三年之久的 etcd3 数据不一致 bug 分析
问题背景
诡异的 K8S 滚动更新异常
笔者某天收到同事反馈,测试环境中 K8S 集群进行滚动更新发布时未生效。通过 kube-apiserver 查看发现,对应的 Deployment 版本已经是最新版,但是这个最新版本的 Pod 并未创建出来。
针对该现象,我们最开始猜测可能是 kube-controller-manager 的 bug 导致,但是观察 controller-manager 日志并未发现明显异常。第一次调高 controller-manager 的日志等级并进行重启操作之后,似乎由于 controller-manager 并没有 watch 到这个更新事件,我们仍然没有发现问题所在。此时,观察 kube-apiserver 日志,同样也没有出现明显异常。
于是,再次调高日志等级并重启 kube-apiserver,诡异的事情发生了,之前的 Deployment 正常滚动更新了!
etcd 数据不一致 ?
由于从 kube-apiserver 的日志中同样无法提取出能够帮助解决问题的有用信息,起初我们只能猜测可能是 kube-apiserver 的缓存更新异常导致的。正当我们要从这个切入点去解决问题时,该同事反馈了一个更诡异的问题——自己新创建的 Pod,通过 kubectl查询 Pod 列表,突然消失了!纳尼?这是什么骚操作?经过我们多次测试查询发现,通过 kubectl 来 list pod 列表,该 pod 有时候能查到,有时候查不到。那么问题来了,K8s api 的 list 操作是没有缓存的,数据是 kube-apiserver 直接从 etcd 拉取返回给客户端的,难道是 etcd 本身出了问题?
众所周知,etcd 本身是一个强一致性的 KV 存储,在写操作成功的情况下,两次读请求不应该读取到不一样的数据。怀着不信邪的态度,我们通过 etcdctl 直接查询了 etcd 集群状态和集群数据,返回结果显示 3 个节点状态都正常,且 RaftIndex 一致,观察 etcd 的日志也并未发现报错信息,唯一可疑的地方是 3 个节点的 dbsize 差别较大。接着,我们又将 client 访问的 endpoint 指定为不同节点地址来查询每个节点的 key 的数量,结果发现 3 个节点返回的 key 的数量不一致,甚至两个不同节点上 Key 的数量差最大可达到几千!而直接通过 etcdctl 查询刚才创建的 Pod,发现访问某些 endpoint 能够查询到该 pod,而访问其他 endpoint 则查不到。至此,基本可以确定 etcd 集群的节点之间确实存在数据不一致现象。
问题分析和排查过程
遇事不决问Google
强一致性的存储突然数据不一致了,这么严重的问题,想必日志里肯定会有所体现。然而,可能是 etcd 开发者担心日志太多会影响性能的缘故,etcd 的日志打印的比较少,以至于我们排查了 etcd 各个节点的日志,也没有发现有用的报错日志。甚至是在我们调高日志级别之后,仍没有发现异常信息。
作为一个21世纪的程序员,遇到这种诡异且暂时没头绪的问题,第一反应当然是先 Google 一下啦,毕竟不会 StackOverFlow 的程序员不是好运维!Google 输入“etcd data inconsistent” 搜索发现,并不是只有我们遇到过该问题,之前也有其他人向 etcd 社区反馈过类似问题,只是苦于没有提供稳定的复现方式,最后都不了了之。如 issue:
