
在腾讯云容器服务 TKE 中利用 HPA 实现业务的弹性伸缩
在 TKE 上利用 HPA 实现业务的弹性伸缩
概述
Kubernetes Pod 水平自动扩缩(Horizontal Pod Autoscaler,以下简称 HPA)可以基于 CPU 利用率、内存利用率和其他自定义的度量指标自动扩缩 Pod 的副本数量,以使得工作负载服务的整体度量水平与用户所设定的目标值匹配。本文将介绍和使用腾讯云容器服务 TKE 的 HPA 功能实现 Pod 自动水平扩缩容。
使用场景
HPA 自动伸缩特性使容器服务具有非常灵活的自适应能力,能够在用户设定内快速扩容多个 Pod 副本来应对业务负载的急剧飙升,也可以在业务负载变小的情况下根据实际情况适当缩容来节省计算资源给其他的服务,整个过程自动化无须人为干预,非常适合服务波动较大,服务数量多且需要频繁扩缩容的业务场景,如:电商服务、线上教育、金融服务等。
原理概述
Pod 水平自动扩缩特性由 Kubernetes API 资源和控制器实现。资源利用指标决定控制器的行为, 控制器会周期性的根据 Pod 资源利用情况调整服务 Pod 的副本数量,以使得工作负载的度量水平与用户所设定的目标值匹配。其扩缩容流程和说明如下:
提示:目前这一功能处于 beta 版本,且 Pod 自动水平扩缩不适用于无法扩缩的对象,比如 DaemonSet 资源。
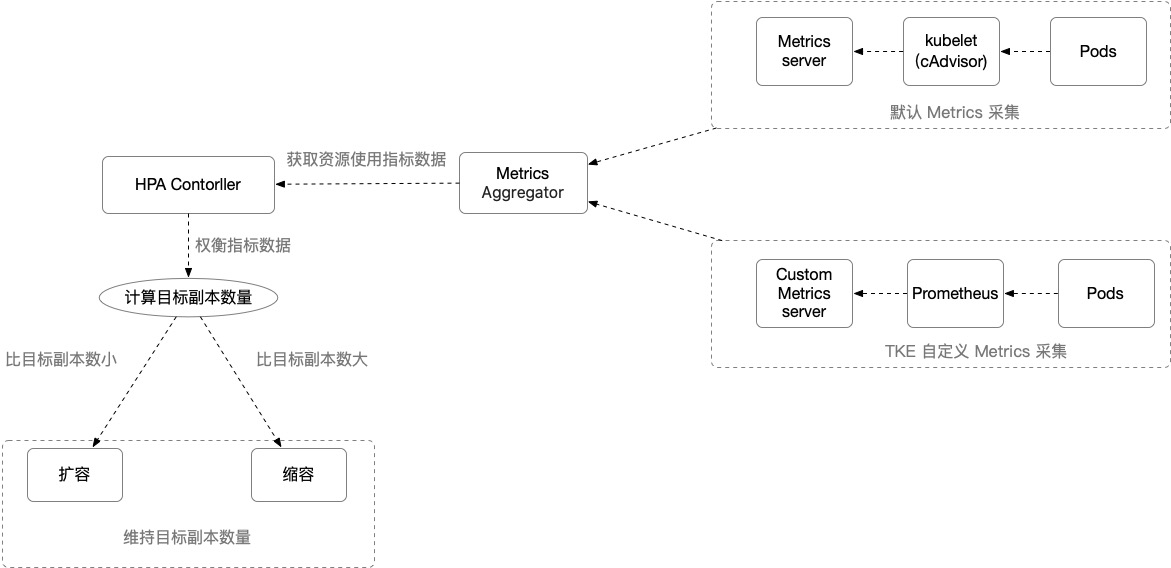
HPA Controller:控制 HPA 扩缩逻辑的控制组件。
Metrics Aggregator:度量指标聚合器。通常情况下,控制器将从一系列的聚合 API(metrics.k8s.io、custom.metrics.k8s.io 和 external.metrics.k8s.io)中获取度量值。 