游戏案例|Service Mesh 在欢乐游戏的应用演变和实践
作者
陈智伟,腾讯 12 级后台专家工程师,现负责欢乐游戏工作室公共后台技术研发以及团队管理工作。在微服务分布式架构以及游戏后台运维研发有丰富的经验。
前言
欢乐游戏工作室后台是分布式微服务架构,目前稳定承载着多款游戏,数千万 DAU 以及数百万级在线。原有云下架构脱胎于 QQGame 后台,核心架构已有 10 多年的历史,其中使用了多套目的不同的自研开发框架,自研基础组件,并为适应繁杂的业务场景,衍生出不同的服务模型,最终积累了数百个微服务,整体简化架构如下所示:
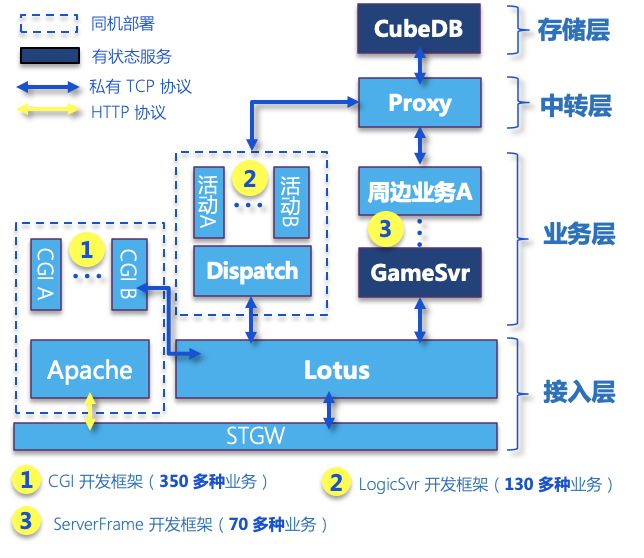
在这种大规模平台化的后台系统和复杂多样的业务架构下,还要持续创造更大的业务价值,这给团队带来了较大的挑战和压力。简单列举几个问题:
- 机器资源利用率极低,集群内 CPU 峰值平均利用率不足 20%;
- 服务治理能力不足,由于存在多套研发框架且服务管理方式不同,导致整体业务的维护以及基础服务治理能力的研发成本较高;
- 服务部署十分繁琐,自动化不足,耗时耗力,且容易出外网问题;
- 大量的陈旧业务服务缺乏维护,陈旧服务可视化能力不足,质量不易保证;
- 整体架构较为复杂,新人上手成本较高,可维护性不足;
- 每年机房裁撤都要耗费较大人力成本;
在云原生时代,借着公司全面“拥抱云原生”的东风,我们深度结合 K8s 以及 Istio 能力,逐模块拆分,细致梳理,经历过各类有状态、无状态服务的上云,协议改造,框架改造适配,服务模型云原生化,数据迁移,完善云上周边服务组件,建立云上服务 DevOps 流程等等众多系统性工程改造。最终,在不停服、平滑兼容过渡的前提下,将整体架构的服务云化以及网格化。
在整体架构上云技术方案选型上,我们权衡了各类方案的完备性、可扩展性以及改造维护成本等因素,最终选择使用 Istio 服务网格作为整体上云的技术方案。
