【Pod Terminating原因追踪系列之一】containerd中被漏掉的runc错误信息
前一段时间发现有一些containerd集群出现了Pod卡在Terminating的问题,经过一系列的排查发现是containerd对底层异常处理的问题。最后虽然通过一个短小的PR修复了这个bug,但是找到bug的过程和对问题的反思还是值得和大家分享的。
本文中会借由排查bug的过程来分析kubelet删除Pod的调用链,这样不仅仅可以了解containerd的bug,还可以借此了解更多Pod删除不掉的原因。在文章的最后会对问题进行反思,来探讨OCI出现的问题。
一个删除不掉的Pod
可能大家都会遇到这种问题,就是集群中有那么几个Pod无论如何也删除不掉,看起来和下图一样。当然可有很多可能导致Pod卡在Terminating的原因,比如mount目录被占用、dockerd卡死了或镜像中有“i”属性的文件。因为节点上复杂的组件(docker、containerd、cri、runc)和过长的调用链,导致很难瞬间定位出现问题的位置。所以一般遇到此类问题都会通过日志、Pod的信息和容器的状态来逐步缩小排查范围。

当然首先看下集群的信息,发现没有使用docker而直接用的cri和containerd。直接使用containerd照比使用docker会有更短的调用链和更强的鲁棒性,照比使用docker应该更稳定才对(比如经常出现的docker和containerd数据不一致的问题在这里就不会出现)。接下来当然是查看kubelet日志,如下(只保留了核心部分),从这条日志中可以发现貌似是kubelet调用cri接口,最终调用runc去删除容器时报错导致删除失败。
$ journalctl -u kubelet
Feb 01 11:37:27 VM_74_45_centos kubelet[687]: E0201 11:37:27.241794 687 pod_workers.go:190] Error syncing pod 18c3d965-38cc-11ea-9c1d-6e3e7be2a462 ("advertise-api-bql7q_prod(18c3d965-38cc-11ea-9c1d-6e3e7be2a462)"), skipping: error killing pod: [failed to "KillContainer" for "memcache" with KillContainerError: "rpc error: code = Unknown desc = failed to kill container \"55d04f7c957e81fcf487b0dd71a4e50fe138165303cf6e96053751fd6770172c\": unknown error after kill: runc did not terminate sucessfully: container \"55d04f7c957e81fcf487b0dd71a4e50fe138165303cf6e96053751fd6770172c\" does not exist\n: unknown"
接下来我们打算分析下容器当前的状态,简单介绍下,containerd中用container来表示容器、用task来表示容器的运行状态,创建一个容器相当于创建container,而把容器运行起来相当于创建一个task并把task状态置为Running。当然停掉容器就相当于把task的状态设置为Stopped。通过ctr命令看下containerd中container和task的状态,容器55d04f对应的container和task都还在、task状态是STOPPED。接下来查看containerd日志,我们节选了一小部分,发现了如下现象,第一条日志是stop容器55d04f时做umount失败,接下来都是kill容器55d04f时发现container不存在。
error="failed to handle container TaskExit event: failed to stop container: failed rootfs umount: failed to unmount target /run/containerd/io.containerd.runtime.v1.linux/k8s.io/55d04f.../rootfs: device or resource busy: unknown"
error="failed to handle container TaskExit event: failed to stop container: unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"
error="failed to handle container TaskExit event: failed to stop container: unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"
error="failed to handle container TaskExit event: failed to stop container: unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"
当然得到这些信息直觉会认为排查方向是:
- 为何rootfs会被占用,只要找出来是谁在占用rootfs就可以解决问题了
- 既然umount报错,我们是否可以使用lazy umount
- 反正之后containerd还会重试,再后来的重试中是否可以正确删除容器
第一个选项直接被排除了,看起来占用rootfs的进程并不是长期存在,等发现问题登录到节点上排查时进程已经不在了。如果不是常驻进程问题就变得麻烦了,可能是某个周期执行的监控组件,也可能是用户的某个日志收集容器某次收集时间较长在rootfs上多停留了一会。
处于懒惰的本能,我们先尝试下第二个方案。刚刚我们说过容器在containerd中被定义为container和task,查看容器信息时发现task并没有被删掉,于是我们直接在containerd的代码中找到了umount容器rootfs的代码,如下(为了阅读体验,已经简化):
func (p *Init) delete(ctx context.Context) error {
err := p.runtime.Delete(ctx, p.id, nil)
// ...
