BAT常问问题总结以及回答(java基础回答一)
java 基础
- 八种基本数据类型的大小,以及他们的封装类
答:八种数据类型分别是byte(1字节)-128~127、short(2字节)-32768~32767、char(2字节)、int(4字节)、long(8字节)、float(4字节)、double(8字节)、boolean(本来是1bit的,但是计算机处理最小的单位是1字节),参数传递时候用的是参数传递,方法的修改并不能改变它。
-
- 引用数据类型
答:类、接口类型、数组类型、枚举类型、注解类型、String 使用的是引用传递(传递的是地址),方法的修改能改变原来的值。使用String时候也是引用传递,传的是地址,方法修改却并不能修改他其他的引用类可以通过引用传递修改内容。
- Switch能否用string做参数
答:jdk1.7之前不可以,但是之后可以了,将string类型转化为hashcode的int类型,从而可以switch
- equals与==的区别
equals比较的是内容是否相同,可以通过重写修改其具体含义;==比较的是栈里的地址,除了内容要一样以外还要让他们的类型一致,地址也一致。
- static的用途
答:static是没有this的,在类加载时进行加载的。分为三种:静态变量,静态方法,静态代码块
- 由于静态的在类加载之前就开始加载,而动态的是当new实例化的时候才开始加载,所以在动态中方法中可以使用静态方法,而在静态方法中无法使用动态变量和动态方法。
- 1、静态变量:
静态变量是供所有对象享有,只有一个副本,所以在改变他的值的时候,改变之后值就确定为修改后的了。而动态变量在每个对象中有他的对应副本,修改单个对象的动态变量的时候不会修改其他对象的动态变量。2、静态方法:静态方法不存在this,所以静态方法可以不依赖对象而去访问。动态方法可以调用静态方法,相反不行。
- 3、静态代码块:加载顺序:父类静态代码块,子类静态代码块,其他静态代码块,父类构造器,子类构造器。静态代码块只会被加载一次,所以对于多次需要的变量可以放到静态代码块当中。使用场景:需要初始化的方法和变量,经常使用的变量。
- 优点:可以不实例化对象直接使用static,使用方便,效率更高不会随对象清理自动清理。
- 缺点:如果创建了该类的任何实例,不能使用实例来访问静态成员,因为静态成员管理的是整个类的信息,需要的是对象的成员变量。另外加载了静态,长时间不适用会耗费内存。
- 自动装箱,常量池
自动装箱和自动拆箱相对应。自动装箱的过程是自动将基本类型转变成包装器类型;而自动拆箱过程是自动将包装器类型转变成基本类型。基本类型对应的包装类型:object——>Number、Boolean->boolean、Character->char
- number:byte->Byte short->Short int->Integer long->Long float->Float double ->Double装箱:Integer num = 99; Integer num = Integer.valueOf(99);
- 拆箱:int number = num; int number = num.intValue();
-
- Object有哪些公用方法
hashcode() equals() finalized() wait() notify() notifyAll() toString() clone() getclass()
- clone的两种类型及其原理
clone分为深克隆和浅克隆,深浅克隆都需要重写方法clone,clone()方法需要类实现clonable接口 ,这个接口相当于一个许可,他本身不带有clone方法,但是没有实现这个接口的类调用clone方法的话会出现clonenotsupportexception异常。单纯的object1=object1; 其实是两个变量同时指向同一个地址而已,并没有生成新的对象。
package test; import java.util.ArrayList; public class A implements Cloneable { public ArrayList b = new ArrayList(); // 浅克隆 // @Override // protected Object clone() throws CloneNotSupportedException { // A a = (A) super.clone(); // return a; // } // // 深克隆 // public Object clone() throws CloneNotSupportedException { // A a = (A) super.clone(); // a.b = (ArrayList) b.clone(); // return a; // } public static void main(String[] args) throws CloneNotSupportedException { A a = new A(); a.b.add("s"); A b = (A) a.clone(); a.b.add("b"); System.out.println(b.b.size()); } }
- Java的四种引用,强弱软虚,用到的场景
强引用:强引用的使用就是我们常用到的实例化,A a = new A(),垃圾回收器不能随意清理强引用的对象,即使是抛出oom异常也不能清理(生活必需品,不能清理)软引用:软引用一般配合一个引用队列使用
