【Pod Terminating原因追踪系列之二】exec连接未关闭导致的事件阻塞
前一阵有客户docker18.06.3集群中出现Pod卡在terminating状态的问题,经过排查发现是containerd和dockerd之间事件流阻塞,导致后续事件得不到处理造成的。
定位问题的过程极其艰难,其中不乏大量工具的使用和大量的源码阅读。本文将梳理排查此问题的过程,并总结完整的dockerd和contaienrd之间事件传递流程,一步一步找到问题产生的原因,特写本文记录分享,希望大家在有类似问题发生时,能够迅速定位、解决。
对于本文中提到的问题,在docker19中已经得到解决,但docker18无法直接升级到docker19,因此本文在结尾参考docker19给出了一种简单的解决方案。
删除不掉Pod
相信大家在解决现网问题时,经常会遇到Pod卡在terminating不动的情况,产生这种情况的原因有很多,比如《Pod Terminating原因追踪系列之一》中提到的containerd没有正确处理错误信息,当然更常见的比如umount失败、dockerd卡死等等。
遇到此类问题时,通常通过kubelet或dockerd日志、容器和Pod状态、堆栈信息等手段来排查问题。本问题也不例外,首先登录到Pod所在节点,使用以下两条指令查看容器状态:
#查看容器状态,看到容器状态为up
docker ps | grep <container-id>
#查看task状态,显示task的状态为STOPPED
docker-container-ctr --namespace moby --address var/run/docker/containerd/docker-containerd.sock task ls | grep <container-id>

可以看到在dockerd中容器状态为up,但在containerd中task状态为STOPPED,两者信息产生了不一致,也就是说由于某种原因containerd中的状态信息没有同步到dockerd中,为了探究为什么两者状态产生了不一致,首先需要了解从dockerd到containerd的整体调用链:

当启动dockerd时,会通过NewClient方法创建一个client,该client维护一条到containerd的gRPC连接,同时起一个协程processEventStream订阅(subscribe)来自containerd的task事件,当某个容器的状态发生变化产生了事件,containerd会返回事件到client的eventQ队列中,并通过ProcessEvent方法进行处理,processEventStream协程在除优雅退出以外永远不会退出(但在有些情况下还是会退出,在后续会推出一篇文章,恰好是这种情况,敬请期待~)。
当容器进程退出时,containerd会通过上述gRPC连接返回一个exit的task事件给client,client接收到来自containerd的exit事件之后由ProcessEvent调用DeleteTask接口删除对应task,至此完成了一个容器的删除。
