kubernetes 降本增效标准指南| 资源利用率提升工具大全
背景
公有云的发展为业务的稳定性、可拓展性、便利性带来了极大帮助。这种用租代替买、并且提供完善的技术支持和保障的服务,理应为业务带来降本增效的效果。但实际上业务上云并不意味着成本一定较少,还需适配云上业务的应用开发、架构设计、管理运维、合理使用等多方面解决方案,才能真正助力业务的降本增效。在《Kubernetes 降本增效标准指南》系列 的上一篇文章《容器化计算资源利用率现象剖析》中可看到,IDC 上云后资源利用率提高有限,即使已经容器化,节点的平均利用率依旧仅在 13% 左右,资源利用率的提升任重道远。
本篇文章将带你了解:
为什么 Kubernetes 集群中的 CPU 和内存资源利用率 通常都如此之低?
现阶段在 TKE 上面有哪些产品化的方法可以轻松提升资源利用率?
资源浪费场景
为何资源利用率通常都如此之低?首先可以看看几个业务的实际使用资源场景:
1. 资源预留普遍存在 50% 以上的浪费
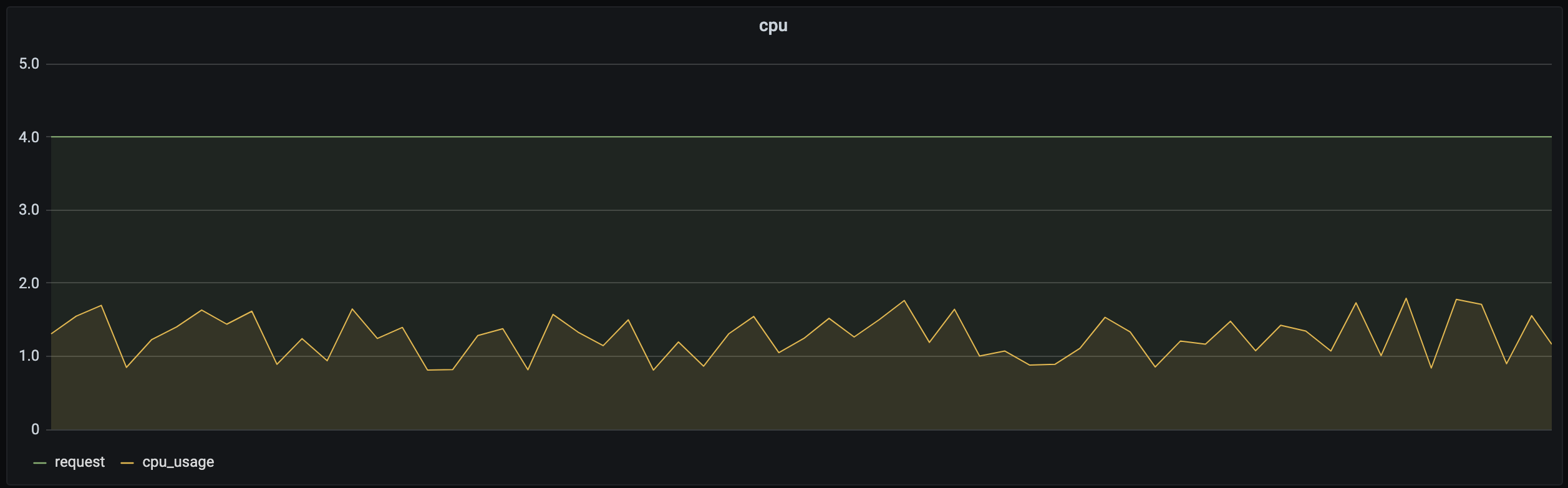
Kubernetes 中的 Request(请求) 字段用于管理容器对 CPU 和内存资源预留的机制,保证容器至少可以达到的资源量,该部分资源不能被其他容器抢占,具体可查看。当 Request 设置过小,无法保证业务的资源量,当业务的负载变高时无力承载,因此用户通常习惯将 Request 设置得很高,以保证服务的可靠性。但实际上,业务在大多数时段时负载不会很高。以 CPU 为例,下图是某个实际业务场景下容器的资源预留(Request)和实际使用量(CPU_Usage)关系图:资源预留远大于实际使用量,两者之间差值所对应的资源不能被其他负载使用,因此 Request 设置过大势必会造成较大的资源浪费。
如何解决这样的问题?现阶段需要用户自己根据实际的负载情况设置更合理的 Request、以及限制业务对资源的无限请求,防止资源被某些业务过度占用。这里可以参考后文中的 Request Quota 和 Limit Ranges 的设置。
此外,TKE 将推出 Request 推荐产品,帮助用户智能缩小 Request 和 Usage 之间的差值,在保障业务的稳定性的情况下有效提升资源利用率。
2. 业务资源波峰波谷现象普遍,通常波谷时间大于波峰时间,资源浪费明显