接下来,我将按照原有架构演进的线路,简单介绍部分模块的上云方案。
研发框架以及架构升级,实现低成本无感平滑演进至服务网格
为了接入 Istio 以及服务能够平滑过渡,在基础框架和架构上做了较多适配性调整,最终可以实现:
- 存量业务代码无需调整,重编即可支持 gRPC 协议;
- 网格服务之间调用,使用 gRPC 通信;
- 云下服务调用网格服务,既可以使用私有协议也可以使用 gRPC 协议;
- 网格服务调用云下服务,使用 gRPC 协议;
- 旧业务可平滑灰度迁移至网格内;
- 兼容 Client 侧的私有协议请求;
接下来,对其中部分内容做简要说明。
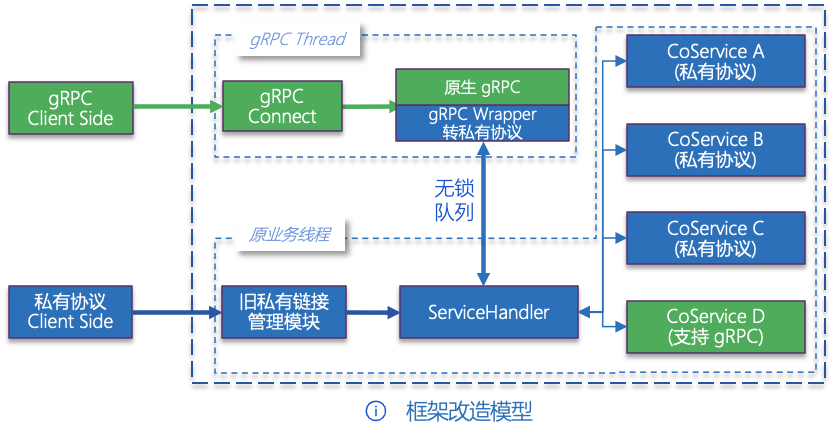
原有架构引入 gRPC
考虑到需要更全面应用 Istio 的服务治理能力,我们在已有开发框架中引入了 gRPC 协议栈。同时为了兼容原有的私有协议的通信能力,使用 gRPC 包装私有协议,并在开发框架层以及架构层都做了兼容性处理。开发框架结构示意图如下所示:
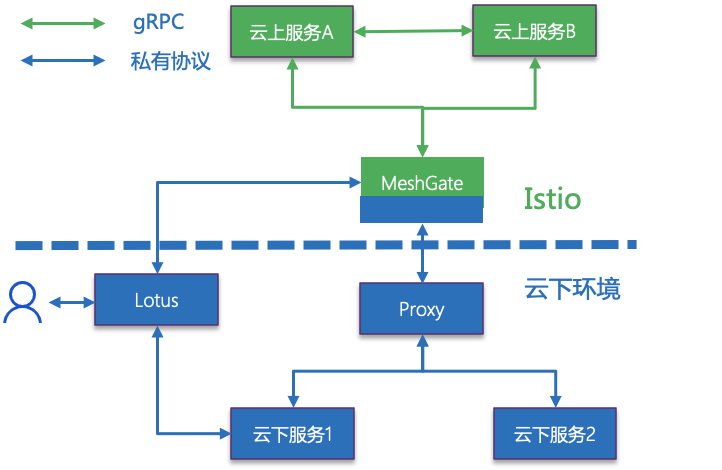
使用 MeshGate 桥接网格以及云下服务
为了使得云上 Istio 中的服务,能够与云下服务互通,我们研发了 MeshGate 服务桥接云上网格以及云下服务。
MeshGate 主要功能是实现服务在网格内外的双边代理注册,并实现 gRPC 与私有协议之间的互转适配,架构如下图所示:
架构演变
基于业务重编支持 gRPC 能力,以及网格内外服务兼容性的打通,我们就可以实现新旧业务无感平滑的迁移上云了。
当然在迁移过程中,我们也并非一味无脑的容器化上云,会对各类服务做针对性的云原生化处理以及服务质量加固,并提高服务的可观测性,最终提升服务的可维护性以及资源利用率。
