一篇文章带你搞懂 etcd 3.5 的核心特性
作者
唐聪,腾讯云资深工程师,极客时间专栏《etcd实战课》作者,etcd活跃贡献者,主要负责腾讯云大规模k8s/etcd平台、有状态服务容器化、在离线混部等产品研发设计工作。
etcd 3.5发布
美东时间2021年6月15号18点,继 etcd 3.4 版本发布近两年之后,etcd 社区官宣发布了3.5 稳定版本,其主要贡献者来自 Google、AWS、Tencent、Red Hat、ByteDance、IBM 等公司的开发者。etcd 3.5 版本的发布,将极大提升开发者体验、更快、更稳的支撑 kubernetes。
腾讯云容器团队(tangcong/wswcfan/mlmhl等)一直致力于参与 etcd社区开源的贡献,参与以及贡献了大量提升 etcd 稳定性、性能优化的 PR 和 QoS Proposal 等,是目前国内最活跃的贡献团队,未来我们也将持续将内部大规模 kubernetes 和 etcd 集群的治理经验回馈给社区,为 kubernetes 和 etcd 社区添砖加瓦!
etcd 3.5 特性分析
那么在 etcd 3.5 版本中有哪些令人期待的特性呢?
下图我从模块化/开发者体验、性能、稳定性、运维和安全、文档及 RoadMap 方面为你总结了 etcd 3.5核心要点。
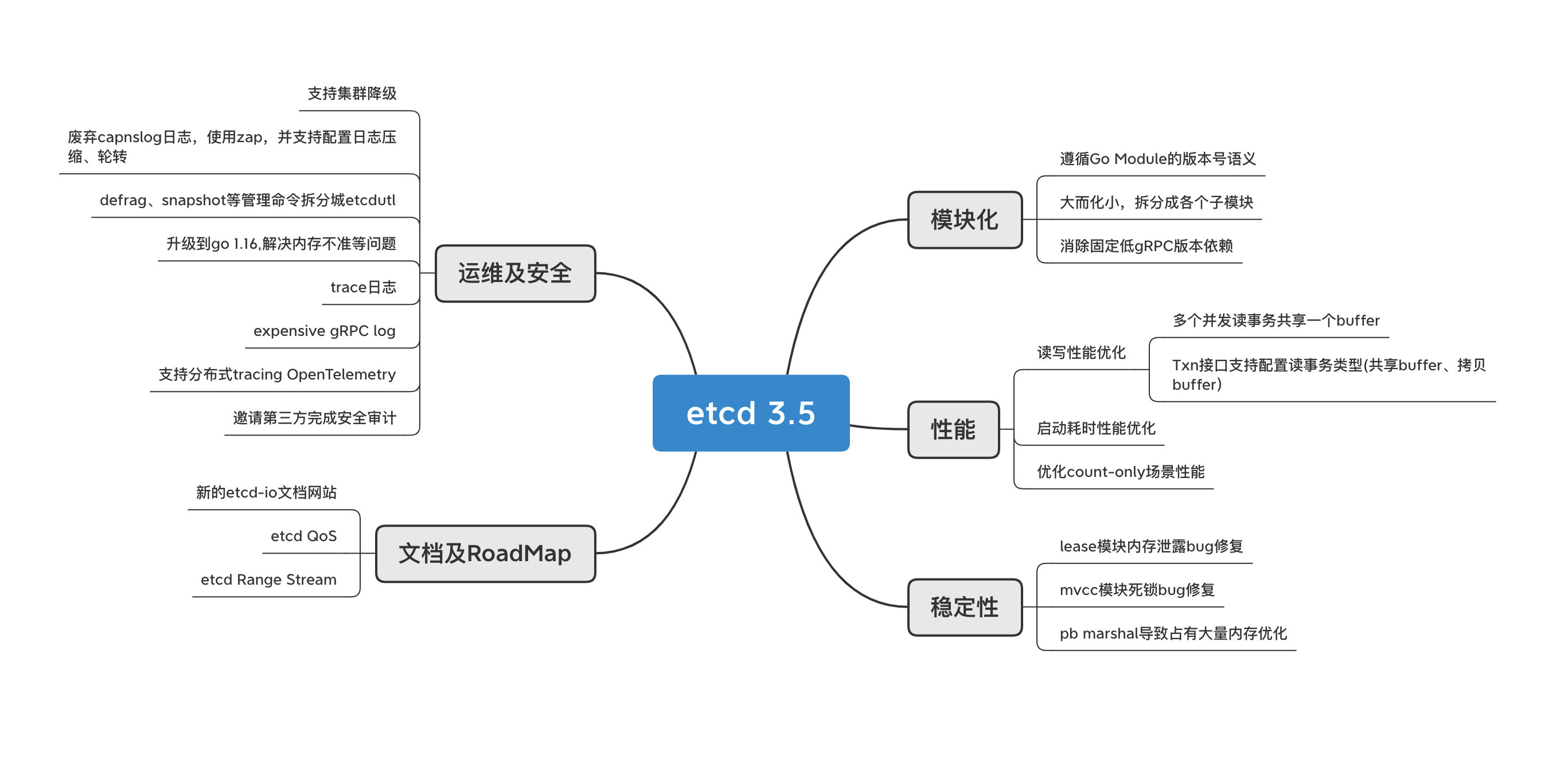
首先,在我看来,在etcd 3.5版本,最令开发者期待的当属对 Go Module 的版本号语义的支持,并将之前大的 etcd 模块按功能进行了拆分,实现了 etcd 的模块化等,解决了饱受社区吐槽的 “go get fail”、依赖复杂、循环依赖、强制依赖过低的 gRPC 版本等痛点,将大大提升 etcd 开发者幸福度。
其次,从性能及稳定性上看,etcd 3.5 版本包含了若干对etcd读写性能优化、启动耗时优化、重要 Bug 修复、内存占用优化等特性,将显著提升集群稳定性、吞吐量、延时,将更好的支撑大规模 kubernetes 集群。
最后,从运维、安全上,etcd 3.5 版本包含了 etcd 日志轮转/压缩、集群降级、etcdutl、expensive request 定位、本地 trace 及分布式 trace OpenTelemetry 等特性支持,以及一系列安全问题优化,将显著提升问题定位效率。
接下来我就从以上各方面为你解读 etcd 3.5 中核心特性。
etcd 3.5 核心特性解读
支持 Go Module 版本号语义及模块化
自从 Go 社区在 Go 1.11 版本开始推出官方的包依赖管理解决方案 Go Module,并在 Go 1.14 版本达到生产环境可用标准后,绝大部分的项目已经使用 Go Module 来解决项目中的包依赖管理的痛点,并且 Go 在1.16版本后 Go Module 已经默认开启了。
然而,如果你的 Go 项目依赖 etcd,原以为一个"go get go.etcd.io/etcd/"命令能下好所有依赖,结果却是要经历一波三折才能下好各种依赖,一开始你会遇到如下的 boltdb 错误。通过 Go Modules 的如下 replace 命令解决后,又会遇到因为 etcd 依赖过低的 gRPC 版本,导致的 gRPC 错误等。
