揭秘日活千万腾讯会议全量云原生化上TKE技术实践
腾讯会议,一款联合国都Pick的线上会议解决方案,提供完美会议品质和灵活协作空间,广泛应用在政府、医疗、教育、企业等各个行业。大家从文章8天扩容100万核,腾讯会议是如何做到的?都知道腾讯会议背后的计算资源已过百万核,如此体量的业务,如何通过云原生技术提升研发和运维效率,是一个非常有价值的课题。这里我将为大家揭秘腾讯自研上云容器平台TKEx在支持腾讯会议全量云原生化上云背后的技术。
TKEx平台是以腾讯云容器服务(Tencent Kubernetes Engine, TKE)为底座,服务于腾讯自研业务的容器平台。腾讯自研业务类型众多、规模超大,云原生上云面临的挑战可想而知。TKEx平台在腾讯自研业务上云的过程中沉淀的最佳实践和解决方案,我们将会在TKE中提供给客户。
腾讯会议业务特性
在Kubernetes中,我们习惯把应用分为无状态和有状态两类,有状态应用主要指实例标识、网络、存储的有状态。腾讯会议的一些服务有如下特性:
- 使用IPC共享内存,里面存放的有状态数据从MB到GB大小不等。
- 升级时IPC数据不能丢失;
- 升级时只能允许ms级的抖动,用户无感知;
- 部分服务最多的实例数过万,要求高效完成一次版本升级;
- 全球多地域部署,要求部署高效;
- 部分服务要求每个实例都分配EIP;
这对Kubernetes管理这种有状态服务提出了更高能力和性能要求。TKEx平台抽象出业务特性背后的产品需求,在灰度发布、多集群工作负载管理、计算资源管理运营、Node稳定性等方面进行了增强和优化,沉淀出了通用的音视频业务容器编排能力。
StatefulSetPlus强大的灰度发布能力
StatefulSetPlus是我们2018年研发并投入生产的首批Operator之一,核心特性包括:
- 兼容StatefulSet所有特性,比如按序滚动更新。
- 支持分批灰度更新和回滚,单批次内的Pods可并发更新、可串行更新。
- 支持各个批次手动待升级勾选Pods。
- 支持用户配置各个批次待升级Pods的比例进行灰度。
- 支持分批回滚和一键失败回滚。
- 发布过程可暂停。
- 支持单个StatefulSetPlus对象管理上万个Pods。
- 支持ConfigMap的分批灰度发布。
- 对接了TKE IPAMD,实现了Pod固定IP。
- 支持HPA和原地VPA。
- 升级过程中的扩容使用LastGoodVersion。
- 支持Node核心状态自检,Node异常时Pod能自动漂移。
- 支持容器原地升级。
- 支持升级失败Pods的容忍率控制,大规模升级过程中升级失败Pods占比小于x%时可继续升级。
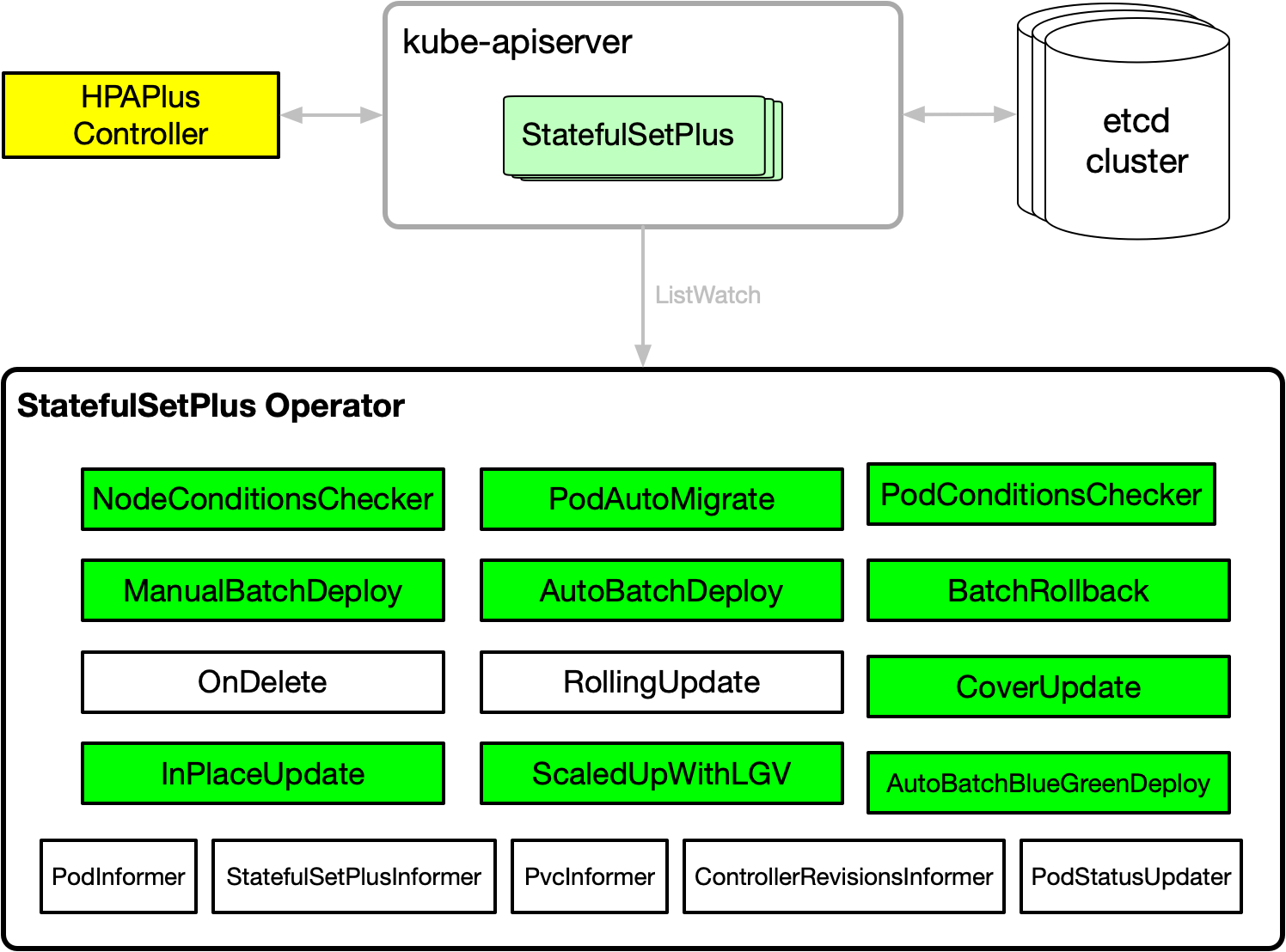
这里主要介绍为腾讯会议上TKE新增的两个发布能力增强:大规模自动分批灰度发布和ConfigMap分批灰度发布。
