容器网络防火墙状态异常导致丢包排查记录
0.导语
K8s容器网络涉及诸多内核子系统,IPVS,Iptable,3层路由,2层转发,TCP/IP协议栈,这些复杂的内核子系统在特定场景下可能会遇到设计者最初也想不到的问题。
本文分享了iptable防火墙状态异常导致丢包的排查记录,这个排查过程非常曲折,最后使用了在现在的作者看来非常落伍的工具:systemtap,才得以排查成功。其实依作者现有的经验,此问题现在仅需一条命令即可找到原因,这条命令就是作者之前分享过文章使用 ebpf 深入分析容器网络 dup 包问题中提到的skbtracker。时隔7个月,这个工具已经非常强大,能解决日常网络中的90%的网络问题。
此文其实已于2019年7月在腾讯内部进行发表,时隔一年,再次翻出来阅读仍然有颇多收获,因此把它分享出来给其他同行一起学习。此外,本篇文章也将作为开篇,后续陆续分享作者近期使用ebpf工具排查各种内核疑难杂症的过程及经验。
1. 问题描述
腾讯内部某业务在容器场景上遇到了一个比较诡异的网络问题,在容器内使用GIT,SVN工具从内部代码仓库拉取代码偶发性卡顿失败,而在容器所在的Node节点使用同样版本的GIT,SVN工具却没有问题。用诡异这个词,是因为这个问题的分析持续时间比较久,经历了多个同学之手,最后都没有揪出问题根源。有挑战的问题排查对于本人来说是相当有吸引力的,于是在手头没有比较紧急任务的情况下,便开始了有趣的debug。
从客户描述看,问题复现概率极大,在Pod里面拉取10次GIT仓库,必然有一次出现卡死,对于必现的问题一般都不是问题,找到复现方法就找到了解决方法。从客户及其他同事反馈,卡死的时候,GIT Server不再继续往Client端发送数据,并且没有任何重传。
1.1 网络拓扑
业务方采用的是TKE单网卡多IP容器网络方案,node自身使用主网卡eth0,绑定一个ip,另一个弹性网卡eth1绑定多个ip地址,通过路由把这些地址与容器绑定,如图1-1.
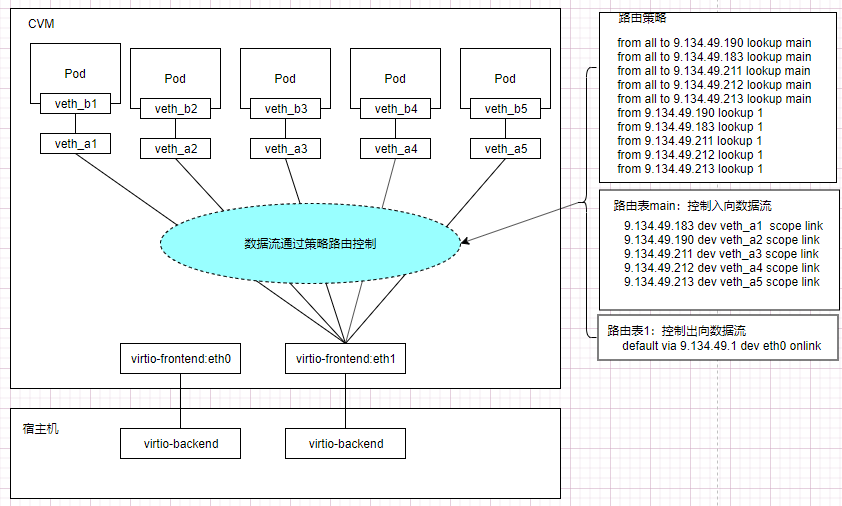
图 1-1 TKE单网卡多IP容器网络
1.2 复现方法

1.3 抓包文件分析
在如下三个网口eth1,veth_a1,veth_b1分别循环抓包,Server端持续向Client发送大包,卡顿发生时,Server端停止往Client发送数据包,没有任何重传报文。
2. 排查过程
分析环境差异:node和Pod环境差异
- Node内存比Pod多,而Node和Pod的TCP 接收缓存大小配置一致,此处差异可能导致内存分配失败。
- 数据包进出Pod比Node多了一次路由判断,多经过两个网络设备:veth_a1和veth_b1,可能是veth的某种设备特性与TCP协议产生了冲突,或veth虚拟设备有bug,或veth设备上配置了限速规则导致。
分析抓包文件: 有如下特征
- 两个方向的数据包,在eth1,veth_a1设备上都有被buffer的现象:到达设备一段时间后被集中发送到下一跳
- 在卡住的情况下,Server端和Client端都没有重传,eth1处抓到的包总比veth_a1多很多,veth_a1处抓到的包与veth_b1处抓到的包总是能保持一致
分析:TCP是可靠传输协议,如果中间因为未知原因(比如限速)发生丢包,一定会重传。因此卡死一定是发包端收到了某种控制信号,主动停止了发包行为。
猜测一:wscal协商不一致,Server端收到的wscal比较小
在TCP握手协商阶段,Server端收到Client端wscal值比实际值小。传输过程中,因为Client端接收buffer还有充裕,Client端累计一段时间没及时回复ack报文,但实际上Server端认为Client端窗口满了(Server端通过比较小的wscal推断Client端接收buffer满了),Server端会直接停止报文发送。