Object obj=new Object(); ReferenceQueue refQueue=new ReferenceQueue(); SoftReference softRef=new SoftReference(obj,refQueue);
String str=new String("abc"); // 强引用 SoftReference<String> softRef=new SoftReference<String>(str); // 软引用
软引用一般是当内存不足的时候才会清除,内存充足的时候调用system.gc()不会清除掉软引用。(生活可有可无品,家满了的时候清除,平时不动)
弱引用:也是配合一个引用队列使用,当被清理的时候,将其放入引用队列中。当gc扫描到该对象的时候,无论内存是否已满,都会回收。是一种比软引用生命力更弱的引用。但是由于gc的优先级较低,所以被清理的String str=new String("abc"); WeakReference<String> abcWeakRef = new WeakReference<String>(str);
虚引用:也叫幽灵引用,用来跟踪对象被垃圾回收器回收的活动。与强引用和软引用的区别在与他必须和引用队列配合使用,在虚引用指向的对象要被清除的时候,先将虚引用放入到引用队列中去,才是清理所要清理的对象指向。 - Hashcode的作用
Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的 字段等)映射成一个数值,这个数值称作为散列值。用来快速查找对应对象的,如果两个对象equals相等(地址和内容都相等),那么他们的hashcode也一定相同。当重写对象的equals方法时候,尽量重写对象的hashcode方法(在hashmap等需要处理冲突问题的地方是必须重写hashcode方法的)。如果两个对象的hashcode一样,那么只能证明他们在一个存储位置,但是不能证明他们完全相同,因为可能会出现碰撞。
- HashMap的hashcode的作用
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
作用:1、为了保证查找的快捷性;2、在使用equals时一定要重写hashcode方法,因为hashmap采取桶机制来解决map冲突问题,当两个对象的hashcode相同的时候,他们可能同时处于同一个bucket中的一个队列上。所以hashmap中hashcode相同的,其值不一定相同。 - 为什么重载hashCode方法?
1、重写equals方法时需要重写hashCode方法,主要是针对Map、Set等集合类型的使用;
a: Map、Set等集合类型存放的对象必须是唯一的;
b: 集合类判断两个对象是否相等,是先判断equals是否相等,如果equals返回TRUE,还要再判断HashCode返回值是否ture,只有两者都返回ture,才认为该两个对象是相等的。
2、由于Object的hashCode返回的是对象的hash值,所以即使equals返回TRUE,集合也可能判定两个对象不等,所以必须重写hashCode方法,以保证当equals返回TRUE时,hashCode也返回Ture,这样才能使得集合中存放的对象唯一。
- ArrayList、LinkedList、Vector的区别
答:Arraylist和Vector底层都是数组实现的,但是Arraylist是线程不安全的,而Vector是线程安全的;性能上由于Vector使用了synchronized方法来保证同步,所以性能上要比arraylist差。二者的插入速度:从内部实现机制来讲ArrayList和Vector都是使用数组(Array)来控制集合中的对象。当你向这两种类型中增加元素的时候,如果元素的数目超出了内部数组目前的长度它们都需要扩展内部数组的长度,Vector缺省情况下自动增长原来一倍的数组长度,ArrayList是原来的50%,所以最后你获得的这个集合所占的空间总是比你实际需要的要大。所以如果你要在集合中保存大量的数据那么使用Vector有一些优势,因为你可以通过设置集合的初始化大小来避免不必要的资源开销。LinkedList也是线程不安全的,底层是链表。当向插入和删除的时间复杂度是O(1),但是查找是很慢的,需要沿着链表去找。当在Arraylist和linkedlist末尾插入一个数据,哪个时间快?答:如果Arraylist已满,则需要扩充容量(扩充之前的一半容量),则linkedlist速度快正常情况下应该是arraylist更快,因为他只需要设置数组下标,而linkedlist还需要加指针进行连接。但如果是在列表的中间插入的话,那么linkedlist就比arraylist速度要快了,因为arraylist需要将数组中元素位置移动,而linkedlist直接指针操作。
- String、StringBuffer与StringBuilder的区别
一、执行速度比较:StringBuilder>StringBuffer>StringString最慢的原因是,String存的是不可变的字符串,而我们使用String str = "www"; str=str+"asd";时候看起来他是可变的,但是实际上是新创建了一个名为str的String变量,将之前的那个gc掉了。所以每次都需要进行产生副本才能进行String扩充,所以速度慢。而当我们使用str=“www"+"asd";的时候其实是wwwasd一起的。二、线程安全:StringBuilder是线程不安全的,StringBuffer是线程安全的(使用Sychonized来保证线程安全)。三、总结:
- String用来表示字符不是很多的字符串操作