metrics.k8s.io API 通常由 Metrics 服务器提供,社区版可提供基本的 CPU、内存度量类型,相比于社区版,TKE 使用自定义 Metrics Server 采集可支持更广泛的的 HPA 的度量指标触发类型,提供包括 CPU 、内存、硬盘、网络和 GPU 相关指标,了解更多详细内容参阅 TKE 自动伸缩指标说明。
提示:控制器也可以直接从 Heapster 获取指标。但自 Kubernetes 1.11 起,从 Heapster 获取指标特性的方式已废弃。
HPA 计算目标副本数算法:TKE HPA 扩缩容算法请参考 工作原理,更多详细算法请参阅 算法细节。
前提条件
- 已 注册腾讯云账户。
- 已登录 腾讯云容器服务控制台。
- 已创建 TKE 集群。关于创建集群,详情请参见 创建集群。
操作步骤
第 1 步:部署测试工作负载
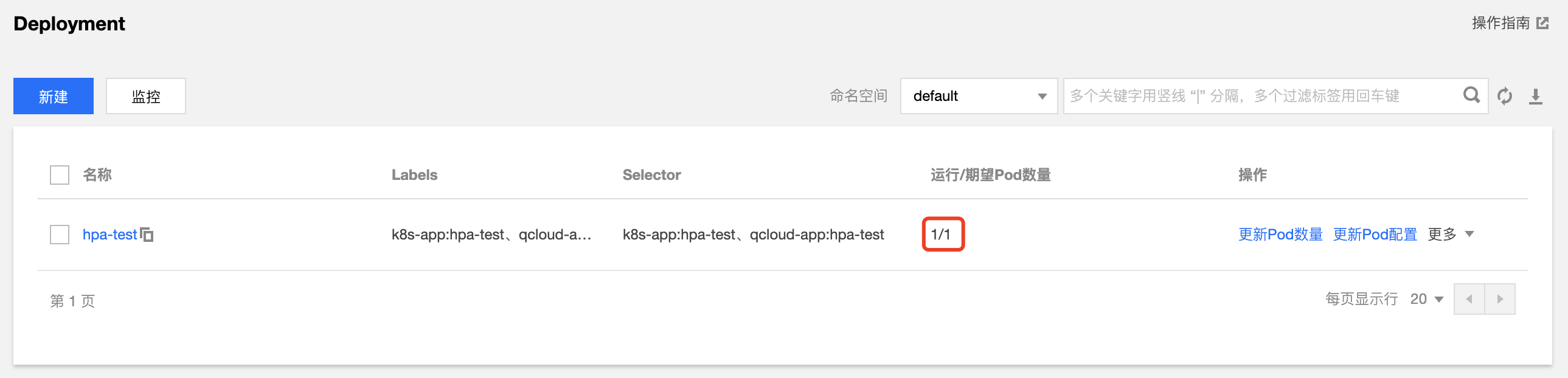
