如何削减 50% 机器预算?“人机对抗”探索云端之路
前言
人机对抗旨在联合各个安全团队,共同治理黑灰产。由于历史原因,业务端对各个安全能力的访问方式入口多,对接系统/协议有十几个,呈现碎片化的状态,对外不利于业务对安全能力的便捷接入,对内不利于安全团队间的协同共建。为了提升各方面的效率,人机对抗服务在建设过程中大范围使用云服务,取得了很好的效果。回顾安全能力上云的过往,是一个从模糊到清晰,从迟疑到坚定的过程,在此给大家做个简要的分享。
关于云
云是什么
我理解的云本质可以理解为自由灵活的资源共享。资源随时加入,随时脱离,如空中飘动的云,来去无定,云起云落,看起来是那片云,细看又不一样。
对云的期待
站在计算机应用的角度,理想的云是可以让计算/网络/存储资源变成生活中的水和电,操控开关即可呼之即来挥之即去。对比物理机部署时代,云用户不用因某台机器死机造成数据损坏而暴走,也不用因机器损坏加班恢复服务而黯然神伤,
- 自动容灾(异常拉起,故障迁移)
- 轻松异地部署(多集群)
- 资源隔离-死道友不死贫道,你贪心了,安息吧
- 快捷扩容,资源呼之即来,来即能战
一切多么完美,开发运维测试兄弟的福音啊!
系统上云分析
随着公司基础服务的完善,目前公司内已有的服务设施可支持我们上云。经过调研发现,公司云相关平台及部署方式有:
CVM
在物理机基础上是对机器硬盘及 cpu 等资源做了虚拟化,用户使用方式上本质还是物理机的方式,只是可以避免机器裁撤的痛苦,用户体验层面上没有本质的改变。
容器化部署平台
docker 容器化部署是目前业界云主要部署方式,docker 容器化部署让我们一次建构,到处运行,完美满足自由运行,资源隔离的要求,系统环境天然是强维护的,一切程序/脚本/配置都在镜像中,不再有丢失或遗漏维护的问题。物理机时代机器损坏导致脚本配置破坏无法恢复的现象不会再出现,系统维护靠自觉或强约束这些问题天然地消失了。
而类似 K8s 这样的容器编排调度系统的出现,支持了自动容灾/故障切换/多集群部署等强大的平台特性,使我们离云服务的目标更近一步。基于 K8s 容器编排调度机制,目前公司内开发出一系列的部署平台,比如 123 平台,GaiaStack,TKE 等,再完美配合L5/北极星等寻址服务的自动关联管理,为云服务提供了完整的平台机制支撑。再加上基于资源管理平台对资源的灵活调配,使云计算使用的便捷性更上一台阶。比如在云梯上资源申请TKE容器资源(CPU/内存/存储等),过程就像到淘宝下单购物一样流畅,资源到位快速,在强推动审批下可达到分钟级到位,我第一次体验时是惊讶赞叹的。
