
揭秘有状态服务上 Kubernetes 的核心技术
背景
随着 Kubernetes 成为云原生的最热门的解决方案,越来越多的传统服务从虚拟机、物理机迁移到 Kubernetes,各云厂商如腾讯自研上云也主推业务通过Kubernetes来部署服务,享受 Kubernetes 带来的弹性扩缩容、高可用、自动化调度、多平台支持等益处。然而,目前大部分基于 Kubernetes 的部署的服务都是无状态的,为什么有状态服务容器化比无状态服务更难呢?它有哪些难点?各自的解决方案又是怎样的?
本文将结合我对 Kubernetes 理解、丰富的有状态服务开发、治理、容器化经验,为你浅析有状态容器化的疑难点以及相应的解决方案,希望通过本文,能帮助你理解有状态服务的容器化疑难点,并能基于自己的有状态服务场景能灵活选择解决方案,高效、稳定地将有状态服务容器化后跑在 Kubernetes 上,提高开发运维效率和产品竞争力。
有状态服务容器化挑战
为了简化问题,避免过度抽象,我将以常用的 Redis 集群为具体案例,详解如何将一个 Redis 集群进行容器化,并通过这个案例进一步分析、拓展有状态服务场景中的共性问题。
下图是 Redis 集群解决方案 codis 的整体架构图(引用自 Codis项目)。
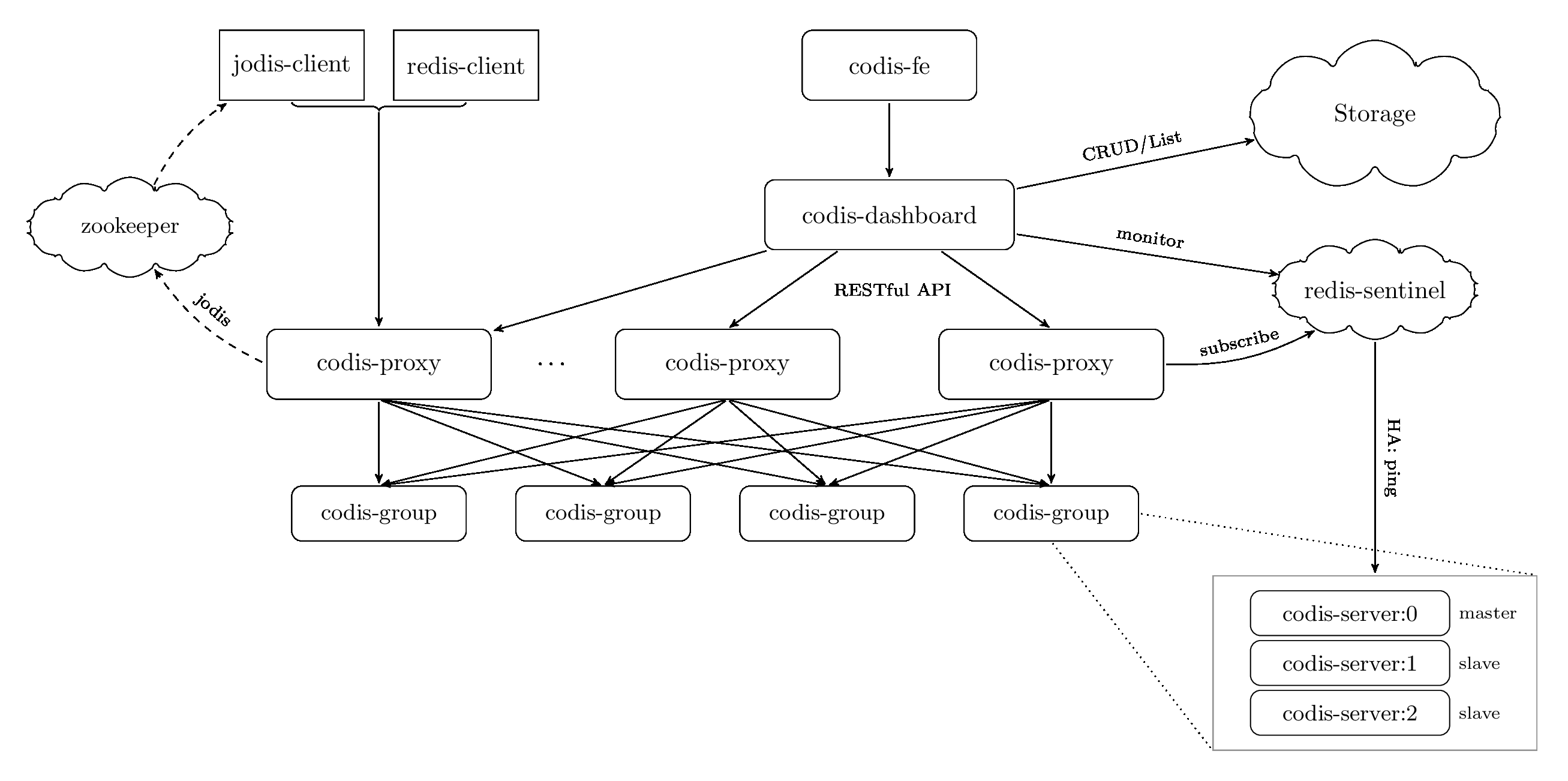
codis 是一个基于 proxy 的分布式 Redis 集群解决方案,它由以下核心组件组成:
- zookeeper/etcd, 有状态元数据存储,一般奇数个节点部署
- codis-proxy, 无状态组件,通过计算 key 的 crc16 哈希值,根据保存在 zookeeper/etcd 内的 preshard 路由表信息,将key转发到对应的后端 codis-group
- codis-group 由一组 Redis 主备节点组成,一主多备,负责数据的读写存储
- codis-dashboard 集群控制面API服务,可以通过它增删节点、迁移数据等
- redis-sentinel,集群高可用组件,负责探测、监听 Redis 主的存活,主故障时发起备切换
那么我们如何基于 Kubernetes 容器化 codis 集群,通过 kubectl 操作资源就能一键创建、高效管理 codis 集群呢?
在容器化类似 codis 这种有状态服务案例中,我们需要解决以下问题:
- 如何用 Kubernetes 的语言描述你的有状态服务?