支持单个StatefulSetPlus上万Pods的自动分批发布能力
TKEx平台在原来StatefulSetPlus手动分批发布能力基础上,这次又开发了自动分批发布的特性,解决像腾讯会议这种大体量业务灰度发布的痛点。用户只要在发布时配置各个批次更新副本的百分比,比如第一批40%,第二批60%。StatefulSetPlus-Operator会根据Readiness探针完成情况,自动进行下一批次的更新,其原理如下。
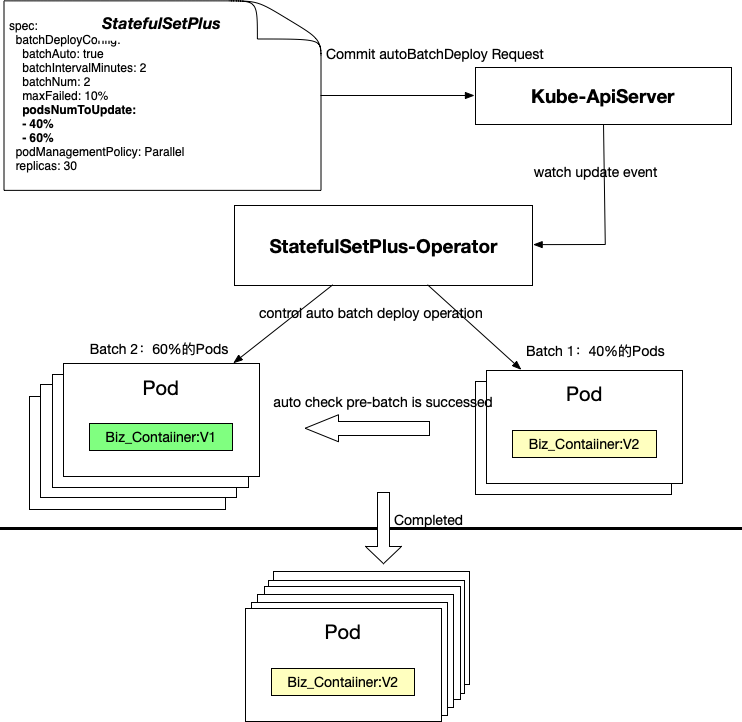
StatefulSetPlus核心Field说明如下:
- batchDeployConfig:
- batchNum:分几批升级
- batchAuto:是否自动分批发布,true表示自动分批发布
- batchIntervalMinutes:两次分批发布之间的间隔分钟数
- podsNumToUpdate:各批次发布的pod数量,如果不设置则将pod平均到每批次发布
StatefulSetPlus对发布过程进行了精细化的监控,提供staus.batchDeployStatus查询发布详细状态,这使得通过CI Pipeline发布变得更显示和可控。
- batchDeployStatus:
- action:当前操作,
Next表示进行下一批发布,WaitToConfirm表示等待确认该批次发布是否成功,Completed表示所有批次均已确认发布成功。 - batchDeadlineTime:本批次发布的Deadline,如果超过该时间,本批次的Pod仍然未Running & Ready,那么本批次发布失败,进入自动回滚流
- batchOrder:当前批次
- batchOrdinal:本批次发布pod的Index的起点
- batchReplicas:本批次发布的pod的数量
- currentDeployComplete:本批次发布是否完成
- currentOrderSuccessPer:成功升级的pod所占百分比
- currentOrderProgress:本批次发布是否成功
- currentRollbackProgress:本批次回滚是否成功
- generalStatus:本次发布全局状态
- action:当前操作,
可在annotations加上platform.tkex/pause-auto-batchDeploy: "true"来暂停自动分批发布和失败自动回滚。
在TKEx平台上,通过如下操作流程即可轻松完成自动分批发布。
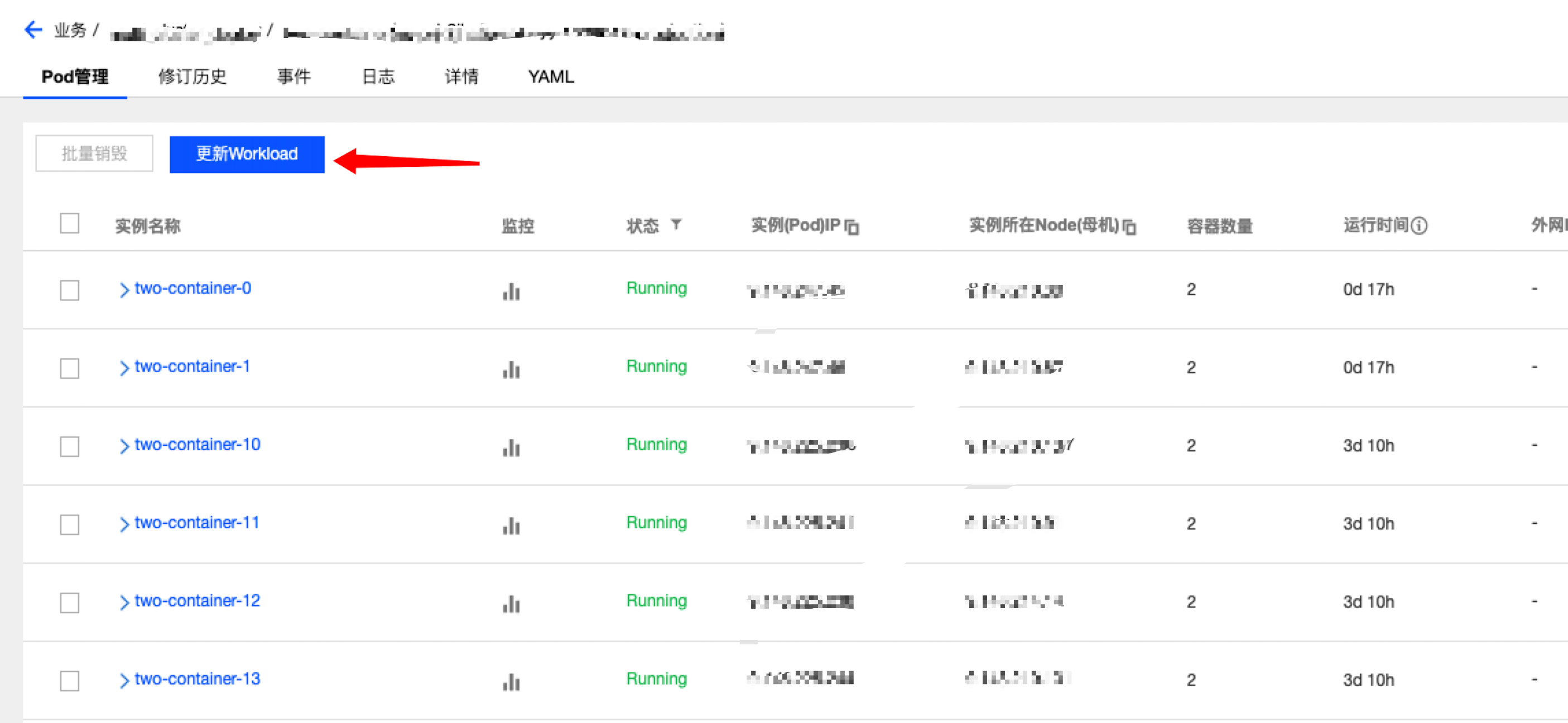
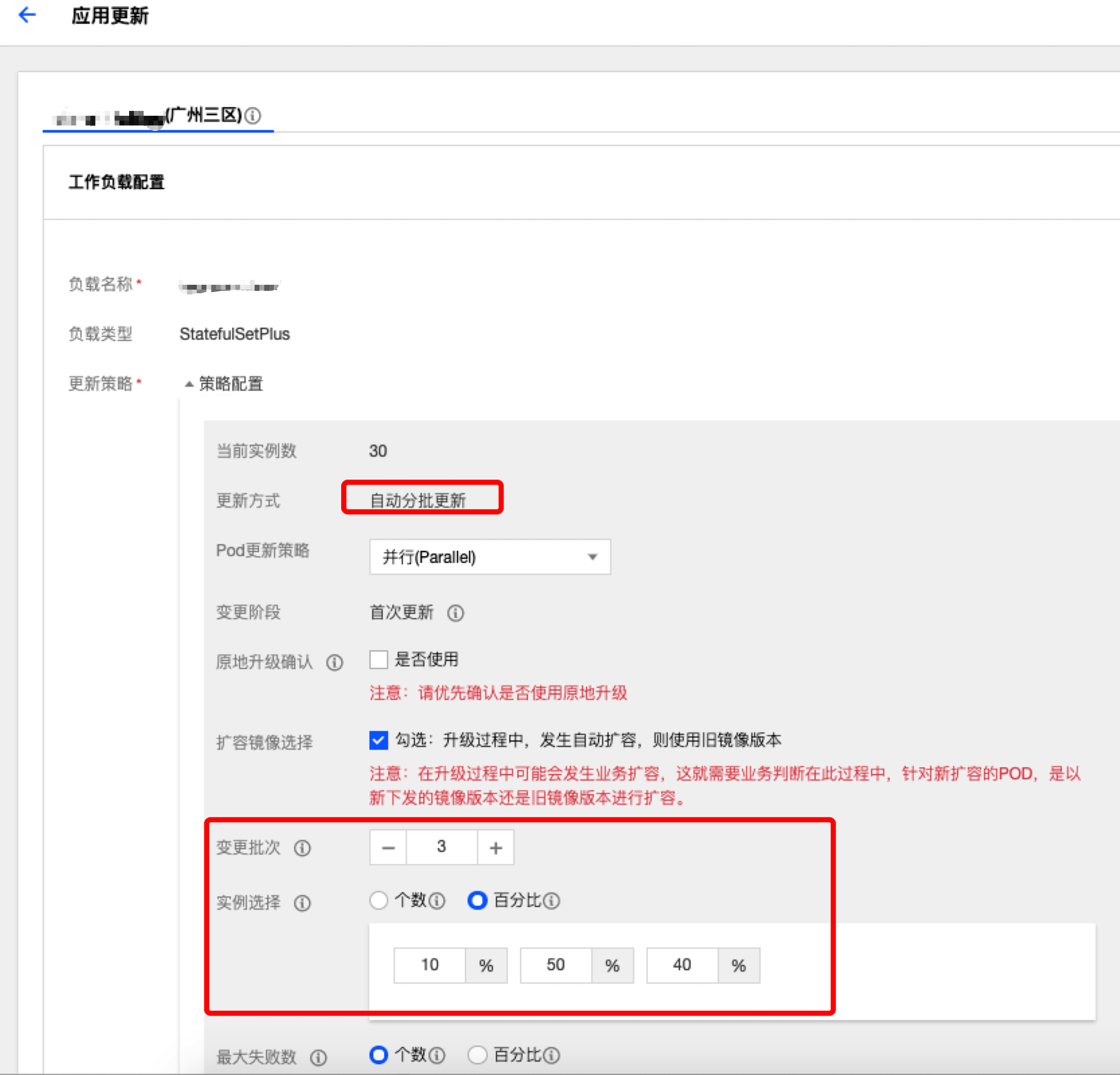
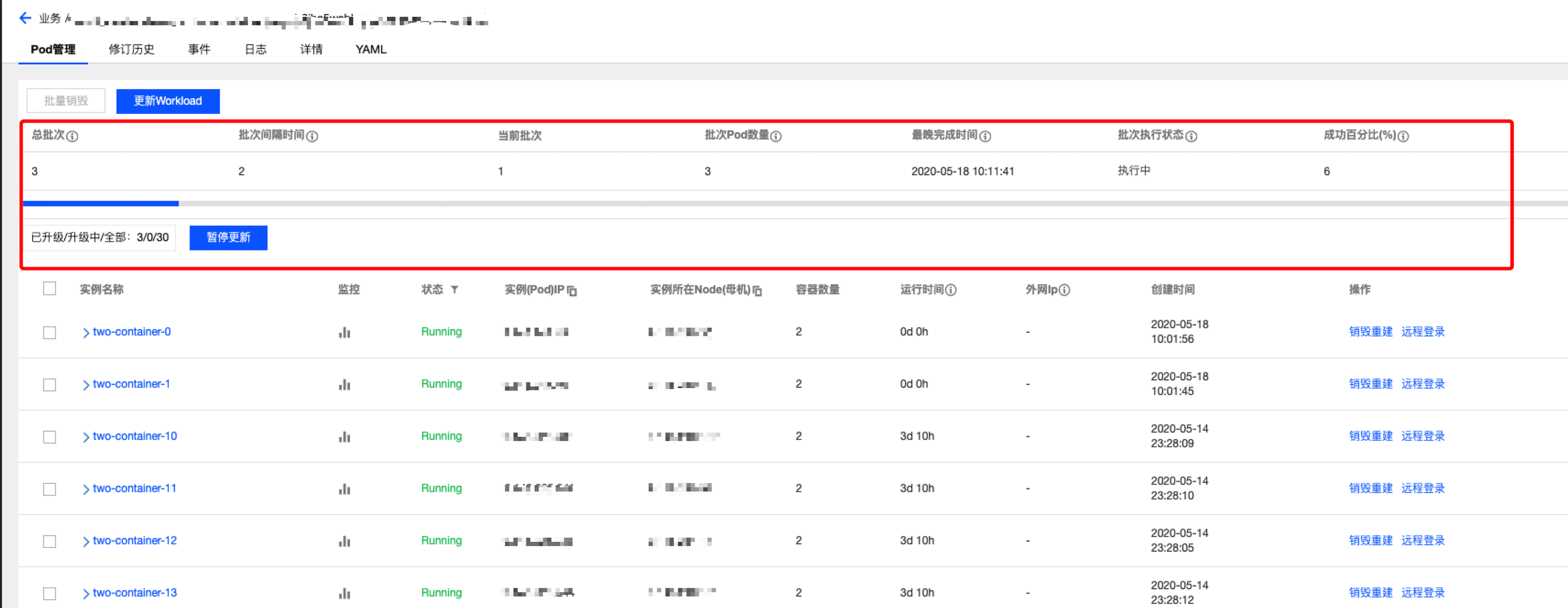
