资源利用率提高67%,腾讯实时风控平台云原生容器化之路
导语
随着部门在业务安全领域的不断拓展,围绕着验证码、金融广告等服务场景,腾讯水滴作为支撑业务安全对抗的实时风控系统,上线的任务实时性要求越来越高,需要支撑的业务请求量也随之增加。对于业务快速上线和资源快速扩缩容的需求,且公司自研上云项目往全面容器化上云方向推进,水滴风控平台开始进行自研上云的改造。本文主要针对腾讯水滴平台上云过程中的实践总结,希望对其他业务迁移上云有一定参考价值。
水滴后台架构
水滴平台主要是用于业务安全对抗的高可用、高性能、低延时的实时风控策略平台,提供一系列的基础组件给策略人员进行构建策略模型,能够帮忙策略人员快速地完成策略模型的构建和测试验证。
水滴系统架构如下图所示:

水滴实时风控平台系统主要由配置处理模块和数据处理模块两部分组成。
配置处理模块主要由前端 web 页面、cgi 、mc_srv 和 Zookeeper 等组成。策略开发人员通过在水滴前端页面进行策略模型的编辑、策略任务的创建、上线和更新操作,构建完成的策略模型信息以 json 格式通过 cgi 和 mc_srv 接口存储到 Zookeeper 数据中心,数据处理模块通过 agent 拉取 Zookeeper 上不同业务对应的策略信息。
数据处理模块主要由 access、engine 和外部系统等构成,核心处理逻辑为 engine 模块。不同业务启动独立的 engine 实例以确保业务间的隔离,业务数据请求通过发送到指定北极星服务地址或者 ip:port 地址,由 access 接入层接收请求数据后根据任务号转发到对应任务的 engine 实例上,存在外部系统访问组件的情况下 engine 会将请求数据查询外部系统。
自研上云实践
在水滴平台改造上云过程中,先对 TKE(Tencent Kubernetes Engine) 平台进行了特性熟悉和测试验证,并梳理出影响服务上云的关键问题点:
- Monitor 监控系统与 TKE 未打通,继续采用 Monitor 指标监控系统的话将需要大量的人工介入;
- 应对突发流量情况需要人为进行扩缩容,过于麻烦且不及时;
- TKE 支持北极星规则,原有 CL5(Cloud Load Balance 99.999%) 存在部分问题;
针对上述自研上云的关键问题点,我们分别从指标改造、容器化改造、流量分发优化等方面进行改造优化以保障业务服务上云顺利。
指标监控改造
腾讯水滴平台采用 Monitor 监控系统进行系统指标视图查看和告警管理,但迁移上云过程中发现 Monitor 监控指标系统存在不少影响上云的问题点,为了解决原有 Monitor 指标监控系统存在的问题,我们将指标监控系统由 Monitor 监控系统改造为智研监控系统。
Monitor 监控系统问题
- TKE 未与 Monitor 监控系统打通,云上实例 ip 地址发生变化时需人工添加对应容器实例 IP 到 Monitor 系统中,且云场景下实例 IP 频繁变动难于维护
- Monitor 指标针对 NAT 网络模式下的容器实例指标无法实例级别的区分,NAT 网络模式下相同属性指标,不利于实例级别的指标查看
- Monitor 监控系统灵活性较差,有新的属性增加时需要申请属性 ID 并调整更新代码实现
智研指标改造过程
Monitor 监控指标系统的指标上报主要是属性 ID 和属性指标值,针对不同指标需要预先申请属性 ID ,在平台系统实现过程中集成 Monitor SDK 进行不同属性ID的埋点调用。如:不同任务请求量指标需要预先申请属性 ID

在使用智研指标改造过程中,我们平台系统实现中集成了智研 Golang SDK ,将原有的 Monitor 指标上报进行了智研调用改造,智研指标改造过程中最重要的是从 Monitor 系统的单属性指标思路需要转换到多维度指标下,需要对智研维度和指标概念有一定的理解和指标设计。
如:设置任务维度,任务取值通过调用上报实现