- 如何为你的有状态服务选择合适的 workload 部署?
- 当 kubernetes 内置的 workload 无法直接描述业务场景时,又该选择什么样的 Kubernetes 扩展机制呢?
- 如何对有状态服务进行安全变更?
- 如何确保你的有状态服务主备实例 Pod 调度到不同故障域?
- 有状态服务实例故障如何自愈?
- 如何满足有状态服务的容器化后的高网络性能需求?
- 如何满足有状态服务的容器化后的高存储性能需求?
- 如何验证有状态服务容器化后的稳定性?
下方是我用思维导图系统性的梳理了容器化有状态的服务的技术难点,接下来我分别从以上几个方面为你阐述容器化的解决方案。
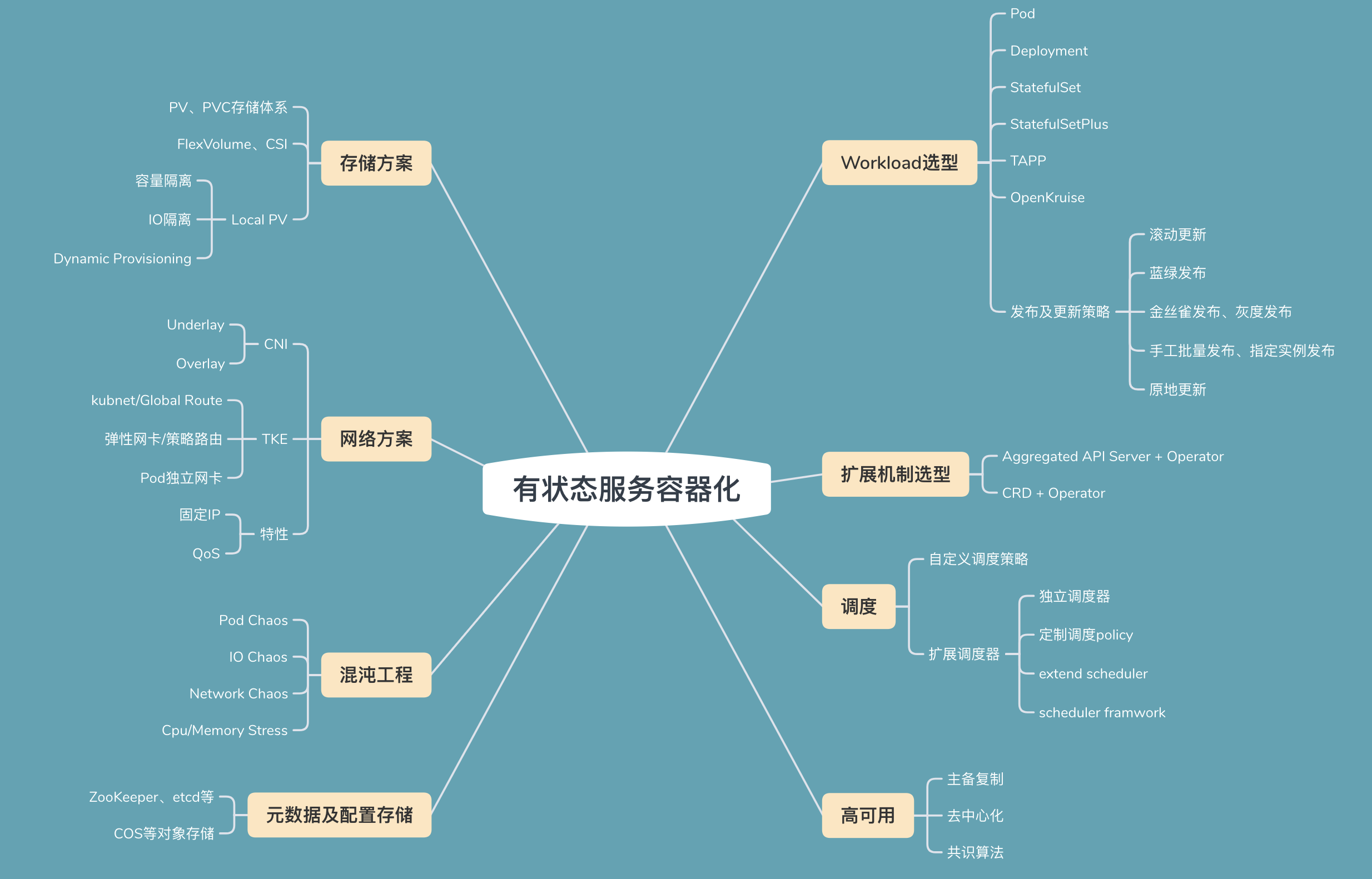
负载类型
有状态服务的容器化首要问题是如何用 Kubernetes 式的 API、语言来描述你的有状态服务?
Kubernetes 为复杂软件世界中的各类业务场景抽象、内置了 Pod、Deployment、StatefulSet 等负载类型(Workload), 那么各个 Workload 的使用场景分别是什么呢?