if err2 := mount.UnmountAll(p.Rootfs, 0); err2 != nil {
log.G(ctx).WithError(err2).Warn("failed to cleanup rootfs mount")
if err == nil {
err = errors.Wrap(err2, "failed rootfs umount")
}
}
return err
}
func unmount(target string, flags int) error {
for i := 0; i < 50; i++ {
if err := unix.Unmount(target, flags); err != nil {
switch err {
case unix.EBUSY:
time.Sleep(50 * time.Millisecond)
continue
default:
return err
}
}
return nil
}
return errors.Wrapf(unix.EBUSY, "failed to unmount target %s", target)
}
containerd创建容器时会创建一个containerd-shim进程来管理创建出来的容器,原本containerd对容器进程的操作就转化成了containerd对shim的RPC调用;而调用runc来操作容器的工作自然就会交给shim来做,这样最大的好处就是可以方便的实现live-restore能力,也就是即使containerd重启也不会影响到容器进程。
上面代码中的 delete函数就是由containerd-shim调用的,函数中主要工作有两个:调用runc delete删掉容器、调用umount卸载掉容器的rootfs。containerd日志中第一次device busy导致的umount失败就是在这里产生的。当然在umount函数中还是有个短暂的重试的,看来社区还是考虑到了偶尔可能会出现rootfs被占用的情况(怀疑是容器进程还没来的急被回收,但在某些场景下,可能这个重试的时间还有点短)。
这里要注意unmount的flags是0,查看docker代码,发现docker在umount时加了MNT_DETACH。在简单地修改了shim的代码后,在节点上测试,果然添加了MNT_DETACH以后就不会出现device busy了。于是自信的向社区提了PR,结果得到的回复却是:
What typically happens in cases like this is you there is a mount marked as private that gets copied into a new mount namespace.
A new mount namespace is created for every container, for systemd services that have MountPropagation or PrivateTmp defined, and these types of things.
When those namespaces are created they get a copy of the root namespace, anything that has a private mount cannot be unmounted until all the namespaces are shut down.