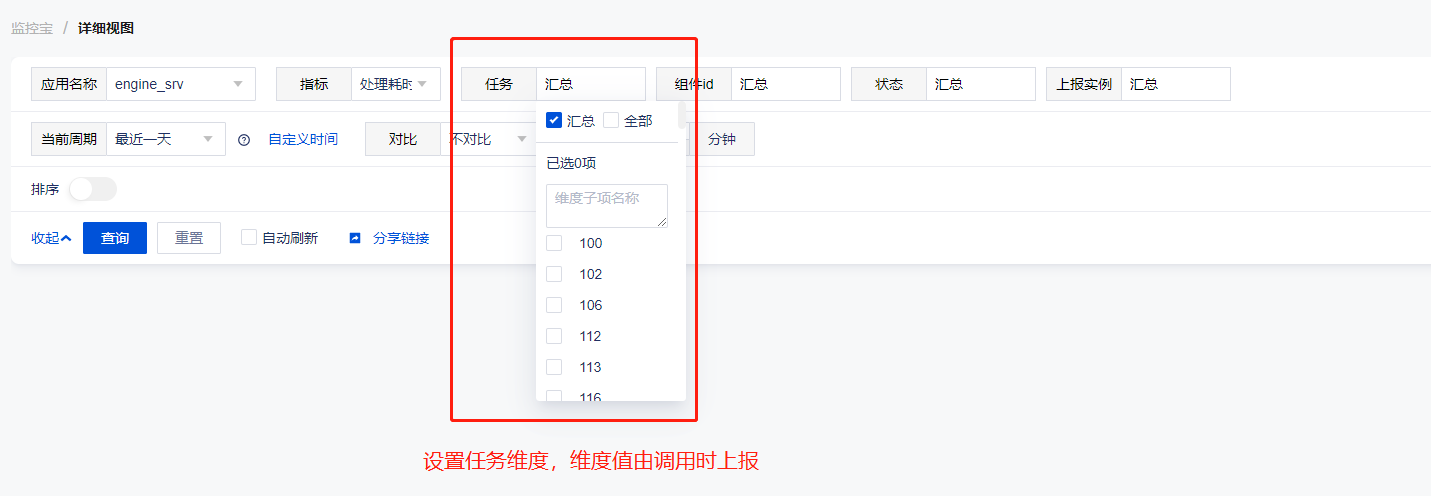
智研指标和维度设计:
智研的指标在实现改造过程中,最主要是理解指标和维度的含义。
指标: 作为一种度量字段,是用来做聚合或者相关计算的。
维度: 是指标数据的属性,通常用例过滤指标数据的不同属性。
维度属性采用指标数据中能够进行统一抽象的特性,如实例 IP、任务号、组件 ID、指标状态等维度,无法抽象成维度的属性则作为指标属性。智研指标改造前期,未进行合理的维度设计,导致指标和维度选择过于混乱,不便于后续的增加和维护。
智研告警通知优化
智研指标改造完成后,我们对平台侧和业务侧的指标告警进行区分,将业务侧相关的指标告警通过告警回调方式直接转发给业务侧,及时通知业务侧进行异常情况的处理,提高了业务侧接收异常的及时性且降低了平台侧处理业务侧告警的干扰。
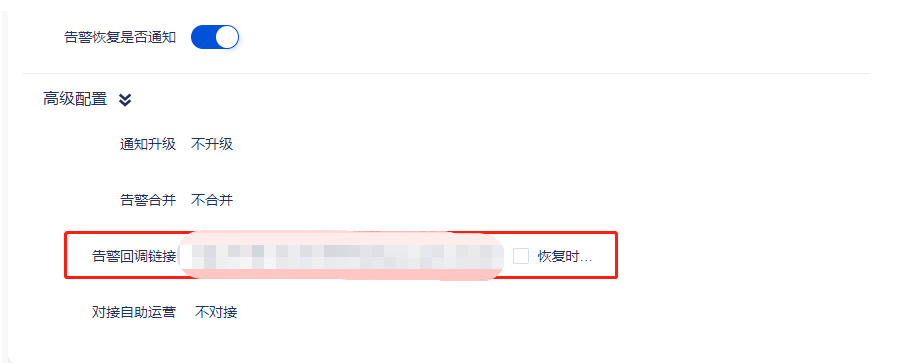
优化智研指标视图 Dashboard 展示,将常用的智研指标视图整合到智研 DashBoard 页面,方便运营人员快速了解关键指标情况。
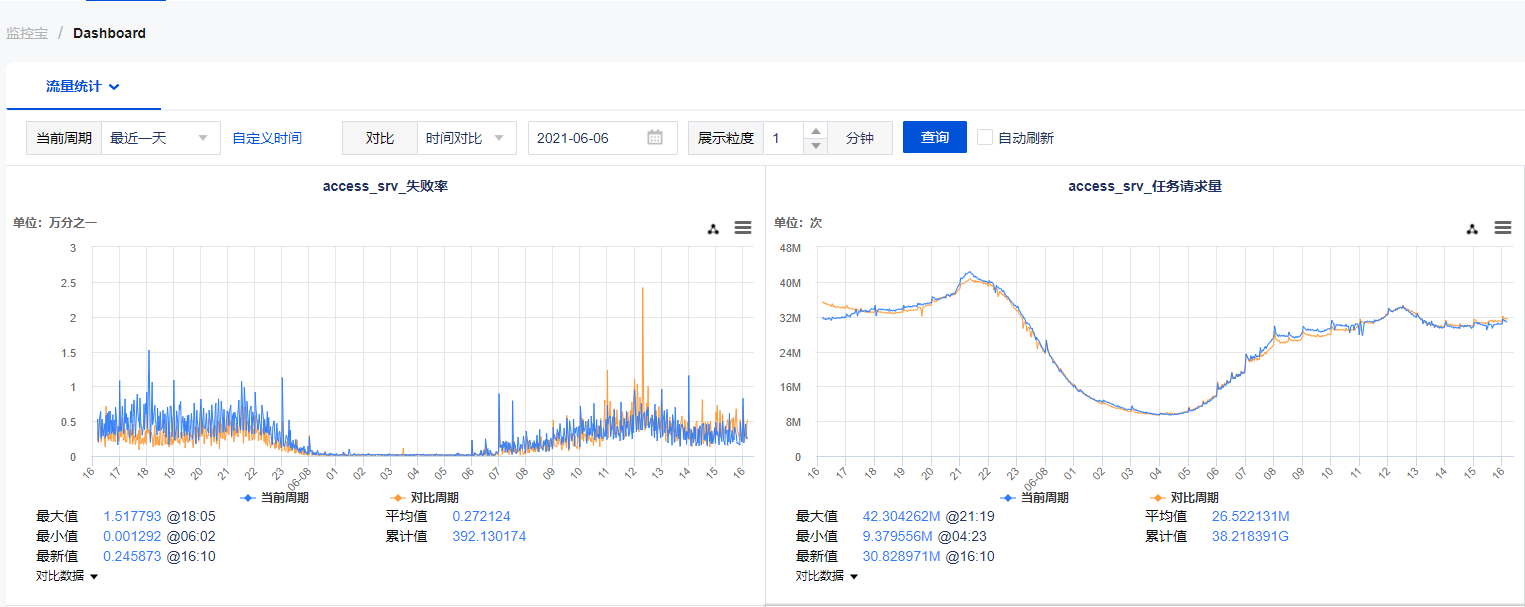
路由分发优化
路由分发问题
1.CL5 首次查询某一个 SID 的节点时,容易遇到以下-9998的问题

2.CL5 SDK 无法进行 NAT 网络模式下的就近访问,在异地服务情况下数据请求容易出现超时情况
迁移北极星(腾讯服务发现治理平台)改造
采用 CL5 进行请求路由情况下,当容器实例采用 NAT 模式时,使用 CL5 接口无法获取到物理机 ip 地址,从而导致请求数据就近访问失败。将负载均衡 API 接口由 CL5 调整为北极星服务接口后,采用北极星接口能够正常获取 NAT 网络模型下容器实例所在物理机 IP 信息,从而能够实现就近访问。
CL5 迁移北极星过程中,将原有的 CL5 SDK 替换成北极星 polaris-go(Golang 版本 SDK)