基于对公司服务的深入了解及分析,最终我们决定使用 TKE 部署平台,采用 docker 容器化部署的方式对人机对抗服务上云
上云对开发的核心影响
上云带来一个核心变化就是资源是易变的,为了便于系统资源调度,服务结点IP是可变的,上云后需要面对包括上游业务端/自身/下游依赖端的IP变化,由此衍生出一系列的约束及依赖
- 上游变化: 对客户端通过来源IP鉴权模式不再可行,需要一种更灵活有弹性的鉴权方式
- 自身变化: 对外服务地址可将服务地址关联绑定到北极星的方式向外提供服务,如果所依赖的下游需要鉴权且使用源IP鉴权的话,下游需要改造支持更灵活的鉴权方式。多数情况下,服务需要对自身做一些例行运维工作,比如需要频繁修改配置下发,老的运维工具不再行得通,需要一个集中的运维配置中心。
- 下游的变化: 这个倒问题不大,只要提供L5或北极星方式自动寻址即可,目前平台提供了相应的服务管理功能。
系统架构及上云规划
人机对抗数据中心主要模块为变量共享平台,它的核心有2个,一个查询服务模块,另一个是支持变量管理 api 的 web 模块,这两模块都基于 tRPC-Go 框架开发,系统架构图如下:
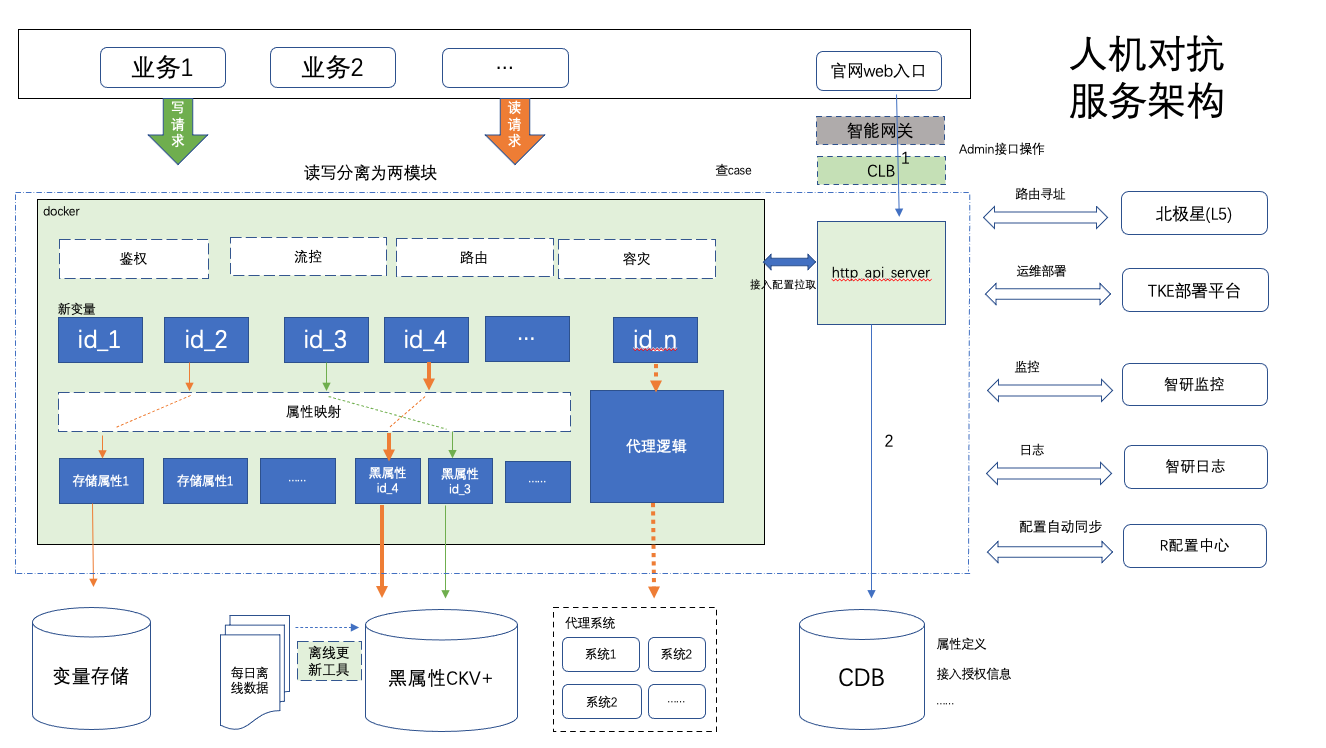
忽略一些依赖系统,目前暂时只对两个核心部分使用 TKE 部署上云,整个 TKE 部署架构如下:
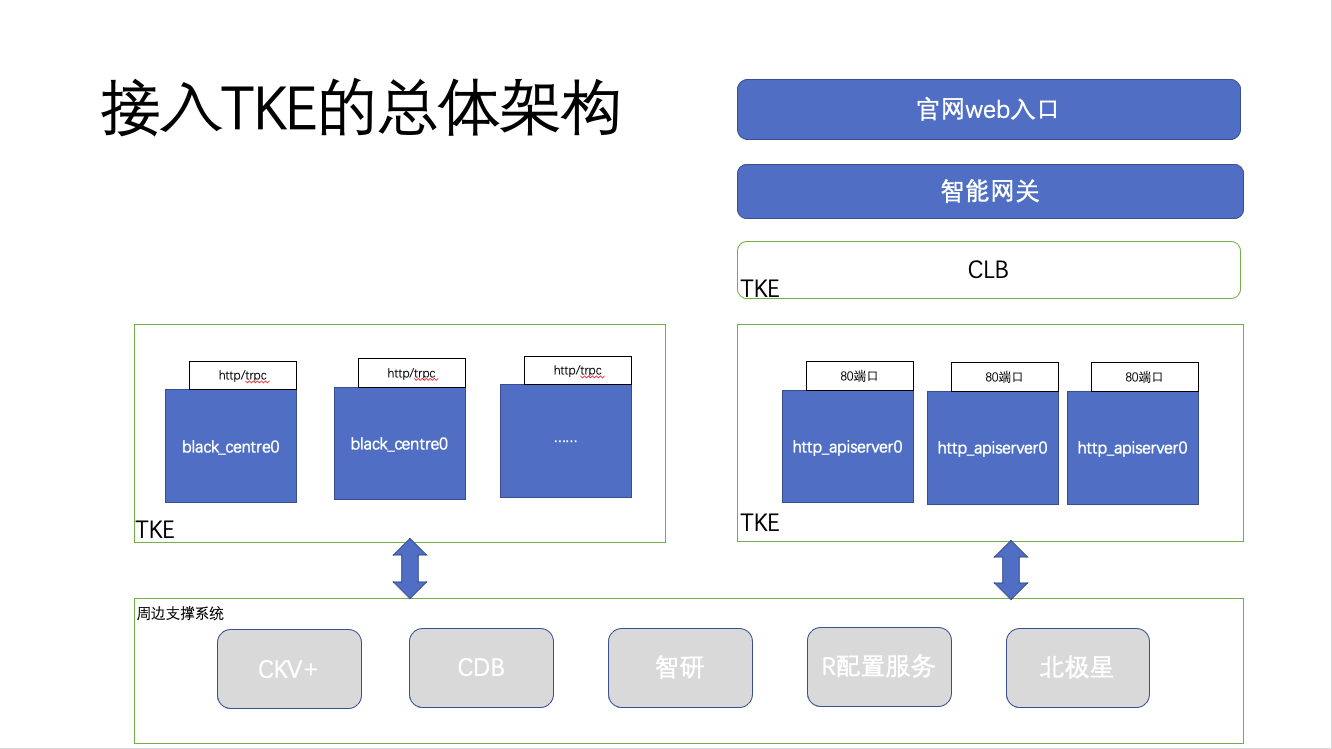
整个系统的部署规划,分别在 TKE 上创建两个系统负载 black_centre,http_apiserver,这两部分都是核心,其中 black_centre 承载用户的变量查询,web 端的请求经过智能网关,再经过 CLB,然后进入 http_apiserver 才得到了真正的业务处理,主要支持查 case 及系统变量管理,变量查询接入申请等功能。大家可能注意到,为什么 http_apiserver 引入了 clb 而不是直接由智能网关访问,主要因为模块上云后,计算结点的IP是随时可能变动的,但是公司内部申请域名指定服务地址时是不支持北极星或L5配置的,只能配置固定IP,而 CLB 提供的固定VIP的特性,很好地解决这个问题。