如果Server端使用IPVS做接入层的时候,开启synproxy的情况下,确实会导致wscal协商不一致。
带着这个猜想进行了如下验证:
- 通过修改TCP 接收buffer(ipv4.tcp_rmem)大小,控制Client wscal值
- 通过修改Pod内存配置,保证Node和Pod的在内存配置上没有差异
- 在Server端的IPVS节点抓包,确认wscal协商结果
以上猜想经过验证一一被否决。并且找到业务方同学确认,虽然使用了IPVS模块,但是并没有开启synproxy功能,wscal协商不一致的猜想不成立。
猜测二:设备buffer了报文
设备开启了TSO,GSO特性,能极大提升数据包处理效率。猜测因为容器场景下,经过了两层设备,在每层设备都开启此特性,每层设备都buffer一段,再集中发送,导致数据包乱序或不能及时送到,TCP层流控算法判断错误导致报文停止发送。
带着这个猜想进行了如下验证:
1)关闭所有设备的高级功能(TSO,GSO,GRO,tx-nocache-copy,SG)
2)关闭容器内部delay ack功能(net.ipv4.tcp_no_delay_ack),让Client端积极回应Server端的数据包
以上猜想也都验证失败。
终极方法:使用systamp脚本揪出罪魁祸首
验证了常规思路都行不通。但唯一肯定的是,问题一定出在CVM内部。注意到eth1抓到的包总是比veth_a1多那么几个,之前猜想是被buffer了,但是buffer了总得发出来吧,可是持续保持抓包状态,并没有抓到这部分多余的包,那这部分包一定被丢了。这就非常好办了,只要监控这部分包的丢包点,问题就清楚了。使用systemtap监控skb的释放点并打印backtrace,即可快速找到引起丢包的内核函数。Systemtap脚本如图2-1,2-2所示。
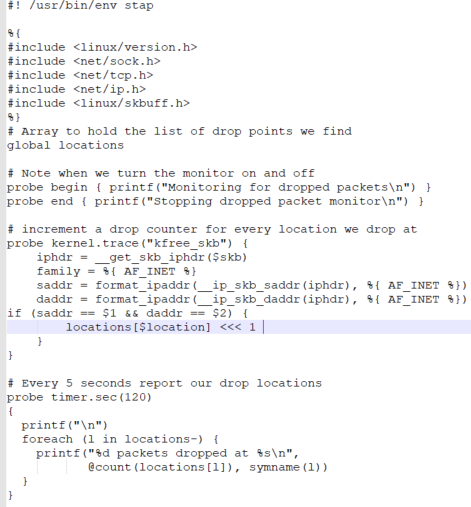
图2-1 dropwatch脚本(不带backtrce打印)
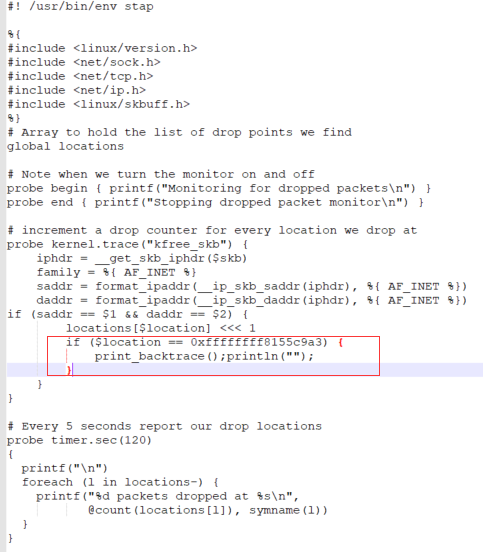
图2-2 dropwatch脚本(带backtrce打印)
首先通过图2-1脚本找到丢包点的具体函数,然后找到丢包具体的地址(交叉运行stap --all-modules dropwatch.stp -g和stap dropwatch.stp -g命令,结合/proc/kallsyms里面函数的具体地址),再把丢包地址作为判断条件,精确打印丢包点的backtrace(图2-2)。
运行脚本stap --all-modules dropwatch.stp -g,开始复现问题,脚本打印如图2-3:

图2-3 丢包函数
正常不卡顿的时候是没有nf_hook_slow的,当出现卡顿的时候,nf_hook_slow出现在屏幕中,基本确定丢包点在这个函数里面。但是有很多路径能到达这个函数,需要打印backtrace确定调用关系。再次运行脚本:stap dropwatch.stp -g,确认丢包地址列表,对比/proc/kallsyms符号表ffffffff8155c8b0 T nf_hook_slow,找到最接近0xffffffff8155c8b0 的那个值0xffffffff8155c9a3就是我们要的丢包点地址(具体内核版本和运行环境有差异)。加上丢包点的backtrace,再次复现问题,屏幕出现图2-4打印。
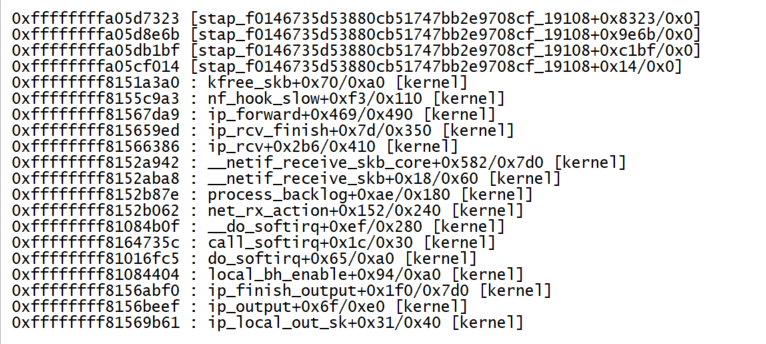
图2-4 丢包点backtrace

图2-5连接表状态