以 Deployment 资源类型的工作负载为例,创建一个单副本数,服务类型为 WEB 服务的 "hpa-test" 工作负载,在 TKE 控制台创建Deployment 类型工作负载方法请参阅 Deployment 管理。本示例创建结果如下图所示:
第 2 步:配置 HPA
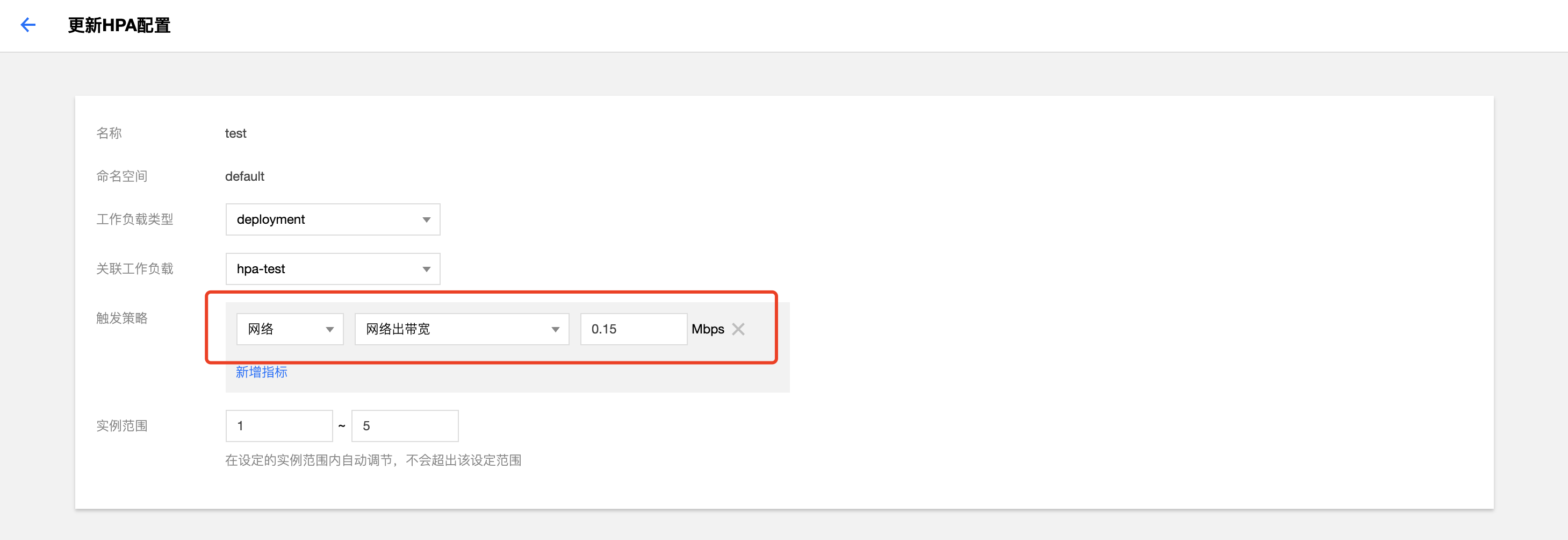
在 TKE 控制台为测试工作负载绑定一个 HPA 配置,关于如何绑定配置 HPA 请参阅 HPA 操作步骤 ,本示例配置当网络出带宽达到0.15Mbps(150Kbps) 时触发扩容的策略。
第 3 步:功能验证
在集群中启动一个临时 Pod 对配置的 HPA 功能进行测试(模拟客户端):
kubectl run -it --image alpine hpa-test --restart=Never --rm /bin/sh
