PostgreSQL 那些值得尝试的功能,你知道多少?
原文:PostgreSQL Features You May Not Have Tried But Should
链接:
https://pgdash.io/blog/postgres-features.html
译者:Rhys_Lee, xiaoaiwhc1, 边城, ljwheyxy, lnovonl
审校:开源中国,转载请注明来源
PostgreSQL包含许多重要的功能。他们中的许多人都非常知名。其他人可以是非常有用的,但没有广泛赞赏。以下是我们首选的PostgreSQL功能,您可能没有仔细看过,但实际上应该这样做,因为它们可以帮助您更快地将代码投入生产,使操作更轻松,并且通常可以使用更少的代码和劳动来完成任务。
发布/订阅通知
PostgreSQL带有一个简单的非持久基于主题的发布 - 订阅通知系统。它不是Kafka,但功能确实支持常见用例。
关于特定主题的消息可以广播给正在监听该主题的所有连接的订阅者。这些消息被 Postgres服务器推送给侦听客户端。轮询不是必需的,但您的数据库驱动程序应支持异步向应用程序传递通知。
通知由主题名称和有效负载组成(最多约8000个字符)。有效载荷通常是一个JSON字符串,但它当然可以是任何东西。您可以使用NOTIFY命令发送通知 :

或者 pg_notify() 函数:

订阅发生在 LISTEN 命令中,但通常您必须使用驱动程序特定的 API。
表继承
假如有一张叫 “invoices(发票)” 的表。你现在想支持 “government invoices(政府发票)”,这种发票在原来的发票之上添加了一些字段。该如何建模?是在 invoices 表中添加若干可空字段,还是增加一个可空的 JSON 字段?不妨试试继承功能:

上述模型反映出了政府发票就是发票,但比发票多一些属性的情况。上面的 “government_invoices” 表总共有 3 列:
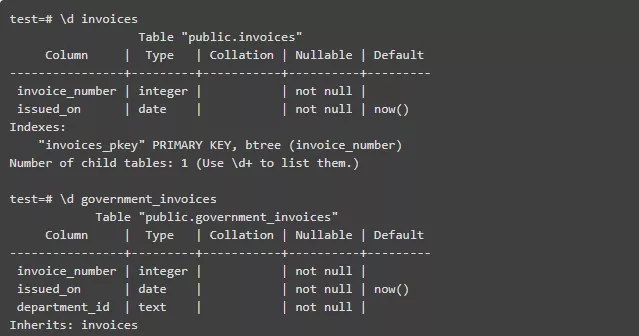
为它添加数据行就跟独立表一样:

不过观察一下 SELECT 时的情况:
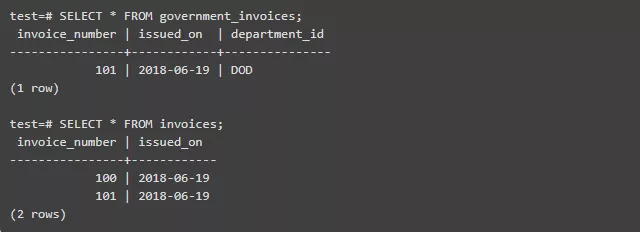
子表添加的编号为 101 的发票,也父表中也列出来了。这样做的好处是在父表中进行的各种算法In完全以忽略子表的存在。
从这个文档可以了解到更多关于 PostgreSQL 继承方面的内容:
-
https://www.postgresql.org/docs/current/static/ddl-inherit.html
外部数据包装器
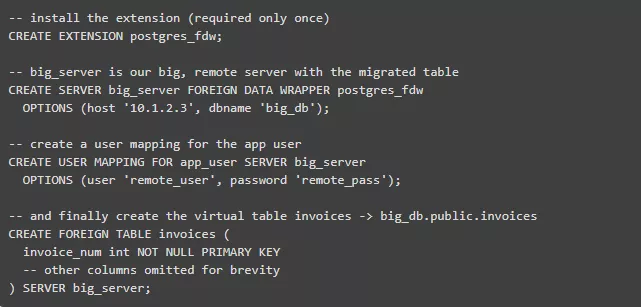
你知道你可以有一张虚表用来指向另一个PostgreSQL实例吗?或者另一个SQLite、MongoDB、Redis甚至其它的数据库?这个功能叫做外部数据包装器(FDW),它提供一个标准化的方法来存取和操作连接到Postgres服务器的外部数据源。有各种各样的FDW实现让你可以连接到不同的数据源,它们通常被打包为扩展插件。
标准Postgres分发包中有一个postgres_fdw扩展,它可以让你连接到其它Postgres服务器。例如,你可以移动一张大表到其它服务器,同时在本地建立一张虚表(正确的术语叫做"外部表"):
这个Wiki有一个很好的列表列出了许多FDW的有效实现:
-
https://wiki.postgresql.org/wiki/Foreign_data_wrappers
除了可以从其它服务器存取数据,FDW也被用作实现交互存储层,比如 cstore_fdw.
还有一个dblink扩展,它是另一种用来存取远程PostgreSQL数据的实现。
拆分表
从版本 10 开始,PostgreSQL 原生支持将一个表拆分成多个子表,其拆分基于对一列或多列数据的计算来进行。这一功能可以让一个巨大的表在物理上存储于多个表中,改善DML性能和存储管理。
下面演示了如何创建拆分表,该演示会为每个月的数据增加一张表:
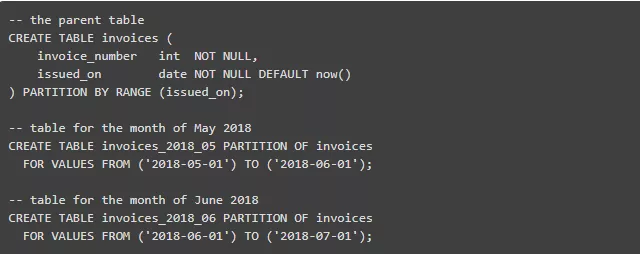
子表必须由人工或通过程序创建,这个创建过程不会自动发生。
你可以在父级表中查询或插入数据,PostgreSQL 会自动到子表中去进行操作,来看一下:
先插入两行数据:

可以看到数据实际被插入到了子表中:

但在父表中也可以完成查询,返回合并的结果:

拆分方法与继承相似(在父表级别查询),但也存在一些区别(比如在拆分父表中没有保存数据)。你可以在这个文档中阅读到更多相关内容:
-
https://www.postgresql.org/docs/current/static/ddl-partitioning.html
已经进入 Beta 阶段的 PostgreSQL 11 对这一功能会有所改进,这篇文章对此进行了叙述:
-
https://pgdash.io/blog/partition-postgres-11.html
区间类型
你以前与温度范围、日程表、价格区间或类似的数值范围打过交道吗?如果是,那你就会有这样的经验:看似简单的问题总会导致你抓耳挠腮并且经常深夜调试bug。以下是一个包含区间列的表和一些数值:
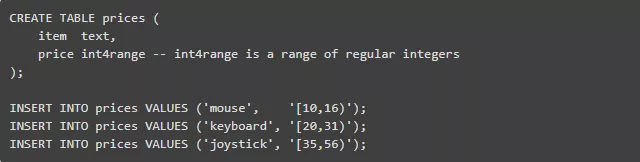
在错配方括号中的数值代表半开区间。以下是一个查询语句,它可以找出在价格区间15$~30$中的所有项,使用了&&操作符(区间交错):
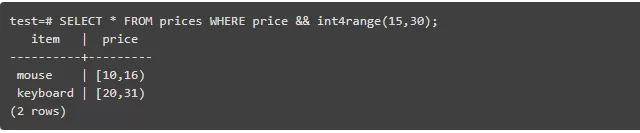
为了让你印象深刻,你可以尝试一下使用无区间类型的查询语句有多难(试试就好)。
区间类型非常强大 --- 这里还有操作符、函数,你也可以定义你自己的区间类型,甚至还可以索引它们。
数组类型
PostgreSQL很久以前就已经支持数组类型了。数组类型可以精简应用代码并可以简化查询操作。以下是一个在表中使用数组列的例子:

假设每一行代表一篇博客,每篇博客又都有一个标签集,下面是我们如何列出所有带“postgres”和"go"标签的博客的代码:

这里数组类型的使用使我们的数据模型更精确,同时也简化了查询操作。Postgres数组总是与操作符和函数一起出现,其中也包括集合函数。你也可以基于数组表达式创建索引。
触发器
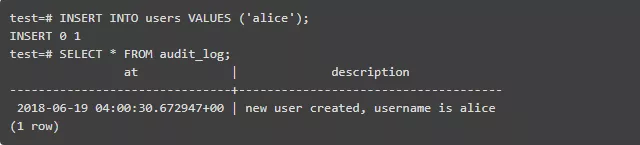
当对表中的行进行插入、更新或删除操作时,你能请求PostgreSQL执行一个特殊的函数,这个函数甚至可以在插入过程中修改值。以下是一个例子:当创建用户时,触发器发出通知并写入稽核日志。

现在,如果你尝试增加一个新用户,一个稽核日志记录将会被自动添加。
pg_stat_statements
pg_stat_statements是一个扩展插件,默认在PostgreSQL分发包中就已经包含了,只是默认没有启用。这个扩展记录了每条执行语句的健康信息,包括执行时长、内存使用、磁盘IO初始化等。对于需要了解和调试查询性能的场景它是不可或缺的一个扩展。
安装和启用这个扩展的开销非常小,它也非常易于使用,因此没有理由不在你的生产server中使用这个扩展。
哈希,GIN还有BRIN索引
PostgreSQL中默认的索引类型是B-Tree,有记录表示也有其他类型。其他索引类型在非常不常见的情况下非常有用。特别是设置散列,GIN和BRIN类型的索引可能只是解决您的性能问题:
-
散列:与具有固有排序的B树索引不同,散列索引是无序的,只能执行相等匹配(查找)。然而,散列索引占用更小的空间并且比平等匹配的B树更快。 (另外,请注意,在PostgreSQL 10之前,不可能复制散列索引;它们未被记录。)
-
GIN:GIN是一个倒排索引,它基本上允许单个键的多个值。 GIN索引对索引数组,JSON,范围,全文搜索等非常有用。
-
BRIN:如果您的数据具有特定的自然顺序(例如时间序列数据),并且您的查询通常只适用于其中的一小部分范围,那么BRIN索引可以以很小的开销加快查询速度。 BRIN索引维护每个数据块的范围,允许优化器跳过包含不会被查询选中的行的块。
在这里开始阅读关于PostgreSQL索引类型。
全文本搜索
PostgreSQL也很好地支持全文本搜索,甚至支持除英语之外的语言。这里有一篇文章教你如何基于PostgreSQL用Go语言一步步创建一个全文本搜索查询:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号