Pod,它是最小的调度、部署单位,由一组容器组成,它们共享网络、数据卷等资源。为什么 Pod 设计上它是一组容器组成而不是一个呢? 因为在实际复杂业务场景中,往往一个业务容器无法独立完成某些复杂功能,比如你希望使用一个辅助容器帮助你下载冷备快照文件、做日志转发等,得益于 Pod 的优秀设计,辅助容器可以和你的 Redis、MySQL、etcd、zookeeper 等有状态容器共享同个网络命名空间、数据卷,帮助主业务容器完成以上工作。这种辅助容器在 Kubernetes 里面叫做 sidecar, 广泛应用于日志、转发、service mesh 等辅助场景,已成为一种 Kubernetes 设计模式。Pod 优秀设计来源于 Google 内部 Borg 十多年运行经验的总结和升华,可显著地降低你将复杂的业务容器化的成本。
通过 Pod 成功将业务进程容器化了,然而 Pod 本身并不具备高可用、自动扩缩容、滚动更新等特性,因此为了解决以上挑战,Kubernetes 提供了更高级的 Workload Deployment, 通过它你可以实现Pod故障自愈、滚动更新、并结合 HPA 组件可实现按 CPU、内存或自定义指标实现自动扩缩容等高级特性,它一般是用来描述无状态服务场景的,因此特别适合我们上面讨论的有状态集群中的无状态组件,比如 codis 集群的 proxy 组件等。
那么 Deployment 为什么不适合有状态呢?主要原因是 Deployment 生成的 Pod 名称是变化、无稳定的网络标识身份、无稳定的持久化存储、滚动更新中过程中也无法控制顺序,而这些对于有状态而言,是非常重要的。一方面有状态服务彼此通过稳定的网络身份标识进行通信是其高可用、数据可靠性的基本要求,如在 etcd 中,一个日志提交必须要经过集群半数以上节点确认并持久化,在 Redis 中,主备根据稳定的网络身份建立主从同步关系。另一方面,不管是 etcd 还是 Redis 等其他组件,Pod 异常重建后,业务往往希望它对应的持久化数据不能丢失。
为了解决以上有状态服务场景的痛点,Kubernetes 又设计实现了 StatefulSet 来描述此类场景,它可以为每个 Pod 提供唯一的名称、固定的网络身份标识、持久化数据存储、有序的滚动更新发布机制。基于 StatefulSet 你可以比较方便的将 etcd、zookeeper 等组件较单一的有状态服务进行容器化部署。
通过 Deployment、StatefulSet 我们能将大部分现实业务场景的服务进行快速容器化,但是业务诉求是多样化的,各自的技术栈、业务场景也是迥异的,有的希望实现 Pod 固定IP的,方便快速对接传统的负载均衡,有的希望实现发布过程中,Pod不重建、支持原地更新的,有的希望能指定任意 Statefulset Pod 更新的,那么 Kubernetes 如何满足多样化的诉求呢?
扩展机制
Kubernetes 设计上对外提供了一个强大扩展体系,如下图所示(引用自 kubernetes blog),从 kubectl plugin 到 Aggreated API Server、再到 CRD、自定义调度器、再到 operator、网络插件(CNI)、存储插件(CSI)。一切皆可扩展,充分赋能业务,让各个业务可基于Kubernetes扩展机制进行定制化开发,满足大家的特定场景诉求。
CRD 和 Aggreated API Server
当你遇到 Deployment、StatefulSet 无法满足你诉求的时候,Kubernetes 提供了 CRD 和 Aggreated API Server、Operator 等机制给你扩展 API 资源、结合你特定的领域和应用知识,实现自动化的资源管理和运维任务。
CRD 即 CustomResourceDefinition,是 Kubernetes 内置的一种资源扩展方式,在 apiserver 内部集成了 kube-apiextension-server, 不需要在 Kubernetes 集群运行额外的 Apiserver,负责实现 Kubernetes API CRUD、Watch 等常规API操作,支持 kubectl、认证、授权、审计,但是不支持 SubResource log/exec 等定制,不支持自定义存储,存储在 Kubernetes 集群本身的 etcd 上,如果涉及大量 CRD 资源需要存储则对 Kubernetes 集群etcd 性能有一定的影响,同时限制了服务从不同集群间迁移的能力。
Aggreated API Server,即聚合 ApiServer, 像我们常用的 metrics-server 属于此类,通过此特性 Kubernetes 将巨大的单 apiserver 按资源类别拆分成多个聚合 apiserver, 扩展性进一步加强,新增API无需依赖修改 Kubernetes 代码,开发人员自己编写 ApiServer 部署在 Kubernetes 集群中, 并通过 apiservice 资源将自定义资源的 group name 和 apiserver 的 service name 等信息注册到 Kubernetes 集群上,当 Kubernetes ApiServer 收到自定义资源请求时,根据 apiservice 资源信息转发到自定义的 apiserver, 支持 kubectl、支持配置鉴权、授权、审计,支持自定义第三方 etcd 存储,支持 subResource log/exec 等其他高级特性定制化开发。
总体来说,CRD提供了简单、无需任何编程的扩展资源创建、存储能力,而 Aggreated API Server 提供了一种机制,让你能对 API 行为有更精细化的控制能力,允许你自定义存储、使用 Protobuf 协议等。
增强型 Workload
为了满足业务上述的原地更新、指定Pod更新等高级特性需求,腾讯内部及社区都提供了相应的解决方案。腾讯内部有经过大规模生产环境检验的 StatefulSetPlus(未开源的)和 tkestack TAPP(已开源),社区也还有有阿里的开源项目 Openkruise,pingcap 为了解决 StatefulSet 指定 Pod 更新问题也推出了一个目前还处于试验状态的 advanced-statefulset 项目。
StatefulSetPlus 是为了满足腾讯内部大量传统业务上 Kubernetes 而设计的, 它在兼容 StatefulSet 全部特性的基础上,支持容器原地升级,对接了 TKE 的 ipamd 组件,实现了固定IP,支持 HPA,支持 Node 不可用时,Pod 自动漂移实现自愈,支持手动分批升级等特性。
Openkruise 包含一系列 Kubernetes 增强型的控制器组件,包括 CloneSet、Advanced StatefulSet、SideCarSet等,CloneSet 是个专注解决无状态服务痛点的 Workload,支持原地更新、指定 Pod 删除、滚动更新过程中支持Partition, Advanced StatefulSet 顾名思义,是个加强版的 StatefulSet, 同时支持原地更新、暂停和最大不可用数。
使用增强版的 workload 组件后,你的有状态服务就具备了传统虚拟机、物理机部署模式下的原地更新、固定IP等优越特性。不过,此时你是直接基于 StatefulSetPlus、TAPP 等 workload 容器化你的服务还是基于 Kubernetes 扩展机制定义一个自定义资源, 专门用于描述你的有状态服务各个组件,并基于 StatefulSetPlus、TAPP 等workload 编写自定义的 operator 呢?
