
不止是上云,更是上岸
作者
常耀国,腾讯SRE专家,现就职于PCG-大数据平台部,负责千万级QPS业务的上云、监控和自动化工作。
背景
BeaconLogServer 是灯塔 SDK 上报数据的入口,接收众多业务的数据上报,包括微视、 QQ 、腾讯视频、 QQ 浏览器、应用宝等多个业务,呈现并发大、请求大、流量突增等问题,目前 BeaconLogServer 的 QPS 达到千万级别以上,为了应对这些问题,平时需要耗费大量的人力去维护服务的容量水位,如何利用上云实现 0 人力运维是本文着重分析的。
混合云弹性伸缩
弹性伸缩整体效果
首先谈一下自动扩缩容,下图是 BeaconLogServer 混合云弹性伸缩设计的方案图
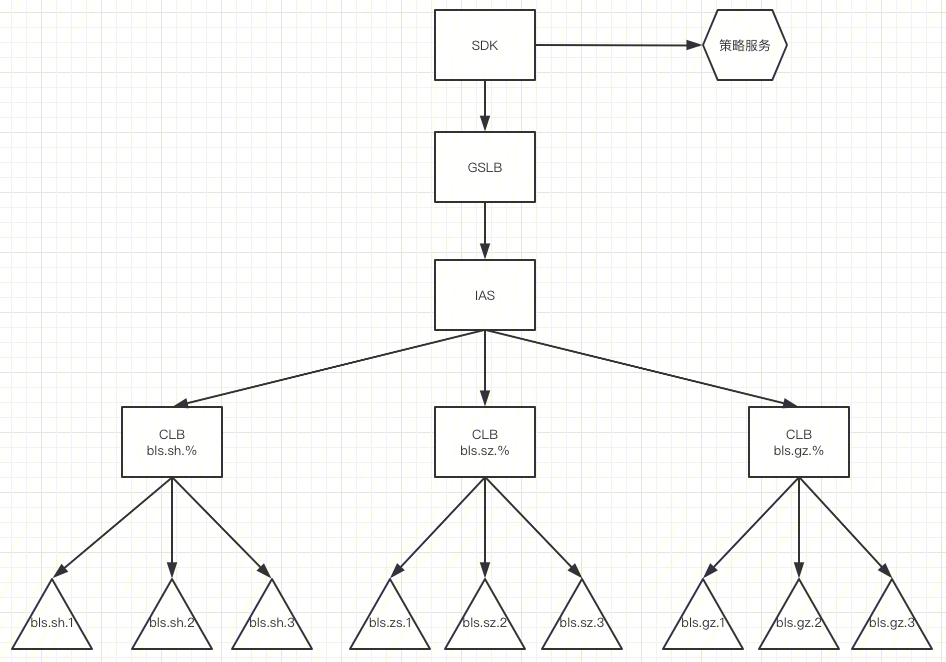
弹性伸缩方案
资源管理
先从资源管理讲起,目前 BeaconLogServer 节点个数是8000多个,需要的资源很大,单独依靠平台的公共资源,在一些节假日流量突增的时候,可能无法实现快速的扩容,因此,经过调研123平台(PAAS 平台)和算力平台(资源平台),我们采用了混合云的方式,来解决这个问题。
分析 BLS 业务场景,流量突增存在下面两种情况:
-
日常业务负载小幅度升高,时间持续较短
-
春节业务负载大幅度升高,并持续一段时间
针对上述的业务场景,我们采用三种资源类型来应对不同场景,具体如下表所述:
| 类型 | 场景 | set |
|---|---|---|
| 公共资源池 | 日常业务 | bls.sh.1 |
| 算力平台 | 小高峰 | bls.sh.2 |
| 专用资源池 | 春节 | bls.sh.3 |
日常业务我们使用公共资源池+算力资源,当业务的负载小幅度上升的话,使用算力资源快速扩容,保障服务的容量水位不超过安全阈值。面对春节负载大幅度升高,这时需要构建专有资源池来应对春节的流量升高。
弹性扩缩容
上文阐述了资源的管理,那么针对不同的资源,何时开始扩容,何时开始缩容?