https://github.com/etcd-io/etcd/issues/9630
https://github.com/etcd-io/etcd/issues/10407
https://github.com/etcd-io/etcd/issues/10594
https://github.com/etcd-io/etcd/issues/11643
由于这个问题比较严重,会影响到数据的一致性,而我们生产环境中当前使用了数百套 etcd 集群,为了避免出现类似问题,我们决定深入定位一番。
etcd 工作原理和术语简介
在开始之前,为方便读者理解,这里先简单介绍下 etcd 的常用术语和基本读写原理。
术语表:
etcd 是一个强一致性的分布式 KV 存储,所谓强一致性,简单来说就是一个写操作成功后,从任何一个节点读出来的数据都是最新值,而不会出现写数据成功后读不出来或者读到旧数据的情况。etcd 通过 raft 协议来实现 leader 选举、配置变更以及保证数据读写的一致性。下面简单介绍下 etcd 的读写流程:
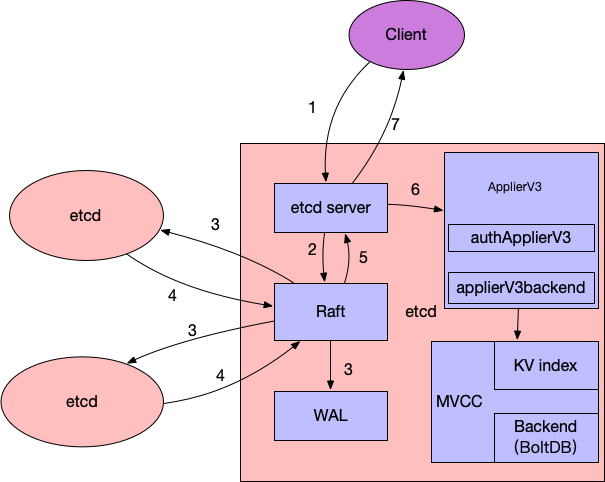
写数据流程(以 leader 节点为例,见上图):
- etcd 任一节点的 etcd server 模块收到 Client 写请求(如果是 follower 节点,会先通过 Raft 模块将请求转发至 leader 节点处理)。
- etcd server 将请求封装为 Raft 请求,然后提交给 Raft 模块处理。
- leader 通过 Raft 协议与集群中 follower 节点进行交互,将消息复制到follower 节点,于此同时,并行将日志持久化到 WAL。
- follower 节点对该请求进行响应,回复自己是否同意该请求。
- 当集群中超过半数节点((n/2)+1 members )同意接收这条日志数据时,表示该请求可以被Commit,Raft 模块通知 etcd server 该日志数据已经 Commit,可以进行 Apply。
- 各个节点的 etcd server 的 applierV3 模块异步进行 Apply 操作,并通过 MVCC 模块写入后端存储 BoltDB。
- 当 client 所连接的节点数据 apply 成功后,会返回给客户端 apply 的结果。
读数据流程:
- etcd 任一节点的 etcd server 模块收到客户端读请求(Range 请求)
- 判断读请求类型,如果是串行化读(serializable)则直接进入 Apply 流程
- 如果是线性一致性读(linearizable),则进入 Raft 模块
- Raft 模块向 leader 发出 ReadIndex 请求,获取当前集群已经提交的最新数据 Index
- 等待本地 AppliedIndex 大于或等于 ReadIndex 获取的 CommittedIndex 时,进入 Apply 流程
- Apply 流程:通过 Key 名从 KV Index 模块获取 Key 最新的 Revision,再通过 Revision 从 BoltDB 获取对应的 Key 和 Value。
初步验证