大多数业务存在波峰波谷,例如公交系统通常在白天负载增加,夜晚负载减少;游戏业务通常在周五晚上开始出现波峰,在周日晚开始出现波谷。如下图所示:同一业务在不同的时间段对资源的请求量不同,如果用户设置的是固定的 Request,f在负载较低时利用率很低。
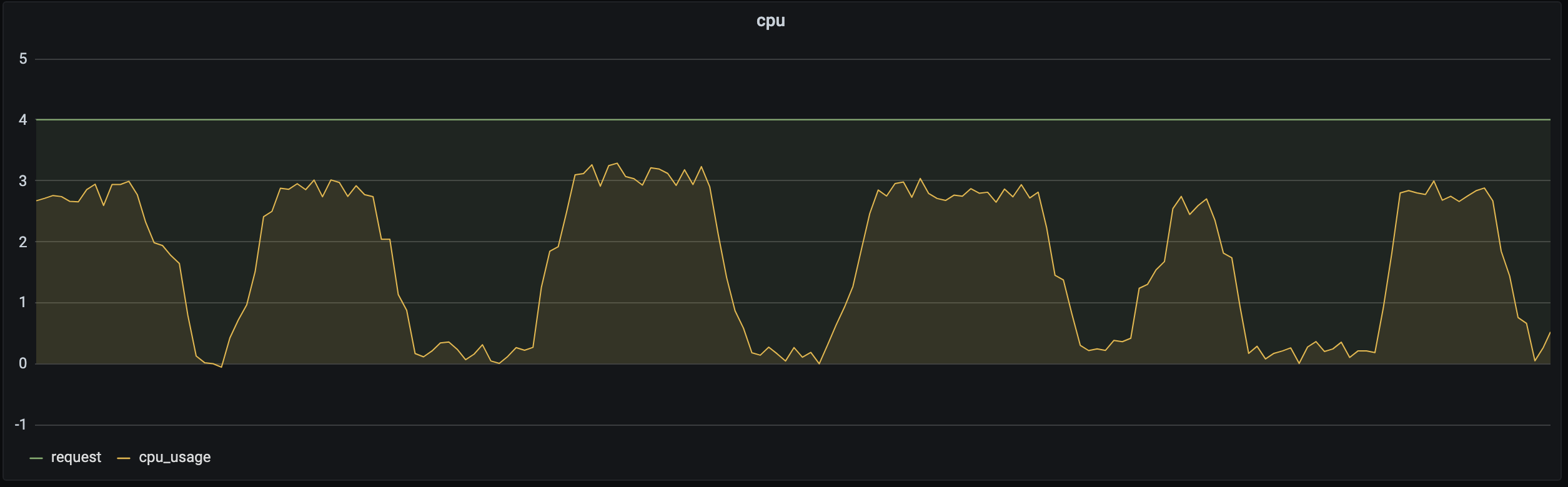
这时可以通过动态调整副本数以高资源利用率承载业务的波峰波谷,可以参考后文中的 HPA 、HPC、CA。
3. 不同类型的业务,导致资源利用率有较大差异
在线业务通常白天负载较高,对时延要求较高,必须优先调度和运行;而离线的计算型业务通常对运行时段和时延要求相对较低,理论上可以在在线业务波谷时运行。此外,有些业务属于计算密集型,对 CPU 资源消耗较多,而有些业务属于内存密集型,对内存消耗较多。
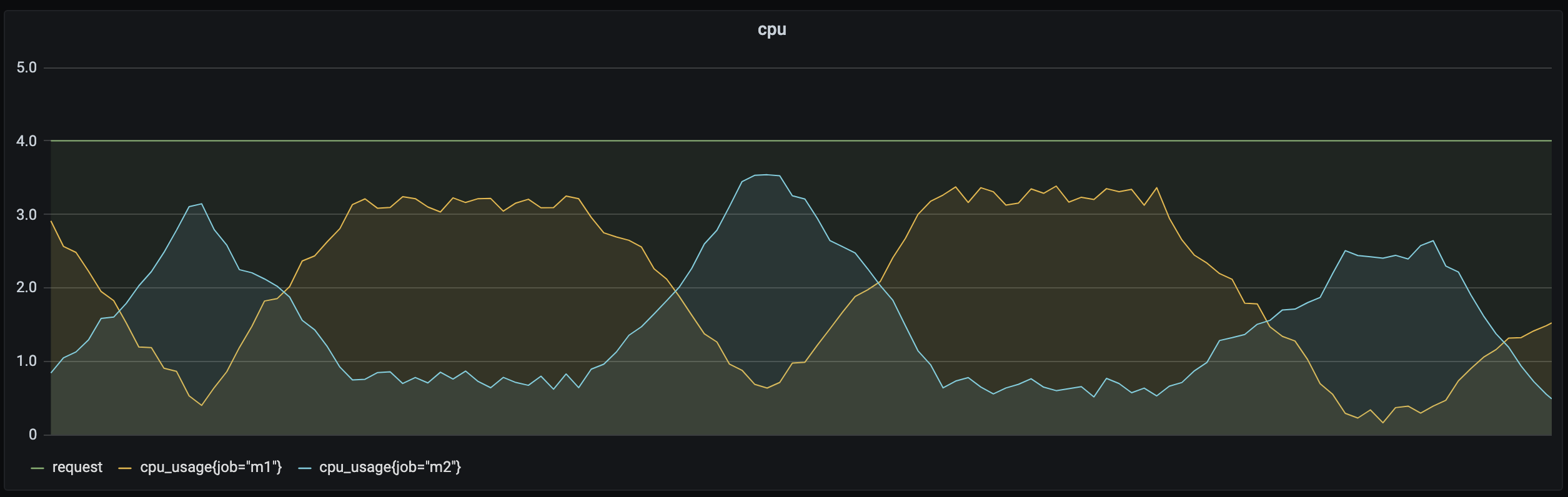
如上图所示,通过在离线混部可以动态调度离线业务和在线业务,让不同类型业务在不同的时间段运行以提升资源利用率。对于计算密集型业务和内存密集型业务,可以使用亲和性调度,为业务分配更合适的节点,有效提升资源利用率。具体方式可参考后文中的离在线混部和亲和性调度。
在 Kubernetes 上提升资源利用率的方法
腾讯云容器服务 TKE 基于大量的用户实际业务,已经产品化了一系列工具,帮助用户轻松有效的提升资源利用率。主要从两方面着手:一是利用原生的 Kubernetes 能力手动进行资源的划分和限制;二是结合业务特性的自动化方案。

1. 如何资源划分和限制
设想,你是个集群管理员,现在有4个业务部门使用同一个集群,你的责任是保证业务稳定性的前提下,让业务真正做到资源的按需使用。为了有效提升集群整体的资源利用率,这时就需要限制各业务使用资源的上限,以及通过一些默认值防止业务过量使用。
理想情况下,业务应该根据实际情况,设置合理的 Request 和 Limit。(Request 用于对资源的占位,表示容器至少可以获得的资源;Limit 用于对资源的限制,表示容器至多可以获得的资源。)这样更利于容器的健康运行、资源的充分使用。但实际上用户经常忘记设置容器对资源的 Request 和 Limit。此外,对于共享使用一个集群的团队/项目来说,他们通常都将自己容器的 Request 和 Limit 设置得很高以保证自己服务的稳定性。如果你使用的是 TKE 的控制台,创建负载时会给所有的容器设置如下默认值。该默认值是 TKE 根据真实业务分析预估得出,和具体的业务需求之间可能存在偏差。