腾讯会议最大的模块需要支持上万个Pods的灰度发布,这是前所未有的挑战。这一次,我们对StatefulSetPlus-Operator进行了优化,性能得到大幅提升。对于一万个pod的StatefulSetPlus,分5批自动升级,单批次2000个pod,不挂载cbs盘的场景,表现如下:
- 非原地升级方式:单批次升级处理耗时40-45秒,单批次升级从发起升级到升级完成耗时三分半钟,升级过程中单次同步StatefulSetPlus status耗时10秒左右。
- 原地升级方式:单批次升级处理耗时30秒左右,单批次升级从发起升级到升级完成耗时一分十秒左右,升级过程中单次同步StatefulSetPlus status耗时10秒左右。
- 正常情况下(非升级过程),同步StatefulSetPlus status毫秒级。
支持ConfigMap的分批灰度发布和版本管理
Kubernetes原生的ConfigMap更新是一次性全量更新到容器内的对应的配置文件,所以通过原生的方式更新配置文件是极其危险的事情。Kubernetes 1.18支持了Immutable ConfigMap/Secret,可以保护关键配置被误改导致业务受影响。业务对容器环境下配置文件的发布同样有着分批灰度发布的极高诉求。
于是我们给StatefulSetPlus赋予了分批发布配置文件的能力,提升了云原生场景下配置文件发布的安全性,原理如下:
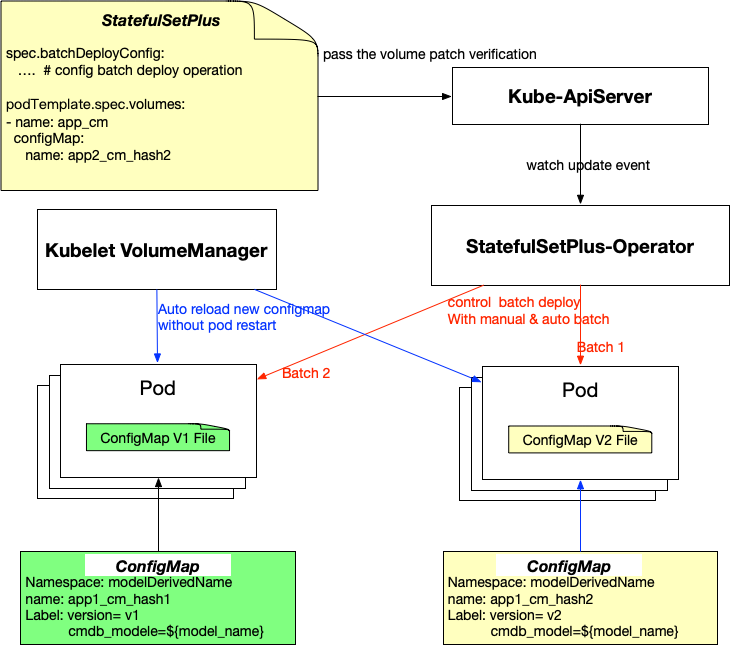
方案概述:
- 用户修改ConfigMap后提交,后台自动创建一个新的ConfigMap,其中ConfigMap Name后缀是data内容的hash值,防止同样的data内容创建出多个ConfigMap,然后在Lable中添加没有data hash值的真正的ConfigMap名字,另外在lable中添加version,或者允许业务自定义一些lable以便标识ConfigMap的版本。
- Kubernetes对Pod的修改只支持更新栏位
spec.containers[*].image, spec.containers[*].resources(if inplace resources update feature enabled),spec.initContainers[*].image, spec.activeDeadlineSeconds or spec.tolerations(only additions to existing tolerations),因此需要修改kube-apiserver代码,使得允许update/patch volumes。 - 通过StatefulSetPlus的分批灰度发布能力,逐个批次的对Pods引用的ConfigMap进行修改,由kubelet volumemanager自动reload configmap,因此ConfigMap的更新不需要重建Pods。