通常集群正常运行情况下,如果没有外部变更的话,一般不会出现这么严重的问题。我们查询故障 etcd 集群近几天的发布记录时发现,故障前一天对该集群进行的一次发布中,由于之前 dbsize 配置不合理,导致 db 被写满,集群无法写入新的数据,为此运维人员更新了集群 dbsize 和 compaction 相关配置,并重启了 etcd。重启后,运维同学继续对 etcd 手动执行了 compact 和 defrag 操作,来压缩 db 空间。
通过上述场景,我们可以初步判断出以下几个可疑的触发条件:
- dbsize 满
- dbsize 和 compaction 配置更新
- compaction 操作和 defrag 操作
- 重启 etcd
出了问题肯定要能够复现才更有利于解决问题,正所谓能够复现的 bug 就不叫 bug。复现问题之前,我们通过分析 etcd 社区之前的相关 issue 发现,触发该 bug 的共同条件都包含执行过 compaction 和 defrag 操作,同时重启过 etcd 节点。因此,我们计划首先尝试同时模拟这几个操作,观察是否能够在新的环境中复现。为此我们新建了一个集群,然后通过编写脚本向集群中不停的写入和删除数据,直到 dbsize 达到一定程度后,对节点依次进行配置更新和重启,并触发 compaction 和 defrag 操作。然而经过多次尝试,我们并没有复现出类似于上述数据不一致的场景。
抽丝剥茧,初现端倪
紧接着,在之后的测试中无意发现,client 指定不同的 endpoint 写数据,能够查到数据的节点也不同。比如,endpoint 指定为 node1 进行写数据,3个节点都可以查到数据;endpoint 指定为 node2 进行写数据,node2 和 node3 可以查到;endpoint 指定为 node3 写数据,只有 node3 自己能够查到。具体情况如下表:
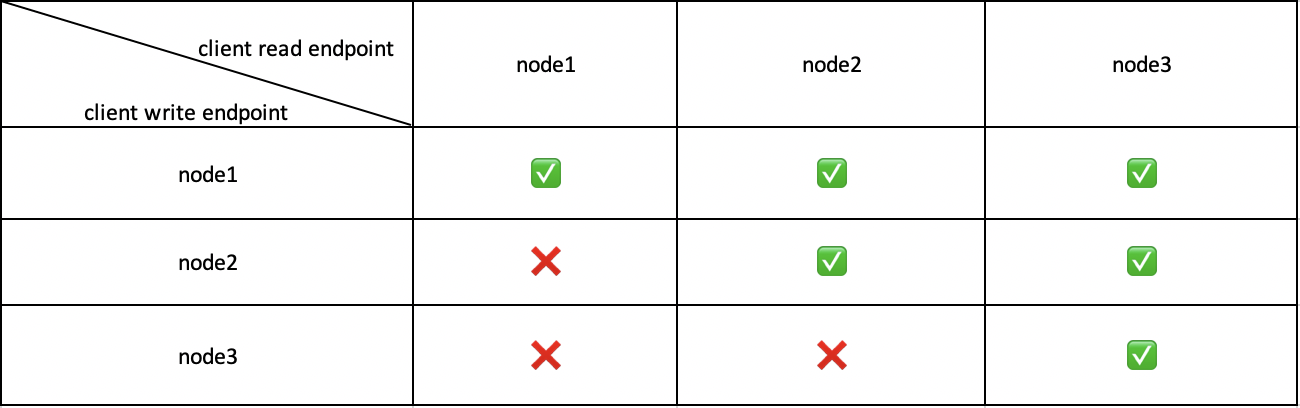
于是我们做出了初步的猜测,有以下几种可能:
- 集群可能分裂了,leader 未将消息发送给 follower 节点。
- leader 给 follower 节点发送了消息,但是 log 异常,没有对应的 command 。
- leader 给 follower 节点发送了消息,有对应的 command,但是 apply 异常,操作还未到 KV Index 和 boltdb 就异常了。
- leader 给 follower 节点发送了消息, 有对应的 command,但是 apply 异常,KV Index 出现了问题。
- leader 给 follower 节点发送了消息, 有对应的 command,但是 apply 异常,boltdb 出现了问题。
为了验证我们的猜测,我们进行了一系列测试来缩小问题范围:
首先,我们通过 endpoint status 查看集群信息,发现 3 个节点的 clusterId,leader,raftTerm,raftIndex 信息均一致,而 dbSize 大小和 revision 信息不一致。clusterId 和 leader 一致,基本排除了集群分裂的猜测,而 raftTerm 和 raftIndex 一致,说明 leader 是有向 follower 同步消息的,也进一步排除了第一个猜测,但是 WAL落盘有没有异常还不确定。dbSize 和 revision 不一致则进一步说明了 3 个节点数据已经发生不一致了。
其次,由于 etcd 本身提供了一些 dump 工具,例如 etcd-dump-log 和 etcd-dump-db。我们可以像下图一样,使用 etcd-dump-log dump 出指定 WAL 文件的内容,使用 etcd-dump-db dump 出 db 文件的数据,方便对 WAL 和 db 数据进行分析。