这里简单提一下CLB(Cloud Load Balancer),它是对多台云服务器进行流量分发的服务。CLB 可以通过流量分发扩展应用系统对外的服务能力,通过消除单点故障提升应用系统的可用性。最常见的用法时是根据关联转发规则(访问端口/http url等,自动转发到规则绑定的工作负载上。回到人机对抗的应用场景,我们主要是低负载的 http 服务,多个服务只要配置一下对url的转发规则就可以共用同一个服务地址资源。比如集群服务A和B都对外提供 http 服务,但是都需要使用80端口,按传统方式一般至少需要部署两台机器,但是利用共享的 CLB,我们只要配置 url 分发规则,就可以将不同接口分发到相应的云服务上。当然使用 nginx 也有类似的功能,但是易用性可维护性稳定性方面,CLB 强了不止一个级别
TKE 云应用部署时,容器易于缩扩容,容器本身一般不固定在某个IP上,所以云应用天生就应该设计为无状态依赖的模式。整个镜像尽量小,业务逻辑尽量微服务模式,避免同时糅合过多的逻辑。由于人机对抗相关模块是一个全新的模块,没有太多的负累,虽然协议灵活兼容性强,但是本质上功能独立,责职单一的,比较好地适应了这个场景。
至于如何申请资源,如何创建空间,创建负载之类的,流程很长,就不再大量截图了,产品帮助文档已经提供了较良好的指引,可参见https://cloud.tencent.com/document/product/457/54224,虽然我使用的是内网TKE,但内外网的云服务,总体上体验差别不大。
在使用 TKE 过程中,持续感受到 TKE 的强大和稳定,但最迫切的感受是需要一个容器参考复制功能,因为在现实的使用场景中,经常是想基于某个已存在的容器,稍修2-3个参数(大概率就是负载名/镜像版本),就能快速把负载创建起来。常用使用场景是测试验证/异地部署,或负载重部署(负载中有很多参数改不了,要改只能重建),甚至部署新服务(跟已有负载的资源使用及运行模式一样)。现在碰到要创建新负载,要填很多参数操作多了就感觉很繁琐,小需求,大进步,如果能解决这个问题,TKE 使用的便捷性相信也能上一大台阶。
发现云中君
从上面的架构流程分析来看,准备好镜像,利用 TKE 平台我们的服务已经跑起来,但是别人怎么找到我的服务地址? 有人说将服务地址录入L5/北极星搞定,但是不要忘了,云结点运行过程中,服务IP是随时可变的,需要想办法把云服务的变动的地址跟北极星建立关联,对北极星的地址列表进行关联管理,才能真正做到举重若轻。刚好 TKE 就提供了这样的特性,完美实现我们的目的。按下面的步骤来可解决:
- 创建负载,就是让服务跑起来,我们的已经没问题了。
- 为负载创建一个对应的北极星服务,供后面使用。
- 新建北极星关联规则,先进入北极星关联操作页面如下图
注意选择到对应的业务集群,进入创建页面:
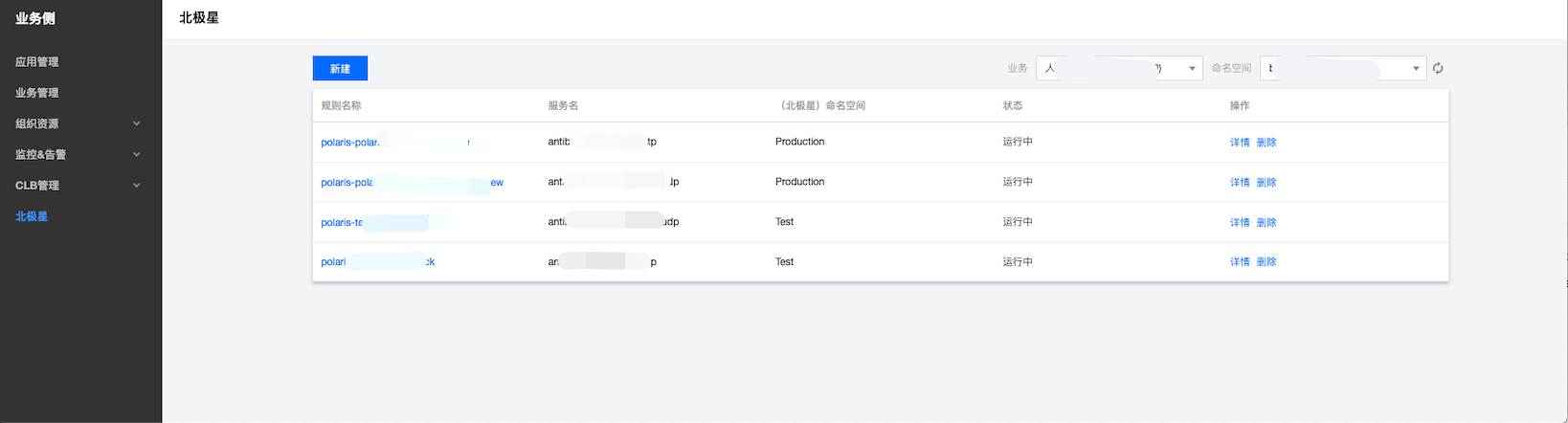
如此这般,把已经创建的北极星服务信息填进去,再跟指定的容器服务关联起来,再提交完成,最后完成北极星与动态服务地址的绑定
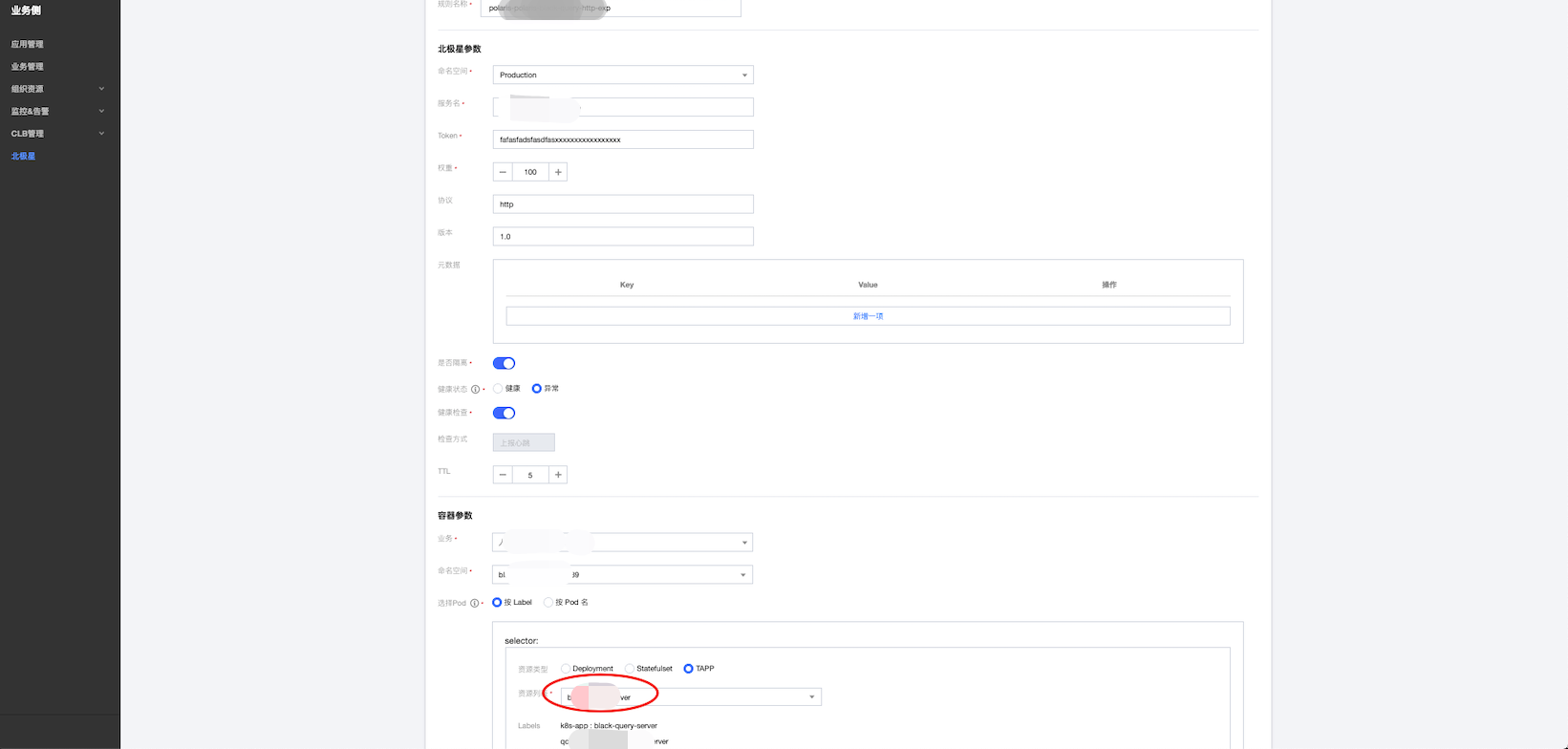
当我们对负载中的容器服务进行扩缩容时,我们可以发现北极星服务中的地址列表也会跟着进行增加或删除,这样无论服务部署变更或容灾迁移,业务方看到的服务地址都是有效的。
同时北极星为了兼容一些老用户使用L5的习惯,还支持对北极星服务创建L5的别名,用户可以利用别名,使用L5方式,就可以愉快寻址到与北极星发布的相同的服务。进入北极星官网左侧的菜单栏"服务管理"->"服务别名"创建别名
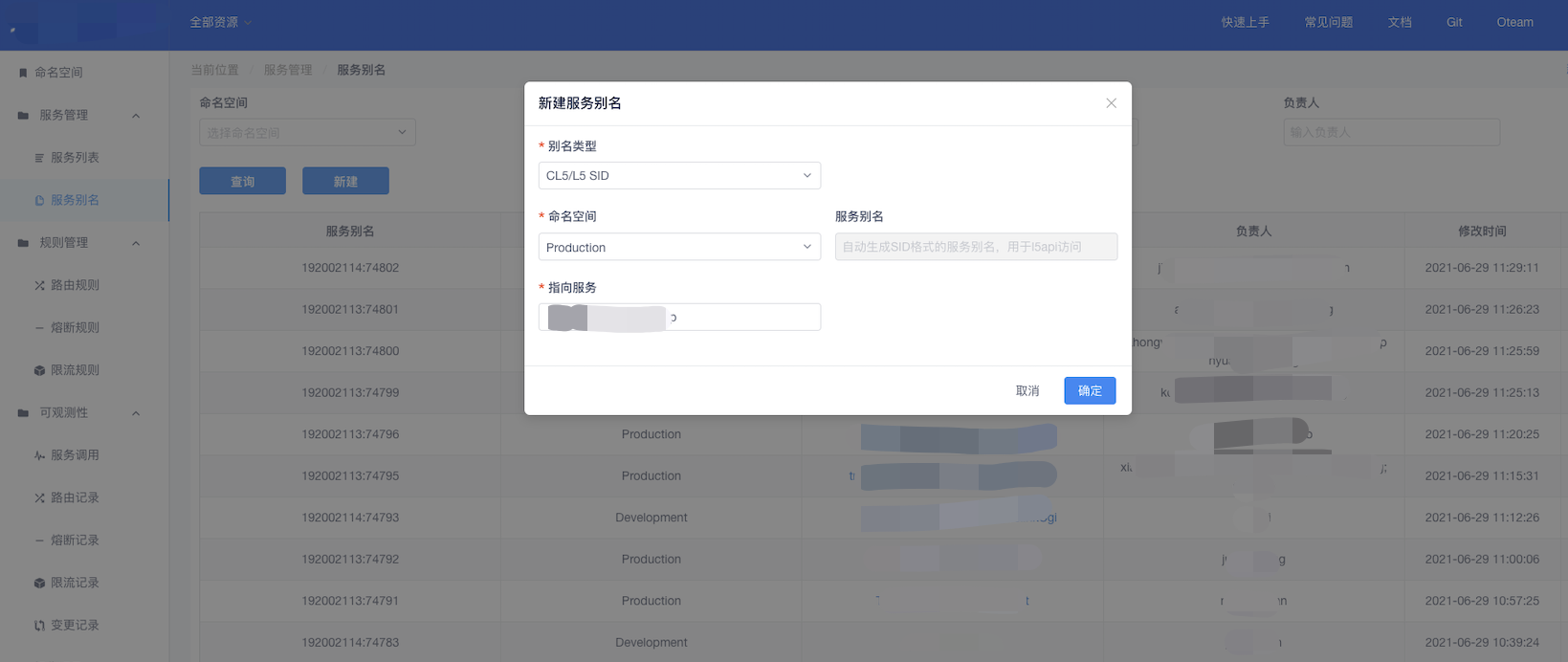
过往分析是老版本的l5agent对这方面兼容性不够,把l5agent升级到最新版本就能解决了。
云上鉴权思路的改变
系统上云后,由于结点IP的不固定,带来最典型的变化就是鉴权模式的影响。老模式下的按来源IP鉴权已经不适用,需要使用更灵活的鉴权方式。业界常用的两种认证鉴权的方案:
- SSL/TLS认证方式,这种方式经常被用来做传输加密,而不是访问控制,tRPC-Go的API已经有了相应支持。
- 基于Token的认证方式,这也是本系统重点要实现的方案
虽然方法很多,但是我们需要根据不同的场景根据需求选择不同的方案。
上游接入鉴权
当用户申请接入访问时,需要对用户进行认证鉴权,来源IP鉴权肯定是行不通的,权衡之下我们使用了 token 鉴权的方式,当用户申请接入时,我们会给他们分配 appid/token,当用户来访问时,我们会要求他们在消息头中带上时间戳,序列号,appid,rand 字符串,签名。其中签名根据时间戳,序列号,appid,rand 字符串及 token 联合生成。当服务端收到请求时,也会根据相应的字段使用与客户端同样的算法生成签名,并与请求的签名做比较,如果一致则通过,否则拒绝。其中时间戳的作用可用于防重播。
其实公司内的鉴权平台 knocknock 也提供了一套 token 签名鉴权方式,它是一种基于 tRPC-Go 认证鉴权方式。但是基于用户访问的简单性及降低平台依赖,所以最终人机对抗按上面的思路定制了自己的 token 鉴权方式。
下游依赖鉴权
