一个优秀的云原生架构需要注意哪些地方
本文整理自腾讯云容器产品,容器解决方案架构团队的陈浪交在 Techo 开发者大会云原生专题的分享内容——一个优秀的云原生架构需要注意哪些地方。本文将会给大家分享云原生架构的特点和以及实践过程中的一些注意事项。
从CNCF给出的云原生官方的定义可以看出,云原生架构其实是一种方法论,没有对开发语言、框架、中间件等做限制,它是一些先进的设计理念的融合,包括容器、微服务、尽量解耦合、敏捷、容灾、频繁迭代、自动化等。

云计算发展到今天已经比较成熟了,同时伴随着开源社区的发展,有个明显的趋势就是云服务商都在努力提供一个平台无关的服务,也就是云原生服务,强大如AWS也没办法阻挡,这个趋势的演变也值得探讨,由于时间有限,线下有机会可以交流下。由于云原生技术跟平台无关,使得用户可以从适配各个云服务商中解脱出来,从而更加聚焦在业务本身。方便让大家对云服务商的云原生平台有一个比较感性的认知,我们一起来看下云原生服务的层级架构。
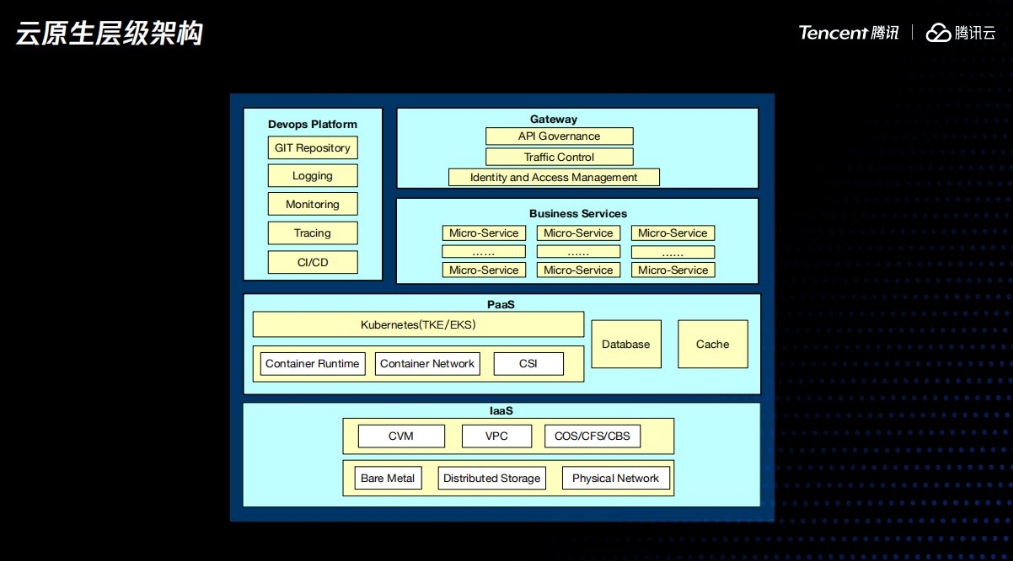