- StringBuffer当多线程的时候使用
- StirngBuilder当单线程的时候使用
-
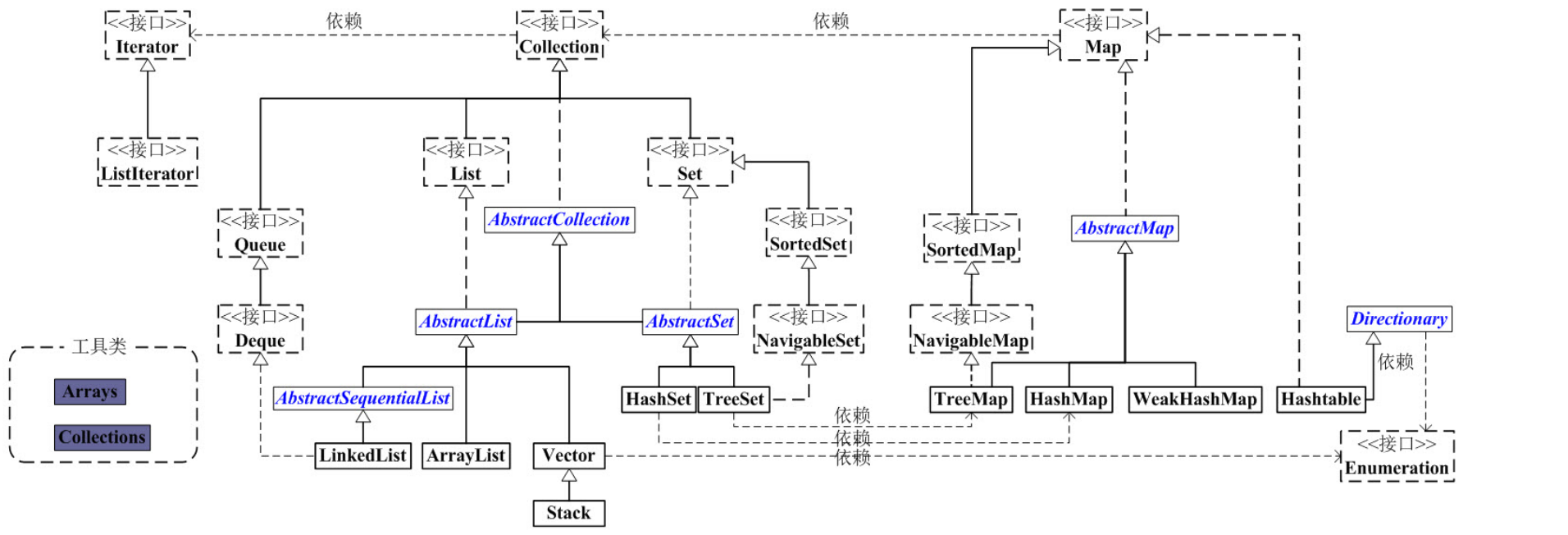
- Map、Set、List、Queue、Stack的特点与用法
1. Interface Iterable 迭代器接口,这是Collection类的父接口。实现这个Iterable接口的对象允许使用foreach进行遍历,也就是说,所有的Collection集合对象都具有"foreach可遍历性"。这个Iterable接口只
有一个方法: iterator()。它返回一个代表当前集合对象的泛型<T>迭代器,用于之后的遍历操作 1.1 Collection Collection是最基本的集合接口,一个Collection代表一组Object的集合,这些Object被称作Collection的元素。Collection是一个接口,用以提供规范定义,不能被实例化使用 1) Set Set集合类似于一个罐子,"丢进"Set集合里的多个对象之间没有明显的顺序。Set继承自Collection接口,不能包含有重复元素(记住,这是整个Set类层次的共有属性)。 Set判断两个对象相同不是使用"=="运算符,而是根据equals方法。也就是说,我们在加入一个新元素的时候,如果这个新元素对象和Set中已有对象进行注意equals比较都返回false,
则Set就会接受这个新元素对象,否则拒绝。 因为Set的这个制约,在使用Set集合的时候,应该注意两点:1) 为Set集合里的元素的实现类实现一个有效的equals(Object)方法、2) 对Set的构造函数,传入的Collection参数不能包
含重复的元素 1.1) HashSet HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,因此具有良好的存取和查找性能。当向HashSet集合中存入一个元素时,HashSet会调用该对象的
hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。 值得主要的是,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法的返回值相等 1.1.1) LinkedHashSet LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。 LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历) 1.2) SortedSet 此接口主要用于排序操作,即实现此接口的子类都属于排序的子类 1.2.1) TreeSet TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态 1.3) EnumSet EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的,
它们以枚举值在Enum类内的定义顺序来决定集合元素的顺序 2) List List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List集合允许加入重复元素,因为它可以通过索引来访问指定位置的集合元素。List集合默认按元素
的添加顺序设置元素的索引 2.1) ArrayList ArrayList是基于数组实现的List类,它封装了一个动态的增长的、允许再分配的Object[]数组。 2.2) Vector Vector和ArrayList在用法上几乎完全相同,但由于Vector是一个古老的集合,所以Vector提供了一些方法名很长的方法,但随着JDK1.2以后,java提供了系统的集合框架,就将
Vector改为实现List接口,统一归入集合框架体系中 2.2.1) Stack Stack是Vector提供的一个子类,用于模拟"栈"这种数据结构(LIFO后进先出) 2.3) LinkedList implements List<E>, Deque<E>。实现List接口,能对它进行队列操作,即可以根据索引来随机访问集合中的元素。同时它还实现Deque接口,即能将LinkedList当作双端队列
使用。自然也可以被当作"栈来使用" 3) Queue Queue用于模拟"队列"这种数据结构(先进先出 FIFO)。队列的头部保存着队列中存放时间最长的元素,队列的尾部保存着队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,
访问元素(poll)操作会返回队列头部的元素,队列不允许随机访问队列中的元素。结合生活中常见的排队就会很好理解这个概念 3.1) PriorityQueue PriorityQueue并不是一个比较标准的队列实现,PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按照队列元素的大小进行重新排序,这点从它的类名也可以
看出来 3.2) Deque Deque接口代表一个"双端队列",双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可以当成队列使用、也可以当成栈使用 3.2.1) ArrayDeque 是一个基于数组的双端队列,和ArrayList类似,它们的底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出该数组的容量时,系统会在底层重
