【从0到1学习边缘容器系列-4】弱网环境利器之分布式节点状态判定机制
导语
边缘场景下网络常常不可靠,容易误触发 Kubernetes 驱逐机制,引起不符合预期的 Pod 驱逐动作,TKE Edge 首创分布式节点状态判定机制,该机制可以更好地识别驱逐时机,保障系统在弱网络下正常运转,避免服务中断和波动。
边缘计算情境下,边缘节点与云端的网络环境十分复杂,网络质量无法保证,容易出现 APIServer 和节点连接中断的场景。如果不加改造直接使用原生 Kubernetes,节点状态会经常出现异常,进而引起 Kubernetes 驱逐机制生效,导致 Pod 的驱逐和 Endpoint 的缺失,最终造成服务的中断和波动。为了解决这个问题,TKE 边缘容器团队在边缘集群弱网环境下提出了边缘节点分布式节点状态判定机制,可以更好地识别驱逐时机。
背景
不同于中心云,边缘场景下,首先要面对云边弱网络的环境,边缘设备常常位于边缘云机房、移动边缘站点,与云端连接的网络环境十分复杂,不像中心云那么可靠。这其中既包含云端(控制端)和边缘端的网络环境不可靠,也包含边缘节点之间的网络环境不可靠,即使是同一区域不同机房之间也无法假设节点之间网络质量良好。
以智慧工厂为例,边缘节点位于厂房仓库和车间,控制端 Master 节点在腾讯云的中心机房内。
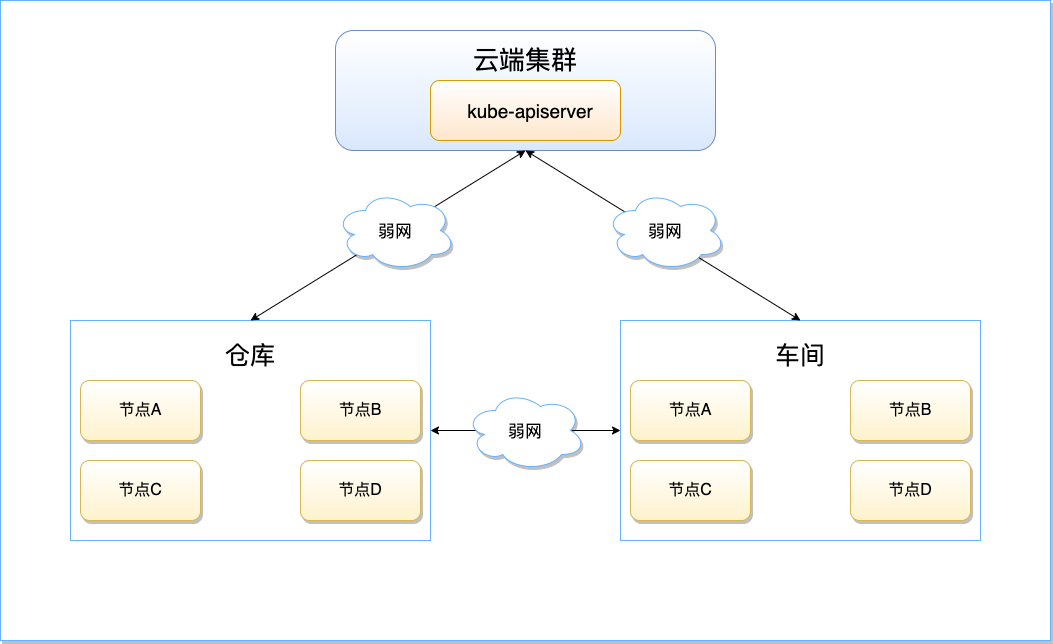