最底层是云服务商的物理机、物理网络以及物理存储,之上是虚拟化服务、包括租户隔离的网络、计算资源以及分布式存储。到了这层,云服务商提供的产品虽然大同小异,但都还是平台相关的。
关键就是在上一层的PaaS服务层,由它来适配各个厂商的计算、网络、存储资源,然后对用户提供统一的访问接口,具体起来就是云服务提供商的Kubernetes服务在内部会去对接底层的存储、计算网络、再加上标准的mysql、redis等开源服务。这样用户对接的就是一个标准接口的PaaS平台,就为我们的业务从本地开发环境无缝迁移到公有云、甚至在云服务商之间迁移、混合云、跨云容灾等提供了技术前提。
结合以上介绍的背景以及云原生的定义,我们再总结下什么是云原生架构,一个平台无关的、自动化的、具备容灾能力的敏捷的分布式业务系统。
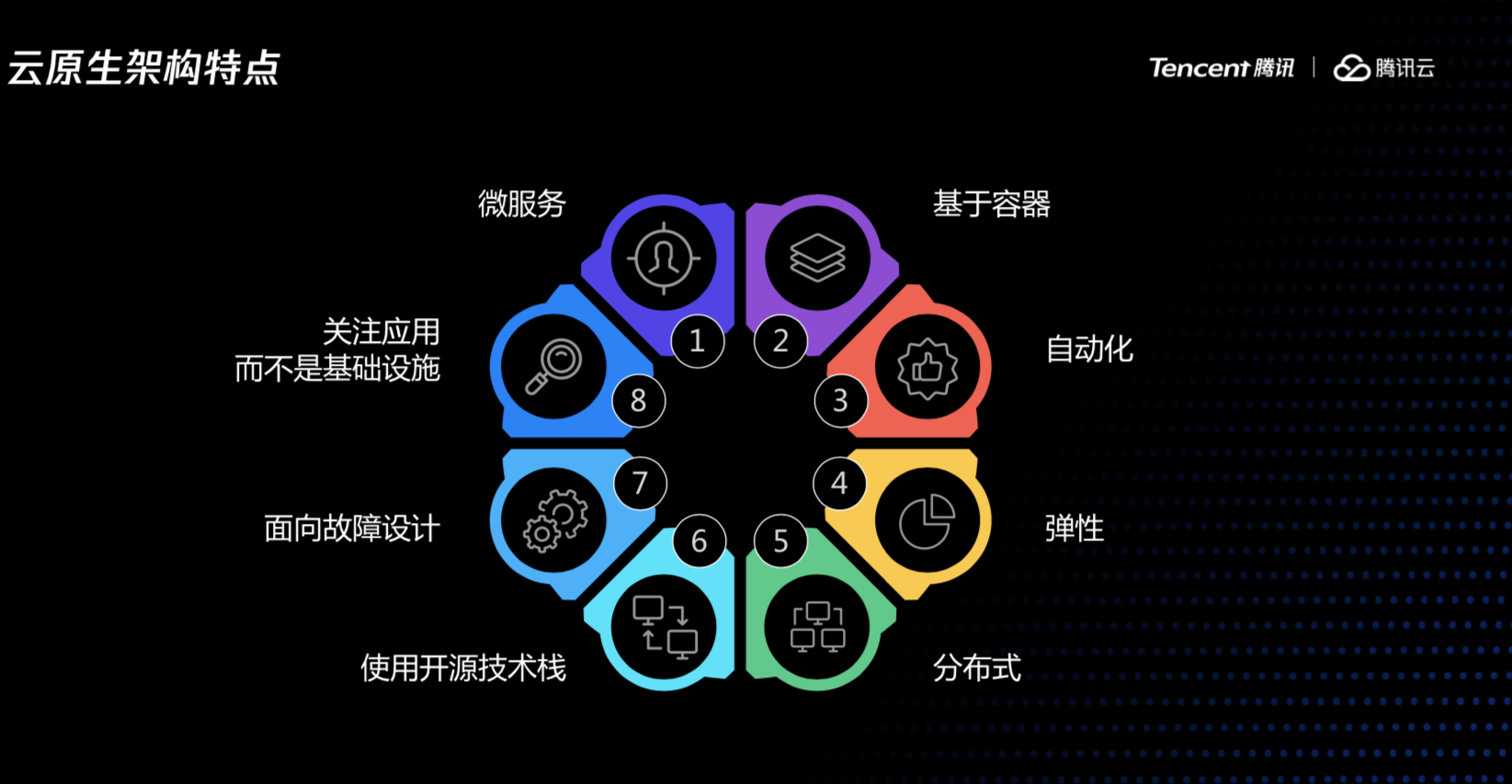
接下来介绍,在构建云原生服务时,有哪些注意事项以及一些个人的一点思考。