在临时 Pod 中运行下面命令短时间内模拟大量请求访问 "hpa-test" 服务使出口流量带宽增大:
# hpa-test.default.svc.cluster.local 为服务在集群中的域名,当需要停止脚本时按 Ctrl+C 即可
while true; do wget -q -O - hpa-test.default.svc.cluster.local; done
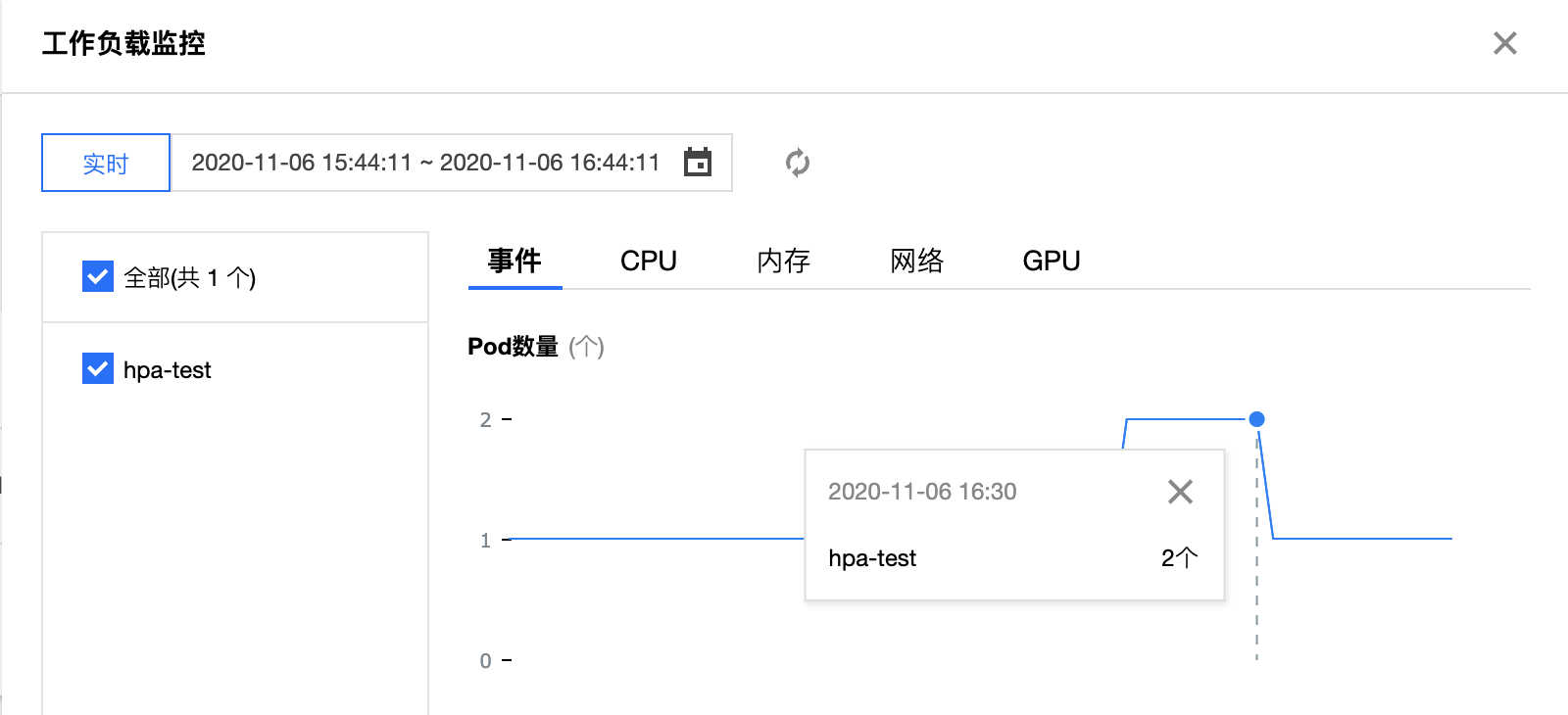
在测试 Pod 中执行模拟请求命令后,通过观察下图中工作负载的 Pod 数量监控可以看到,在 16:21 分时工作负载扩容副本数量至 2 个,由此可推断出已经触发了 HPA 的扩容事件。
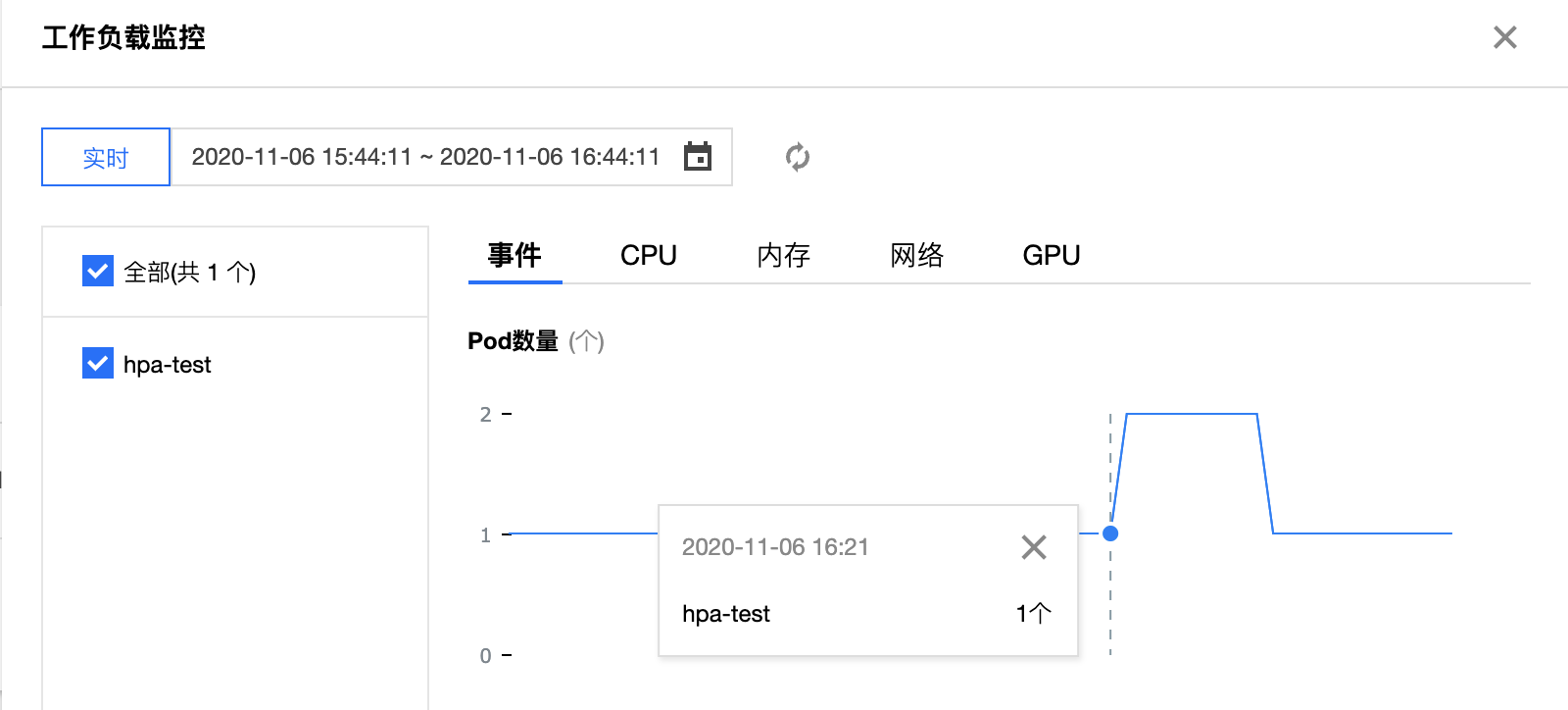
再通过下图的工作负载的网络出口带宽监控可以看出在 16:21 右左时网络出口带宽增至大概 199 Kbps,已经超过 HPA 