Node.js自学完全总结
零、什么是Node.js?
引用Node.js官方网站的解释如下:
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient.
翻译成中文就是:
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。
1、 运行环境(Runtime)
如果做一个类比,Node.js与JavaScript关系,就像JDK(Java Development Kit)与Java的关系。
总的来说,Node.js不是一门语言,而是用来进行Web开发的Runtime。
2、事件驱动(Event-driven)
在前端web开发中比较常见的事件驱动例子是,给一个按钮绑定一个事件处理程序,这个事件处理程序就是事件驱动的,JavaScript进程并不知道什么时候调用它,点击按钮,触发Click事件,此时主程序得到相应的通知,就知道调用绑定的的事件处理程序了。
因为Node.js是JavaScript的Runtime,所以天然就可以使用这种模式通知主进程的I/O 完成。
3、非阻塞式 I/O(Non-blocking I/O)
阻塞:I/O 时进程休眠等待 I/O 完成后进行下一步
非阻塞:I/O 时函数立即返回,进程不等待I/O 完成
一、Node.js 究竟好在哪里?
1、为什么偏爱Node.js
① 前端需求变得重要、职责范围变大,统一开发体验
② 在处理高并发、I/O 密集型场景性能优势明显
Node.js 使用了事件驱动和非阻塞的 I/O 模型,使 Node 轻量高效,非常适合 I/O 密集的 Web 场景。
CPU密集型 VS I/O密集型
CPU密集型:计算等逻辑判断的操作,如:压缩、解压、加密和解密等。
I/O 密集型:存取设备,网络设施的读取操作,如:文件的存取,http等网络操作,数据库操作等。
2、Web常见场景
① 静态资源读取
html,css,js等文件的读取
② 数据库操作
把数据存取到物理设磁盘或内存中
③ 渲染页面
读取模板文件,根据数据生成html
3、高并发应对之道
高并发,简而言之就是单位时间内访问量特别大。
对应生活中的场景,一家菜馆做菜招待顾客,老板刚开始就雇了一个厨师,做菜好吃不贵,顾客很多,顾客排好一条队,然后顾客选好菜,厨师拿到菜单开始做菜,做好菜,给顾客端上来,再招待下个顾客。

客人增多,一个厨师忙不过来了,老板于是又招了2个厨师,这样顾客可以排3条队,快了很多。
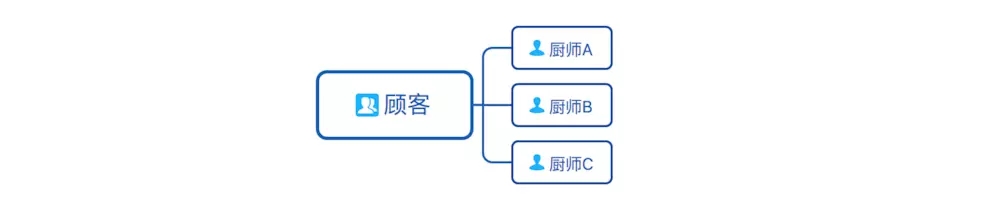
随着菜馆名气增大,顾客越来越多,老板本想再用之前的方法多招几个厨师,但是老板想,多招厨师好像不太划算,有些厨师做饭快,有些做饭慢,经过调查,老板发现做饭快2倍的厨师只需要花费原来厨师工资的1.5倍,于是精明的老板炒掉了原来的3个厨师,招来了比原来厨师做饭速度快2倍的另外3个厨师,菜馆比之前运转的更好了。
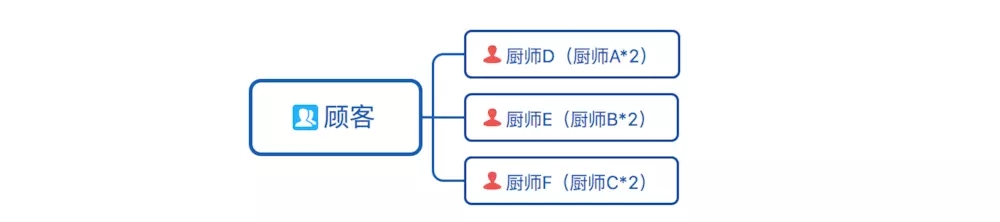
回到Web开发场景,厨师就是物理服务器,应对高并发的方法如下:① 增加机器数
机器多了,流量还是一样的大,通过Nginx负载均衡分到不同的机器上处理
② 增加每台机器的CPU数——多核
单位机器,核数增多,运算能力增强了
4、进程与线程
进程在百度百科中的解释如下:
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
换成正常的人话就是:电脑桌面的程序,如QQ音乐,当我们双击图标时,实际上是把这个程序加载到内存中执行,我们称这个执行中的程序就是进程,操作系统都是用进程作为基本单位进行分配和调度的。
多进程:启动多个进程,多个进程可以一块执行多个任务。
线程,进程内一个相对独立的、可调度的执行单元,与同属一个进程的线程共享进程的资源。
多线程,启动一个进程,在一个进程内启动多个线程,这样,多个线程也可以一块执行多个任务。
5、Node.js工作模型
传统的server处理请求(如多线程高并发模式的Apache)对应生活中的场景,如下:
一个老板开了一家饭店,不同于之前那个菜馆,这家的每个厨师配备了一个服务员,专门负责点菜,然后把菜单给厨师,厨师负责做菜,做完后给服务员,服务员端给客人,然后再接待顾客队伍中的下一个。