Mounts get marked private depending on the propagation defined on their root mount or if explicitly set.... so for example if you have /var/foo mounted and /var is mounted with mount private propagation, /var/foo will inherit the private propagation.In this case
MNT_DETACHonly detaches the mount and hides very real problems. Even if you remove the mountpoint the data will not be freed until (possibly?) a reboot or all other namespaces with copies of that mount in them are shut down.
大概意思就是如果你用了MNT_DETACH,会有一些真正的问题被藏起来。(这里有待测试,我觉得社区里这个人回复的思路有问题)。
看起来我们只能排查下为什么重试时还会失败了,节点上执行删除Pod的流程还是比较长的,很难简单通过几个举例直接说明问题,所以接下来分析下kubelet从cri到OCI删除容器的流程。
kubelet如何删除Pod中的容器
对于kubelet的分析就要从大名鼎鼎的SyncPod开始分析了,在SyncPod开始时会计算podContainerChanges,接下来整个流程都是根据podContainerChanges的情况来执行对容器的操作。我们假设change就是KillPod,而kubelet执行KillPod会先通过创建多个goroutine并发执行StopContainers,等到所有Containers都删除成功后再删除Pod的Sandbox。具体调用流程如下:
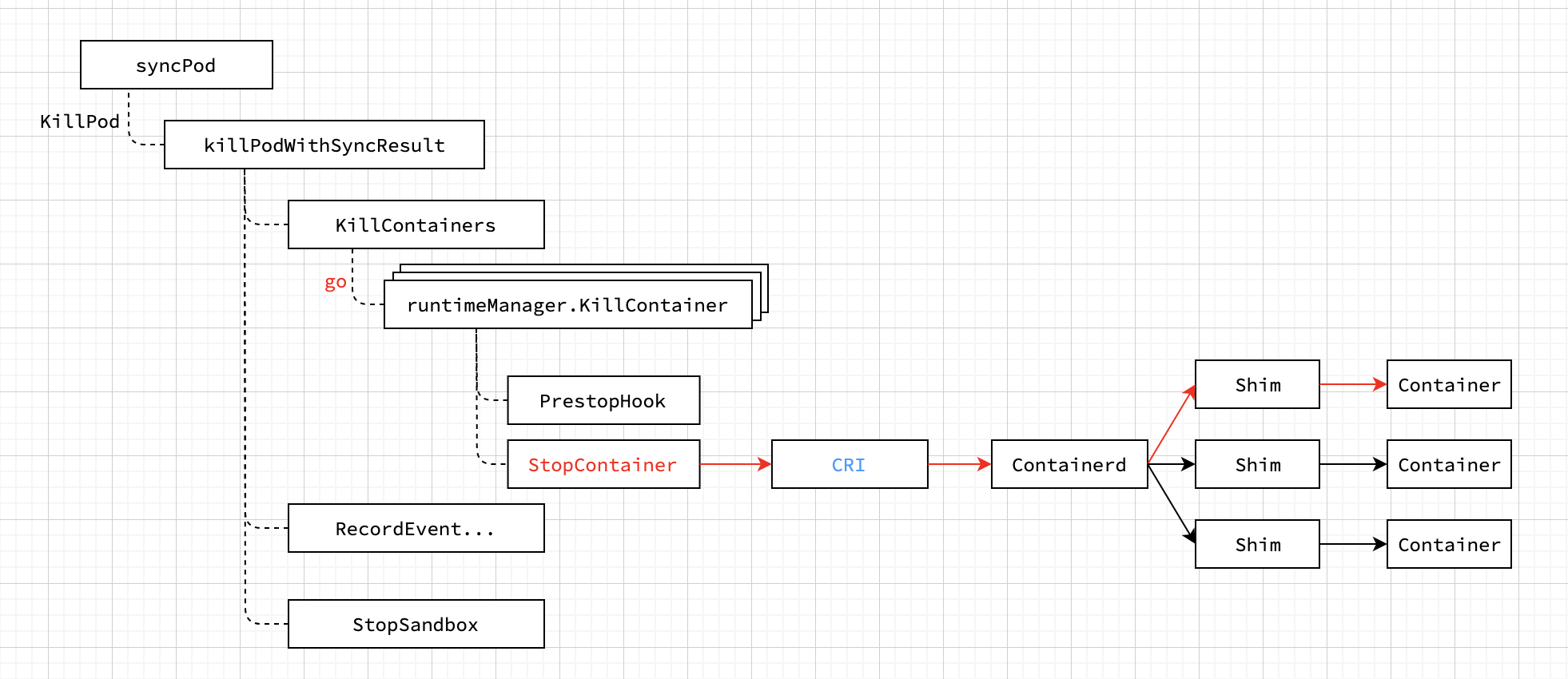
图中用红色标记的StopContainer其实就是最终调用了cri接口(container runtime interface),比如以下是两个和删除容器相关的两个cri接口,Kubernetes要求每种容器运行时都要实现cri接口。docker通过docker-shim实现了cri接口;而container通过cri插件实现了cri接口,两者并没区别。比如运行时是containerd时,对cri的调用就会通过containerd-shim最终在容器上产生影响。
// StopContainer stops a running container with a grace period (i.e., timeout).
// This call is idempotent, and must not return an error if the container has
// already been stopped.
// TODO: what must the runtime do after the grace period is reached?
StopContainer(context.Context, *StopContainerRequest) (*StopContainerResponse, error)
// RemoveContainer removes the container. If the container is running, the
// container must be forcibly removed.
// This call is idempotent, and must not return an error if the container has
// already been removed.