北极星 polaris-go 使用示例:
//***********************获取服务实例***************************
// 构造单个服务的请求对象
getInstancesReq = &api.GetOneInstanceRequest{}
getInstancesReq.FlowID = atomic.AddUint64(&flowId, 1)
getInstancesReq.Namespace = papi.Namespace
getInstancesReq.Service = name
// 进行服务发现,获取单一服务实例
getInstResp, err := consumer.GetOneInstance(getInstancesReq)
if nil != err {
return nil, err
}
targetInstance := getInstResp.Instances[0]
//************************服务调用上报*************************
// 构造请求,进行服务调用结果上报
svcCallResult := &api.ServiceCallResult{}
// 设置被调的实例信息
svcCallResult.SetCalledInstance(targetInstance)
// 设置服务调用结果,枚举,成功或者失败
if result >= 0 {
svcCallResult.SetRetStatus(api.RetSuccess)
} else {
svcCallResult.SetRetStatus(api.RetFail)
}
// 设置服务调用返回码
svcCallResult.SetRetCode(result)
// 设置服务调用时延信息
svcCallResult.SetDelay(time.Duration(usetime))
// 执行调用结果上报
consumer.UpdateServiceCallResult(svcCallResult)
容器化改造
根据水滴平台架构图可知,业务方在水滴平台创建不同的任务后,水滴平台上会启动不同的 engine 实例进行对应任务的计算操作,水滴平台任务与水滴任务 engine 实例呈1:N 关系,任务越多需要部署上线的 engine 实例越多。为了快速地上线不同的水滴任务 engine 实例,我们需要能够确保任务对应的 engine 实例快速的部署上线,因此 engine 实例模块进行容器化和自研上云能够提升运营效率。
水滴平台数据处理模块随着请求量的变化,需要对 access 实例和 engine 实例进行扩缩容操作,因此对 access 和 engine 实例会进行频繁地扩缩容操作。
水滴数据处理模块架构图:
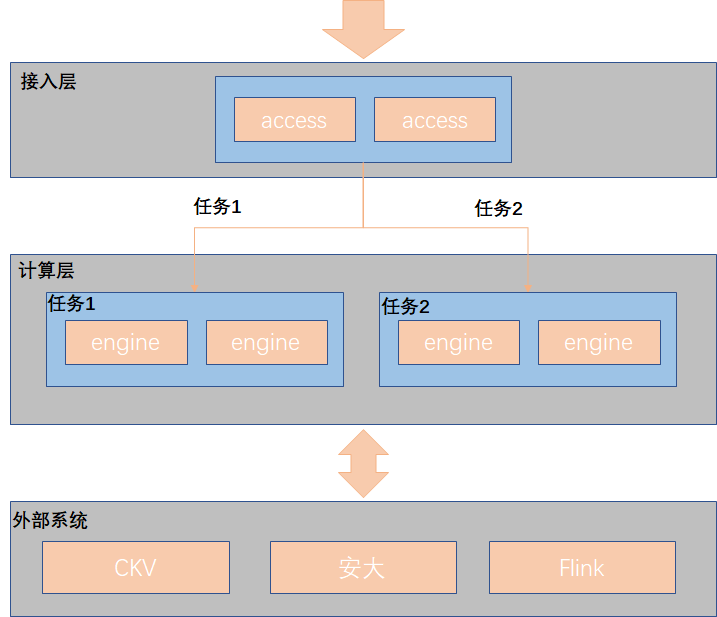
物理机部署情况
-
任务创建:新增加任务情况时,需要申请新任务对应的北极星名称服务地址,将任务的 engine 进程部署在不同的物理机上启动,并手动将 engine 实例与北极星名称服务绑定,需要人工手动进行进程的启动和管理、添加和修改对应的负载均衡服务,管理复杂,运维成本高
![]()
-
任务升级:任务程序升级过程,需要将任务对应的所有 engine 进程程序进行更新,并重启所有相关的 engine 进程
![]()
-
任务扩缩容:任务进行扩容过程,需要进行在物理机上部署并启动新的 engine 进程,再将新进程实例加入到对应的北极星名称服务中;任务进行缩容过程,需要将缩容进程先从北极星名称服务中剔除,再对相应 engine 进程进行暂停。服务扩缩容流程类似于服务升级过程。
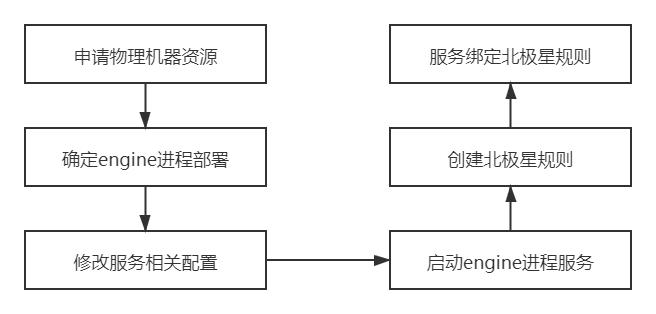

TKE 平台部署情况
-
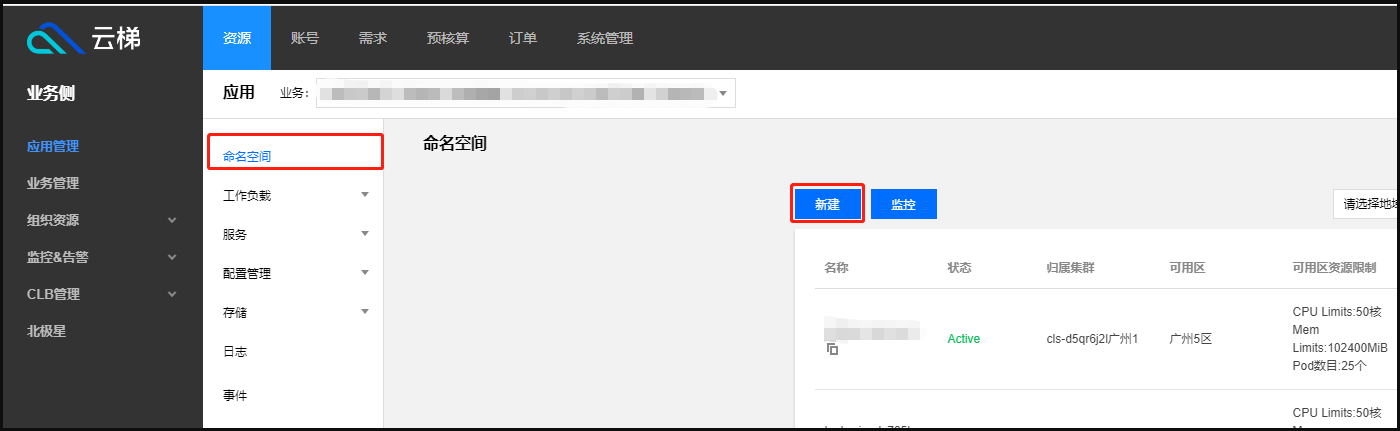