服务上云之后,其资源配置粒度变为 Pod 级别,并支持自动伸缩能力,因此无需为具体的服务预留过多资源,绝大部分服务都可以共用 Node 资源。进而可以大幅提高机器资源的利用率,整体的资源使用降幅可达 60-70% 左右。
除了机器资源的减少好处之外,服务使用 helm 声明式一键部署模式,从而 K8s 可以较好地维持服务的可用性,同时架构也获得了 Istio 强大的服务治理能力。最终极好地提升了业务的 DevOps 效能。
整体架构的演变如下图所示:
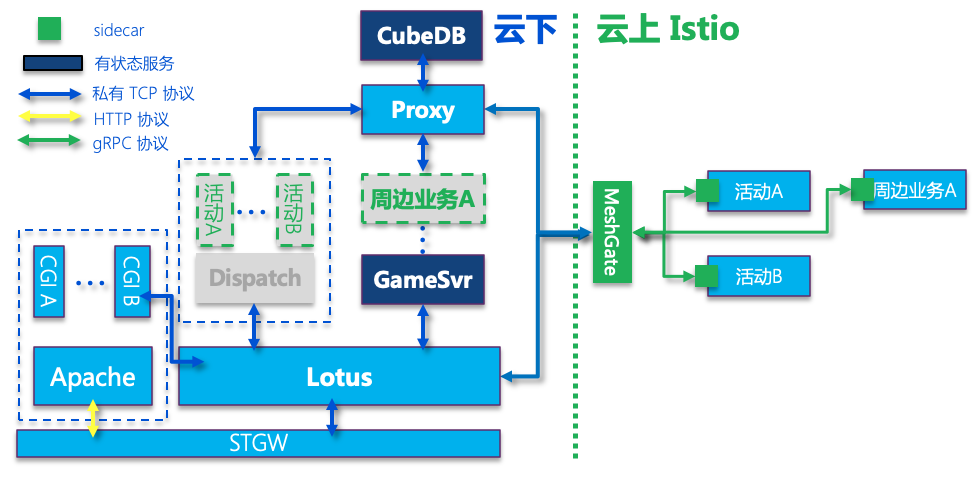
但心细的同学可能会发现,服务上了网格之后,业务和 Client 侧的通信需要从自研接入集群 Lotus 转发至 MeshGate,并做多次的协议转换以及转发,导致通信链路的性能开销以及时延加大。而对于游戏中时延敏感的业务场景,其中时延的损失,是难以接受的。因此我们迫切需要一个网格内的网关接入服务,接下来就介绍一下网关接入的改造方案。
网格内私有协议的接入服务
原有云下的自研接入集群 Lotus,是基于私有协议的 TCP 长链接的 Client 侧接入服务,具备服务注册,大规模用户链接管理,通信鉴权,加解密,转发等等能力。
除了前述服务迁移至网格后,导致通信效果损耗之外,还存在一些其他问题:
-
Lotus 集群的运维十分繁琐;因为为了防止用户游戏过程中出现链接的断开导致的不好体验,Lotus 进程的停止,需要等待用户侧主动断开,而新链接则不会发送给待停的 Lotus 中,简而言之,Lotus 的停止需要排空已有长链接,这也导致 Lotus 的更新需要等待较长的时间。我们有统计过,每次全网跟新发布 Lotus 版本需要持续数天的时间。而遇到问题、裁撤或者新增节点时,其变更需要人工调整全网配置策略,且需要执行十多项步骤,整体效率较低。
-