目前我们的下游比较简单,大数据查询代理(见架构图)已经改造为支持token鉴权方式,ckv+ 是登录时密码鉴权方式。除了 CDB,其它服务没有太多的问题。访问 CDB,按安全规范不允许使用 root,而且需要针对IP授权访问,而授权需要先指定特定IP,在上云过程中,容器IP经常漂移。这些情况 TKE 已经在规划实现跟业务下游打通授权,CDB 就在其中。各个业务也可以对接TKE来打通注册。其实本质是在 CDB 与 TKE 之间增加一个自动注册机制,根据服务IP的变化,自动将IP注册到CDB的鉴权列表,逻辑上类似北极星之与 TKE 负载变动的关联关系。
为什么是 tRPC-Go
在人机对抗服务平台建设开始阶段,曾经面对过语言框架选型问题,部门原来习惯c++,框架上有 SecAppFramework 或 spp framework,新系统我们要怎么抉择? 回答这个问题前,回到我们面对的问题及目标:
- 访问量大,高并发性要求及较高的机器资源利用率
- 业务的快速发展要求我们高效支撑,包括开发/运维发布/定位问题/数据分析
- 公司内各服务上云是趋势,将会用到公司内各种云相关平台及服务,所用语言及 framework 最好能方便快捷把这些能力用起来,c++ 及 AppFramework 看起来就头大,各种服务支撑不够或用起来很难,有点力不从心,
面对部门老框架/spp Framework/tRPC-cpp/tRPC-Go 等一系列的选择,从性能/开发便捷性/并发控制/周边服务支撑丰富程度多个角度,最终选用了 tRPC-Go,目标就是围绕研效提升,更细化的分析如下:
- Golang 语言简单,各种代码包完备丰富,性能接近c++,但是天生支持协程且并发控制简单,简单的并发设计就可榨干机器资源,相对c++心智负担更低,生产能力更强。
- spp framework 和 tRPC-C++等公司内的一系列协程框架都是基于 c++,同时 spp 框架下,worker 单进程最多只能使用单核,而且 proxy 本身会成为瓶颈,tRPC-C++ 也使用过,复杂性比较高
- tRPC 是公司力推的 OTeam,并在不断完善,tRPC-Go 服务接口开发简单,而且周边服务支持组件丰富,增加到配置文件即可以跑起来,比如北极星/L5,智研日志/监控,各种存储访问组件(比如 mysql/redis 等),使用R配置服务等。开发层面各个环节基本覆盖,再加上原来有一定的使用使用经验,熟悉程度高,调用各种服务如臂使指。
使用 tRPC-Go 构建系统过程中,除了在熟悉过程碰到一些问题,但没碰到过很大的坑,代码写错也能很快定位,没碰到过那种神鬼莫测的诡异问题。总体上是流畅顺滑的,心智负担轻,能更聚焦于业务,生产能力强