于是,我们向 node3 写了一条便于区分的数据,然后通过 etcd-dump-log 来分析 3 个节点的 WAL,按照刚才的测试,endpoint 指定为 node3 写入的数据,通过其他两个节点应该查不到的。但是我们发现 3 个节点都收到了 WAL log,也就是说 WAL 并没有丢,因此排除了第二个猜测。
接下来我们 dump 了 db 的数据进行分析,发现 endpoint 指定为 node3 写入的数据,在其他两个节点的 db 文件里找不到,也就是说数据确实没有落到 db,而不是写进去了查不出来。
既然 WAL 里有而 db 里没有,因此很大可能是 apply 流程异常了,数据可能在 apply 时被丢弃了。
由于现有日志无法提供更有效的信息,我们打算在 etcd 里新加一些日志来更好地帮助我们定位问题。etcd 在做 apply 操作时,trace 日志会打印超过每个超过 100ms 的请求,我们首先把 100ms 这个阈值调低,调整到 1ns,这样每个 apply 的请求都能够记录下来,可以更好的帮助我们定位问题。
编译好新版本之后,我们替换了其中一个 etcd 节点,然后向不同 node 发起写请求测试。果然,我们发现了一条不同寻常的错误日志:"error":"auth:revision in header is old",因此我们断定问题很可能是因为——发出这条错误日志的节点,对应的 key 刚好没有写进去。
搜索代码后,我们发现 etcd 在进行 apply 操作时,如果开启了鉴权,在鉴权时会判断 raft 请求 header 中的 AuthRevision,如果请求中的 AuthRevision 小于当前 node 的AuthRevision,则会认为 AuthRevision 太老而导致 Apply 失败。
func (as *authStore) isOpPermitted(userName string, revision uint64, key, rangeEnd []byte, permTyp authpb.Permission_Type) error { // ... if revision < as.Revision() { return ErrAuthOldRevision } // ...}
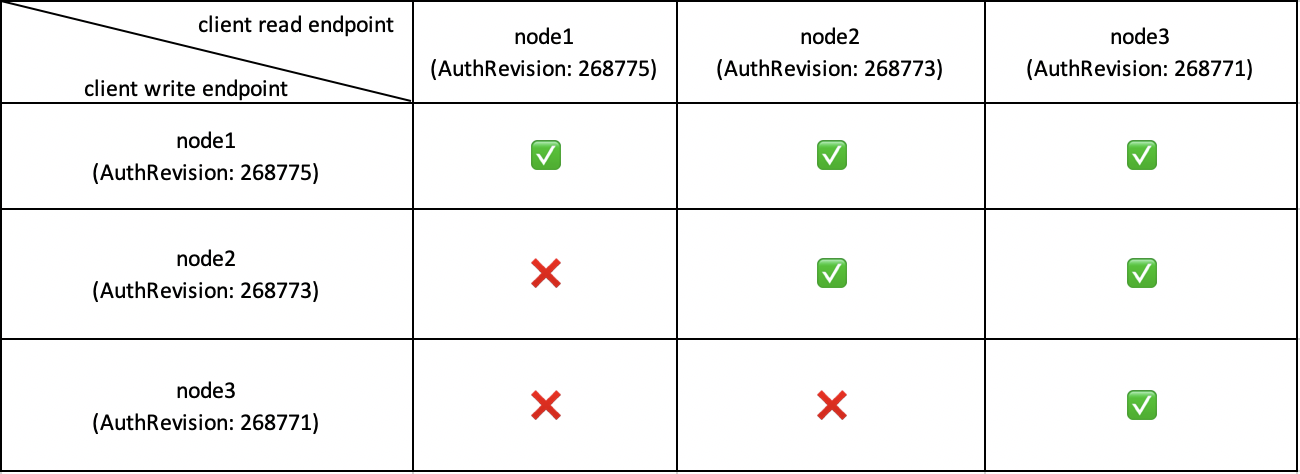
这样看来,很可能是不同节点之间的 AuthRevision 不一致了,AuthRevision 是 etcd 启动时直接从 db 读取的,每次变更后也会及时的写入 db,于是我们简单修改了下 etcd-dump-db工具,将每个节点 db 内存储的 AuthRevision 解码出来对比了下,发现 3 个节点的 AuthRevision 确实不一致,node1 的 AuthRevision 最高,node3 的 AuthRevision 最低,这正好能够解释之前的现象,endpoint 指定为 node1 写入的数据,3 个节点都能查到,指定为 node3 写入的数据,只有 node3 能够查到,因为 AuthRevision 较低的节点发起的 Raft 请求,会被 AuthRevision 较高的节点在 Apply 的过程中丢弃掉(如下表)。
源码之前,了无秘密?