由于containerd一直处于STOPPED状态,因此通过上面的调用链猜测会不会是task exit事件因为某种原因而阻塞掉了?产生的结果就是在containerd侧由于发送了exit事件而进入STOPPED状态,但由于没有调用DeleteTask接口,因此本task还存在。
模拟task exit事件
通过发送task exit事件给一个卡住的Pod,来模拟容器结束的情况:
/tasks/exit {"container_id":"23bd0b1118238852e9dec069f8a89c80e212c3d039ba030cfd33eb751fdac5a7","id":"23bd0b1118238852e9dec069f8a89c80e212c3d039ba030cfd33eb751fdac5a7","pid":17415,"exit_status":127,"exited_at":"2020-07-17T12:38:01.970418Z"}
我们可以手动将上述事件publish到containerd中,但是需要注意的一点的是,在publish之前需要将上述内容进行一下编码(参考containerd/cmd/containerd-shim/main_unix.go Publish方法)。得到的结果如下图,可以看到事件成功的被publish,也被dockerd捕获到,但容器的状态仍然没有变化。
#将file文件中的事件发送到containerd
docker-containerd --address var/run/docker/containerd/docker-containerd.sock publish --namespace moby --topic /tasks/exit < ~/file
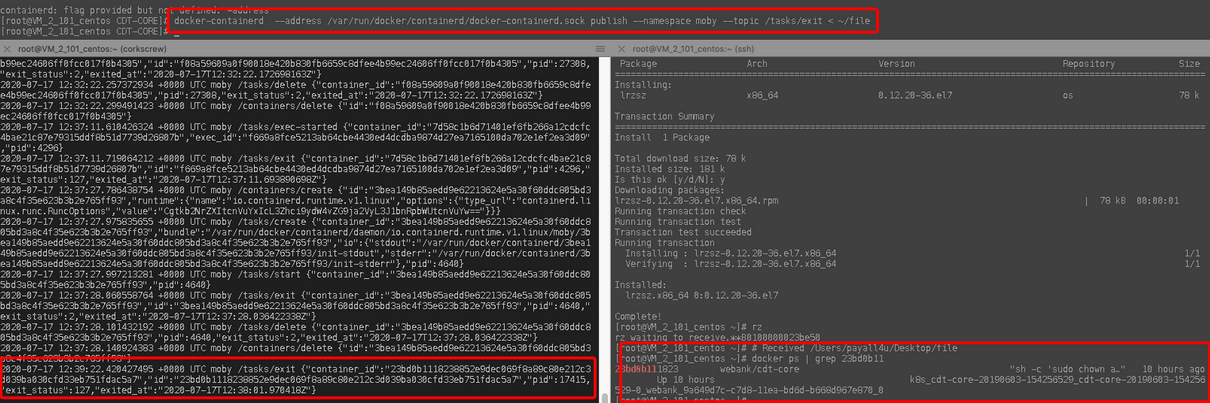
当我们查看docker堆栈日志(向dockerd进程发送SIGUSR1信号),发现有大量的Goroutine卡在append方法,每次publish新的exit事件都会增加一个append方法的堆栈信息:
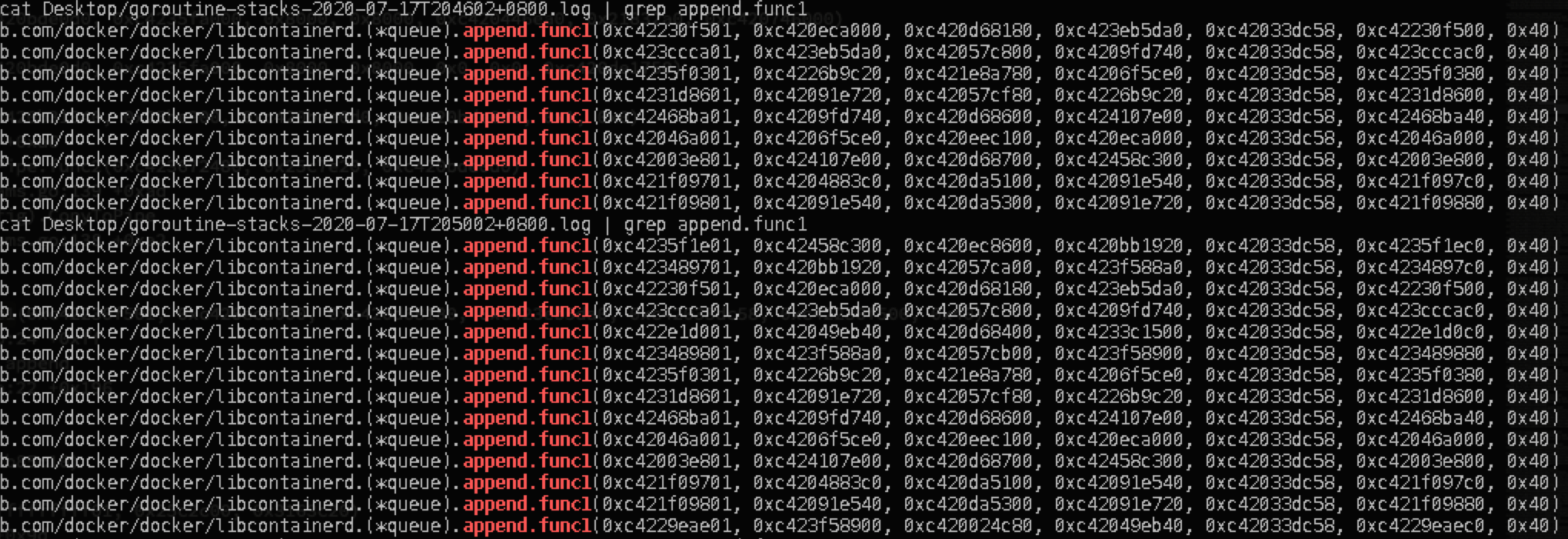
通过查看append方法的源码发现,append方法负责将收到的containerd事件放入eventQ,并执行回调函数,对收到的不同类型事件进行处理:
func (q *queue) append(id string, f func()) {
q.Lock()
defer q.Unlock()
if q.fns == nil {
q.fns = make(map[string]chan struct{})
}
done := make(chan struct{})
fn, ok := q.fns[id]
q.fns[id] = done
go func() {
if ok {
<-fn
}
f()
close(done)
q.Lock()
if q.fns[id] == done {
