使用node.js做爬虫
本文整理自你不知道的 node 爬虫原来这么简单
环境:cheerio,用来解析html 安装命令:npm install cheerio
IDE为sublime,选择build system 为js,将以下代码写入js文件中,build一下,就出结果,下面代码运行时间为3.0s,觉得麻烦却很快👍
const https = require('https');
const cheerio = require('cheerio');
const fs = require('fs');
https.get('https://movie.douban.com/top250', function(res){
let html = '';
res.on('data', function(chunk){
html+=chunk;
})
res.on('end', function(){
console.log(html);
const $ = cheerio.load(html);
let allFilms = [];
$('li .item').each(function(){
const title = $('.title', this).text();
const star = $('.rating_num', this).text();
const pic = $('.pic img', this).attr('src');
allFilms.push({
title, star, pic
})
})
fs.writeFile('./films.json', JSON.stringify(allFilms), function(err){
if(!err){
console.log('文件写入完毕');
}
})
downloadImage(allFilms);
})
})
function downloadImage(allFilms){
for(let i = 0; i < allFilms.length; i++){
const picUrl = allFilms[i].pic;
https.get(picUrl, function(res){
res.setEncoding('binary');
let str = '';
res.on('data', function(chunk){
str+=chunk;
})
res.on('end', function(){
fs.writeFile('./images/'+i+'.png', str, 'binary', function(err){
if(!err){
console.log('第'+i+'张图片下载成功');
}
})
})
})
}
}
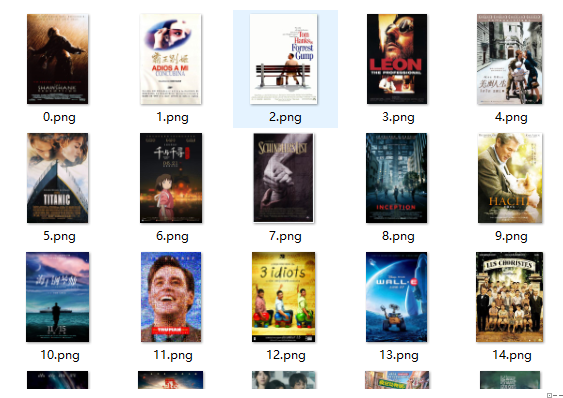
该代码爬取豆瓣250强电影页面,请求的过程中,获取到数据就做包的拼接,结束就分析拼接的文件,利用选择器得到想要的内容,将电影的相关信息存储在json文件中,文件内容如[{"title":"肖申克的救赎 / The Shawshank Redemption","star":"9.7","pic":"https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg"},{"title":"霸王别姬","star":"9.6","pic":"https://img3.···所示。
下载图片如下图所示