% go get go.etcd.io/etcd/
go get: github.com/coreos/bbolt@none updating to
github.com/coreos/bbolt@v1.3.6: parsing go.mod:
module declares its path as: go.etcd.io/bbolt
but was required as: github.com/coreos/bbolt
go.etcd.io/etcd imports
github.com/coreos/etcd/etcdmain imports
github.com/coreos/etcd/proxy/grpcproxy imports
google.golang.org/grpc/naming: cannot find module providing package google.golang.org/grpc/naming
当你解决完各种依赖问题,满心欢喜的开始编译时,你又可能会遇到版本过低,导致编译错误,又陷入崩溃中。
为什么会版本过低呢? 查看 go.mod 文件你会发现,原来你最后 go get 下载得版本是 v3.3.25,如下所示。
% cat go.mod | grep etcd
module github.com/tangcong/etcd-lab
github.com/coreos/etcd v3.3.25+incompatible // indirect
go.etcd.io/etcd v3.3.25+incompatible
首先为什么v3.3.25后面含有个 incompatible 呢? 这主要是因为 etcd 3.3 分支还未支持 Go Module(未含有go mod文件),incompatible 表示它的主版本号大于2,与较低的版本号属于同一模块。go 命令可能会将其自动升级到更高的 incompatible 版本,即使它会导致构建失败。
那如何通过 go get 来下载 etcd 3.4 最新稳定版本呢?
首先在etcd 3.4中引入了 go mod 文件,然而 Go 社区在设计 Go Module 的时,定了一些可能会导致原有 Go 服务迁移到 Go Module 时需要进行适配的规则。etcd 含有三大版本,v0系列、v2系列、v3系列,在 Go Module 的设计实现中,如果主版本是 2 或更高版本发布的模块必须在其模块路径上具有匹配的主版本后缀。比如,如果模块在 v0.5.0 中具有路径 go.etcd.io/etcd/client,则在 v2.x.y 版本中它必须具有路径 go.etcd.io/etcd/client/v2,在 v3.x.y 版本中它必须含有路径 go.etcd.io/etcd/client/v3。