RemoveContainer(context.Context, *RemoveContainerRequest) (*RemoveContainerResponse, error)
当请求到了cri后,剩下的任务就都交给了containerd和containerd-cri。cri以插件的方式运行在containerd中,本质和containerd是同一个进程,因此可以通过containerd提供的client直接通过函数调用containerd提供的service。正常情况下整个调用链如下图所示。
另外,cri插件中存在一个eventloop专门处理从containerd中获取的event。比如当容器删除后,会收到TaskExit事件,这是cri会做清理工作;比如当容器oom时,会收到OOMKill事件,cri除了清理还会更新Reason。接下来我们了解下整个删除流程
- 当kubelet调用cri的StopContainer接口后,cri会调用containerd的
task.Kill接口(这里的task就是containerd中用来表示容器运行状态的模块),containerd收到请求后会调用containerd-shim的kill接口,而containerd-shim会通过命令行工具runc来kill掉容器进程。runc虽然不是守护进程,但是也有部分数据会被持久化到文件系统中,执行runc kill后,不只会给容器进程发送信号,同时还会修改runc的持久化数据。另外,当容器进程被干掉后,会被父进程shim回收掉。 - shim成功干掉容器后,会给cri发送TaskExit的事件。当cri收到事件后会调用containerd的
task.Delete接口,这个接口会先通过shim清理runc保留的容器持久化数据和容器运行时所用的rootfs。当两者都被清理后,shim留着也没用了,这时干脆直接发信号kill掉shim,并清理掉containerd保存的task信息。这时containerd中和容器状态相关的信息就都消失了,当然containerd中的container还完好无损。 - 哪怕代码中不存在bug,这么长的调用链也可能会遇到系统问题。eventLoop调用
task.Delete如果返回错误会把当前的event放到一个backoff队列,等过一段时间拿出来重试。这样就保证哪怕当前对一个容器的操作失败了,过段时间还可以重试。