| Request | Limit | |
|---|---|---|
| CPU(核) | 0.25 | 0.5 |
| Memory(MiB) | 256 | 1024 |
为了更细粒度的划分和管理资源,可以在 TKE 上设置命名空间级别的 Resource Quota 以及 Limit Ranges。
1.1 使用 Resource Quota 划分资源
如果你管理的某个集群有4个业务,为了实现业务间的隔离和资源的限制,你可以使用命名空间和 Resource Quota
Resource Quota 用于设置命名空间资源的使用配额,命名空间是 Kubernetes 集群里面的一个隔离分区,一个集群里面通常包含多个命名空间,例如 Kubernetes 用户通常会将不同的业务放在不同的命名空间里,你可以为不同的命名空间设置不同的 Resource Quota,以限制一个命名空间对集群整体资源的使用量,达到预分配和限制的效果。Resource Quota 主要作用于如下方面,具体可查看。
- 计算资源:所有容器对 CPU 和 内存的 Request 以及 Limit 的总和
- 存储资源:所有 PVC 的存储资源请求总和
- 对象数量:PVC/Service/Configmap/Deployment等资源对象数量的总和
Resource Quota 使用场景
- 给不同的项目/团队/业务分配不同的命名空间,通过设置每个命名空间资源的 Resource Quota 以达到资源分配的目的
- 设置一个命名空间的资源使用数量的上限以提高集群的稳定性,防止一个命名空间对资源的多度侵占和消耗
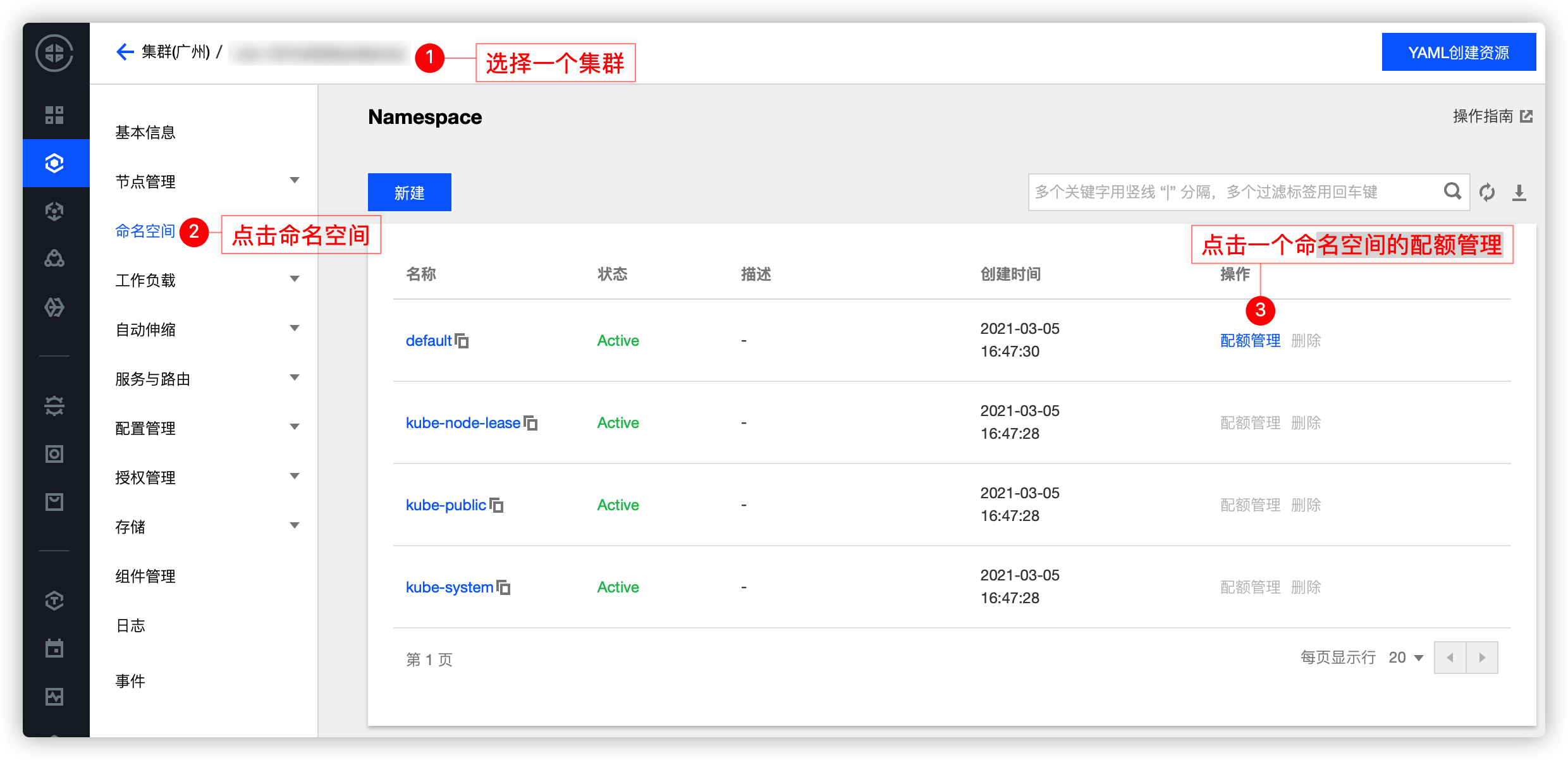
TKE 上的 Resource Quota
TKE 上已经实现对 Resource Quota 的产品化,你可以直接在控制台利用 Resource Quota 限制一个命名空间的资源使用量,具体可参考文档。
1.2 使用 Limit Ranges 限制资源
用户经常忘记设置资源的 Request 和 Limit,或者将值设置得很大怎么办?作为管理员,如果可以为不同的业务设置不同资源使用默认值以及范围,可以有效减少业务创建时的工作量同时,限制业务对资源的过度侵占。