众生之力加持
除了模块的核心逻辑,为了让服务更稳定,运维更高效,需要一系列的周边服务来支持,比如日志/监控/配置中心等支持服务
统一日志
云上结点,写本地日志对定位问题是不合适的,最核心原因在于问题出现时,本地日志你得先找到问题所在的结点再进去查看,光这个就是个麻烦的过程,而且云结点重启可能会使日志丢失,所以使用一个统一的网络日志中心势在必行,目前公司内主流的日志服务有:
- 智研,TEG产品,操作简单,易用,在验证码有成功实践。在 tRPC-Go 框架使用下,更简单易用,只要配置一下,不修改业务代码就可以把日志转发到日志中心
- 鹰眼,系统功能丰富,但接入复杂,易用性需要加强
- uls,cls等
最终选用的是智研日志,主要是在满足要求条件下足够简单易用,在 tRPC-Go 加持下,仅需要:
- 在代码中引入代码包
- 在 yaml 中简单配置即可使用:

在问题定位的时候,可以在 web 端查看日志:
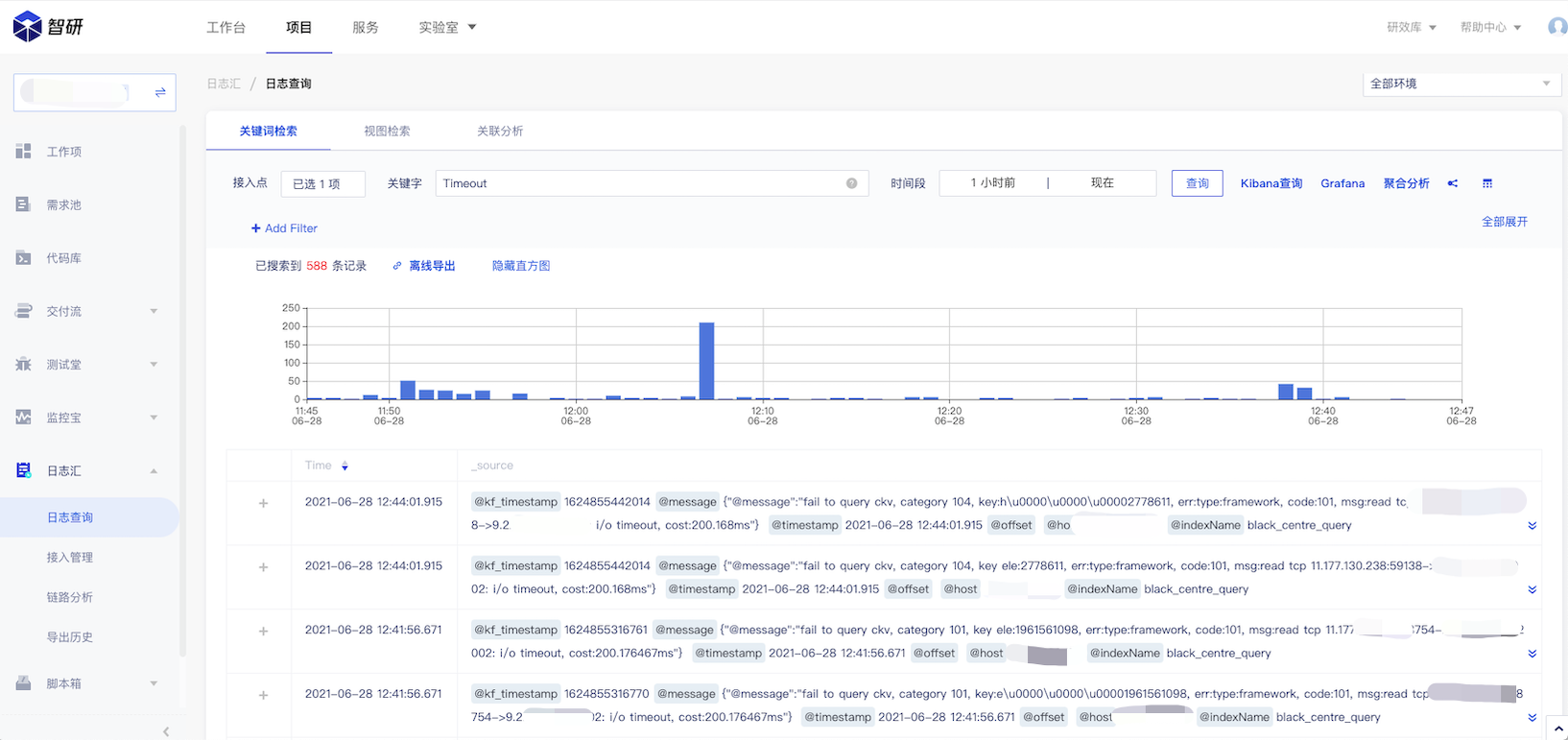
具体中间件实现细节及帮助可见 tRPC-Go 下面的智研日志插件工程
强大监控
监控服务有:
- 智研: TEG 产品,多维度监控,功能强大易用,使用简捷,部门内多次使用验证
- monitor: 基于属性定义的监控,老产品,成熟稳定,但是监控方式单一
- 007: 系统功能丰富,接入复杂,易用性需要加强
最终选用的是智研监控,智研的多维度监控,使监控能力更丰富,定位问题更快速,且使用足够简单,在 tRPC-Go 体系下,仅需要插件配置/插件注册/调用api进行数据上报,即可完成例行的数据监控,同时多维度监控,可以利用合适的维度定义,使监控数据更立体,更利于分析问题:
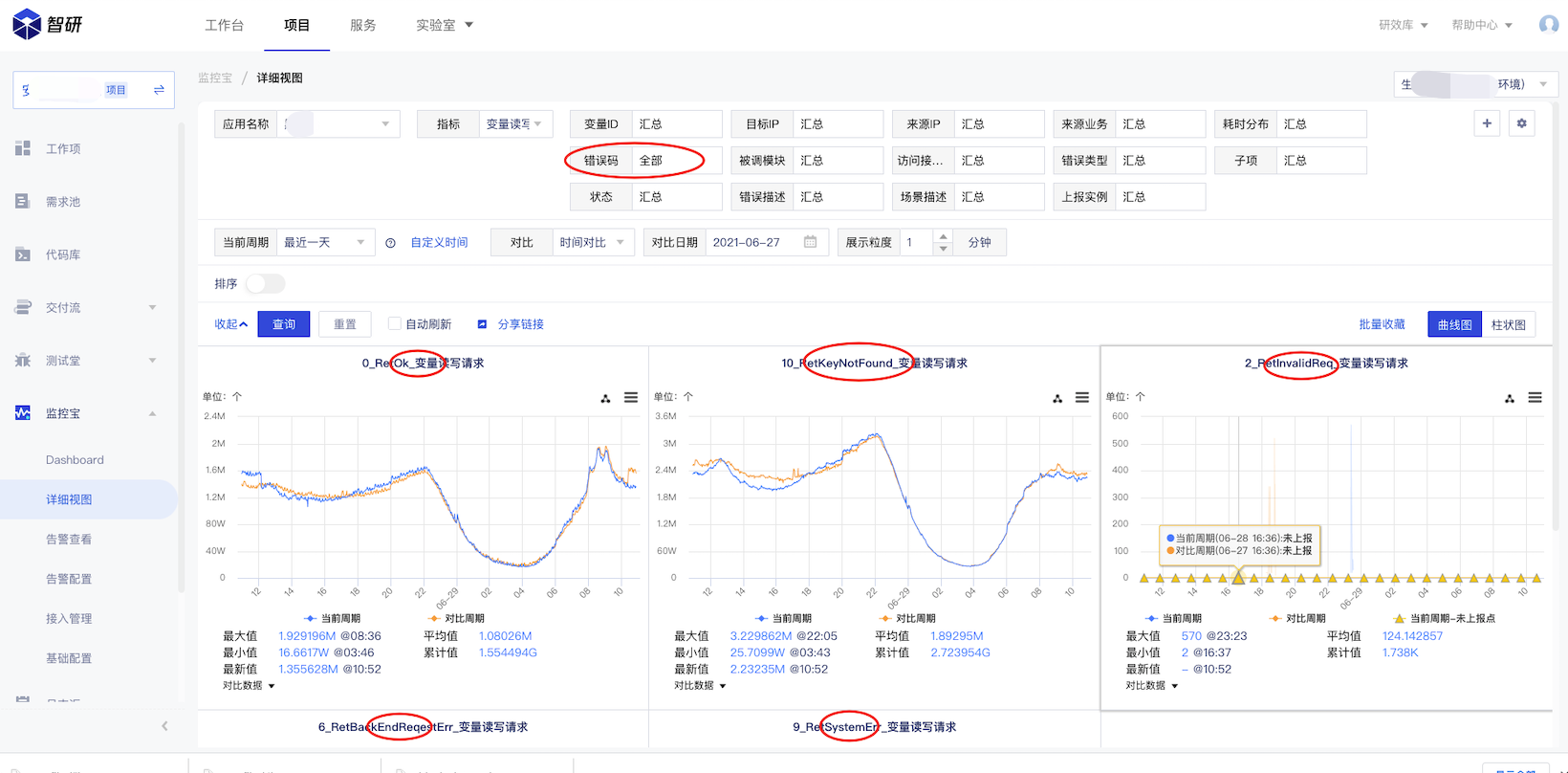
以上面这个图为例,可以定义一个变量查询的指标,关联来源ip/处理结果两个纬度,在我们关注对应业务的访问情况时,可以看到来自每个来源IP的访问量,也可以看到每种处理结果(如上图)的各个访问量,服务的整体情况一目了然,跟原来 monitor 监控相比,这是一个维度提升。
统一配置中心
我们的业务一般是基于一定配置运行的,我们也会经常修改配置再发布。过去传统的方式是到每个机器上修改配置文件,再重启。或是把配置集中存储,各机器上模块定时读取配置,再加载到程序中去。在 Oteam 协作的情况下,公司提供了各种配置同步服务,目前公司主要有两种同步方案:
T 配置服务
使用简单,功能丰富程度一般
