spring boot 2.x 系列 —— spring boot 整合 kafka
文章目录
一、kafka的相关概念:
1.主题和分区
2.分区复制
3. 生产者
4. 消费者
5.broker和集群
二、项目说明
1.1 项目结构说明
1.2 主要依赖
二、 整合 kafka
2.1 kafka基本配置
2.2 KafkaTemplate实现消息发送
2.3 @KafkaListener注解实现消息的监听
2.4 测试整合结果
三、关于多消费者组的测试
3.1 创建多分区主题
3.2 多消费者组对同一主题的监听
3.2 发送消息时候指定主题的具体分区
3.4 测试结果
四、序列化与反序列化
源码Gitub地址:https://github.com/heibaiying/spring-samples-for-all
一、kafka的相关概念:
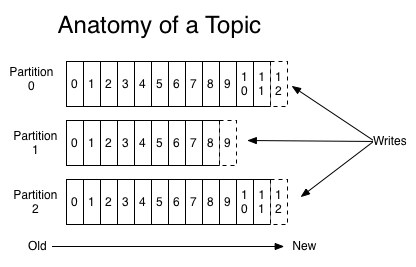
1.主题和分区
kafka 的消息通过主题进行分类。一个主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。kafka通过分区来实现数据的冗余和伸缩性,分区可以分布在不同的服务器上,也就是说一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能(类比HDFS分布式文件系统)。
注意:由于一个主题包含多个分区,因此无法在整个主题范围内保证消息的顺序性,但可以保证消息在单个分区内的顺序性。
2.分区复制
每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存在 broker 上,每个 broker 可以保存成百上千个属于不同主题和分区的副本。副本有以下两种类型 :
首领副本 每个分区都有一个首领副本 。 为了保证一致性,所有生产者请求和消费者请求都会经过这个副本。
跟随者副本 首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一的任务就是从首领那里复制消息,保持与首领一致的状态。如果首领发生崩渍,其中的一个跟随者会被提升为新首领。
3. 生产者
默认情况下生产者在把消息均衡地分布到在主题的所有分区上,而并不关心特定消息会被写到那个分区;
如果指定消息键,则通过对消息键的散列来实现分区;
也可以通过消息键和分区器来实现把消息直接写到指定的分区,这个需要自定义分区器,需要实现Partitioner 接口,并重写其中的partition方法。
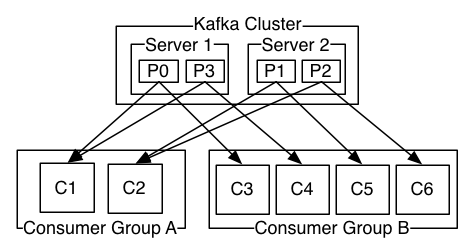
4. 消费者
消费者是消费者群组的一部分。也就是说,会有一个或者多个消费者共同读取一个主题,群组保证每个分区只能被一个消费者使用。
一个分区只能被同一个消费者群组里面的一个消费者读取,但可以被不同消费者群组里面的多个消费者读取。多个消费者群组可以共同读取同一个主题,彼此之间互不影响。
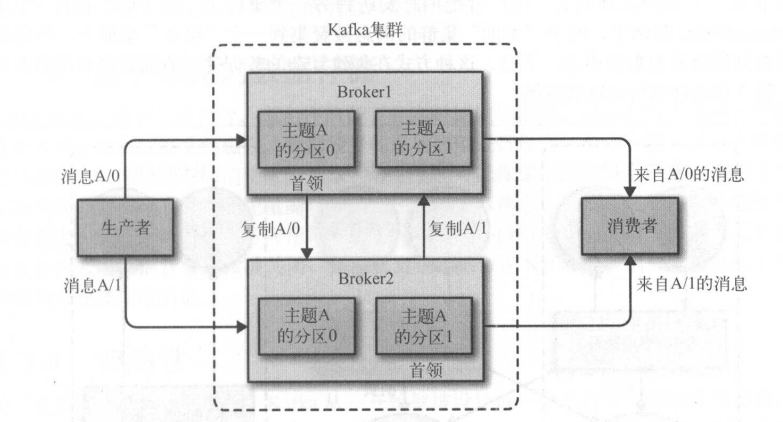
5.broker和集群
一个独立的kafka服务器被称为broker。broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘的消息。
broker是集群的组成部分。每一个集群都有一个broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给broker和监控broker。在集群中,一个分区从属一个broker,该broker被称为分区的首领。一个分区可以分配给多个broker,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果有一个broker失效,其他broker可以接管领导权。
更多kafka 的说明可以参考我的个人笔记:《Kafka权威指南》读书笔记
二、项目说明
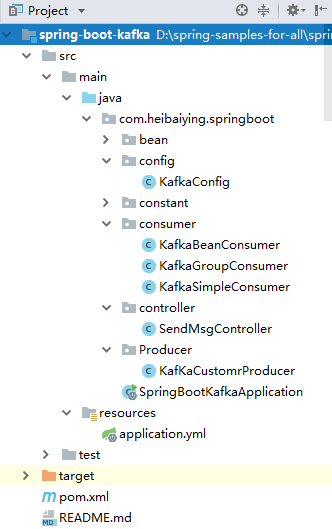
1.1 项目结构说明
本项目提供kafka发送简单消息、对象消息、和多消费者组消费消息三种情况下的sample。
kafkaSimpleConsumer 用于普通消息的监听;
kafkaBeanConsumer 用于对象消息监听;
kafkaGroupConsumer 用于多消费者组和多消费者对主题分区消息监听的情况。
1.2 主要依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka-test</artifactId> <scope>test</scope> </dependency>
二、 整合 kafka
2.1 kafka基本配置
spring:
kafka:
# 以逗号分隔的地址列表,用于建立与Kafka集群的初始连接(kafka 默认的端口号为9092)
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: true
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
这里需要说明的是:
在spring boot 2.X 版本 auto-commit-interval(自动提交的时间间隔)采用的是值的类型为Duration ,Duration 是 jdk 1.8 版本之后引入的类,在其源码中我们可以看到对于其字符串的表达需要符合一定的规范,即数字+单位,如下的写法1s ,1.5s, 0s, 0.001S ,1h, 2d 在yaml 中都是有效的。如果传入无效的字符串,则spring boot 在启动阶段解析配置文件的时候就会抛出异常。
public final class Duration
implements TemporalAmount, Comparable<Duration>, Serializable {
/**
* The pattern for parsing.
*/
private static final Pattern PATTERN =
Pattern.compile("([-+]?)P(?:([-+]?[0-9]+)D)?" +
"(T(?:([-+]?[0-9]+)H)?(?:([-+]?[0-9]+)M)?(?:([-+]?[0-9]+)(?:[.,]([0-9]{0,9}))?S)?)?", Pattern.CASE_INSENSITIVE);
........
}
2.2 KafkaTemplate实现消息发送
@Component