为防止ConfigMap累积过多,影响etcd集群的性能,我们在自研组件
TKEx-GC-Controller增加ConfigMap的回收逻辑,只保留最近10个版本的ConfigMap。
用户只要在更新Workload页面,选择手动分批或者自动分批更新,在数据卷选项重新选择新版本的ConfigMap即可。可以在更新业务镜像的同时也更新ConfigMap配置文件,或者只更新ConfigMap配置文件。
ConfigMap配置文件更新,需要容器内业务进程能watch到配置文件的变更进行重启加载或者热加载。然而有些业务当前并没有这个能力,因此TKEx在ConfigMap发布的入口提供配置文件更新后的ProUpdate Hook,比如业务进程的冷/热重启命令。
如何保证有状态服务的升级只有ms级抖动
拒绝胖容器模式(把容器当虚拟机用)是TKEx平台的原则,如何使用镜像发布并且提供像进程重启一样的ms级业务抖动,这是腾讯会议容器化上云最有挑战性的需求之一。TKEx平台在灰度发布能力上已经做了长期的技术沉淀,上万个业务模块在使用,但当前能力仍无法满足这一需求,镜像预加载+容器原地升级的方案,仍与这目标差距甚远。
经过多个方案的设计、分析、测试对比,考虑通用性、云原生、发布效率多个因素,最终使用如下方案:
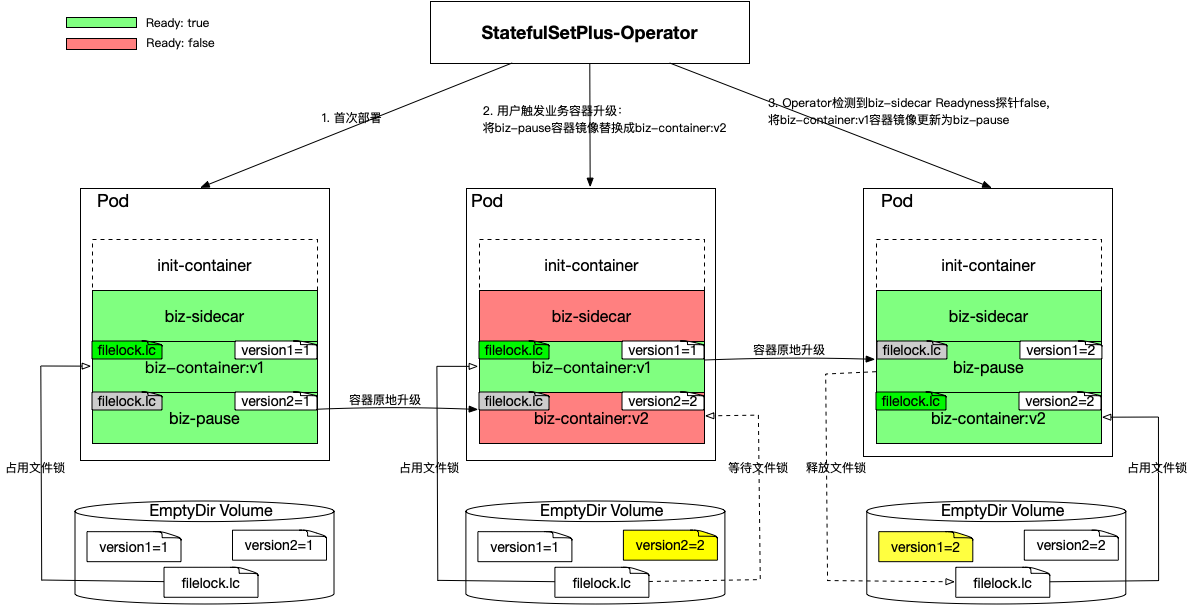
Pod里面有3个关键容器,它们的职责分别如下:
- biz-sidecar: Sidercar容器职责很简单,检测Pod是否在升级中。通过Readyness Probe比较EmptyDir Volume中的业务发布版本文件version1和version2的内容是否相等,相等则Ready,否则notReady。
- biz-container:容器启动脚本会将环境变量(预注入)里的一个版本号写到versionX文件中,然后开始循环等文件锁,如果成功获取文件锁则启动业务进程。文件锁是防止Pod内同时运行多个版本的业务Container的关键,用文件锁来做不同版本容器的互斥。
- biz-pause:启动脚本会将环境变量里的一个版本号写到versionX文件里,然后就进入无限sleep状态。这个容器是备用容器,当业务升级时,它就会通过原地升级的方式切换到biz-container的角色。
升级流程概述
以业务容器镜像从版本V1升级到版本V2为例,升级流程描述如下:
- 用户第一次部署业务,如上最左边的Pod, 一共有3个容器。biz-sidecar,biz-container(配置环境变量版本号为1)以及biz-pause(配置环境变量版本号为1)。所有2个容器启动之后会分别将version1, version2文件的内容更新为1,biz-sidecar此时为Ready。