CNCF提供的云原生的定义对云原生做了经典概括,下述所讲内容也在它的定义范畴之内,包括为什么要做微服务拆分,为什么要容器化、如何做CICD、如何避免故障、以及故障发生时我们有哪些应对措施,最后一起交流下如何检验我们的系统是否符合云原生架构。
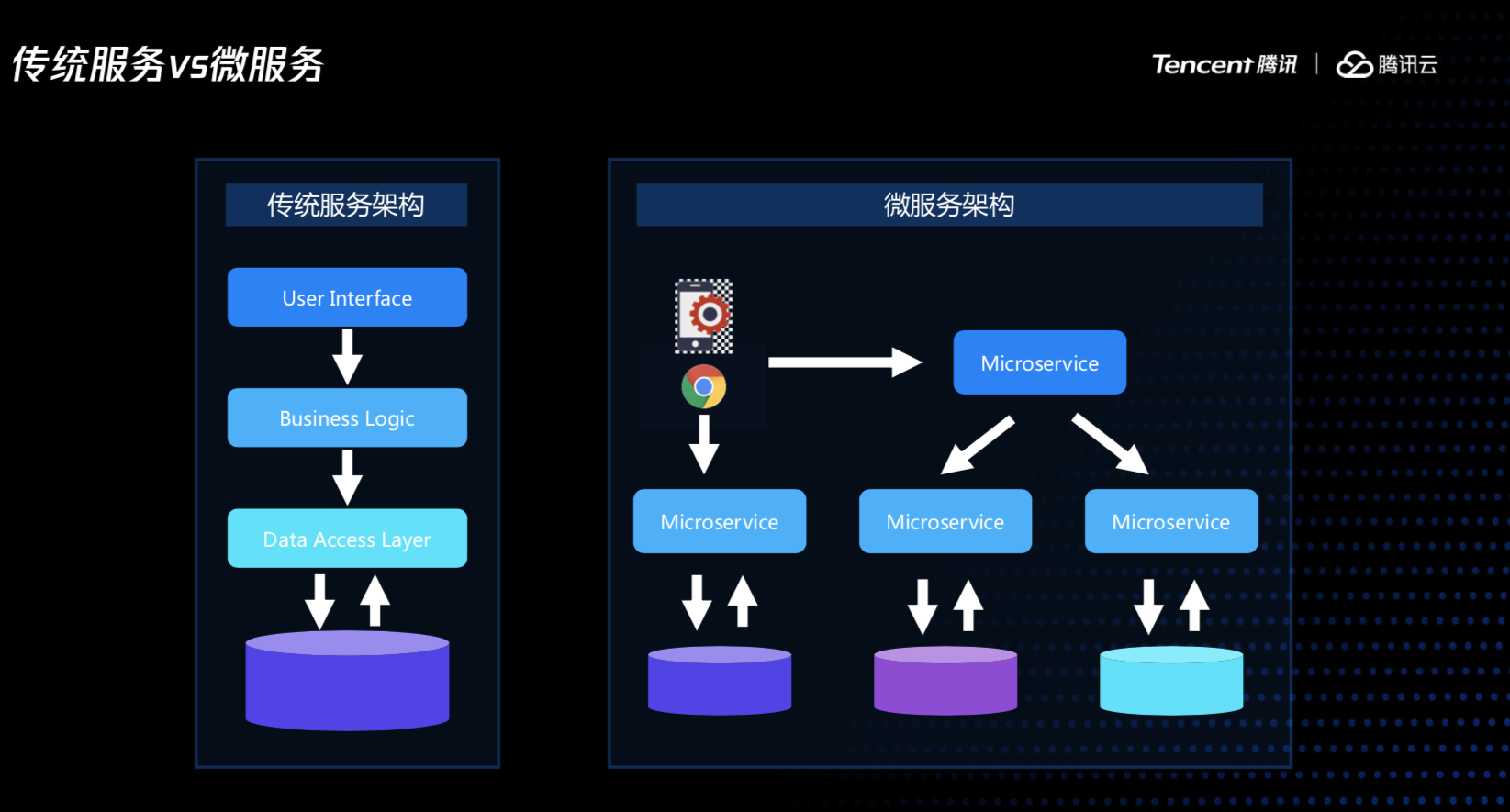
我们在讨论微服务时,其实讨论的是一个业务模块的微服务拆分是否彻底,这决定我们业务模块能否做到横向水平扩容、整体能否成为一个分布式系统。比如一个商城系统,库存服务逻辑变化了是否会影响到商品服务、订单服务,到双十一的时候,订单服务需要大幅扩容,我们能否只扩容一个服务、跟这个服务相关的数据库表而不影响其它服务。
因此,我们需要尽量减少服务之间的业务逻辑耦合、数据耦合,通过通信来进行数据共享,而不是通过共享数据来进行业务通信,使得我们在做必要的变更时,影响的范围能降低到最小。
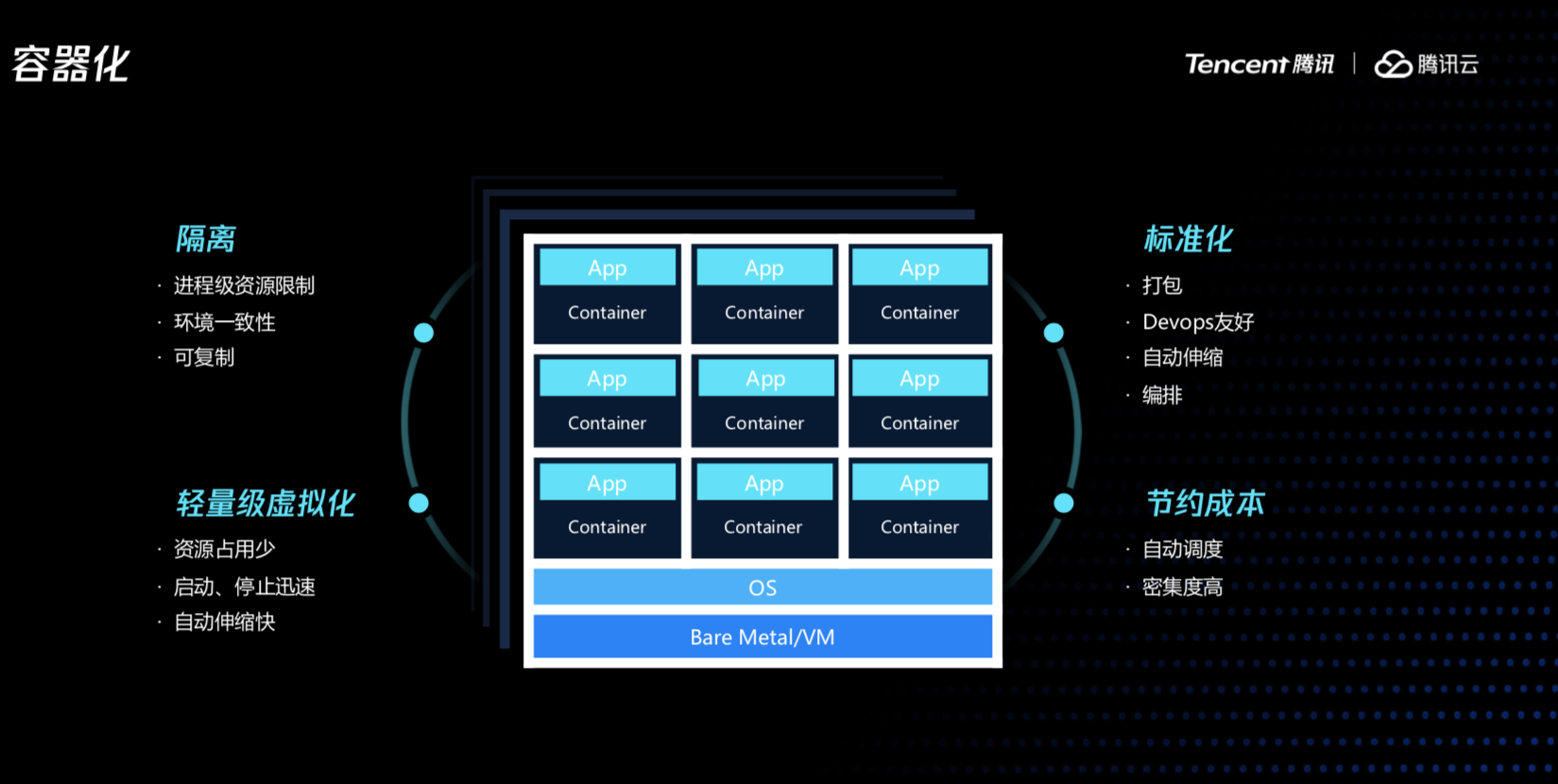