前者适合于简单有状态服务场景,它们组件少、管理方便,同时不需要你懂任何 Kubernetes 编程知识,无需开发。后者适用于较复杂场景,要求你懂 Kubernetes 编程模式,知道如何自定义扩展资源、编写控制器。 你可以结合你的有状态服务领域知识,基于 StatefulSetPlus、TAPP 等增强型 workload 编写一个非常强大的控制器,帮助你一键完成一个复杂的、多组件的有状态服务创建和管理工作,并具备高可用、自动扩缩容等特性。
基于 operator 扩展
在我们上文的 codis 集群案例中,就可以选择通过 Kubernetes 的 CRD 扩展机制,自定义一个 CRD 资源来描述一个完整的 codis 集群,如下图所示。

通过 CRD 实现声明式描述完你的有状态业务对象后,我们还需要通过 Kubernetes 提供的 operator 机制来实现你的业务逻辑。Kubernetes operator 它的核心原理就是控制器思想,从 API Server 获取、监听业务对象的期望状态、实际状态,对比期望状态与实际状态的差异,执行一致性调谐操作,使实际状态符合期望状态。
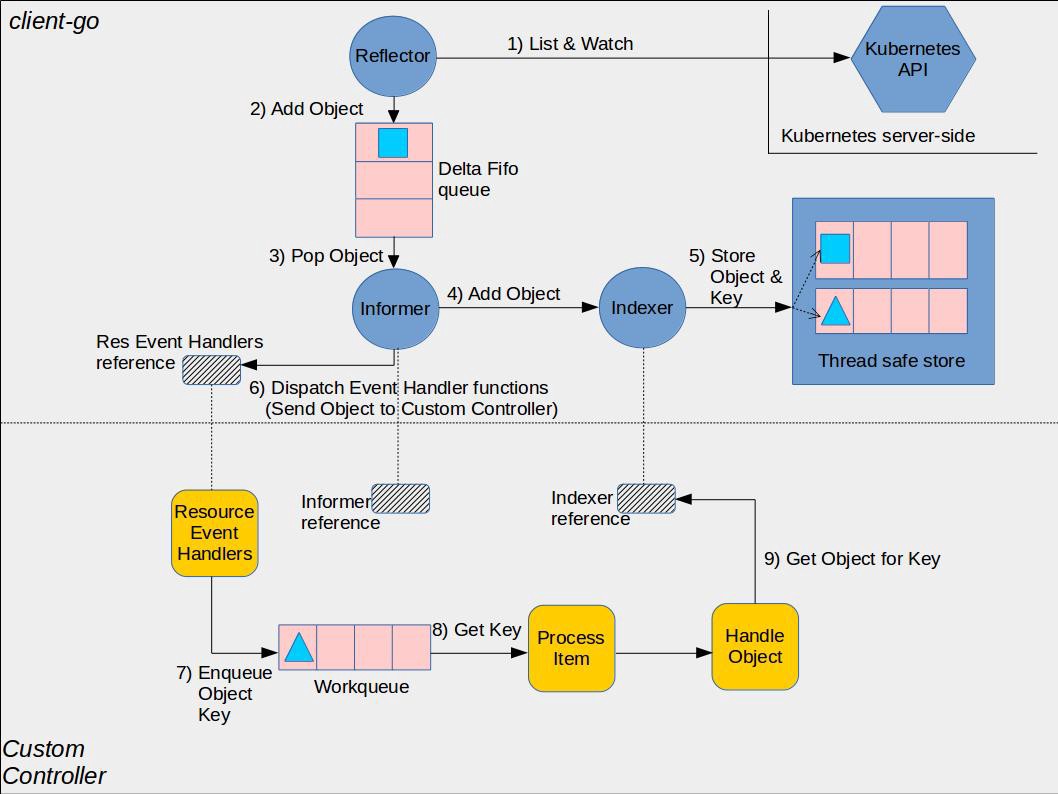
它的核心工作原理如上图(引用自社区)所示。
- 通过 Reflector 组件的 List 操作,从 kube-apiserver 获取初始状态数据(CRD等)。
- 从 List 请求返回结构中获取资源的 ResourceVersion,通过 Watch 机制指定 ResourceVersion 实时监听 List之后的数据变化。
- 收到事件后添加到 Delta FIFO 队列,由 Informer 组件进行处理。
- Informer 将 delta FIFO 队列中的事件转发给 Indexer 组件,Indexer 组件将事件持久化存储在本地的缓存中。
- operator开发者可通过 Informer 组件注册 Add、Update、Delete 事件的回调函数。Informer 组件收到事件后会回调业务函数,比如典型的控制器使用场景,一般是将各个事件添加到 WorkQueue 中,operator 的各个协调 goroutine 从队列取出消息,解析 key,通过 key 从 Informer 机制维护的本地 Cache 中读取数据。
- 比如当收到创建一个 Codis CRD 对象的事件后,发现实际无这个对象相关的 Deployment/TAPP 等组件在运行,这时候你就可以通过的 Deployment API 创建 proxy 服务,TAPP API创建Redis服务等。
调度
在解决完如何基于 Kubernetes 内置的 workload 和其扩展机制描述、承载你的有状态服务后,你面临的第二个问题就是如何确保有状态服务中“等价”Pod跨故障域部署,确保有状态服务的高可用性?
首先如何理解“等价” Pod 呢? 在 codis、TDSQL 集群中,一组 Redis/MySQL 主备实例,负责处理同一个数据分片的请求,通过主备实现高可用。因主备实例 Pod 负责的是同数据分片,因此我们称之为等价 Pod,生产环境期望它们应跨故障域部署。
其次如何理解故障域?故障域表示潜在的故障影响范围,可按范围分为主机级、机架级、交换机级、可用区级等。一组 Redis 主备案例,至少应该实现主机级高可用,任意一个分片所在的主实例所在的节点故障,备实例应自动提升为主,整个 Redis 集群所有分片仍可提供服务。同样,在 TDSQL 集群中,一组 MySQL 实例,至少应该实现交换机、可用区级别容灾,以确保核心的存储服务高可用。
那么如何实现上面所述等价 Pod 跨故障域部署呢?
答案是调度。 Kubernetes 内置的调度器可根据你的Pod所需资源和调度策略,自动化的将 Pod 分配到最佳节点,同时它还提供了强大的调度扩展机制,让你轻松实现自定义调度策略。一般情况下,在简单的有状态服务场景下,你可以基于 Kubernetes 提供的亲和和反亲和高级调度策略,实现 Pod 跨故障域部署。
假设希望通过容器化、高可用部署一个含三节点的 etcd 集群,故障域为可用区,每个etcd节点要求分布在不同可用区节点上,我们如何基于 Kubernetes 提供的亲和 (affinity) 和反亲和 (anti affinity) 特性实现跨可用区部署呢?