仓库和车间内的边缘设备同云端集群之间的网络较复杂,因特网、5G、WIFI 等形态均有可能,网络质量差次不齐没有保障;但是,相比于和云端的网络环境,由于仓库和车间内的边缘设备之间是本地网络,因此网络质量肯定要优于同云端集群之间的连接,相对而言更加可靠。
造成的挑战
原生 Kubernetes 处理方式
云边弱网络带来的问题是影响运行在边缘节点上的 kubelet 与云端 APIServer 之间通信,云端 APIServer 无法收到 kubelet 的心跳或者续租,无法准确获取该节点和节点上pod的运行情况,如果持续时间超过设置的阈值,APIServer 会认为该节点不可用,并做出如下一些动作:
- 失联的节点状态被置为 NotReady 或者 Unknown 状态,并被添加 NoSchedule 和 NoExecute 的 taints
- 失联的节点上的 Pod 被驱逐,并在其他节点上进行重建
- 失联的节点上的 Pod 从 Service 的 Endpoint 列表中移除
需求场景
再看一个音视频拉流场景,音视频服务是边缘计算的一个重要应用场景,如图所示:
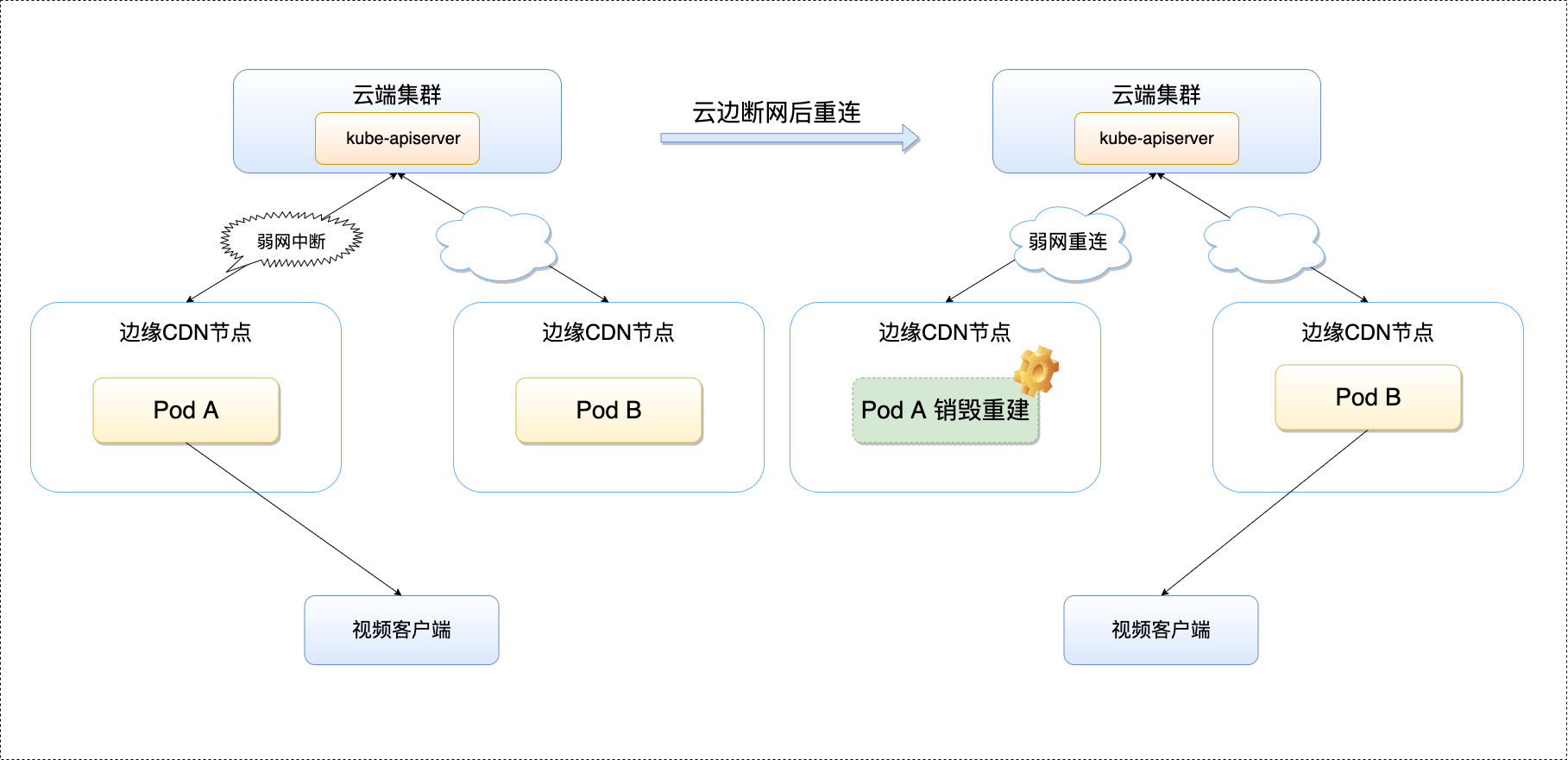
考虑到用户体验及公司成本,音视频拉流经常需要提高边缘缓存命中率减少回源,将用户请求的同一文件调度到同一个服务实例以及服务实例缓存文件均是常见的做法。
然而,在原生 Kubernetes 的情况下,如果 Pod 因为网络波动而频繁重建,一方面会影响服务实例缓存效果,另一方面会引起调度系统将用户请求调度到其他服务实例。无疑,这两点都会对 CDN 效果造成极大的影响,甚至不能接受。