任务创建:新增加任务情况时,需要申请新任务对应的北极星名称服务地址,再在 TKE 平台进行任务对应 engine 应用实例创建
![]()
-
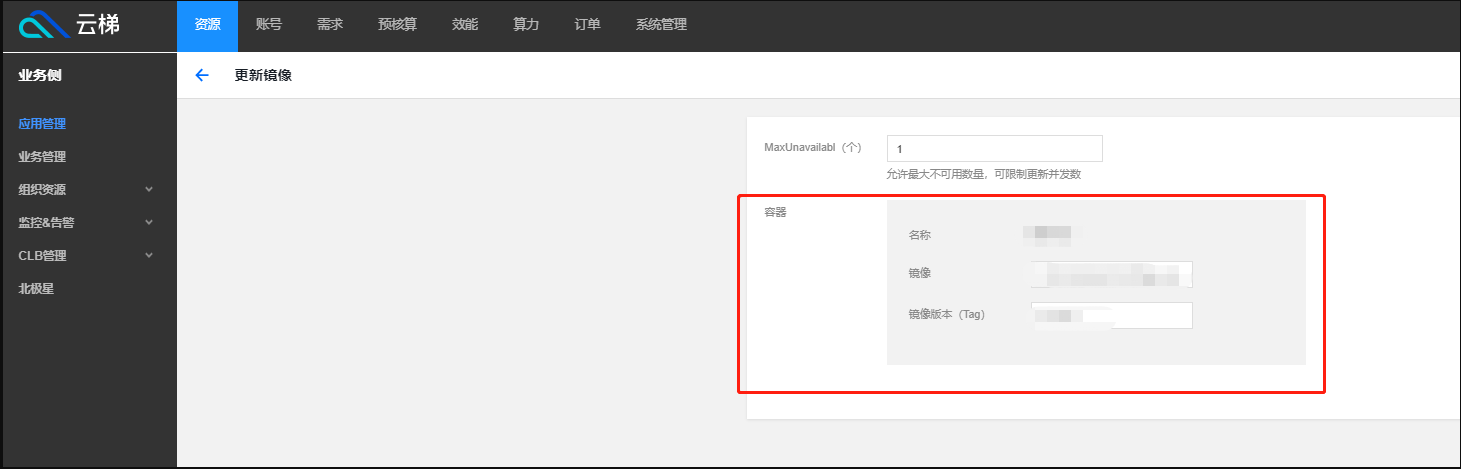
任务升级:任务程序升级过程,更新任务对应 engine 实例镜像版本即可
![]()
-
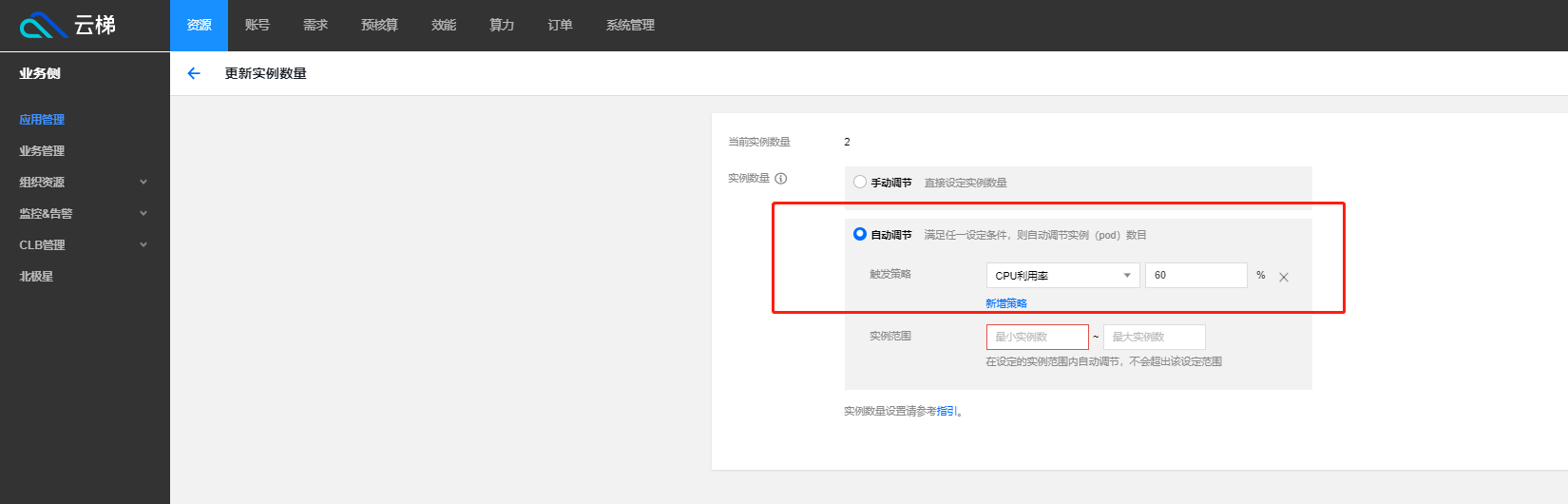
任务扩缩容:任务进行扩缩容过程,在 TKE 平台页面通过设置 HPA(Horizontal Pod Autoscaler) 自动调应用实例的扩缩容
![]()
云原生成熟度提升经验
1.对不同的业务类型进行服务划分,CPU 密集型服务创建核数大的 Pod 服务,IO 密集型服务(目前主要应对瞬时流量业务情况,网络缓冲区易成为瓶颈)创建核数偏小的 Pod 服务, 如 CPU 密集型业务单 Pod 取4核,而瞬时突发流量服务单 Pod 取0.25核或0.5核。
2.容器服务采用 HPA 机制,业务接入时根据业务请求量预估所需的 CPU 和内存资源,由预估的 CPU 和内存资源设置 Pod 服务的 Request 值,通常保持 Request 值为 Limit 值的50%左右。
自研上云效果
水滴平台在进行迁移上云过程中,自研平台迁移到 TKE 云上后带来了不少的效率提升。
上云后带来的效率提升主要有以下方面:
- 上云资源申请流程更加简单快速,上云前机器申领搬迁、虚拟 IP 申请、机器转移等流程周期一周左右,上云后资源申请周期缩短为小时级别
- 机器资源利用率提高67%,上云前 CPU 利用率约36%,上云后 CPU 利用率59.9%.
- 应对突发流量无需人工进行扩缩容操作,通过 HPA 机制可完成扩缩容,从人工扩缩容周期15分钟左右缩短到一两分钟。
- 业务策略部署上线周期可由2小时缩短至10分钟。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号