很显然,接触过 etcd 的小伙伴们都知道,etcd 在3.4分支的代码与 Go Module 版本号语义是不兼容的,并未遵从Go Module 的以上设计。因此当你通过如下 go get 命令下载指定版本号时就会报如下错误,这是因为 etcd 3.4 分支 go mod 定义的模块路径是 go.etcd.io/etcd,它是使用旧版的 v0 module 命名。
% go get go.etcd.io/etcd@v3.4.9
go get: go.etcd.io/etcd@v3.4.9: invalid version: module contains a go.mod file, so major version must be compatible: should be v0 or v1, not v3
针对这种情况,我们可以通过 Go Module 提供的伪版本号(pseudo-versions)来实现对 etcd 3.4 的依赖管理,比如 kubernetes 项目中 go mod 中管理 etcd 的依赖如下所示:
go.etcd.io/etcd => go.etcd.io/etcd v0.5.0-alpha.5.0.20200910180754-dd1b699fc489
那上面的一连串字符串分别是含义呢?
-
v0.5.0-alpha.5 是祖先语义版本标记,go 命令下载依赖时会进行验证检查。
-
20200910180754 表示 commmit 提交记录时间戳
-
dd1b699fc489 是 commit 记录 hash 值的前12位,go get 会通过此 hash 值从 git 中下载对应的版本的代码。
那以上信息如何生成呢? 你可以通过如下的命令进行查看:
% TZ=UTC git --no-pager show \
--quiet \
--abbrev=12 \
--date='format-local:%Y%m%d%H%M%S' \
--format="%cd-%h"
20200824191128-ae9734ed278b
也就是如果你要下载 etcd 3.4 版本的代码,你可以通过参考 kubernetes 项目指定伪版本号来实现 etcd 3.4 库的依赖管理。
为了解决以上各种痛点、吐槽,etcd 社区首先通过 name packages with go.etcd.io/etcd/v3 pr,遵循 Go Module 版本号语义规范支持了v3语义,解决了无法通过"go get go.etcd.io/etcd/v3"下载最新版本的问题。
但是 etcd 依赖问题远远不止此,从 kubernetes 项目中的 go mod 文件中你可以看到,竟然出现了多个 etcd 相关的依赖包,K8s 的代码库依赖也与 etcd 依赖存在若干冲突,甚至还在有些项目出现了如下循环依赖。
github.com/coreos/etcd => github.com/coreos/etcd v3.3.13+incompatible
go.etcd.io/etcd => go.etcd.io/etcd v0.5.0-alpha.5.0.20200910180754-dd1b699fc489 // ae9734ed278b is the SHA for git tag v3.4.13