亲和与反亲和
很简单,我们可以通过给部署 etcd 的 workload 添加如下的反亲和性配置,声明目的 etcd 集群 Pod 的标签,拓扑域为 node 可用区,同时是硬亲和规则,若 Pod不 满足规则将无法调度。
那么调度器又遇到被添加了反亲和配置的 Pod 后是如何调度的呢?
affinity:
PodAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: etcd_cluster
operator: In
values: ["etcd-test"]
topologyKey: failure-domain.beta.Kubernetes.io/zone
首先调度器监听到 etcd workload 生成的的待调度 Pod 后,通过反亲和配置中的标签查询出已调度 Pod 的节点、可用区信息,然后在调度器的筛选阶段,若候选节点可用区与已调度 Pod 可用区一致,则淘汰,最后进入评优阶段的节点都是满足 Pod 跨可用区部署等条件限制的节点,根据调度器配置的评优策略,选择出一个最优节点,将 Pod 绑定到此节点上,最终实现 Pod 跨可用区部署、容灾。
然而在 codis 集群、TDSQL 分布式集群等复杂场景中,Kubernetes 自带的调度器可能就无法满足你的诉求了,但是它提供了如下的扩展机制帮助你自定义调度策略,实现各种复杂场景的调度诉求。
自定义调度策略、extend scheduler 等
首先你可以修改调度器的筛选/断言 (predicates) 和评分/优先级 (priorities) 策略, 配置满足你业务诉求的调度策略。比如你希望降低成本,用最小的节点数支撑集群所有服务,那么我们需要让 Pod 尽量优先往满足其资源诉求、已分配资源较多的节点上调度。 此场景,你就可以通过修改 priorities 策略,配置 MostRequestedPriority 策略,调大权重。
然后你可以基于 Kubernetes 调度器实现 extend scheduler, 在调度器的 predicates 和 priorities 阶段,回调你的扩展调度服务,已满足你的调度诉求。比如你希望负责同一个数据分片的一组 MySQL 或 Redis 主备实例实现跨节点容灾,那么你就可以实现自己的predicates 函数,将同组已调度 Pod 的节点从候选节点中删除,保证进入 priorities 流程的节点都是满足你业务诉求的。
接着你可以基于 Kubernetes 的调度器实现自己独立的调度器,部署独立的调度器到集群后,你只需要通过将 Pod的 schedulerName 声明为你独立的调度器即可。
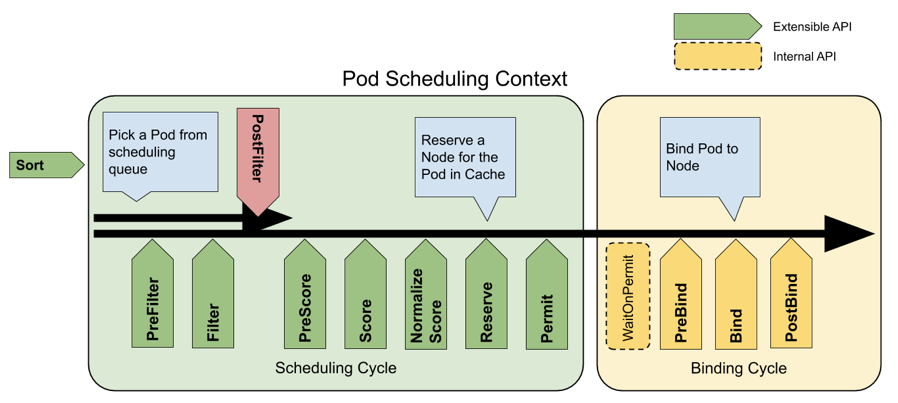
scheduler framwork
最后 Kubernetes 在1.15版本中推出了一个新的调度器扩展框架,它在调度器的核心流程前后都增加了 hook。选择待调度 Pod,支持自定义排队算法,筛选流程提供了 PreFilter 和 Filter 接口,评分流程增加了 PreScore,Score,NormalizeScore 等接口,绑定流程提供 PreBind 和 Bind,PostBind 三个接口。基于新的调度器扩展框架,业务可更加精细化、低成本的控制调度策略,自定义调度策略更加简单、高效。
高可用
解决完调度问题后,我们的有状态服务已经可以高可用的部署了。然而高可用部署不代表服务能高可用的对外的提供服务,容器化后我们也许会遇到比传统物理机、虚拟机模式部署更多的稳定性挑战。稳定性挑战可能来自业务编写的 operator、Kubernetes 组件、docker/containerd 等运行时组件、linux 内核等,那如何应对以上各种因素导致的稳定性问题呢?
我们在设计上应把 Pod 异常当作常态化案例处理,任一 Pod 异常后,在容器化场景中,我们应当具备自愈的机制。若是无状态服务,我们只需为业务Pod添加合理的存活和就绪检查即可,Pod 异常后自动重建,节点故障 Pod 自动漂移到其他节点。然而在有状态服务场景中,即便承载你有状态服务的 workload,支持节点故障后 Pod 自动漂移功能,却也可能会因 Pod 自愈时间过长和数据安全性等无法满足业务诉求,为什么呢?