@Slf4j
public class KafKaCustomrProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, Object object) {
/*
* 这里的ListenableFuture类是spring对java原生Future的扩展增强,是一个泛型接口,用于监听异步方法的回调
* 而对于kafka send 方法返回值而言,这里的泛型所代表的实际类型就是 SendResult<K, V>,而这里K,V的泛型实际上
* 被用于ProducerRecord<K, V> producerRecord,即生产者发送消息的key,value 类型
*/
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, object);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
log.info("发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> sendResult) {
System.out.println("发送结果:" + sendResult.toString());
}
});
}
}
2.3 @KafkaListener注解实现消息的监听
@Component
@Slf4j
public class KafkaSimpleConsumer {
// 简单消费者
@KafkaListener(groupId = "simpleGroup", topics = Topic.SIMPLE)
public void consumer1_1(ConsumerRecord<String, Object> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic, Consumer consumer) {
System.out.println("消费者收到消息:" + record.value() + "; topic:" + topic);
/*
* 如果需要手工提交异步 consumer.commitSync();
* 手工同步提交 consumer.commitAsync()
*/
}
}
2.4 测试整合结果
@Slf4j
@RestController
public class SendMsgController {
@Autowired
private KafKaCustomrProducer producer;
@Autowired
private KafkaTemplate kafkaTemplate;
/***
* 发送消息体为基本类型的消息
*/
@GetMapping("sendSimple")
public void sendSimple() {
producer.sendMessage(Topic.SIMPLE, "hello spring boot kafka");
}
}
三、关于多消费者组的测试
3.1 创建多分区主题
/**
* @author : heibaiying
* @description : kafka配置类
*/
@Configuration
public class KafkaConfig {
@Bean
public NewTopic groupTopic() {
// 指定主题名称,分区数量,和复制因子
return new NewTopic(Topic.GROUP, 10, (short) 2);
}
}
3.2 多消费者组对同一主题的监听
消费者1-1 监听主题的 0、1 分区
消费者1-2 监听主题的 2、3 分区
消费者1-3 监听主题的 0、1 分区
消费者2-1 监听主题的所有分区
/**
* @author : heibaiying
* @description : kafka 消费者组
* <p>
* 多个消费者群组可以共同读取同一个主题,彼此之间互不影响。
*/
@Component
@Slf4j
public class KafkaGroupConsumer {
// 分组1 中的消费者1
@KafkaListener(id = "consumer1-1", groupId = "group1", topicPartitions =
{@TopicPartition(topic = Topic.GROUP, partitions = {"0", "1"})
})
public void consumer1_1(ConsumerRecord<String, Object> record) {
System.out.println("consumer1-1 收到消息:" + record.value());
}
// 分组1 中的消费者2
@KafkaListener(id = "consumer1-2", groupId = "group1", topicPartitions =
{@TopicPartition(topic = Topic.GROUP, partitions = {"2", "3"})
})
public void consumer1_2(ConsumerRecord<String, Object> record) {
System.out.println("consumer1-2 收到消息:" + record.value());
}
// 分组1 中的消费者3
@KafkaListener(id = "consumer1-3", groupId = "group1", topicPartitions =
{@TopicPartition(topic = Topic.GROUP, partitions = {"0", "1"})
})
public void consumer1_3(ConsumerRecord<String, Object> record) {
System.out.println("consumer1-3 收到消息:" + record.value());
}
// 分组2 中的消费者
@KafkaListener(id = "consumer2-1", groupId = "group2", topics = Topic.GROUP)
public void consumer2_1(ConsumerRecord<String, Object> record) {
System.err.println("consumer2-1 收到消息:" + record.value());