etcd -> prometheous-client -> prometheus-common -> go-kit -> etcd
为了解决以上问题,社区又提出了模块化的解决方案,也就是将 etcd 整个大的模块,按角色与功能拆分成 client、server、raft、api、tests、etcdctl、etcdutl 相关的子模块,具体如下图。
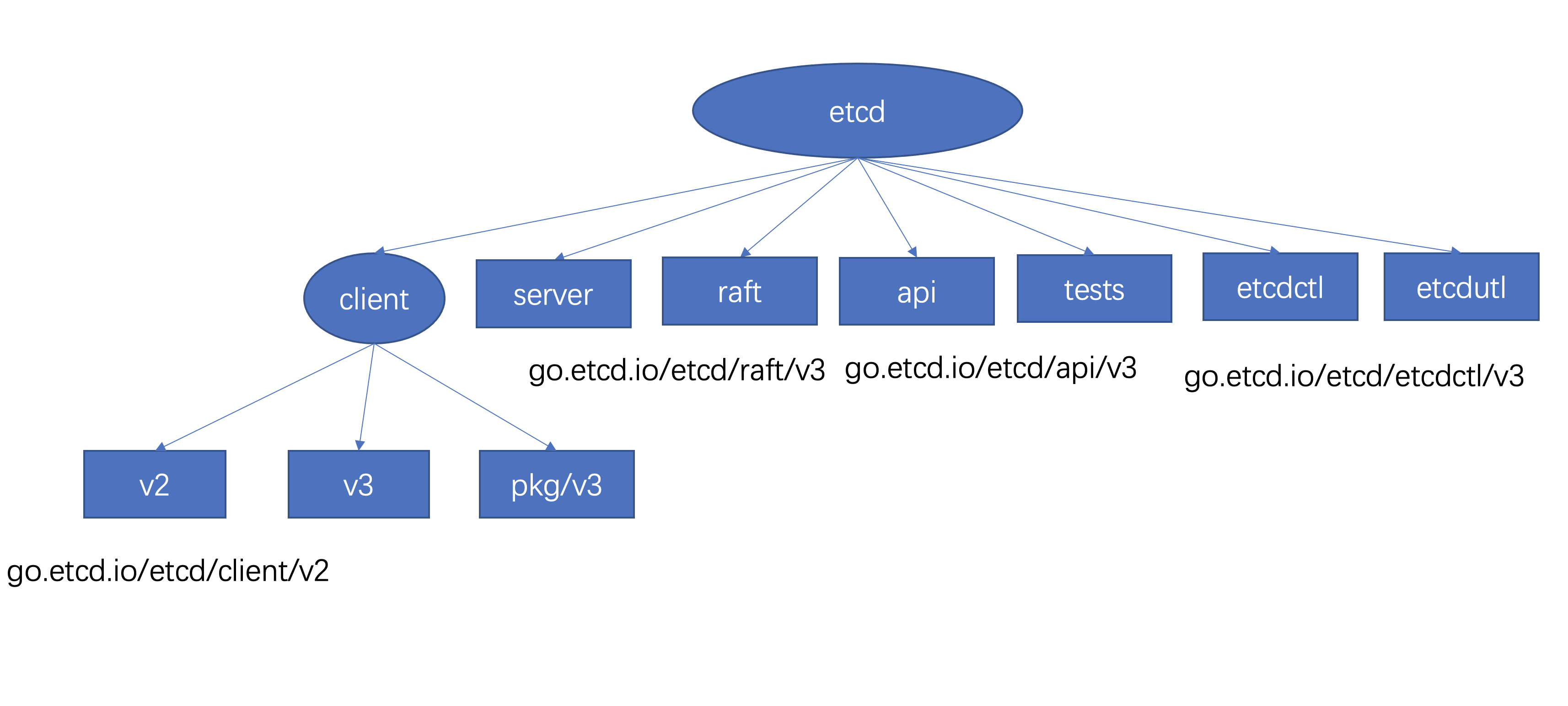
通过这样的模块化拆分后,各个业务只需要下载对应的模块就可以,比如你的项目需要使用 etcd client v3 库对etcd 进行读写操作,你只需要执行如下 go get go.etcd.io/etcd/client/v3 命令即可,执行完后 go mod 内容如下。
% go get go.etcd.io/etcd/client/v3
require go.etcd.io/etcd/client/v3 v3.5.0
如果你需要通过 etcdctl 访问 etcd server,也只需要执行如下 go get 命令安装即可。
% go get go.etcd.io/etcd/etcdctl/v3go get: added go.etcd.io/etcd/etcdctl/v3 v3.5.0
性能及稳定性提升
etcd 读写性能优化
重点介绍完 etcd 3.5 版本对 Go Module 版本号语义的支持以及模块化后,接着我们再看看 etcd 有哪些令人期待的性能及稳定性提升呢?
首先是 etcd 的读写性能优化。在介绍 etcd 读写性能优化之前,我先和你简单介绍下背景知识,也就是在 etcd 中读写一个 key hello 的基础原理。
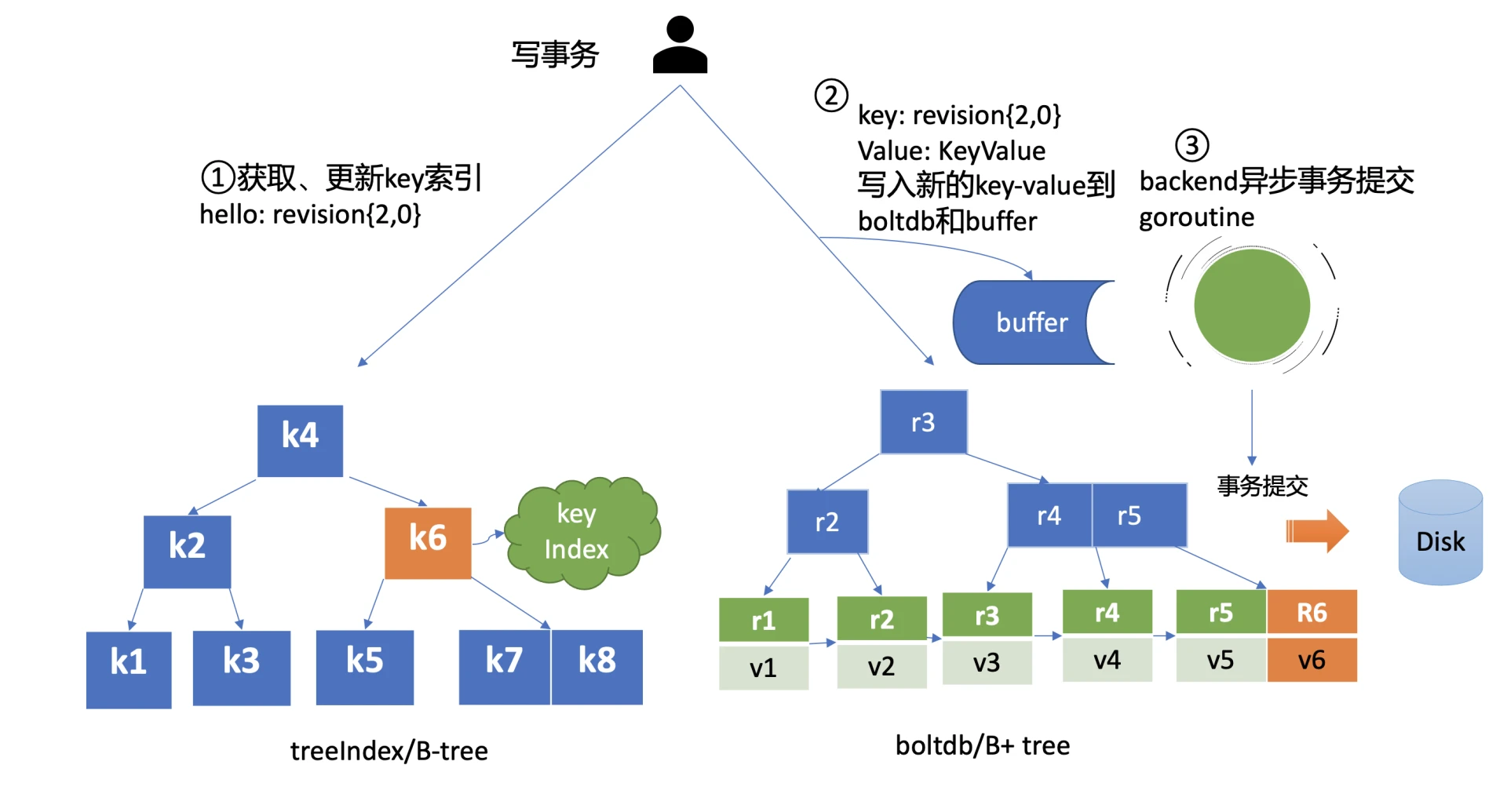
启动一个空集群后,当你通过 etcdctl 执行 put key hello 写流程核心如下图所示:
-
根据 etcd 的全局逻辑时钟版本号(空集群启动默认为1)自增生成 key hello 版本号 revision{2,0},并从treeIndex/B-tree 中查找索引项,若不存在则插入 key hello 索引项,存在则更新。
-
key是 revision 版本号{2,0}, value 是个保存用户请求原始 key、value、版本号等的结构体,etcd 基于 boltdb 的 kv API,将以上 key-value 写入到 boltdb 和 buffer(保存暂未持久化到 boltdb 的数据)。
-
注意 etcd 为了提升写性能,一般情况下(pending 事务过多才会触发同步提交)是异步批量(backend goroutine 每隔 100ms)将boltdb的事务进行提交,持久化到磁盘的。
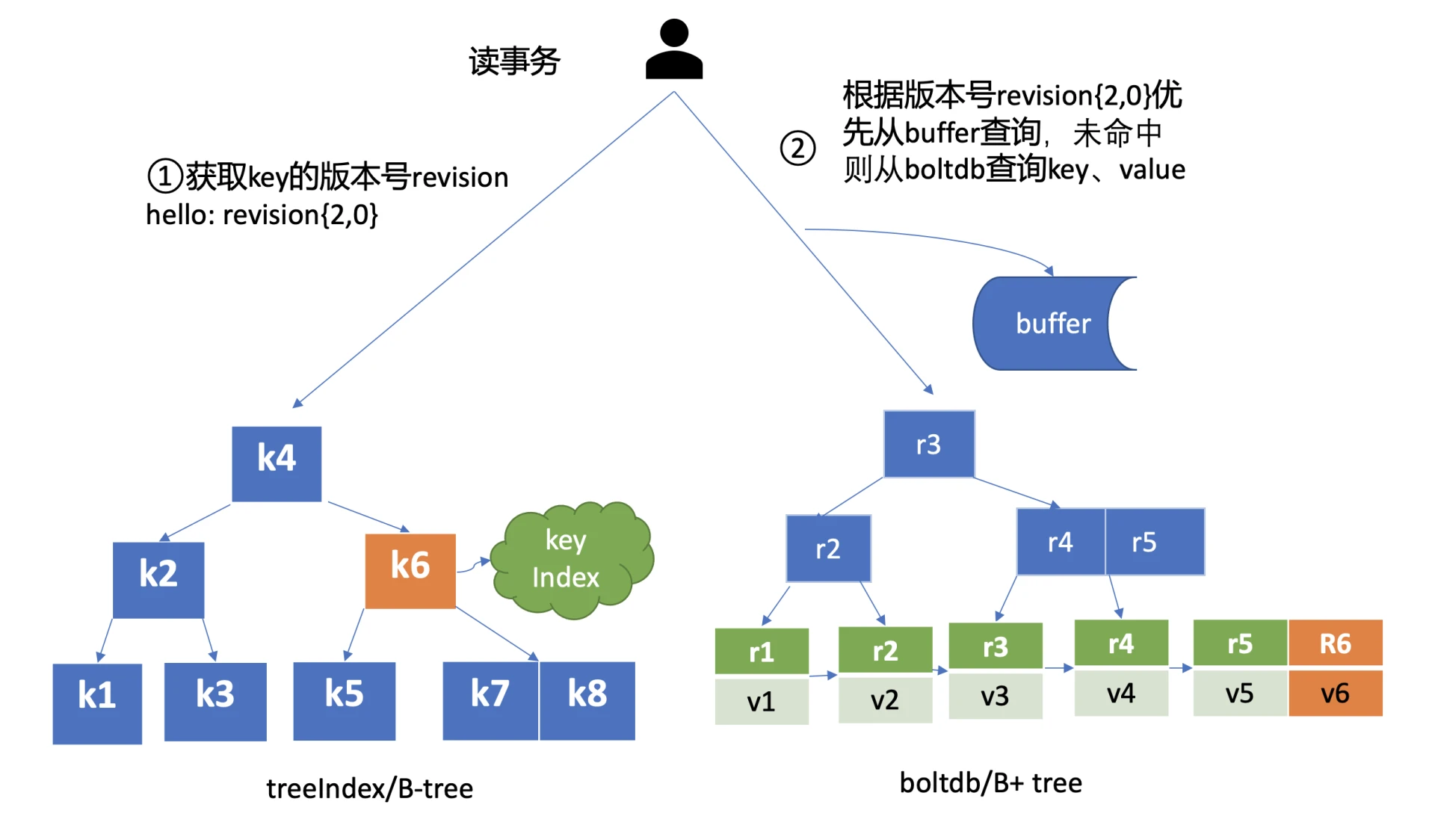
介绍完写流程,我们再看看读流程。etcdctl get hello 其读流程核心如下图所示(引用自我的 etcd 极客时间专栏 《基础架构:etcd 一个读请求是如何执行的?》)。
-
首先根据 key hello 从 treeIndex/B-tree 中查找索引项,若存在则返回其版本号{2,0}.