设定的网络出口带宽目标值,进一步证明此时触发 HPA 扩缩容算法 扩容了一个副本数来满足设定的目标值,故工作负载的副本数量变成了 2 个。
注意:HPA 扩缩容算法 不只以公式计算维度去控制扩缩容逻辑,而会多维度去衡量是否需要扩容或缩容,详情可以参阅 算法细节,所以在实际情况中可能和预期会稍有偏差。
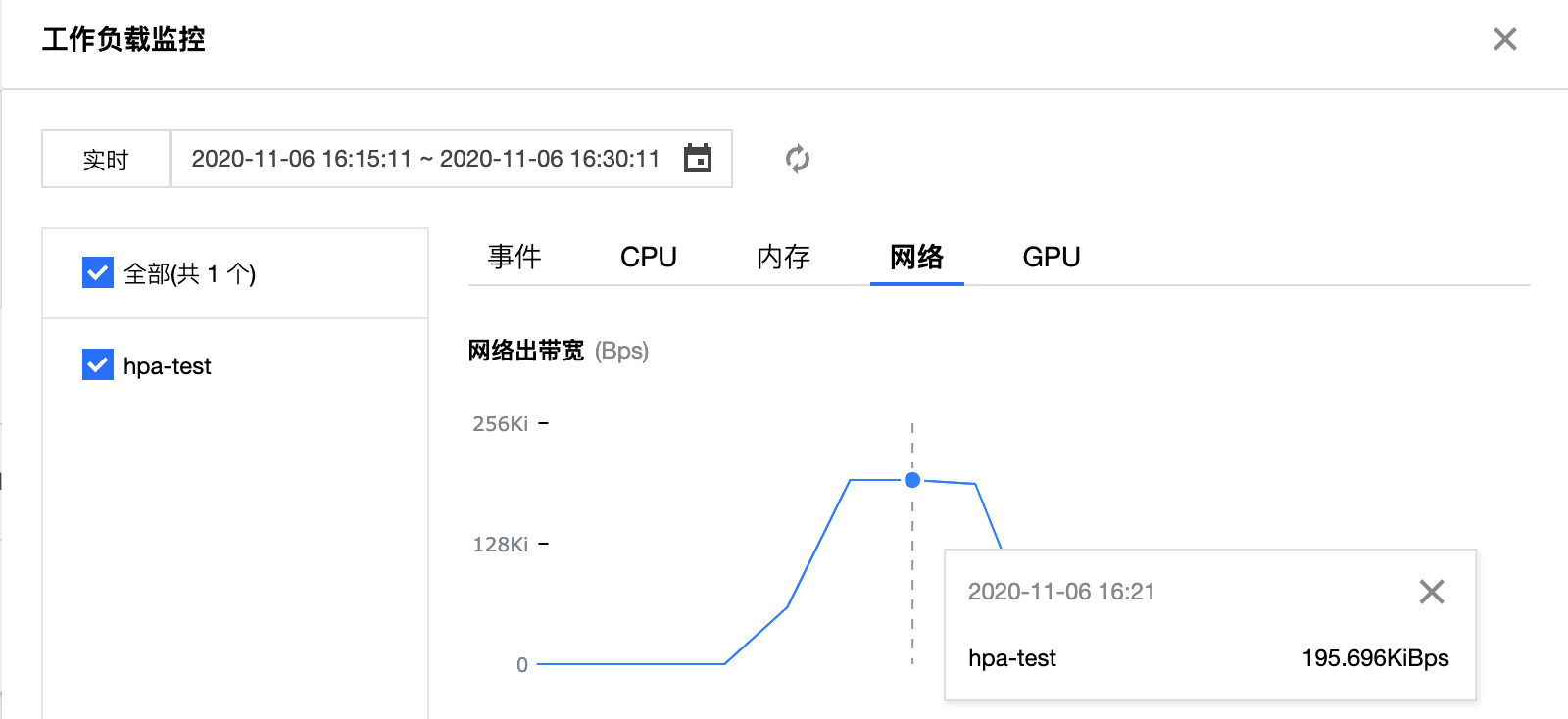
接下来模拟缩容过程,在 16:24 左右手动停止执行模拟请求的命令, 从下图监控看到此时网络出口带宽值下降到扩容前位置,按照 HPA 的逻辑,此时已经满足工作负载缩容的条件。
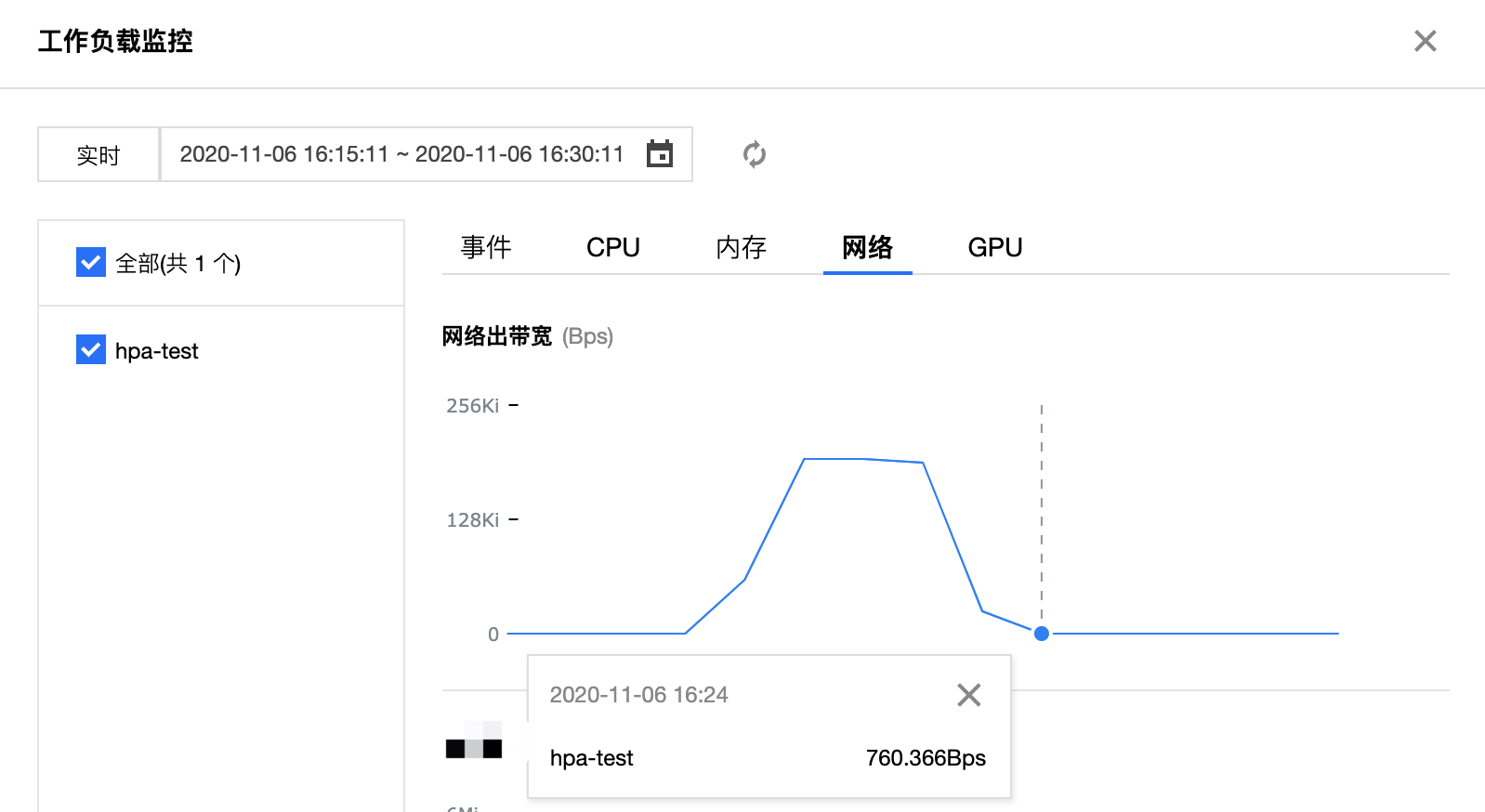
但从下图工作负载的 Pod 数量监控可以看出,工作负载在 16:30 分时才触发了 HPA 的缩容,这是因为触发了 HPA 缩容有默认 5 分钟的容忍时间的算法,以防止度量指标短时间波动导致的频繁的扩缩容,详情请参阅 冷却/延迟支持。