容器是云原生架构的基础,这是容器的标准化属性来决定的,如果不使用容器,CICD、自动扩缩容就没办法做,我们不知道这些服务依赖什么配置、程序如何启动、如何停止,我们可以基于自身业务特性自己开发一套CICD系统、扩缩容系统,但是不是通用的,无法移植的。
有人说没有集装箱就没有全球化,这里的容器就是集装箱,大家想是不是这个道理。容器还有很多优点,首先可以降低成本,K8s知道如何调度把容器到合适的机器上,使得集群节点使用率均衡、并且提高节点的资源使用率,可运维性也上来了。
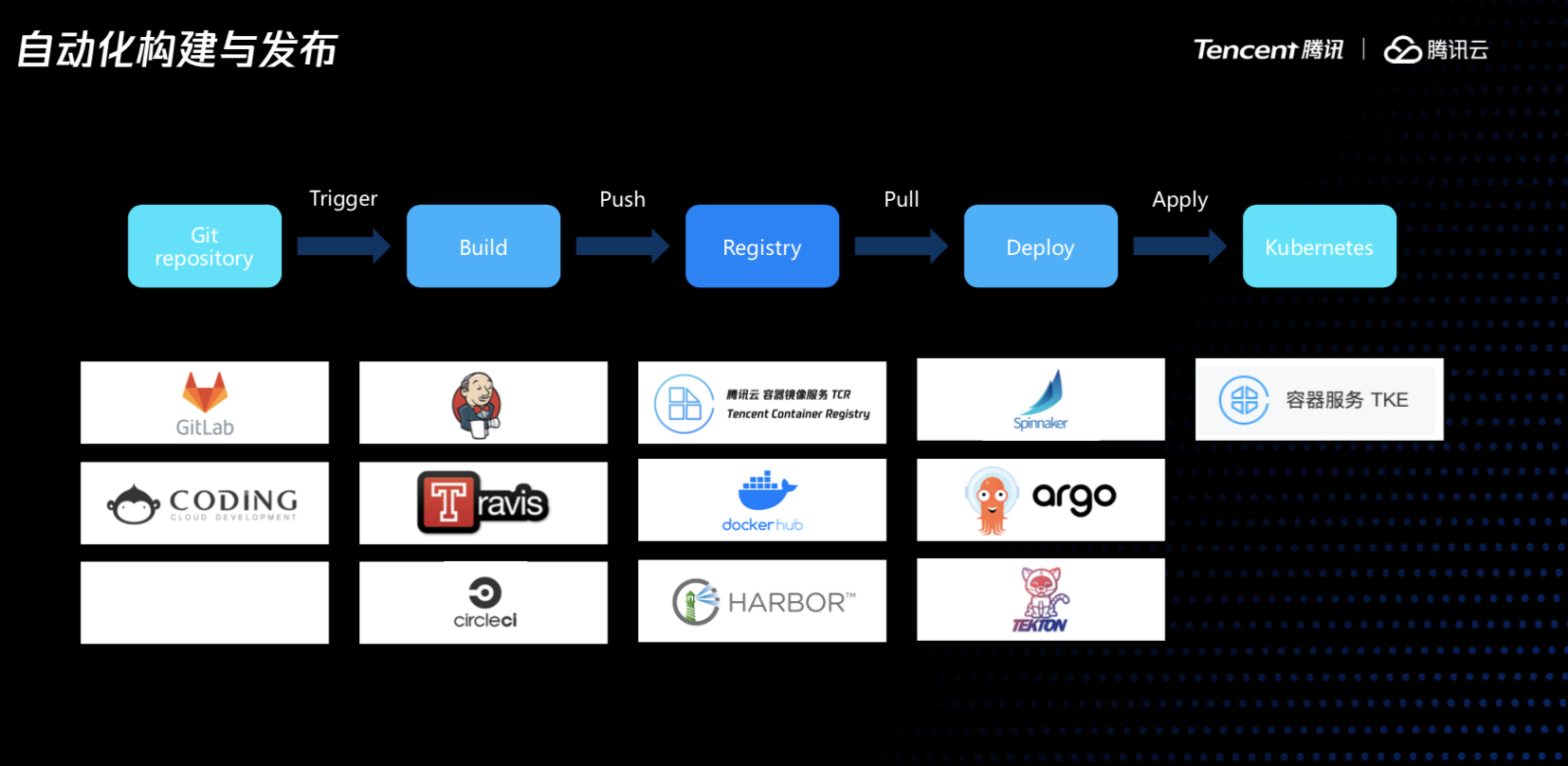
接下来讲下CICD,我们的服务容器化之后,CICD也很方便,围绕容器,围绕K8s,代码变成容器镜像、镜像发布到不同环境测试,最后再到线上,蓝绿、灰度等策略也很好做。
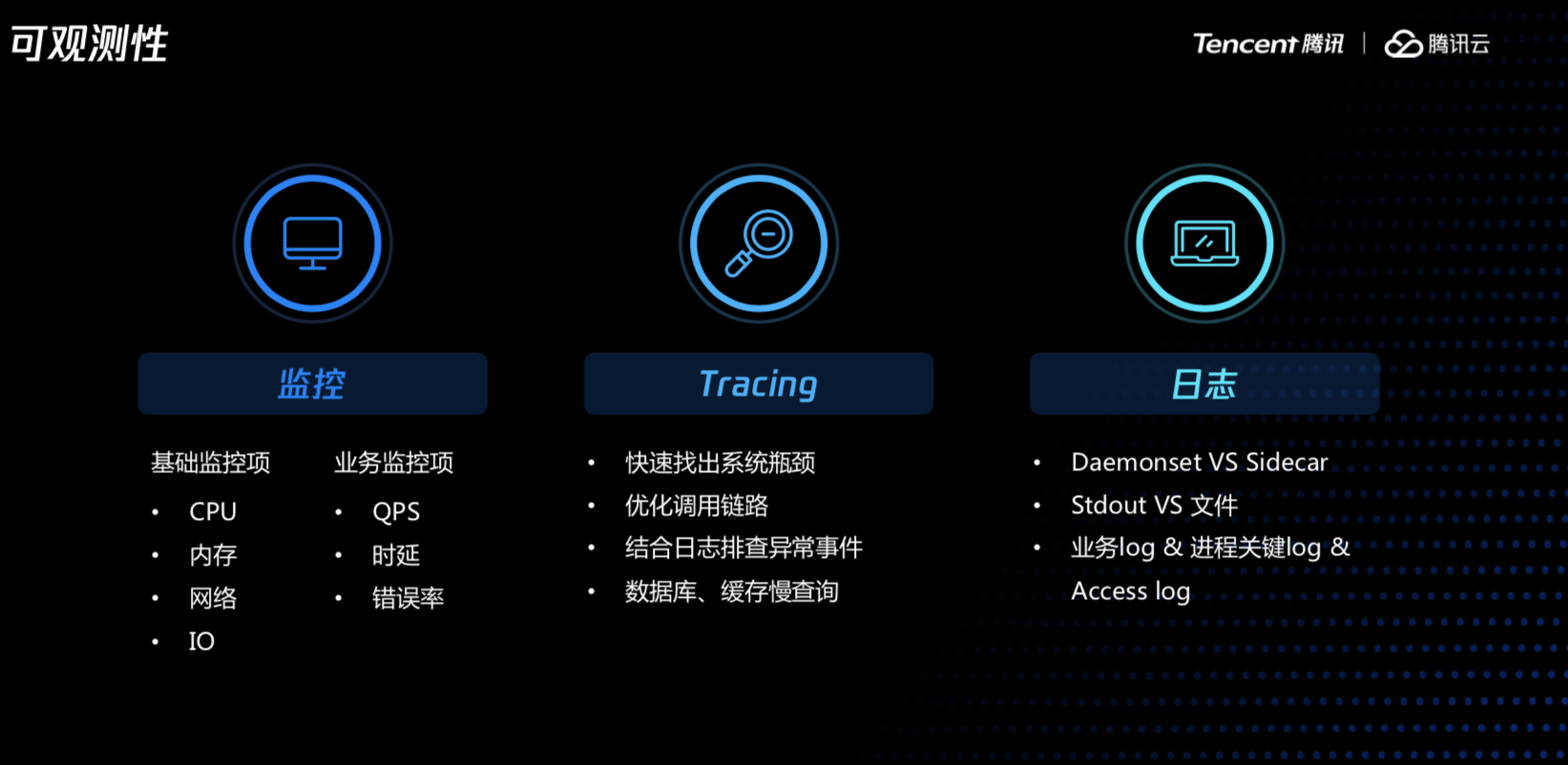
业务部署后,我们需要有一套问题发现、问题定位的手段,这样大家才能安心。常用的手段有监控、tracing以及日志系统。
对于监控,我们需要同时做好基础监控以及业务监控,容器的CPU、内存、网络、各种句柄等,业务层面,我们需要监控业务的服务质量,比较常见的就是业务的响应时间、错误率等。