-
其次根据版本号{2,0}优先从 buffer 中查询,若命中则直接访问。
-
若 buffer 中未命中则从 boltdb 查询。
etcd 3.5 的优化重点就是以上读写流程中的 buffer,我们再来看看 etcd 不同版本对其的优化历史。
-
在 etcd 3.2 为了提升写吞吐量,引入了 buffer。在 etcd 3.2 到 etcd 3.3 版本,读事务会加读锁,写事务结束时要升级锁更新 buffer,但是 expensive request 导致读事务长时间持有锁,最终导致写请求超时。
-
在 etcd 3.4 中,为了解决这个这个问题,实现了全并发读,创建各个读事务的时候都会全量拷贝 buffer, 读写事务不再因为 buffer 阻塞,大大缓解了 expensive request 对 etcd 性能的影响。尤其是 Kubernetes List Pod 等资源场景来说,etcd 稳定性显著提升。
然而 etcd 3.4 各个读事务拷贝 buffer 的行为,带来了不可避免的开销,并对写入密集型的事务性能产生了负面影响。为了优化各读事务拷贝的带来的开销,etcd 社区在 etcd 3.5 版本中通过如下两个优化方案进一步提升事务并发性能。
第一是多个读事务在 buffer 未变的场景下,共享同一个读 buffer 的解决方案,其原理如下图所示。
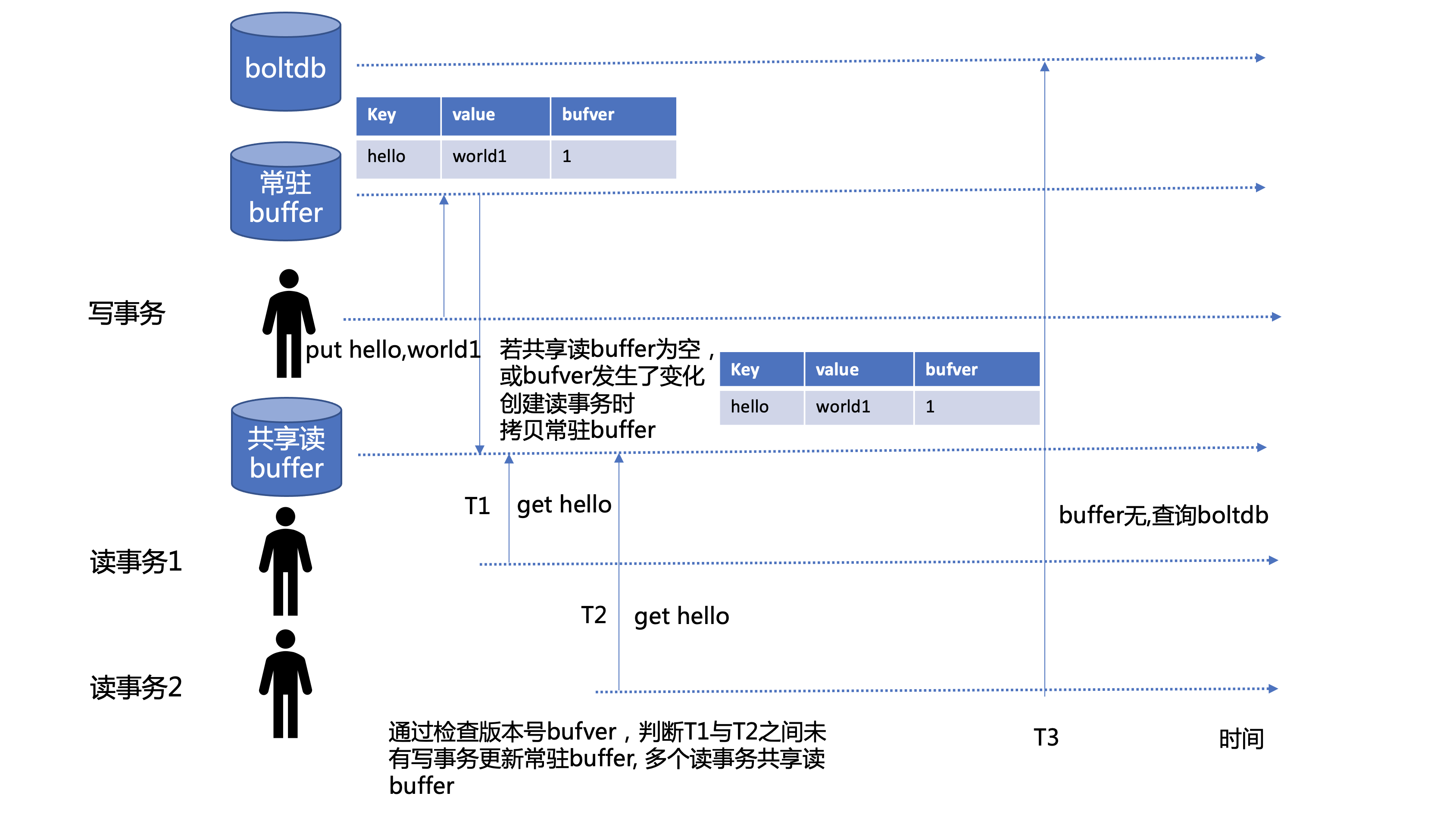
其原理如上图所示,优化后的创建读事务时流程如下:
-
若共享读 buffer 为空,则从写事务所维护的常驻 buffer 中拷贝当前最新数据到共享读 buffer。
-
若共享读 buffer 不为空,则判断当前常驻 buffer 中的版本号与共享读 buffer 中的版本号是否一致,若不一致则说明共享读 buffer 是陈旧的,则全量拷贝常驻 buffer。由此可见,此优化方案在读多写少的场景,将表现较好。若写请求较频繁,将退化成之前的每次创建读事务时都需拷贝一次 buffer 模式。
-
若共享读 buffer 中的版本号与常驻 buffer 版本号一致,说明共享读 buffer 在上一次被创建之后,并无写请求更新它,可直接使用当前共享读 buffer 即可。
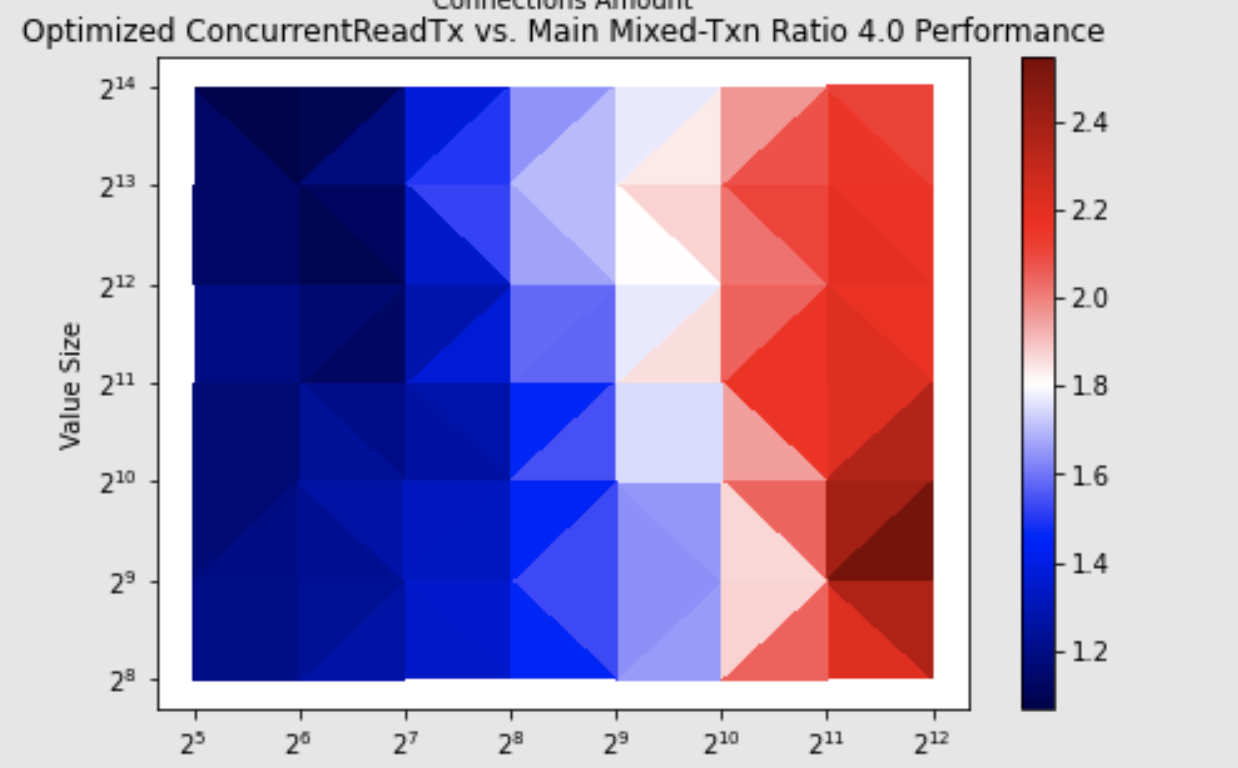
优化后的性能对比数据如下图读写热力图所示,横轴为连接数 /client,纵轴为 key-value 数,key-value 大小为256 个字节,在 K8s 场景下(读/写为4:1),有2倍左右的性能提升。
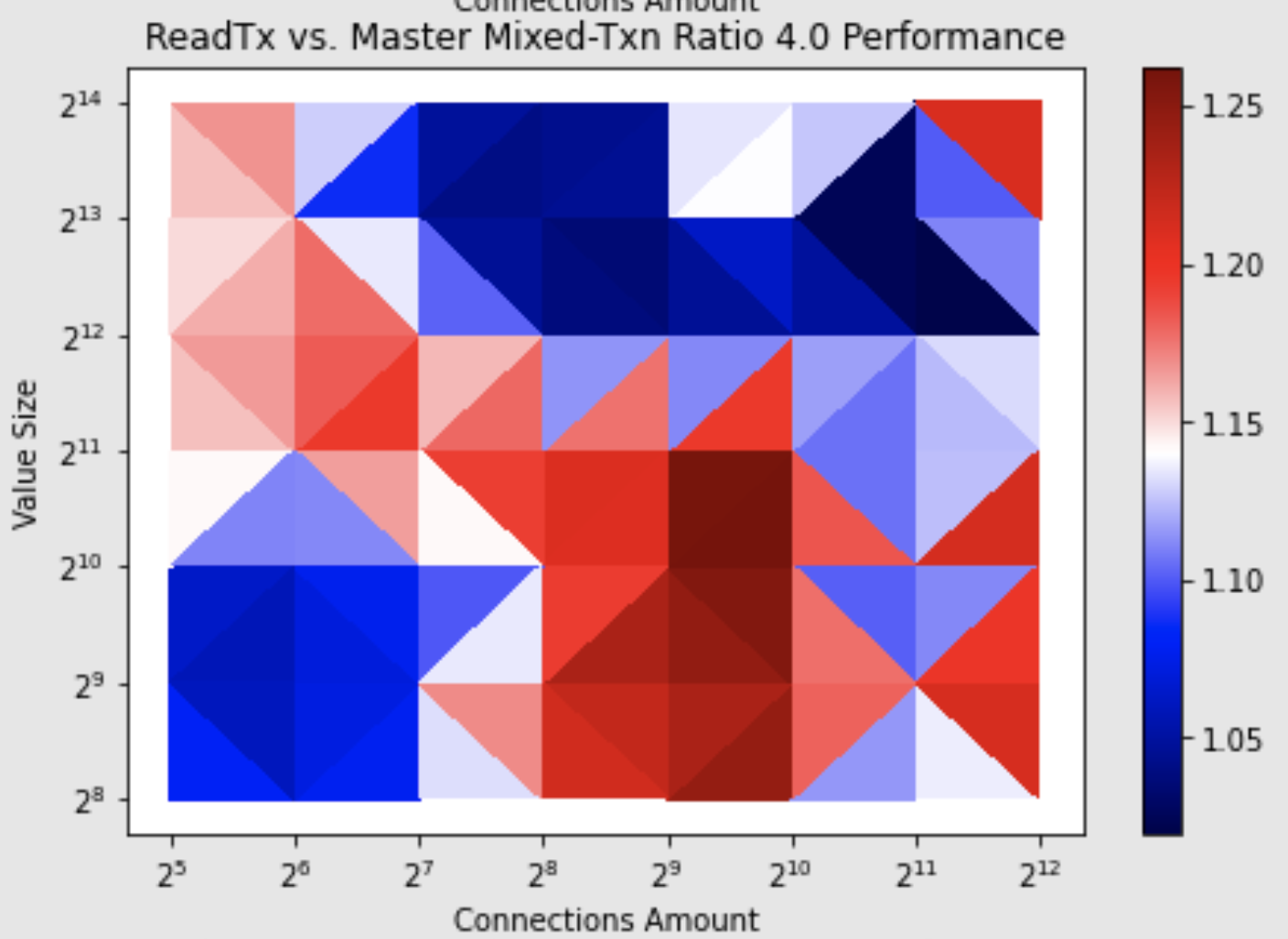
第二是针对 kubernetes 场景频繁使用的 Txn 的接口,支持在 Txn 接口中指定读事务类型(通过 experimental-txn-mode-write-with-shared-buffer 参数),详情如下:
- 针对只读工作负载,依然使用 concurrentReadTx,也就是创建读事务时,需拷贝写事务所维护的常驻 read buffer,给读事务使用。不过得益于上面第一点对 concurrentReadTx 的优化,多个读事务可共享一个 buffer,读请求非常多场景,将极大减少拷贝次数和开销。
- 当 txn 事务包含写操作时,针对 kubernetes 场景,默认使用 ReadTx 而不是 ConcurrentReadTx 以避免拷贝 buffer 的额外开销(默认 experimental-txn-mode-write-with-shared-buffer 为 true), ReadTx 也就是通过加读写锁,直接访问写事务的维护的常驻 read Buffer。
优化后的性能对比数据如下图读写热力图所示,横轴为连接数 /client,纵轴为 key-value 数,key-value 大小为256 个字节,在 K8s 场景下(读/写为4:1),有1倍左右的性能提升。
etcd 启动耗时的优化
介绍完 etcd 3.5 对读写性能优化的改进,我们在看看 etcd 启动耗时的优化。
之前在大数据量的压测场景下,我们发现 etcd 的启动耗时高达5分钟,随后通过对 etcd 的启动耗时进行深入分析,发现etcd为了获取 consistent index 校验快照文件对有效性,会进行两次重建 treeIndex 的操作。优化方案在重构consistent index 相关逻辑后,形成独立 conistent index(cindex) 模块,就可以非常简单地通过 cindex 模块,获取到 consistent index 值,进行快照校验工作,避免了多次重建 treeIndex 操作,详情可参考 pr #11779,pr #11699。
etcd 稳定性优化
最后是 etc d的稳定性优化。在 etcd 3.5 版本中,我们修复了 etcd 3.4 社区版本中 lease 模块存在的一个内存泄露 bug,这个 bug 在 K8s 场景中 event 较多时非常容易触发,并 cherry-pick 到了 etcd 3.4 版本中。同时,在大规模使用 etcd 集群过程中,我们多次遇到磁盘io抖动导致的死锁 bug,经过深入定位我们发现这个死锁 bug 的触发条件是落后的 follower 节点基于快照重建、并同时进行压缩操作时导致的。针对此 bug 的修复方案,也 cherry-pick 到了 etcd 3.4 模块中。针对这类磁盘io抖动导致的 etcd,我们基于 etcd 的 functional test 测试框架,增加了模拟磁盘 io 抖动的测试 case,便于更加及时发现此类磁盘 io 导致的 bug。
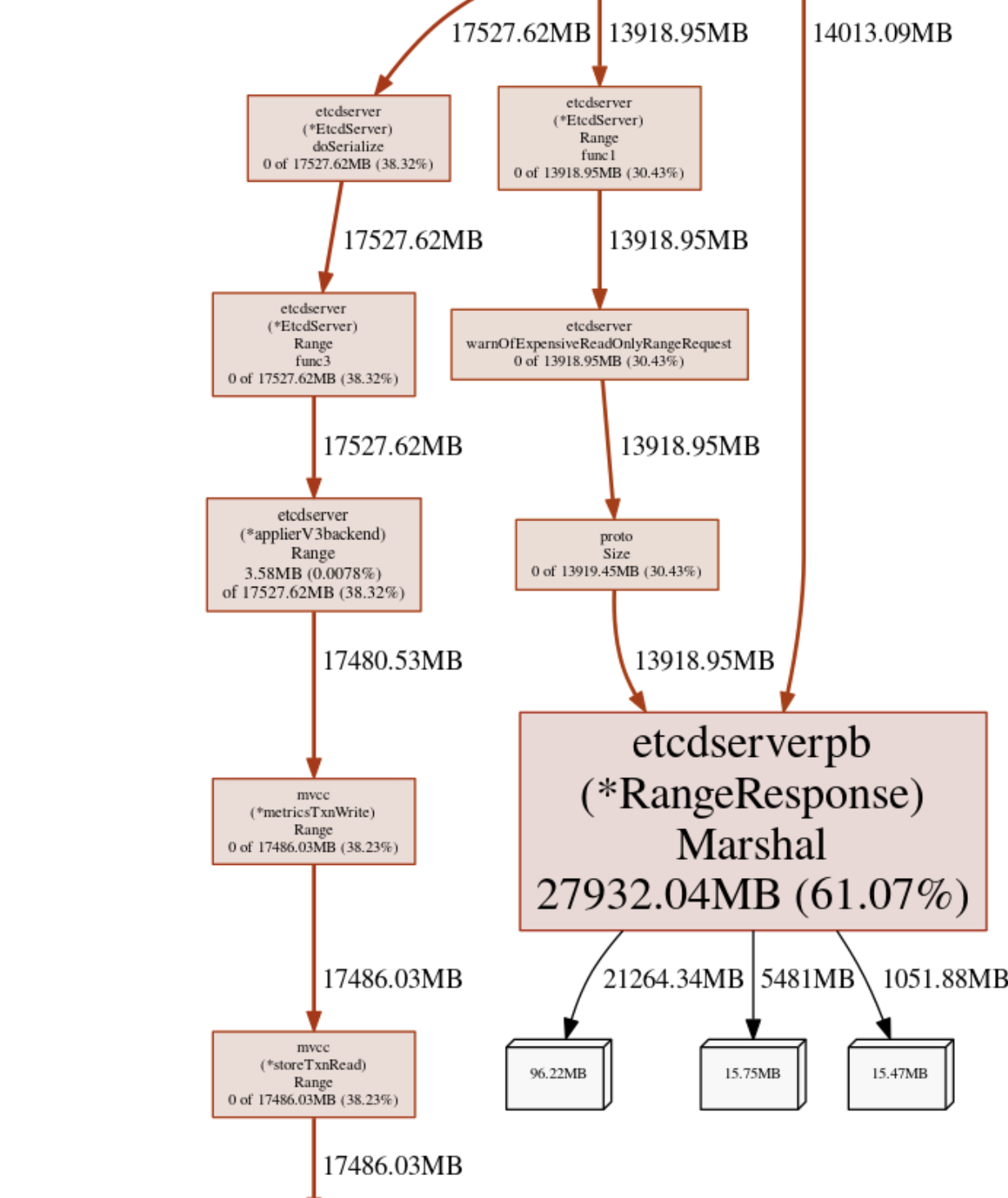