与 Resource Quota 对命名空间整体的资源限制不同,Limit Ranges 适用于一个命名空间下的单个容器。可以防止用户在命名空间内创建对资源申请过小或过大容器,防止用户忘记设置容器的 Request 和 Limit。Limit Ranges 主要作用于如下方面,具体可查看。
- 计算资源:对所有容器设置 CPU 和内存使用量的范围
- 存储资源:对所有 PVC 能申请的存储空间的范围
- 比例设置:控制一种资源 Request 和 Limit 之间比例
- 默认值:对所有容器设置默认的 Request/Limit,如果容器未指定自己的内存请求和限制,将为它指定默认的内存请求和限制
Limit Ranges 使用场景
- 设置资源使用默认值,以防用户遗忘,也可以避免 QoS 驱逐重要的 Pod
- 不同的业务通常运行在不同的命名空间里,不同的业务通常资源使用情况不同,为不同的命名空间设置不同的 Request/Limit 可以提升资源利用率
- 限制容器个对资源使用的上下限,保证容器正常运行的情况下,限制其请求过多资源
TKE 上的 Limit Ranges
TKE 上已经实现对 Limit Ranges 的产品化,你可以直接在控制台管理命名空间的 Limit Ranges,具体可参考文档。
2. 自动化提升资源利用率的方法
上面提到的利用 Resource Quota 和 Limit Ranges 来分配和限制资源的方法依赖经验和手工,主要解决的是资源请求和分配不合理。如何更自动化的动态调整以提升资源利用率是用户更关心的问题,接下来从弹性伸缩、调度、在离线混部三大产品化的方向,详述如何提升资源利用率。
2.1 弹性伸缩
2.1.1 通过 HPA 按指标弹性扩缩容
如上面资源浪费场景2所说,如果你的业务是存在波峰波谷的,固定的资源 Request 注定在波谷时会造成资源浪费,针对这样的场景,如果波峰的时候可以自动增加业务负载的副本数量,波谷的时候可以自动减少业务负载的副本数量,将有效提升资源整体利用率。
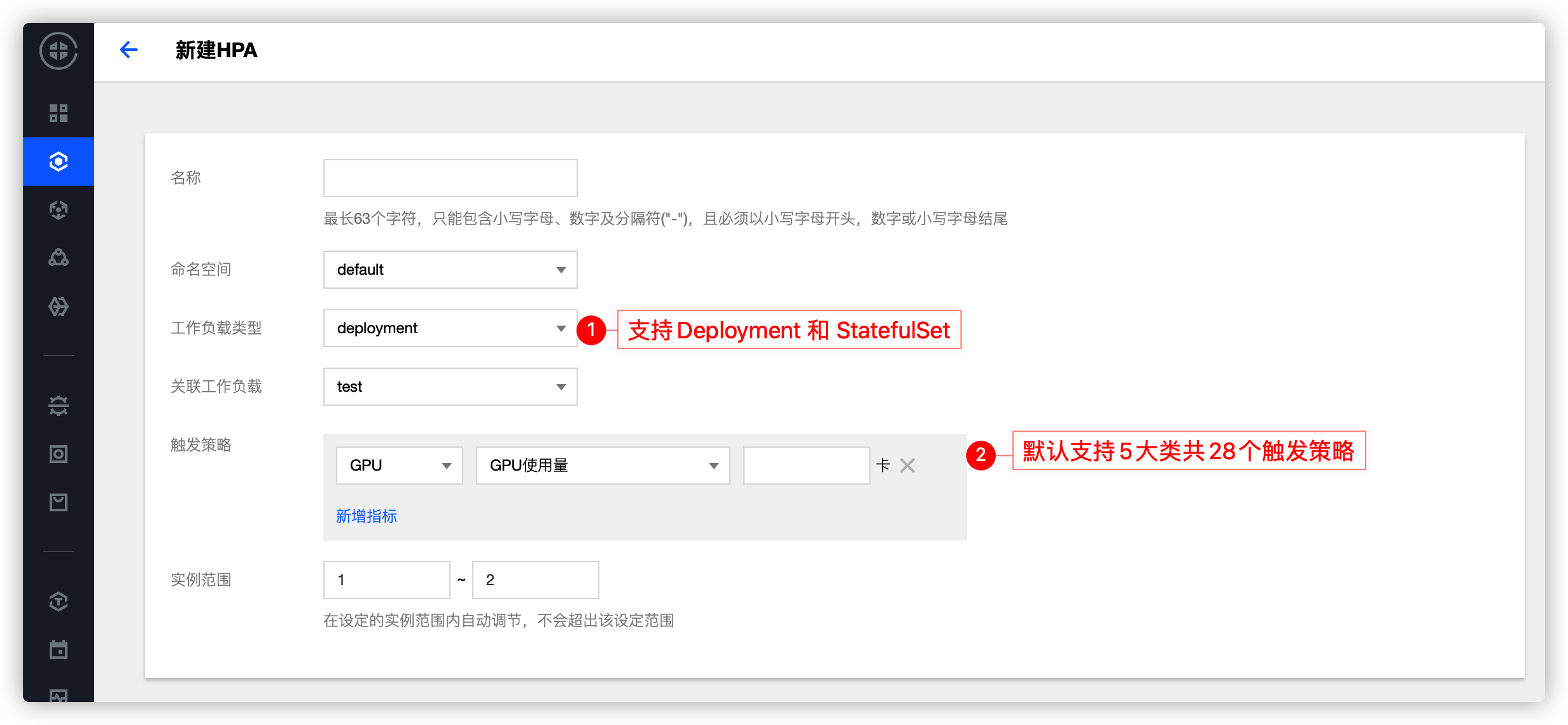
HPA(Horizontal Pod Autoscaler)可以基于一些指标(例如 CPU、内存的利用率)自动扩缩 Deployment 和 StatefulSet 中的 Pod 副本的数量,达到工作负载稳定的目的,真正做到按需使用。
HPA 使用场景