通过tracing,我们可以找到具体某个请求在调用链路上的瓶颈,比如由于某个服务访问一个不重要的旁路服务,导致延时增加了50ms,如果没有tracing,很难发现这样的问题,同时还可以把数据库、缓存等中间件服务的访问信息上报到tracing系统,便于排查一些类似数据库慢查询、hot key、 big key引起的问题。
日志服务就更重要了,无论是性能问题、业务问题的排查都需要相应的日志,业务容器化后,日志查询会更加复杂一些,因为容器不会固定运行在某个主机上,需要把容器的日志采集到一个中心化的日志服务,采集容器日志时,有不同的方案,有的小伙伴选择使用SDK在业务容器里直接把日志打到日志服务,更多的是日志先落盘,然后再通过agent采集到后端存储,如果业务的log都统一输出到标准输出,建议部署daemonset的方式统一采集,如果容器的log输出到某个文件,建议使用sidecar的方式会更灵活。同时建议把进程的启动停止日志以及业务日志分开,在定位容器的启动失败等一些关键事件时更方便。关于日志平台,可以使用云服务商的日志服务,也可以自建,根据各自的需求而定。
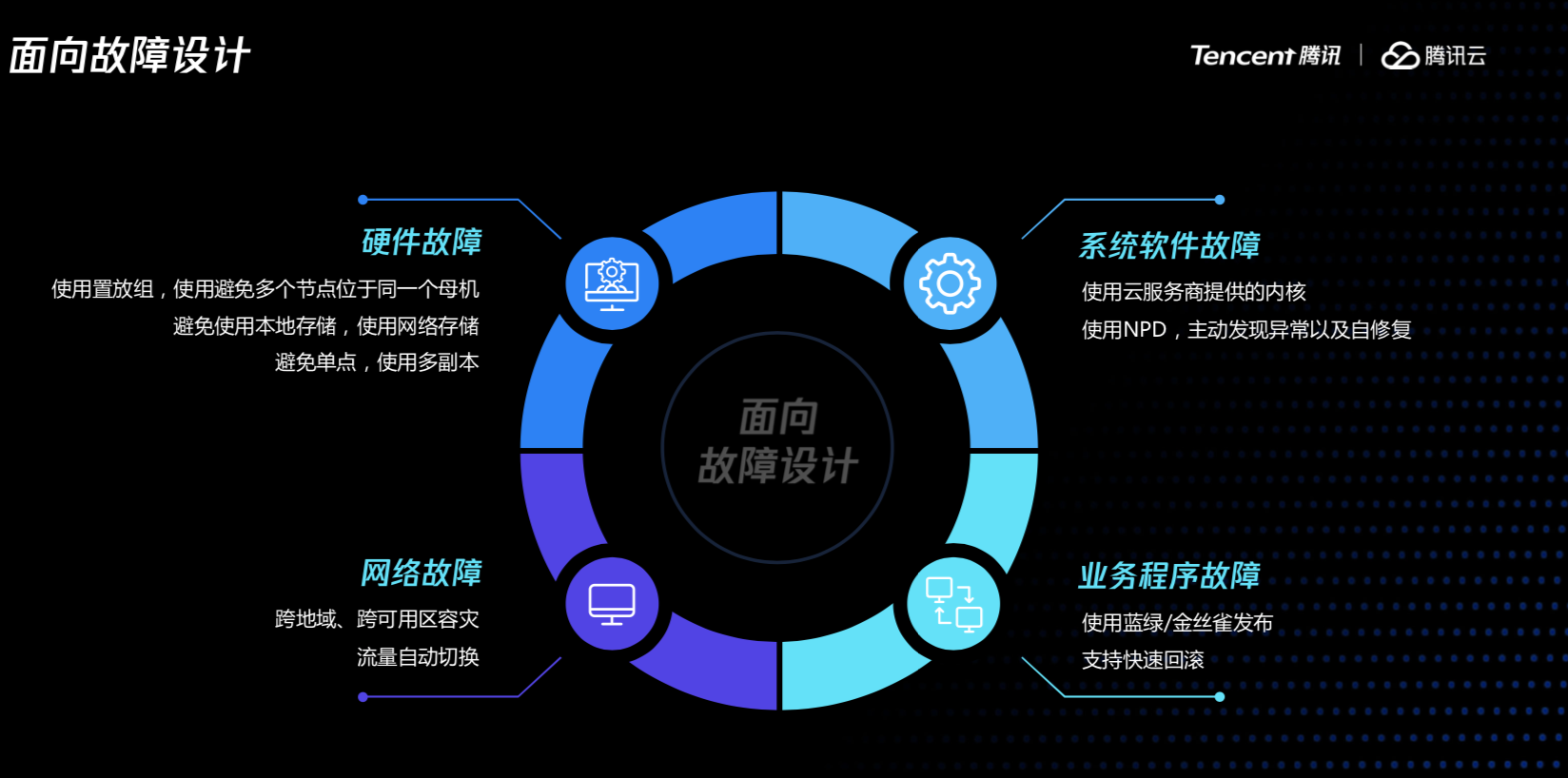
在设计系统的时候,我们要时刻考虑到,故障是不可避免的,我们随时要做好故障的预案。
常见的故障有网络故障、硬件故障、系统故障、业务故障,其中网络故障需要考虑业务部署的时候是不是要做好分区的隔离,比如可以在多个区做容灾和流量切换的机制。对于硬件故障,需要考虑一台母机挂了以后,能够结合云服务商的能力来保证同一个用户下面的子机尽量打散;同时为避免单点故障,一个服务可以多一个副本,比如虚拟机挂了以后,可以做一定的冗余。系统软件建议提供云服务商提供的系统内核,因为他做了很多优化。业务的故障,我们平时在发布过程中不要一次性马上把业务发布上去,要流量一点一点逐步发到线上,同时要做好一个预案,假如新版本问题,能否马上回滚到之前的版本。
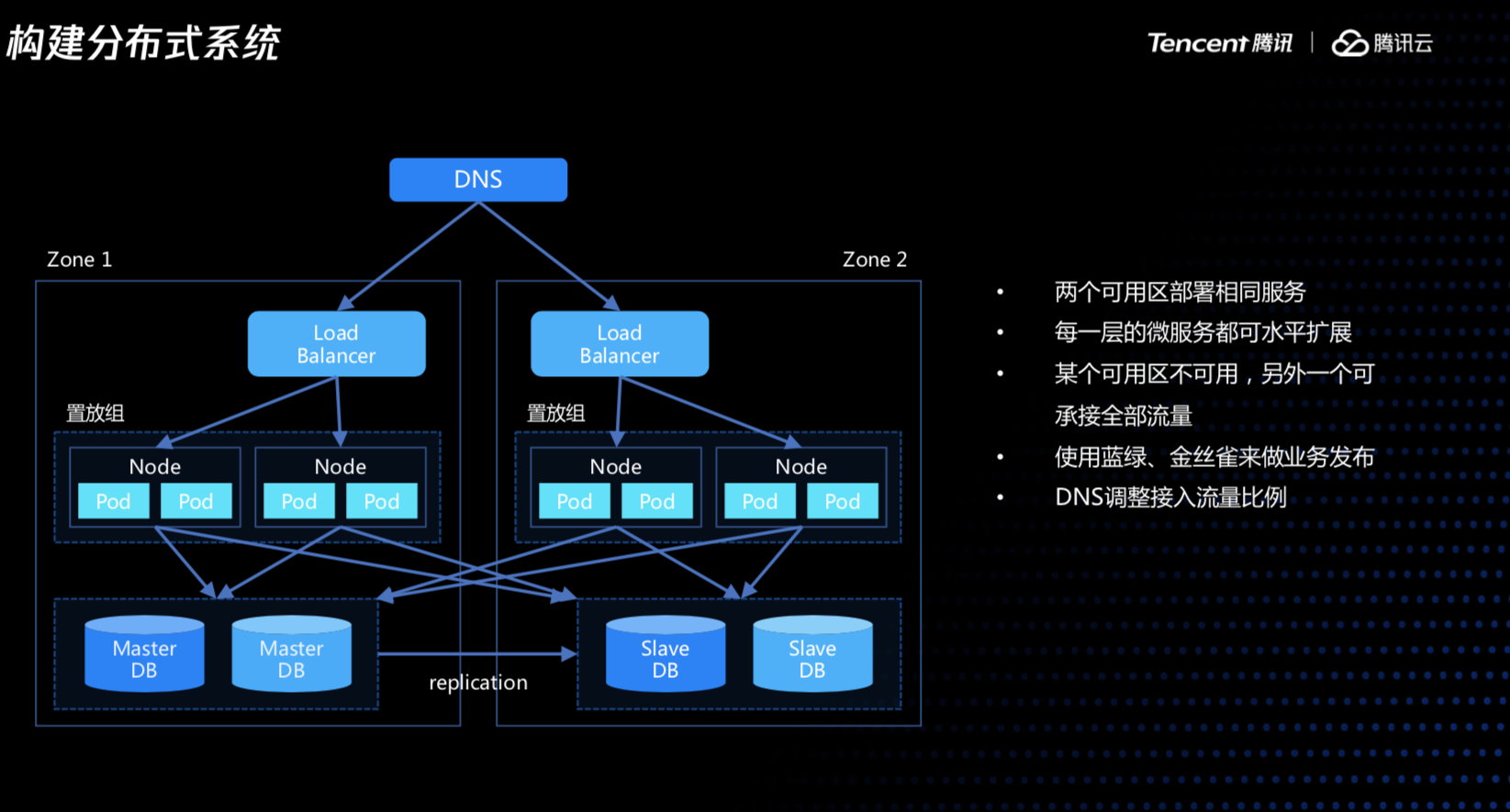