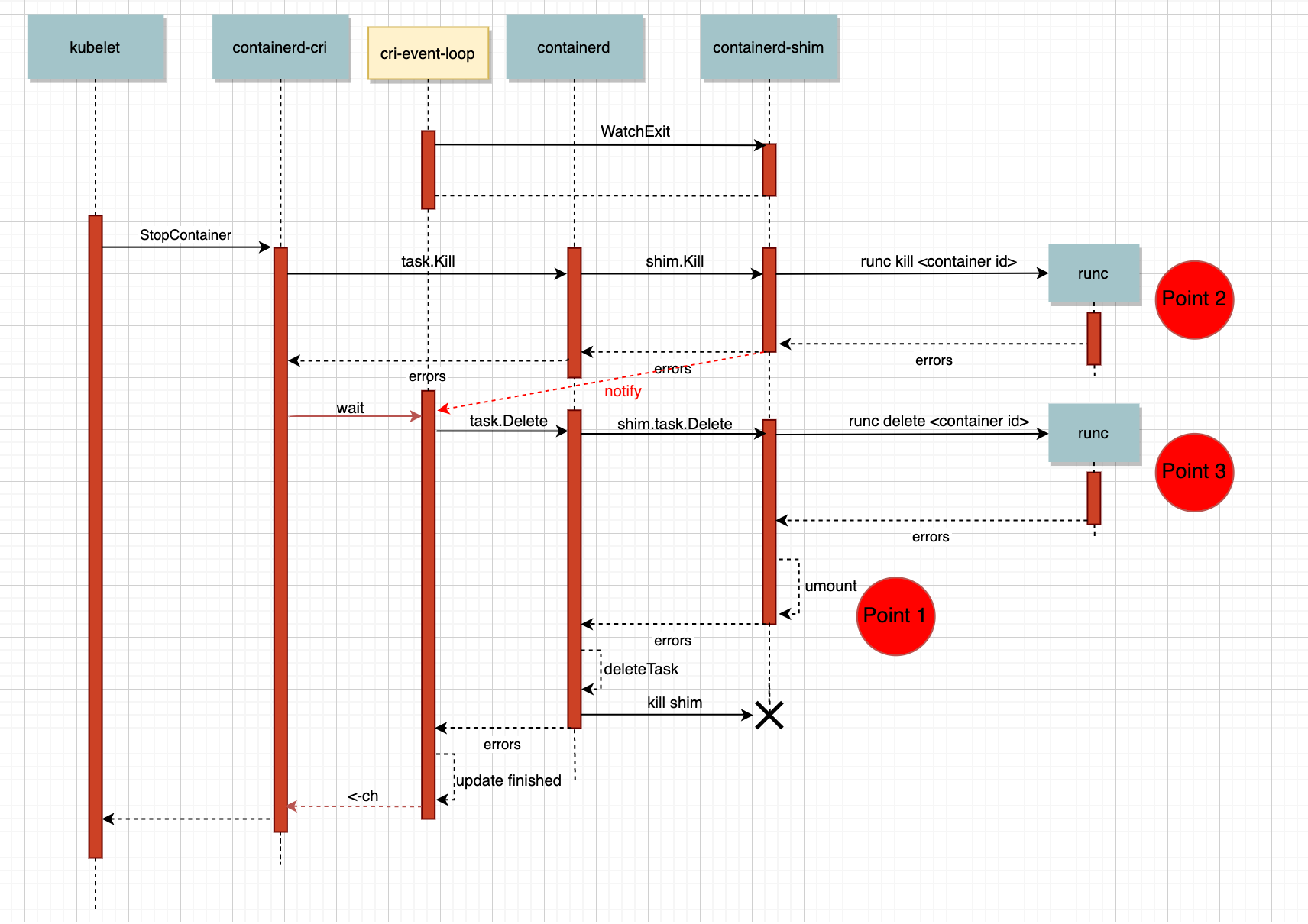
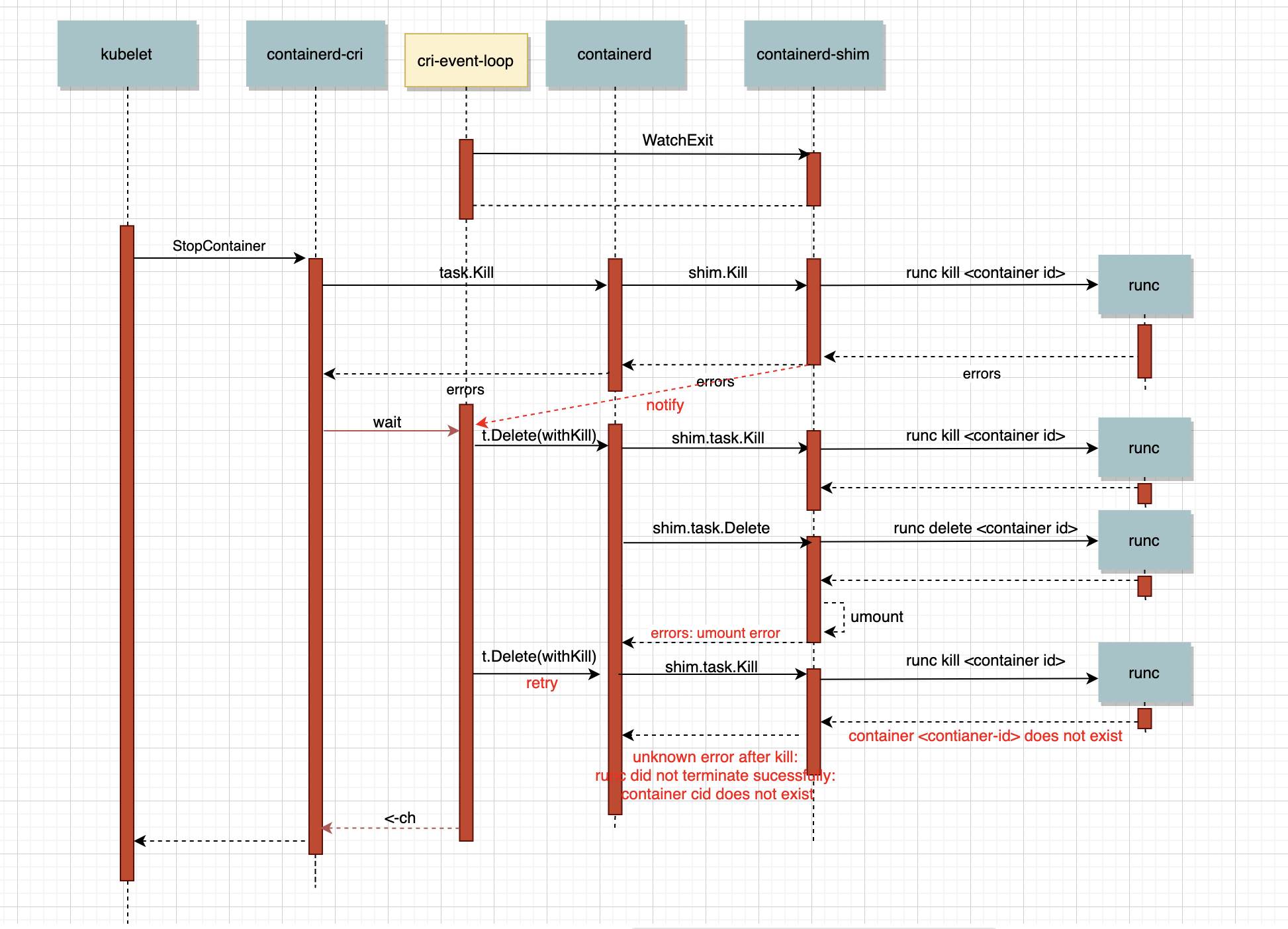
回到之前的问题上,可能有些聪明的同学通过上面的流程图和分析之前的日志就可以猜到答案了。没猜到也没关系,现在和大家一起分析下。还记的当时containerd的日志分成两部分么,首先是执行umount报错device busy,之后反复出现unknown error after kill: runc did not terminate sucessfully: container "55d04f..." does not exist"。这两部分和我们上面说的“delete task时清理rootfs,如果失败了会隔段时间进行重试”这个表述很接近。我们再把调用的流程图画的更细点,这下应该就可以在图中找到答案了。
当容器被kill掉之后还一切正常,cri收到了容器退出的信号,调用containerd的task.Delete()时,可以注意到,这里多了个withKill选项(上面的流程中其实也有,只不过被省略掉了)。添加这个选项会在调用shim的Delete接口之前再次调用Kill,这样可以防止Delete了正在运行的容器,算是“悲观”的决定。
在第一次task Delete的流程中,一切运行的都很顺畅,runc kill掉一个已经挂掉的容器也没什么问题。直到umount容器的rootfs,发现rootfs被占用了,而且在umount的50次重试中占用rootfs的进程并没有退出,shim只好通过containerd向cri返回一个错误。cri会在之后的一段时间里重新尝试处理刚刚的这个event。
在接下来重试 task Delete中,会和第一次执行一样,都会在delete之前执行kill。但由于第一次runc delete成功的删除了runc所持久化的容器信息,重试时执行runc kill会报错container does not exist。不巧的是shim和containerd并没有特别处理这个错误信息,而是直接返回给了cri。这就导致了cri删除容器会失败,并且再也无法umount容器的rootfs了。cri中的容器无法被删掉,自然发起删除流程的syncPod也会出现问题,这样最终就导致了Pod卡在了Terminating。