- 流量突发:突然流量增加,负载过载时会自动增加 Pod 数量以及时响应
- 自动缩容:流量较少时,负载对资源的利用率过低时会自动减少 Pod 的数量以避免浪费
TKE 上的 HPA
TKE 基于 Custom Metrics API 支持许多用于弹性伸缩的指标,涵盖 CPU、内存、硬盘、网络以及 GPU 相关的指标,覆盖绝大多数的 HPA 弹性伸缩场景,详细列表请参见 自动伸缩指标说明。此外,针对例如基于业务单副本 QPS 大小来进行自动扩缩容等复杂场景,可通过安装 prometheus-adapter 来实现自动扩缩容,具体可参考文档。
2.1.2 通过 HPC 定时扩缩容
假设你的业务是电商平台,双十一要进行促销活动,这时可以考虑使用 HPA 自动扩缩容。但是 HPA 需要先监控各项指标后,再进行反应,可能扩容速度不够快,无法及时承载高流量。针对这种有预期的流量暴增,如果能提前发生副本扩容,将有效承载流量井喷。
HPC(HorizontalPodCronscaler)是 TKE 自研组件,旨在定时控制副本数量,以达到提前扩缩容、和提前触发动态扩容时资源不足的影响,相较社区的 CronHPA,额外支持:
- 与 HPA 结合:可以实现定时开启和关闭 HPA,让你的业务在高峰时更弹性
- 例外日期设置:业务的流量不太可能永远都是规律的,设置例外日期可以减少手工调整 HPC
- 单次执行:以往的 CronHPA 都是永久执行,类似 Cronjob,单次执行可以更灵活的应对大促场景
HPC 使用场景
以游戏服务为例,从周五晚上到周日晚上,游戏玩家数量暴增。如果可以将游戏服务器在星期五晚上前扩大规模,并在星期日晚上后缩放为原始规模,则可以为玩家提供更好的体验。如果使用 HPA,可能因为扩容速度不够快导致服务受影响。
TKE 上的 HPC
TKE 上已经实现对 HPC 的产品化,但你需要提前在”组件管理“里面安装 HPC,HPC 使用 CronTab 语法格式。
安装:
使用:
2.1.3 通过 CA 自动调整节点数量
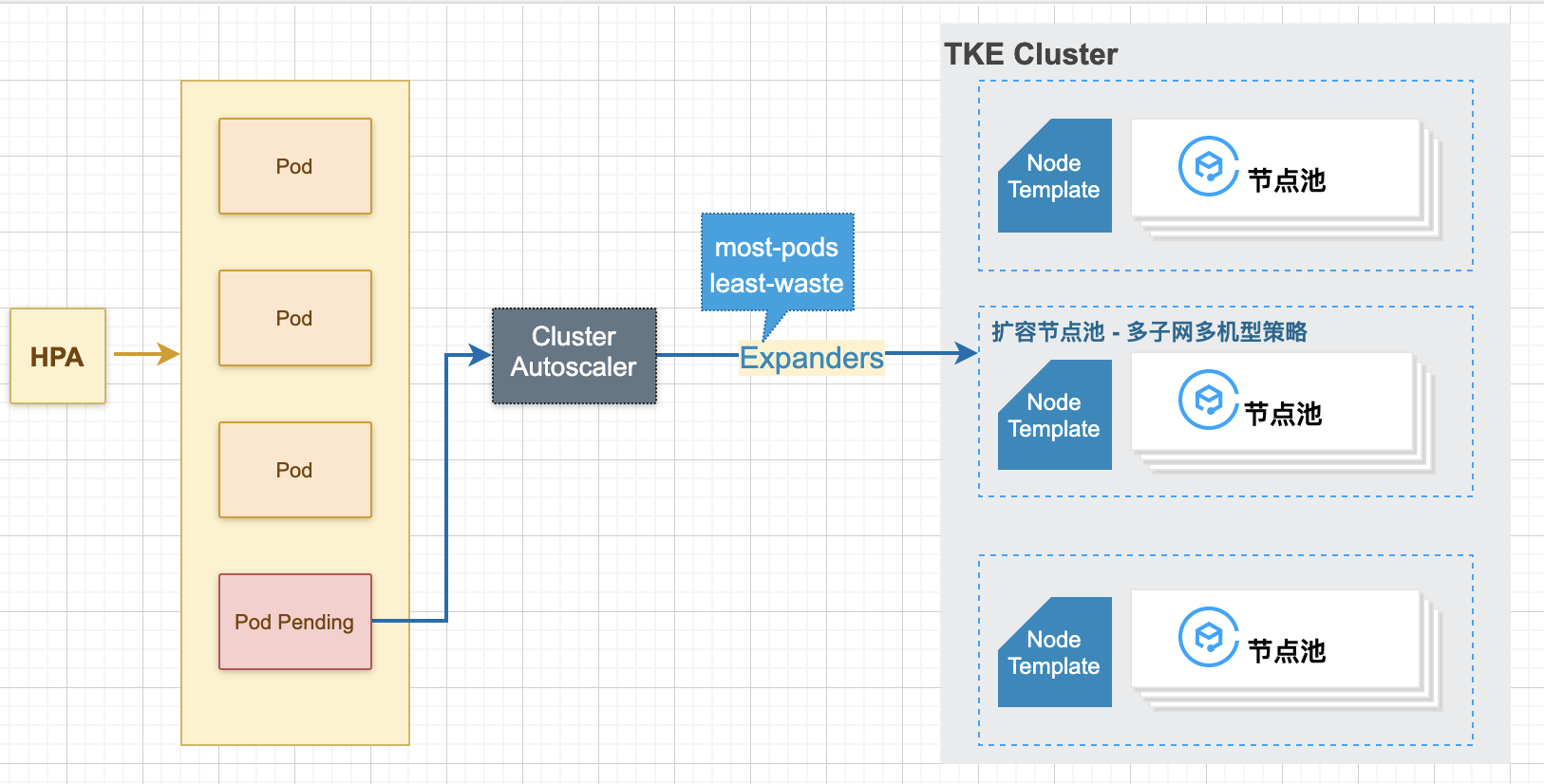
上面提到的 HPA 和 HPC,都是在业务负载层面的自动扩缩副本数量,以灵活应对流量的波峰波谷,提升资源利用率。但是对于集群整体而言,资源总数是固定的,HPA 和 HPC 只是让集群有更多空余的资源,是否有一种方法,能在集群整体较“空”时回收部分资源,能在集群整体较“满”时扩充集群整体资源?因为集群整体资源的使用量直接决定了账单费用,这种集群级别的弹性扩缩将真正帮助你节省使用成本。