Lotus 集群的资源利用率低;由于 Lotus 是最基础的服务,且部署不方便,因此为了应对业务流量的变化,就要预留出充足的机器资源。但这也导致了 Lotus 的资源利用率较低,日常 CPU 峰值资源利用率仅 25% 左右;
为此,我们基于 CNCF 旗下的开源项目 Envoy 的基础之上,支持私有协议的转发,并对接 Istio 控制面,使之适配我们原有的业务模型,并实现私有通信鉴权,加解密,客户端链接管理等等能力,最终完成接入服上云的工作。整体技术框架如下图所示:
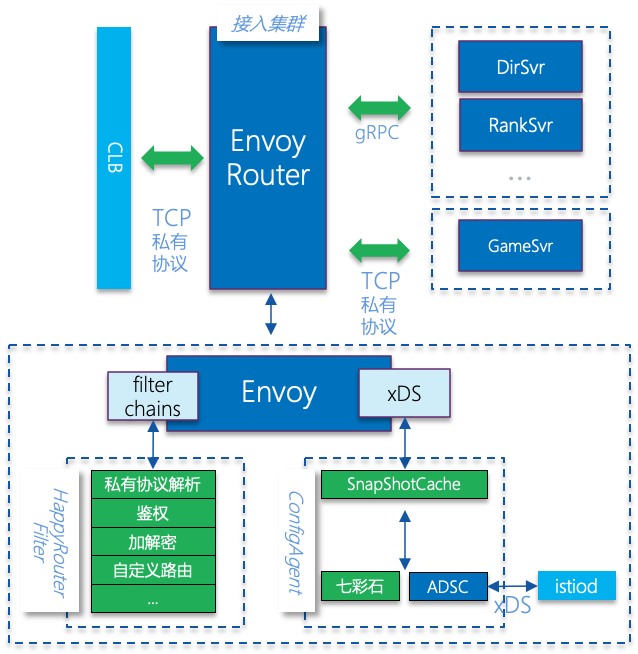
改造完毕之后,云上接入集群在各方面都获得了较好的提升。
-
核心业务场景下的私有协议转发性能以及延迟开销与云下环境接近;
针对核心的业务场景,我们做过相应的压力测试,Envoy 在支持私有协议之后,其接入转发的性能开销以及时延与云下直连属于同一个量级。其中测试时延,如下表所示:场景 平均耗时 P95 耗时 云下直连 0.38ms 0.67ms K8s pod 间转发 0.52ms 0.90ms Istio + TCP 转发(私有协议) 0.62ms 1.26ms Istio + gRPC 转发 6.23ms 14.62ms -
天然支持 Istio 的服务治理能力,更贴近云原生 Istio 下的使用方式;
-
通过 Helm 部署以及定义 Controller 管理,实现一键服务上架以及滚动更新;整个升级是自动的,且过程中实现排空更新能力,并考虑会负载能力,排空效率更优。
-
由于支持自动伸缩能力,接入服务无需预留过多的资源,因此可以大幅降低资源开销;全量云化后接入集群的 CPU 节省 50%-60%,内存节省了近 70% 左右。
架构演变
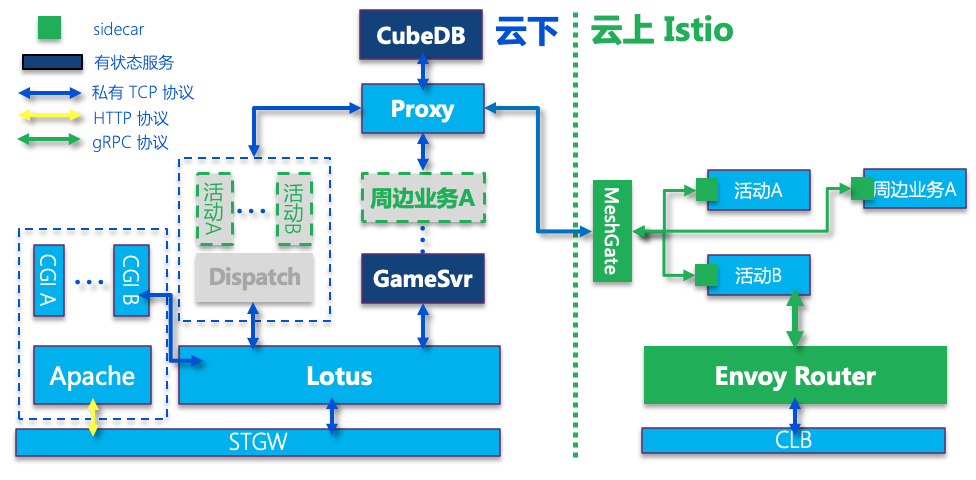