BeaconLogServer 日常的流量分布是 123 平台公共资源:算力平台=7:3。目前设置的自动扩容的阈值时60%,当 CPU 使用率大于60%,平台自动扩容。弹性扩缩容依赖的是 123 平台的调度功能,具体的指标设置如下:
| 类型 | CPU自动缩容阈值 | CPU自动扩容阈值 | 最小副本数 | 最大副本数 |
|---|---|---|---|---|
| 123平台公共资源池 | 20 | 60 | 300 | 1000 |
| 算力平台 | 40 | 50 | 300 | 1000 |
| 123平台专有资源池 | 20 | 60 | 300 | 1000 |
可以看到算力平台自动缩容阈值较大,自动扩容阈值较小,主要考虑算力平台是应对流量突增的情况,而且算力平台资源经常替换,因此优先考虑先扩容或缩容算力平台的资源。最小副本数是保障业务所需的最低资源需求,如果少于这个值,平台会自动补充。最大副本数设置1000,是因为 IAS 平台(网关平台)一个城市支持的最大 RS 节点数是1000。
问题及解决
方案推进的过程中,我们也遇到了很多问题,挑选几个问题和大家分享一下。
1)首先从接入层来讲,之前接入层业务使用的是 TGW , TGW 有一个限制,就是RS的节点不能超过200个,目前 BeaconLogServer 的节点是8000多个,继续使用 TGW 需要申请很多个域名,迁移耗时多且不便于维护。我们调研接入层 IAS , IAS 四层每个城市支持的节点个数是1000个,基本可以满足我们的需求,基于此,我们设计如下的解决方案如下:
总体上采用“业务+地域”模式分离流量。当集群中一个城市的 RS 节点超过500个就需要考虑拆分业务,例如公共集群的节点超出阈值,可以把当前业务量大的视频业务拆分出来,作为一个单独的集群;如果是一个独立集群的业务节点超出阈值,先考虑增加城市,把流量拆分到新的城市。如果无法新增城市,此时考虑新增一个 IAS 集群,然后在 GLSB 上按照区域把流量分配到不同的集群。
2)同一个城市不同的资源池设置不同的 set,那么IAS如何接入同一个城市不同 set 呢?
北极星本来有[通配组功能],但是 IAS 不支持 set 通配符功能实际上,我们推动 IAS 实现了通配组匹配,例如使用 bls.sh.% 可以匹配 bls.sh.1 , bls.sh.2 , bls.sh.3 。注意, IAS 通配符和北极星的不一样,北极星使用的是**, IAS 在上线的时候发现有用户使用做单独匹配,所以使用%来表示通配符。
3)资源管理这块遇到的难点是 IAS 四层无法使用算力资源的节点,后面在经过沟通,打通了 IAS 到算力资源的。这里的解决方案是使用 SNAT 能力。