假设在 codis 集群中,一个 Redis 主节点所在node突然”失联“了,此时若等待5分钟才进入自愈流程,那么对外将造成5分钟的不可用性, 显然对重要的有状态服务场景是无法接受的。即便你缩小节点失联自愈时间,你也无法保证其数据安全性,万一此时集群网络出现了脑裂,失联节点也在对外提供服务,那么将出现多个 master 双写,最终可能导致数据丢失。
那么有状态的服务安全的高可用解决方案是什么呢? 这取决于有状态服务本身高可用实现机制,Kubernetes 容器平台层是无法提供安全的解决方案。常用的有状态服务高可用解决方案有主备复制、去中心化复制、raft/paxos 等共识算法,下面我分别简易阐述三者的区别和优劣势,以及介绍在容器化过程中的注意事项。
主备复制
像我们上面讨论的 codis 集群案例、TDSQL 集群案例都是基于主备复制实现的高可用,实现上相比去中心化复制、共识算法较简单。主备复制又可分为主备全同步复制、异步复制、半同步复制。
全同步复制是指主收到一个写请求后,必须等待全部从节点确认返回后,才能返回给客户端成功,因此若一个从节点故障,整个系统就会不可用,这种方案为了保证多副本集的一致性,而牺牲了可用性,一般使用不多。
异步复制是指主收到一个写请求后,可及时返回给 client,异步将请求转发给各个副本, 但是若还未将请求转发到副本前就故障了,则可能导致数据丢失,但可用性是最高的。
半同步复制介于全同步复制、异步复制之间,它是指主收到一个写请求后,至少有一个副本接收数据后,就可以返回给客户端成功,在数据一致性、可用性上实现了平衡和取舍。
基于主备复制模式实现的有状态服务,业务需要实现、部署主备切换的 HA 服务,HA服务按实现架构,可分为主动上报型和分布式探测型。主动上报型以 TDSQL 中 MySQL 主备切换为例,各个 MySQL 节点上部署有 agent, 向元数据存储集群 (zookeeper/etcd) 上报心跳,若 master 心跳丢失, HA 服务将快速发起主备切换。分布式探测型以 Redis sentinel 为例,部署奇数个哨兵节点,各个哨兵节点定时探测Redis主备实例的可用性,彼此之间通过 gossip 协议交互探测结果,若对一个主 Redis 节点故障达到多数派认可,那么就由其中一个哨兵发起主备切换流程。
总体来说,基于主备复制的有状态服务,在传统的部署模式,节点故障后,依赖运维、人工替换节点。容器化后的有状态服务,可通过 operator 实现故障节点自动替换、快速垂直扩容等特性,显著降低运维复杂度,但是 Pod 可能会发生重建等,应部署负责主备切换的HA服务,负责主备 Pod 的切换,以提高可用性。若业务对数据一致性非常敏感,较频繁的切换的可能会导致增大丢失数据的概率,可通过使用 dedicated 节点、稳定及较新的运行时和Kubernetes 版本等减少不稳定因素。
去中心化复制
跟主从复制相反的就是去中心化复制,它是指在一个n副本节点集群中,任意节点都可接受写请求,但一个成功的写入需要w个节点确认,读取也必须查询至少r个节点。你可以根据实际业务场景对数据一致性的敏感度,设置合适w/r参数。比如你希望每次写入后,任意client都能读取到新值,若n是3个副本,你可以将w和r设置为2,这样当你读两个节点时候,必有一个节点含有最近写入的新值,这种读我们称之为法定票数读 (quorum read)。
AWS 的 dynamo 系统就是基于无中心化的复制算法实现的,它的优点是节点角色都是平等的,降低运维复杂度,可用性更高,容器化难度更低,无需部署HA组件等,但缺陷是去中心化复制,务必会导致各种写入冲突,业务需要关注冲突处理等。
共识算法
基于复制算法实现的数据库,为了保证服务可用性,大多数提供的是最终一致性,不管是主从复制还是去中心化复制,都存在一定的缺陷,无法满足数据强一致、高可用的诉求。
如何解决以上复制算法的困境呢?
答案就是 raft/paxos 共识算法,它最早是基于复制状态机背景下提出来的,由共识模块、日志模块、状态机组成, 如下图(引用自 Raft 论文)。通过共识模块保证各个节点日志的一致性,然后各个节点基于同样的日志、顺序执行指令,最终各个复制状态机的结果是一致性的。这里我以 raft 算法为例,它由 leader 选举、日志复制、安全性组成,leader 节点故障后,follower 节点可快速发起新的 leader 选举,并确保数据安全性,follwer 节点故障后,只要多数节点存活,就不影响集群整体可用性。
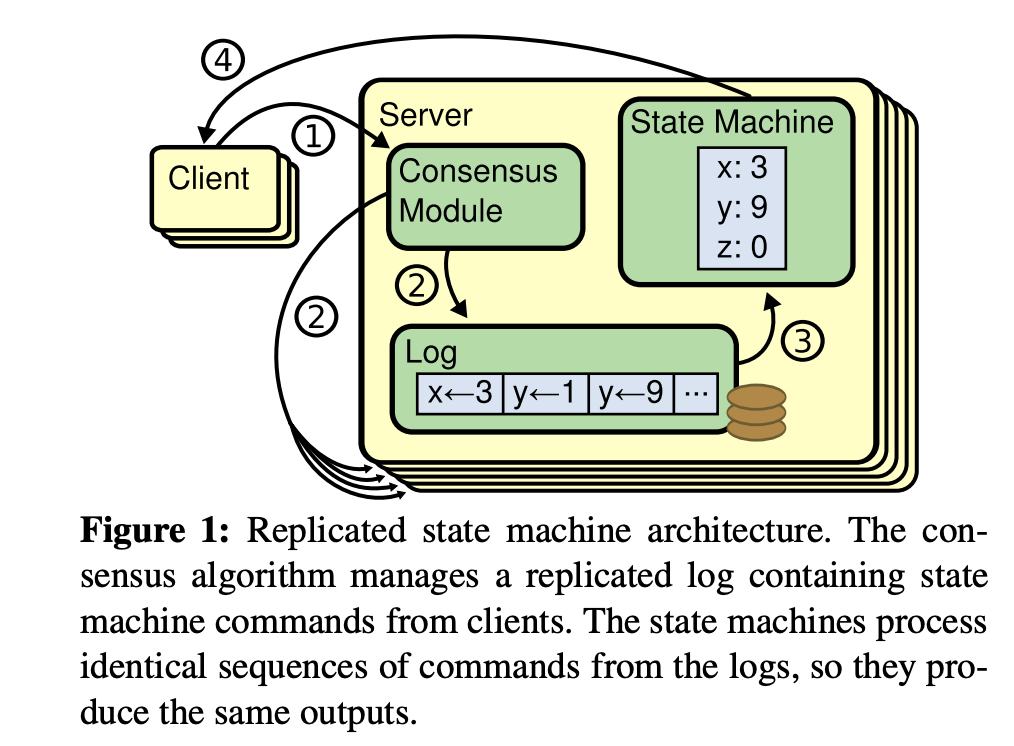
基于共识算法实现的有状态服务,典型案例是 etcd/zookeeper/tikv 等,在此架构中,服务本身集成了 leader 选举算法、数据同步机制,使得运维和容器化复杂度相比主备复制的服务要显著降低,容器化更加安全。即便容器化过程中遇上 Bug 导致 leader 节点故障,得益于共识算法,数据安全和服务可用性几乎不受任何影响,因此优先推荐将使用共识算法的有状态服务进行容器化。
高性能