配置权限控制单一,经咨询数据加密方面也没版本计划
R 配置服务
公司级方案,有专门的 Oteam 支持
配置同步有权限控制,后续会支持加密特性
配置形式支持丰富,json,yaml,string,xml 等
支持公有/私有配置组,方便配置的复用及配置在模块间的划分,同时支持灰度/分步发布
两个服务在 tRPC-Go 的开发模式下都简单易用,而且数据修改后后台可以即时生效,综合考虑下最终选用R配置服务做为配置同步同台,使用方式比较简单:
- 先在R配置服务上注册项目,并配置分组
- 在代码中连接R配置服务,读取数据并侦听可变配置项的变化。
下面是简单易用的操作界面:
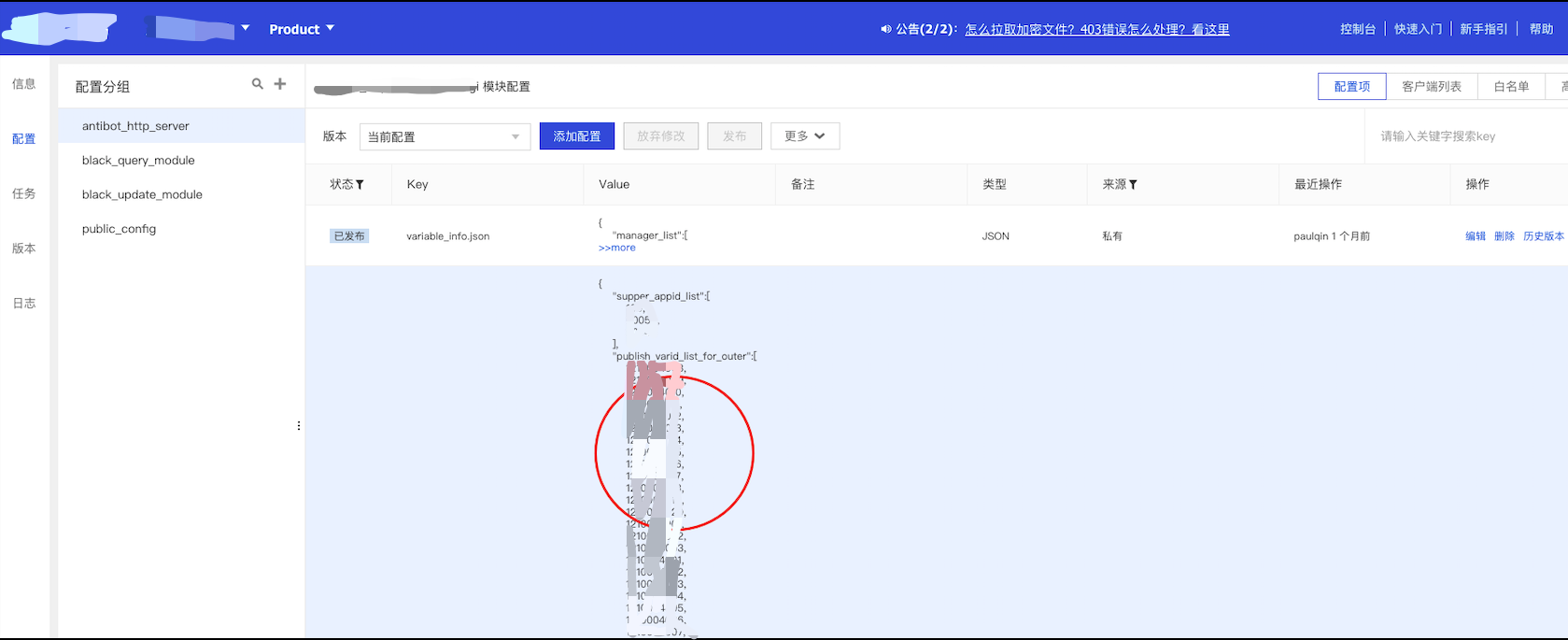
以对外发布变量ID的配置为例,这个ID列表会根据需求不停增加或修改,只要用户在web端修改发布,云上各结点就能感知到配置的变化并立即生效。无论是服务稳定性还是发布效率,相对传统配置修改发布方式都有了质的提升
tRPC-Go 对服务进行插件形式的设计,大大简化了各个服务的调用方式,再加上 tRPC-Go 下面活跃的开源项目,对研效的提升超过50%。以我们常用的访问 mysql/redis 为例,以通常的开源库使用或封装,需要处理异常/连接池封装/寻址封装(公司内使用L5或北极星)等,开发+测试基本需要1-2天,但是使用 trpc-go/database 下的对应开源组件可降到2小时左右。再说配置同步/日志中心服务的使用与自研或半自研相比,开发时间可以由2天降到4小时。客观而论,相关组件如果自研或半自研,在这么短的时间内,只能做到定制能用,稳定性通用性方面,相信是较难比得上平台服务的。关键是公司内的代码协同及各种 Oteam,将会有特性日益丰富强大的过程,他们成熟度的的提升,也会衍化为整个组织生产力的跃升。整体评估,使用公司内成熟的中间件是一个正确的选择
上云带来了什么
目前人机对抗服务不断在引入老系统流量或接入新业务,整个系统读写访问量最高超过 1200万/min,变量纬度访问流量最高达 1.4亿/min(单个访问请求可以访问多个变量)。整个服务在云上稳定运行超3个月,不负众望。
稳定性提升
忽略模块本身的代码质量,稳定性提供主要是由云上容器部署所具有的几个平台特性所带来的:
-
TKE支持服务心跳检查,应用异常拉起,故障迁移
-
轻松支持异地部署,多地容灾
-
资源隔离,异常业务不影响正常业务
如果99.999%是我们对服务稳定性的追求,相对老部署模式下小时/天级别的机器异常恢复时间,服务稳定性提升1-2个9这是可以预见的