delete(q.fns, id)
}
q.Unlock()
}()
}
形参中的id为container的id,因此对于同一个container它的事件是串行处理的,只有前一个事件处理结束才会处理下一个事件,且没有超时机制。
因此只要eventQ中有一个事件发生了阻塞,那么在它后面所有的事件都会被阻塞住。这也就解释了为什么每次publish新的对于同一个container的exit事件,都会在堆栈中增加一条append的堆栈信息,因为它们都被之前的一个事件阻塞住了。
深入源码定位问题原因
为了找到阻塞的原因,我们找到阻塞的第一个exit事件append的堆栈信息再详细的看一下:
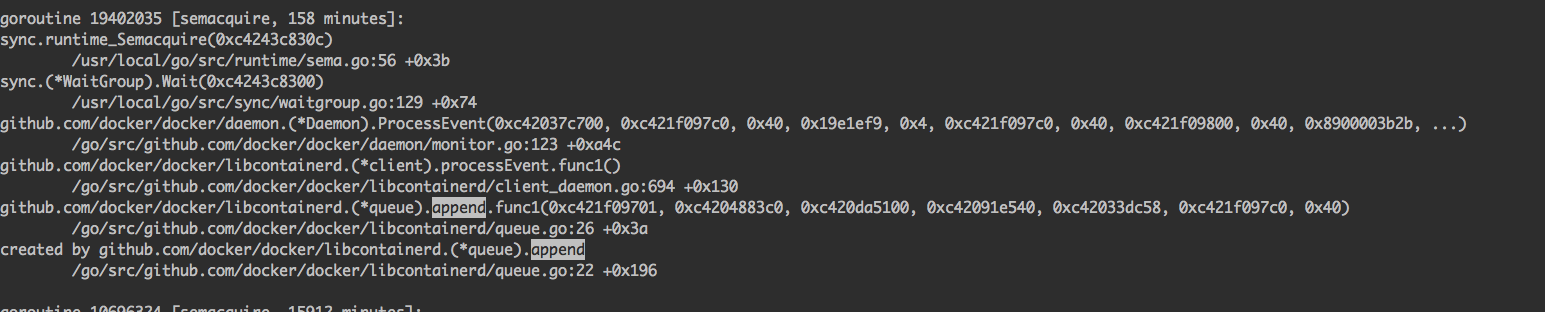
通过堆栈可以发现代码卡在了docker/daemon/monitor.go文件的123行(省略了不重要的代码):
func (daemon *Daemon) ProcessEvent(id string, e libcontainerd.EventType, ei libcontainerd.EventInfo) error {
......
case libcontainerd.EventExit:
......
if execConfig := c.ExecCommands.Get(ei.ProcessID); execConfig != nil {
......
123行 execConfig.StreamConfig.Wait()
if err := execConfig.CloseStreams(); err != nil {
logrus.Errorf("failed to cleanup exec %s streams: %s", c.ID, err)
}
......
} else {
......
}
......
return nil
}
可以看到收到的事件为exit事件,并在第123行streamConfig在等待一个wg,这里的streamconfig为一个内存队列,负责收集来自containerd的输出返回给客户端,具体是如何处理io的在后面会细讲,这里先顺藤摸瓜查一下wg在什么时候add的:
func (c *Config) CopyToPipe(iop *cio.DirectIO) {
copyFunc := func(w io.Writer, r io.ReadCloser) {
c.Add(1)
go func() {
if _, err := pools.Copy(w, r); err != nil {
logrus.Errorf("stream copy error: %v", err)
}
r.Close()
c.Done()
}()
}
if iop.Stdout != nil {
copyFunc(c.Stdout(), iop.Stdout)
}
if iop.Stderr != nil {
copyFunc(c.Stderr(), iop.Stderr)
}
.....