实现完有状态服务在 Kubernetes 中更稳的运行的目标后,下一步目标则是追求高性能、更快,而有状态服务的高能又依托底层容器化网络方案、磁盘 IO 方案。在传统的物理机、虚拟机部署模式中,有状态服务拥有固定的IP、高性能的 underlay 网络、高性能的本地 SSD 磁盘,那么在容器化后,如何达到传统模式的性能呢? 我将分别从网络和存储分别简易阐述 Kubernetes 的解决方案。
可扩展的网络解决方案
首先是可扩展、插件化的网络解决方案。得益于 Google 多年的 Borg 容器化运行经验和教训,在 Kubernetes 的网络模型中,每个 Pod 拥有独立的IP,各个 Pod 可以跨主机通信而需NAT, 同时 Pod 也可以与 Node 节点实现网络互通。Kubernetes 优秀的网络模型良好的兼容了传统的物理机、虚拟机业务的网络方案,让传统业务上Kubernetes 更加简单。最重要的是,Kubernetes 提供了开放的 CNI 网络插件标准,它描述了如何为 Pod 分配 IP和实现 Pod 跨节点容器互通,各个开源、云厂商可以基于自己业务业务场景、底层网络,实现高性能、低延迟的CNI插件,最终达到跨节点容器互通。
在基于 CNI 实现的各种 Kubernetes 的网络解决方案中,按数据包的收发模式实现可分为 underlay 和 overlay 两类。前者是直接基于底层网络,实现互联互通,拥有良好的性能,后者是基于隧道转发,它是在底层网络的基础上,加上隧道技术,构建一个虚拟的网络,因此存在一定的性能损失。
这里我分别以开源的 flannel 和 tke 集群网络方案为例,阐述各自的解决方案、优缺点。
在 flannel 中,它设计上后端支持 udp、vxlan、host-gw 等多种转发模式。udp 和 vxlan 转发模式是基于 overlay隧道转发模式实现,它支持将原始请求封装在 udp、vxlan 数据包内,然后基于 underlay 网络转发给目的容器。udp 是在用户态进行数据的封解包操作,性能较差,一般用于debug和不支持 vxlan 协议的低版本内核。vxlan 是在内核态完成了数据的封解包操作,性能损失较小。host-gw 模式则是直接通过下发每个子网的IP路由信息到各个节点上,实现跨主机的 Pod 网络通信,无需数据包的封解包操作,相比 udp/vxlan,性能最佳,但要求各主机节点的二层网络是连通的。
在tke集群网络方案中,我们也支持多种网络通信方案,经历了从 global route、VPC-CNI 到 Pod 独立网卡的三种模式的演进。global route 即全局路由,每个节点加入集群时,会分配一个唯一的 Pod cidr, tke 会通过 VPC 的接口下发全局路由到用户 VPC 的子机所在的母机上。当用户 VPC 的容器、节点访问的ip属于此 Pod cir 时,就会匹配到此全局路由规则,转发到目标节点上。此方案中 Pod CIDR 并不属于VPC资源,因此它不是 VPC 的一等公民,无法使用 VPC 的安全组等特性,但是其简单、同时在用户VPC层不需要任何的数据解封包操作,性能无较大的损失。
为了解决容器 Pod IP 不是 VPC 一等公民而导致一系列 VPC 特性无法使用的问题,tke 集群实现了 VPC-CNI 网络模式,Pod IP 来自用户 VPC 的子网,跨节点容器网络通信、节点与容器通信与 VPC 内的 CVM 节点通信原理一致,底层都是基于 VPC 的 GRE 隧道路由转发实现,数据包在节点内通过策略路由转发到目标容器。基于此方案,容器 Pod IP 可享受 VPC 的特性,实现CLB直连Pod,固定IP等一系列高级特性。
近期为了满足游戏、存储等业务对容器网络性能更加极致的要求,TKE 团队又推出了下一代网络方案,Pod 独占弹性网卡的 VPC-CNI 模式,不再经过节点的网络协议栈,极大缩短容器访问链路和延时,并使 PPS 可以达到整机上限。基于此方案我们实现了 Pod 绑定 EIP/NAT,不再依赖节点的外网访问能力,支持 Pod 绑定安全组,实现Pod级别的安全隔离,详细可阅读文章末尾的相关文章。
基于 Kubernetes 的可扩展网络模型,业务可以实现特定场景的高性能网络插件。比如腾讯内部的 tenc 平台,基于 SR-IOV 技术的实现了 sriov-cni CNI 插件,它可以给 Kubernetes 提供高性能的二层VLAN网络解决方案。特别是对网络性能要求高的场景,比如分布式机器学习训练,游戏后端服务等。
可扩展的存储解决方案
介绍完可扩展的网络解决方案后,有状态服务的另一大核心瓶颈则是高性能存储IO诉求。 在传统的部署模式中,有状态服务一般使用的是本地硬盘,并根据服务的类型、规格、对外的 SLA,选择 HDD、SSD 等不同类型的磁盘。 那么在 Kubernetes 中如何满足不同场景下的存储诉求呢?
在 Kubernetes 存储体系中,此问题被拆分成若干个子问题来优雅解决,并具备良好的可扩展性、可维护性,无论是本地盘、还是云盘、NFS等文件系统都可基于其扩展实现相应的插件, 并实现了开发、运维职责分离。
那么 Kubernetes 的存储体系是如何构建的呢?