- 更新Pod之前的biz-pause容器为业务V2版本的镜像同时环境变量版本号为2,等该容器原地升级之后把version2文件的内容更新为2之后开始等文件锁。此时biz-sidecar探针转为notReady状态。
- StatefulSet-Operator Watch到biz-sidecar为notReady之后再将之前的v1版本的业务镜像替换成biz-pause镜像同时环境变量版本号为2。等pause镜像容器原地重启之后会将之前v1业务镜像占的文件锁释放,同时version1内容更新为2。此时sidecar探针为Ready, 整个升级结束。
需要说明以下两点:
- 原生Kubernetes apiserver只允许修改Pod的image等field,不支持修改resource以及环境变量等,所以该方案需要改K8s apiserver的相关代码。
- 另外为了保证Pod Level Resource以及Pod QoS不变,StatefulSetPlus-Operator在升级时需要对容器状态变更过程中进行Container Resource调整。
多地域部署和升级,变得更简单
在多地域服务管理上,我们主要解决两个诉求:
- 同一个服务需要部署在很多的地域,提供就近访问或者多地容灾,如何进行服务在多个集群的快速复制;
- 部署在多个地域的同一个服务,如何进行快速的同步升级;
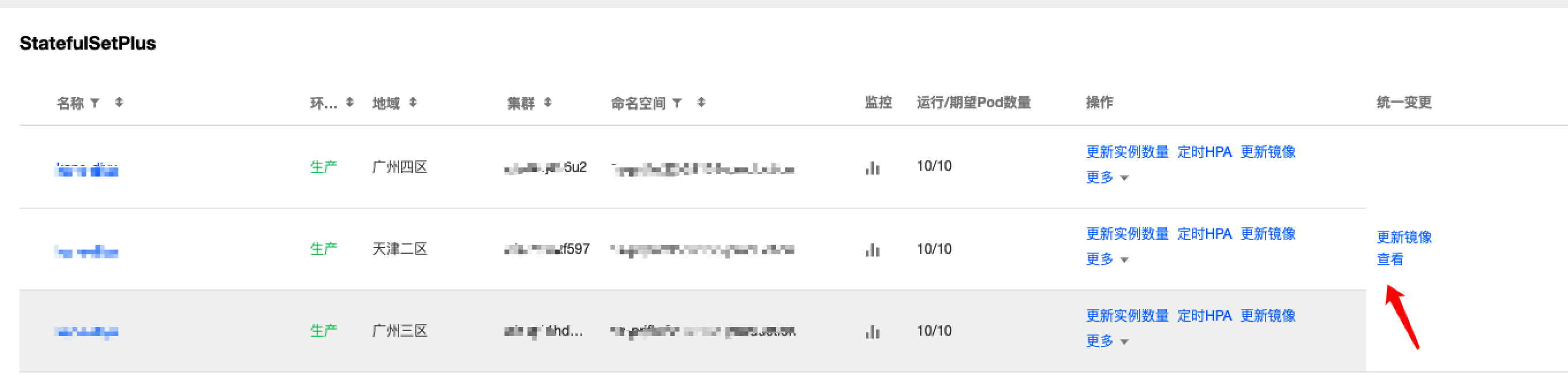
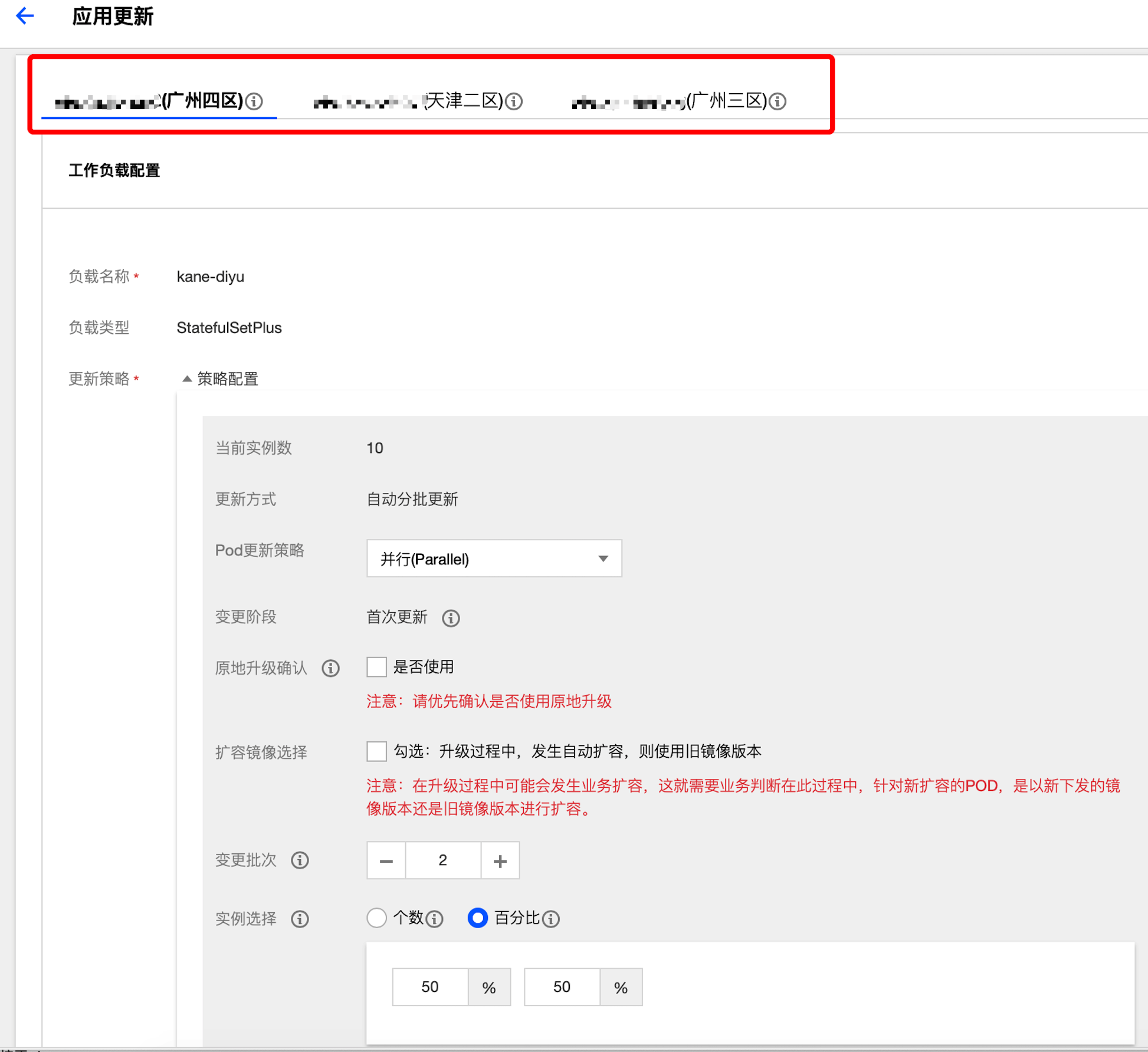
TKEx提供了便捷的多地域多集群业务部署和业务同步升级能力。
- 支持一次性部署到多个地域多个集群。
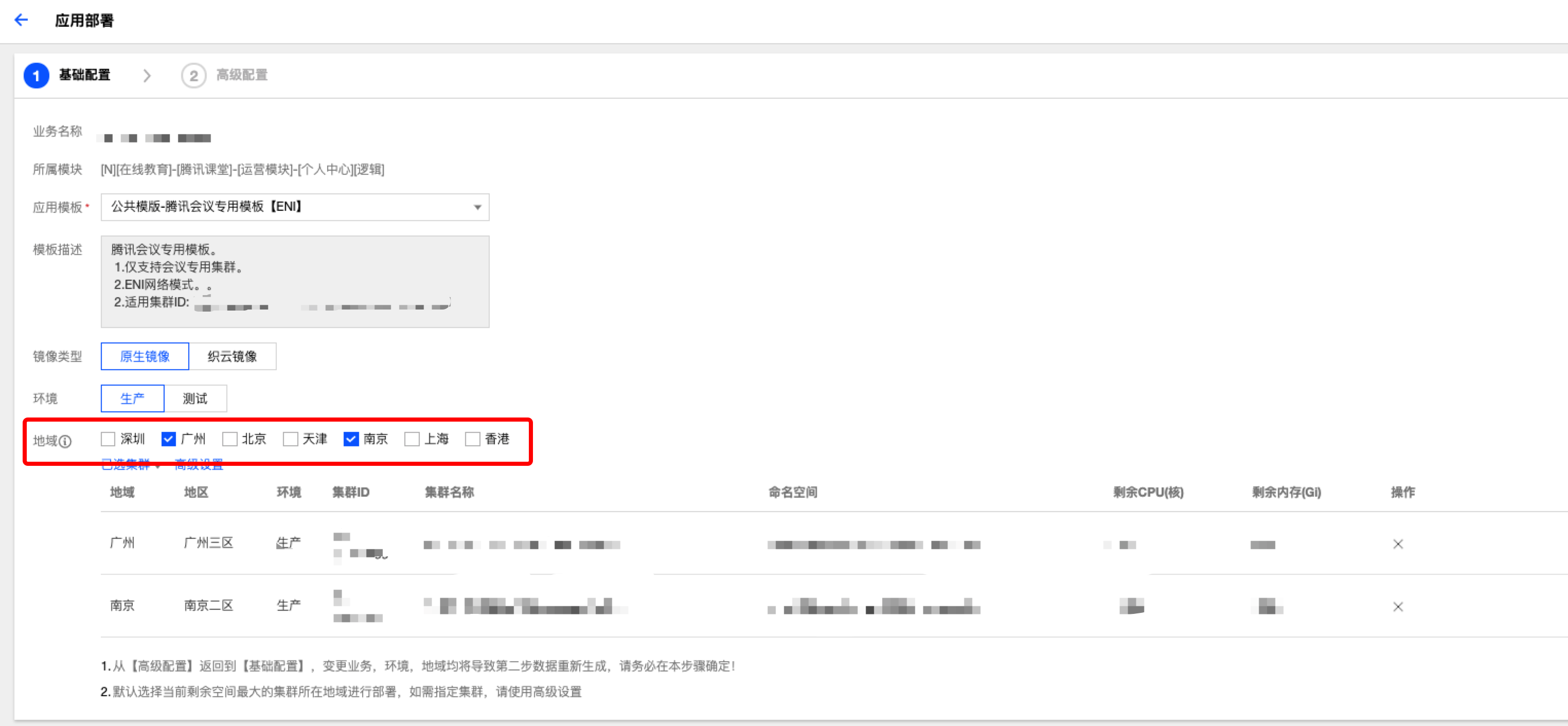
- 支持部署在多个集群的Workload同步升级。
平台资源管理能力增强
TKEx平台的集群资源是所有服务共享的,各种服务混部在集群和节点中。各个产品都有自己的资源预算,平台接受各个产品的预算,然后根据自动生成对应的资源配额,以此控制各个产品在整个平台上的Quota。产品部署后,涉及到成本核算,平台会根据真实使用的资源量,以小时为时间计量粒度,跟踪统计每个业务产品下面各个Workload的资源使用情况。
DynamicQuota-Operator
Kubernetes原生用ResourceQuota来做资源限制,但是它与我们的期望相比存在如下问题:
- ResourceQuota是基于Namespace的,无法做到产品基本的限制。
- ResourceQuota是基于集群内的限制,无法做到平台级的,无法进行多集群联动Balance。
- 只有限制能力,无法保障业务有足够的资源可以使用。
基于我们对于业务产品的管理需求及期望,TKEx的配额管理系统须满足如下特性:
- 使用简单,用户无需关心底层细节,比如配额如何在各个集群间分布及调配都由系统来自动完成。