如果这个饭店是Web的话,点菜这个动作很快,相当于CPU的运算,如访问一个静态资源,CPU运算后知道是哪个文件了,去相应盘读取,类似于厨师做饭,是一个相对较慢的阻塞I/O操作,当顾客很多时候就相当于高并发了。忙不过来的时候,可以选择增加厨师数量和服务员数量,即并发多进程处理多个请求的概念。
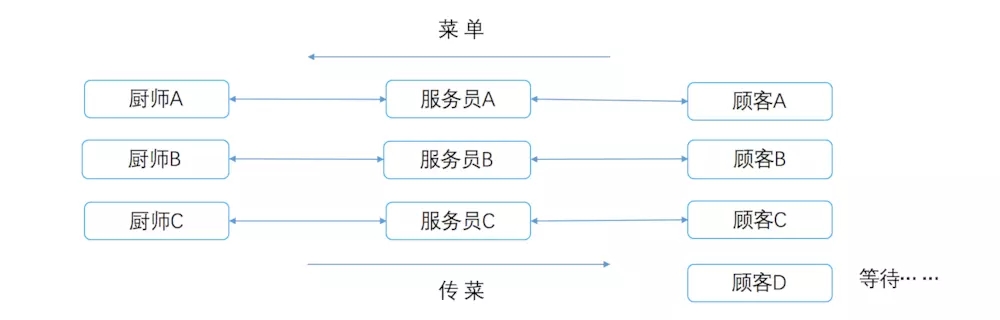
但是这个饭店老板慢慢发现,增加服务员和厨师的同时,饭店的空间是有限的,慢慢的变得拥挤(阻塞),而且更为头疼的是另一个问题:服务员太悠闲了,2分钟就把点菜的事干完了,厨师做菜10分钟,那他就有8分钟在那干等着,没事干,因为厨师没把菜做完给他,他也不能接待下一个顾客。
同样类似于Apache开发web时候,CPU分配的最大进程数是有限的,并不能没完没了的分配进程的,并发到一定数目的时候,必须得排队(阻塞)了,更大的问题是,CPU处理的速度远远快于I/O,在Web场景中,CPU运用场景很少,大头都在I/O上,CPU大部分进程情况下都是在等待,等待I/O,CPU的资源被浪费掉了,相当于饭店的服务员一直干等着没事干。
Node.js很好的解决了上面的问题👆👆👆,来看下Node.js对应的生活中的场景,如下:
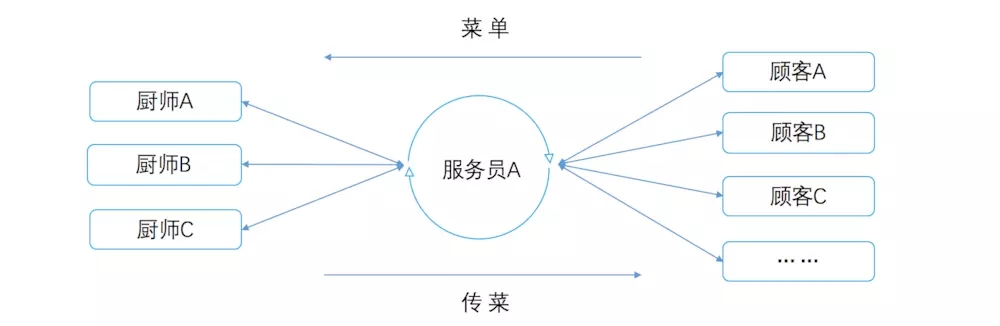
另一个老板也开了一家饭店,这家饭店只雇佣了一个服务员,这个服务员接待所有的顾客,顾客来了依次点菜,点完菜拿个号找地方坐着去了,然后服务员把菜单交给厨师们,然后再去给下一波客人点菜下单,等后厨什么时候说,服务员几号的菜好了,然后服务员端好菜给制定号码的顾客,无论哪个顾客来了立刻相应,厨师一直做菜,服务员一直接单,顾客的体验也比上一家要好,不用等到上一个顾客拿到菜才开始点单等待。对应Web体验就是:一直在那转圈等待,要比直接显示连不上要好。
同样在Node.js中,用户(顾客)发来请求,有一个主进程(服务员),对应有一个事件轮询(Event Loop),来处理用户的各种请求过来的进程(菜单),如qq音乐(小葱拌豆腐),Photoshop(鱼香肉丝)等,然后给Worker threads即多线程(厨师)的去处理,处理完后完成回调(上菜),CPU的利用率达到最大。在Node.js中,一个CPU上只开一个进程,一个进程里只有一个线程。
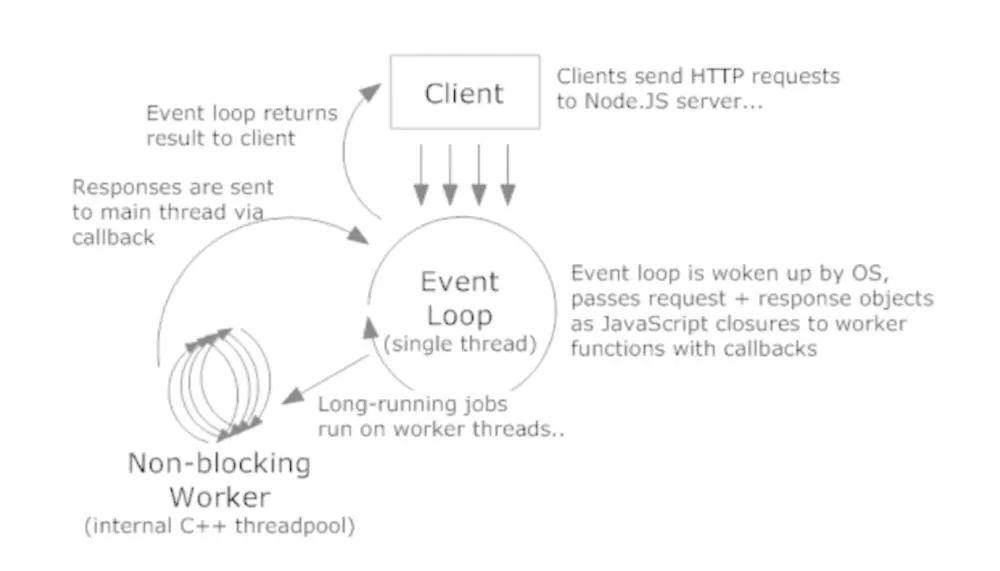
6、Node.js单线程
Node.js单线程指的是,一个CPU上只开一个进程,一个进程里只有一个线程。但这个单线程只是针对主进程,I/O 等其它各种异步操作都是操作系统底层在多线程调度的 。Node.js就是主进程发起一个请求,请求交给I/O 之后,是由操作系统底层多进程多线程进行调度,然后达到最佳性能。
Node.js是单线程的,但是不要理解为它做所有事都是单线程的,有一部分不是自己做的,而是交给操作系统做的,它只负责单进程的在那听,操作系统好了,就告诉它单进程的做另外的事情,操作系统怎么处理I/O,它不管。
单线程并不就是单进程,Node.js有个多核处理模块叫cluster,专门用来处理多CPU,CPU如果有8个核,用了cluster之后,Node.js就启了8个进程,不会浪费CPU的能力。
7、Node.js能干嘛
- Web Server
- 本地代码编译构建(grunt、babel等工具都是基于Node.js开发的)
- 实用工具的开发(爬虫等)
三、Node.js的基础API
1、path(路径)
path 模块提供了一些工具函数,用于处理文件与目录的路径。可以通过以下方式使用:
const path = require('path');
path常用方法:
① path.normalize(path)
会规范化给定的 path,并解析 '..' 和 '.' 片段,如:
const { normalize } = require('path');
console.log(normalize.('/usr///local/bin')); // /usr/local/bin
console.log(normalize.('/usr//local/../bin')); // /usr/bin
/*或者这样写:
const path = require('path');
console.log(path.normalize.('/usr///local/bin'));
*/
② path.join([...paths])