从下图可以看出工作负载副本数在停止命令 5 分钟后按照 HPA 扩缩容算法 缩容到了最初设定的 1 个副本数。
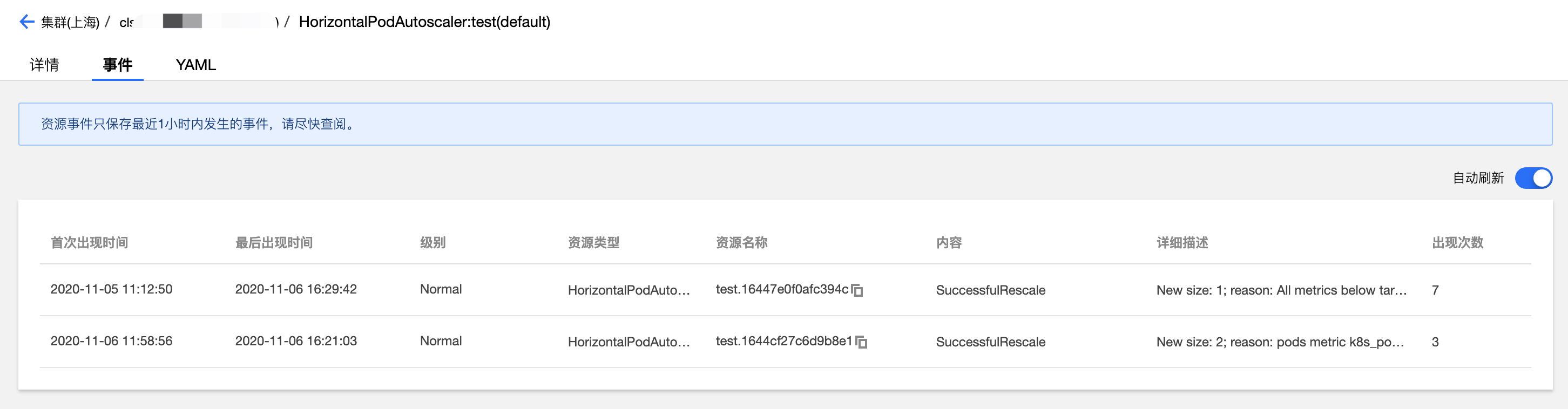
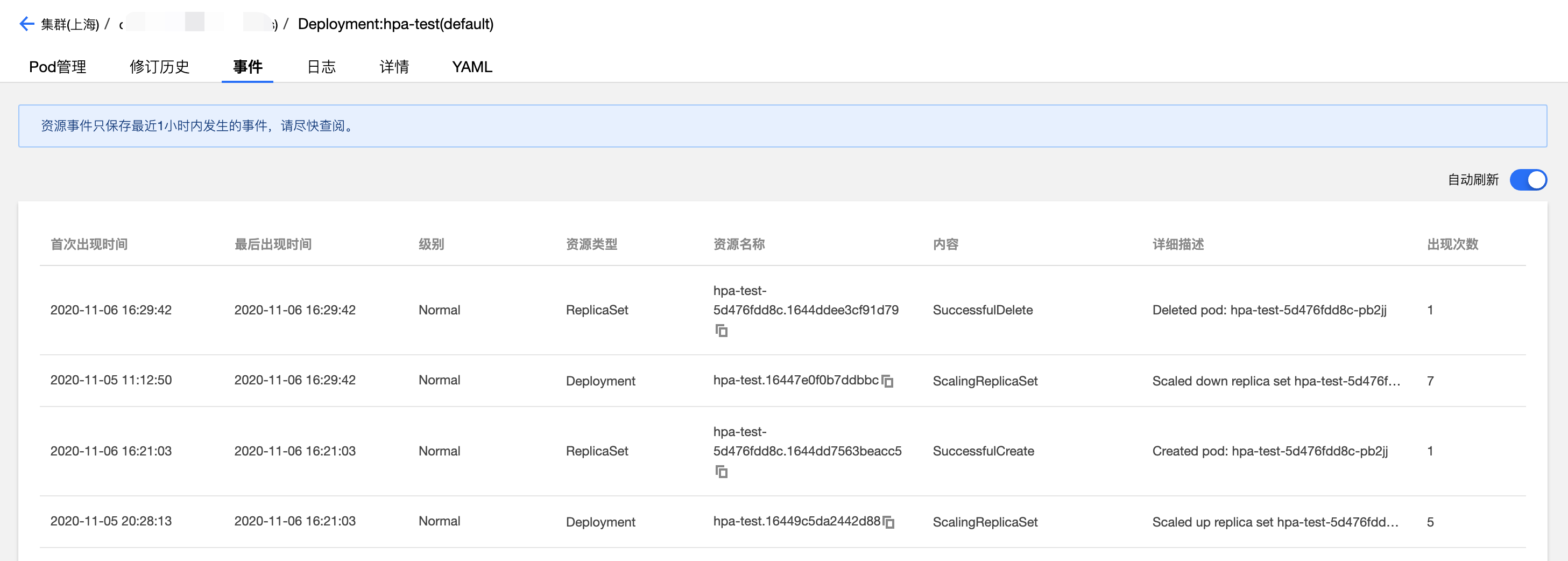
当 TKE 发生 HPA 扩缩容事件时,会在对应的 HPA 实例的事件列表展示,如下图所示。需要注意的是事件通知列表的时间分为 “首次出现时间” 和 “最后出现时间”,“首次出现时间” 表示相同事件第一次出现的时间,”最后出现时间” 为相同事件出现的最新时间,所以从下图事件列表 “最后出现时间” 字段可以看到本示例扩容事件时间点是16:21:03,缩容事件时间是16.29:42,时间点与工作负载监控看到的时间点相吻合。
此外,工作负载事件列表也会记录 HPA 发生时工作负载的增删副本数事件,从下图可以看出工作负载扩缩容时间点与 HPA 事件列表的时间点也是吻合的,增加副本数时间点是 16:21:03,减少副本数时间点是 16: 29:42。
总结
在本示例中主要演示了 TKE 的 HPA 功能, 使用 TKE 自定义的网络出口带宽度量类型作为工作负载 HPA 的扩缩容度量指标,当工作负载实际度量值超过 HPA 配置的度量目标值时, HPA 根据扩容算法计算出合适的副本数实现水平扩容,保证工作负载的度量指标满足预期,保障工作负载健康稳定运行;当实际度量值远低于 HPA 配置的度量目标值时,HPA 会在容忍时间后计算合适的副本数实现水平缩容,适当释放闲置资源,达到提升资源利用率的目的,并且整个过程在 HPA 和工作负载事件列表都会有相应的事件记录,使整个工作负载水平扩缩容全程可追溯。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号