- 分配给产品的配额,必须保障产品始终有这么多资源可以使用。
- 满足平台在离线混合部署场景诉求,配额要有限制离线任务配额的能力。
- 为了避免某一个产品占用配额而不使用导致平台资源浪费,要有在产品间配额借和还的能力。
我们设计了一个DynamicQuota CRD,用来管理集群中各个业务产品的Quota,实现以上能力。
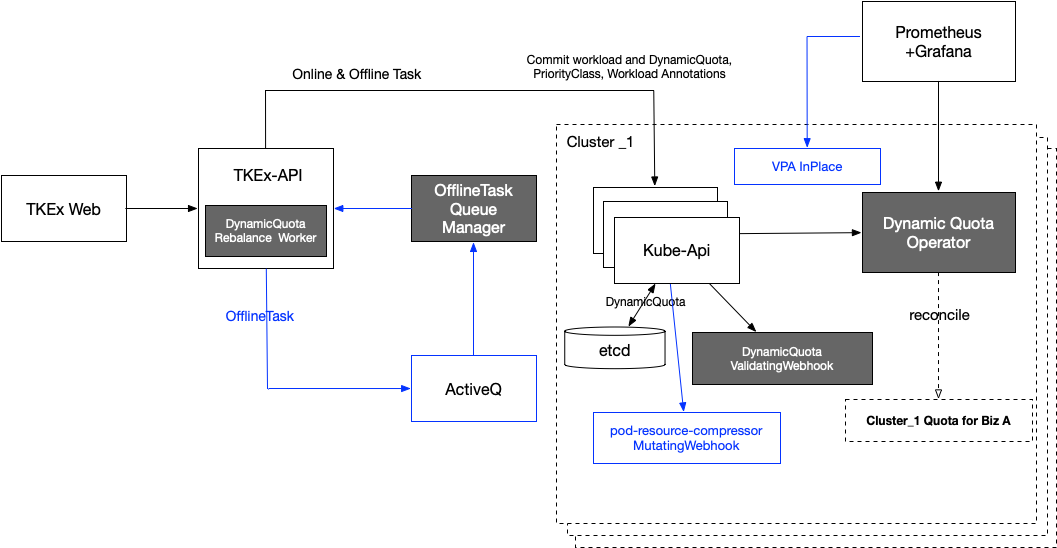
- Quota Rebalance Worker: 该Worker会定期根据产品在各集群的配额使用情况,动态的将产品配额在各集群间调配。比如有个产品的服务因为配置了弹性扩缩容,当产品在某个集群因为扩容导致配额用完但是在其他的集群还有比较多的配额,这时Worker就会将配额从空闲集群调配到该集群。
- DynamicQuota Operator: 负责维护自定义CRD DynamicQuota的状态,同时会收集各产品在集群中的使用情况暴露给Prometheus。
- DynamicQuota ValidatingWebhook: 截获集群中所有向kube-apiserver的pod创建请求,并阻止那些超配额的产品Pod创建请求。
- OfflineTask QueueManager: 负责从离线作业队列(ActiveQ)中根据作业优先级进行消费,并判断各个集群的离线作业资源占比是否超过水位线,以达到控制所有离线作业资源占比的目的,防止离线作业消耗过多的集群资源。
- pod-resource-compressor和VPA组件,根据集群和节点实际负载、资源分配情况,对离线作业进行资源压缩和原地升降配,以保护在线任务的资源使用。在离线混部时,我们还在内核层面对Cpu调度进行了优化,以达到离线任务快速避让,以保证在线任务的服务质量。
预算转移自动生成产品Quota
产品完成预算归属到TKEx平台后,平台将自动为产品增加对应的产品配额,自动修改DynamicQuota。用户可以在TKEx监控面板中查看归属产品的资源配额。
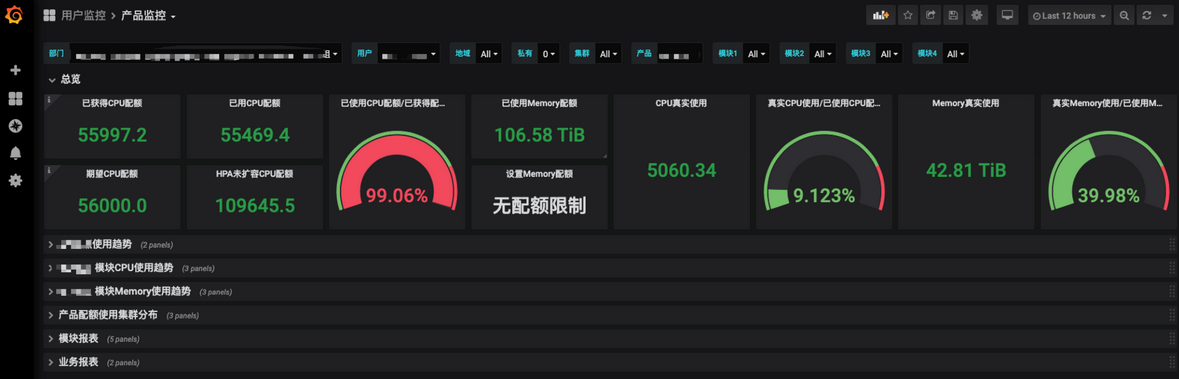
业务核算自动化和可视化
TKEx会以核*时为业务使用资源的计量粒度进行成本核算,用户可以在TKEx监控面板中查看具体的各个Kubernetes Workload的详细资源使用情况。
提升自愈能力
随着集群规模和节点部署密度越来越高,集群平均负载超过50%,高峰期很多节点的负载甚至80%以上,一些稳定性问题开始显现,为此TKEx针对节点稳定性做了如下优化:
- 主动探测dockerd的可用性,异常时主动重启dockerd,防止dockerd hung住导致Node上Pods自动销毁重建,
- 主动监控kubelet的可用性,异常时主动重启kubelet,防止kubelet hung住导致Pods大量漂移重建。