有了云上接入集群,整体架构演变如上图所示。接下来再以游戏业务中的 GameSvr 作为游戏强状态服务的代表,简单介绍其上云方案。
GameSvr 上云
欢乐工作室以往大都是单局房间类的游戏(注:目前已经远不止这些了,也有 MMO,大世界,SLG 等等各种游戏品类)。云下 GameSvr 架构如下图所示:
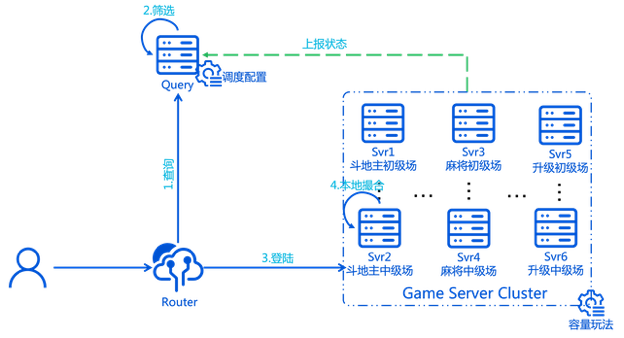
但以上架构在云下存在一些问题:
- 运维繁琐;单台 GameSvr 上下架需十余步人工操作,每年不停服机器裁撤需要耗费数周的人力,且容易发生事故;
- 资源利用率低;同样因为扩缩不易,就需预留足够的资源,做冗余部署,导致高峰期 CPU 利用率仅 20% 左右;
- 整体的容灾能力弱,宕机后需人工介入处理;
- 对局调度不灵活,都是依靠人工配置静态策略;
因此借助云原生的能力,我们打造了一套易伸缩、易维护和高可用的单局类 GameSvr 架构。如下图所示:
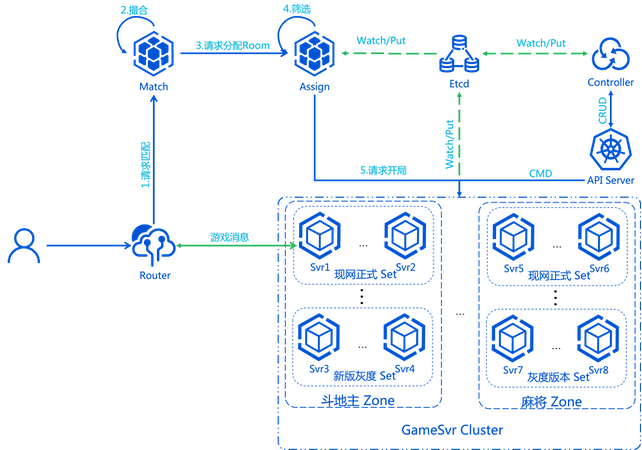
在整个迁移上云的过程中,我们是不停服,不变更前端,用户无感地平滑过渡至云上网格 GameSvr 集群。最终实现了:
-
资源利用率上获得大幅提升;整体 CPU 以及内存的使用都减少了近 2/3。
-
运维效率获大幅提升;通过自定义 CRD 和 Controller 的管理,实现 Helm 一键部署整个集群,上下架十分便捷,仅一个业务项目组每个月因发布 GameSvr 都可以有效节省人力近 10 人天;
-
GameSvr 可根据当前集群的负载压力变化以及历史负载压力的时间序列实现可靠自动伸缩;
-
实现了灵活可靠的单局调度能力;通过简单的配置,即可实现单局根据不同的属性,调度到不同的 Set 中。且在调度的过程中,也会考虑负载和服务质量,最终实现整体调度的较优选择。
架构演变