新分配一个Object[]数组来存储集合元素 3.2.2) LinkedList 1.2 Map Map用于保存具有"映射关系"的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value。key和value都可以是任何引用类型的数据。Map的key不允
许重复,即同一个Map对象的任何两个key通过equals方法比较结果总是返回false。 关于Map,我们要从代码复用的角度去理解,java是先实现了Map,然后通过包装了一个所有value都为null的Map就实现了Set集合 Map的这些实现类和子接口中key集的存储形式和Set集合完全相同(即key不能重复) Map的这些实现类和子接口中value集的存储形式和List非常类似(即value可以重复、根据索引来查找) 1) HashMap 和HashSet集合不能保证元素的顺序一样,HashMap也不能保证key-value对的顺序。并且类似于HashSet判断两个key是否相等的标准也是: 两个key通过equals()方法比较返回true、
同时两个key的hashCode值也必须相等 1.1) LinkedHashMap LinkedHashMap也使用双向链表来维护key-value对的次序,该链表负责维护Map的迭代顺序,与key-value对的插入顺序一致(注意和TreeMap对所有的key-value进行排序进行区
分) 2) Hashtable 是一个古老的Map实现类 2.1) Properties Properties对象在处理属性文件时特别方便(windows平台上的.ini文件),Properties类可以把Map对象和属性文件关联起来,从而可以把Map对象中的key-value对写入到属性文
件中,也可以把属性文件中的"属性名-属性值"加载到Map对象中 3) SortedMap 正如Set接口派生出SortedSet子接口,SortedSet接口有一个TreeSet实现类一样,Map接口也派生出一个SortedMap子接口,SortedMap接口也有一个TreeMap实现类 3.1) TreeMap TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的
key-value对处于有序状态。同样,TreeMap也有两种排序方式: 自然排序、定制排序 4) WeakHashMap WeakHashMap与HashMap的用法基本相似。区别在于,HashMap的key保留了对实际对象的"强引用",这意味着只要该HashMap对象不被销毁,该HashMap所引用的对象就不会被垃圾回收。
但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,当垃
圾回收了该key所对应的实际对象之后,WeakHashMap也可能自动删除这些key所对应的key-value对 5) IdentityHashMap IdentityHashMap的实现机制与HashMap基本相似,在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等 6) EnumMap EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap根据key的自然顺序
(即枚举值在枚举类中的定义顺序) - HashMap和HashTable的区别
区别一:出现时间不同,HashMap比HashTable上线较晚。HashMap和HashTable都是基于HashCode来实现的,所以从他们暴露在外的api看起区别二:接口不同,HashMap继承了Abstract Map抽象类,而Abstract Map实现了Map接口;HashTable之前是继承了Dictionary抽象类,但是该抽象类已经过时,所以现在是实现了Map接口。他俩都实现了Map、Cloneable、Serializable接口。区别三:支持空不同,HashMap支持null值和null键(将null的hashcode设置为0),而HashTable传入null值和null键的时候会抛出NullPointerException.区别四:数据结构相同,HashMap和HashTable都实现了entry接口,entry对象在内部保存一个键值对。
Entry对象唯一表示一个键值对,有四个属性:
-K key 键对象
-V value 值对象
-int hash 键对象的hash值
-Entry entry 指向链表中下一个Entry对象,可为null,表示当前Entry对象在链表尾部内部有一个指向entry的数组,数组的每个元素都是一个entry,每个entry结构又是个链表结构,指向下一个entry。
1.8之前当发生hash冲突的时候可以使用entry的链表来解决冲突;但是很难保证hashmap的均匀性,很容易出现很长的链表,影响查询效率。
1.8之后使用了红黑树解决hash冲突,具体的可以看:https://blog.csdn.net/u011240877/article/details/53358305