使用平台特定的分隔符把全部给定的 path 片段连接到一起,并规范化生成的路径,也能解析 '..' 和 '.' ,如:
const { join } = require('path');
console.log(join.('/usr', 'local', 'bin/')); // /usr/local/bin
console.log(join.('/usr', '../local', 'bin/')); // /usr/bin
③ path.resolve([...paths])
会把一个路径或路径片段的序列解析为一个绝对路径,如:
const { resolve } = require('path');
console.log(resolve.('./')); // /Users/peng/Desktop 返回当前路径的绝对路径
④ path.basename(path[, ext])
返回文件名
path.dirname(path) 返回所在文件夹名
path.extname(path) 返回扩展名
const { basename, dirname, extname } = require('path');
const filePath = '/usr/local/bin/test.html';
console.log(basename.(filePath)); // test.html
console.log(dirname.(filePath)); // /usr/local/bin
console.log(extname.(filePath)); // .html
⑤ path.parse(path)
返回一个对象,对象的属性表示 path 的元素
path.format() 会从一个对象返回一个路径字符串。 与 path.parse()方法相反
const { parse, format } = require('path');
const filePath = '/usr/local/bin/test.html';
const ret = parse(filePath);
console.log(ret);
/*
{ root: '/',
dir: '/usr/local/bin',
base: 'test.html',
ext: '.html',
name: 'test' }
*/
console.log(format(ret)); // /usr/local/bin/test.html
另外:
__dirname、__filename总是返回文件的绝对路径
process.cwd()总是返回执行node命令所在的文件夹
2、Buffer (缓冲)
Buffer 类被引入作为 Node.js API 的一部分,使其可以在 TCP 流或文件系统操作等场景中处理二进制数据流。
Buffer 类的实例类似于整数数组,但 Buffer 的大小是固定的、且在 V8 堆外分配物理内存。 Buffer 的大小在被创建时确定,且无法调整。
Buffer 类在 Node.js 中是一个全局变量(global),因此无需使用require('buffer').Buffer。
常用方法:
① Buffer.byteLength()
返回一个字符串的实际字节长度。 这与 String.prototype.length不同,因为那返回字符串的字符数。
console.log(Buffer.byteLength('test')); // 4
console.log(Buffer.byteLength('中国')); // 6
② Buffer.from(array)
通过一个八位字节的 array 创建一个新的 Buffer ,如果 array 不是一个数组,则抛出 TypeError 错误。
console.log(Buffer.from([1, 2, 3])); // <Buffer 01 02 03>
③ Buffer.isBuffer(obj)
如果 obj 是一个 Buffer 则返回 true ,否则返回 false
console.log(Buffer.isBuffer({ 'a': 1 })); // false
console.log(Buffer.isBuffer(Buffer.from([1, 2, 3]))); // true
④ Buffer.concat(list)
如果 obj 是一个 Buffer 则返回 true ,否则返回 false