目前为止我们已经可以明确,新写入的数据通过访问某些 endpoint 查不出来的原因是由于 AuthRevision 不一致。但是,数据最开始发生不一致问题是否是由 AuthRevision 造成,还暂时不能断定。为什么这么说呢?因为 AuthRevision 很可能也是受害者,比如 AuthRevision 和数据的不一致都是由同一个原因导致的,只不过是 AuthRevision 的不一致放大了数据不一致的问题。但是,为更进一步接近真相,我们先假设 AuthRevision 就是导致数据不一致的罪魁祸首,进而找出导致 AuthRevision 不一致的真实原因。
原因到底如何去找呢?正所谓,源码之前了无秘密,我们首先想到了分析代码。于是,我们走读了一遍 Auth 操作相关的代码(如下),发现只有在进行权限相关的写操作(如增删用户/角色,为角色授权等操作)时,AuthRevision 才会增加。AuthRevision 增加后,会和写权限操作一起,写入 backend 缓存,当写操作超过一定阈值(默认 10000 条记录)或者每隔100ms(默认值),会执行刷盘操作写入 db。由于 AuthRevision 的持久化和创建用户等操作的持久化放在一个事务内,因此基本不会存在创建用户成功了,而 AuthRevision 没有正常增加的情况。
func (as *authStore) UserAdd(r *pb.AuthUserAddRequest) (*pb.AuthUserAddResponse, error) { // ... tx := as.be.BatchTx() tx.Lock() defer tx.Unlock() // Unlock时满足条件会触发commit操作 // ... putUser(tx, newUser) as.commitRevision(tx) return &pb.AuthUserAddResponse{}, nil}func (t *batchTxBuffered) Unlock() { if t.pending != 0 { t.backend.readTx.Lock() // blocks txReadBuffer for writing. t.buf.writeback(&t.backend.readTx.buf) t.backend.readTx.Unlock() if t.pending >= t.backend.batchLimit { t.commit(false) } } t.batchTx.Unlock()}
那么,既然 3 个节点的 AuthRevision 不一致,会不会是因为某些节点写权限相关的操作丢失了,从而没有写入 db ?如果该猜测成立,3 个节点的 db 里 authUser 和 authRole 的 bucket 内容应该有所不同才对。于是为进一步验证,我们继续修改了下 etcd-dump-db 这个工具,加入了对比不同 db 文件 bucket 内容的功能。遗憾的是,通过对比发现,3 个节点之间的 authUser 和 authRole bucket 的内容并没有什么不同。
既然节点写权限相关的操作没有丢,那会不会是命令重复执行了呢?查看异常时间段内日志时发现,其中包含了较多的 auth 操作;进一步分别比对 3 个节点的 auth 操作相关的日志又发现,部分节点日志较多,而部分节点日志较少,看起来像是存在命令重复执行现象。由于日志压缩,虽然暂时还不能确定是重复执行还是操作丢失,但是这些信息能够为我们后续的排查带来很大启发。
我们继续观察发现,不同节点之间的 AuthRevison虽有差异,但是差异较小,而且差异值在我们压测期间没有变过。既然不同节点之间的 AuthRevision 差异值没有进一步放大,那么通过新增的日志基本上也看不出什么问题,因为不一致现象的出现很可能是在过去的某个时间点瞬时造成的。这就造成我们如果想要发现问题根因,还是要能够复现 AuthRevison 不一致或者数据不一致问题才行,并且要能够抓到复现瞬间的现场。
问题似乎又回到了原点,但好在我们目前已经排除了很多干扰信息,将目标聚焦在了 auth 操作上。
混沌工程,成功复现
鉴于之前多次手动模拟各种场景都没能成功复现,我们打算搞一套自动化的压测方案来复现这个问题,方案制定时主要考虑的点有以下几个:
-
如何增大复现的概率?
根据之前的排查结果,很有可能是 auth 操作导致的数据不一致,因此我们实现了一个 monkey 脚本,每隔一段时间,会向集群写入随机的用户、角色,并向角色授权,同时进行写数据操作,以及随机的重启集群中的节点,详细记录每次一操作的时间点和执行日志。
-
怎样保证在复现的情况下,能够尽可能的定位到问题的根因?
根据之前的分析得出,问题根因大概率是 apply 过程中出了问题,于是我们在 apply 的流程里加入了详细的日志,并打印了每次 apply 操作committedIndex、appliedIndex、consistentIndex 等信息。
-
如果复现成功,如何能够在第一时间发现?