CA(Cluster Autoscaler)用于自动扩缩集群节点数量,以真正实现资源利用率的提升,并直接作用于用户的费用,是降本增效的关键。
CA 使用场景
- 在业务波峰时,根据业务突增的负载扩容合适的节点
- 在业务波谷时,根据资源的空闲情况释放多余的节点
TKE 上的 CA
TKE 上的 CA 是以节点池的形态来让用户使用的,CA 推荐和 HPA 一起使用:HPA 负责应用层的扩缩容,CA 负责资源层(节点层)的扩缩容,当 HPA 扩容造成集群整体资源不足时,会引发 Pod 的 Pending,Pod Pending 会触发 CA 扩充节点池以增加集群整体资源量,整体扩容逻辑可参考下图:
具体的参数配置方式以及应用场景可参考《像管理 Pod 一样管理 Node》,或者可参考腾讯云容器服务官方文档。
2.2 调度
Kubernetes 调度机制是 Kubernetes 原生提供的一种高效优雅的资源分配机制,它的核心功能是为每个 Pod 找到最适合它的节点,在 TKE 场景下,调度机制帮助实现了应用层弹性伸缩到资源层弹性伸缩的过渡。通过合理利用 Kubernetes 提供的调度能力,根据业务特性配置合理的调度策略,也能有效提高集群中的资源利用率。
2.2.1 节点亲和性
倘若你的某个业务是 CPU 密集型,不小心被 Kubernetes 的调度器调度到内存密集型的节点上,导致内存密集型的 CPU 被占满,但内存几乎没怎么用,会造成较大的资源浪费。如果你能为节点设置一个标记,表明这是一个 CPU 密集型的节点,然后在创建业务负载时也设置一个标记,表明这个负载是一个 CPU 密集型的负载,Kubernetes 的调度器会将这个负载调度到 CPU 密集型的节点上,这种寻找最合适的节点的方式,将有效提升资源利用率。
创建 Pod 时,可以设置节点亲和性,即指定 Pod 想要调度到哪些节点上(这些节点是通过 K8s Label)来指定的。
节点亲和性使用场景
节点亲和性非常适合在一个集群中有不同资源需求的工作负载同时运行的场景。比如说,腾讯云的 CVM(节点) 有 CPU 密集型的机器,也有内存密集型的机器。如果某些业务对 CPU 的需求远大于内存,此时使用普通的 CVM 机器,势必会对内存造成较大浪费。此时可以在集群里添加一批 CPU 密集型的 CVM,并且把这些对 CPU 有较高需求的 Pod 调度到这些 CVM 上,这样可以提升 CVM 资源的整体利用率。同理,还可以在集群中管理异构节点(比如 GPU 机器),在需要 GPU 资源的工作负载中指定需要GPU资源的量,调度机制则会帮助你寻找合适的节点去运行这些工作负载。