最终修复与反思
当然这里的修复也很简单,只需要在调用runc kill后添加特殊判断就可以了,具体修复的pr见https://github.com/containerd/containerd/pull/4214,目前已经合并到主干,并且回溯到1.2的版本中了。很多时候发现问题远比修复问题要复杂的多,虽然最终修复bug的代码很简单,但是整个为了发现bug,我们用了好几天时间来分析梳理整个流程。简单看下错误处理的代码,这里的error就是调用runc出现错误的返回结果。
if strings.Contains(err.Error(), "os: process already finished") ||
strings.Contains(err.Error(), "container not running") ||
strings.Contains(strings.ToLower(err.Error()), "no such process") ||
err == unix.ESRCH {
return errors.Wrapf(errdefs.ErrNotFound, "process already finished")
} else if strings.Contains(err.Error(), "does not exist") {
// we add code here !
return errors.Wrapf(errdefs.ErrNotFound, "no such container")
}
return errors.Wrapf(err, "unknown error after kill")
}
显而易见这坨代码存在问题:
containerd-shim原本目的就是支持各种OCI工具,但是却把runc的错误处理信息写死在调用OCI的路径上,这样最终可能导致shim只能为runc服务,而不好适配其他的OCI。比如完善containerd测试时就会发现这坨代码对crun并不work(crun是用纯c语言实现的OCI工具)。不可能在containerd中适配每一种OCI工具,所以问题还是出现在制定OCI规范时没考虑到错误处理的情况,同样我们也和OCI社区提了issue。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号