另外 etcd 社区还发现 kube-apiserver 在使用 etcd 的时候,内存出现异常增长,占据了 30% 的内存,通过 go pprof 工具分析发现是打印日志时 protobuf marshal 导致的,如下图所示。优化方案很简单,避免 protobuf marshal,使用 rangeResponse.Size()。

集群运维
最后则是关于 etcd 3.5 运维能力相关的介绍。
从前面我们介绍 etcd 模块化时提到过 etcdutl 工具,在etcd 3.5中,etcd 将一些直接操作 etcd 存储文件的管理命令单独独立成了 etcdutl 工具,它包括快照备份、快照重建、碎片整理功能。得益于 etcd 3.5 模块化的设计,你可以非常方便的通过如下的 go get go.etcd.io/etcd/etcdutl/v3 命令下载安装它。
% go get go.etcd.io/etcd/etcdutl/v3go get: upgraded go.etcd.io/etcd/etcdutl/v3 v3.5.0
其次是 etcd 3.5 废弃了 capnslog 日志,默认使用 zap logger, 并支持配置日志是否压缩、轮转、日志文件最大大小、保留副本数等,详细配置信息可参考下面点参数。
Logging: --logger 'zap' Currently only supports 'zap' for structured logging. --log-outputs 'default' Specify 'stdout' or 'stderr' to skip journald logging even when running under systemd, or list of comma separated output targets. --log-level 'info' Configures log level. Only supports debug, info, warn, error, panic, or fatal. --enable-log-rotation 'false' Enable log rotation of a single log-outputs file target. --log-rotation-config-json '{"maxsize": 100, "maxage": 0, "maxbackups": 0, "localtime": false, "compress": false}' Configures log rotation if enabled with a JSON logger config. MaxSize(MB), MaxAge(days,0=no limit), MaxBackups(0=no limit), LocalTime(use computers local time), Compress(gzip)".