TKE 上的节点亲和性
TKE 提供与原生 Kubernetes 完全一致的亲和性使用方式,你可通过控制台或配置 YAML 的方式使用此项功能,具体可参考。
2.2.2 动态调度器
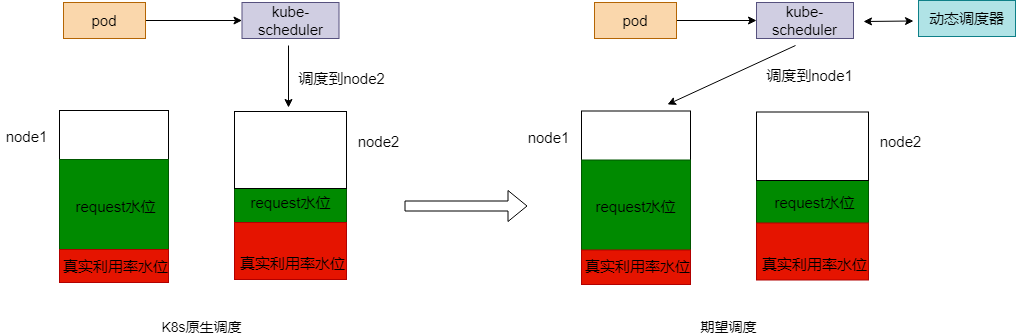
原生的 Kubernetes 调度策略倾向于调度pod到节点剩余资源较多的节点上, 比如默认的 LeastRequestedPriority 策略。但是原生调度策略存在一个问题:这样的资源分配是静态的,Request 不能代表资源真实使用情况,因此一定会存在一定程度的浪费。因此,如果调度器可以基于节点的实际资源利用率进行调度,将一定程度上解决资源浪费的问题。
TKE 自研的动态调度器所做的就是这样的工作。动态调度器的核心原理如下:
动态调度器的使用场景
除了降低资源浪费,动态调度器还可以很好的缓解集群调度热点的问题。
- 动态调度器会统计过去一段时间调度到节点的 Pod 数目,避免往同一节点上调度过多的 Pod
- 动态调度器支持设置节点负载阈值,在调度阶段过滤掉超过阈值的节点。
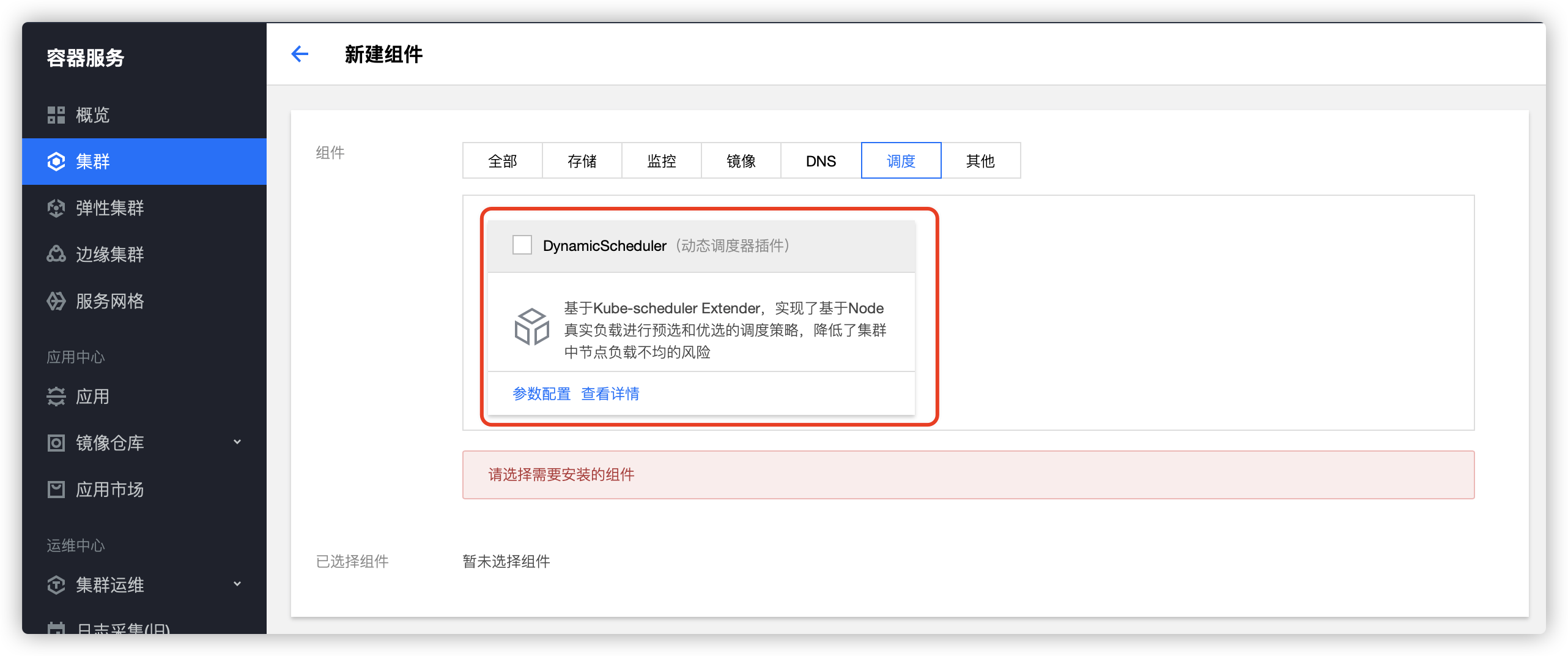
TKE 上的动态调度器
你可以在扩展组件里面安装和使用动态调度器:
更多关于动态调度器的使用指南,可以参考 《TKE 重磅推出全链路调度解决方案》 和官方文档。
2.3 在离线业务混部
如果你既有在线 Web 服务业务,又有离线的计算服务业务,借助 TKE 的在离线业务混部技术可以动态调度和运行不同的业务,提升资源利用率。
在传统架构中,大数据业务和在线业务往往部署在不同的资源集群中,这两部分业务相互独立。但大数据业务一般更多的是离线计算类业务,在夜间处于业务高峰,而在线业务恰恰相反夜间常常处于空载状态。云原生技术借助容器完整(CPU,内存,磁盘IO,网络IO等)的隔离能力,及 Kubernetes 强大的编排调度能力,实现在线和离线业务混合部署,从而使在离线业务充分利用在线业务空闲时段的资源,以提高资源利用率。
在离线业务混部使用场景