此方案的注意事项
-
只能绑定 IP 地址,无法拉取实例,实例销毁也不会自动解绑,需要通过控制台或 API 主动解绑(已跨账号,拉取不到实例)
-
如果是大规模上量:过哪些网关、哪些容量需要评估、风险控制,需要评估
单机故障自动化处理
单机故障处理效果
单机故障自动化处理,目标是实现0人力维护,如下图是我们自动化处理的截图。
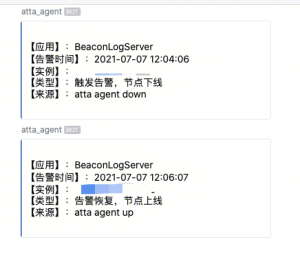
单机故障处理方案
单机故障主要从系统层面和业务层面两个维度考虑,详情如下:
| 维度 | 告警项 |
|---|---|
| 系统层面 | CPU |
| 系统层面 | 内存 |
| 系统层面 | 网络 |
| 系统层面 | 磁盘 |
| 业务层面 | ATTA Agent不可用 |
| 业务层面 | 队列过长 |
| 业务层面 | 发送atta数据成功率 |
针对单机故障,我们采用的是开源的 Prometheus +公司的 Polaris(注册中心) 的方式解决。Prometheus 主要是用来采集数据和发送告警,然后通过代码把节点从 Polaris 摘除。
至于告警发生和告警恢复的处理,当告警发生的时候,首先会判断告警的节点个数,如果低于三个以下,我们直接在 Polaris 摘除节点,如果大于3个,可能是普遍的问题,这时候我们会发送告警,需要人工的介入。当告警恢复的时候,我们直接在平台重启节点,节点会重新注册 Polaris 。
ATTA Agent 异常处理
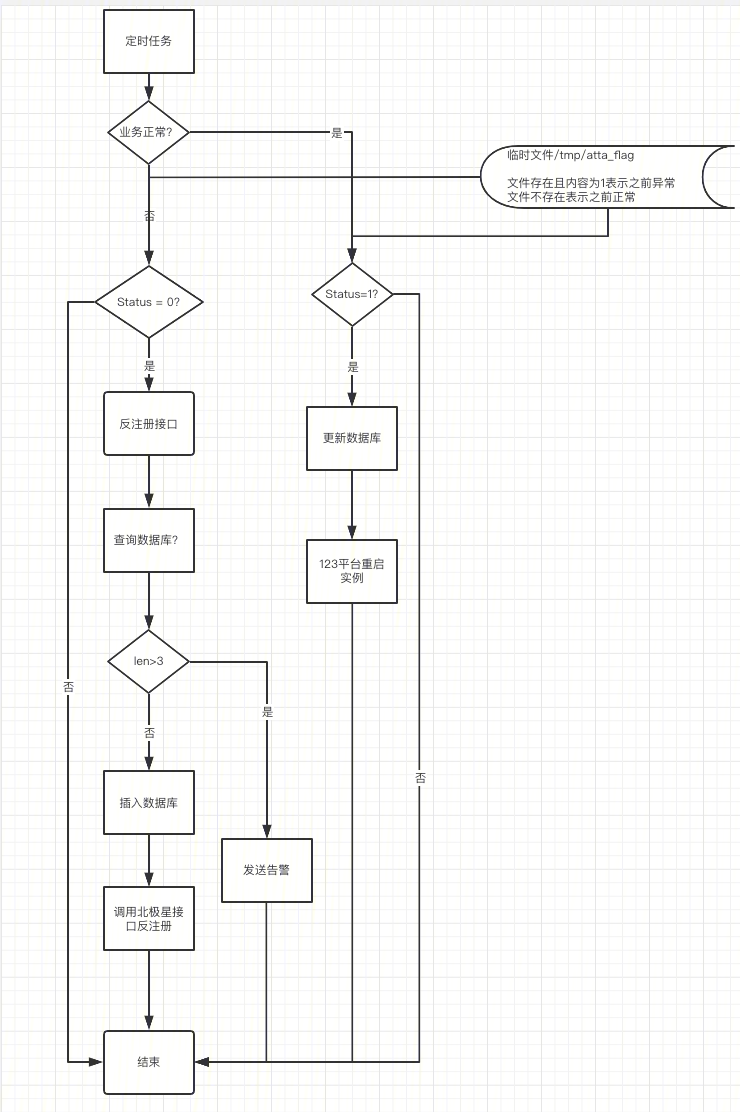
如图所示,处理流程是两条线,告警触发和告警恢复,当业务异常的时候,首先判断当前异常节点的数量,保证不会大范围的摘掉节点。然后在北极星摘除节点。当业务恢复的时候,直接重启节点。
问题及解决
主要的难点是 Prometheus Agent 的健康检查和 BeaconLogServer 节点的动态变化,对于第一个问题,目前主要是由平台方负责维护。对于第二个问题,我们利用了定时脚本从 Polaris 拉取节点和 Prometheus 热加载的能力实现的。
总结
此次上云有效的解决了自动扩缩容和单机故障这两块的问题,减少了手动操作,降低了人为操作错误风险,提升系统的稳定性。通过此次上云,也总结了几点:
-
迁移方案:上云之前做好迁移方案的调研,特别是依赖系统的支持的功能,降低迁移过程因系统不支持的系统性风险 。
-
迁移过程:做好指标监控,迁移流量之后,及时观测指标,出现问题及时回滚。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号