同时,你可以通过 trace 日志特性高效的定位问题。另外我们针对鉴权耗时操作、expensive request 来源ip定位困难等问题,在 etcd gRPC 入口增加了 expensive request 日志,可打印任意 expensive request 和其来源 ip 等信息。 同时,针对在磁盘io性能较差、频繁备份等场景下,备份可能会影响业务正常读写的问题,在 etcd 3.5 中你可以通过 learner 实现备份能力。
接着,etcd 3.4 版本是使用 go 1.12 编译的,go runtime 的默认内存管理策略是 MADV_FREE, 它的性能较好,但是会导致你看到的etcd内存虚高,监控指标异常、用户体验不佳等问题,原因是这种策略,在系统内存有压力的时候,内核才会释放占用的内存。
从 go v1.16 起,Go 在 Linux 下的默认内存管理策略变成了 MADV_DONTNEED 策略。MADV_DONTNEED 虽然效率相比 MADV_FREE 策略较低,但是会让 rss 内存下降较快,更加符合直观感受,能避免 MADV_FREE 相关的副作用。
然后针对集群升级可能会触发bug,需要回滚的问题,之前 etcd 升级后不允许降级,在 etcd 3.5 中提供了集群降级的功能。比如你从 etcd 3.4 升级到 etcd 3.5 后,若遇到 crash bug 则可以通过集群降级功能回退到3.4。因 etcd 涉及到数据安全,建议先在测试环境升级进行验证,现网升级后若遇到问题,也不要急于回滚,先可看看是否属于配置问题等。目前降级功能实现上整体还并不完备,未通过大规模生产环境检验,建议谨慎操作。
最后安全性上,etcd 在 cncf 的赞助下,邀请第三方安全公司做了非常详细的安全审计报告,针对发现的若干潜在安全问题,进行了修复。
etcd 未来规划
针对 kubernetes 集群中 List Pod 等 expensive request 导致 etcd OOM 等不稳定现象,未来对 etcd 3.6 版本计划实现 etcd Range Stream 特性和 QoS 特性,其中 QoS 特性可参考我们之前提的 QoS Proposal。
参考资料
- https://github.com/etcd-io/etcd/blob/main/CHANGELOG-3.5.md
- https://etcd.io/blog/2021/announcing-etcd-3.5/
- https://github.com/etcd-io/etcd
容器服务 TKE:无需自建,即可在腾讯云上使用稳定, 安全,高效,灵活扩展的 Kubernetes 容器平台。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号