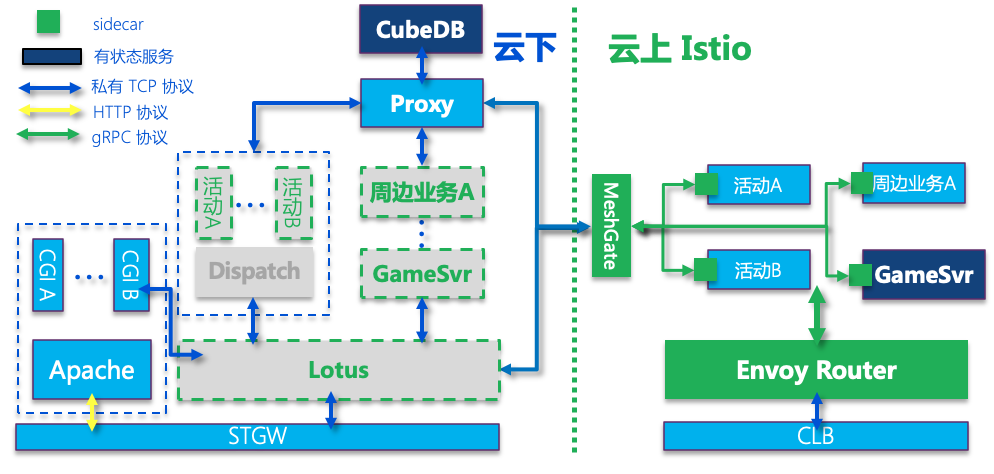
GameSvr 上云之后,整体架构变迁如上图所示,接下来再看 CGI 是如何上云的。
数量庞大的 CGI 上云
我们曾大规模使用 Apache 下的 CGI 作为运营类活动开发的框架。但原有 CGI 业务的一些现状:
-
业务种类较多,现网部署约 350 种 CGI 服务,且流量巨大;
-
CGI 同步阻塞的进程模型,导致其单进程的吞吐量极低;大部分 CGI 业务的 QPS 仅个位数,且存在 Apache 的服务调度以及消息分发的性能开销;
-
CGI 之间的资源隔离性差;因为 CGI 是同机多进程部署,极易出现由于某个业务 CGI 突然资源开销暴增,影响其他业务 CGI 的情况;
面对数量庞大且性能低效的 CGI 的上云,则需要研发成本以及资源开销都低的上云方案。一开始我们尝试过将 Apache 以及 CGI 整体打包成一个镜像简单容器化上云,但发现资源开销和部署模型都十分不理想,因此需要更优雅的上云方案。
接着,我们对 CGI 的流量分布进行分析,发现 90% 的业务流量主要集中在 5% 的 CGI 中,如下图所示。

因此,我们针对不同流量的 CGI,做了一些区分改造上云。
-
针对头部流量 CGI 进行协程异步化改造,剥离 Apache,使框架性能获数十倍提升。
-
在框架层实现监听 http 请求以及异步化:
- 使用 http-parser 改造,使的框架自身就支持 http 监听以及处理;
- 基于 libco 改造,使框架底层支持协程,从而实现异步化;
-
在业务层,也需要针对性做各类适配性处理:
- 针对全局变量,进行私有化或者关联至协程对象管理;
- 后端网络、io、配置加载以及内存等资源做各类复用化优化,提升效率;
最终业务侧做较小的调整,即可协程异步化改造完。但即使改造成本再低,已有的 CGI 数量还是太多了,全量异步化改造性价比十分低。