可以看出ip_forward调用nf_hook_slow最终丢包。很明显数据包被iptable上的FORWARD 链规则丢了。查看FORWARD链上的规则,确实有丢包逻辑(-j REJECT --reject-with icmp-port-unreachable),并且丢包的时候一定会发 icmp-port-unreachable类型的控制报文。到此基本确定原因了。因为是在Node上产生的icmp回馈信息,所以在抓包的时候无法通过Client和Server的地址过滤出这种报文(源地址是Node eth0地址,目的地址是Server的地址)。同时运行systamp脚本和tcpdump工具抓取icmp-port-unreachable报文,卡顿的时候两者都有体现。
接下来分析为什么好端端的连接传输了一段数据,后续的数据被规则丢了。仔细查看iptalbe规则发现客户配置的防火墙规则是依赖状态的:-m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT。只有ESTABLISHED连接状态的数据包才会被放行,如果在数据传输过程中,连接状态发生变化,后续入方向的报文都会被丢弃,并返回端口不可达。通过conntrack工具监测连接表状态,发现出问题时,对应连接的状态先变成了FIN_WAIT,最后变成了CLOSE_WAIT(图2-5)。通过抓包确认,GIT在下载数据的时候,会开启两个TCP连接,有一个连接在过一段时间后,Server端会主动发起fin包,而Client端因为还有数据等待传输,不会立即发送fin包,此后连接状态就会很快发生如下切换:
ESTABLISHED(Server fin)->FIN_WAIT(Client ack)->CLOSE_WAIT
所以后续的包就过不了防火墙规则了(猜测GIT协议有一个控制通道,一个数据通道,数据通道依赖控制通道,控制通道状态切换与防火墙规则冲突导致控制通道异常,数据通道也跟着异常。等有时间再研究下GIT数据传输相关协议)。这说明iptables的有状态的防火墙规则没有处理好这种半关闭状态的连接,只要一方(此场景的Server端)主动CLOSE连接以后,后续的连接状态都过不了规则(-m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT)。
明白其中原理以后,对应的解决方案也比较容易想到。因为客户是多租户容器场景,只放开了Pod主动访问的部分服务地址,这些服务地址不能主动连接Pod。了解到GIT以及SVN都是内部服务,安全性可控,让用户把这些服务地址的入方向放行,这样即使状态发生切换,因为满足入向放行规则,也能过防火墙规则。
3. 思考
在排查问题的过程中,发现其实容器的网络环境还有非常多值得优化和改进的地方的,比如:
- TCP接受发送buffer的大小一般是在内核启动的时候根据实际物理内存计算的一个合理值,但是到了容器场景,直接继承了Node上的默认值,明显是非常不合理的。其他系统资源配额也有类似问题。
- 网卡的TSO,GSO特性原本设计是为了优化终端协议栈处理性能的,但是在容器网络场景,Node的身份到底是属于网关还是终端?属于网关的话那做这个优化有没有其他副作用(数据包被多个设备buffer然后集中发出)。从Pod的角度看,Node在一定意义上属于网关的身份,如何扮演好终端和网关双重角色是一个比较有意思的问题
- Iptables相关问题
此场景中的防火墙状态问题
规则多了以后iptables规则同步慢问题
Service 负载均衡相关问题(规则加载慢,调度算法单一,无健康检查,无会话保持,CPS低问题)
SNAT源端口冲突问题,SNAT源端口耗尽问题
- IPVS相关问题
统计timer在配置量过大时导致CPU软中断收包延时问题
net.ipv4.vs.conn_reuse_mode导致的一系列问题 (参考:https://github.com/kubernetes/kubernetes/issues/81775 )
截止到现在,以上大多数问题已经在TKE平台得到解决,部分修复patch提到了内核社区,相应的解决方案也共享到了K8s社区。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号