以上二者是相同的但是二者在实现数据结构时的算法不同:需要有算法在哈希桶内的键值对多到一定程度时,扩充哈希表的大小(数组的大小)。HashTable的初始大小为11,他每次扩充为原来的2*n+1,第二次为23;HashMap的初始大小为16,他每次扩充为原来的2*n,第二次为32.如果在创建时给定了初始化大小(5),那么HashTable会直接使用你给定的大小(5),而HashMap会将其扩充为2的幂次方大小(32)可以看出hashtable取得的大小一般为素数,因为使用素数作为大小的话可以取模hash更均匀;但是如果是2的幂次方的话,可以直接使用位运算,比除法效率更高;所以总体说还是hashmap的效率更高。区别五:hashtable是线程安全的而hashmap是线程不安全的。hashtable使用了synchronized描述符。如果你不需要线程安全,那么使用HashMap,如果需要线程安全,那么使用ConcurrentHashMap。HashTable已经被淘汰了,不要在新的代码中再使用它。 - JDK7与JDK8中HashMap的实现
JDK7就是个数组和entry链表的结合,在数组中的位置就是通过hashcode算法得出,而如果发生了hash冲突,就将旧值放到链表,将新值放到数组的entry中;当键为null时,全都保存到table[0]上,当数组不够用的时候会以原先值的2倍扩充它。JDK8则是利用红黑树和链表结合解决的hash冲突问题,当同数组节点上的链表元素小于8个的话就用链表表示,大于等于8个时才转化为红黑树;链表的查找时间复杂度最坏情况下为O(n),而红黑树的时间复杂度一直是O(lgn);同时entry也变成了node,因为红黑树和node有关。
- HashMap和ConcurrentHashMap的区别,HashMap的底层源码
HashMap是线程不安全的,而ConcurrentHashMap是线程安全的;HashMap可以存null值而ConcurrentHashMap不可以存放null键和null值。ConcurrentHashMap的实现原理是:引入一个"分段锁"机制,可以理解为把一个Map拆分成n个小的table,根据key.hashCode()来决定把key放到哪个HashTable中 每个segement是一个数组单元,使用ReentrantLock来保证每个segement是线程安全的,以保证全局的线程安全。每个segement中的结构类似于hashmap。一个重要指标是concurrencyLevel可以翻译成并行级别,并行数,segement数等,默认为16,表示默认有16个segement字段,不同线程的写操作放在16个不同的segement中就可以实现多线程。这个指标是可以初始化的,初始化后的值不可以更改。
- ConcurrentHashMap能完全替代HashTable吗?????????(这道题保留)
HashTable可以看成是Hashmap的线程安全整合版,当HashTable大小增加到一定程度的时候,性能会急剧下降,因为迭代时需要长时间锁定,所以效率很低
- 为什么HashMap是线程不安全的
因为Hashmap中的put方法并不是线程同步的(他所调用的addentry()entry链表增长方法也不是线程同步的),容易出现两个线程分别同时加入一个元素,让后hash冲突,进入同一个链进行addEntry可能会出现线程竞技,导致一个元素丢失。另一方面,resize()方法(增加entry方法)也不是线程安全的,多个线程同时到达entry数量阈值的时候就会导致只有一个线程的entry扩容成功,其他的全部新增数据丢失。
- 如何线程安全的使用HashMap
了解了HashMap为什么线程不安全,那现在看看如何线程安全的使用HashMap。这个无非就是以下三种方式:
- Hashtable
- ConcurrentHashMap
- Synchronized Map
例子:
//Hashtable Map<String, String> hashtable = new Hashtable<>(); //synchronizedMap Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>()); //ConcurrentHashMap Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
依次来看看。
Hashtable
先稍微吐槽一下,为啥命名不是HashTable啊,看着好难受,不管了就装作它叫HashTable吧。这货已经不常用了,就简单说说吧。HashTable源码中是使用
synchronized来保证线程安全的,比如下面的get方法和put方法:public synchronized V get(Object key) { // 省略实现 } public synchronized V put(K key, V value) { // 省略实现 }
所以当一个线程访问HashTable的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。举个例子,当一个线程使用put方法时,另一个线程不但不可以使用put方法,连get方法都不可以,好霸道啊!!!so~~,效率很低,现在基本不会选择它了。
ConcurrentHashMap
ConcurrentHashMap(以下简称CHM)是JUC包中的一个类,Spring的源码中有很多使用CHM的地方。之前已经翻译过一篇关于ConcurrentHashMap的博客,如何在java中使用ConcurrentHashMap,里面介绍了CHM在Java中的实现,CHM的一些重要特性和什么情况下应该使用CHM。需要注意的是,上面博客是基于Java 7的,和8有区别,在8中CHM摒弃了Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法,有时间会重新总结一下。
SynchronizedMap
看了一下源码,SynchronizedMap的实现还是很简单的。