-
-
针对剩余长尾流量 CGI,与 Apache 一并打包,使用脚本一次性搬迁上云。为了提升可观测性,还对这种单容器内,超多进程的 metrics 采集 export 做了特殊处理。
最后在上云过程中,充分利用 Apache 的转发机制,实现灰度可回滚上云。
上云后,CGI 的整体资源利用率以及可维护性均获大幅提升。全量云化之后 CPU 可节省近 85% 的核数,内存可节省 70% 左右。
架构演变
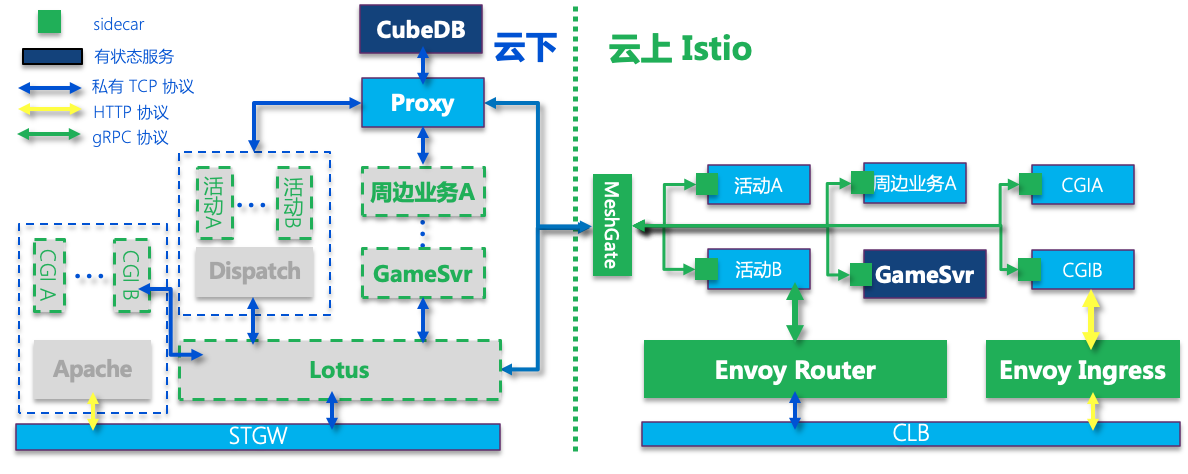
搬迁完 CGI 之后,整体架构如上图所示。接下来介绍一下自研存储 CubeDB 的改造方案。
自研存储业务迁移
我们云下有具有数十 T 的自研存储数据,自建数百张 MySQL 表,整体的维护成本较高,且上云困难。因此我们的解决方案是“专业的事交给专业的人做”,将存储迁移托管至 TcaplusDB(腾讯 IEG 自研公共存储服务)。整体的迁移步骤简要描述如下:

-
研发了适配代理服务,即上图所示的 Cube2TcaplusProxy,将 CubeDB 私有协议适配转换至 TcaplusDB,那么新业务的存储就可以直接使用 TcaplusDB 了;
-
在 CubeDB 的备机同步业务的热数据,在开启同步之后,TcaplusDB 就有业务的最新数据;
-
将冷数据导入至 TcaplusDB,如果 TcaplusDB 中有记录数据,说明它是最新的,则不覆盖;
-
全量比对 MySQL 与 TcaplusDB 的数据,多次校验全量通过后则切换 Proxy 的路由;
最终通过这种方案,我们实现 DB 存储的无损平滑迁移。
架构演变
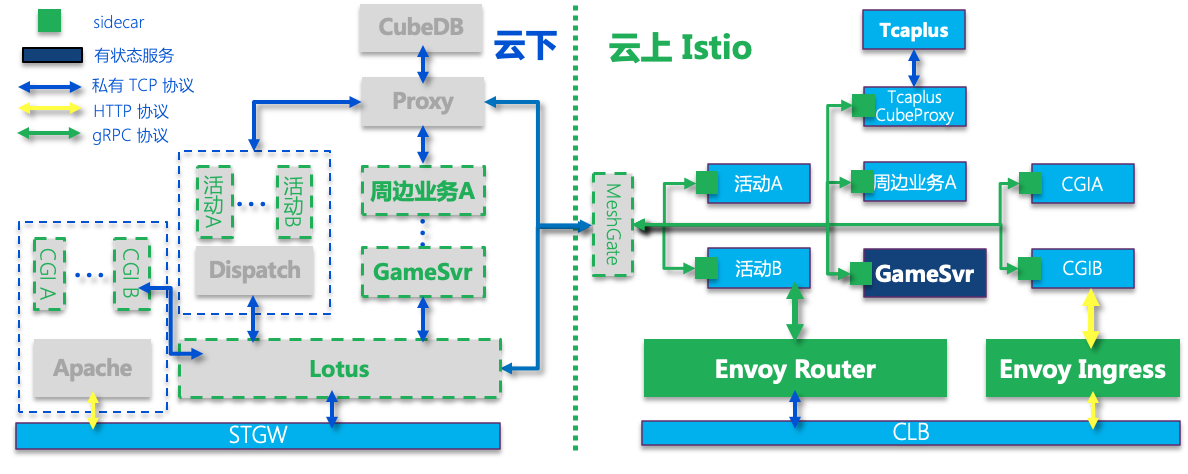