事实上,边缘节点完全运行正常,Pod 驱逐或重建其实是完全不必要的。为了克服这个问题,保持服务的持续可用,TKE 边缘容器团队提出了分布式节点状态判定机制。
解决方案
设计原则
显然,在边缘计算场景中,仅仅依赖边缘端和 APIServer 的连接情况来判断节点是否正常并不合理,为了让系统更健壮,需要引入额外的判断机制。
相较于云端和边缘端,边缘端节点之间的网络更稳定,如何利用更稳定的基础设施来提高准确性呢?我们首创了边缘健康分布式节点状态判定机制,除了考虑节点与 APIServer 的连接情况,还引入了边缘节点作为评估因子,以便对节点进行更全面的状态判断。经过测试及大量的实践证明,该机制在云边弱网络情况下大大提高系统在节点状态判断上的准确性,为服务稳定运行保驾护航。
该机制的主要原理:
- 每个节点定期探测其他节点健康状态
- 集群内所有节点定期投票决定各节点的状态
- 云端和边缘端节点共同决定节点状态
首先,节点内部之间进行探测和投票,共同决定具体某个节点是否存在状态异常,保证大多数节点的一致判断才能决定节点的具体状态;另外,虽说节点之间的网络状态一般情况下要优于云边网络,但同时应该注意到,边缘节点之间网络情况也十分复杂,它们之间的网络也不是100%可靠。
因此,也不能完全信赖节点之间的网络,节点的状态不能只由节点自行决定,云边共同决定才更为可靠。基于这个考虑,我们做出了如下的设计:
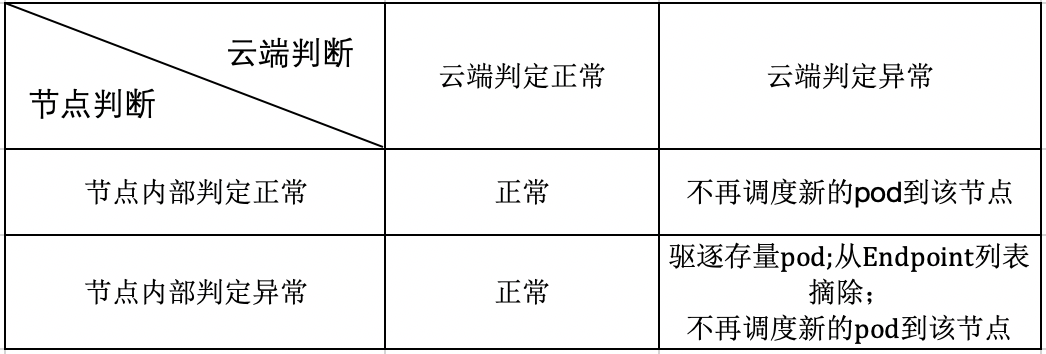
方案特性
需要注意的是,当云端判定节点异常,但是其他节点认为节点正常的时候,虽然不会驱逐已有 Pod,但是为了确保增量服务的稳定性,不会再将新的 Pod 调度到该节点上,存量的正常运行也得益于边缘集群的边缘自治能力;
另外,由于边缘网络和拓扑的特殊性,常常会存在节点组之间网络单点故障的问题,比如厂房的例子中,仓库和车间虽然都属于厂房这个地域内,但是可能二者之间的网络连接依靠一条关键链路,一旦这条链路发生中断,就会造成节点组之间的分裂,我们的方案能够确保两个分裂的节点组失联后互相判定时始终保持多数的一方节点不会被判定为异常,避免被判定为异常造成 Pod 只能被调度到少部分的节点上,造成节点负载过高的情况。
除此之外,边缘设备很有可能位于不同的地区、相互不通,让网络不通的节点之间相互检查显然就不合适了。为了应对这种情况,我们的方案也支持对节点进行分组,各个分组内的节点之间相互检测状态。考虑到有可能对节点重新分组,机制也支持实时对节点变更分组而无需重新部署检测组件或重新初始化。
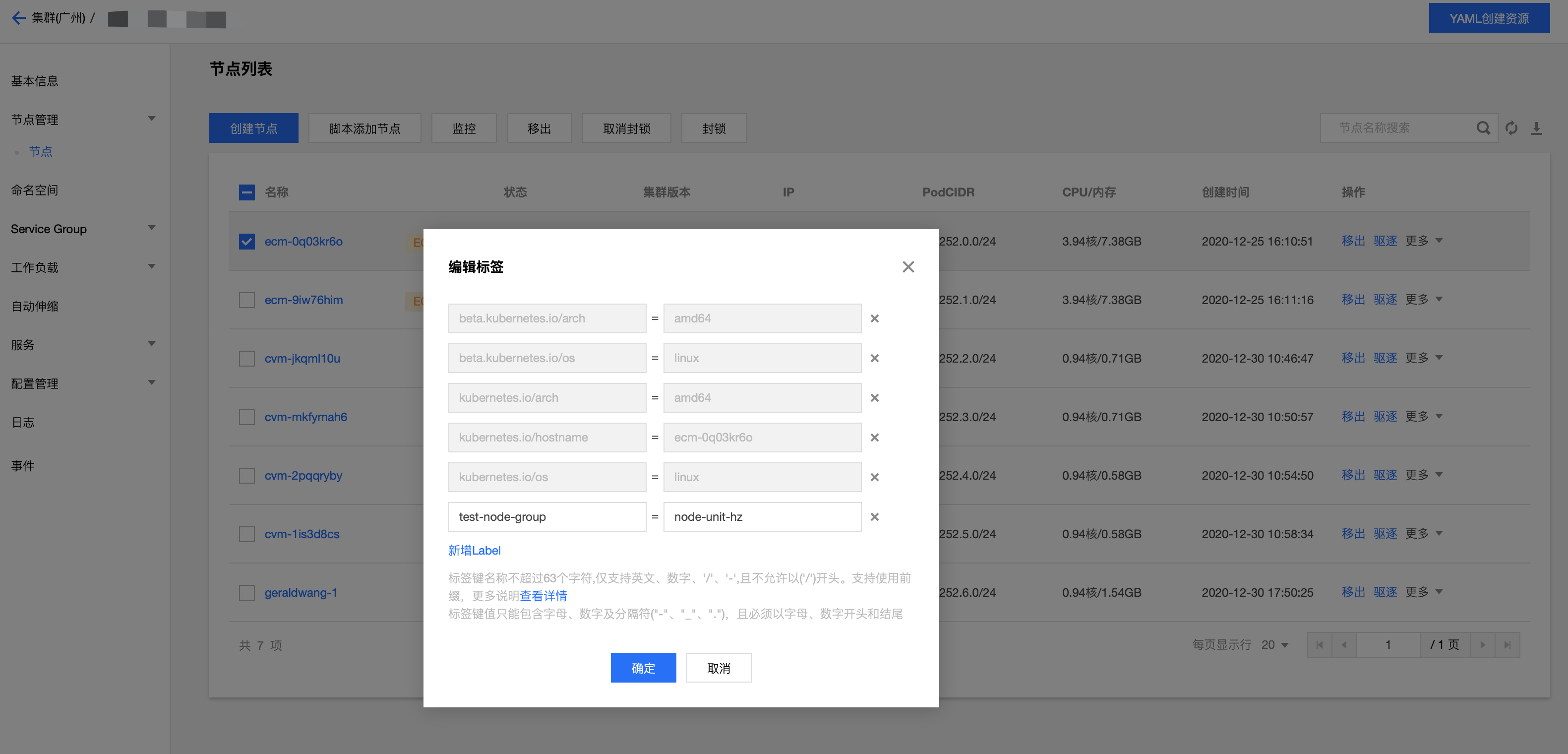
检测机制默认关闭,如果需要操作可进入基本信息-开启 Edge Health(默认关闭),如果需要为节点分组,可以继续打开“开启多地域”,然后给节点分组,分组方式为编辑和添加节点相应的标签;如果开启多地域检查后未给节点分组,默认是各个节点自己是一个组,不会检查其他节点。