}
CopyToPipe是用来将containerd返回的输出copy到streamconfig的方法,可以看到当来自containerd的io流不为空,则会对wg add1,并开启协程进行copy,copy结束后才会done,因此一旦阻塞在copy,则对exit事件的处理会一直等待copy结束。我们再回到docker堆栈中进行查找,发现确实有一个IO wait,并阻塞在polls.Copy函数上:
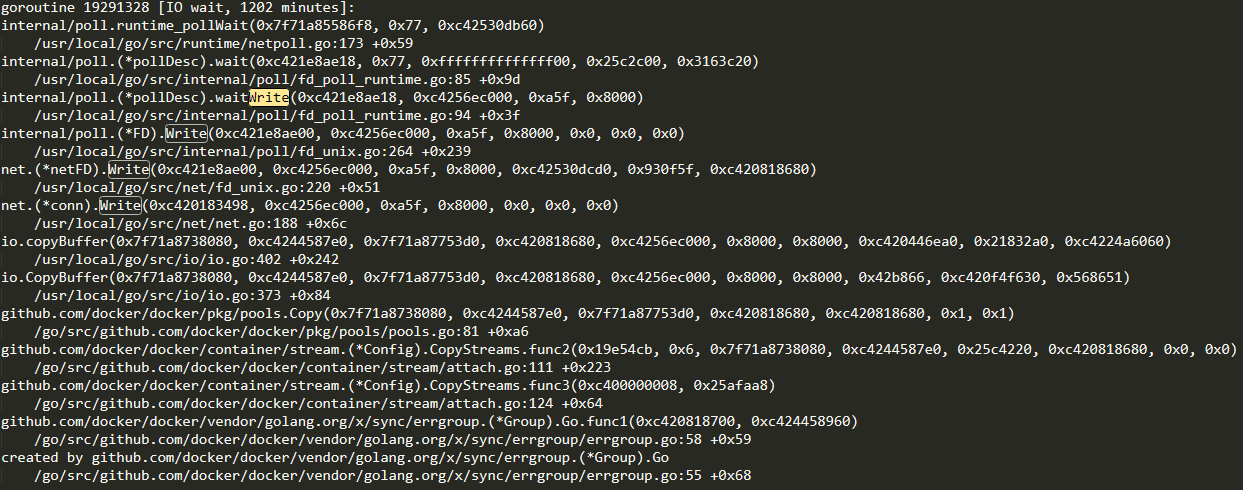
至此造成dockerd和containerd状态不一致的原因已经找到了!我们来梳理一下。
首先通过查看dockerd和containerd状态,发现两者状态不一致。由于containerd处于STOPPED状态因此判断在containerd发送task exit事件时可能发生阻塞,因此我们构造了task exit事件并publish到containerd,并查看docker堆栈发现有大量阻塞在append的堆栈信息,证实了我们的猜想。
最后我们通过分析代码和堆栈信息,最终定位在ProcessEvent由于pools.Copy的阻塞,也会被阻塞,直到copy结束,而事件又是串行处理的,因此只要有一个事件处理被阻塞,那么后面所有的事件都会被阻塞,最终表现出的现象就是dockerd和containerd状态不一致。
找出罪魁祸首
我们已经知道了阻塞的原因,但是究竟是什么操作阻塞了事件的处理?其实很简单,此exit事件是由exec退出产生的,我们通过查看堆栈信息,发现在堆栈有为数不多的ContainerExecStart方法,说明有exec正在执行,推测是客户行为:

ContainerExecStart方法中第二个参数为exec的id值,因此可以使用gdb查找对应地址内容,查看其参数中的execId和terminating Pod中的容器的exexId(docker inspect可以查看execId,每个exec操作对应一个execId)是否一致,结果发现execId相同!因此可以断定是由于exec退出,产生的exit事件阻塞了ProcessEvent的处理逻辑,通过阅读源码总结出exec的处理逻辑:
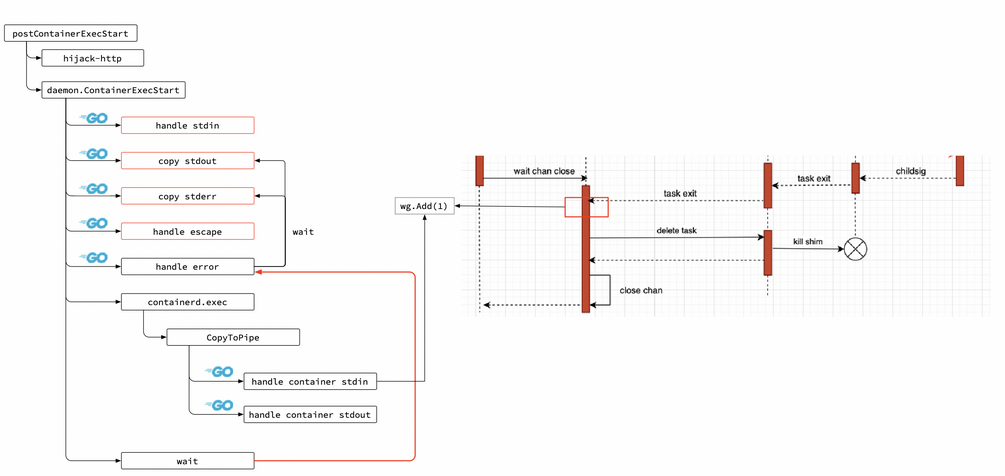
那么为什么exec的exit会导致Write阻塞呢?我们需要梳理一下exec的io处理流程看看究竟Write到了哪里。下图为io流的处理过程:
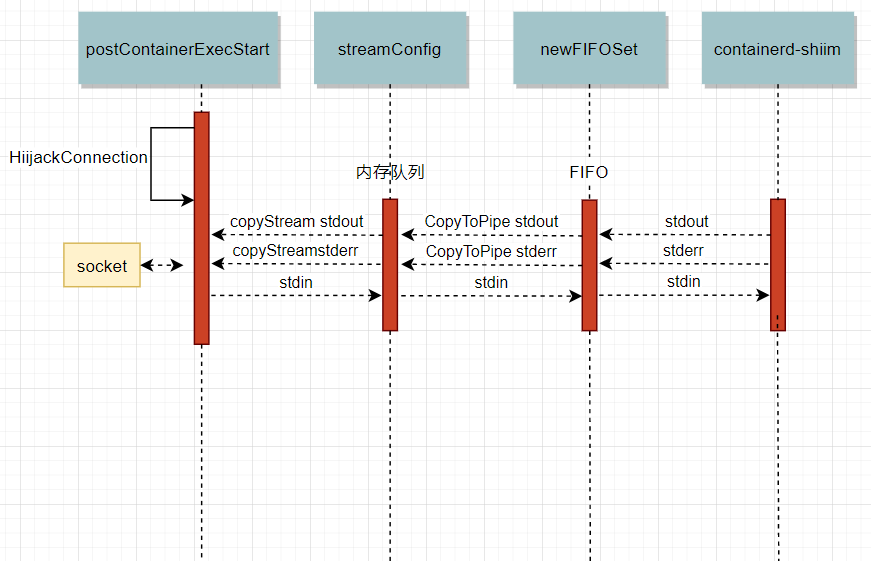
首先在exec开始时会将socket的输出流attach到一个内存队列,并启动了⼀个goroutine用来把内存队列中的内容输出到socket中,除了内存队列外还有一个FIFO队列,通过CopyToPipe开启协程copy到内存队列。FIFO队列用来接收containerd-shim的输出,之后由内存队列写入socket,以response的方式返回给客户端。但我们的问题还没有解决,还是不清楚为什么Write会阻塞住。不过可以通过gdb来定位到Write函数打开的fd,查看一下socket的状态:
n, err := syscall.Write(fd.Sysfd, p[nn:max])
type FD struct {
// Lock sysfd and serialize access to Read and Write methods.
fdmu fdMutex
// System file descriptor. Immutable until Close.
Sysfd int
......