我们自研存储服务改造完毕之后,绝大部分服务均可以上云了。同时我们还做了很多云上周边能力的建设和应用,例如云上统一配置中心,grafana as code,promethues,日志中心,染色调用链等等能力。
最终架构演变为:
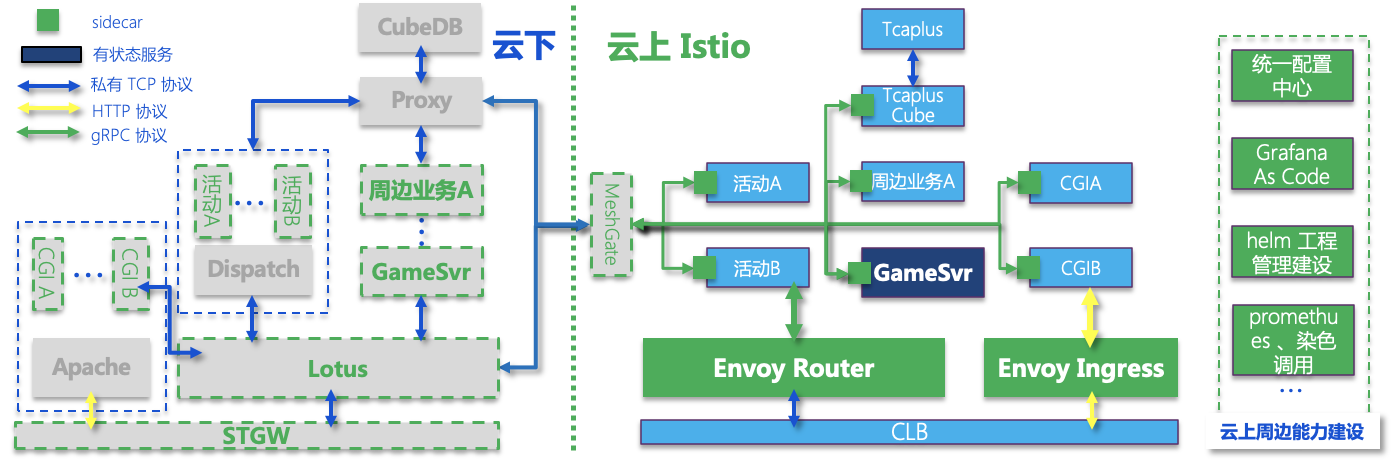
多集群的部署模式
在云下,我们是一个全区全服的架构,所有的游戏业务都在一个集群之中。但由于我们组织架构以及业务形态的原因,期望上云之后,不同的业务团队工作在不同的业务 K8s 集群,而对于大家共用的服务,则放到公共集群下管理。因此在迁移上云的过程中,则还需要做更多的适配迁移工作。
在 Istio 层面,由于我们的 Istio 服务托管给 TCM 团队(腾讯云服务网格 TCM),在 TCM 同学的大力支持下,结合我们目前的组织架构以及业务形态,实现 Istio 多集群下控制面信息的互通,由此我们在多集群之间的互相调用,成本就很低了。如下是 TCM 相关的后台架构:
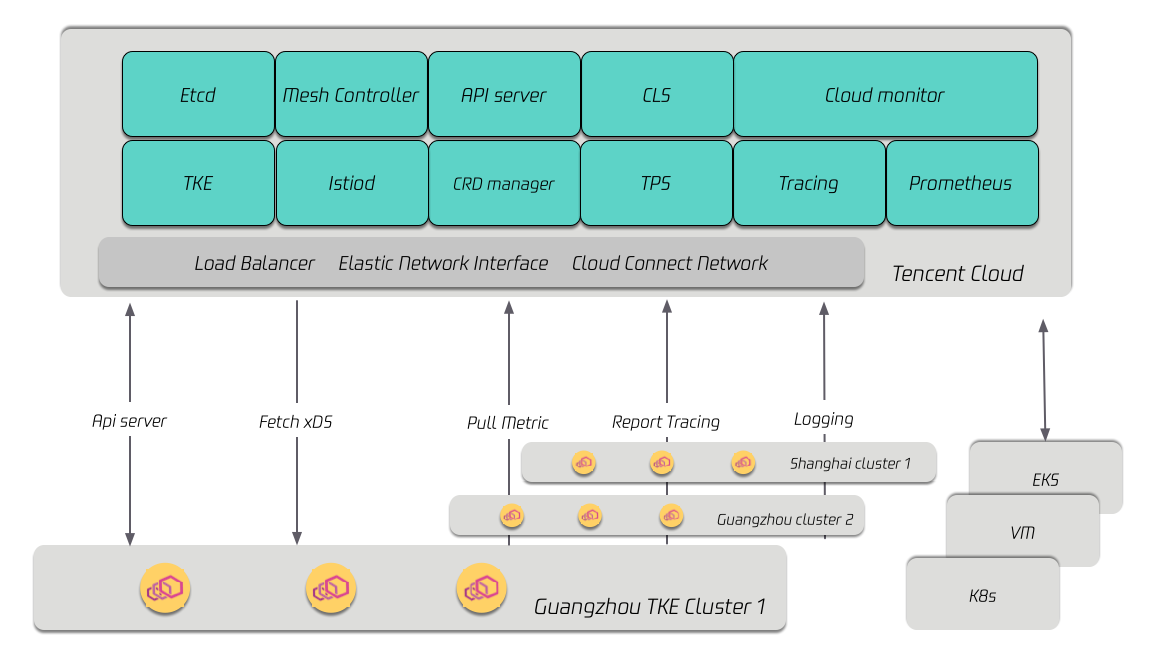
总结
最终,我们在复杂的游戏业务架构下,经过细致分析和基于云原生技术的持续重构演进,深度结合 K8s 以及 Istio 的能力,最终实现游戏业务场景下架构平稳平滑的高质量上云以及网格化,拥有多框架多语言的微服务框架,自动化,服务发现,弹性伸缩,服务管控,流量调度治理,立体度量监控等等能力,并沉淀游戏各类业务场景上云经验。对于业务模块的可靠性、可观测性、可维护性大幅提高,整体研运效率提升十分明显。
欢乐游戏工作室旗下拥有欢乐斗地主,欢乐麻将,欢乐升级等数款国民棋牌类游戏,同时在研大世界,MMO,SLG 等多种品类游戏,现大量招聘研发、策划以及美术等各类岗位,欢迎猛戳招聘链接,推荐或者投递简历。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号