- 因为Kubernetes在pids.max, file-max等内核参数隔离机制不完善,在kubernetes 1.14中虽然支持了对Pods内Pids numbers的限制,但实际落地时很难为业务指定默认的pids limit。集群中仍会出现因为节点Pids和file-max耗尽导致同一节点上其他业务容器受影响的问题。对此,我们在
Node-Problem-Detector(简称NPD)组件中增加了节点pids,file-max的监控,达到相关资源使用水位线时,会自动检测消耗pids和file-max最多的Container并上报,主动触发告警并对Container进行原地重启。
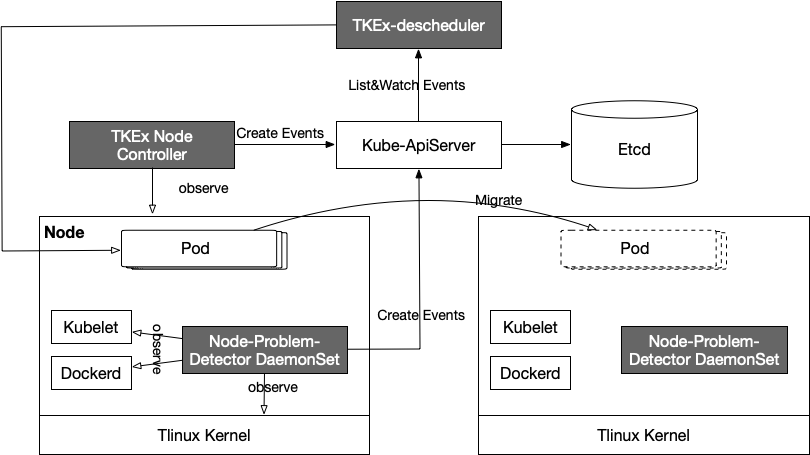
以上几项能力都在NPD组件中实现,负责监控节点的工作状态,包括内核死锁、OOM频率、系统线程数压力、系统文件描述符压力等指标,做节点驱逐、节点打Taint等动作,并通过Node Condition或者Event的形式上报给Apiserver。
当前NPD组件会在节点中增加如下特定的Conditions:
| Condition Type | 默认值 | 描述 |
|---|---|---|
| ReadonlyFilesystem | False | 文件系统是否只读 |
| FDPressure | False | 查看主机的文件描述符数量是否达到最大值的80% |
| PIDPressure | False | 查看主机是否已经消耗了90%以上的pids |
| FrequentKubeletRestart | False | Kubelet是否在20Min内重启超过5次 |
| CorruptDockerOverlay2 | False | DockerImage 是否存在问题 |
| KubeletProblem | False | Kubelet service是否Running |
| KernelDeadlock | False | 内核是否存在死锁 |
| FrequentDockerRestart | False | Docker是否在20Min内重启超过5次 |
| FrequentContainerdRestart | False | Containerd是否在20Min内重启超过5次 |
| DockerdProblem | False | Docker service是否Running(若节点运行时为Containerd,则一直为False) |
| ContainerdProblem | False | Containerd service是否Running(若节点运行时为Docker,则一直为False |
| ThreadPressure | False | 系统目前线程数是否达到最大值的90% |