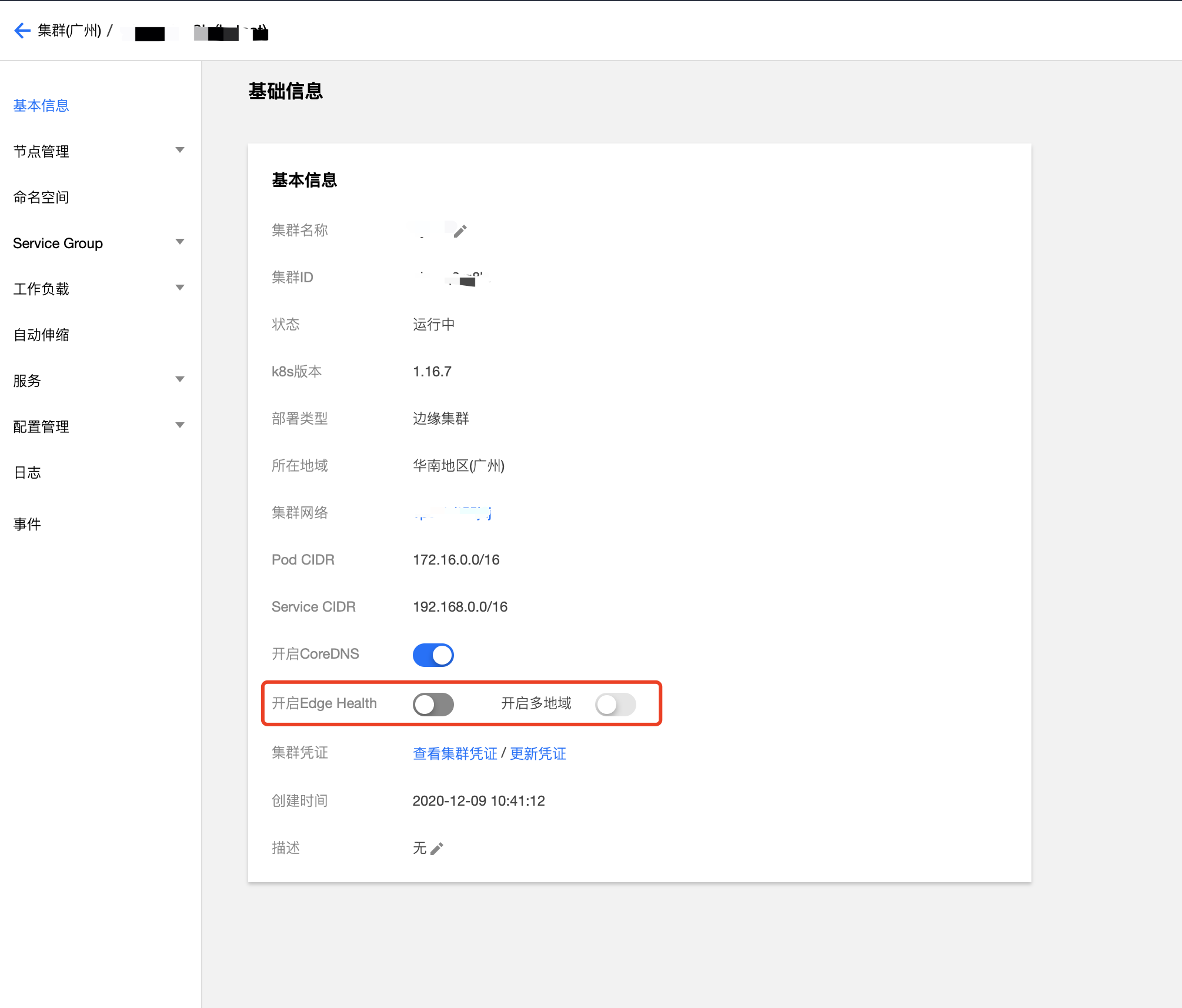
在此特性开发过程中,我们也发现了一个 node taint 相关的 Kubernetes 社区 bug 并提出了修复方案。
未来展望
未来我们会支持更多的检查方式,增强在各种场景下的稳定性;此外,当前开源的一些去中心的集群状态探测管理项目在一些场景下还不能完全满足边缘的场景,如集群分裂情况,后期我们会尝试融合借鉴满足我们的需求。
开源项目 SuperEdge
当前该组件作为边缘容器项目 SuperEdge 的一部分已经对外开源(https://github.com/superedge/superedge),欢迎大家 star,下方是微信群,微信企业微信都可以加入
公有云产品 TKE Edge
目前该产品已经全量开放,欢迎前往 边缘容器服务控制台 进行体验~
边缘系列往期精彩推荐
- 【从0到1学习边缘容器系列-1】之 边缘计算与边缘容器的起源
- 【从0到1学习边缘容器系列-2】之 边缘应用管理
- 【从0到1学习边缘容器系列-3】应用容灾之边缘自治
- 完爆!用边缘容器,竟能秒级实现团队七八人一周的工作量
- 腾讯云联合多家生态伙伴,重磅开源 SuperEdge 边缘容器项目
- 云上视频业务基于边缘容器的技术实践
- 一文读懂 SuperEdge 边缘容器架构与原理
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号