}
Write为系统调用,其参数中第一位即打开的fd号,但需要注意,Sysfd并非FD结构体的第一个参数,因此需要加上偏移量16字节(fdMutex占16字节)
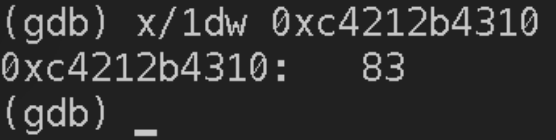

发现该fd为一个socket连接,使用ss查看一下socket的另一端是谁:
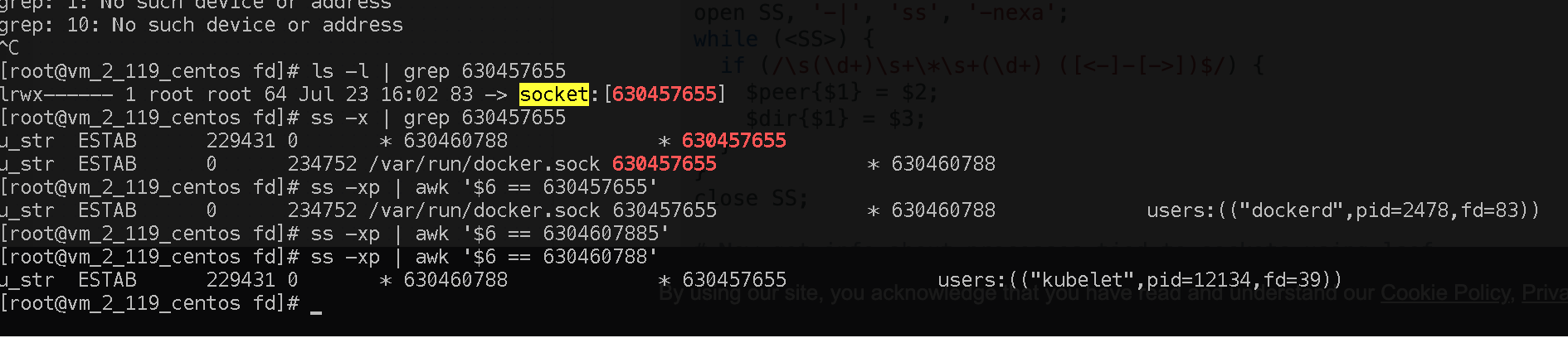
发现该fd为来自kubelet的一个socket连接,且没有被关闭,因此可以判断Write阻塞的原因正是客户端exec退出以后,该socket没有正常的关闭,使Write不断地向socket中写数据,直到写满阻塞造成的。
通过询问客户是否使用过exec,发现客户自己写了一个客户端并通过kubelet exec来访问Pod,与上述排查结果相符,因此反馈客户可以排查下客户端代码,是否正确关闭了exec的socket连接。
修复与反思
其实docker的这个事件处理逻辑设计并不优雅,客户端的行为不应该影响到服务端的处理,更不应该造成服务端的阻塞,因此本打算提交pr修复此问题,发现在docker19中已经修复了此问题,而docker18的集群无法直接升级到docker19,因为docker会持久化数据到硬盘上,而docker19不支持docker18的持久化数据。
虽然不能直接升级到docker19,不过我们可以参考docker19的实现,在docker19中通过添加事件处理超时的逻辑避免事件一直阻塞,在docker18中同样可以添加一个超时的逻辑!
对exit事件添加超时处理:
#/docker/daemon/monitor.go
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
execConfig.StreamConfig.WaitWithTimeout(ctx)
cancel()
#/docker/container/stream/streams.go
func (c *Config) WaitWithTimeout(ctx context.Context) {
done := make(chan struct{}, 1)
go func() {
c.Wait()
close(done)
}()
select {
case <-done:
case <-ctx.Done():
if c.dio != nil {
c.dio.Cancel()
c.dio.Wait()
c.dio.Close()
}
}
}
这里添加了一个2s超时时间,超时则优雅关闭来自containerd的事件流。
至此一个棘手的Pod terminating问题已经解决,后续也将推出小版本修复此问题,虽然修复起来比较简单,但问题分析的过程却无比艰辛,希望本篇文章能够对大家今后的问题定位打开思路,谢谢观看~
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号