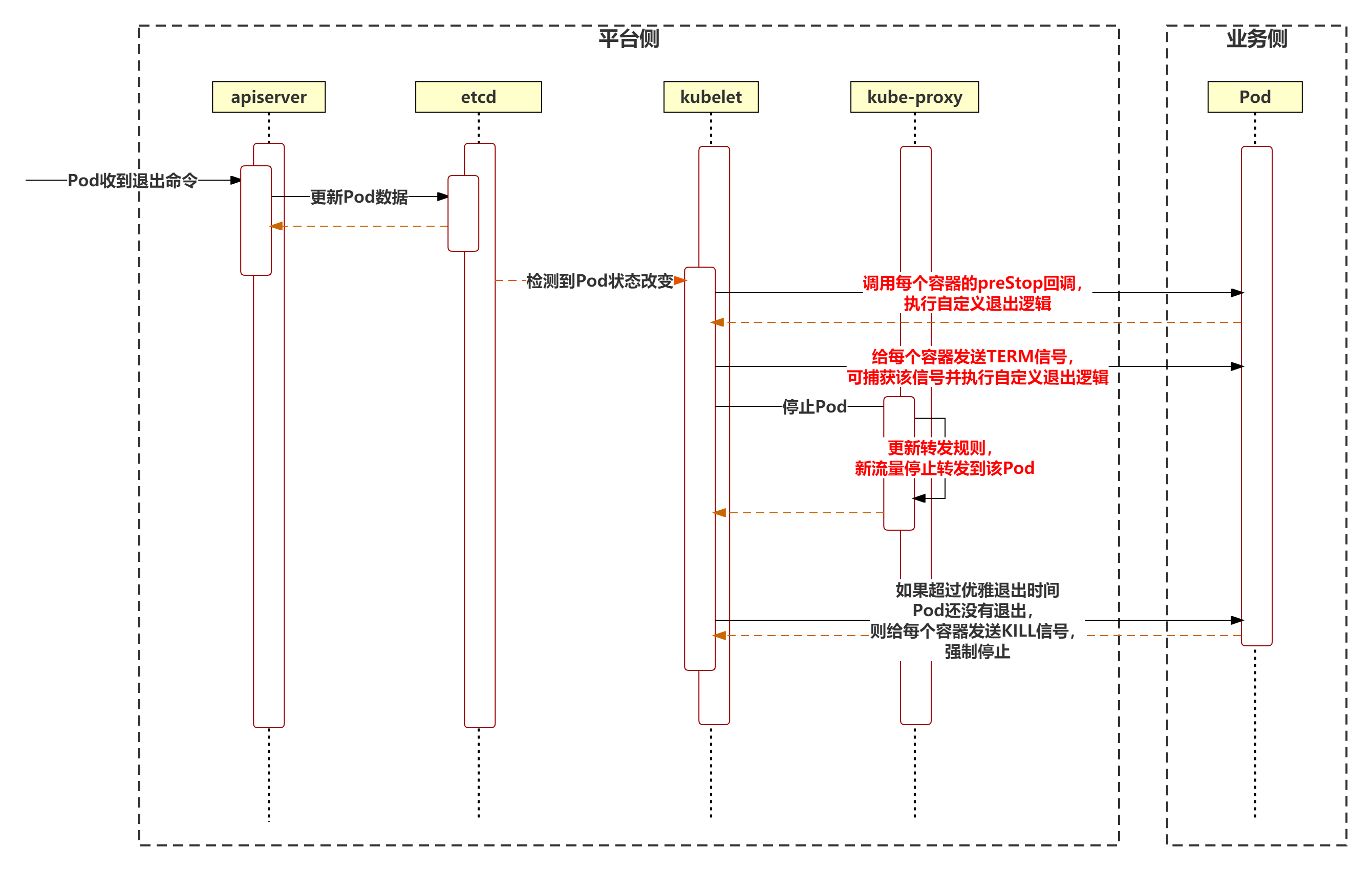
强状态服务指 Pod 立即停止对当前业务有影响,并且致命。此类服务的停止比较复杂,需要平台侧和业务侧协同合作。其中业务侧需要设置 Pod Prestop 回调,且需要捕获并处理退出时收到的 TERM 信号,对当前请求进行收尾并退出。平台侧则需要切断转发到该 Pod 的流量,避免有新的请求发送到该 Pod。具体流程如下:
基于 Pod 预测值调度存在以下风险:
Pod 可能因为资源过度压缩,无法正常提供服务 突发性流量高峰可能使 Pod 资源使用超过 predicts
针对第一种情况,可以给 Pod 设置存活探针,监控 Pod 的健康状态。如果 Pod 频繁出现不健康,则需要进一步查看原因,是否有其他关键资源维度或者需要调整节点预期的资源利用率。
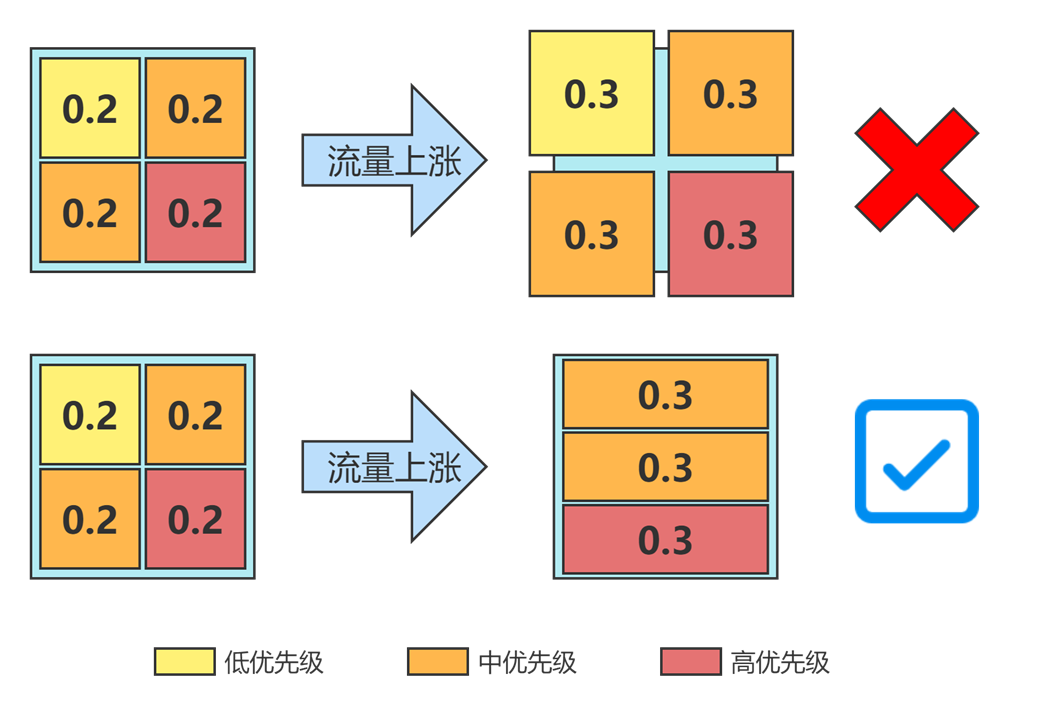
针对第二种情况,需要设置告警监控集群节点状态,告警触发时自动调用接口刷新 Pod predicts 并驱逐低优先级的 Pod,保证高优先级的 Pod 正常运行。这样可以有效避免突发流量影响业务服务质量。
前文提到通过整体编排解决多维度空闲资源碎片化问题,但是整体编排的整个流程耗时比较长,无法快速地回收资源。在实际生产环境中,针对一些可预见的流量高峰期(例如国庆),业务会提前扩容,这要求新节点资源的添加;流量峰值过后,业务会再缩容,这时之前添加的节点资源就会空闲出来,但是这些空闲资源并不能直接回收,因为缩容并不能精准缩容之前扩容出的 Pod,并且在新节点上架期间,老的 Pod 也会被调度上去。因此业务缩容过后经常出现的情况是直接添加的节点负载很低,但是上面有少量业务 Pod 还在运行。
对于这种情况,如果采用之前的整体编排方案去解决难免有大炮打蚊子的嫌疑,因此我们采用了另一套更简单直接的解决方案:
筛选出低负载节点; 将上面的 Pod 驱逐,该步骤也需要在不影响业务服务质量的前提下进行; 正式下架节点,完成成本的削减。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号