融合了上面的一些的设计理念之后,我们的业务系统首先要做一定的冗余,在多个可用区部署相同的服务,流量可能对外要提供两个不同的入口,在入口处对流量进行分配,当出现导致网络隔离的问题时,可以直接从前端进行流量切换,微服务和数据库也做了拆分,使得每个服务都可以单独做自动伸缩。整体看来,就是一个比较合理的分布式的业务系统。
关注业务而非基础设施。这里给大家讲一个发生在我们这里的一个真实的故事。
有一天一个客户联系到我们说他出十万块钱,让我们帮他们做一个事情,客户在腾讯上部署了一个K8s生产集群需要升级到更高版本,他们发现K8s集群升级时,集群的容器会重启一遍,但是对比腾讯云上提供的TKE集群,从一个版本升级到另外一个版本,容器不需要重启,对业务来说是无感知的、透明的。
接收到这个求助之后,我们跟客户介绍了TKE的技术方案,整个升级过程需要做大量前置校验工作,并且还要针对不同的K8s版本做patch、以及适配不同的Linux发行版等,这些工作在客户的环境里实现起来工作量太大,成本太高。K8s集群的维护是很复杂的,他介于IaaS跟PaaS之间,需要针对Linux内核、K8s内核以及依赖的网络、存储、计算资源做大量的优化,才能保证集群稳定、高效运行。对团队来说,需要招聘业界顶级专家,否则当集群功能异常无法解决,可能造成业务大面积受损。

最后给大家介绍下,其他的业界专家提供的,怎么从个人的环境里面的服务迁移到公有云上,他总结了一些必要的步骤,和上云的一个成熟度模型,同时还有我们怎么样去验证我们的业务系统是不是一个服务云原生架构的系统,他提了很多问题,根据这些问题来检验我们的系统是否符合云原生架构。由于演讲时间已经超过了预定的15分钟,这里就不一条条来过了,感兴趣的同学可以下来参考原始的资料,相信大家会有收获。

我上面讲的大部分也是方法论层面的内容,我们的系统从架构上要达到这些目标,这个过程工作量会很大,很复杂,我这里先抛砖引玉。后面我们的嘉宾会详细介绍他们在容器化实践过程中的经验。谢谢大家!
本文相关 PPT 下载方式,请在腾讯云原生后台回复关键字“云原生”获取。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号