在 Hadoop 架构下,离线作业和在线作业往往分属不同的集群,然而在线业务、流式作业具有明显的波峰波谷特性,在波谷时段,会有大量的资源处于闲置状态,造成资源的浪费和成本的提升。在离线混部集群,通过动态调度削峰填谷,当在线集群的使用率处于波谷时段,将离线任务调度到在线集群,可以显著的提高资源的利用率。然而,Hadoop Yarn 目前只能通过 NodeManager 上报的静态资源情况进行分配,无法基于动态资源调度,无法很好的支持在线、离线业务混部的场景。
TKE 上的在离线混部
在线业务具有明显的波峰浪谷特征,而且规律比较明显,尤其是在夜间,资源利用率比较低,这时候大数据管控平台向 Kubernetes 集群下发创建资源的请求,可以提高大数据应用的算力,具体可参考。
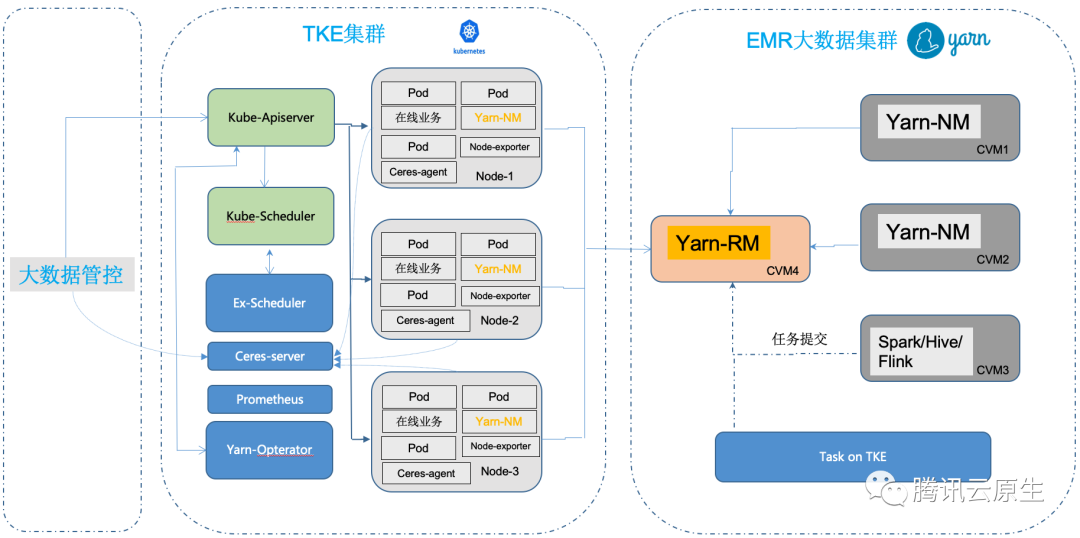
如何权衡资源利用率与稳定性
在企业的运维工作中,除了成本,系统的稳定性也是十分重要的指标。如何在两者间达到平衡,可能是很多运维人员心中的“痛点”。一方面,为了降低成本,资源利用率当然是越高越好,但是资源利用率达到一定水位后,负载过高极有可能导致业务 OOM 或 CPU 抖动等问题。
为了减小企业成本控制之路上的顾虑,TKE 还提供了“兜底神器“ - 重调度器 来保障集群负载水位在可控范围内。
重调度器是动态调度器是一对好搭档(它们的关系可以参考下图),就像它的名字一样,它主要负责“保护”节点中已经负载比较“危险”的节点, 优雅驱逐这些节点上的业务。
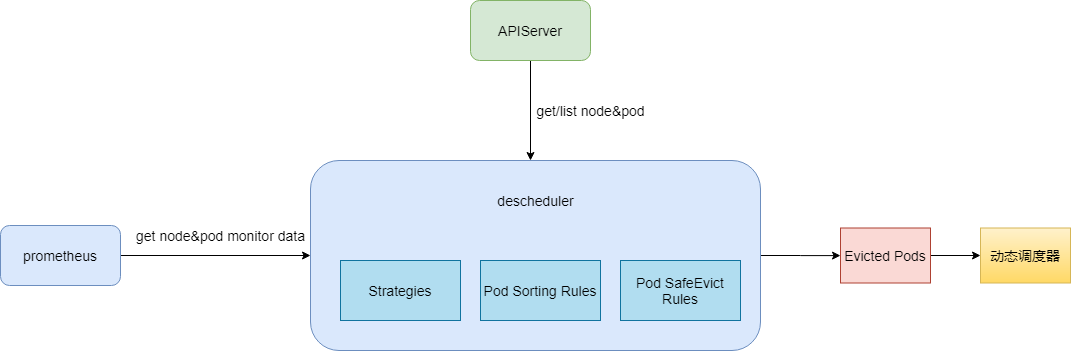
TKE 上的重调度器
可以在扩展组件里面安装和使用重调度器:
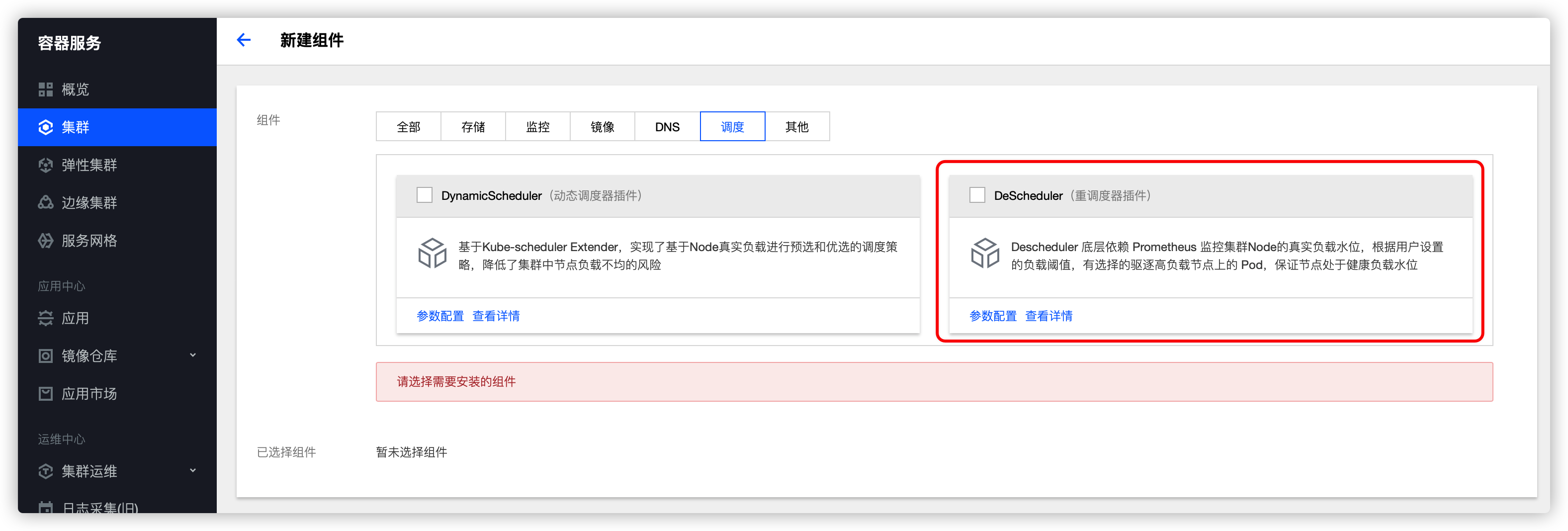
更多关于重调度器的使用指南,可以参考 《TKE 重磅推出全链路调度解决方案》 。
总结
资源利用率的提升道阻且长,如何在保障业务稳定性的前提下,有效提升资源利用率具有较大挑战。利用上述这些 TKE 的产品化方案,可以有效帮助用户解决资源利用率提升过程中的种种挑战,此外 TKE 也在开发其他的工具帮助用户降低提升资源利用率的门槛。《Kubernetes 降本增效标准指南》系列后期文章将更加深入讲解 Kubernetes 提升资源利用率的方法,敬请期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号