提升资源利用率
在物理机/CMV的部署模式下,一般整机资源利用率达到20%就不错了,特别是一些小模块。但是上云后TKE的弹性扩缩容机制之下,通过配置轻松可以使容器资源利用率达到70%。
比如下面就是目前我的应用大盘监控,为了应对可能的大流量冲击,我配置了自动扩容,且设置了较多的基础结点数,所以 cpu 占用率较低,实际上这些都是可以配置的。云上容器模式部署相对传统模式可以提升50%的系统资源利用率。
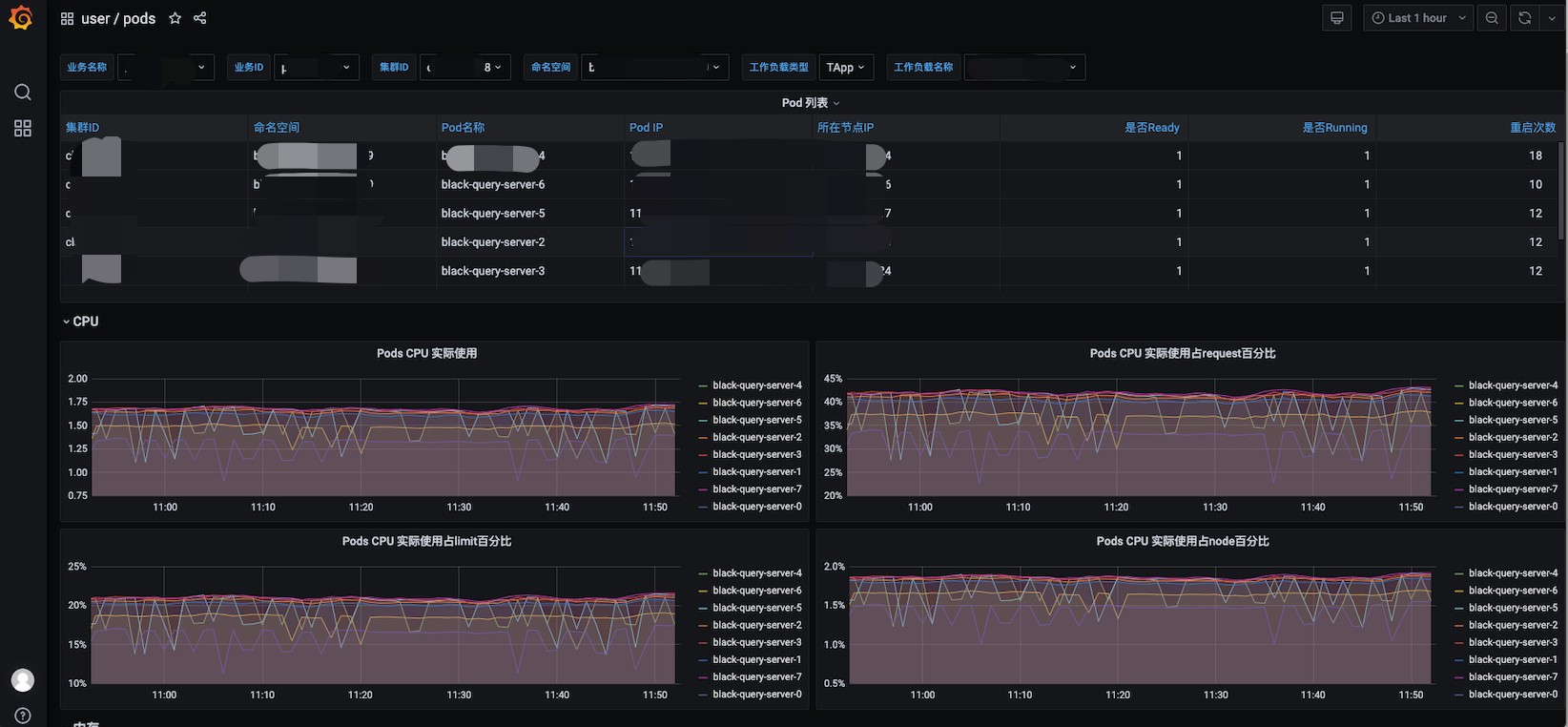
上云后的提升
- 利用公司内的开源技术,需求开发效率提升50%以上
- 由于机器资源利用率的提升,人机对抗方面的机器预算比原来缩减了50%
- 各种服务的中心化使得发布及问题定位变得更快捷,比如R配置服务及智研的投入使用,发布及问题解决由半小时->分钟级
- 容器部署模式,系统进入天然强维护状态。因为镜像是完整可重演的,有问题修复后也会肯定记录入库,没有丢失或遗漏的后顾之忧。在物理机/CVM时代,程序/脚本/配置很可能是单一放置到某个机器上(特别是某些离线预处理系统),机器损坏或系统崩溃这些东西就没了,当然你会说物理机部署也能做到备份或及时入库,但是那需要依赖于人的自觉或对行为的强约束,成本是不一样的。但是大多数情况下,墨菲定律会变成你绕不开的梦魇
结语
回首这么多年中心和公司在研效提升的努力,系统框架从最开始的 srv_framework,到中心的 Sec Appframework,再到 spp framework 等各种协程框架,再到 tRPC 的蓬勃发展。数据同步一致性从手工同步,主备同步,到使用同步中心同步再到公司内的各种分布式存储服务,系统部署从物理机手工部署到各种五花八门的发布工具到织云蓝鲸,从物理机,CVM再到承载服务的云得到大规模业务的成功验证等,公司的研效提升一路走来,从一个蹒跚学步的小孩,成长为一个健步如飞的少年。站在现代算力体系巅峰的云上回望,公司对云的的认识和探索实践,也经历了从模糊到清晰,从迟疑到坚定的过程,而我们的努力并没有被这个时代所辜负,一串串提升的各种指标描述及用户的认可就是对我们的肯定和嘉奖,激励我们义无反顾向未来前行。
认识并建设云,创新并开拓云,我们脚踏大地,可是我们更仰望星空。子在川上曰:“逝者如斯夫!不舍昼夜。”
以上是我在人机对抗上云过程中的一点实践跟感悟,跟大家分享共勉。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号