const buf1 = Buffer.from('hello ');
const buf2 = Buffer.from('world');
const buf = Buffer.concat([buf1, buf2]);
console.log(buf.toString()); // hello world
常用属性:
① buf.length 长度
buf.toString() 转为字符串
buf.fill() 填充
buf.equals() 判断是否相等
buf.indexOf() 是否包含,如果包含返回位置值,不包含返回-1
const buf = Buffer.from('hello world');
const buf2 = Buffer.from('hello world!');
console.log(buf.length); // 15
console.log(buf.toString()); // hello world
console.log(buf.fill(10, 2, 6)); // <Buffer 68 65 0a 0a 0a 0a 77 6f 72 6c 64> 这里从第3个到第6个都被替换成了0a,a就是16进制的数字10
console.log(buf.equals(buf2)); // false
console.log(buf.indexOf('h')); // 0
3、events(事件)
大多数 Node.js 核心 API 都采用惯用的异步事件驱动架构,其中某些类型的对象(触发器)会周期性地触发命名事件来调用函数对象(监听器)。
所有能触发事件的对象都是 EventEmitter 类的实例。 这些对象开放了一个 eventEmitter.on() 函数,允许将一个或多个函数绑定到会被对象触发的命名事件上。 事件名称通常是驼峰式的字符串,但也可以使用任何有效的 JavaScript 属性名。
官网例子:一个绑定了一个监听器的 EventEmitter 实例。 eventEmitter.on() 方法用于注册监听器,eventEmitter.emit() 方法用于触发事件。
const EventEmitter = require('events');
class CustomEvent extends EventEmitter {}
const myEmitter = new CustomEvent();
myEmitter.on('error', err => {
console.log(err);
})
myEmitter.emit('error', new Error('This is an error!'));
当有一个错误的时候,会显示Error: This is an error!,然后显示具体错误内容。
4、fs(文件系统)
通过 require('fs') 使用该模块。 所有的方法都有异步和同步的形式。
异步方法的最后一个参数都是一个回调函数。 传给回调函数的参数取决于具体方法,但回调函数的第一个参数都会保留给异常。 如果操作成功完成,则第一个参数会是 null 或 undefined。
常用方法如下:
① fs.readFile(path[, options], callback)
异步地读取一个文件的全部内容
const fs = require('fs');
fs.readFile('./test.txt', (err, data) => {
if (err) throw err;
console.log(data);
});
此时如果test.txt文件内容只有一个字母a,那么打印出来的就是<Buffer 61>
回调有两个参数 (err, data),其中 data 是文件的内容。如果未指定字符编码,则返回原始的 buffer。
指定编码格式后,就会按照编码格式打印文件内容:
const fs = require('fs');
fs.readFile('./test.txt', 'utf-8',(err, data) => {
if (err) throw err;
console.log(data);
});
此时如果test.txt文件内容只有一个字母a,那么打印出来的就是a
② fs.writeFile(file, data[, options], callback)
异步地写入数据到文件,如果文件已经存在,则替代文件。
const fs = require('fs');