由于日志量太大,只有第一时间发现问题,才能够更精确的缩小问题范围,才能更利于我们定位问题。于是我们实现了一个简单的 metric-server,每隔一分钟拉取各个节点的 key 数量,并进行对比,将差异值暴露为 metric,通过 prometheus 进行拉取,并用 grafana 进行展示,一旦差异值超过一定阈值(写入数据量大的情况下,就算并发统计各个节点的 key 数量,也可能会有少量的差异,所以这里有一个容忍误差),则立刻通过统一告警平台向我们推送告警,以便于及时发现。
方案搞好后,我们新建了一套 etcd 集群,部署了我们的压测方案,打算进行长期观察。结果第二天中午,我们就收到了微信告警——集群中存在数据不一致现象。
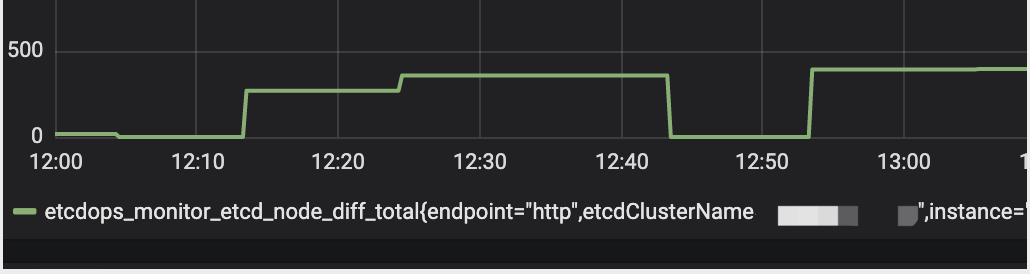
于是,我们立刻登录压测机器进行分析,首先停掉了压测脚本,然后查看了集群中各个节点的 AuthRevision,发现 3 个节点的 AuthRevision 果然不一样!根据 grafana 监控面板上的监控数据,我们将数据不一致出现的时间范围缩小到了 10 分钟内,然后重点分析了下这 10 分钟的日志,发现在某个节点重启后,consistentIndex 的值比重启前要小。然而 etcd 的所有 apply 操作,幂等性都依赖 consistentIndex 来保证,当进行 apply 操作时,会判断当前要 apply 的 Entry 的 Index 是否大于 consistentIndex,如果 Index 大于 consistentIndex,则会将 consistentIndex 设为 Index,并允许该条记录被 apply。否则,则认为该请求被重复执行了,不会进行实际的 apply 操作。
// applyEntryNormal apples an EntryNormal type raftpb request to the EtcdServerfunc (s *EtcdServer) applyEntryNormal(e *raftpb.Entry) { shouldApplyV3 := false if e.Index > s.consistIndex.ConsistentIndex() { // set the consistent index of current executing entry s.consistIndex.setConsistentIndex(e.Index) shouldApplyV3 = true } // ... // do not re-apply applied entries. if !shouldApplyV3 { return } // ...}
也就是说,由于 consistentIndex 的减小,etcd 本身依赖它的幂等操作将变得不再幂等,导致权限相关的操作在 etcd 重启后被重复 apply 了,即一共apply 了两次!
问题原理分析
为何 consistentIndex 会减小?走读了 consistentIndex 相关代码后,我们终于发现了问题的根因:consistentIndex 本身的持久化,依赖于 mvcc 的写数据操作;通过 mvcc 写入数据时,会调用 saveIndex 来持久化 consistentIndex 到 backend,而 auth 相关的操作,是直接读写的 backend,并没有经过 mvcc。这就导致,如果做了权限相关的写操作,并且之后没有通过 mvcc 写入数据,那么这期间 consistentIndex 将不会被持久化,如果这时候重启了 etcd,就会造成权限相关的写操作被 apply 两次,带来的副作用可能会导致 AuthRevision 重复增加,从而直接造成不同节点的 AuthRevision 不一致,而 AuthRevision 不一致又会造成数据不一致。
func putUser(lg *zap.Logger, tx backend.BatchTx, user *authpb.User) { b, err := user.Marshal() tx.UnsafePut(authUsersBucketName, user.Name, b) // 直接写入Backend,未经过MVCC,此时不会持久化consistentIndex}func (tw *storeTxnWrite) End() { // only update index if the txn modifies the mvcc state. if len(tw.changes) != 0 { tw.s.saveIndex(tw.tx) // 当通过MVCC写数据时,会触发consistentIndex持久化 tw.s.revMu.Lock() tw.s.currentRev++ } tw.tx.Unlock() if len(tw.changes) != 0 { tw.s.revMu.Unlock() } tw.s.mu.RUnlock()}
再回过头来,为什么数据不一致了还可以读出来,而且读出来的数据还可能不一样?etcd 不是使用了 raft 算法吗,难道不能够保证强一致性吗?其实这和 etcd 本身的读操作实现有关。