}
}
3.2 发送消息时候指定主题的具体分区
/***
* 多消费者组、组中多消费者对同一主题的消费情况
*/
@GetMapping("sendGroup")
public void sendGroup() {
for (int i = 0; i < 4; i++) {
// 第二个参数指定分区,第三个参数指定消息键 分区优先
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(Topic.GROUP, i % 4, "key", "hello group " + i);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
log.info("发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> sendResult) {
System.out.println("发送结果:" + sendResult.toString());
}
});
}
}
测试结果:
# 主要看每次发送结果中的 partition 属性,代表四次消息分别发送到了主题的0,1,2,3分区 发送结果:SendResult [producerRecord=ProducerRecord(topic=spring.boot.kafka.newGroup, partition=1, headers=RecordHeaders(headers = [], isReadOnly = true), key=key, value=hello group 1, timestamp=null), recordMetadata=spring.boot.kafka.newGroup-1@13] 发送结果:SendResult [producerRecord=ProducerRecord(topic=spring.boot.kafka.newGroup, partition=0, headers=RecordHeaders(headers = [], isReadOnly = true), key=key, value=hello group 0, timestamp=null), recordMetadata=spring.boot.kafka.newGroup-0@19] 发送结果:SendResult [producerRecord=ProducerRecord(topic=spring.boot.kafka.newGroup, partition=3, headers=RecordHeaders(headers = [], isReadOnly = true), key=key, value=hello group 3, timestamp=null), recordMetadata=spring.boot.kafka.newGroup-3@13] 发送结果:SendResult [producerRecord=ProducerRecord(topic=spring.boot.kafka.newGroup, partition=2, headers=RecordHeaders(headers = [], isReadOnly = true), key=key, value=hello group 2, timestamp=null), recordMetadata=spring.boot.kafka.newGroup-2@13] # 消费者组2 接收情况 consumer2-1 收到消息:hello group 1 consumer2-1 收到消息:hello group 0 consumer2-1 收到消息:hello group 2 consumer2-1 收到消息:hello group 3 # 消费者1-1接收情况 consumer1-1 收到消息:hello group 1 consumer1-1 收到消息:hello group 0 # 消费者1-3接收情况 consumer1-3 收到消息:hello group 1 consumer1-3 收到消息:hello group 0 # 消费者1-2接收情况 consumer1-2 收到消息:hello group 3 consumer1-2 收到消息:hello group 2
3.4 测试结果
和kafka 原本的机制一样,多消费者组之间对于同一个主题的消费彼此之间互不影响;
和kafka原本机制不一样的是,这里我们消费者1-1和消费1-3共同属于同一个消费者组,并且监听同样的分区,按照原本kafka的机制,群组保证每个分区只能被同一个消费者组的一个消费者使用,但是按照spring的声明方式实现的消息监听,这里被两个消费者都监听到了。
四、序列化与反序列化
用例采用的是第三方fastjson将实体类序列化为json后发送。实现如下:
/***
* 发送消息体为bean的消息
*/
@GetMapping("sendBean")
public void sendBean() {
Programmer programmer = new Programmer("xiaoming", 12, 21212.33f, new Date());
producer.sendMessage(Topic.BEAN, JSON.toJSON(programmer).toString());
}
@Component
@Slf4j
public class KafkaBeanConsumer {
@KafkaListener(groupId = "beanGroup",topics = Topic.BEAN)
public void consumer(ConsumerRecord<String, Object> record) {
System.out.println("消费者收到消息:" + JSON.parseObject(record.value().toString(), Programmer.class));
}
}
附:源码Gitub地址:https://github.com/heibaiying/spring-samples-for-all
---------------------
作者:m0_37809146
来源:CSDN
原文:https://blog.csdn.net/m0_37809146/article/details/86680328
版权声明:本文为博主原创文章,转载请附上博文链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号