fs.writeFile('message.txt', 'Hello Node.js', (err) => {
if (err) throw err;
console.log('The file has been saved!');
});
③ fs.stat(path,callback)
可用来判断一个文件是否存在
回调有两个参数 (err, stats),其中 stats是一个 fs.Stats对象。
const fs = require('fs');
fs.stat('./message.txt', (err, stats)=>{
if (err){
console.log('文件不存在');
return;
};
console.log(stats.isFile()); // true 判断是否是一个文件
console.log(stats.isDirectory()); // false 判断是否是一个文件夹
});
④ fs.rename(oldPath, newPath, callback)
用来修改文件名
const fs = require('fs');
fs.rename('./message.txt', 'm.txt', err=>{
if (err) throw err;
console.log('修改成功!');
})
⑤ fs.unlink(path, callback)
删除文件
const fs = require('fs');
fs.unlink('./m.txt', err=>{
if (err) throw err;
console.log('删除成功!');
})
⑥ fs.readdir(path[, options], callback)
读取指定路径下的所有文件
const fs = require('fs');
fs.readdir('./', (err, files)=>{
if (err) throw err;
console.log(files);
/*
[ '.DS_Store',
'node_modules',
'package.json',
'test.js',
'test.txt' ]
*/
})
⑦ fs.mkdir(path[, mode], callback)
在指定路径里创建一个文件夹
const fs = require('fs');
// 在当前目录创建一个叫test的文件夹
fs.mkdir('./test', err=>{
if (err) throw err;
console.log('文件夹创建成功');
})
⑧ fs.rmdir(path, callback)
删除指定路径下的文件夹
const fs = require('fs');
fs.rmdir('./test', err=>{
if (err) throw err;
console.log('文件夹删除成功');
})
⑨ fs.watch(filename[, options][, listener])
和gulp里的watch很像,用来监视 filename的变化,filename 可以是一个文件或一个目录。
监听器回调有两个参数 (eventType, filename)。 eventType 可以是 'rename' 或 'change',filename 是触发事件的文件的名称。
const fs = require('fs');
fs.watch('./', {
recursive: true // 指明是否全部子目录应该被监视
}, (eventType, filename) =>{
console.log(eventType, filename);
})
注意,在大多数平台,当一个文件出现或消失在一个目录里时,'rename' 会被触发。
⑩ fs.createReadStream(path[, options])
返回一个新建的 ReadStream 对象
const fs = require('fs');
const rs = fs.createReadStream('./test.txt');
rs.pipe(process.stdout); // 在终端输出test.txt内容
作者:JokerPeng
链接:https://www.jianshu.com/p/22f62a08559f
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号