我通过如何给你的有状态Pod应用挂载一个数据存储盘为案例,来介绍 Kubernetes 的可扩展存储体系,它可以分为以下步骤:
-
应用如何申请一个存储盘呢?(消费者)
-
Kubernetes 存储体系是如何描述一个存储盘的呢?人工创建存储盘呢还是自动化按需创建存储盘?(生产者)
-
如何将存储资源池的盘与存储盘申请者的诉求进行匹配?(控制器)
-
如何描述存储盘的类型、数据删除策略、以及此类型盘的服务提供者信息呢?(storageClass)
-
如何实现对应的存储数据卷插件?(FlexVolume、CSI)
首先 Kubernetes 中提供了一个名为PVC的资源,描述应用申请的存储盘的类型、访问模式、容量规格,比如你想给etcd服务申请一个存储类为cbs, 大小100G的云盘,你可以创建一个如下的PVC。
apiVersion: v1
kind: PersistentVolumeClaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: cbs
其次 Kubernetes 中提供了一个名为 PV 的资源,描述存储盘的类型、访问模式、容量规格,它对应一块真实的磁盘,支持通过人工和自动创建两种模式。下图描述的是一个 100G 的 cbs 硬盘。
apiVersion: v1
kind: PersistentVolume
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 100Gi
persistentVolumeReclaimPolicy: Delete
qcloudCbs:
cbsDiskId: disk-r1z73a3x
storageClassName: cbs
volumeMode: Filesystem
接着,当应用创建一个 PVC 资源时,Kubernetes 的控制器就会尝试将其与PV进行匹配,存储盘的类型是否一致、PV的容量大小是否满足 PVC 的诉求,若匹配成功,此 PV 的状态会变成绑定, 控制器会进一步的将此PV对应的存储资源attach到应用 Pod 所在节点上,attach 成功后,节点上的 kubelet 组件会将对应的数据目录挂载到存储盘上,进而实现读写。
以上就是应用申请一个盘的流程,那么在容器中如何通过 PV/PVC 这套体系实现支持多种类型的块存储和网络文件系统呢?比如块存储服务支持普通 HHD 云盘,SSD 高性能云盘,SSD 云盘,本地盘等,远程网络文件系统支持NFS等。其次是Kubernetes控制器如何按需动态的去创建PV呢?
为了支持多种类型的存储诉求,Kubernetes 提供了一个 StorageClass 的资源来描述一个存储类。它描述了存储盘的类别、绑定和删除策略、由什么服务组件提供资源创建。比如高性能版和基础版的 MySQL 服务依赖不同类型的存储磁盘,你只需要创建 PVC 的时候填写相应的 storageclass 名字即可。
最后,Kubernetes 为了支持开源社区、云厂商众多的存储数据卷,提供了存储数据卷扩展机制,从早期的 in-tree 的内置数据卷、到 FlexVolume 插件、再到现在已经 GA 的的容器化存储 CSI 插件机制, 存储服务提供商可将任意的存储系统集成到Kubernetes存储体系中。比如 storage cbs 的 provisioner 是腾讯云的 TKE 团队,我们会基于 Kubernetes 的 flexvolume/CSI 扩展机制,通过腾讯云 CBS 的 API 实现创建、删除cbs硬盘。
apiVersion: storage.Kubernetes.io/v1
kind: StorageClass
parameters:
type: cbs
provisioner: cloud.tencent.com/qcloud-cbs
reclaimPolicy: Delete
volumeBindingMode: Immediate
为了满足有状态等服务对磁盘IO性能的极致追求,Kubernetes 基于以上介绍的 PV/PVC 存储体系,实现了 local pv 机制,它可避免网络 IO 开销,让你的服务拥有更高的IO读写性能。local pv 核心是通过将本地盘、lvm 分区抽象成 PV,使用 local pv 的 Pod,依赖延迟绑定特性实现准确调度到目标节点。
local pv的关键核心技术点是容量隔离(lvm、xfs quota)、IO隔离(cgroup v1一般要定制内核,cgroup v2支持buffer io等)、动态provision等问题,为了解决以上或部分痛点,社区也诞生了一系列的开源项目,如TopoLVM(支持动态provision、lvm),sig-storage-local-static-provisioner等项目,各云厂商如腾讯内部也有相应的local pv解决方案。总体而言,local pv适用于磁盘io敏感型的etcd、MySQL、tidb等存储服务,如pingcap的tidb项目就推荐在生产环境使用local pv。
local pv 的缺点是节点故障后,数据无法访问、可能丢失、无法垂直扩容(受限于节点磁盘容量等)。 因此这对有状态服务本身和其 operator 提出了更高要求,服务本身需要通过主备复制协议和共识算法,保证数据安全性。任一节点故障后,operator 能及时扩容新节点,从冷备、leader 快照进行数据恢复。如 tidb 的 tikv 服务,当检测到实例有异常后,会自动扩容新实例,通过 raft 协议完成数据的复制等。
混沌工程
通过以上技术方案,解决了负载类型选型、自定义资源扩展、调度、高可用、高性能网络、高性能存储、稳定性测试等一系列痛点后,我们可基于 Kubernetes 的构建稳定、高可用、弹性伸缩的有状态服务。
那么如何验证容器化后的有状态服务稳定性呢?
社区提供了多个基于 Kubernetes 实现的混沌工程开源项目,比如 pingcap 的 chaos-mesh, 提供了 Pod chaos/Network chaos/IO chaos 等多种故障注入。基于 chaos mesh,你可以快速注入 Pod 故障、磁盘IO、网络IO等异常到集群中任意 Pod,帮助你快速发现有状态服务本身和 operator Bug、检验集群的稳定性。 在 TKE 团队中,我们基于 chaos mesh 排查、复现 etcd Bug, 压测 etcd 集群的稳定性,极大的降低了我们复现复杂 Bug 的难度,帮助我们提升 etcd 内核的稳定性。
总结
本文通过从有状态集群中的各个组件 workload 选型、扩展机制的选择,介绍了如何使用 Kubernetes 的描述、部署你的有状态服务。有状态服务出于其特殊性,数据安全、高可用、高性能是其核心目标,为了保证服务的高可用,可通过调度和HA服务来实现。通过 Kubernetes 的多种调度器扩展机制,你可以将你的有状态服务的等价 Pod 完成跨故障域部署。通过主备切换服务和共识算法,你可以完成主节点故障后,备节点自动提升为主,以保证服务的高可用性。高性能主要取决于网络和存储性能,Kubernetes 提供了 CNI 网络模型和 PV/PVC 存储体系、CSI 扩展机制来满足各种业务场景下的定制需求。最后介绍了混沌工程在有状态服务中的应用,通过混沌工程你可以模拟各类异常场景下,你的有状态服务容错性,帮助你检验和提升系统的稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号