// synchronizedMap方法 public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) { return new SynchronizedMap<>(m); } // SynchronizedMap类 private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable { private static final long serialVersionUID = 1978198479659022715L; private final Map<K,V> m; // Backing Map final Object mutex; // Object on which to synchronize SynchronizedMap(Map<K,V> m) { this.m = Objects.requireNonNull(m); mutex = this; } SynchronizedMap(Map<K,V> m, Object mutex) { this.m = m; this.mutex = mutex; } public int size() { synchronized (mutex) {return m.size();} } public boolean isEmpty() { synchronized (mutex) {return m.isEmpty();} } public boolean containsKey(Object key) { synchronized (mutex) {return m.containsKey(key);} } public boolean containsValue(Object value) { synchronized (mutex) {return m.containsValue(value);} } public V get(Object key) { synchronized (mutex) {return m.get(key);} } public V put(K key, V value) { synchronized (mutex) {return m.put(key, value);} } public V remove(Object key) { synchronized (mutex) {return m.remove(key);} } // 省略其他方法 }
从源码中可以看出调用synchronizedMap()方法后会返回一个SynchronizedMap类的对象,而在SynchronizedMap类中使用了synchronized同步关键字来保证对Map的操作是线程安全的。
性能对比
这是要靠数据说话的时代,所以不能只靠嘴说CHM快,它就快了。写个测试用例,实际的比较一下这三种方式的效率(源码来源),下面的代码分别通过三种方式创建Map对象,使用
ExecutorService来并发运行5个线程,每个线程添加/获取500K个元素。public class CrunchifyConcurrentHashMapVsSynchronizedMap { public final static int THREAD_POOL_SIZE = 5; public static Map<String, Integer> crunchifyHashTableObject = null; public static Map<String, Integer> crunchifySynchronizedMapObject = null; public static Map<String, Integer> crunchifyConcurrentHashMapObject = null; public static void main(String[] args) throws InterruptedException { // Test with Hashtable Object crunchifyHashTableObject = new Hashtable<>(); crunchifyPerformTest(crunchifyHashTableObject); // Test with synchronizedMap Object crunchifySynchronizedMapObject = Collections.synchronizedMap(new HashMap<String, Integer>()); crunchifyPerformTest(crunchifySynchronizedMapObject); // Test with ConcurrentHashMap Object crunchifyConcurrentHashMapObject = new ConcurrentHashMap<>(); crunchifyPerformTest(crunchifyConcurrentHashMapObject); } public static void crunchifyPerformTest(final Map<String, Integer> crunchifyThreads) throws InterruptedException { System.out.println("Test started for: " + crunchifyThreads.getClass()); long averageTime = 0; for (int i = 0; i < 5; i++) { long startTime = System.nanoTime(); ExecutorService crunchifyExServer = Executors.newFixedThreadPool(THREAD_POOL_SIZE); for (int j = 0; j < THREAD_POOL_SIZE; j++) { crunchifyExServer.execute(new Runnable() { @SuppressWarnings("unused") @Override public void run() { for (int i = 0; i < 500000; i++) { Integer crunchifyRandomNumber = (int) Math.ceil(Math.random() * 550000); // Retrieve value. We are not using it anywhere Integer crunchifyValue = crunchifyThreads.get(String.valueOf(crunchifyRandomNumber)); // Put value crunchifyThreads.put(String.valueOf(crunchifyRandomNumber), crunchifyRandomNumber); } } }); } // Make sure executor stops crunchifyExServer.shutdown(); // Blocks until all tasks have completed execution after a shutdown request crunchifyExServer.awaitTermination(Long.MAX_VALUE, TimeUnit.DAYS); long entTime = System.nanoTime(); long totalTime = (entTime - startTime) / 1000000L; averageTime += totalTime; System.out.println("2500K entried added/retrieved in " + totalTime + " ms"); } System.out.println("For " + crunchifyThreads.getClass() + " the average time is " + averageTime / 5 + " ms\n"); } }
测试结果:
这个就不用废话了,CHM性能是明显优于Hashtable和SynchronizedMap的,CHM花费的时间比前两个的一半还少,哈哈,以后再有人问就可以甩数据了。
Test started for: class java.util.Hashtable 2500K entried added/retrieved in 2018 ms 2500K entried added/retrieved in 1746 ms 2500K entried added/retrieved in 1806 ms 2500K entried added/retrieved in 1801 ms 2500K entried added/retrieved in 1804 ms For class java.util.Hashtable the average time is 1835 ms Test started for: class java.util.Collections$SynchronizedMap 2500K entried added/retrieved in 3041 ms 2500K entried added/retrieved in 1690 ms 2500K entried added/retrieved in 1740 ms 2500K entried added/retrieved in 1649 ms 2500K entried added/retrieved in 1696 ms For class java.util.Collections$SynchronizedMap the average time is 1963 ms Test started for: class java.util.concurrent.ConcurrentHashMap 2500K entried added/retrieved in 738 ms 2500K entried added/retrieved in 696 ms 2500K entried added/retrieved in 548 ms 2500K entried added/retrieved in 1447 ms 2500K entried added/retrieved in 531 ms For class java.util.concurrent.ConcurrentHashMap the average time is 792 ms
- 多并发情况下HashMap是否还会产生死循环
因为在hash冲突时链表添加新的entry的时候会使用头插法插入新节点,所以可能会出现多线程的时候产生环。具体原因,当size已满,两个线程put新元素时,一个线程读取完当前链表的顺序后,就另一个线程进行扩容,扩容需要调用transfer函数,因为头插法所以导致刚才的链表顺序在rehash后顺序反转,然后切回第一个线程,重新rehash的时候,由于第二个线程导致的顺序反转而产生环。
-
- TreeMap、HashMap、LindedHashMap的区别
Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复。
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。LinkedHashMap使用after before指针来控制插入的顺序。 - Collection包结构,与Collections的区别
![]() Collection是单列集合,是集合类的上级接口,子接口主要有Set和List、Map。Collections是针对集合类的一个帮助类,提供了操作集合的工具方法:一系列静态方法实现对各种集合的搜索、排序、替换和线程安全化等操作。
Collection是单列集合,是集合类的上级接口,子接口主要有Set和List、Map。Collections是针对集合类的一个帮助类,提供了操作集合的工具方法:一系列静态方法实现对各种集合的搜索、排序、替换和线程安全化等操作。 - try?catch?finally,try里有return,finally还执行么
还执行。
- Excption与Error包结构,OOM你遇到过哪些情况,SOF你遇到过哪些情况
他俩都实现throwable接口,Exception下还继承了RuntimeException。java可抛出的分为三种可检查异常,运行时异常,错误error第一种:运行时异常:如果异常没有人为的被throws和try catch捕获的话就直接被编译器通过,例如byzeroexception第二种:可抛出异常:java编译器会检查到他,除非使用异常捕获进行捕获否则将不能通过编译。例如ClassNotFoundException。被检查异常一般都是可以恢复的第三种:错误:编译器也不会对错误进行检查。 当资源不足、约束失败、或是其它程序无法继续运行的条件发生时,就产生错误。程序本身无法修复这些错误的。例如,VirtualMachineError就属于错误。
OOM异常是内存溢出异常:?????????????????? - Java(OOP)面向对象的三个特征与含义
三个特征是:封装,继承,多态封装:是指某个类通过权限控制来限制其他类直接读取该类的成员变量和成员方法,使用getset有选择的公布部分成员。继承:继承是子对象可以继承父对象的属性和行为多态:多态是指父对象中的同一个行为能在其多个子对象中有不同的表现
- Override和Overload的含义去区别
- Interface与abstract类的区别
- Static?class?与non?static?class的区别
- java多态的实现原理
- foreach与正常for循环效率对比
- Java?IO与NIO
- java反射的作用于原理
什么是反射:
1、在运行状态中,对于任意一个类,都能够知道这个类的属性和方法。
2、对于任意一个对象,都能够调用它的任何方法和属性。
这种动态获取信息以及动态调用对象的方法的功能称为JAVA的反射。
反射的作用:
在JAVA中,只有给定类的名字,就可以通过反射机制来获取类的所有信息,可以动态的创建对象和编译。
实现原理:
JAVA语言编译之后会生成一个.class文件,反射就是通过字节码文件找到某一个类、类中的方法以及属性等。
反射的实现主要借助以下四个类:
Class:类的对象
Constructor:类的构造方法
Field:类中的属性对象
Method:类中的方法对象
根据类的名字获取类:Class<T> c = Class.forName("类名");
根据类c获取对象:Object o = c.newInstance();
根据类c获取实现的接口:Class<?> interfaces = c.getInterfaces();
获取有参构造器:Constructor<?> con = c.getConstructor(String.class,int.class);
获取属性:Field f2 = c.getField("age");
方法调用:
public class ReflectCase { public static void main(String[] args) throws Exception { Proxy target = new Proxy(); Method method = Proxy.class.getDeclaredMethod("run"); method.invoke(target); } static class Proxy { public void run() { System.out.println("run"); } } }
- 泛型常用特点
- 解析XML的几种方式的原理与特点:DOM、SAX
- Java1.7与1.8,1.9,10 新特性
- 设计模式:单例、工厂、适配器、责任链、观察者等等
- JNI的使用
- AOP是什么
- OOP是什么
- AOP与OOP的区别
AOP是面向切面编程,是spring中的一个特性,可以增加业务的重用性,一旦某一功能出现问题直接修改该功能所在模块就好。隔离业务,降低耦合度,提高开发效率。常用来处理日志记录,性能统计,安全分析等。
OOP是java的基本编程思想,面向对象编程。针对业务处理过程中的实体以及属性和行为进行封装,以获得更加清晰的逻辑划分。
区别:对于某一类物体,其所具有的属性和动作方法可以使用oop来进行封装;而对于一个行为片段我们只能使用aop进行隔离,最常用的AOP应用在数据库连接以及事务处理上,实现模式为代理模式和工厂模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号