| NetworkUnavailable | False | NTP service是否Running |
有些事件是不适合在NDP DaemonSet做分布式检测的,我们就放在TKEx Node Controller中去做中心式检测,由其生成Event并发送到Apiserver。比如:
- 快速检测Node网络问题,而不依赖于5min延时的NodeLost Condition,这个问题NDP检测到也无法把事件发送到Apiserver。
- Node Cpu持续高负载导致业务服务质量下降,会有TKEx Node Controller做检测,并将cpu负载Top N的Pods通过Event发送到Apiserver,由TKEx-descheduler来决定驱逐哪些Pods。做驱逐决策时,需要考虑Pods所属Workload是否是单副本的,Pods是否能容忍Pods漂移重建等。
TKEx-descheduler则负责ListWatch NPD和TKEx Node Controller发送的Events,做出对应的行为决策,比如对Pod内某个问题Container进行原地重启、问题Pod的驱逐等。
容器网络增强和调度能优化
容器网络支持EIP
TKEx之前提供的VPC+ENI的Underlay网络方案,使得容器网络和CVM网络、IDC网络在同一网络平面,并且支持容器固定IP,极大地方便自研业务上云。这次TEKx平台的容器网络能力再升级,支持在使用HostNetwork和VPC+ENI容器网络方案上,再为Pod分配EIP(弹性公网IP)的能力。
调度优化
当后端集群资源池耗尽,会有大量的待调度的pending pods,此时使用任何类型的Workload进行镜像更新时都会出现资源抢占导致升级失败的情况。
为了解决这个问题,提升业务升级的稳定性,我们优化了Kubernetes Scheduler Cache的逻辑,给StatefulSet/StatefulSetPlus升级时提供了资源预抢占的调度能力,很好的保证了在不新增资源的情况下StatefulSet/StatefulSetPlus能正常升级成功,不会被调度队列中的Pendnig Pod抢占资源。
后面团队会单独输出一篇技术文章对此进行详细分析,感兴趣的同学请关注腾讯云原生公众号,加小助手TKEplatform,拉你进腾讯云容器技术交流群。
总结
本文总结了腾讯会议在TKE容器化部署时用到的平台相关特性,包括业务镜像自动分批灰度发布、ConfigMap分批灰度发布、Pod内A/B容器ms级切换发布、多集群发布管理、基于DynamicQuota的产品配额管理、探测节点和集群稳定性问题以提升自愈能力等。腾讯自研业务在TKE上沉淀的优秀组件和方案,后面会在公网TKE产品中提供给公网客户,也在计划开源,敬请期待。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号