而影响 ReadIndex 操作的,一个是 leader 节点的 CommittedIndex,一个是当前节点的 AppliedIndex,etcd 在 apply 过程中,无论 apply 是否成功,都会更新 AppliedIndex,这就造成,虽然当前节点 apply 失败了,但读操作在判断的时候,并不会感知到这个失败,从而导致某些节点可能读不出来数据;而且 etcd 支持多版本并发控制,同一个 key 可以存在多个版本的数据,apply 失败可能只是更新某个版本的数据失败,这就造成不同节点之间最新的数据版本不一致,导致读出不一样的数据。
影响范围
该问题从 2016 年引入,所有开启鉴权的 etcd3 集群都会受到影响,在特定场景下,会导致 etcd 集群多个节点之间的数据不一致,并且 etcd 对外表现还可以正常读写,日志无明显报错。
触发条件
-
使用的为 etcd3 集群,并且开启了鉴权。
-
etcd 集群中节点发生重启。
-
节点重启之前,有 grant-permission 操作(或短时间内对同一个权限操作连续多次增删),且操作之后重启之前无其他数据写入。
-
通过非重启节点向集群发起写数据请求。
修复方案
了解了问题的根因,修复方案就比较明确了,我们只需要在 auth 操作调用 commitRevision 后,触发 consistentIndex 的持久化操作,就能够保证 etcd 在重启的时候 consistentIndex 的本身的正确性,从而保证 auth 操作的幂等性。具体的修复方式我们已经向 etcd 社区提交了 PR #11652,目前这个特性已经 backport 到 3.4,3.3 等版本,将会在最近一个 release 更新。
那么如果数据已经不一致了怎么办,有办法恢复吗?在 etcd 进程没有频繁重启的情况下,可以先找到 authRevision 最小的节点,它的数据应该是最全的,然后利用 etcd 的 move-leader 命令,将 leader 转移到这个节点,再依次将其他节点移出集群,备份并删除数据目录,然后将节点重新加进来,此时它会从 leader 同步一份最新的数据,这样就可以使集群其他节点的数据都和 leader 保持一致,即最大可能地不丢数据。
升级建议
需要注意的是,升级有风险,新版本虽然解决了这个问题,但由于升级过程中需要重启 etcd,这个重启过程仍可能触发这个 bug。因此升级修复版本前建议停止写权限相关操作,并且手动触发一次写数据操作之后再重启节点,避免因为升级造成问题。
另外,不建议直接跨大版本升级,例如从 etcd3.2 → etcd3.3。大版本升级有一定的风险,需谨慎测试评估,我们之前发现过由 lease 和 auth 引起的另一个不一致问题,具体可见 issue #11689,以及相关 PR #11691。
问题总结
导致该问题的直接原因,是由于 consistentIndex 在进行权限相关操作时未持久化,从而导致 auth 相关的操作不幂等,造成了数据的不一致。
而造成 auth 模块未持久化 consistentIndex 的一个因素,是因为 consistentIndex 目前是在 mvcc 模块实现的,并未对外暴露持久化接口,只能通过间接的方式来调用,很容易漏掉。为了优化这个问题,我们重构了 consistentIndex 相关操作,将它独立为一个单独的模块,其他依赖它的模块可以直接调用,一定程度上可以避免将来再出现类似问题,具体见 PR #11699。
另一方面,etcd 的 apply 操作本身是个异步流程,而且失败之后没有打印任何错误日志,很大程度上增加了排障的难度,因此我们后边也向社区提交了相关 PR #11670,来优化 apply 失败时的日志打印,便于定位问题。
造成问题定位困难的另一个原因,是 auth revision 目前没有对外暴露 metric 或者 api,每次查询只能通过 [etcd-dump-db 工具来直接从 db 获取,为方便 debug,我们也增加了相关的
metric](https://github.com/etcd-io/etcd/pull/11652/commits/f14d2a087f7b0fd6f7980b95b5e0b945109c95f3) 和 status api,增强了 auth revision 的可观测性和可测试性。
参考资料
- etcd 源码:https://github.com/etcd-io/etcdetcd
- 存储实现:https://www.codedump.info/post/20181125-etcd-server/高可用分布存储
- etcd 的实现原理:https://draveness.me/etcd-introduction/etcd
- raft 设计与实现:https://zhuanlan.zhihu.com/p/51063866,https://zhuanlan.zhihu.com/p/51065416
致谢
感谢在 PR 提交过程中,etcd 社区 jingyih,mitake 的热心帮助和建议!
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号